
Linux を学習するためにクラウド サーバーやその他のクラウド製品が必要な学生は、 / --> Tencent Cloud <-- / --> Alibaba Cloud <-- / --> Huawei Cloud <-- / 公式 Web サイトに移動できます。軽量のクラウド サーバーは次のとおりです。年間 112 元の低コストで、新規ユーザーは最初の注文で超低割引を受けることができます。
目次
3. MySQL、OS、およびディスクの対話方法 (InnoDB ストレージ エンジン)
1. MySQL は、IO のためにディスクを操作するときに、使用した分だけロードする方法ではなく、ページ スキームを使用するのはなぜですか?
2.6 B+ ツリーが他のデータ構造よりもインデックス作成に優れているのはなぜですか?
2.7 クラスター化インデックスと非クラスター化インデックス
4. どのフィールドにインデックスを付ける必要がありますか?
1. インデックスの初期理解とテストデータの構築
インデックス: データベースの検索パフォーマンスを向上させます。クエリ速度の向上には、挿入、更新、削除の速度が犠牲になり、これらの書き込み操作により大量の IO が増加します。したがって、その価値は、大量のデータの取得速度を向上させることにあります。
一般的なインデックスは次のように分類されます。
主キーインデックス
一意のインデックス
通常のインデックス(インデックス)
全文インデックス (フルテキスト) -- neutron テキストのインデックス作成の問題を解決します。
8,000,000 レコードのデータを構築します。
mysql> source /home/jly/index_data.sql;
Query OK, 0 rows affected (32 min 14.69 sec)
--看一下前5条数据
mysql> select* from EMP limit 5;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 100002 | YPdZKD | SALESMAN | 0001 | 2023-06-24 00:00:00 | 2000.00 | 400.00 | 377 |
| 100003 | YJmqTw | SALESMAN | 0001 | 2023-06-24 00:00:00 | 2000.00 | 400.00 | 288 |
| 100004 | yIUxHR | SALESMAN | 0001 | 2023-06-24 00:00:00 | 2000.00 | 400.00 | 127 |
| 100005 | JIrHnr | SALESMAN | 0001 | 2023-06-24 00:00:00 | 2000.00 | 400.00 | 455 |
| 100006 | xFJFYc | SALESMAN | 0001 | 2023-06-24 00:00:00 | 2000.00 | 400.00 | 185 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
5 rows in set (0.03 sec)従業員番号 998877 の従業員情報を見つけるには 25 秒かかります。
mysql> select * from EMP where empno=998877;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 998877 | HJxoaj | SALESMAN | 0001 | 2023-06-24 00:00:00 | 2000.00 | 400.00 | 463 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
1 row in set (25.21 sec)実際のプロジェクトでは、パブリック ネットワーク上に配置され、1,000 人が同時にクエリを実行すると、クラッシュする可能性があります。したがって、テーブルにインデックスを作成します。
--创建索引用时1分8秒
mysql> alter table EMP add index(empno);
Query OK, 0 rows affected (1 min 7.59 sec)従業員番号 998877 の従業員情報を再度検索すると、0.04 秒かかります。
mysql> select * from EMP where empno=998877;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 998877 | HJxoaj | SALESMAN | 0001 | 2023-06-24 00:00:00 | 2000.00 | 400.00 | 463 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
1 row in set (0.04 sec)2. ディスク
MySQL はユーザーにストレージ サービスを提供します。保存されるのはデータであり、ディスクの周辺デバイスに保存されます。ディスクはコンピュータ内の機械装置であり、コンピュータの他の電子部品に比べてディスクの効率が比較的低く、IO 自体の特性も考慮すると、効率をいかに向上させるかが MySQL の重要なテーマであることがわかります。
ディスクのブログについては、ここをクリックしてください: [Linux] バッファ/ディスク i ノード/動的および静的ライブラリの作成
3. MySQL、OS、およびディスクの対話方法 (InnoDB ストレージ エンジン)
アプリケーション ソフトウェアとして、MySQL は特別なファイル システムとして想像できます。より高い IO シナリオがあるため、基本的な IO 効率を向上させるために、IO の MySQL の基本単位は 16 KB です (InnoDB ストレージ エンジンを使用して後で説明します)。
mysql> show global status like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.06 sec)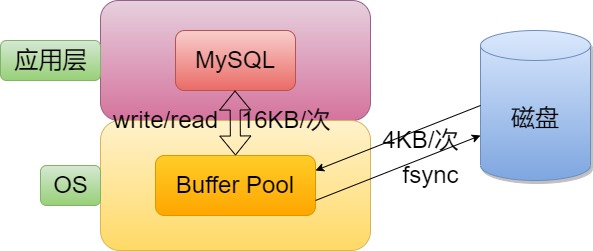
1. MySQL サーバーがメモリ内で実行されている場合、さまざまなキャッシュを実行するためにサーバー内のバッファ プールと呼ばれる大きなメモリ空間が適用されます。実際、これはディスク データとの IO 対話のための大きなメモリ空間です。バッファ プールは、一度に 1M データをディスクにフラッシュし、一度に 100M データをディスクにフラッシュします。効率は明らかに異なります。MySQL の最下層には、IO 効率を確保するための独自の「バッファ」リフレッシュ戦略もあります。
2. MySQL のデータ ファイルはページ単位でディスクに保存されます。
3. MySQL の CURD 操作では、対応する挿入位置を見つけるため、または変更またはクエリされる対応するデータを見つけるための計算が必要です。
4. 計算が関与する限り、CPU が参加する必要がありますが、CPU の参加を容易にするために、まずデータをメモリに移動する必要があります。したがって、特定の期間内にデータがディスクとメモリに存在する必要があります。メモリ データに対する後続の操作の後、データは特定のリフレッシュ戦略を使用してディスクにリフレッシュされます。このとき、ディスクとメモリ間のデータ対話、つまり IO が関係します。このときのIOの基本単位はPageとなります。
5. 効率を高めるには、システム IO とディスク IO の数をできるだけ減らす必要があります。
4. MySQL のインデックスとページについて理解する
ディスク ハードウェア デバイスの基本単位は 512 バイト (これより大きいものもあります)、MySQL InnoDB エンジンとディスク間のデータ対話の基本単位は 16 KB です。これらの基本データ単位はそれぞれ、MySQL ではページと呼ばれます (注意してください)。システムページの区別に関係します)
MySQL には多数のページが存在する必要があります。最初に記述してから整理するため、ユーザー データに加えて、MySQL が多数のページを整理して管理するためのデータ構造の一部も 1 つのページ内に存在します。 。
1. MySQL は、IO のためにディスクを操作するときに、使用した分だけロードする方法ではなく、ページ スキームを使用するのはなぜですか?
局所性の原則に基づいたプリロードにより、IO の数が削減され、効率が向上します。
低い IO 効率の主な矛盾は、単一の IO データ ボリュームのサイズではなく、IO の数です。
2. MySQL がページを管理する方法
テスト テーブルを作成し、主キー制約を忘れずに追加します。
create table if not exists user (
id int primary key, --一定要添加主键,只有这样才会默认生成主键索引
age int not null,
name varchar(16) not null
);
mysql> desc user;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| age | int(11) | NO | | NULL | |
| name | varchar(16) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.04 sec)複数のデータセットを順不同で挿入しますが、テーブルは主キーに従って順番に保存されています。
mysql> insert into user (id, age, name) values(3, 18, '杨过');
Query OK, 1 row affected (0.01 sec)
mysql> insert into user (id, age, name) values(4, 16, '小龙女');
Query OK, 1 row affected (0.00 sec)
mysql> insert into user (id, age, name) values(2, 26, '黄蓉');
Query OK, 1 row affected (0.01 sec)
mysql> insert into user (id, age, name) values(5, 36, '郭靖');
Query OK, 1 row affected (0.00 sec)
mysql> insert into user (id, age, name) values(1, 56, '欧阳锋');
Query OK, 1 row affected (0.00 sec)
--乱序插入,但是数据是有序的
mysql> select * from user;
+----+-----+-----------+
| id | age | name |
+----+-----+-----------+
| 1 | 56 | 欧阳锋 |
| 2 | 26 | 黄蓉 |
| 3 | 18 | 杨过 |
| 4 | 16 | 小龙女 |
| 5 | 36 | 郭靖 |
+----+-----+-----------+
5 rows in set (0.00 sec)MySQL がデータの事前並べ替えに役立つのはなぜですか?
2.1 まずエラーページのデータ構造を見てみましょう。
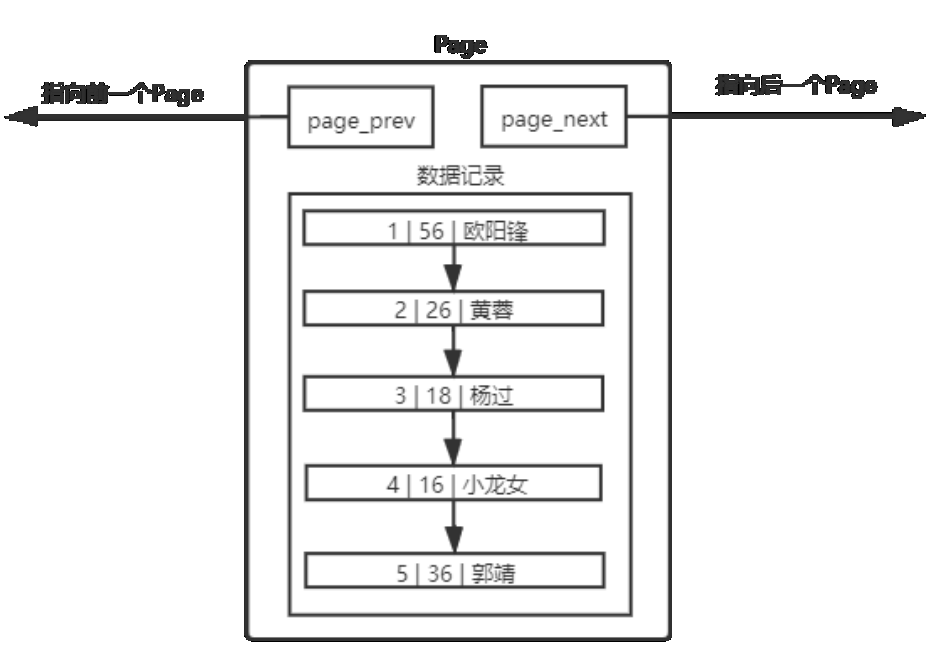
MySQL は毎回ページをロードします。各ページは、隣接するページを関連付けるために双方向リンク リストを使用します。リンク リストは、内部ページを接続するためにも使用されます。CRUD の要件を満たすことができますが、データ量が多く、カーペット状の逐次検索が困難となり、データ検索効率が大幅に低下します。
2.2 単一ページ内の正しいデータ構造
セクション 2.1 の構造と比較して、この構造はディレクトリを格納するためにより多くのスペースを必要とします。このディレクトリは、本を読んだり辞書を引いたりするようなもので、目的のデータのおおよそのページ数がすぐにわかり、検索効率が向上します。したがって、MySQL ページ内のこれらのディレクトリはもう少し多くのスペースを必要としますが、データ検索の速度は大幅に向上します (スペースは時間と交換されます)。
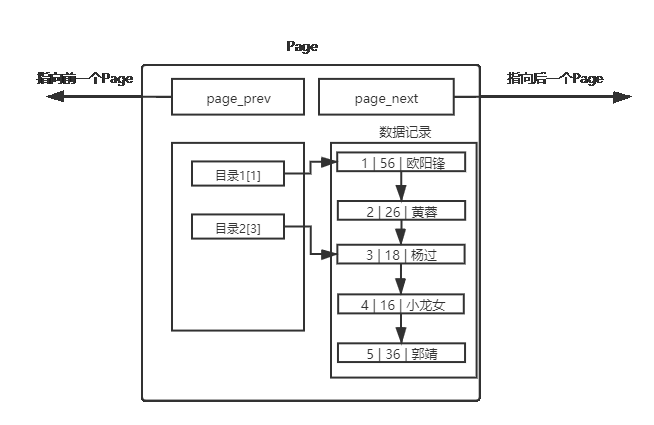
これは、この段落の先頭にデータを順不同で挿入したときに、MySQL が自動的にデータを並べ替えてくれたことも説明しています。データが整っている場合にのみ、MySQL はページ ディレクトリを簡単に導入でき、その後の検索効率を向上させることができるからです。(ページ ディレクトリは整理されている必要があります。ページ ディレクトリが乱れている場合は、それをコンピュータに置き換えます。あなたがコンピュータであれば、乱れたページ ディレクトリに面してデータをすぐに見つけることができますか?)
2.3 複数ページ間の正しいデータ構造
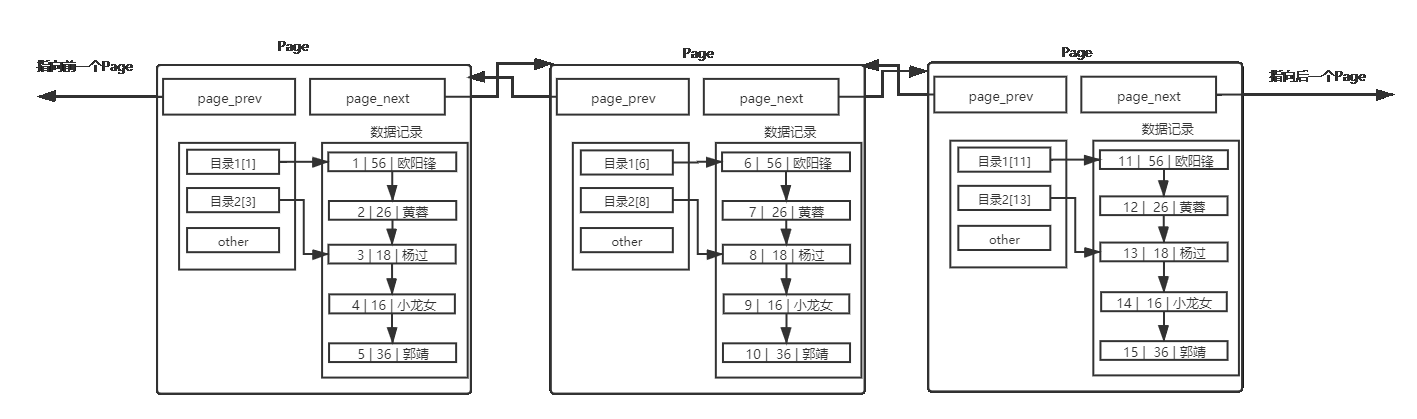
各ページ内にページ ディレクトリを作成しました。これにより、ページ内の検索数が減り、単一ページの検索効率が向上します。
上の図は複数のページ間の接続関係を示しています。この図から、ページ ディレクトリも複数のページ間の順序関係を示していることがわかります。ページをまたいでデータを検索する場合、各ページを前から後ろに順番にたどることしかできません。 . ページ ディレクトリ。ページが多すぎる場合、この取得方法ではページ間のデータ検索速度が大幅に低下します。この問題を解決するために、ディレクトリ メソッドを使用して各ページのディレクトリを管理します。

上の図では、ページ メソッドを使用してページ ディレクトリを管理しています。各ページには有効なデータは含まれていませんが、対応するページの開始ページ ディレクトリと終了ページ ディレクトリのみが含まれています。したがって、「第 1 レベル ディレクトリ」は数千のページを管理できます。
そこで再び疑問が生じますが、下部にページ数が多ければ、必然的に第 1 レベルのディレクトリの数も増加します。その場合、第 1 レベルのディレクトリのトラバースは再び線形トラバースになるのではないでしょうか? 別のレイヤーを適用します。

通常、2 つまたは 3 つのレベルで十分です。インデックス作成のみに使用されるページはそれぞれ 16 KB にすることができます。1 つのページで、次のレベルの数千のページにインデックスを付けることができます。3 つのレイヤーを備えているため、MySQL のクエリ効率は、大量のデータに直面しても低くありません。(十分でない場合は、別のレイヤーを追加すると、ストレージの量が指数関数的に増加します。) 以降の検索では、検索は上から下に実行され、見つかったページの部分のみがロードされ、B+ ツリー全体がロードされます。メモリにロードされません。
写真をよく見ると、これが B+ の木であることがわかります。ただし、注意してください:
1. すべてのストレージ エンジン インデックスが B+ ツリー、ハッシュ インデックス、その他の方法を使用するわけではありません。主流のストレージ エンジンはインデックス データ構造として B+ ツリーを使用しているとしか言えません。
2. これは B+ ツリーの特性であるため、リンク リストを使用してリーフ ノードのみがカスケードされます。同時に、カスケード リーフ ノードは範囲検索を満たすことができます (データがページ間で読み取られる場合があり、リーフ ノードには、次のページがとても便利です)
2.4 B+ ツリーの特徴

1. 非リーフ ノードはデータを保存せず、インデックス作成にのみ使用され、すべてのデータはリーフ ノードに保存されます。
2. データは葉ノードにのみ保存され、前後の葉ノードへのポインタが保存され、葉ノードはリンクリストポインタを介してカスケードされ、葉ノード自体はキーワードの昇順に接続されます。
2.5MySQL の主キー
以前にテーブルを作成したときに主キー列を指定すると、MySQL は主キーに基づいてソートします。テーブルの作成時に主キーを指定しない場合、MySQL は主キーとして非表示のカラムを生成します。これは、主キーを指定すると、MySQL が主キーに従ってソートすることも示しています。主キーを指定しない場合、MySQL のソートはデフォルトで生成される主キーに基づいて行われます。データが挿入される順序と取り出される順序はどうですか?
この記事の最初の画像では、従業員番号 998877 の従業員情報が検索されています。これには 25 秒かかります。これは、MySQL のテーブルがデフォルトの主キーに基づくインデックスで構築された B+ ツリーであるためです。無関係な従業員番号で検索すると、MySQL は線形にしか検索できず、当然ながら時間がかかります。

その後、従業員番号に従って B+ ツリー (補助インデックス) を再構築し、その番号に従って従業員情報を再度検索したところ、検索が非常に高速であることがわかりました。

2.6 B+ ツリーが他のデータ構造よりもインデックス作成に優れているのはなぜですか?
1. 線形データ構造
連結リストや逐次リストなどの線形データ構造は 1 つずつたどられますが、これは線形リストの効率が低いためであり、何度も B+ ツリーに構造が修正されます。
2. 二分探索木
二分探索木を学習するとき、このデータ構造の時間計算量は検索分岐の高さによって完全に決定されることを忘れないでください。最適な時間計算量は O(lgN) ですが、二分探索木が少し歪んでしまうと、線形構造に縮退することもありますが、この時点では複雑さは大幅に改善されます。
3. 赤黒ツリーと AVL ツリー
この 2 つのデータ構造は優れており、下図に示すように、8,000 万件のデータを検索する場合、最悪でも 26 回程度の検索で済みます。ただし、赤黒ツリーと AVL ツリーは本質的にバイナリ ツリーです。同じデータのツリーの高さは B+ ツリーよりも高くなります。ツリーの高さが高いほど、1 回の検索で削除されるデータの量は少なくなります。 、効率が低くなります。検索効率はB+ツリーより若干劣ります。

4.ハッシュ
公式のインデックス実装では、MySQL のインデックスは HASH をサポートしていますが、InnoDB と MyISAM は HASH をサポートしていません。ハッシュ化の検索効率はO(1)ですが、範囲検索には対応していません。
5.Bツリー
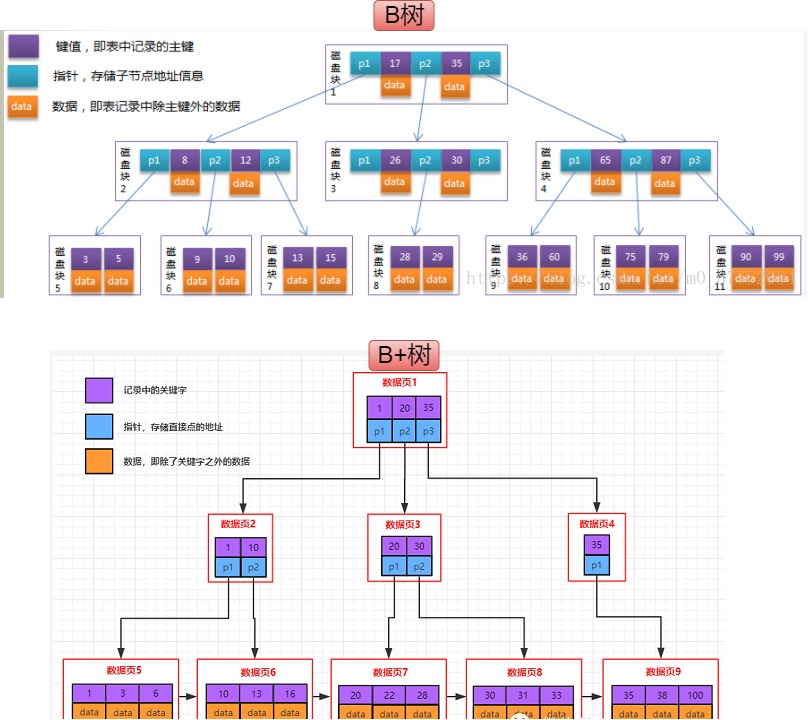
B ツリーと B+ ツリーの違いは次のとおりです。
1. 次の層のページ ディレクトリを格納することに加えて、B ツリーの非リーフ ノードにもデータが格納されるため、各非リーフ ノードが格納する次の層のページ ディレクトリが少なくなり、サイズが増加する可能性があります。木全体の高さ。
2. B ツリーのリーフ ノードはチェーン構造で接続されません。範囲検索では、ツリー全体を逆走査する必要があります。
2.7 クラスター化インデックスと非クラスター化インデックス
MyISAM ストレージ エンジン - 主キー インデックス
MyISAM エンジンはインデックス結果としても B+ ツリーを使用します。前のセクションで説明した innodb ストレージ エンジンとは異なり、MyISAM リーフ ノードのデータ フィールドにはデータレコードのアドレスが格納されます。下の図は MyISAM テーブルの主インデックスを示しています。Col1 が主キーです。
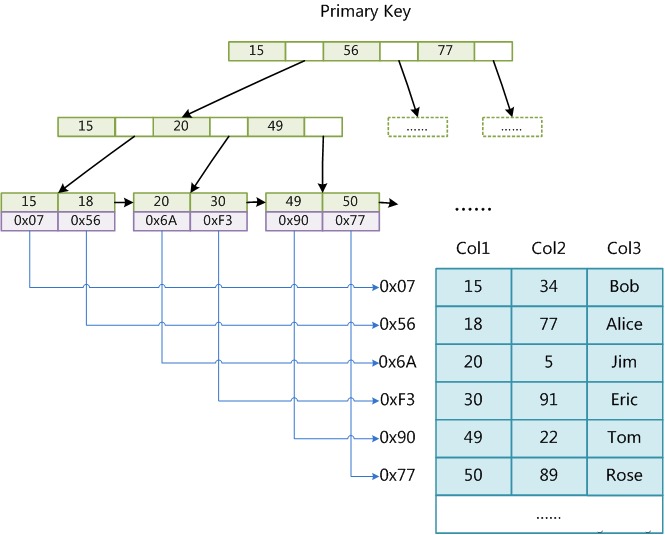
クラスター化インデックス: innodb ストレージ エンジンのように B+ ツリーとデータを一緒に保存することは、クラスター化インデックスと呼ばれます。
非クラスター化インデックス: MyISAM ストレージ エンジンのように B+ ツリーとデータを分離する方法は、非クラスター化インデックスと呼ばれます。
2.7.1MyISAMの補助(通常)インデックス
MySQL ユーザーは、デフォルトで主キー インデックスを作成するだけでなく、他のカラム情報に基づいてインデックスを作成することもできます。一般に、このようなインデックスは補助 (通常) インデックスと呼ばれます。
MyISAM の場合、セカンダリ (通常) インデックスと主キー インデックスの確立に違いはなく、主キーは繰り返すことができないが、非主キーは繰り返すことができるというだけです。
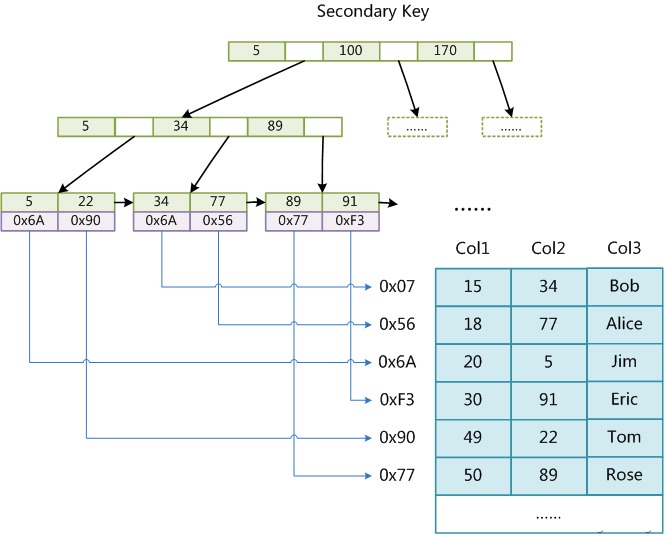
MyISAM ストレージ エンジンは、テーブル内に複数のインデックスを作成できます。次の図は、MyISAM の Col2 に基づくインデックスであり、主キー インデックスと何ら変わりません。
2.7.2 innodb の補助 (通常) インデックス
主キー インデックスに加えて、InnoDB ユーザーは補助 (通常) インデックスも作成します。上の表の Col3 に対応する補助インデックスを作成します。
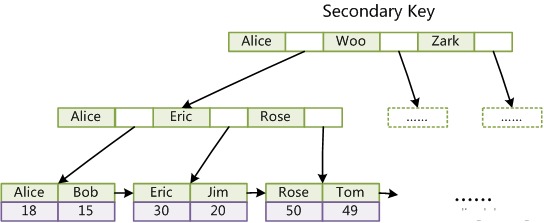
InnoDB の非主キー インデックスのリーフ ノードにはデータはなく、対応するレコードのキー値のみが存在します。したがって、補助 (通常) インデックスを通じてターゲット レコードを検索するには、2 つのインデックス パスが必要です。まず、補助インデックスを取得して主キーを取得し、次に主キーを使用して主インデックス内のレコードを取得します。このプロセスはテーブル クエリと呼ばれます。
この補助 (通常の) インデックス シナリオでは、InnoDB がデータをリーフ ノードに添付しないのはなぜですか? データには主キー インデックスがあるため、コピーを 2 つ保存する必要はありません。保存しないと領域の無駄になります。
5. インデックス操作
1. インデックスを作成する
1.1 主キーインデックスの作成
方法 1: テーブルの作成時に主キーを指定する
-- 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));方法 2: 方法 1 と同じですが、記述方法が異なります
-- 在创建表的最后,指定某列或某几列为主键索引
create table user2(id int, name varchar(30), primary key(id));方法 3: テーブルの作成後に主キーを追加する
create table user3(id int, name varchar(30));
-- 创建表以后再添加主键
alter table user3 add primary key(id);1.2 一意のインデックス(通常のインデックス)を作成する
方法 1: テーブルの作成時に一意のキーを指定する
-- 在表定义时,在某列后直接指定unique唯一属性。
create table user4(id int primary key, name varchar(30) unique);方法 2: 方法 1 と同じですが、記述方法が異なります
-- 创建表时,在表的后面指定某列或某几列为unique
create table user5(id int primary key, name varchar(30), unique(name));方法 3: テーブルの作成後に一意のキーを追加する
create table user6(id int primary key, name varchar(30));
alter table user6 add unique(name);1.3 通常インデックス/複合インデックスの作成
方法1: テーブル作成時に通常のインデックスを指定する
create table user8(id int primary key,
name varchar(20),
email varchar(30),
index(name) --在表的定义最后,指定某列为索引
);方法2: テーブル作成後、通常のインデックスとしてカラムを指定する
create table user9(id int primary key, name varchar(20), email
varchar(30));
alter table user9 add index(name); --创建完表以后指定某列为普通索引方法 3: テーブルの作成後にカスタム名で共通インデックスを作成する
create table user10(id int primary key, name varchar(20), email
varchar(30));
-- 创建一个索引名为 idx_name 的索引
create index idx_name on user10(name);作成された複合インデックスは実際には B+ インデックスです。名前が電子メールの通常のキーと同じであることがわかります。複合インデックスの機能は、複数のフィールドを指定して B+ ツリーを構築することです。名前で電子メールを検索する必要がある場合は、複合インデックスを構築すると、テーブルにクエリを戻す必要がなくなります。インデックスを使用して別のインデックスを見つける方法は、インデックス カバレッジと呼ばれます。:
mysql> alter table test1 add index(name,email);
Query OK, 0 rows affected (0.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
*************************** 2. row ***************************
Table: test1
Non_unique: 1
Key_name: name--索引名称是一样的,这俩是同一颗B+树
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 3. row ***************************
Table: test1
Non_unique: 1
Key_name: name--索引名称是一样的,这俩是同一颗B+树
Seq_in_index: 2
Column_name: emile
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
3 rows in set (0.00 sec)複合インデックスの作成が完了すると、名前を使用して検索することも、(名前, 電子メール) を使用して検索することもできますが、電子メールを使用して検索することはできません。これがインデックスの左端の一致原則です。
1.4 全文インデックスの作成
全文インデックスは、記事フィールドまたは大量のテキストを含むフィールドを検索するときに使用されます。MySQL はフルテキスト インデックス メカニズムを提供しますが、テーブルのストレージ エンジンが MyISAM である必要があるという要件があり、デフォルトのフルテキスト インデックスは英語のみをサポートし、中国語はサポートしません。中国語で全文検索を行う場合は、中国語版のsphinx(coreseek)を使用できます。
--创建全文索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)--创建全文索引
)engine=MyISAM;
--插入数据
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');データベース データがあるかどうかを確認します。
--普通查询
select * from articles where body like '%database%';
--全文索引
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database');
2. クエリインデックス
show keys from 表名;--方式一
show index from 表名;--方式二
desc 表名;----方式三,这种方式显示出来的信息比较简略
mysql> show index from test1\G;
*************************** 1. row ***************************
Table: test1
Non_unique: 0
Key_name: PRIMARY--索引名称(B+树索引)
Seq_in_index: 1
Column_name: id--以那一列为索引构建的B+树
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE--索引类型(B+树)
Comment:
Index_comment:
1 row in set (0.00 sec)3. インデックスの削除
主キーインデックスを削除します。
--方式一:删除主键索引
alter table 表名 drop primary key;他のインデックスの削除 (一意のインデックスの削除など):
--方式二:索引名就是show keys from 表名中的 Key_name 字段
alter table 表名 drop index 索引名;
--方式三:
mysql> drop index name on user8;4. どのフィールドにインデックスを付ける必要がありますか?
1. 主キー制約と一意キー制約のあるフィールドには独自のインデックスがあります
2. 特定の列がクエリ条件として頻繁に使用される
3. 一意性の低い列は、たとえこの列が頻繁にクエリされる場合でも、インデックスとしては適していません。
4. 頻繁に更新されるフィールドはインデックスとして適さない