Alibaba Cloud の ODPS シリーズ製品は、MaxCompute、DataWorks、Hologres を中核として、ユーザーの多様化するデータのコンピューティング ニーズを解決し、ストレージ、スケジューリング、メタデータ管理における統合アーキテクチャの統合を実現し、交通、金融、科学のサポートに取り組んでいます。シーンデータの効率的な処理は、中国で最も初期に自社開発され、最も広く使用されている統合ビッグデータ プラットフォームです。
この問題では次のことに焦点を当てます
ꔷ Hologres がコンピューティング グループ インスタンスを起動
ꔷ Hologres は JSON データをサポートします
ꔷ Hologres ベクトル計算 + 大規模モデル機能
ꔷ Hologres の新しいデータ同期機能
ꔷHologres データ階層型ストレージ
新機能 - Hologres がコンピューティング グループ インスタンスを起動
コンピューティング グループ インスタンスは、高可用性展開をより適切に提供するために、コンピューティング リソースをさまざまなコンピューティング グループに分解することをサポートします。
アプリケーションシナリオ:
- リソースの分離:書き込みと書き込みの間の相互作用、読み取りと書き込みの間の相互作用、大規模なクエリと小規模なクエリの間の相互作用、およびオンライン サービス間の相互作用、多次元分析、アドホックなど、さまざまなエンタープライズ シナリオ間の相互作用によって生じるクエリ ジッター一部のビッグ データ エンジンは、複数のコピーによる分離などの高コストのビジネス シナリオを実現するために、ストレージと計算の分離アーキテクチャを使用しません。
- 高可用性:サービス レベルの高可用性、ディザスタ リカバリ、およびマルチ アクティビティを備えていないソリューションの場合、企業はデュアル/マルチ リンクを使用して高可用性、ディザスタ リカバリ、およびマルチ アクティビティを実現します。これには人的資源や人材などの高コストのビジネス シナリオが伴います。コンピューティングリソース。
- 柔軟な拡張と縮小:ビジネスの柔軟性に対する企業の高い要求に応えます。ビジネス トラフィックの急激な増加には、トラフィックの処理に間に合うように拡張することができ、ビジネスの低ピーク時に容量を削減して、ビジネス資本の損失とコストを削減できます。 。
特徴:
- 自然な物理リソースの分離:各コンピューティング グループ間には自然な物理リソースの分離があり、企業での使用によりコンピューティング グループ間の相互影響を回避し、ビジネスのジッターを軽減できます。
- オンデマンドでの柔軟な拡張と縮小:コンピューティングとストレージは拡張性が高く、二重の弾力性を備えています。企業はオンタイムまたはオンデマンドでスケールアップ (スケールアウト)、オンデマンドでのホットな拡張と縮小 (スケールアップ) が可能です。
- コストの削減:物理レプリケーションの実装に基づいて、物理ファイルは完全に再利用され、企業はオンデマンドでリソースを柔軟に使用でき、コストを最小限に抑えることができます。
製品デモコンピューティンググループインスタンス
Hologres コンソールに移動し、SQL を通じて新しい計算グループを作成し、対応するテーブル グループ (データ) 権限を付与します。計算グループを変更し、初期ウェアハウスを新しく作成した読み取りウェアハウスに変更します。クエリを実行すると、負荷全体が読み取り倉庫に転送されました。同時に、必要に応じて計算グループを開始および停止することができ、停止または開始の操作は SQL を使用して実装することも、インターフェイス上で視覚的に操作することもできます。同時に、コンピューティング グループのリソースもオンデマンドで調整でき、ページ上または CPO を使用して視覚的に操作できます。コンピューティング グループが使用する必要がなくなったときに、リソースを占有することなく、適切なタイミングで解放できます。リソース。
新機能 - Hologres が JSON データをサポート
列指向の JSONB ストレージをサポートしてクエリ効率を向上させます
アプリケーションシナリオ:
- クエリ効率:半構造化スキーマの場合、スキーマを事前に固定することができず、行ストレージが主に使用され、大規模なデータを計算する場合、大量のデータをスキャンする必要があります。クエリの効率性は企業のビジネス ニーズを満たす必要があります。
- ストレージ効率:カラムストレージの圧縮機能を使用できないため、圧縮率が低くなり、ストレージスペースが大きくなります。ストレージ効率は企業のビジネス ニーズを満たす必要があります
- データ処理:半構造化データの処理における比較的複雑な問題の場合は、データのクリーニング、抽出、変換などの操作が必要です。企業のより包括的な機能サポートのビジネス ニーズを満たす必要があります。
特徴:
JSON データ処理メソッド:一般的な半構造化データ型として、JSON には 2 つのデータ処理メソッドがあります。
- インポートとは、データ構造を解析し、強力なスキーマにデータを保存することを意味します。この方法の利点は、データがデータベースに保存される時点ですでに強力なスキーマ データであるため、クエリ パフォーマンスとストレージ パフォーマンスが優れていることです。欠点は、解析プロセス中にデータを強力なスキームに変換する必要があり、JSON データの柔軟性が失われることです。JSONkeyを追加または削減した場合は、解析プログラムを変更する必要があります。
- もう 1 つの方法は、このデータ層をデータベースに直接書き込み、クエリ中に JSON 関数を使用して解析することです。この方式のメリットは、JSON データの柔軟性を最大限に保持できることですが、デメリットは、クエリのパフォーマンスが悪く、その都度適切な処理関数やメソッドを選択する必要があり、開発が煩雑になることです。
JSON データ処理方法の場合、Hologres は JSON データ ストレージ機能を最適化し、その欠点に応じて JSON データを保存できます。JSON データ システムは、書き込まれたキーと値の値に基づいて、保存できるデータ型を推測します。
- 柔軟で使いやすい:オプション 1 とは異なり、データは事前に強力にスキーマ化され、JSON データの柔軟性を最大限に保持します。
- 高い圧縮率:列型ストレージを使用すると、圧縮率が効果的に向上し、ストレージ領域を節約できます。
- 強力なクエリ パフォーマンス:列ストレージを使用して、スキャン データを削減し、IO 効率を向上させ、クエリ効率を向上させます。
製品デモ列 JSON 関数
JSON 形式で保存されたキー値データを含む、JSON 形式で保存された公開サンプル データに基づいて、各行にはさまざまなビジネス上の意味を表すキーと値が含まれます。——このセクションCを使用して、年および月ごとにクローズされた問題の数をクエリし、システムが実行を開始します ——従来の実行方法とクエリ方法は、1行ずつスキャンしてキーと値を1つずつ取り出します合計時間は 55 秒かかります。——この時点で、データ列のストレージが有効になり、完了後にクエリを実行できるようになり、合計で 1.47 秒かかり、クエリ効率が大幅に向上しました。
新機能 - Hologres ベクトル計算 + 大規模モデル機能
高性能ベクトル コンピューティングと大規模モデルを組み合わせて独自の知識ベースを構築
アプリケーションシナリオ:
エンタープライズレベルの大規模モデルのナレッジベースを展開する際の問題:
企業がモデルを展開する場合、コンピューティングおよびストレージ リソースの高コスト、リソースの弾力性、大規模なモデルの展開などの問題が発生します。
業務でコーパスを処理する場合、元のコーパス処理プロセスが複雑になる コーパスデータが大量になると、ベクトルデータベースの記述能力やリアルタイム性の要求が高くなる 知識ベースの質疑応答を行う場合QPSが高く、ベクトルデータベースのクエリ能力が高く、要件やその他のニーズがある。
企業が大規模なモデルのナレッジ ベースを構築すると、長いプロセス、多くの製品が関与すること、全体的なアーキテクチャ接続コストの高さ、アーキテクチャの接続の難しさなどの問題が発生します。
特徴:
Hologres + Proxima の全体的な利点:
Proxima は DAMO Academy が自社開発したベクトルエンジンであり、Faiss などのオープンソース製品よりも安定性とパフォーマンスが優れています。Hologres は、DAMO アカデミーが自社開発したベクトル エンジンである Proxima と緊密に統合されており、高 PQS と低遅延のベクトル コンピューティング サービスを提供します。その具体的な利点は次のとおりです。
- 高性能:統合されたデータ ウェアハウスを通じて、低遅延、高スループットのオンライン ベクトル クエリ サービスを提供します。ベクトル データのリアルタイムの書き込みと更新をサポートし、書き込み後すぐにクエリを実行できます。
- 高いユーザビリティ:ベクトル データをクエリするための統合 SQL クエリ インターフェイス、PostgreSQL エコシステムと互換性があり、複雑なフィルタリング条件によるベクトル検索をサポート
- エンタープライズ レベルの機能:ベクトル コンピューティングおよびストレージ リソースの柔軟な水平拡張。マスター/スレーブ インスタンス アーキテクチャ、コンピューティング グループ インスタンス アーキテクチャをサポートし、コンピューティング リソースの物理的分離をサポートし、エンタープライズ レベルの高可用性機能を実現します。
Hologres+PAI は、大規模モデルのナレッジ ベース アーキテクチャと利点を導入します。
アーキテクチャは主に 3 つのレベルに分かれています
- 前データ前処理層:元のコーパス データに対して、読み込みと分析後にテキスト チャンクが形成され、その後 Embedding によってベクトル化されてコーパス ベクトル データが生成され、最終的にリアルタイム データ Hologres に書き込まれます。
- テキスト生成層:ユーザーの元の質問の場合、質問は最初に質問ベクトルに埋め込まれ、次に上位 K ベクトルが Hologres で取得されます。
- 最終生成層:トップ K コーパスが大規模モデルの入力として使用され、チャット履歴やプロンプトの最終推論などの大規模モデルの他の入力と組み合わせて、最終的な回答が得られます。ここの大規模モデルは、機械学習プラットフォームを通じて均一にデプロイできます。
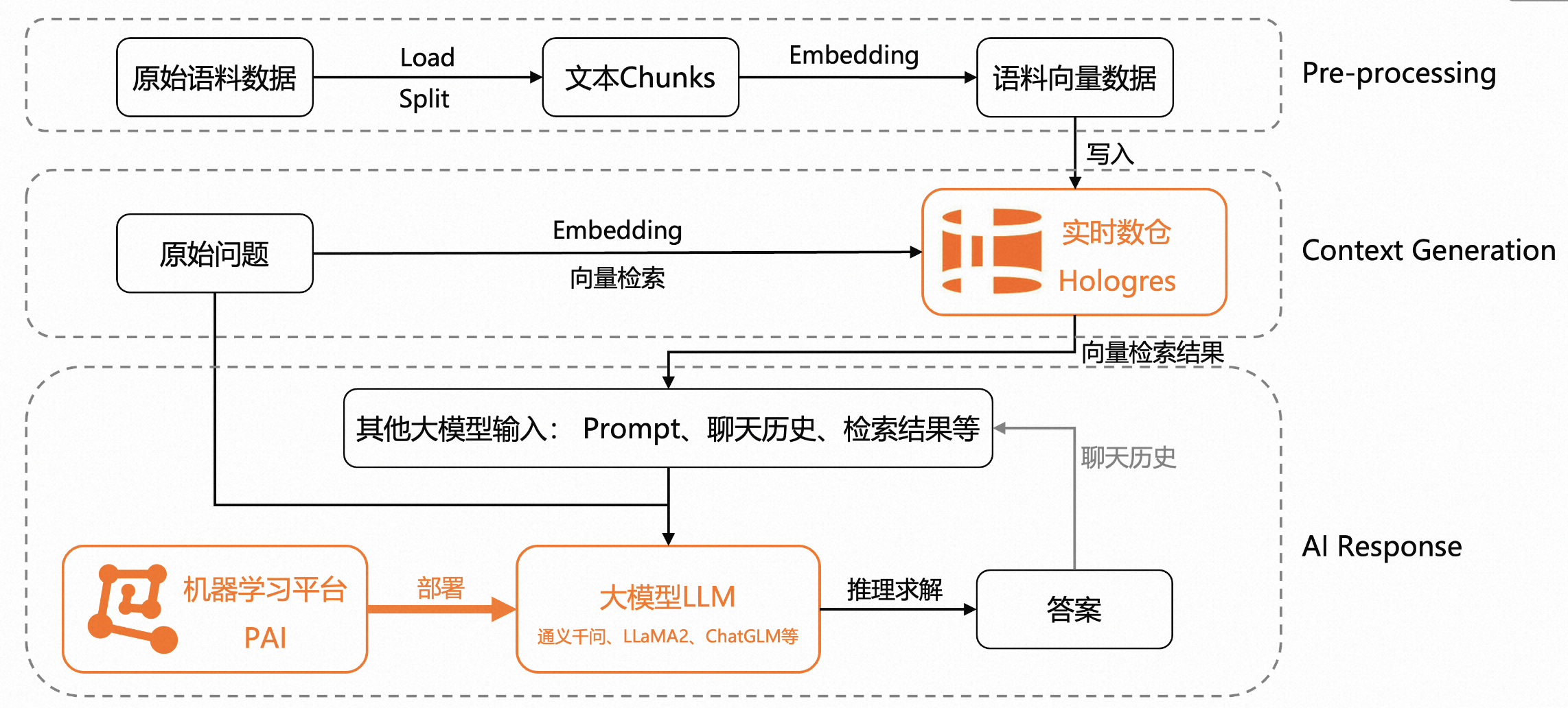
アーキテクチャ上の利点:
- 簡素化されたモデル展開:モデル オンライン サービス PAI-EAS を介した LLM 大規模モデル推論サービスのワンクリック展開
- コーパスの処理とクエリを簡素化:ワンクリックでコーパス データのロード、スライス、ベクトル化、Hologres へのインポートを行うことができ、同時に Hologres の低遅延かつ高スループットのベクトル取得機能に基づいて、より高速で優れたベクトルをユーザーに提供します。検索サービス。
- ワンストップのナレッジベース構築:手動接続が不要で、大規模モデルのデプロイ、WebUI デプロイ、コーパスデータ処理、大規模モデルの微調整を 1 つのプラットフォーム上で完了できます。
製品デモのデモンストレーション - Hologres+PAI は大規模なモデルのナレッジ ベースを展開します
Hologres インスタンスを開き、インスタンスの詳細ページのネットワーク情報にインスタンスのドメインを記録します。ログイン インスタンス ボタンをクリックして HoloWeb に入ります - 元のデータ管理ページでデータベースを作成し、データベース アカウント名を記録します - セキュリティ センターをクリックしてユーザー管理ページに入り、カスタム ユーザーを作成して認証し、作成したユーザー名を記録します大規模なモデルのデプロイメントの場合、PAI-EAS を使用して大規模な LLM モデルをデプロイし、大規模なモデルの呼び出し情報を記録できます。デモでは、PAI-EAS を使用して langchain の WebUI サービスをデプロイします。 Web アプリケーションを使用して Web UI ページに入ります。設定ページで埋め込みモデルを設定します。デプロイしたばかりの LLM ラージ モデルと Hologres ベクター ストレージを設定できます。上記のファイルは、Json ファイルを使用してワンクリックで構成できます。[解析] をクリックし、関連する構成情報をワンクリックで入力します。同時に、「Hologres に接続」をクリックして接続をテストします。アップロード ページに入り、コーパス データを処理します。コーパス データをアップロードし、テキスト スライスに関連するパラメーターを設定し、[アップロード] をクリックしてデータを Hologres ベクター テーブルにインポートします。HoloWeb エディターに戻って更新すると、コーパス データがベクターとして Hologres にインポートされます。先ほどの Web UI ページに戻り、チャット ページに入り、最初にネイティブの ChaGLM 大きなモデルを試して「Hologres とは何ですか」と尋ねますが、結果は理想的ではありません。次に Hologres を使用して大きなモデルを微調整し、同じ質問、結果は正しい - langchain チャットボット ページに戻り、情報を呼び出して上記のソリューションの API 呼び出しを完了します。
新機能 - Hologres データ同期の新機能
ClickHouse、kafka、Postgres などのデータ ソースを Hologres に同期するためのサポートを追加しました
アプリケーションシナリオ:
- 同期パフォーマンス:エンタープライズ データのソースは多数あるため、データベース全体の同期、完全な増分同期、サブデータベースとサブテーブルのマージ、リアルタイム同期など、さまざまなデータ要件が生じます。
- 企業はデータ プラットフォームを構築します。各データ ソースは特定の調整を行う必要があるため、高パフォーマンスの書き込みを実現するには、開発学生は特定の同期調整機能を備えている必要があります。
- 同期コスト:データソースが多く、対応するクライアント開発により開発者の初期費用が高額になる、同期パフォーマンスがビジネスニーズを満たせない、リソースが短期間で継続的に追加されコストが増加する、メタデータ管理データ同期中は困難です
- ビジネスの運用と保守:自社構築のデータ プラットフォーム、開発のライフ サイクル全体、デバッグ、展開、運用と保守などはすべて開発学生によって管理されます。プロセス全体が非常に煩雑であり、リンク全体でデータの不整合がないかを 1 つずつチェックする必要があるため、コストがかかります。ある時点でデータに問題がある場合は、データのバックウォッシュが必要になります。バックウォッシュのソースは次のとおりです。異なるため、運用とメンテナンスのプロセスが非常に困難になります。
特徴:
Hologres データ同期機能の概要
Hologres は非常にオープンなエコシステムを備えており、Flink、DataWorks データ統合、Holo クライアント、JDBC、およびデータを Hologres に同期するその他の方法をサポートし、さまざまなビジネスのデータ同期とデータ移行のニーズを満たし、よりリアルタイムで効率的なデータ分析とデータを実現します。サービス能力
- Flink は完全な互換性を備えており、リアルタイムのデータ書き込み、ディメンション テーブルの関連付け、読み取りなどを実現できます。
- DataWorksデータ連携への高い適応性: DataWorksデータ連携への適応性が高く、例えばDataWorksがサポートする各種データソースは基本的にHologresに同期することが可能です。
- Holo Client と Holo Shipper はすぐに使用できます。Holo Client を通じて、高性能のデータ チェックと高性能のポイントツーライト更新を実現できます。同時に、Holo Shipper はデータ インスタンスのデータベース全体の移行を実現できます。
- 標準 JDBC/ODBC インターフェイス:すぐに使用できる標準 JDBC/ODBC インターフェイスを提供します。
継続的な進化、Hologres データ同期の新機能
さまざまなビジネス ニーズを満たすために、Hologres はデータ同期機能を継続的に更新しており、その新機能には次のような特徴があります。
- ClickHouse のデータベース全体のオフライン移行: DataWorks データ統合に依存します。オフライン移行全体は 2 つの部分に分かれています: 1 つはメタデータの自動識別とマッピングで、もう 1 つはデータベース全体のデータを必要とせずに 1 回限りの同期です。従来の作業と同様に1テーブルに1つのテーブルを記述することで、開発・運用時のさまざまな不便を大幅に軽減し、ClickHouseデータのHologresへの迅速な移行を実現しました。
- Kafak リアルタイム サブスクリプション: Kafak リアルタイム サブスクリプションは 2 つの方法で実現できます。1 つは、Flink が Kafka をサブスクライブし、それをリアルタイムで Hologres に書き込み、データ ウェアハウス層でリアルタイム データ ウェアハウスのストリーミング ETL を実装することです。 2 番目に、DataWorks データ統合を通じてリアルタイムで Kafka を使用し、メッセージの変更は自動的に同期され、その後 Hologres に自動的に直接書き込まれます。Kafak データにはすぐにアクセスできます。
- PostgreSQL リアルタイム同期: PostgreSQL データは、DataWorks データ統合を通じてリアルタイムで Hologres に同期されます。単一テーブルのリアルタイム同期をサポートするだけでなく、DDL 機能構成、データベース全体のリアルタイム同期、自動マッピングもサポートします。データベースとテーブル構造の完全な合計 リアルタイムの増分データ同期により、開発同期の問題が大幅に軽減されます。
製品デモ - ClickHouse 全体のライブラリ同期
DataWorks データ統合インターフェイスで、ClickHouse および Hologres データ ソースを構成し、データ ソースの接続をテストします。テストに合格した場合は、次のステップに進むことができます。ClickHouse で同期する必要があるテーブルを選択し、シングルエンドタスクの速度などの高度な構成、同時実行、実行およびその他の構成、テーブルを確認して一度に Hologres に同期します - ターゲットテーブルのマッピング、バッチ更新ボタンをクリックしてテーブル構造のマッピングを実現します -同期タスクを開始し、約 2 分間待ちます - データの同期が完了すると、ページが更新されます。書き込まれたデータの数に基づいて上流のデータを検証し、データが合格したかどうかを確認できます - Hologres がデータ検証を実行しますテーブルに対して簡単なクエリを作成すると、クエリが完了します。
新機能 - Hologres データ階層型ストレージ
アプリケーションシナリオ:
- 電子商取引の注文:ここ数カ月間、注文には頻繁にアクセスがあり、RT の感度は高く、履歴データのアクセス頻度は低く、レイテンシは敏感ではありません。
- 行動分析:最近のトラフィック データの高頻度クエリには高い適時性が必要ですが、履歴データのクエリは頻度は高くありませんが、いつでも確認できることが必要です。
- ログ分析:最近のデータは頻繁にクエリされますが、その後の監査とバックトラック作業を確実にするために、履歴データは長期間保存する必要があります。
特徴:
- 標準ストレージ:標準ストレージは、Hologres のデフォルト ストレージであるフル SSD ホット ストレージであり、主にテーブル全体のデータが頻繁にアクセスされ、アクセス パフォーマンスに対する高い要件があるシナリオに適しています。
- 低頻度アクセス ストレージ:アクセス頻度は時間の経過とともに減少し、徐々にコールド データになります。たとえば、一部のログ データは今年以降アクセスできなくなるため、コストを削減するためにデータを標準ストレージから低頻度ストレージに移行する必要があります。ルールに基づいてホット データとコールド データを自動的に変換する機能があれば、メンテナンスコストは、データ量が多く、アクセス頻度が低く、ストレージコストを削減する必要があるシナリオに適しています。
- パーティションの動的ホットおよびコールド階層化:動的パーティション機能を通じてホットおよびコールドのパーティション フロー ルールを設定し、パーティションの動的なホットおよびコールド階層化を実現します。また、ホットおよびコールド階層化のコスト (北京市の年間サブスクリプションと月次サブスクリプションを例として挙げます)。ストレージは月額 1 GB あたり 1 元、低頻度保証ストレージは月額 1 GB あたり 0.144 元で、コストの約 7 倍の差があります。パフォーマンスの点では、標準的な TPC から ETB データを使用して測定されたテスト セットの結果に基づくと、約 3 ~ 4 倍のギャップがあります。
製品デモ - コールド ストレージ テーブル ステートメントを作成し、パーティション テーブルをセットアップする
たとえば、デモのテーブル作成ステートメントでは、テーブルの作成時にサイエンス テーブル プロパティを設定すると、[実行] をクリックしてコールド ストレージ テーブルを作成できることが示されます。HG テーブル ストレージ ステータス システム テーブルをクエリすると、ストレージが次の表の戦略は期待に応えます。——テーブルの進捗状況はコールドで、これはストレージテーブルです。システムにすでに存在するこの標準ストレージのホット ストレージ テーブルについては、コマンドに従って個別に実行し、テーブルを指定して [実行] をクリックすると、コールド ストレージの設定が成功します。すべてのデータがテーブルの既存の状態にあります。コールド ストレージ低周波記憶媒体に完全に移動されました。——パーティション テーブルは 2 つの部分に分かれています。最初の部分では、通常のパーティション テーブルのコールド ストレージ テーブルを作成します。次に、このテーブルのストレージ モードを設定します。パーティション テーブルの作成ステートメント パーティション テーブルのパーティション サブテーブルはデフォルトになります ストレージ戦略はデータベース テーブルとして記録されるため、個別に設定する必要はありません。——一方、あるパーティションの属性を変更したい場合、テーブルプロパティにパーティションサブテーブルのテーブル名を指定し、ストレージを設定するとします。特定のパーティション サブテーブルを変更するポリシーが、必要なホット属性とコールド属性に変更されます。動的パーティションテーブルの場合は、他のプロパティを設定する必要があります。
Hologres5000CU を受け取った場合の無料トライアル: https://free.aliyun.com/?pipCode=hologram
DataWorks の無料トライアルを入手: https://free.aliyun.com/?pipCode=dide
MaxCompute5000CU受信時の無料使用:https://free.aliyun.com/?pipCode =odps
200元の罰金と100万元以上を没収 You Yuxi: 高品質の中国語文書の重要性 MuskのJDK 21用ハードコア移行サーバー Solon、仮想スレッドは信じられないほど素晴らしい!!! TCP 輻輳制御によりインターネットが節約される OpenHarmony 用の Flutter が登場 Linux カーネルの LTS 期間が 6 年から 2 年に復元される Go 1.22 で for ループ変数エラーが修正される Google は 25 周年を祝う Svelte は「新しい車輪」 - ルーンを構築