1つのパラダイム
1.1 パラダイムの概要
リレーショナル データベースでは、データ テーブル設計の基本原則と規則はパラダイムと呼ばれます。
これは、データ テーブルの設計構造が満たす必要がある、特定の設計標準のレベルとして理解できます。合理的に構造化されたリレーショナル データベースを設計するには、特定のパラダイムを満たす必要があります。
1.2 パラダイムには何が含まれますか?
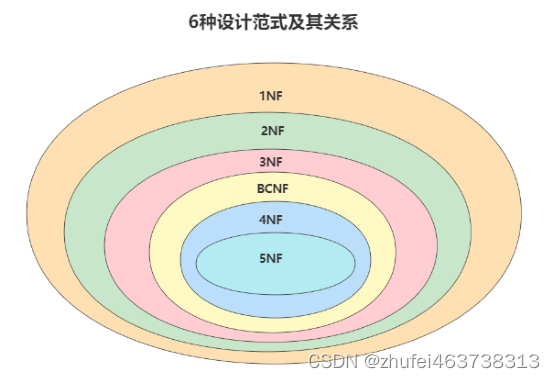
現在、リレーショナル データベースには 6 つの一般的なパラダイムがあり、パラダイム レベルに応じて、低いものから高いものの順に、第 1 正規形 (1NF)、第 2 正規形 (2NF)、第 3 正規形 (3NF)、バスコード正規形となります
。形式 (BCNF) )、第 4 正規形 (4NF)、および第 5 正規形 (5NF、完全正規形とも呼ばれます
)。
1.3 キーと関連する属性の概念
例:
ここには 2 つのテーブルがあります:
プレーヤー テーブル (プレーヤー): プレーヤー番号 | 名前 | ID 番号 | 年齢 | チーム番号
チーム テーブル (チーム): チーム番号 | ヘッド コーチ | チームの所在地
フィールド名 フィールド タイプが Yes であるかどうか 主キー説明
ID INT はい 主キー ID
username VARCHAR(30) No ユーザー名
password VARCHAR(50) No パスワード
user_info VARCHAR(255) No ユーザー情報 (本名、電話番号、住所を含む)
- スーパー キー: プレーヤー テーブルの場合、スーパー キーは、(プレーヤー番号) (プレーヤー番号、名前) (ID 番号、年齢) など、プレーヤー番号または ID 番号の任意の組み合わせです。
- 候補キー:最小のスーパーキーで、選手テーブルの場合は(選手番号)または(IDカード番号)が候補キーとなります。
- 主キー: 自分で選択します。つまり、(プレイヤー番号) などの候補キーから 1 つを選択します。
- 外部キー: プレーヤー テーブルのチーム番号。
- 主属性、非主属性:選手テーブルにおいて主属性は(選手番号)(IDカード番号)であり、その他の属性(名前)(年齢)(チーム番号)は非主属性である。
1.4 第一正規形
例 1:
会社が従業員の名前と連絡先情報を保存したいとします。次のようなテーブルが作成されます。
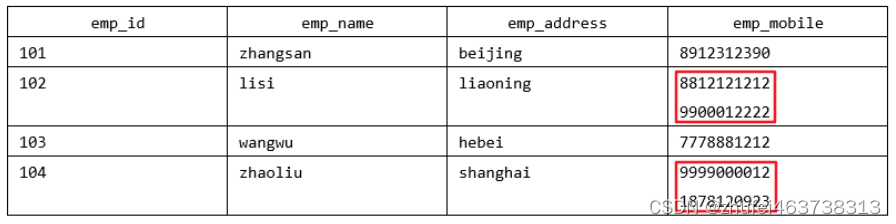
このテーブルは 1NF に準拠していません。ルールに「テーブルの各属性にはアトミック (単一) 値がなければなりません」と記載されており、lisi 従業員と zhaoliu 従業員の emp_mobile 値がそのルールに違反しているためです。テーブルを 1NF に準拠させるには、次のテーブル データが必要です:
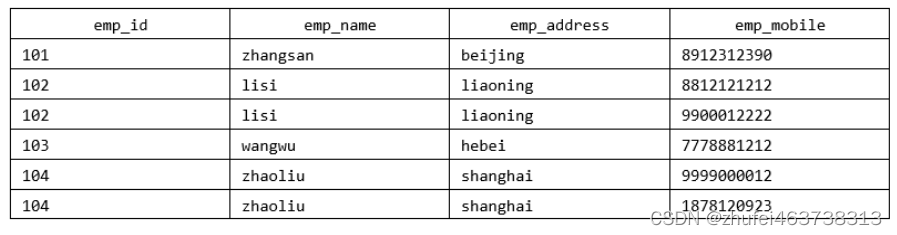
例 2:
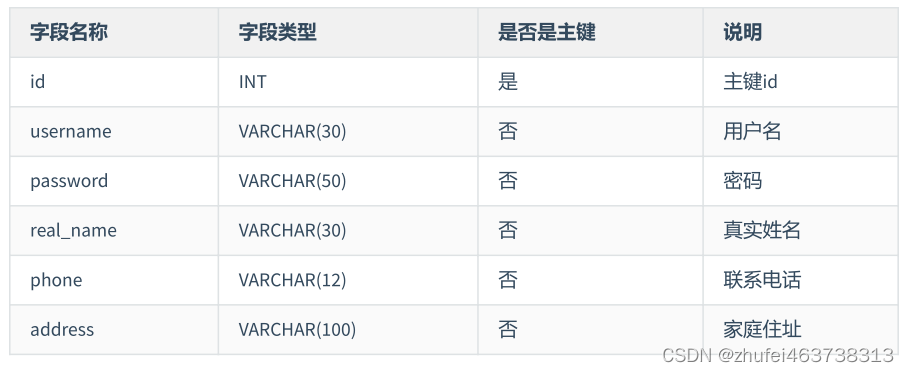
ユーザー テーブルの設計は第 1 正規形に準拠していません
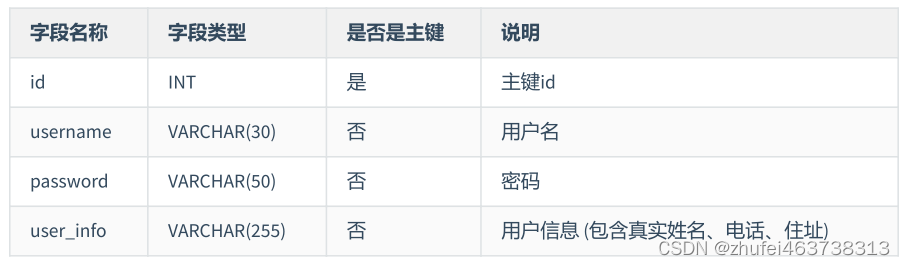
。 user_info フィールドはユーザー情報であり、さらに小さなデータに分割できます。 -粒度フィールドは、データベース設計要件に準拠していません。パラダイム要件です。user_info は次のように分割されます。
例 3:
属性の原子性は主観的です。たとえば、Employees リレーションシップの従業員名は 1 (フルネーム)、2 (名
と姓)、または 3 (名、ミドルネーム、姓) 属性で表す必要がありますか? 答えはアプリケーションによって異なります。
アプリケーションで従業員の名前の部分を個別に処理する必要がある場合(検索目的など)、それらを分離する必要がある場合があります。それ以外の場合は必要ありません。
表 1:

表 2:

1.5 秒正規形
例1:
得点表(学籍番号、科目番号、成績)の関係において、(学籍番号、科目番号)は成績を決定することができますが、学生番号で成績を決定することはできず、科目番号で成績を決定することはできません。したがって、「(学生番号, 科目番号) )→得点」は完全な依存関係になります。
例 2:
ゲーム テーブル player_game には、プレイヤー番号、名前、年齢、ゲーム番号、試合時間、試合会場などの属性が含まれています。ここでの候補キーと主キーは両方とも (プレイヤー番号、ゲーム番号) です。 key (または主キー) ) を使用して、次の関係を決定します。
(球员编号, 比赛编号) → (姓名, 年龄, 比赛时间, 比赛场地,得分)
ただし、データ テーブル内のフィールド間には次の対応関係が依然として存在するため、このデータ テーブルは第 2 正規形を満たしていません。
(球员编号) → (姓名,年龄)
(比赛编号) → (比赛时间, 比赛场地)
非主属性の場合、候補キーは完全には依存しません。これによりどのような問題が発生するのでしょうか?
- データの冗長性: プレーヤーが m 試合に参加できる場合、プレーヤーの名前と年齢は m-1 回繰り返されます。ゲームには n 人のプレイヤーが参加することもあり、ゲームの時間と場所は n-1 回繰り返されます。
- 挿入例外: 新しいゲームを追加したいが、参加するプレイヤーがまだ決定していない場合は、挿入できません。
- 削除例外:プレイヤー番号を削除したい場合、対局表を別途保存しておかないと、対局情報も同時に削除されます。
- 更新の例外: 特定のゲームの時間を調整する場合、データ テーブル内のすべてのゲームの時間を調整する必要があります。調整しないと、ゲームの時間が異なります。
上記の状況を回避するために、プレイヤー ゲーム テーブルを次の 3 つのテーブルに設計できます。
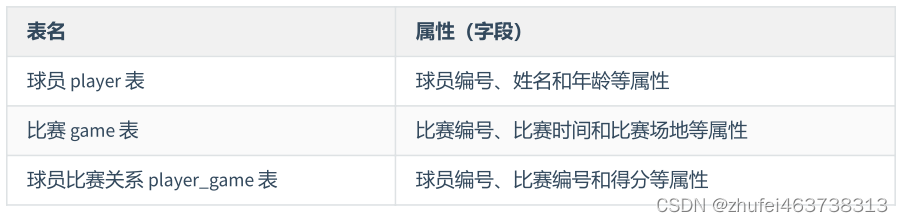
この場合、各データテーブルは第 2 正規形に準拠しているため、異常事態は回避されます。
1NF はフィールド属性がアトミックである必要があることを示しますが、2NF はテーブルが独立したオブジェクトであり、テーブルは 1 つの意味のみを表現することを示します。
例 3:
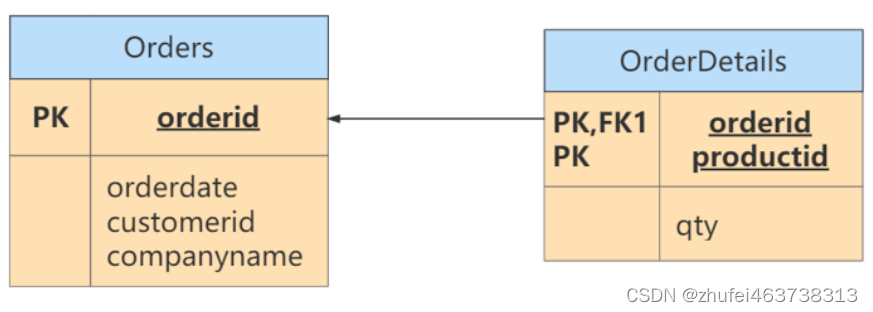
Orders という名前のリレーションシップは、注文と注文明細に関する情報を表すために定義されています。これは、

候補キー (または主キー) の一部にのみ依存する非主キー属性があるため、第 2 正規形に違反します。たとえば、注文の orderdate、customerid、companyname は orderid を通じてのみ検索でき、productid を使用する必要はありません。
修正:
Orders テーブルと OrderDetails テーブルは次のとおりであり、第 2 正規形に準拠しています。
1.6 第 3 正規形
例 1:
部門情報テーブル: 各部門には、部門番号 (dept_id)、部門名、部門紹介などが含まれます。
従業員情報テーブル: 各従業員には、従業員番号、名前、および部門番号があります。部門番号をリストした後は、部門名、部門プロフィールなど
の部門関連情報を従業員情報テーブルに追加することはできません。
部門情報テーブルが存在しない場合は、第 3 正規形 (3NF) に従って構築する必要があります。そうしないと、データの冗長性が高くなります。
例 2:
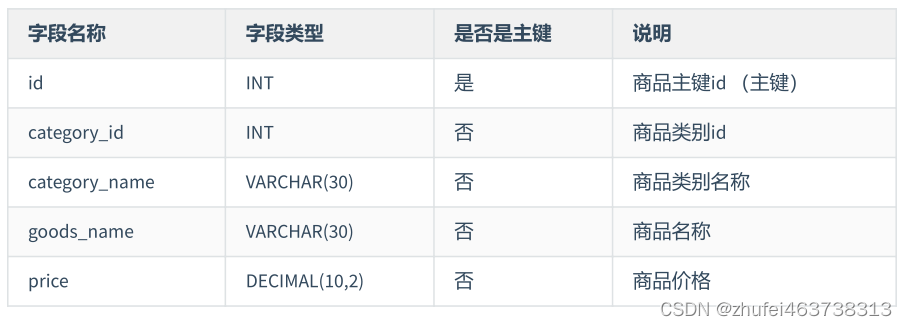
製品カテゴリ名は製品カテゴリ番号に依存しており、第 3 正規形に準拠していません。
変更:
表 1: 第 3 パラダイムに準拠した製品カテゴリ テーブルの設計
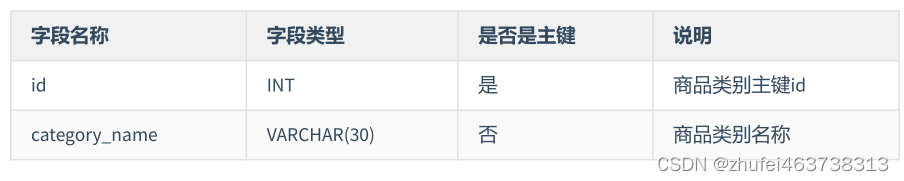
表 2: 第 3 パラダイムに準拠した製品テーブルの設計 製品
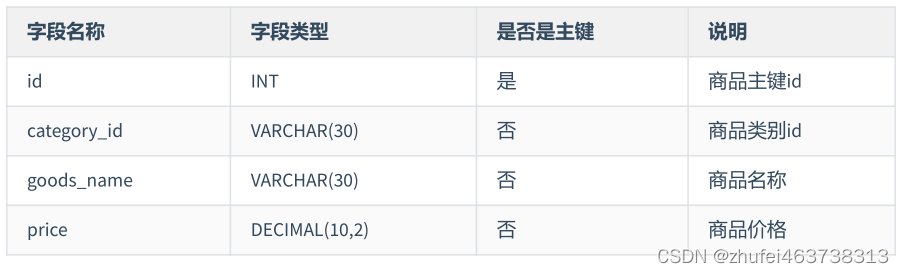
テーブル Goods は、製品カテゴリ ID フィールド ( category_id)。
例 3:
選手テーブル: 選手番号、名前、チーム名、チームのヘッドコーチ。ここで、以下の図に示すように、属性間の依存関係を描画します:
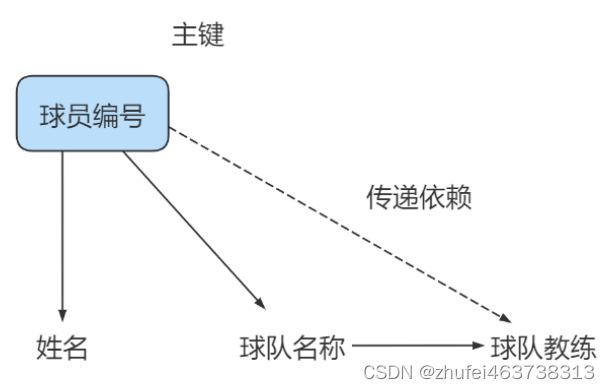
選手番号がチーム名を決定し、チーム名がチームのヘッドコーチを決定することがわかります。パスはプレーヤーの番号付けに依存しているため、3NF の要件を満たしていません。
3NF の要件を満たすには、データ テーブルを次のように分割する必要があります。

例 4:
例 3 を第 2 正規形に変更します。
この時点の Orders 関係には、orderid、orderdate、customerid、companyname という属性が含まれており、主キーは orderid として定義されています。
customerid と companyname はどちらも主キー orderid に依存します。たとえば、注文内の顧客を表す customerID を検索するには、orderid 主キーを使用する必要があり、同様に、注文内の顧客の会社名 (companyname) を検索するには、orderid 主キーを使用する必要があります。ただし、customerid と companyname は相互に依存しています。第 3 正規形を満たすには、次のように書き換えることができます。
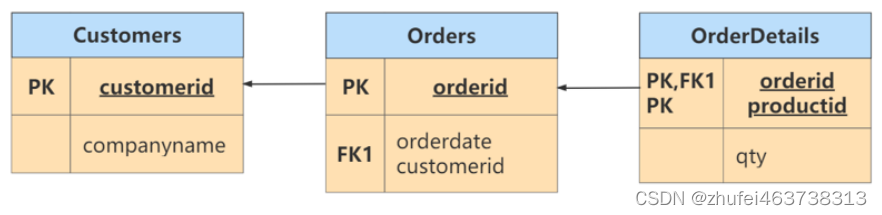
3NF 準拠後のデータ モデル 平たく言えば、2NF と 3NF は通常、「すべての非キー属性はキーに依存し、キー全体に依存し、キー以外には何も存在しない」という文で要約されます。
2 非正規化
2.1 概要
正規化とパフォーマンス
- 特定のビジネス目標を達成するには、データベースの正規化よりもデータベースのパフォーマンスが重要です。
- データの正規化中は、データベースのパフォーマンスを総合的に考慮する必要があります。
- フィールドを追加することで、特定のテーブルから情報を検索するのに必要な時間を大幅に短縮します。
- クエリを容易にするために、指定されたテーブルに計算列を挿入します。
2.2 応用例
例 1:
従業員情報はemployeesテーブルに格納され、部門情報はDepartmentsテーブルに格納されます。従業員テーブルの部門 ID フィールドを通じて部門テーブルとの関係を確立します。従業員の部門名を照会したい場合:
select employee_id,department_name
from employees e join departments d
on e.department_id = d.department_id;
この操作を頻繁に実行する必要がある場合、接続クエリにより多くの時間が無駄になります。
毎回接続操作を実行する必要がないように、employees テーブルに冗長フィールドラップトップ フィールドを追加できます。
例 2:
非正規化商品製品情報テーブルは次のように設計されています。
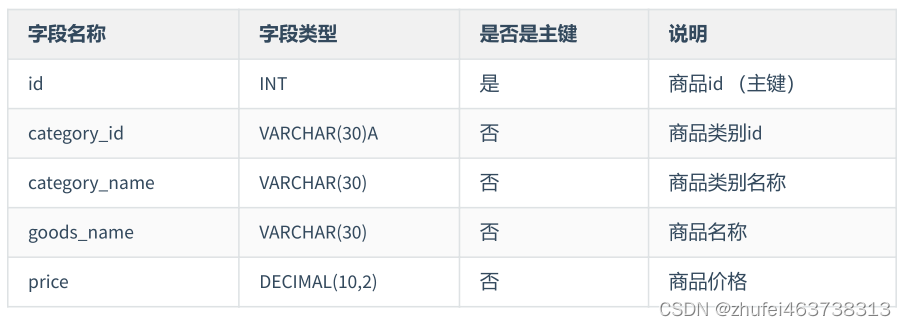
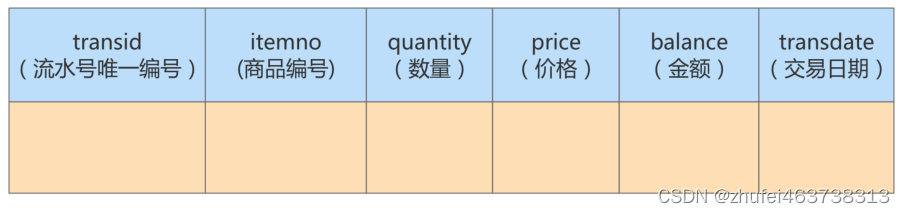
例 3:製品フロー テーブル (atguigu.trans) と製品情報テーブル
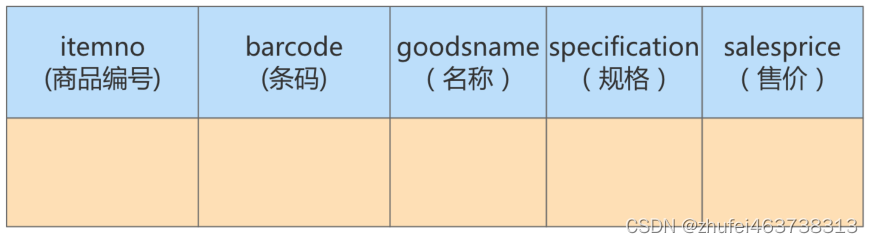
(atguigu.goodsinfo) の 2 つのテーブルがあります。製品フロー テーブルには 400 万件の販売レコードがあり、製品情報テーブルには 2,000 件の製品レコードがあります。
製品フロー テーブル:
製品情報テーブル:
新しい製品フロー テーブルは次のとおりです。

例 4:
コース コメント テーブル class_comment、対応するフィールド名と意味は次のとおりです。

Student テーブル Student、対応するフィールド名と意味は次のとおりです。
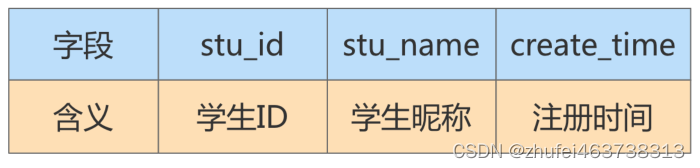
実際のアプリケーションでは、コース コメントを表示するとき、通常、学生 ID の代わりに学生のニックネームが表示されます。したがって、コースの最初の 1000 件のコメントをクエリする場合は、クエリ用に class_comment と Student の 2 つのテーブルを関連付ける必要があります。
実験データ: 200 万レベルのデータ テーブルをシミュレート
. SQL 最適化実験をより適切に実施するには、学生テーブルとコース コメント テーブルの数百万のデータをランダムにシミュレートする必要があります。ストアド プロシージャを通じてデータをシミュレートできます。
アンチパラダイム最適化実験の比較
コース ID 10001 の最初の 1000 件のコメントをクエリする場合は、次のように記述する必要があります。
SELECT p.comment_text, p.comment_time, stu.stu_name
FROM class_comment AS p LEFT JOIN student AS stu
ON p.stu_id = stu.stu_id
WHERE p.class_id = 10001
ORDER BY p.comment_id DESC
LIMIT 1000;
実行結果 (1000 データ行):
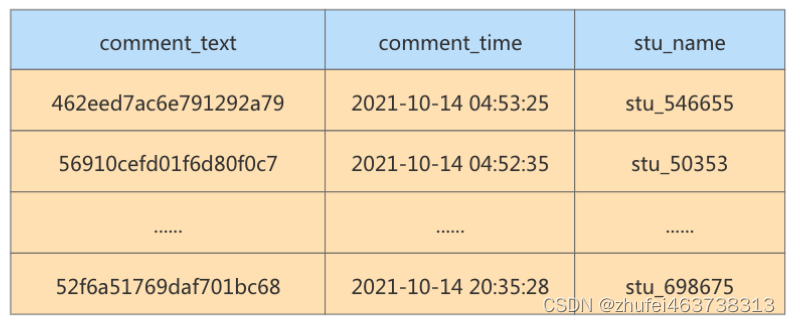
実行時間は 0.395 秒で、Web サイトの応答が非常に遅く、ユーザー エクスペリエンスが非常に悪くなります。
クエリの効率を向上させたい場合は、適切なデータ冗長性を許可できます。つまり、製品レビュー テーブルにユーザー ニックネーム フィールドを追加し、class_comment データ テーブルに stu_name フィールドを追加して、class_comment2 データ テーブルを取得します。
このようにして、単一のテーブル クエリだけでデータ セットの結果を取得できます。
SELECT comment_text, comment_time, stu_name
FROM class_comment2
WHERE class_id = 10001
ORDER BY class_id DESC LIMIT 1000;
実行結果 (データ 1000 個):
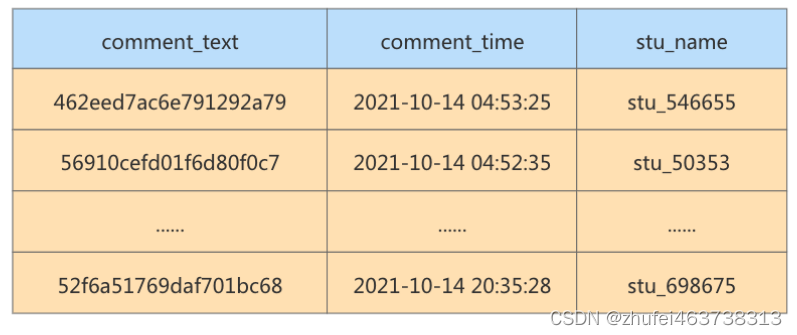
最適化後、クラスター化インデックスのスキャンは 1 回だけで済み、実行時間は 0.039 秒、クエリ時間は以前の 1/10 になりました。データ量が多い場合、クエリ効率が大幅に向上することがわかります。
2.3 アンチパラダイムの新たな問題
- 収納スペースが増えた
- 1 つのテーブルのフィールドが変更された場合、別のテーブルの冗長フィールドも同期的に変更する必要があります。そうしないと、データが不整合になります。
- ストアド プロシージャを使用してデータの更新や削除などの追加操作をサポートする場合、頻繁な更新により大量のシステム リソースが消費されます。
- データ量が少ない場合、アンチパラダイムはパフォーマンス上の利点を反映できず、データベース設計がより複雑になる可能性があります。
2.4 アンチパラダイムの適用シナリオ
冗長な情報が価値がある場合大幅度提高查询效率、または有効な場合は、アンチパラダイム最適化を採用します。
1. 冗長フィールドの追加に関する提案
2. 履歴スナップショットと履歴データの必要性
実際には、名前、電話番号、住所などの注文の荷受人情報などの余分な情報が必要になることがよくあります。订单收货信息何かが起こる历史快照たびに、それは保存される必要がありますが、ユーザーはいつでも自分の情報を変更できるため、現時点では、この冗長な情報を保存することが非常に必要です。
アンチパラダイム最適化は数据仓库、 の設計でもよく使用されます。これは、データ ウェアハウスには通常、存储历史数据リアルタイムの追加、削除、変更に対する強い要件はありませんが、履歴データの分析には強い要件があるためです。現時点では、データ分析をより便利にするためにデータの冗長性を許可することが適切です。
3 BCNF (バス正規形)
1.ケース
次の表でパラダイム状況を分析します。
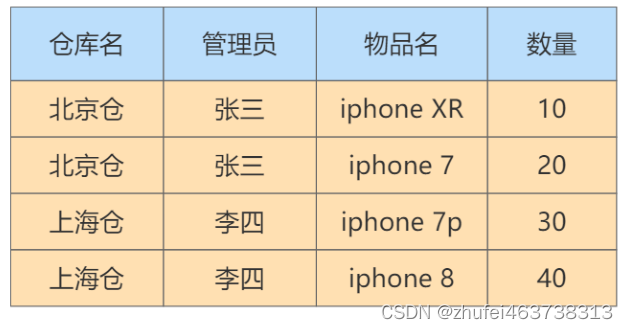
この表では、ウェアハウスには 1 人の管理者のみが存在し、管理者は 1 つのウェアハウスのみを管理します。まず、これらのプロパティ間の依存関係を整理しましょう。
倉庫名によって管理者が決まり、管理者が倉庫名を決めると同時に、(倉庫名、品目名)の属性セットによって数量属性を決めることができます。このようにして、データテーブルの候補キーを見つけることができます。
候选键: (管理者、品目名) と (倉庫名、品目名) で、(倉庫名、品目名) のように、候補キーの中から 1 つを主キーとして選択します。
主属性: 候補キーに含まれる属性、つまり倉庫名、管理者、品目名。
非主属性: 数量属性。
2. 3つのパラダイムに適合しているか
テーブルのパラダイムをどのように決定するか? パラダイムの低位から高位までの階層に基づいて判断する必要があります。
まず第一に、データ テーブルのすべての属性はアトミックであり、1NF の要件を満たしています。
次に、データ テーブルの非主属性「数量」は候補キーに完全に依存しており、(倉庫名、品目名) によって数量が決まり、(管理者、品目名) によって数量が決まります。したがって、データシートは 2NF の要件に準拠しています。
最後に、データ テーブル内の非プライマリ属性は、候補キーに推移的に依存しません。したがって、3NF の要件を満たします。
3. 問題点
データテーブルはすでに3NFの要件を満たしているので問題ないでしょうか?次の状況を見てみましょう。
- 倉庫が追加されましたが、アイテムはまだ保管されていません。データ テーブル エンティティの整合性の要件に従って、主キーに null 値を含めることはできないため、挿入例外が発生します。
- ウェアハウスの管理者が変更された場合、データ テーブル内の複数のレコードを変更する場合があります。
- 倉庫内の商品がすべて売り切れた場合、その時点で倉庫名と対応する管理者名も削除されます。
データ テーブルが 3NF の要件を満たしていても、データの挿入、更新、削除時に例外が発生する可能性があることがわかります。
4. 問題解決
まず、例外の原因を確認する必要があります。メイン属性のウェアハウス名が候補キー (管理者、項目名) に部分的に依存しているため、上記の例外が発生する可能性があります。したがって、BCNF が導入され、3NF に基づく候補キーに対する主属性の部分依存性または推移的依存性が排除されます。
- リレーション R で、U が主キーであり、属性 A が主キーの属性である場合、A->Y が存在し、Y が主属性である場合、そのリレーションは BCNF に属しません。
BCNF の要件に従って、倉庫管理関係のwarehouse_keeperテーブルを次のように分割する必要があります。
仓库表:(倉庫名、管理者)
库存表:(倉庫名、品目名、数量)
このように、候補キーに対する主属性の部分依存または推移依存はなく、上記のデータ テーブルの設計は BCNF に準拠しています。
もう一つの例:
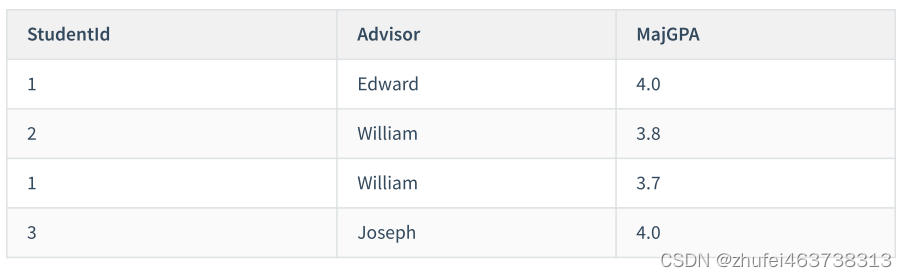
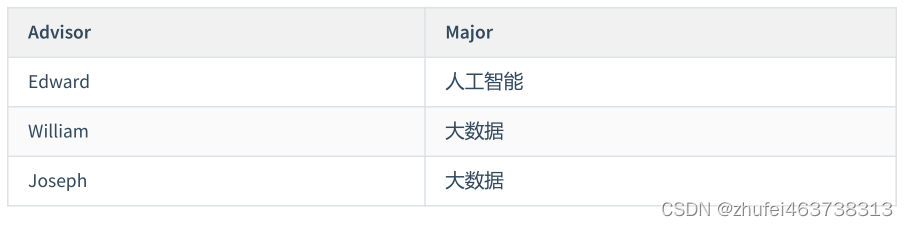
学生講師テーブルがあり、これには学生 ID、専攻、講師、専攻 GPA のフィールドが含まれています。学生 ID と専攻は共通の主キーです。
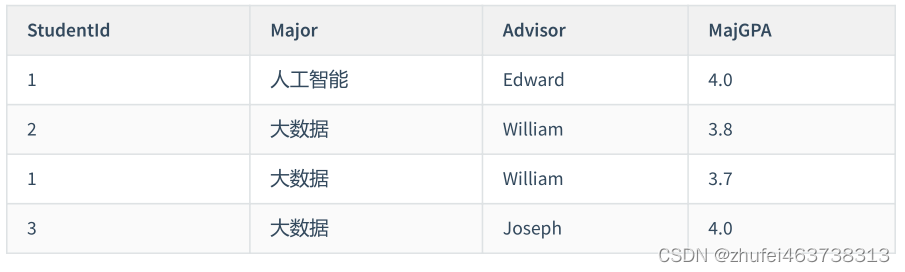
このテーブルの設計は 3 つのパラダイムを満たしていますが、ここには別の依存関係があります。「プロフェッショナル」は「講師」に依存しており、各講師はプロの講師としてのみ機能することを意味します。どの講師であるかがわかっている限り、自然にそれがどの専攻であるかがわかります。
したがって、このテーブルの主キー Major の一部は、非主キー属性 Advisor に依存するため、次の調整を行って、それを 2 つのテーブルに分割できます:
Student tutor テーブル:
tutor テーブル:
4 第 4 のパラダイム
**例 1:**従業員テーブル (従業員番号、従業員の子供の名前、従業員の選択コース)。
このテーブルでは、同じ従業員が複数の従業員の子の名前を持つ場合があります。同様に、同じ従業員が複数の従業員選択コースを受講することもできます。つまり、ここには多値の事実があり、これは 4 番目のパラダイムに準拠しません。
第 4 正規形に準拠する場合は、上記のテーブルを 2 つのテーブルに分割して、多値ファクトが 1 つだけになるようにするだけです。たとえば、従業員テーブル 1 (従業員
番号2 (従業員番号、従業員選択コース) の場合、どちらのテーブルにも多値ファクトが 1 つだけあるため、第 4
正規形に準拠します。
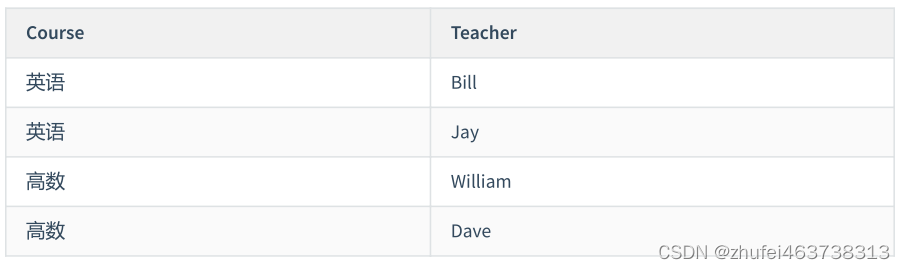
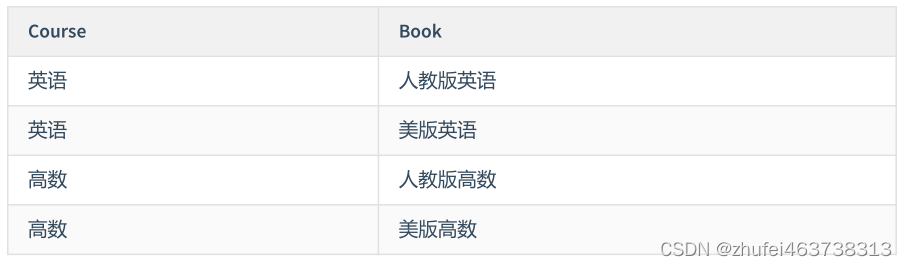
例 2:
たとえば、コース、教師、教材のモデルを構築します。各コースには対応する教師がおり、各コースにはそれに対応する
教材があると規定しており、コースで使用される教材と教師は関係ありません。私たちが確立した関係表は次のとおりです。
コース ID、教師 ID、教科書 ID、これら 3 つの列が共通の主キーとして機能します。
表現の便宜上、ID の代わりに名前を使用します。これにより、理解しやすくなります。

このテーブルには、主キーを除いて他のフィールドがないため、BC パラダイムを確実に満たしていますが、多值依赖それによって生じる例外もあります。
来学期に新しい英国版の高度な数学の教科書を使用したいが、どの教師がそれを教えるかが決まっていない場合、この表でコースの高度な数学と英語版の高度な数学の教科書の関係を維持することはできません。
解決策は、この複数値の依存関係テーブルを 2 つのテーブルに分解し、それぞれの関係を確立することです。これが私たちの分割テーブルです
:
5 第 5 正規形、ドメインキー正規形
第 4 正規形に加えて、より高度な第 5 正規形 (完全正規形とも呼ばれる) とドメイン キー正規形 (DKNF) もあります。
第4正規形(4NF)を満たすことに基づいて、候補キーに含まれない接続依存性が除去される。如果关系模式R中的每一个连接依赖均由R的候选键所隐含の場合、この関係モデルは第 5 正規形に準拠していると言われます。
関数の依存関係は複数値の依存関係の特殊なケースであり、複数値の依存関係は実際には接続の依存関係の特殊なケースです。ただし、接続の依存関係は、
関数の依存関係や複数値の依存関係には语义直接导出反映されません关系连接运算。接続依存関係のあるモデルでも
、データの冗長性や挿入、変更、削除の例外などの問題が発生する可能性があります。
5 番目のパラダイムは、ロスレス接続はめったに発生せず、検出が難しいため、无损连接问题このパラダイムが基本であるという事実を扱います。ドメイン キー パラダイムは、すべての依存関係と制約タイプを考慮するパラダイムを定義しようとしますが、実用的な価値は最小限であり、理論的研究にのみ存在します。没有实际意义终极范式
6ERモデル
6.1 ERモデルの概要
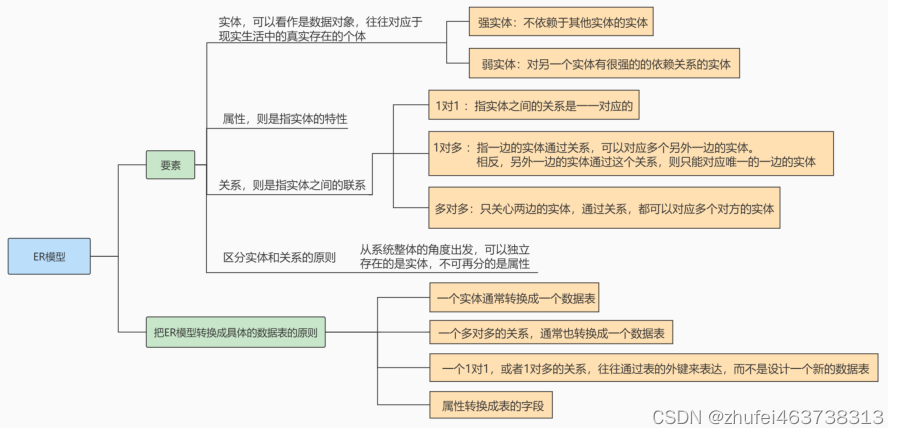
ER モデルには、エンティティ、属性、関係という 3 つの要素があります。
实体、多くの場合、現実の現実の個人に対応するデータ オブジェクトと見なすことができます。ER モデルでは、長方形で表されます。强实体エンティティは、との 2 つのカテゴリに分類されます弱实体。強いエンティティは他のエンティティに依存しないエンティティを指し、弱いエンティティは別のエンティティに強い依存性を持つエンティティを指します。
属性、エンティティの特性を指します。たとえば、スーパーマーケットの住所、連絡先、従業員数などです。ER モデルでは で表されます椭圆形。
关系、エンティティ間の接続を指します。たとえば、スーパーマーケットが顧客に商品を販売するとき、それはスーパーマーケットと顧客の間のつながりです。ER モデルでは で表されます菱形。
注: エンティティとプロパティは簡単に区別できません。これは原則です。システム全体の観点からそれを見るべきです可以独立存在 的是实体,不可再分的是属性。つまり、プロパティには他のプロパティを含めることはできません。
6.2 関係の種類
ER モデルの 3 つの要素のうち、関係は 1 対 1、1 対多、多対多の 3 つのタイプに分類できます。
一对一: エンティティ間の 1 対 1 の関係を指し、たとえば、個人と ID カード情報は 1 対 1 の関係になります。ID カード情報は 1 人につき 1 つだけ持つことができ、1 つの ID カード情報は 1 人にのみ属します。
一对多: これは、一方のエンティティがリレーションシップを通じて他方の複数のエンティティに対応できることを意味します。逆に、この関係を通じて、相手側の実体は唯一側の実体にのみ対応することができます。たとえば、新しいクラス テーブルを作成すると、各クラスには複数の生徒がいて、各生徒はクラスに対応し、クラスと生徒の間には 1 対多の関係が存在します。
多对多: これは、関係の両側のエンティティが、その関係を通じて互いに複数のエンティティに対応できることを意味します。たとえば、購買モジュールでは、サプライヤーとスーパーマーケットの関係は多対多の関係になり、1 つのサプライヤーが複数のスーパーマーケットに商品を供給したり、1 つのスーパーマーケットが
複数のサプライヤーから
商品を購入したりすることもできます。もう 1 つの例は、多くの科目を含むコース選択スケジュールであり、各科目には多くの学生が選択し、各学生は複数の科目を選択できます。これは
多対多の関係です。
6.3 モデリング分析
ER モデルは面倒に思えますが、プロジェクト全体をコントロールすることは非常に重要です。小規模なアプリケーションを開発しているだけであれば、おそらくいくつかのテーブルを設計するだけで十分ですが、ある程度の規模のアプリケーションを設計する場合は、プロジェクトの初期段階で完全な ER モデルを確立することが非常に重要です。アプリケーション プロジェクト開発の本質は、実際には です建模。
私たちが設計したケースは、电商业务電子商取引事業が大規模かつ複雑すぎるため、事業を簡素化したもので、例えば、SKU(StockKeeping Unit)とSPU(Standard Product Unit、標準化された製品単位)の意味で言えば、直接 SKU が使用され、SPU の概念については言及されていません。この e コマース ビジネス デザインには、以下に示すように、合計 8 つのエンティティがあります。
- 住所エンティティ
- ユーザーエンティティ
- ショッピングカートエンティティ
- コメントエンティティ
- 商品エンティティ
- 製品分類エンティティ
- 注文エンティティ
- 注文詳細エンティティ
その中でも、用户と は商品分类他のエンティティに依存する必要がないため、強力なエンティティです。その他は弱いエンティティです。独立して存在できますが、すべてユーザー エンティティに依存するため、すべて弱いエンティティです。これらの要素を理解すると、図に示すように、電子商取引ビジネスの ER モデルを作成できます。
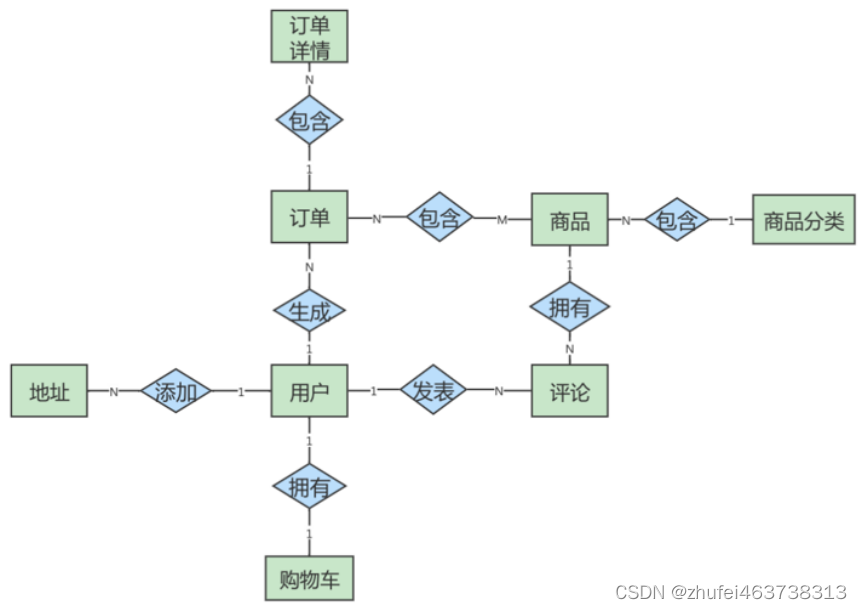
この図では、アドレスとユーザーの間に追加された関係は 1 対多の関係ですが、製品と製品の関係は詳細は 1 対 1 ですが、製品と注文の関係は多対多の関係になります。この ER モデルには、8 つのエンティティ間の 8 つの関係が含まれています。
(1) ユーザーは電子商取引プラットフォームに複数のアドレスを追加できます;
(2) ユーザーはショッピング カートを 1 つだけ持つことができます;
(3) ユーザーは複数の注文を作成できます;
(4) ユーザーは複数のコメントを投稿できます;
(5) 1 つのアイテム A製品には複数のコメントを含めることができます;
(6) 各製品カテゴリには複数の製品が含まれます;
(7) 注文には複数の製品を含めることができ、製品は複数の注文に含めることができます。
(8) 注文には異なる種類の商品が含まれる場合があるため、注文には複数の注文詳細が含まれます。
6.4 ERモデルの改良
理解この ER モデルを使用すると、電子商取引ビジネス全体を分析できます。先ほどの ER モデルは電子商取引ビジネスの枠組みを示していますが、そこに含まれるエンティティは、注文、住所、ユーザー、ショッピング カート、コメント、商品、商品カテゴリ、注文内容の 8 つのエンティティとそれらの間の関係のみであり、これらを表現することはできません。特定のテーブルとテーブル間の関係。取得する ER モデルをより完全なものにするために、属性を追加し、それらを楕円で表す必要があります。
したがって、この ER モデルの各部分をさらに設計する必要があります。つまり、電子商取引の特定のビジネス プロセスを洗練し、それらを統合して完全な ER モデルを形成する必要があります。これは、データベースの設計アイデアを明確にするのに役立ちます。
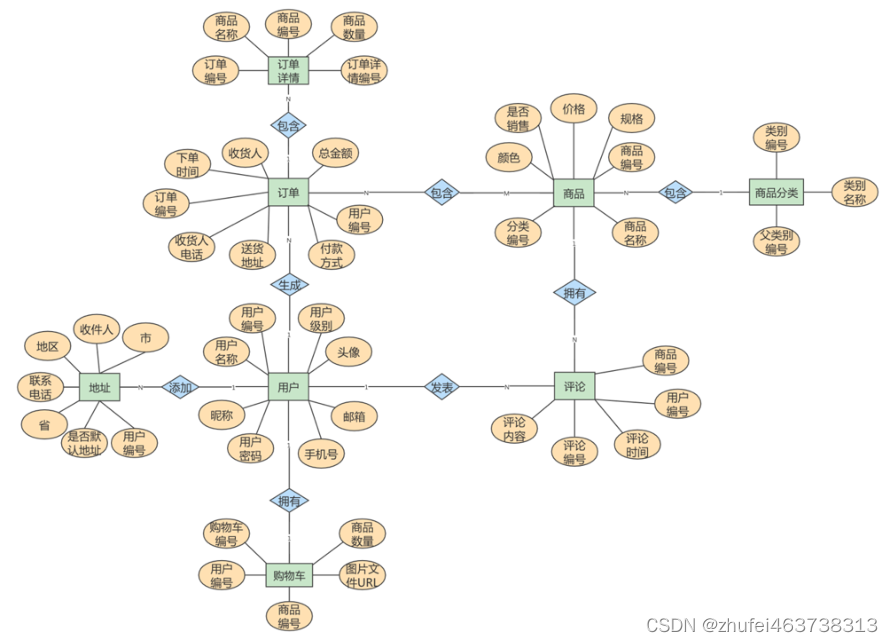
次に、以下に示すように、各エンティティの属性を分析しましょう。
(1)地址实体ユーザー番号、都道府県、市、地域、受信者、連絡先番号、およびデフォルトの住所かどうかが含まれます。
(2)用户实体ユーザー番号、ユーザー名、ニックネーム、ユーザーパスワード、携帯電話番号、メールアドレス、アバター、ユーザーレベルを含みます。
(3)购物车实体ショッピングカート番号、ユーザー番号、商品番号、商品数量、画像ファイルのURLが含まれます。
(4)订单实体注文番号、荷受人、受取人の電話番号、合計金額、ユーザー番号、支払方法、配送先住所、注文時刻を含みます。
(5)订单详情实体注文明細番号、注文番号、商品名、商品番号、商品数量を含みます。
(6)商品实体製品番号、価格、品名、カテゴリー番号、販売の有無、仕様、色など。
(7)评论实体レビューID、レビュー内容、レビュー時刻、ユーザー番号、商品番号を含む
(8)商品分类实体カテゴリ番号、カテゴリ名、親カテゴリ番号を含む
このように細分化した上で、ECビジネスを再設計することができます。図に示すとおりです
6.5 ERモデル図をデータテーブルに変換する
ER モデルを描画することで、ビジネス ロジックが明確になりました。次に、描画された ER モデルを特定のデータ テーブルに変換するという、非常に重要なステップに進みます。変換の原則については、次のとおりです。
A.实体通常は one に変換されます数据表;
(2) one 多对多的关系、通常は one にも変換されます数据表;
(3) one 1 对 1、または の1 对多関係は、外键新しいデータ テーブルを設計するのではなく、 table を通じて表現されることがよくあります;
(4) 属性table に変換されます字段。
実際、データベース ベースのアプリケーション プロジェクトは、最初に ER モデルを確立し、次にそれをデータ テーブルに変換することでデータベース設計作業を完了できます。ERモデルを作ることが目的ではなく、ビジネスロジックを整理して優れたデータベースを設計することが目的です。
モデリングのためのモデリングではなく、ER モデルの作成プロセスを使用してアイデアを整理し、ER モデルの作成が意味のあるものになるようにすることをお勧めします。
7 データテーブルの設計原則
上記の内容に基づいて、データ テーブル設計の一般原則を「3 つ減らして 1 つ増やす」と要約します。
- データテーブルの数は少ないほど良い
- データテーブル内のフィールドが少ないほど良い
- データ テーブル内の結合主キー フィールドの数は少ないほど良いです。
- 使用する主キーと外部キーの数が多いほど、より良い結果が得られます。
注: この原則は絶対的なものではなく、場合によっては、データ処理の効率と引き換えにデータの冗長性を犠牲にする必要があります。