Directorio de artículos
- Prefacio
- Reglas básicas del árbol B
- Inserción de datos del árbol B (descripción de texto + ilustración)
- Búsqueda de datos del árbol B
- Análisis de eficiencia del árbol B
- El papel del árbol B
- Reglas básicas del árbol B+
- Comparación entre el árbol B+ y el árbol B
- B* reglas básicas del árbol
- Comparación entre el árbol B* y el árbol B+
- expandir
Prefacio
Reglas básicas del árbol B
-
Cada nodo tiene como máximo m nodos secundarios, donde m es un número entero positivo. Excepto el nodo raíz, otros nodos tienen al menos ⌈m/2⌉ nodos secundarios.
-
Los valores clave de cada nodo están organizados en orden no descendente. Para el valor clave k en el nodo, si hay n nodos secundarios, entonces los valores clave n-1 en el nodo dividirán el nodo en n intervalos. El valor clave del i-ésimo intervalo es menor que k, y el valor clave del intervalo i+1-ésimo es El valor clave es mayor o igual a k.
-
Todos los nodos hoja están ubicados en la misma capa y no contienen ninguna información de valor clave y pueden considerarse como bloques almacenados externamente.
-
La cantidad de valores clave en cada nodo no hoja es 1 menos que la cantidad de nodos secundarios.
-
El número de valores clave en cada nodo satisface:
⌈m/2⌉-1 <= número de valores clave <= m-1

Inserción de datos del árbol B (descripción de texto + ilustración)
Descripción general de las reglas de inserción:
1. Comenzando desde el nodo raíz, compare de acuerdo con los valores clave en los nodos para encontrar el nodo hoja apropiado (el resultado de la comparación es similar a un árbol de búsqueda binario).
2. Si el valor clave ya existe en el nodo hoja, actualice el valor correspondiente.
3. Si el valor clave no existe en el nodo hoja, inserte el valor clave en la posición apropiada del nodo hoja y mantenga los valores clave en el nodo en orden.
4. Si después de insertar el valor clave, el número de valores clave en el nodo hoja excede el límite superior m-1, se realizará una operación de división.
将叶子节点的键值分成两部分,左边部分包含⌈(m-1)/2⌉个键值,右边部分包含⌊(m-1)/2⌋个键值。
将右边部分的键值和对应的子节点分离出来,形成一个新的叶子节点。
将新的叶子节点插入到叶子节点的右边,并更新父节点的键值信息。
5. Si después de insertar el valor clave, el número de valores clave en el nodo hoja no excede el límite superior m-1, insértelo directamente.
6. Si el nodo principal existe y se excede el límite superior m-1 después de insertar el valor clave, realice una operación de división.
将父节点的键值分成两部分,左边部分包含⌈(m-1)/2⌉个键值,右边部分包含⌊(m-1)/2⌋个键值。
将右边部分的键值和对应的子节点分离出来,形成一个新的父节点。
将新的父节点插入到父节点的右边,并更新祖父节点的键值信息。
Repita el paso 6 hasta llegar al nodo raíz.
(Ilustración) Las situaciones de inserción se clasifican en las siguientes categorías:
-
Sin nodo principal, no es necesario dividirlo;
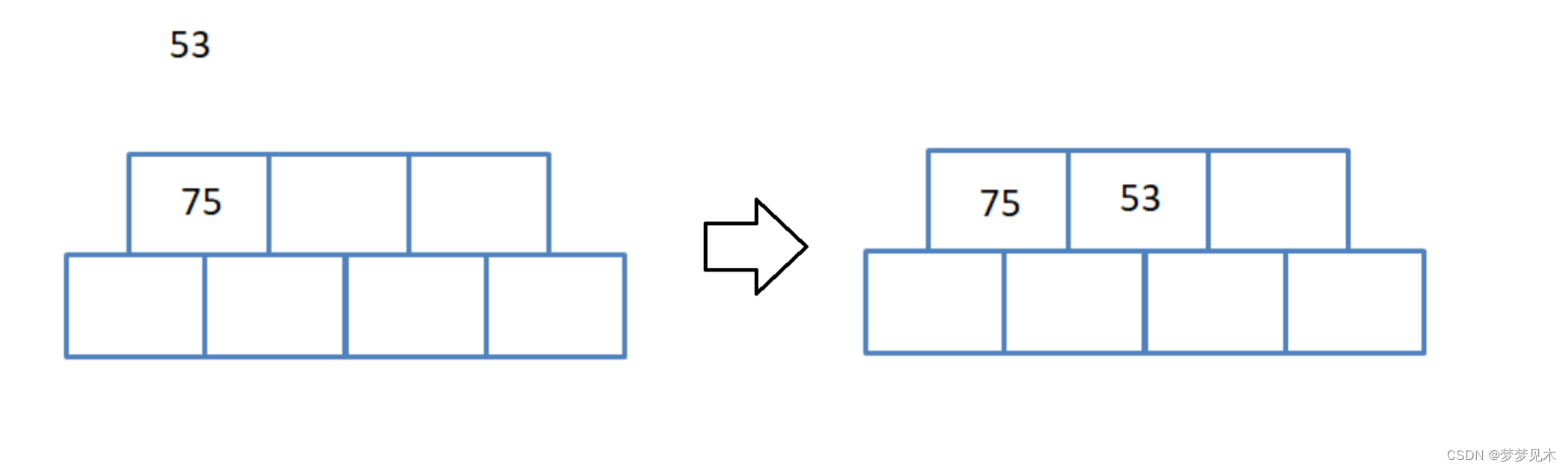
-
Hay un nodo padre, no es necesario dividirlo;
-
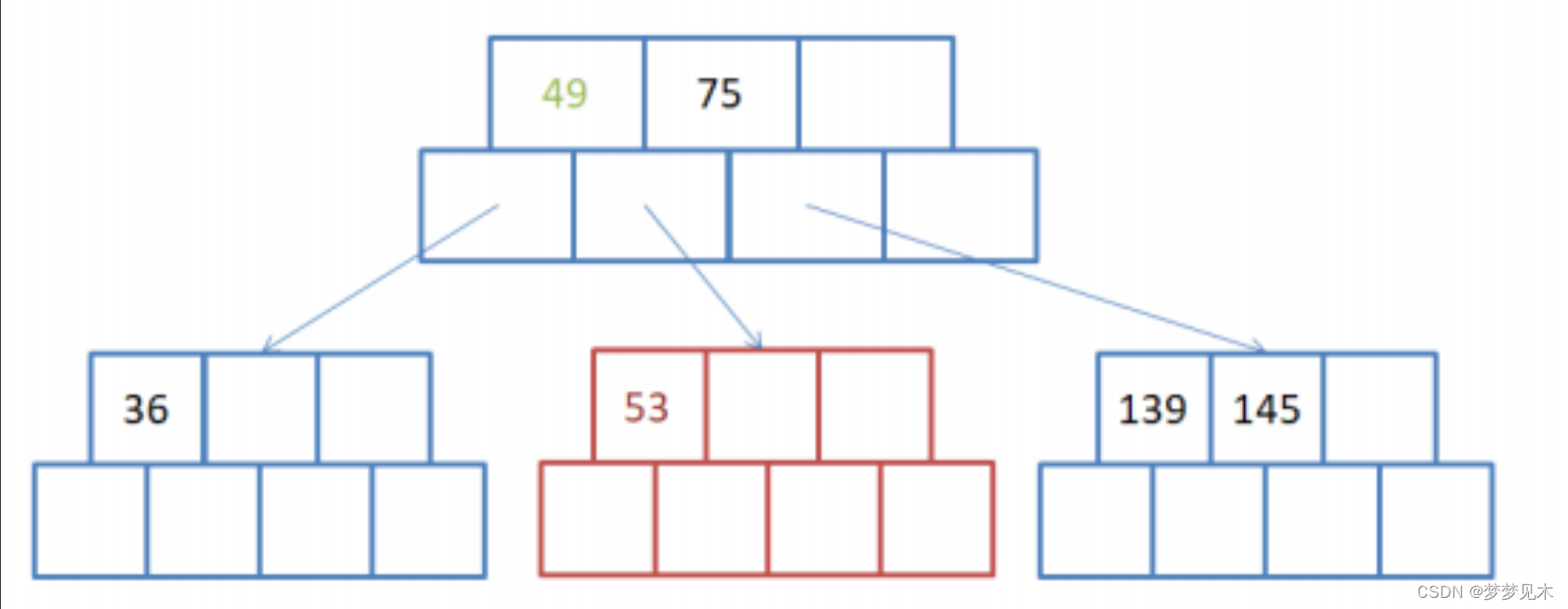
No es necesario dividir ningún nodo principal;
将叶子节点的键值分成两部分,左边部分包含⌈(m-1)/2⌉个键值,右边部分包含⌊(m- 1)/2⌋个键值。 将右边部分的键值和对应的子节点分离出来,形成一个新的叶子节点。 -
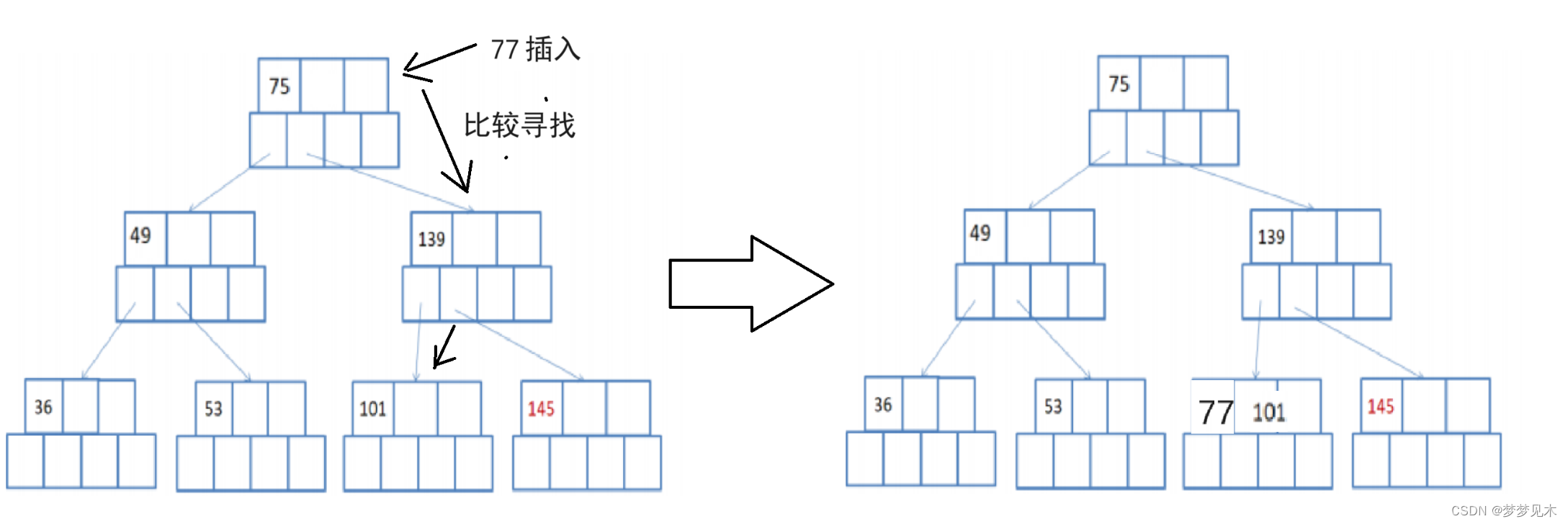
Hay un nodo principal y el nodo insertado debe dividirse. Después de la inserción, no es necesario dividir el nodo principal;
el valor clave del nodo hoja se divide en dos partes, la parte izquierda contiene ⌈ (m-1 )/2⌉ valores clave, y la parte derecha contiene valores clave ⌊(m- 1)/2⌋.
Separe el valor clave en la parte derecha del nodo secundario correspondiente para formar un nuevo nodo hoja.Inserte el nuevo nodo hoja a la derecha del nodo hoja y actualice la información del valor clave del nodo principal.
-
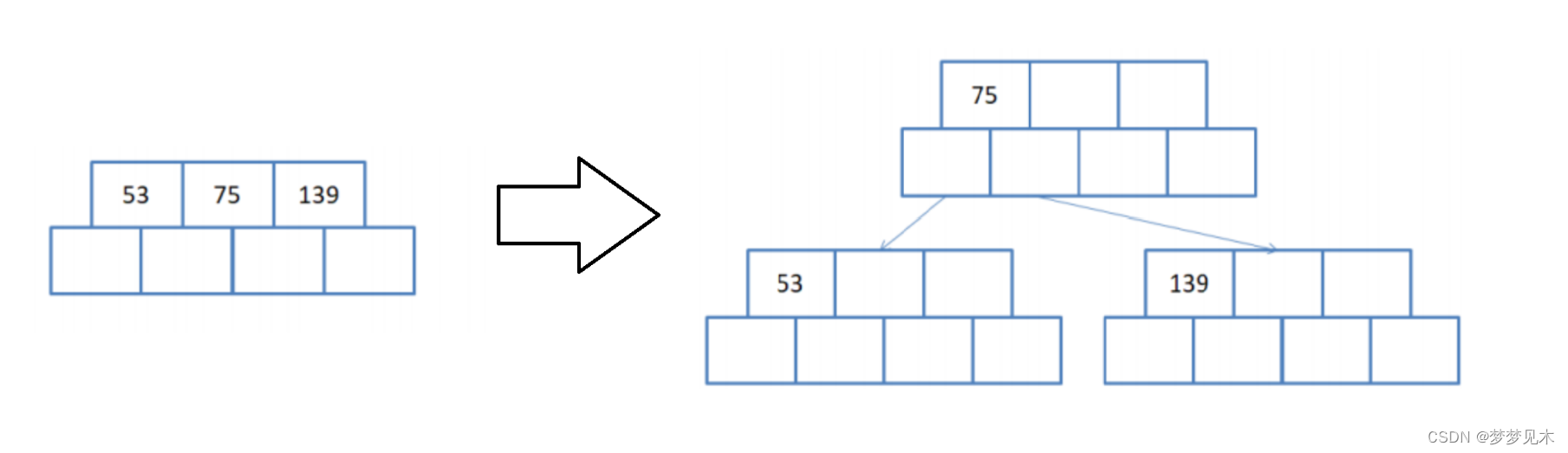
Si hay un nodo principal, el nodo insertado debe dividirse y el nodo principal debe dividirse después de la inserción;
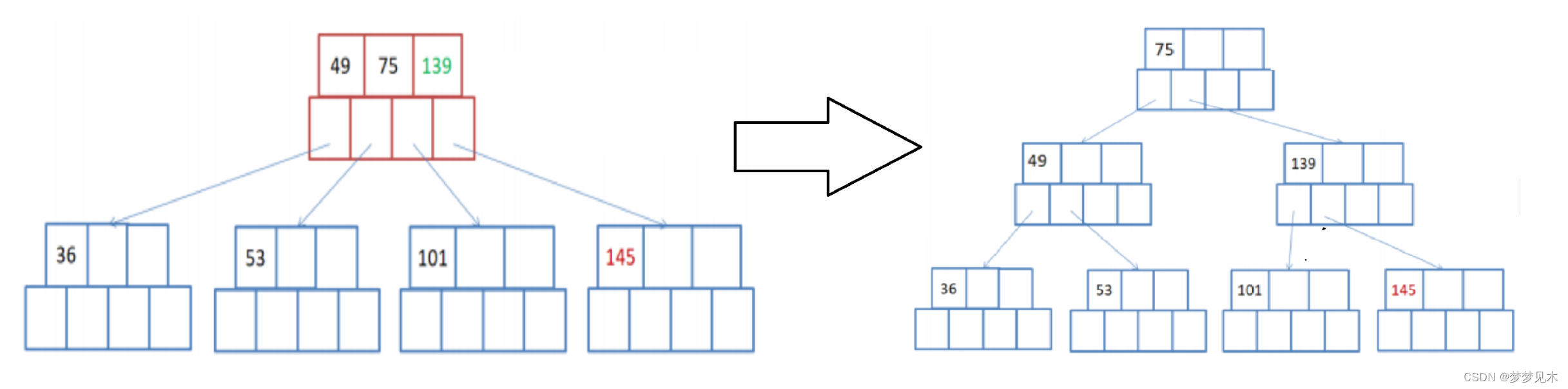
将父节点的键值分成两部分,左边部分包含⌈(m-1)/2⌉个键值,右边部分包含⌊(m-1)/2⌋个键值。
将右边部分的键值和对应的子节点分离出来,形成一个新的父节点。
将新的父节点插入到父节点的右边,并更新祖父节点的键值信息。
重复以上步骤,直到根节点
Búsqueda de datos del árbol B
Dado que el formato de la disposición de los datos es similar a la búsqueda en un árbol binario, la búsqueda también lo es.
Análisis de eficiencia del árbol B
Si ignora la enorme diferencia en el tiempo de búsqueda entre la memoria y la memoria externa:
Supongamos:
número de valores válidos = N;
grado = M;
entonces: número de valores válidos de un nodo = M/2 ~ M-1;
por lo tanto: árbol La altura es = log{M/2} N ~ log{M-1}N; la
complejidad de buscar dentro de un nodo = O(log{2}M/2) ~ O(log{2}M- 1);
por lo tanto: Complejidad del tiempo final = [ O(log{2}M/2 ) ~ O(log{2}M-1 ) ] * [ log{M/2} N ~ log{M-1}N ]
Sin embargo, este no es el caso en las aplicaciones reales: el tiempo real se consume principalmente en el proceso de acceder a los nodos de nivel inferior desde el nodo de nivel superior, porque acceder a este nodo en realidad accede a la memoria externa;
( Punto clave de comprensión ) Durante el proceso de búsqueda del árbol B, la operación IO es la operación de ingresar al nodo. Cuando es necesario acceder al nodo en el disco durante el proceso de búsqueda, se requiere una operación IO para leer el nodo desde el disco en la memoria.
Entonces, el consumo de tiempo principal es: [ log{M/2} N ~ log{M-1}N ] veces de acceso a la memoria externa. ! ! !
Para N = 62*1000000000 nodos, si el grado M es 1024, entonces log M / 2 N log_{M/2}Niniciar sesión _m / 2N <=
4, es decir, entre 62 mil millones de elementos, si el grado de este árbol es 1024, se necesitarán menos de 4 veces para ubicar el nodo y luego usar la búsqueda binaria para ubicar rápidamente el elemento, lo que reduce en gran medida la lectura. número de discos.
El papel del árbol B
Índice de la base de datos: el árbol B se utiliza a menudo como estructura de índice de la base de datos, que puede admitir de manera eficiente la búsqueda de datos y la consulta de rango.
Sistema de archivos: el árbol B se utiliza para la estructura de directorios en el sistema de archivos, que puede admitir de manera eficiente la búsqueda y administración de archivos.
Sistema de almacenamiento en caché: B-tree se puede utilizar para almacenar en caché la estructura del índice en el sistema para acelerar el acceso y la consulta de datos.
Tabla de enrutamiento: B-tree se puede utilizar para almacenar y buscar tablas de enrutamiento para localizar rápidamente direcciones de destino.
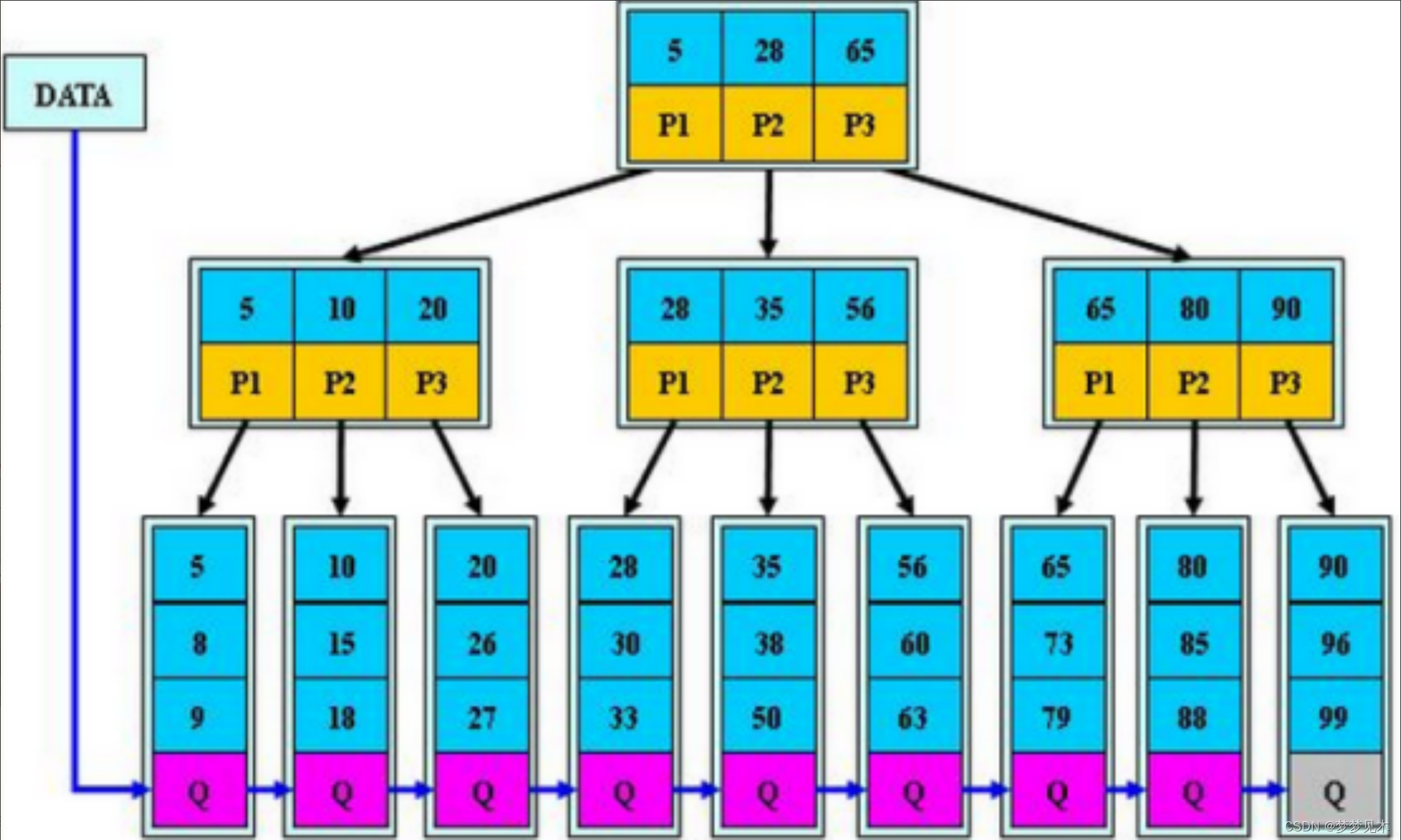
Reglas básicas del árbol B+
- El puntero del subárbol del nodo de rama es el mismo que el número de palabras clave
- El puntero del subárbol p [i] del nodo de rama apunta al rango de valores clave entre [k [i], k [i + 1])
- Todos los nodos de hoja están vinculados entre sí agregando un puntero de enlace.
Todas las palabras clave y sus datos de mapeo aparecen en los nodos de hoja (todos los datos se almacenan en la capa inferior). - Todas las palabras clave aparecen en la lista vinculada de nodos hoja y los nodos en la lista vinculada están ordenados.
- Es imposible acceder a los datos en el nodo de rama (todos los datos se almacenan en la capa más baja)
- El nodo de rama es equivalente al índice del nodo hoja, y el nodo hoja es la capa de datos donde se almacenan los datos.
Comparación entre el árbol B+ y el árbol B
Primero hablemos de la conclusión:
1. El árbol B es más adecuado para la búsqueda aleatoria y el árbol B+ es más adecuado para la búsqueda por rango
2. El árbol B+ ahorra relativamente más espacio 3.
Al insertar y eliminar datos, el árbol B+ es más alto
Razón:
- Cada nodo del árbol B contiene palabras clave y punteros correspondientes, que se utilizan para almacenar datos y crear índices. Los nodos del árbol B pueden almacenar datos directamente, por lo que el nodo donde se encuentran los datos se puede ubicar directamente durante la búsqueda.
Cada nodo del árbol B+ solo contiene palabras clave y los datos se almacenan en nodos hoja. Los nodos hoja están conectados mediante punteros para formar una lista vinculada ordenada, y las palabras clave en los nodos hoja también forman una secuencia ordenada. Los nodos no hoja del árbol B + solo se utilizan para indexar y no almacenan datos, lo que puede reducir la cantidad de nodos no hoja y mejorar la utilización de la memoria. - Los nodos del árbol B almacenan tanto datos como índices, por lo que cada nodo puede almacenar más datos. Esto puede reducir la altura del árbol y mejorar la eficiencia de las consultas. Sin embargo, dado que los nodos del árbol B contienen datos, las operaciones de inserción y eliminación requieren movimiento y ajuste de datos, lo cual es relativamente lento.
Los nodos que no son hojas del árbol B+ solo se usan para indexar y no almacenan datos, por lo que cada nodo puede almacenar más índices. Los nodos hoja están conectados mediante punteros para formar una lista vinculada ordenada, que puede realizar un acceso secuencial de manera eficiente. Al mismo tiempo, dado que los datos del árbol B+ solo se almacenan en los nodos hoja, las operaciones de inserción y eliminación solo necesitan ajustar el nodo índice, lo cual es relativamente rápido.
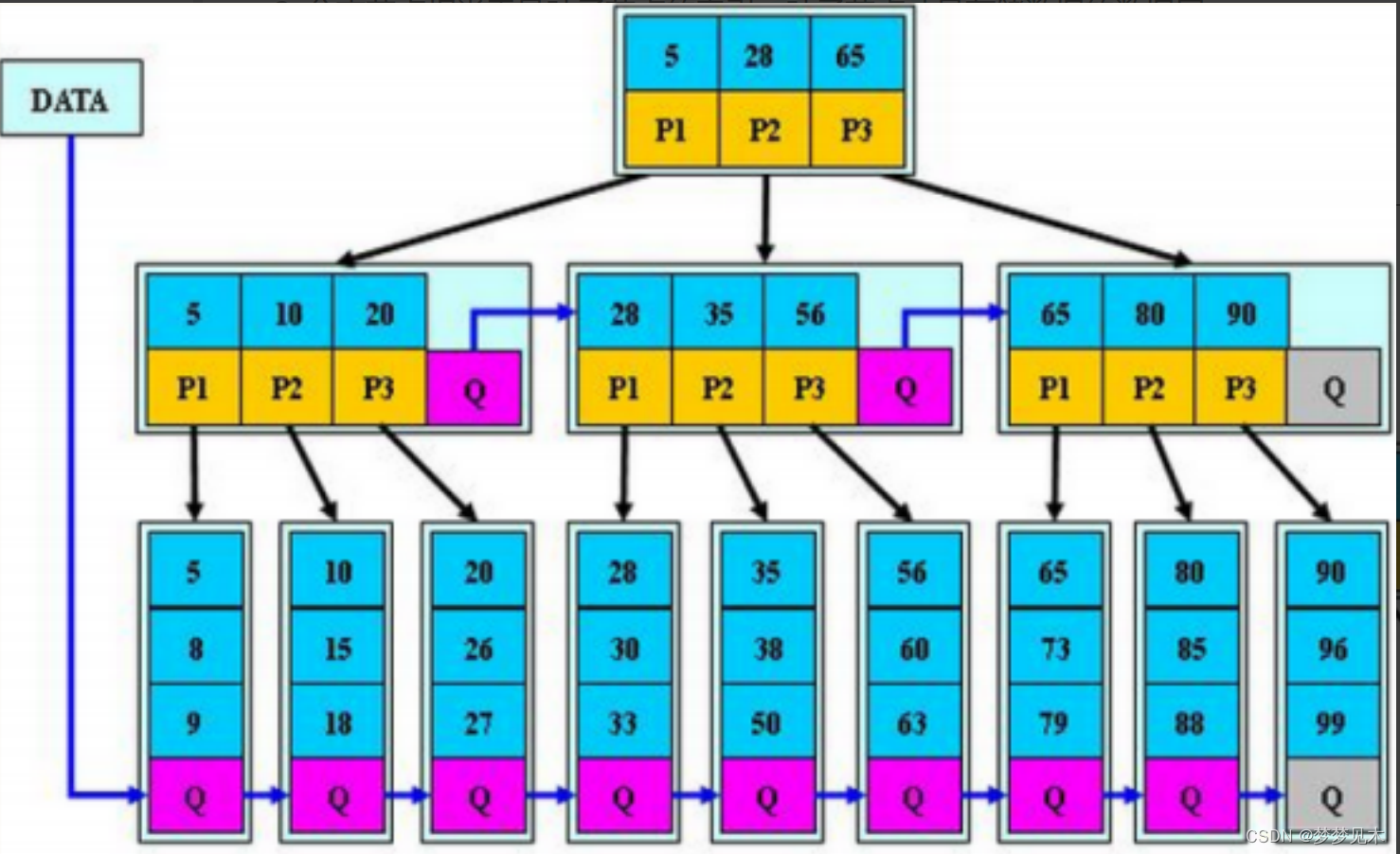
B* reglas básicas del árbol
El árbol B * es una deformación del árbol B +. Los punteros a los nodos hermanos se agregan a los nodos que no son raíz ni hoja del árbol B +.
Comparación entre el árbol B* y el árbol B+
Conclusión: el árbol B* tiene una mayor utilización del espacio que el árbol B+
División del árbol B+: cuando un nodo está lleno, asigne un nuevo nodo, copie la mitad de los datos del nodo original al nuevo nodo y finalmente agregue el puntero del nuevo nodo al nodo principal;
División del árbol B *: cuando un nodo está lleno, si su siguiente nodo hermano no está lleno, mueva parte de los datos al nodo hermano, luego inserte la palabra clave en el nodo original y finalmente modifique el hermano en el nodo padre
. La palabra clave del nodo (porque el rango de palabras clave del nodo hermano ha cambiado); si el hermano también está lleno, agregue un nuevo nodo entre el nodo original y el nodo hermano, y copie 1/3 de los datos al nuevo nodo .punto y, finalmente, agregue el puntero del nuevo nodo al nodo principal.
expandir
Las reglas de operación de inserción del árbol B+ son las siguientes:
Encuentre la posición de inserción: comenzando desde el nodo raíz, busque la posición de inserción de acuerdo con las reglas de búsqueda del árbol B +. Si la palabra clave insertada ya existe en el árbol, se procesará de acuerdo con la situación específica (como reemplazar, ignorar o fusionar, etc.).
Insertar en el nodo hoja: inserte la nueva palabra clave en la posición apropiada en el nodo hoja. Si la cantidad de palabras clave que hacen que los nodos hoja excedan el límite superior del orden después de la inserción, se realiza una operación de división.
División de nodos de hoja: divida el nodo de hoja que excede el límite superior del orden en dos nodos. Mueva la mitad de las palabras clave a nuevos nodos y ajuste las conexiones del puntero. Al mismo tiempo, la clave mínima del nuevo nodo se inserta en el nodo principal.
Ajuste del nodo principal: si la división de un nodo hoja hace que el número de palabras clave del nodo principal exceda el límite superior del orden, se realizará una operación de división recursiva. Divida el nodo principal que excede el límite superior del orden en dos nodos e inserte la clave mínima del nuevo nodo en el nodo principal del nodo principal.
Ajuste recursivo: si la división del nodo principal hace que el número de palabras clave del nodo ancestro exceda el límite superior del orden, la operación de división recursiva continuará hasta el nodo raíz.
División del nodo raíz: si la división del nodo raíz hace que la altura del árbol aumente, cree un nuevo nodo raíz y divida el nodo raíz original en dos nodos. Inserte la clave mínima del nuevo nodo raíz en el nuevo nodo raíz y ajuste la conexión del puntero.