prefacio
Después de aprender, explicamos los siete componentes de la página de datos de InnoDB. Sabemos que cada página de datos puede formar una lista enlazada bidireccional, y los registros en cada página de datos formarán una lista enlazada unidireccional en el orden de la clave principal. valores de pequeño a grande. Cada página de datos generará un directorio de páginas para los registros almacenados en él. Al buscar un registro a través de la clave principal, puede usar el método de dicotomía en el directorio de páginas para ubicar rápidamente la ranura correspondiente, y luego recorra el grupo correspondiente de la ranura.registros para encontrar rápidamente el registro especificado. Así que dibujamos un diagrama simple de la relación de la siguiente manera:
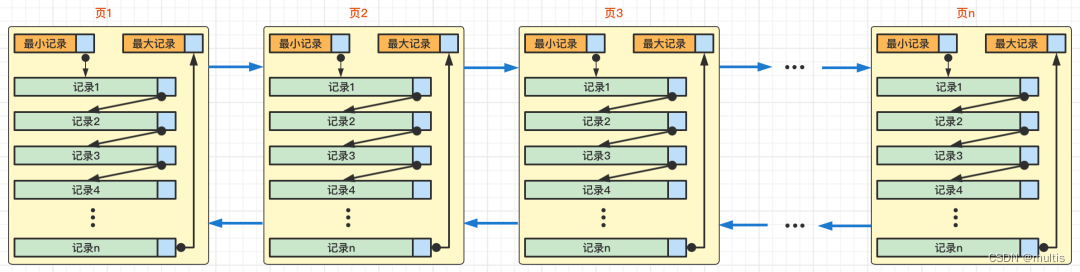
Donde página 1, página 2, página 3... página n estas páginas pueden no estar conectadas en una estructura física, sino que solo necesitan estar asociadas a través de una lista doblemente enlazada.
Siempre he escuchado que crear un índice para la base de datos puede mejorar el rendimiento de las consultas, pero ¿qué es un índice y cómo funciona?Hoy, aprendamos sobre el índice de árbol B+ del motor de almacenamiento InnoDB.
Tabla de contenido
- 1. Buscar sin índice
- 2. índice
- 3. Índice agrupado
- Cuarto, el índice secundario (Índice secundario)
- 5. Índice conjunto (índice compuesto)
- 6. Precauciones para el índice de árbol B+ de InnoDB
- Siete, una breve introducción al esquema de índices en MyISAM
- 8. Declaraciones para crear y eliminar índices en MySQL
- Nueve Resumen
1. Buscar sin índice
Antes de aprender formalmente el índice, debemos entender cómo encontrar registros cuando no hay índice. Para facilitar la comprensión, solo usamos la condición de búsqueda para hacer coincidir exactamente una columna determinada (coincidencia exacta significa que la condición de búsqueda es igual a = para conectar la expresión) como ejemplo, como la siguiente declaración:
select[列名列表] from 表名 where 列名 = xxx;
1.1 Buscar en una página
Sabemos que el tamaño de una página de datos es de 16 KB (16384 bytes), excepto que la información de metadatos necesaria en la página requiere una parte del espacio de almacenamiento, quedará mucho espacio para almacenar nuestros registros de usuario. Suponiendo que hay relativamente pocos registros en la tabla actual, todos los registros se pueden almacenar en una página. Al buscar registros, se puede dividir en dos situaciones según las diferentes condiciones de búsqueda:
-
La clave principal se utiliza como condición de búsqueda.
Utilice el método de dicotomía en el directorio de páginas para ubicar rápidamente el espacio correspondiente (Slot), y luego recorra los registros en el grupo correspondiente al espacio para encontrar rápidamente el registro especificado. -
Uso de otras columnas como criterio de búsqueda
El proceso de búsqueda de columnas de clave no primaria no es tan afortunado, porque no existe el llamado directorio de páginas para columnas de clave no primaria en la página de datos, por lo que no podemos ubicar rápidamente las ranuras correspondientes a través de el método de la dicotomía. En este caso, solo podemos recorrer cada registro en la lista enlazada de forma secuencial comenzando desde el registro más pequeño y luego comparar si cada registro cumple con los criterios de búsqueda. Obviamente, la eficiencia de esta búsqueda es muy baja.
1.2 Encontrar en muchas páginas
En la mayoría de los casos, hay muchos registros almacenados en nuestra tabla y se necesitan muchas páginas de datos para almacenar estos registros. La búsqueda de registros en muchas páginas se puede dividir en dos pasos:
- Navegue a la página donde se encuentra el registro.
- Encuentre el registro correspondiente de la página en la que se encuentra.
En ausencia de un índice, ya sea buscando en base a los valores de la columna de clave principal u otras columnas, dado que no podemos ubicar rápidamente la página donde se encuentra el registro, solo podemos buscar hacia abajo en la lista doblemente enlazada desde la primera página. En cada página, busque el registro especificado según el método de búsqueda del que acabamos de hablar. Debido a que se deben recorrer todas las páginas de datos, este método obviamente consume mucho tiempo. Si una tabla tiene 100 millones de registros, si usa este método para encontrar registros, tendrá que esperar hasta los años del mono para obtener los resultados de la búsqueda.
Entonces, el índice entra en juego.
2. índice
Para facilitar la visualización, primero creamos una tabla:
mysql> create table demo6(c1 int primary key,c2 int,c3 char(1)) row_format=compact;
Query OK, 0 rows affected (0.02 sec)
La tabla demo6 recién creada tiene 2 columnas de tipo int y 1 columna de tipo char(1), y estipulamos que la columna c1 es la clave principal. Esta tabla usa el formato de fila compacto para almacenar registros. Para facilitar la comprensión del índice, simplificamos el diagrama de formato de filas de la tabla demo6:
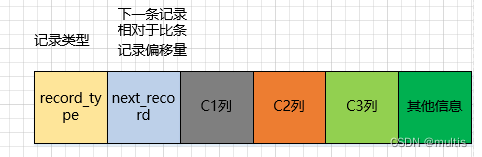
Repasemos el significado específico de estas partes mostradas:
- record_type: un atributo de la información del encabezado del registro, que indica el tipo de registro, 0 significa registro ordinario, 2 significa el registro más pequeño, 3 significa el registro más grande, 1 aún no lo hemos usado, hablaremos de eso pronto
- next_record: un atributo de la información del encabezado del registro, que indica el desplazamiento de la dirección de la siguiente dirección en relación con este registro. Para facilitar la comprensión, se utilizan flechas para indicar quién es el siguiente registro.
- El valor de cada columna: aquí solo se registran tres columnas en la tabla demo6, a saber, c1, c2 y c3
- Otra información: Toda la información excepto los 3 tipos de información anteriores, incluidos los valores de otras columnas ocultas e información adicional registrada.
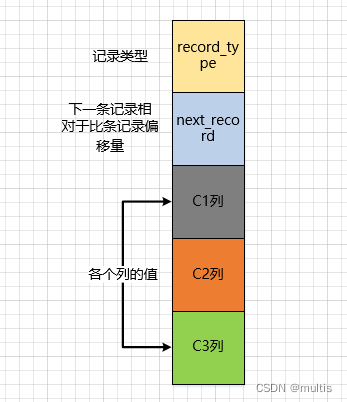
Hagamos algunos ajustes al diagrama nuevamente, eliminando otra información del diagrama de formato de registro y erigiéndolo.Este es el efecto:
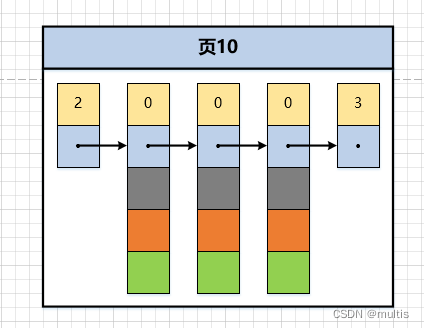
El diagrama esquemático de poner algunos registros en la página es el siguiente (ver el color para saber el significado):
2.1 Un esquema de indexación simple
Volviendo al tema, ¿por qué recorrer todas las páginas de datos al buscar algunos registros en función de una determinada condición de búsqueda? Debido a que los registros en cada página no son regulares, no sabemos qué registros en qué páginas coinciden nuestras condiciones de búsqueda, por lo que tenemos que recorrer todas las páginas de datos a la vez. Entonces, ¿qué sucede si queremos ubicar rápidamente en qué páginas de datos se encuentran los registros que necesitamos encontrar? ¿Recuerda el directorio de páginas que configuramos para ubicar rápidamente la posición de un registro en la página según el valor de la clave principal? También podemos encontrar una manera de crear otro directorio para ubicar rápidamente la página de datos donde se encuentra el registro.Para crear este directorio, se debe hacer lo siguiente:
Primero: el valor de la clave principal del registro de usuario en la siguiente página de datos debe ser mayor que el valor de la clave principal del registro de usuario en la página anterior
Necesitamos hacer una suposición aquí: suponga que cada una de nuestras páginas de datos puede almacenar hasta 3 registros (de hecho, una página de datos es muy grande y puede almacenar muchos registros). Con esta suposición, insertamos demo63 registros en la tabla:
mysql> insert into demo6 values(1, 4, 'u'), (3, 9, 'd'), (5, 3, 'y');
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
Luego, estos registros se han concatenado en una lista unidireccional según el tamaño del valor de la clave principal, como se muestra en la figura:
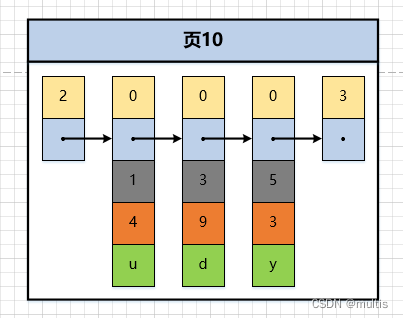
En la figura se puede ver que demo6los tres registros de la tabla se han insertado en la página de datos numerada 10. Ahora insertemos otro registro:
mysql> insert into demo6 values(4, 4, 'a');
Query OK, 1 row affected (0.01 sec)
La página 10 solo puede contener hasta 3 registros, por lo que tenemos que asignar una nueva página
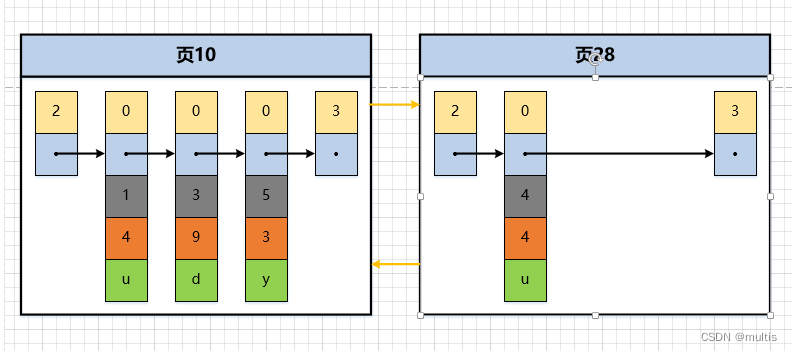
Los números de las páginas de datos recién asignadas pueden no ser consecutivos, lo que significa que las páginas que usamos pueden no estar una al lado de la otra en el espacio de almacenamiento. Solo establecen una relación de lista enlazada manteniendo los números de la página anterior y la página siguiente.
El valor de clave principal máximo del registro de usuario en la página 10 es 5, y el valor de clave principal de un registro en la página 28 es 4, porque 5 > 4, por lo que esto no cumple con el requisito de que el valor de clave principal del registro de usuario en la siguiente página de datos debe ser mayor que El requerimiento del valor de clave primaria del registro de usuario en la página anterior, por lo que al insertar el registro con el valor de clave primaria de 4, necesita ir acompañado de un movimiento de registro, es decir , el registro con el valor de clave principal de 5 se mueve a la página 28 y luego Inserte un registro con un valor de clave principal de 4 en la página 10. El diagrama esquemático de este proceso es el siguiente:
-
Mueva el registro con valor de clave principal 5 a la página 28
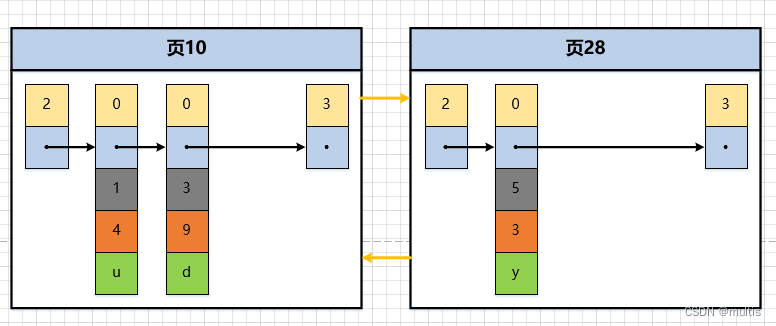
-
Inserte la clave principal 4 en la página 10

Este proceso muestra que en el proceso de agregar, eliminar y modificar registros en la página, siempre debemos asegurar este estado a través de algunas operaciones como el movimiento de registros: el valor de la clave principal del registro de usuario en la siguiente página de datos debe ser mayor que el anterior El valor de la clave principal del registro de usuario en la página. También podemos llamar a este proceso页分裂.
Segundo: Cree una entrada de directorio para todas las páginas
Dado que los números de las páginas de datos pueden no ser continuos, después demo6de insertar muchos registros en la tabla, el efecto puede ser el siguiente:
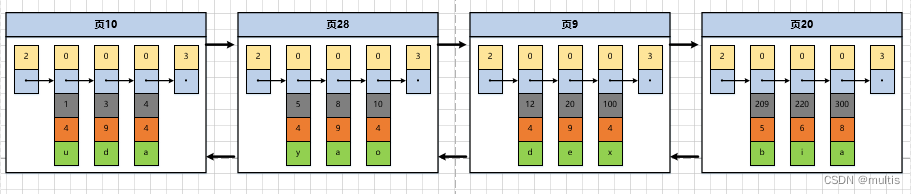
Debido a que estas páginas de 16 KB pueden no estar una al lado de la otra en el almacenamiento físico, si queremos ubicar rápidamente la página donde se encuentran algunos registros en función del valor de la clave principal de tantas páginas, debemos crear un directorio para ellos y cada página corresponde a un directorio Elementos, cada elemento del directorio incluye las siguientes dos partes:
- El valor de clave principal más pequeño en el registro de usuario de la página, lo
keydenotamos por - Número de página, lo
page_nodenotamos por
Entonces, el catálogo que hicimos en las páginas anteriores se ve así:
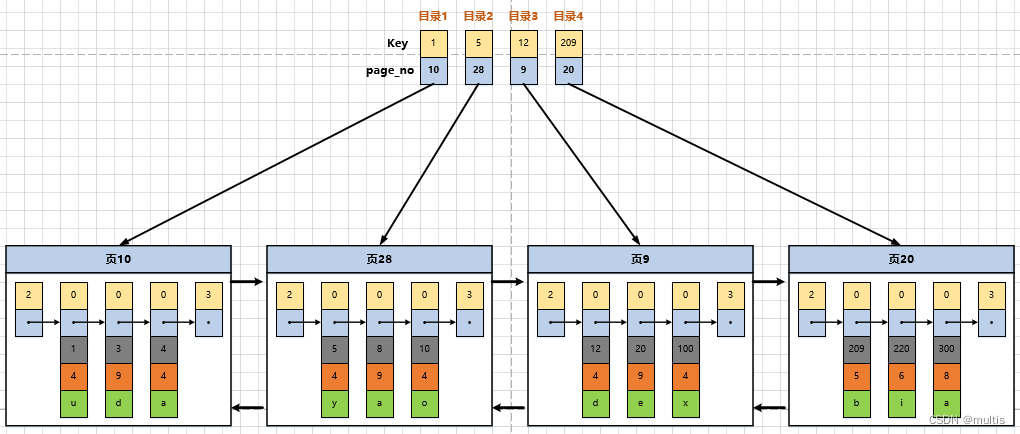
Tomando como ejemplo la página 28, corresponde al elemento de directorio 2, que contiene el número de página 28 de la página y el valor mínimo de clave primaria 5 de los registros de usuario en la página. Solo necesitamos almacenar varios elementos de directorio continuamente en la memoria física, por ejemplo, colocarlos en una matriz, y luego podemos realizar la función de buscar rápidamente un determinado registro de acuerdo con el valor de la clave principal. Por ejemplo, si queremos encontrar registros con un valor de clave principal de 20, el proceso de búsqueda específico se divide en dos pasos:
- Primero, determine rápidamente a partir de la entrada del directorio que el registro con un valor de clave principal de 20 está en la entrada del directorio 3 (porque 12<20<209), y su página correspondiente es la página 9.
- Luego vaya a la página 9 para ubicar el registro específico según el método de búsqueda de registros en la página mencionada anteriormente.
Hasta ahora, la tabla de contenido simple para la página de datos está lista. Este directorio tiene un alias llamado index.
2.2 Esquema de índice en InnoDB
La razón por la que lo anterior se denomina esquema de indexación simple es porque asumimos que todas las entradas del directorio se pueden almacenar continuamente en la memoria física para usar el método de dicotomía para ubicar rápidamente entradas de directorio específicas cuando se busca según el valor de la clave principal, pero esto tiene algunos problemas:
- InnoDB usa páginas como la unidad básica para administrar el espacio de almacenamiento, es decir, puede garantizar un espacio de almacenamiento continuo de hasta 16 KB, y a medida que aumenta la cantidad de registros en la tabla, se requiere un espacio de almacenamiento continuo muy grande para almacenar todo el directorio. entradas. , lo que no es realista para tablas con una gran cantidad de registros.
- A menudo agregamos y eliminamos registros. Supongamos que eliminamos todos los registros en la página 28, no hay necesidad de la página 28, lo que significa que no hay necesidad del elemento de directorio 2, que requiere el elemento de directorio Los elementos de directorio después de 2 se mueven todos adelante. Este tipo de diseño que afecta a todo el cuerpo no es una buena idea ~
Por lo tanto, InnoDB necesita una forma de administrar de manera flexible todas las entradas del directorio. Estas entradas de directorio en realidad se parecen a nuestros registros de usuario, excepto que las dos columnas en las entradas de directorio son claves principales y números de página, por lo que reutilizan las páginas de datos que previamente almacenaron registros de usuario para almacenar entradas de directorio. a estos registros utilizados para representar entradas de directorio como registros de entrada de directorio. Entonces, ¿cómo distingue InnoDB si un registro es un registro de usuario ordinario o un registro de entrada de directorio? No olvide registrar los atributos en la información del encabezado record_type. Los significados de cada valor son los siguientes:
0:registro de usuario normal1:registro de entrada de directorio2:registro mínimo3:récord más grande
¿Entiendes el significado del valor record_type de 1? El diagrama esquemático de colocar los elementos del directorio que usamos anteriormente en la página de datos es el siguiente:
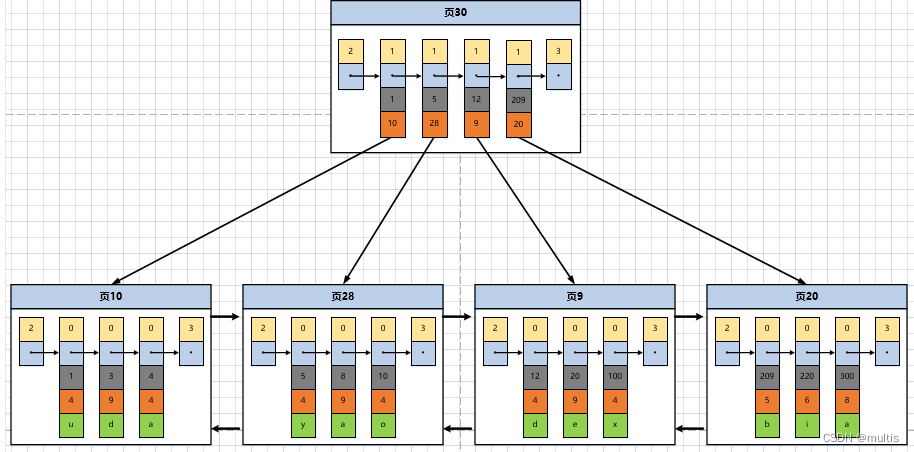 Como se puede ver en la figura, recientemente asignamos una página con el número 30 para almacenar registros de entrada de directorio. Aquí nuevamente, se enfatiza la diferencia entre los registros de entrada de directorio y los registros de usuario ordinarios:
Como se puede ver en la figura, recientemente asignamos una página con el número 30 para almacenar registros de entrada de directorio. Aquí nuevamente, se enfatiza la diferencia entre los registros de entrada de directorio y los registros de usuario ordinarios:
- El valor record_type de los registros de entrada de directorio es 1, mientras que el valor record_type de los registros de usuario ordinarios es 0
- Los registros de entrada de directorio solo tienen dos columnas, el valor de la clave principal y el número de página, mientras que las columnas de los registros de usuario ordinarios están definidas por el usuario y pueden contener muchas columnas. Además, hay columnas ocultas agregadas por InnoDB.
- ¿Aún recuerda que cuando hablábamos de la información del encabezado del registro, dijimos que hay un atributo llamado ?Solo el valor min_rec_mask del registro de entrada de directorio con el valor de clave principal más pequeño en la página que almacena el registro de entrada de directorio es 1, y el valor
min_rec_maskde otros registros esmin_rec_mask
Excepto por los puntos anteriores, no hay diferencia entre los dos. Usan la misma página de datos (el tipo de página es 0x45bf), y la estructura de la página también es la misma, y ambos generarán un directorio de páginas para el valor de clave principal (directorio de página) para que la dicotomía se pueda usar para acelerar las consultas al buscar por valor de clave principal. Ahora tome como ejemplo la búsqueda de un registro con una clave principal de 20. Los pasos para encontrar un registro basado en un cierto valor de clave principal se pueden dividir aproximadamente en los siguientes dos pasos:
- Primero vaya a la página donde se encuentra el registro de la entrada del directorio, es decir, la página 30 localiza rápidamente la entrada del directorio correspondiente a través del método de dicotomía, porque 12<20<209, entonces la página donde se encuentra el registro correspondiente es la página 9
- Vaya a la página 9 donde se almacenan los registros de usuario y ubique rápidamente los registros de usuario con un valor de clave principal de 20 según la dicotomía
Aunque solo el valor de la clave principal y el número de página correspondiente se almacenan en el registro de entrada de directorio, que es mucho más pequeño que el espacio de almacenamiento requerido por el registro de usuario, de todos modos, una página tiene solo 16 KB de tamaño y la entrada de directorio registra eso se pueden almacenar también son limitadas.Si hay demasiados datos en la tabla, por lo que una página de datos no es suficiente para almacenar todos los registros de entrada del directorio, ¿qué debo hacer?
Por supuesto, hay una página más para almacenar registros de entrada de directorio ~ Para comprender mejor el proceso de asignación de una nueva página de registro de entrada de directorio, asumimos que una página para almacenar registros de entrada de directorio solo puede almacenar hasta 4 registros de entrada de directorio ( tenga en cuenta que es una suposición, puede almacenar muchas entradas en la situación real), por lo que si insertamos un registro de usuario con un valor de clave principal de 320 en la imagen superior en este momento, entonces debemos asignar un nuevo página para almacenar registros de entrada de directorio. :
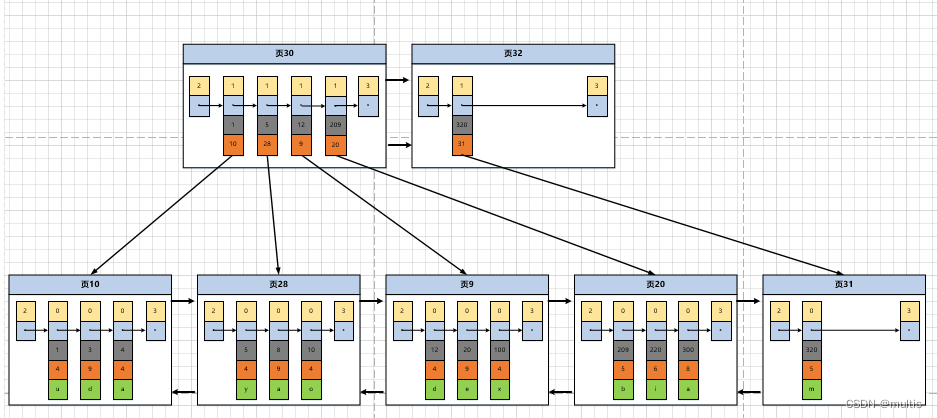
Como se puede ver en la figura, necesitamos dos nuevas páginas de datos después de insertar un registro de usuario con un valor de clave principal de 320:
- La página 31 se creó recientemente para almacenar este registro de usuario
- Debido a que la capacidad de la página 30 que originalmente almacenó registros de entradas de directorio está llena (asumimos que solo se pueden almacenar 4 registros de entradas de directorio), se necesita una nueva página 32 para almacenar la entrada de directorio correspondiente a la página 31
Ahora, debido a que hay más de una página para almacenar registros de entrada de directorio, si queremos encontrar un registro de usuario basado en el valor de la clave principal, toma alrededor de 3 pasos.Tome la búsqueda de un registro con un valor de clave principal de 20 como un ejemplo:
- Determine la página de registro de entrada de directorio, ahora tenemos dos páginas para almacenar registros de entrada de directorio, a saber, la página 30 y la página 32, y debido a que el rango del valor de clave principal de la entrada de directorio representada por la página 30 es [1, 320), página 32 representa El valor de clave principal de la entrada de directorio no es inferior a 320, por lo que la entrada de directorio correspondiente al registro con el valor de clave principal de 20 se registra en la página 30
- Determinar la página donde se encuentra realmente el registro de usuario a través de la página de registro de elementos del directorio
- Ubique registros específicos en la página que realmente almacena registros de usuarios
Aquí viene el problema. En el primer paso de esta consulta, necesitamos ubicar las páginas que almacenan registros de entrada de directorio, pero es posible que estas páginas no estén una al lado de la otra en el espacio de almacenamiento. Si hay muchos datos en nuestro tabla, se generarán muchos directorios de almacenamiento página de registro de elementos, ¿cómo localizamos rápidamente una página que almacena registros de elementos de directorio en función del valor de la clave principal? De hecho, también es simple. Se genera un directorio más avanzado para estas páginas que almacenan registros de elementos de directorio, al igual que un directorio de varios niveles. Los directorios pequeños se anidan en directorios grandes, y los datos reales están en los directorios pequeños. Así que ahora cada página El esquema se ve así:
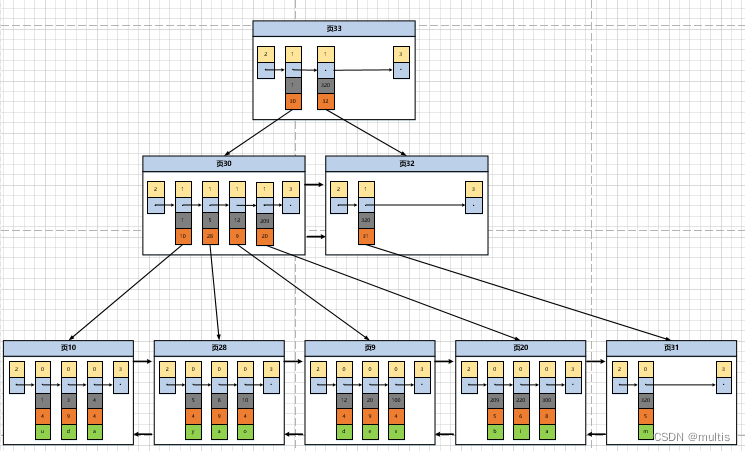
Como se muestra en la figura, hemos generado una página 33 que almacena elementos de directorio de nivel superior. Los dos registros en esta página representan la página 30 y la página 32 respectivamente. Si el valor de clave principal del registro de usuario está entre [1, 320) , luego vaya a la página 30 para encontrar registros de entrada de directorio más detallados, si el valor de la clave principal no es inferior a 320, vaya a la página 32 para encontrar registros de entrada de directorio más detallados. A medida que aumentan los registros en la tabla, la jerarquía de este directorio seguirá aumentando. ¡Esta imagen no es como un árbol al revés, con raíces en la parte superior y hojas en la parte inferior! De hecho, esta es una forma de organizar datos, o una estructura de datos, y su nombre es árbol B+.
Ya sea una página de datos que almacene registros de usuarios o una página de datos que almacene registros de elementos de directorio, los hemos almacenado en la estructura de datos del árbol B+, por lo que también llamamos a estas páginas de datos nodos. Como se puede ver en la figura, nuestros registros de usuario reales se almacenan en los nodos inferiores del árbol B. Estos nodos también se denominan, y el resto de los nodos utilizados para almacenar elementos del directorio se denominan , entre los cuales la parte superior 叶子节点或叶节点del 非叶子节点或者内节点árbol El árbol B+ también se conoce como nodo 根节点.
Se puede ver en la figura que los nodos de un árbol B+ en realidad se pueden dividir en varias capas. Para facilitar la discusión, InnoDB estipula que la capa inferior, es decir, la capa donde se almacenan nuestros registros de usuario, es la 0. capa, y luego se suman secuencialmente. En el entorno real, la cantidad de registros almacenados en una página es muy grande. Suponga, suponiendo, suponiendo que todas las páginas de datos representadas por nodos hoja que almacenan registros de usuario pueden almacenar 100 registros de usuario, y todas las páginas de datos representadas por nodos internos que almacenan directorios registros de entrada pueden Para almacenar 1000 registros de entrada de directorio, entonces: 如果B+树有4层,最多能存放1000×1000×1000×100=100000000000registros. Entonces, en circunstancias normales, el árbol B+ que usamos no excederá las 4 capas, entonces solo necesitamos hacer una búsqueda en 4 páginas como máximo para encontrar un registro a través del valor de la clave principal (buscar 3 páginas de elementos de directorio y una página de registro de usuario) , y debido a que hay un llamado directorio de páginas (page directory) en cada página, también es posible localizar rápidamente registros en la página a través de la dicotomía. Es por eso que los índices pueden acelerar las consultas.
3. Índice agrupado
El árbol B+ que presentamos arriba es en sí mismo un directorio, o un índice en sí mismo. Tiene dos características:
-
Use el tamaño del valor de la clave principal del registro para ordenar registros y páginas, lo que incluye tres significados:
- Los registros en la página se organizan en una lista enlazada unidireccional en el orden del tamaño de la clave principal
- Cada página que almacena registros de usuario también se organiza en una lista doblemente vinculada según el orden del tamaño de la clave principal de los registros de usuario en la página.
- Las páginas que almacenan los registros de entrada de directorio se dividen en diferentes niveles, y las páginas en el mismo nivel también se organizan en una lista doblemente enlazada según el orden del tamaño de la clave principal de los registros de entrada de directorio en la página.
-
Los nodos hoja del árbol B+ almacenan registros de usuario completos
El llamado registro de usuario completo significa que los valores de todas las columnas (incluidas las columnas ocultas) se almacenan en este registro
Llamamos al árbol B+ con estas dos características un índice agrupado, y todos los registros de usuario completos se almacenan en los nodos hoja de este índice agrupado. Este índice agrupado no requiere que usemos explícitamente la declaración de índice en la declaración de MySQL para crear, el motor de almacenamiento InnoDB creará automáticamente un índice agrupado para nosotros. Otro punto interesante es que en el motor de almacenamiento InnoDB, el índice agrupado es el método de almacenamiento de datos (todos los registros de usuario se almacenan en los nodos hoja), es decir, el llamado índice son los datos y los datos son el índice.
Cuarto, el índice secundario (Índice secundario)
El índice agrupado solo puede funcionar cuando la condición de búsqueda es el valor de la clave principal, porque los datos en el árbol B+ se ordenan según la clave principal. Entonces, ¿qué pasa si queremos usar otras columnas como criterios de búsqueda? ¿Solo es posible recorrer los registros secuencialmente a lo largo de la lista enlazada de principio a fin?
No, podemos construir varios árboles B+ más, y los datos en diferentes árboles B+ adoptan diferentes reglas de clasificación. Por ejemplo, usamos el tamaño de la columna c2 como la regla de clasificación de la página de datos y los registros en la página, y luego construimos un árbol B+, el efecto se muestra en la siguiente figura:
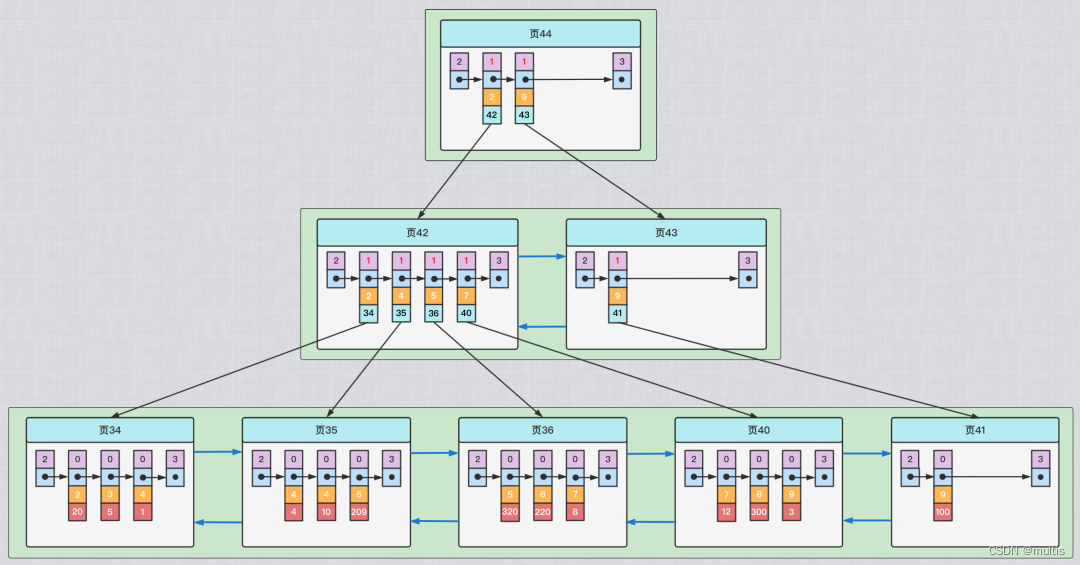
Este árbol B+ tiene varias diferencias con el índice agrupado presentado anteriormente:
-
Use el tamaño de la columna del registro c2 para ordenar registros y páginas, que incluye tres significados:
- Los registros de la página se organizan en una lista enlazada unidireccional en el orden del tamaño de la columna c2
- Cada página que almacena registros de usuario también se organiza en una lista doblemente enlazada de acuerdo con el tamaño de la columna c2 registrada en la página.
- Las páginas que almacenan los registros de entrada de directorio se dividen en diferentes niveles, y las páginas en el mismo nivel también se organizan en una lista doblemente enlazada según el orden del tamaño de columna c2 de los registros de entrada de directorio en la página.
-
Los nodos de hoja del árbol B+ no almacenan registros de usuario completos, sino solo los valores de las dos columnas c2 + clave principal.
-
El registro del elemento del directorio ya no es la combinación de la clave principal + el número de página, sino la combinación de la columna c2 + el número de página.
Entonces, si ahora queremos encontrar algunos registros a través del valor de la columna c2, podemos usar el árbol B+ que acabamos de crear. Tomemos como ejemplo la búsqueda del registro cuyo valor es 4 en la columna c2, el proceso de búsqueda es el siguiente:
Entonces, si ahora queremos encontrar algunos registros a través del valor de la columna c2, podemos usar el árbol B+ que acabamos de crear. Tomemos como ejemplo la búsqueda del registro cuyo valor es 4 en la columna c2, el proceso de búsqueda es el siguiente:
-
Determinar la página de registro de entrada de directorio
De acuerdo con la página raíz, es decir, la página 44, puede ubicar rápidamente la página donde se encuentra el registro de entrada de directorio como página 42 (porque 2<4<9) -
De acuerdo con la página raíz, es decir, la página 33, se puede ubicar rápidamente que la página donde se encuentra el registro de entrada del directorio es la página 30.
-
Utilice la página de registro de entrada de directorio para determinar la página donde reside realmente el registro de usuario.
En la página 42, la página que realmente almacena los registros de usuario se puede ubicar rápidamente, pero dado que no existe una restricción única en la columna c2, los registros cuyo valor es 4 en la columna c2 se pueden distribuir en varias páginas de datos, y debido a que 2< 4≤4, así que asegúrese de que las páginas que realmente almacenan registros de usuarios estén en las páginas 34 y 35 -
Localice un registro específico en la página que realmente almacena registros de usuarios.
Vaya a la página 34 y la página 35 para localizar el registro específico -
Sin embargo, los registros en los nodos hoja de este árbol B+ solo almacenan dos columnas, c2 y c1 (es decir, la clave principal), por lo que debemos buscar el registro de usuario completo nuevamente en el índice agrupado de acuerdo con el valor de la clave principal.
Solo podemos determinar el valor de la clave principal del registro que estamos buscando según el árbol B+ ordenado por el tamaño de la columna c2, por lo que si queremos encontrar el registro de usuario completo según el valor de la columna c2, todavía necesita verificarlo nuevamente en el índice agrupado, este proceso también se llama 回表. Es decir, consultar un registro de usuario completo basado en el valor de la columna c2 necesita usar 2 árboles B+.
Sugerencia:
si coloca los registros de usuario completos en los nodos hoja, no necesita devolver la tabla, pero ocupa demasiado espacio ~ Es equivalente a copiar todos los registros de usuario cada vez que construye un árbol B+, que es un poco demasiado desperdicio de espacio de almacenamiento. Debido a que este tipo de árbol B+ construido de acuerdo con la columna de clave no principal necesita una operación de retorno de tabla para ubicar el registro de usuario completo, este tipo de árbol B+ también se denomina índice secundario (nombre en inglés Índice secundario) o índice auxiliar. Dado que usamos el tamaño de la columna c2 como la regla de clasificación del árbol B+, también llamamos a este árbol B+ el índice creado para la columna c2.
5. Índice conjunto (índice compuesto)
También podemos usar el tamaño de varias columnas como regla de ordenación al mismo tiempo, es decir, crear índices para varias columnas al mismo tiempo. Por ejemplo, queremos que el árbol B+ se ordene según el tamaño de c2 y c3 columnas Esto contiene dos significados:
- Primero ordene cada registro y página según la columna c2.
- Cuando la columna c2 de los registros es la misma, la columna c3 se usa para ordenar.
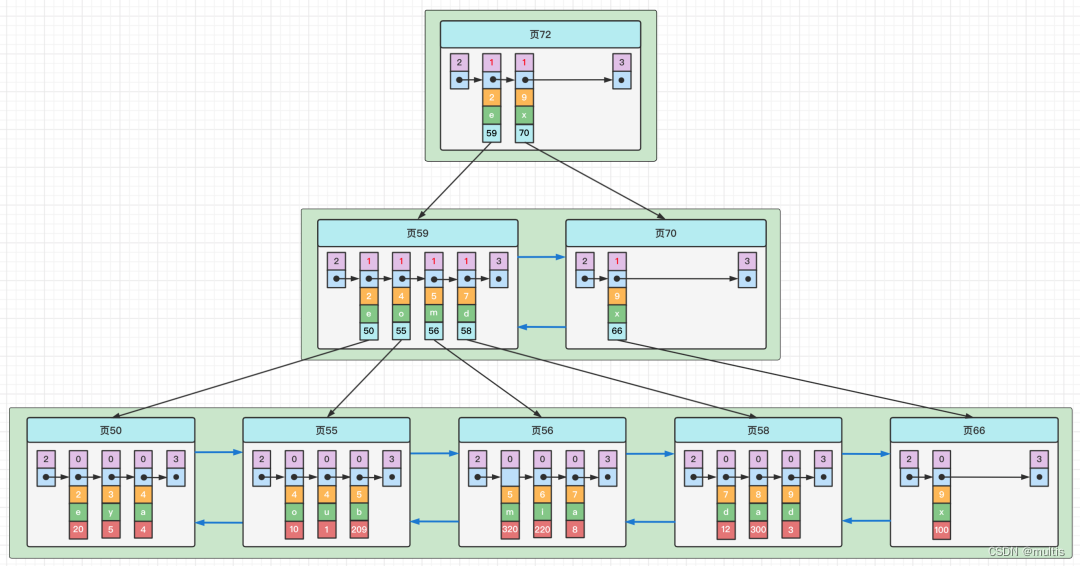
Como se muestra en la figura, debemos prestar atención a los siguientes puntos:
-
Cada registro de entrada de directorio consta de tres partes: c2, c3 y número de página. Cada registro se ordena primero según el valor de la columna c2. Si los registros de la columna c2 son iguales, se ordenan según el valor de la columna c3. .
-
El registro de usuario en el nodo hoja del árbol B+ consta de las columnas c2, c3 y la clave principal c1.
Debe tenerse en cuenta que el árbol B+ creado con el tamaño de las columnas c2 y c3 como regla de clasificación se denomina índice conjunto, que es esencialmente un índice secundario. Su significado es diferente a la expresión de índices de construcción para las columnas c2 y c3 respectivamente, las diferencias son las siguientes:
- Construir un índice conjunto solo creará un árbol B+ como se muestra en la figura anterior.
- La creación de índices para las columnas c2 y c3 respectivamente creará dos árboles B+ con el tamaño de las columnas c2 y c3 como reglas de clasificación
6. Precauciones para el índice de árbol B+ de InnoDB
6.1 La página raíz nunca se mueve
Cuando introdujimos el índice del árbol B+ anteriormente, para la conveniencia de la comprensión de todos, primero dibuje los nodos de hoja que almacenan registros de usuario y luego dibuje los nodos internos que almacenan registros de elementos de directorio. De hecho, el proceso de formación del árbol B+ es como sigue:
-
Cada vez que se crea un índice de árbol B+ para una tabla (el índice agrupado no se crea artificialmente, existe de manera predeterminada), se creará una página de nodo raíz para este índice. Cuando no hay datos en la tabla al principio, no hay registro de usuario ni registro de elemento de directorio en el nodo raíz correspondiente a cada índice de árbol B+.
-
Cuando inserte registros de usuario en la tabla más tarde, primero almacene los registros de usuario en este nodo raíz.
-
Cuando se agote el espacio libre en el nodo raíz, continúe insertando registros. En este momento, todos los registros en el nodo raíz se copiarán en una página recién asignada, como la página a, y luego la nueva página se dividirá en obtener otra Una nueva página, digamos página b. En este momento, los registros recién insertados se asignarán a la página a o a la página b según el tamaño del valor de la clave (es decir, el valor de la clave principal en el índice agrupado, el valor de la columna de índice correspondiente en el índice secundario) , y el nodo raíz será Páginas promovidas para almacenar registros de entrada de catálogo.
Este proceso requiere que todos presten especial atención a: el nodo raíz de un índice de árbol B+ no se moverá desde su nacimiento. De esta manera, siempre que creemos un índice para una tabla, el número de página de su nodo raíz se registrará en algún lugar y luego, cuando el motor de almacenamiento InnoDB necesite usar este índice, sacará el nodo raíz de ese fijo. lugar para acceder al índice.
Sugerencia:
La información en qué página se almacena el nodo raíz de un determinado índice es un elemento de información en el diccionario de datos legendario. Más detalles sobre el contenido del diccionario de datos se explicarán en detalle más adelante.
6.2 Unicidad de registros de entrada de directorio en nodos internos
Sabemos que el contenido del registro de entrada de directorio en el nodo interno del índice de árbol B+ es la combinación de columna de índice + número de página, pero esta combinación es un poco imprecisa para el índice secundario. También tome demo6la tabla como ejemplo, asumiendo que los datos en esta tabla son así:
| c1 | c2 | c3 |
|---|---|---|
| 1 | 1 | 'tú' |
| 3 | 1 | 'd' |
| 5 | 1 | 'y' |
| 7 | 1 | 'a' |
Si el contenido del registro de entrada de directorio en el índice secundario es solo la combinación de la columna de índice + el número de página, entonces el árbol B+ después de indexar la columna c2 debería verse así:
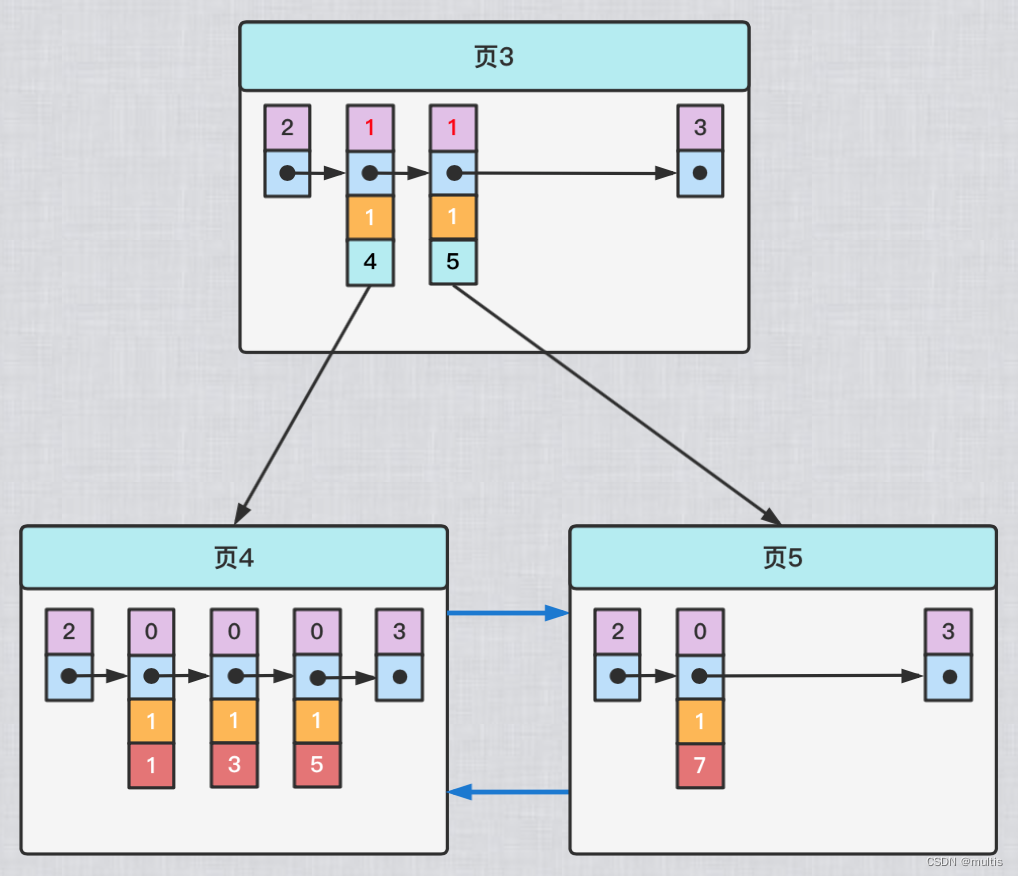
Si queremos insertar una nueva fila de registros, donde los valores de c1, c2 y c3 son: 9, 1 y 'c' respectivamente, entonces nos encontramos con un gran problema al modificar el árbol B+ correspondiente al secundario. índice establecido para la columna c2: dado que el registro de entrada de directorio almacenado en la página 3 se compone del valor de la columna c2 + número de página, los valores de la columna c2 correspondientes a los dos registros de entrada de directorio en la página 3 son ambos 1, y el registro recién insertado El valor de la columna c2 también es 1, entonces, ¿nuestro registro recién insertado debe colocarse en la página 4 o debe colocarse en la página 5? La respuesta es: lo siento, confundido.
Para que el registro recién insertado se encuentre en esa página, debemos asegurarnos de que el registro de entrada de directorio del nodo en el mismo nivel del árbol B+ sea único, excepto por el campo de número de página. Por lo tanto, el contenido registrado en la entrada de directorio del nodo interno del índice secundario en realidad se compone de tres partes:
- el valor de la columna indexada
- valor de la clave principal
- número de página
Es decir, también agregamos el valor de la clave principal al registro de entrada de directorio en el nodo del índice secundario, de modo que podamos asegurarnos de que cada registro de entrada de directorio en cada capa del nodo de árbol B+ sea único excepto por el campo de número de página, por lo que el diagrama esquemático después de establecer el índice secundario para la columna c2 debería verse así:
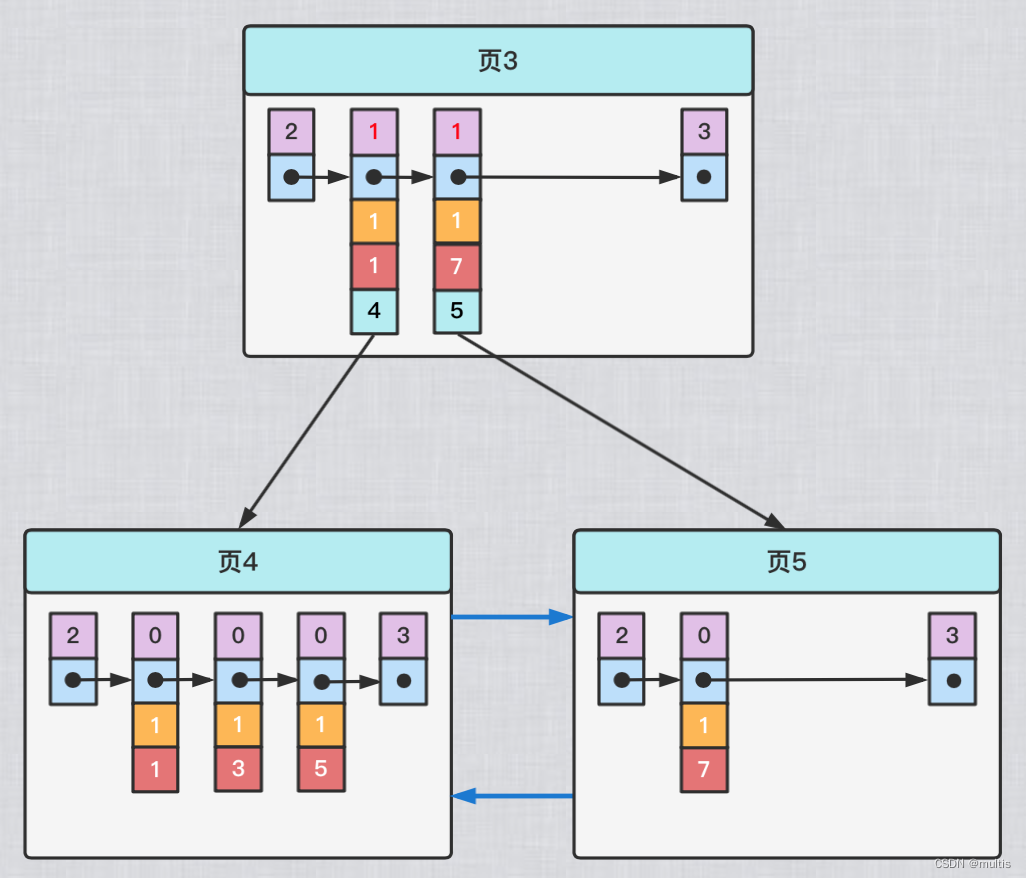
De esta forma, cuando insertamos el registro (9, 1, 'c'), dado que el registro de entrada de directorio almacenado en la página 3 está compuesto por el valor de la columna c2 + clave principal + número de página, primero podemos combinar el valor de columna c2 del nuevo registro con Compare los valores de la columna c2 de cada entrada de directorio en la página 3. Si los valores de la columna c2 son los mismos, puede comparar los valores de la clave principal, porque los valores de la columna c2 + clave primaria de diferentes entradas de directorio en la misma capa del árbol B+ debe ser diferente, igual, por lo que el único registro de entrada de directorio se puede ubicar al final, en este caso, finalmente se determina que el nuevo registro debe insertarse en la página 5.
6.3 Una página almacena al menos 2 registros
Dijimos anteriormente que un árbol B+ puede almacenar fácilmente cientos de millones de registros con solo unos pocos niveles, ¡y la velocidad de consulta es rápida! Esto se debe a que el árbol B+ es esencialmente un gran directorio de varios niveles, y muchos subdirectorios no válidos se filtran cada vez que se pasa un directorio, hasta que finalmente se accede al directorio que almacena datos reales. Entonces, ¿cuál es el efecto si solo se almacena un subdirectorio en un directorio grande? Es decir, hay muchísimos niveles de directorio, y solo se puede almacenar un registro en el último directorio que almacena datos reales. ¿Tomó mucho tiempo almacenar solo un registro de usuario real? ¿Me estás tomando el pelo? Por lo tanto, una página de datos de InnoDB puede almacenar al menos dos registros.Esta es también una conclusión que dijimos cuando presentamos el formato de fila de registros.
Siete, una breve introducción al esquema de índices en MyISAM
Ahora, presentemos brevemente el esquema de indexación en el motor de almacenamiento MyISAM. Sabemos que el índice en InnoDB son los datos, es decir, todos los registros de usuario completos se han incluido en los nodos hoja del árbol B+ del índice agrupado, mientras que el esquema de índice MyISAM también utiliza una estructura de árbol, pero el índice y Los datos se almacenan por separado:
-
Los registros de la tabla se almacenan por separado en un archivo según el orden de inserción de los registros, que se denomina archivo de datos (archivo .MYD en el disco). Este archivo no está dividido en varias páginas de datos, ya que hay muchos registros en este archivo. Podemos acceder rápidamente a un registro por número de línea.
Los registros de MyISAM también necesitan información de encabezado de registro para almacenar algunos datos adicionales.Tomemos la tabla mencionada anteriormente
demo6como ejemplo y veamos cómo los registros de esta tabla usan MyISAM como motor de almacenamiento en el espacio de almacenamiento: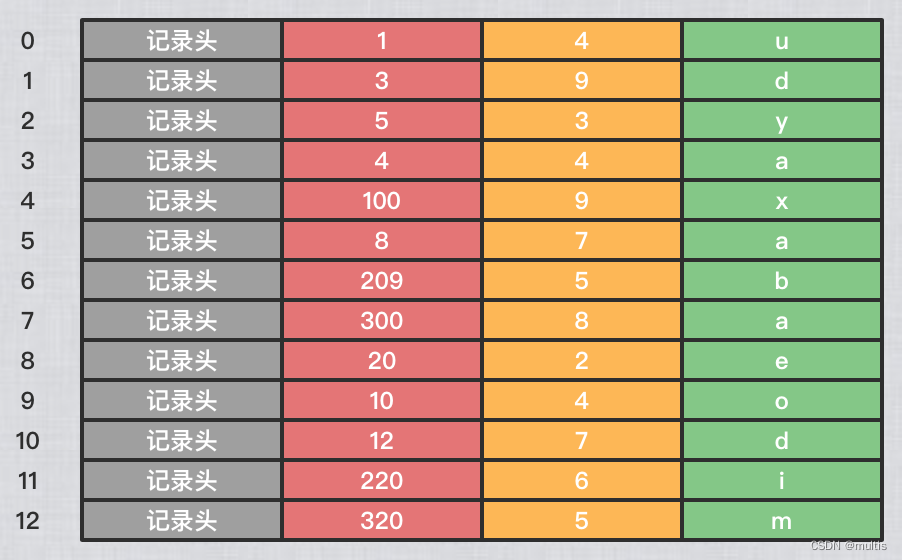
Dado que los datos no se ordenan deliberadamente según el tamaño de la clave principal al insertar datos, no podemos utilizar el método de dicotomía para buscar estos datos. -
Las tablas que utilizan el motor de almacenamiento MyISAM también almacenan información de índice en otro archivo denominado archivo de índice (archivo .MYI en el disco). MyISAM creará un índice para la clave principal de la tabla por separado, pero lo que se almacena en el nodo hoja del índice no es un registro de usuario completo, sino una combinación de valor de clave principal + número de fila. Es decir, primero busque el número de fila correspondiente a través del índice y luego busque el registro correspondiente a través del número de fila.
Esto es completamente diferente de InnoDB.En el motor de almacenamiento de InnoDB, solo necesitamos buscar el índice agrupado en función del valor de la clave principal para encontrar el registro correspondiente, pero en MyISAM, debemos realizar una operación de tabla de retorno, lo que significa que los índices establecidos en MyISAM son equivalentes a todos los índices secundarios!
-
Si es necesario, también podemos crear índices separados o índices conjuntos para otras columnas. El principio es similar al índice en InnoDB, pero el número de columna + fila correspondiente se almacena en el nodo hoja. Estos índices también son todos índices secundarios.
Sugerencia:
Los formatos de fila de MyISAM incluyen formato de registro de longitud fija (Static), formato de registro de longitud variable (Dynamic) y formato de registro comprimido (Compressed). La tabla utilizada anteriormentedemo6adopta el formato de registro de longitud fija, es decir, el tamaño del espacio de almacenamiento ocupado por un registro es fijo, de modo que el desplazamiento de dirección de un determinado registro en el archivo de datos se puede calcular fácilmente. Pero el formato de registro de longitud variable no funciona.MyISAM almacenará directamente el desplazamiento de la dirección del registro en el archivo de datos en el nodo hoja de índice. Se puede ver a partir de esto que la operación de retorno de tabla de MyISAM es muy rápida, porque obtiene datos directamente del archivo con la dirección compensada. En contraste, InnoDB busca registros en el índice agrupado después de obtener la clave principal. Aunque no es lento para decir, pero aún no es tan bueno como usar directamente la dirección para acceder. Espero que entienda que el índice en InnoDB son los datos y los datos son el índice, pero en MyISAM, el índice es el índice y los datos son los datos.
8. Declaraciones para crear y eliminar índices en MySQL
Condescendientemente para aprender el principio de la indexación, ¿cómo usamos las declaraciones de MySQL para construir este tipo de índice? InnoDB y MyISAM tomarán la iniciativa de crear un índice de árbol B+ para la clave principal o la columna declarada como ÚNICA, pero si queremos crear un índice para otras columnas, debemos especificarlo explícitamente. ¿Por qué no crear automáticamente un índice para cada columna? No olvide, cada vez que se crea un índice, se construye un árbol B+, y cada vez que se inserta un registro, se debe mantener la relación de clasificación de cada registro y página de datos, lo que consume mucho rendimiento y espacio de almacenamiento.
Podemos especificar una sola columna para indexar o varias columnas para indexar al crear una tabla:
create talbe 表名 (
各种列的信息 ··· ,
[key|index] 索引名 (需要被索引的单个列或多个列)
)
Consejo:
clave e índice son sinónimos, puede elegir cualquiera
También podemos agregar índices al modificar la estructura de la tabla:
alter table 表名 add [index|key] 索引名 (需要被索引的单个列或多个列);
También puede eliminar el índice al modificar la estructura de la tabla:
alter table 表名 drop [index|key] 索引名;
Por ejemplo, si queremos agregar un índice conjunto a las columnas c2 y c3 al crear la tabla index_demo, podemos escribir la declaración de creación de la tabla de la siguiente manera:
create table demo7(
c1 int,
c2 int,
c3 char(1),
primary key(c1),
index idx_c2_c3(c2,c3)
);
El nombre del índice que creamos en esta declaración de creación de tablas es idx_c2_c3, que puede nombrarse a voluntad, pero aún así recomendamos agregarle el prefijo idx_, seguido de los nombres de las columnas que deben indexarse, y los nombres de varias columnas están separados por guiones bajos _. abierto.
Si queremos borrar este índice, podemos escribir así:
alter table demo7 drop index idx_c2_c3;
Si queremos consultar el índice
show index from 表名;
Nueve Resumen
Hay mucho contenido hoy en día, vamos a resumir brevemente:
-
Cada índice corresponde a un árbol B+, el árbol B+ se divide en varias capas, la capa inferior es el nodo hoja y el resto son nodos internos. Todos los registros de usuario se almacenan en los nodos de hoja del árbol B+ y todos los registros de entrada de directorio se almacenan en los nodos internos.
-
El motor de almacenamiento InnoDB creará automáticamente un índice agrupado para la clave principal (si no, se agregará automáticamente para nosotros), y los nodos de hoja del índice agrupado contienen registros de usuario completos.
-
Podemos crear un índice secundario para las columnas que nos interesan. Los registros de usuario contenidos en los nodos de hoja del índice secundario están compuestos por columnas de índice + claves primarias, por lo que si queremos encontrar registros de usuario completos a través del índice secundario, debemos necesita volver a la tabla. , es decir, después de encontrar el valor de la clave principal a través del índice secundario, se busca el registro de usuario completo en el índice agrupado.
-
Cada capa de nodos en el árbol B+ se clasifica de acuerdo con el orden de los valores de las columnas de índice de menor a mayor para formar una lista doblemente enlazada, y los registros en cada página (ya sean registros de usuario o registros de entrada de directorio) se clasifican de acuerdo con los valores de la columna de índice de pequeño a grande El orden grande forma una lista enlazada individualmente. Si se trata de un índice conjunto, las páginas y los registros se ordenan primero según la columna que se encuentra delante del índice conjunto, y si los valores de las columnas son iguales, se ordenan según la columna que se encuentra detrás del índice conjunto.
-
La búsqueda de registros a través del índice comienza desde el nodo raíz del árbol B+ y busca hacia abajo capa por capa. Dado que cada página establece el Page Directory (directorio de páginas) según el valor de la columna de índice, la búsqueda en estas páginas es muy rápida.
-
MyISAM creará un índice para la clave principal de la tabla por separado, pero lo que se almacena en el nodo hoja del índice no es un registro de usuario completo, sino una combinación de valor de clave principal + número de fila. En el motor de almacenamiento InnoDB, solo necesitamos buscar el índice agrupado una vez de acuerdo con el valor de la clave principal para encontrar el registro correspondiente, pero en MyISAM, necesitamos realizar una operación de tabla de retorno, lo que significa que los índices establecidos en MyISAM son equivalentes a todos es un índice secundario.
-
Precauciones para el índice de árbol B+ de InnoDB:
-
La página raíz nunca se anida;
-
El registro de entrada de directorio en el nodo interno es único;
-
Una página almacena al menos 2 registros.
-
-
El índice en InnoDB son los datos y los datos son el índice, mientras que en MyISAM el índice es el índice y los datos son los datos.
Hoy aprendimos sobre el índice de árbol B+ de InnoDB, conoce su estructura y principio de funcionamiento, el artículo de hoy es muy muy importante
Hasta ahora, el estudio de hoy ha terminado, espero que te conviertas en un yo indestructible
~~~
No puedes conectar los puntos mirando hacia adelante; solo puedes conectarlos mirando hacia atrás. Así que tienes que confiar en que los puntos se conectarán de alguna manera en tu futuro. Tienes que confiar en algo: tu instinto, destino, vida, karma, lo que sea. Este enfoque nunca me ha defraudado y ha marcado una gran diferencia en mi vida.
Si mi contenido te es útil, por favor 点赞, 评论,, 收藏la creación no es fácil, el apoyo de todos es la motivación para que yo persevere
