MYSQL 入門シリーズ - パート 2
1. フィルター条件:
(1) 比較演算子:
| オペレーター | 意味 |
|---|---|
| = | 等しい (注: == ではない) |
| >= | 以上 |
| != または <> | 等しくない |
| < | 未満 |
| > | 以上 |
| <= | 以下 |
| 無効です | 空です |
| NULL ではありません | ヌルではない |
ナレッジ ポイント供給ステーション:
IS NULL と IS NOT NULL の使用方法
select * from tb_name where 字段名 IS NULL;
tb_name テーブルで、指定されたフィールド名が空であるすべてのデータを照会します。
(2) 論理演算子:
| オペレーター | 意味 |
|---|---|
| と | と |
| また | また |
| いいえ | いいえ |
(3) その他の操作:
1. 並べ替え:
select name1 from tb2_name order by tb3_name [asc/desc];
-
最初の名前は、指定されたクエリのデータ、つまり表示されるデータです。
-
2 番目の tb2_name はテーブルの名前です。
-
3 番目の tb3_name は、テーブルで並べ替えられた列のフィールドです (通常、文字の場合は数字で並べ替え、最初のアルファベット順で並べ替えます)。
-
asc は正の順序 (デフォルト、入力なしも正の順序)、desc (降順、降順) は逆の順序です。
2. 制限:
select name1 from tb_name limit start,count;
-
最初の name1 は、指定されたクエリのデータ、つまり表示されるデータです。
-
2 番目の tb_name テーブルの名前。
-
3 番目の start は、制限されたテーブルで開始する行数で、count は表示される行数です。(テーブルの行数は0から始まります。startにデータがない場合、デフォルトでは0行目から始まります)
拡大:
条件付き制限 (場所):
select name1 from tb_name where 条件语句 limit start,count;
- where に一致し、start と count の制約を満たすデータは、name1 からフィルター処理されます。
3. 重複排除:
select distinct name1 from tb_name;
-
最初の name1 は、指定されたクエリ データ、つまり表示されるデータです。これは重複排除用に指定されたデータです。
-
2 番目の tb_name はテーブル名です。
注:
name1 が * の場合、テーブル全体の行が同じように重複排除されます; name1 がフィールド名の場合、対応するフィールド値が同じように重複排除されます。
4.あいまいクエリ: (「%」など)
-
任意の文字数: %
あいまいクエリと範囲クエリは where と共に使用されます。 -
任意の文字: _
例:
select name1 from tb_name where name like 'h%';
-
クエリ テーブルは、名前が h で始まる対応する name1 フィールドの下のフィールド値を満たします。
-
「h%」を「h_」に置き換えると、h で始まる名前と、h の後の 1 文字のみを照会できます。
-
'h%' が '%h%' に置き換えられた場合、名前の途中に h が含まれる名前のみを照会できます
5. 範囲クエリ:
- 連続範囲: a と b の間 a
<= 値 <= b (a と b を含む)
例:
select name1 from tb_name where id between a and b;
- クエリ テーブルの a と b (a と b を含む) の間の id を持つ name1 フィールドの下のフィールド値。
- 間隔の範囲: in()
角かっこは、表にない値を含め、任意の値を書き込むことができます。エラーは報告されません。角かっこで指定された値のみがクエリされます。
例:
select name1 from tb_name where id in (1,7);
- テーブル内の ID 1 と 7 を持つ対応する name1 フィールドの下のフィールド値のみを照会します。テーブルにないフィールド値を書き込むことができ、エラーは報告されません。
2. 集約とグループ化 (強調!):
データ表作成(分かりやすく説明するため、実演効果に合わせます):
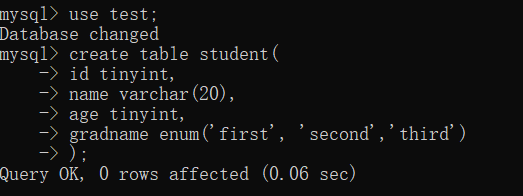
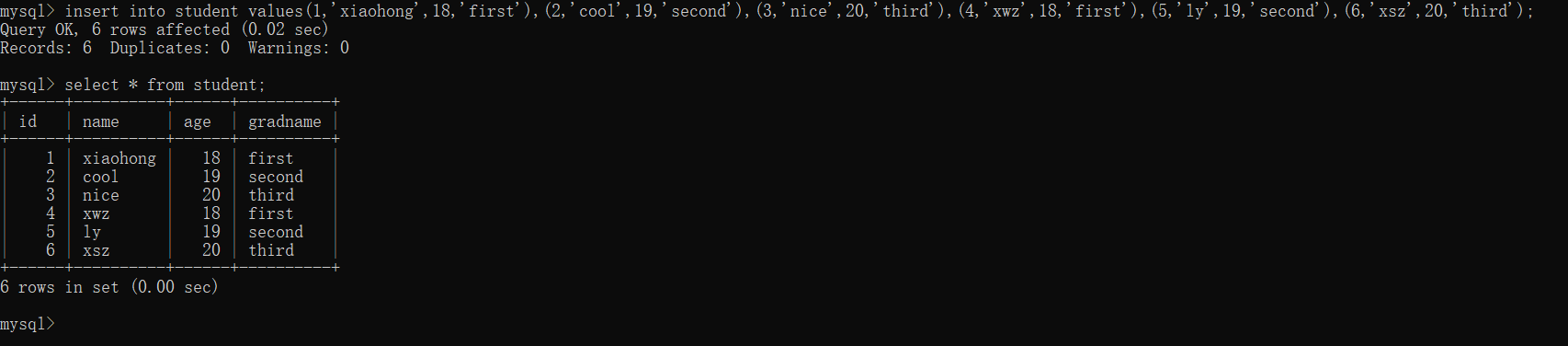
(1) 一般的に使用される集計関数:
| 集計関数 | 効果 |
|---|---|
| カウント(列) | 統計学 |
| 合計(列) | 和 |
| 最大(列) | 最大値 |
| 平均(列) | 平均値 |
| 分(列) | 最小 |
| group_concat(列) | すべてのフィールド値を一覧表示する |
利用方法:
select 聚合函数(字段) from 表;
(実際、これらの集約関数は、単独で使用すると実用的な効果がないと感じるかもしれません。実際、集約関数は、一般的にグループ化と組み合わせて使用され、その役割を果たします〜)
ハイライト:
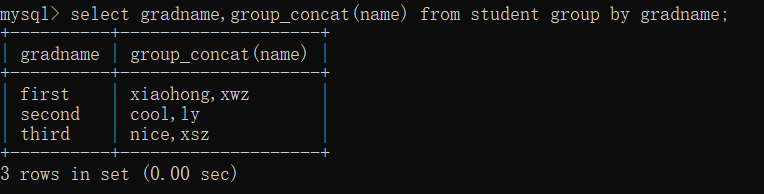
select group_concat(字段) from 表;
- 指定されたフィールドのすべての値を一覧表示します (グループ化後に、各グループ内の指定されたフィールドのすべての値を一覧表示できます。
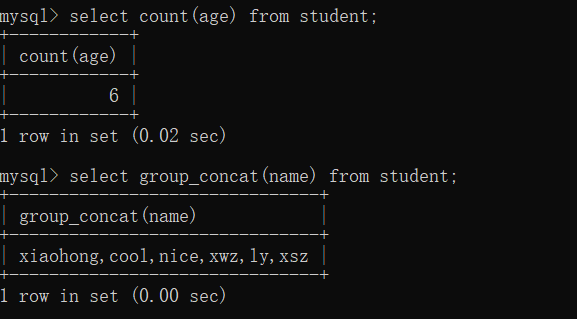
(2) グループクエリ:
select 字段 from 表 group by 字段;
(注: ここの 2 つのフィールドは一致している必要があります。一致していないと、エラーが報告されます)
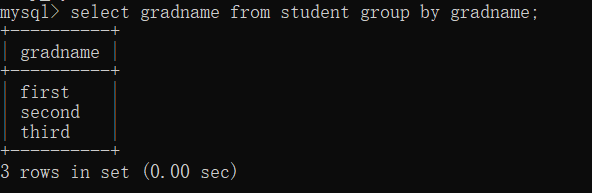
select 字段,count(*) from 表 group by 字段;
たとえば、表示カウント、つまり数値などの集計関数で使用します。
| 注: グループ化の場合、グループ化フィールド (つまり、グループ化のフィールド) と集計フィールドのみが表示され、他のフィールドは意味がなく、エラーが報告されます! |
ちょっとした注意:
where フィルターを追加する場合は、where ステートメントをグループ クエリ group by~ の前に配置する必要があります。
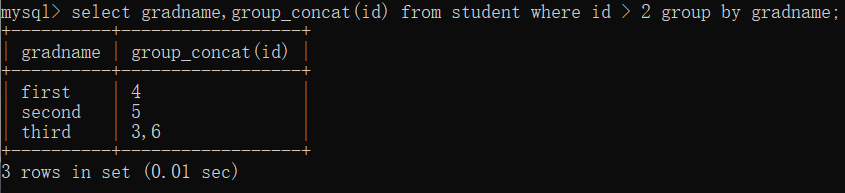
(3) 集計スクリーニング: (有)
select 字段1 from 表名 group by 字段1,字段2 having 字段2>=80;
(出力結果を絞り込むための条件式を追加します。どこで考えましたか? 心配しないで、私も考えました~)

クエリ ステートメントにエイリアス (as)、集約関数が含まれている場合、その実行順序は次のとおりです。
- 最初の実行: 今回はテーブル全体を前提にフィルタリングする場所
- 次に実行: 関数とエイリアスの集約
- 最終実行: having、今回はフィールドでのフィルタリング
(where は having よりも高速です! したがって、where を使用します)
注: 一般に、where で記述された条件付きフィルタリングは、filtering を持つことで表現できます。
小さなヒント: 最後に having class = 'first' を追加します。その前に where を使用できます。コードの実行結果は同じです。
ただし、where はテーブル全体でフィルタリングされ、having は集計およびグループ化操作後に生成された仮想テーブルでフィルタリングされることに注意してください。(つまり、どこが集計グルーピング前のデータをフィルタリングするか、有は
集計後にフィルタリングすることです) どちらを使うかはシーン次第ですよ~
3. サブクエリ:
1 つのクエリの結果を次のクエリに残す (select 内にネストされた select)
必要とする:
-
クエリ内にネスト
-
常に括弧内に表示する必要があります
例:
- 学生の平均年齢を求める
select avg(age) from students;
- 平均年齢より古いデータを見つける
select * from student where age > 19.7273;
- 平均年齢を求める SQL ステートメントを使用して、平均年齢よりも古いステートメントを見つけます。
select * from students where age > (select avg(age) from students);
4. 接続クエリ:
別のテーブルを作成し、上記で作成したテーブルを組み合わせて効果を実証します。
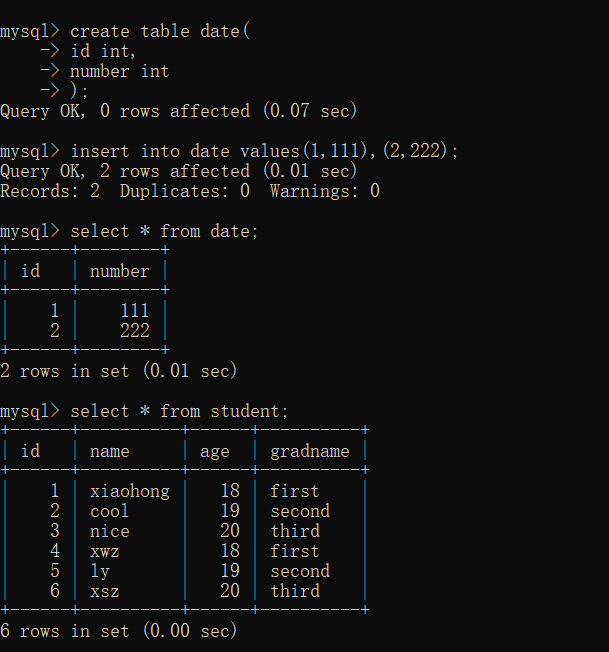
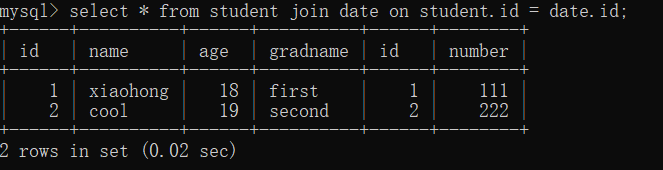
(1) 内部結合
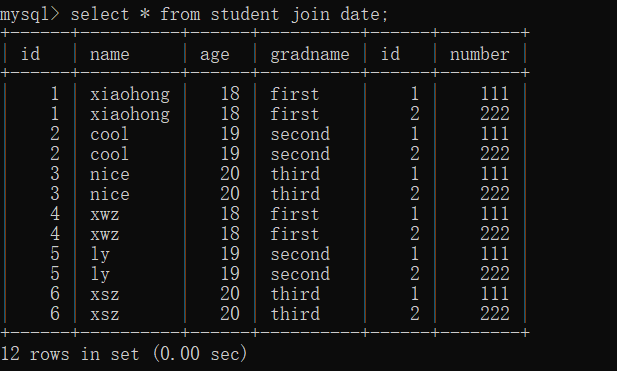
- 無条件の内部結合:
無条件の内部結合は、クロス結合/デカルト結合とも呼ばれ、最初のテーブルの各アイテムが他のテーブルの各アイテムと順番に結合されます
select * from 表1 [inner] join 表2;
inner は書き込み可能かどうかは関係ありません。
たとえば、最初のテーブルには 6 個のデータがあり、2 番目のテーブルには 2 個のデータがあり、内部結合クエリには 12 個のデータがあり、最初のテーブルの各データは次の 2 つのデータと結合されます。 2番目のテーブル。
- 条件付き内部結合:
無条件の内部リンクに基づいて、on 句を追加します。接続時に、組み合わせのために意味のあるレコードを除外し
select * from 表1 inner join 表2 on 条件
ます (例: table 1.id = table 2.id)。
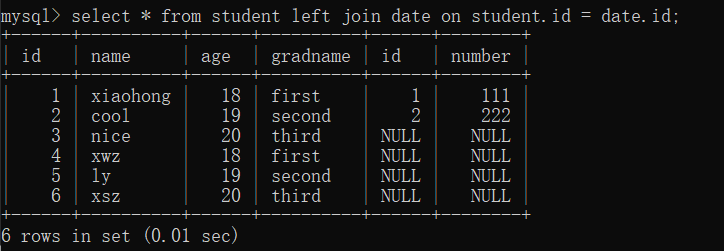
(2) 外結合(左右結合)
- 左外部結合:(左表を基に)
2つの表を接続する場合、接続条件が一致しない場合は左表のデータを残し、右表のデータはNULL
select * from 表1 left join 表2 on 条件;
条件で埋める 表1フィールド = 表 2. フィールド。
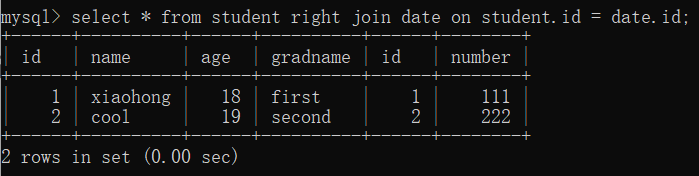
- 右外部結合:(右表を元に)
2つの表を結合する場合、結合条件が一致しない場合は右表のデータを残し、左表のデータはNULLで埋める
select * from 表1 right join 表2 on 条件;
拡大:
3 つの接続:
select * from 表1 left join 表2 on 条件1 left join 表3 on 条件2;
表 1 と表 2 は、メインの表である表 3 と結合されます。