Introducción
El aprendizaje conjunto es un método de aprendizaje automático que tiene como objetivo mejorar la precisión general de la predicción combinando las predicciones de varios alumnos individuales (llamados clasificadores base o alumnos base).
El aprendizaje conjunto puede verse como un método en el que "varias personas trabajan juntas para hacer cosas". Cada clasificador base es un alumno independiente que se entrena con datos de entrenamiento y produce una predicción. Estos clasificadores base pueden utilizar diferentes algoritmos, diferentes configuraciones de parámetros o diferentes datos de entrenamiento. Finalmente, se suman los resultados de predicción de todos los clasificadores base y el resultado de predicción final se obtiene mediante un determinado método combinado (como votación, votación ponderada, etc.).
En comparación con un clasificador único, el aprendizaje conjunto puede mejorar significativamente la precisión y la capacidad de generalización del clasificador. Esto se debe a que el aprendizaje conjunto puede reducir eficazmente el sesgo y la varianza del clasificador, evitando así problemas de sobreajuste y desajuste. Además, el aprendizaje conjunto también puede aumentar la solidez del clasificador, haciéndolo más tolerante al ruido y los valores atípicos.
En la actualidad, el aprendizaje en conjunto se ha utilizado ampliamente en diversos campos, como el reconocimiento de imágenes, el procesamiento del lenguaje natural, la evaluación de riesgos financieros, etc. Los métodos comunes de aprendizaje en conjunto incluyen embolsado, impulso, apilamiento, etc.
En el aprendizaje en conjunto, suelen estar involucrados varios conceptos, entre ellos:
-
Clasificador base: se refiere a un alumno separado e independiente, y sus resultados de predicción se combinarán para generar el resultado final de la predicción. Los clasificadores base comúnmente utilizados en el aprendizaje integrado incluyen árboles de decisión, máquinas de vectores de soporte y lógica. Regresión, Bayes ingenuo, redes neuronales , etc. Diferentes clasificadores base pueden mostrar un rendimiento diferente en diferentes conjuntos de datos y tareas, por lo que en aplicaciones prácticas, es necesario seleccionar un clasificador base apropiado de acuerdo con la situación específica. .
-
Clasificador de conjunto: se refiere a un clasificador compuesto por múltiples clasificadores base. El clasificador de conjunto puede considerarse como un "metaclasificador" que puede combinar los resultados de predicción de múltiples clasificadores base para obtener resultados de predicción más precisos.
-
Bagging (Bootstrap Aggregating): es un método de aprendizaje integrado basado en un método de muestreo de autoservicio. Genera múltiples conjuntos de entrenamiento muestreando el conjunto de entrenamiento original varias veces con reemplazo, y utiliza cada conjunto de entrenamiento para generar un clasificador base. Finalmente, los resultados de la predicción de todos los clasificadores base se votan o promedian para obtener el resultado de la predicción final.
-
Impulsar: es un método de aprendizaje iterativo e integrado que mejora gradualmente el rendimiento del clasificador base. Pondera el conjunto de entrenamiento para que el clasificador base preste más atención a esas muestras mal clasificadas, mejorando así la precisión del clasificador. Existen muchos métodos de Boosting, como AdaBoost, Gradient Boosting, etc.
-
Apilamiento: es un método de aprendizaje conjunto que toma los resultados de predicción de múltiples clasificadores base como entrada y luego entrena un "metaclasificador". El método de apilamiento puede considerarse como un método de aprendizaje de dos niveles, que utiliza los resultados de predicción del clasificador base como nuevas características y luego los entrena para obtener resultados de predicción más precisos.
Estos conceptos son contenidos muy básicos e importantes en el aprendizaje integrado. Comprenderlos puede ayudarnos a comprender y aplicar mejor los algoritmos de aprendizaje integrado.
Método de clasificación integrado
Los métodos de clasificación de conjuntos comúnmente utilizados incluyen los siguientes:
-
Bagging: un método basado en el muestreo de arranque mediante el entrenamiento de múltiples clasificadores de base independientes y luego votando o promediando sus resultados.
-
Impulso: al entrenar gradualmente una serie de clasificadores débiles, cada ronda de entrenamiento ajustará el peso de la muestra de acuerdo con el error de la ronda anterior de clasificadores, de modo que las muestras mal clasificadas reciban más atención, mejorando así el rendimiento del clasificador.
La siguiente es una implementación de clasificador de conjunto para ambos métodos de conjunto.
-
Bosque aleatorio: es un método de integración de ensacado basado en árboles de decisión. Genera múltiples árboles de decisión seleccionando aleatoriamente características y muestras, y luego vota sus resultados.
-
AdaBoost: Es un método de integración basado en Boosting. Entrena gradualmente una serie de clasificadores débiles. Cada ronda de entrenamiento ajustará el peso de la muestra de acuerdo con el error de la ronda anterior de clasificadores y asignará cada clasificador durante el proceso de entrenamiento. peso, y luego sus resultados se ponderan como promedio.
-
Árbol de decisión de impulso de gradiente (GBDT): Es un método de integración basado en Boosting que mejora el rendimiento del clasificador entrenando gradualmente una serie de árboles de decisión. Cada árbol de decisión se entrena en función del residuo del árbol anterior. Las salidas de todos Luego, los árboles de decisión se ponderan como promedio.
Estos clasificadores de conjunto pueden mostrar diferentes desempeños en diferentes conjuntos de datos y tareas, por lo que en aplicaciones prácticas, es necesario seleccionar un clasificador de conjunto apropiado de acuerdo con la situación específica.
Harpillera
Método de agregación Bootstrap, también conocido como método de embolsado. El embolsado utiliza muestreo de arranque para datos de entrenamiento, es decir, muestreo de datos con reemplazo. La idea principal es:
- Se extrae un conjunto de entrenamiento del conjunto de muestra original. En cada ronda, se extraen n muestras de entrenamiento del conjunto de muestras original utilizando el método Bootstrapping (en el conjunto de entrenamiento, algunas muestras se pueden extraer varias veces, mientras que algunas muestras no se pueden seleccionar una vez). Se realizan un total de k rondas de extracción para obtener k conjuntos de entrenamiento. (Los k conjuntos de entrenamiento son independientes entre sí)
- Cada vez que se utiliza un conjunto de entrenamiento para obtener un modelo, se utilizan k conjuntos de entrenamiento para obtener un total de k modelos. (Nota: aquí no existe un algoritmo de clasificación o método de regresión específico. Podemos utilizar diferentes métodos de clasificación o regresión según problemas específicos, como árboles de decisión, perceptrones, etc.)
- Para problemas de clasificación: utilice k modelos obtenidos en el paso anterior para votar y obtener los resultados de clasificación; para problemas de regresión, calcule la media de los modelos anteriores como resultado final. (todos los modelos tienen la misma importancia)
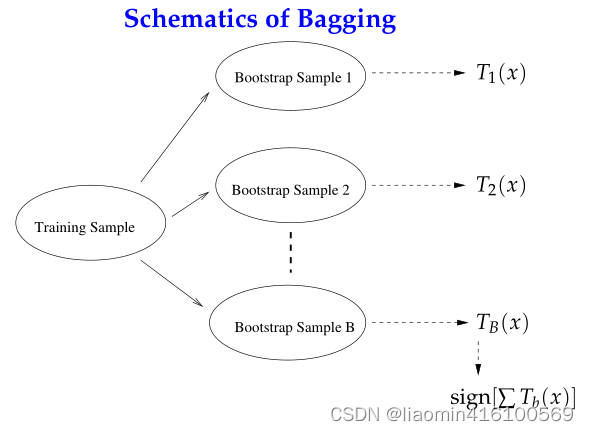
Impulsando
Boosting es una tecnología muy similar a Bagging. La idea de Boosting es utilizar el método de reponderación para entrenar iterativamente el clasificador base. La idea principal es:
- A cada ronda de muestras de datos de entrenamiento se le asigna un peso, y la distribución del peso de cada ronda de muestras depende de los resultados de clasificación de la ronda anterior, es decir, el peso de la muestra actual se ve afectado por el peso de los resultados de clasificación. , Y la tasa de error de los resultados de la clasificación actual es mayor. Cuanto mayor sea el peso de la muestra actual, mayor será el peso y se utilizará la función exponencial para amplificarlo.
- Los clasificadores base se combinan mediante un método de ponderación lineal secuencial.
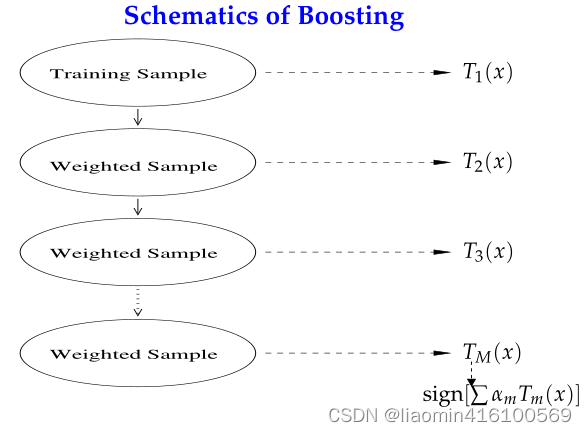
La diferencia entre ensacar e impulsar
Selección de muestras:
- Embolsado: el conjunto de entrenamiento se selecciona con reemplazo del conjunto original, y cada conjunto de entrenamiento seleccionado del conjunto original es independiente.
- Impulso: el conjunto de entrenamiento en cada ronda permanece sin cambios, pero el peso de cada muestra en el conjunto de entrenamiento en el clasificador cambia. Los pesos se ajustan en función de los resultados de clasificación de la ronda anterior.
Peso de la muestra:
- Ensacado: Utilice muestreo uniforme, con igual peso para cada muestra.
- Impulso: ajuste continuamente el peso de la muestra de acuerdo con la tasa de error. Cuanto mayor sea la tasa de error, mayor será el peso. Es decir, cada muestra tiene un peso. Cuanto mayor sea la tasa de error, mayor será el peso y mayor probabilidad de necesitar ser reentrenado.
Función de predicción:
en el aprendizaje conjunto, generalmente asignamos un peso a cada clasificador base, y este peso depende del desempeño del clasificador en el conjunto de entrenamiento. Para los clasificadores con buen desempeño, damos ponderaciones más altas para que desempeñen un papel más importante en las decisiones de votación. Por el contrario, a los clasificadores con bajo rendimiento se les asignan ponderaciones más bajas para reducir su impacto en los resultados finales.
- Embolsado: todas las funciones de predicción tienen el mismo peso.
- Impulso: cada clasificador débil tiene un peso correspondiente, y los clasificadores con pequeños errores de clasificación tendrán pesos mayores.
computación paralela:
- Bagging: Las funciones de predicción individuales se pueden generar en paralelo.
- Impulso: cada función de predicción solo se puede generar secuencialmente, porque los últimos parámetros del modelo requieren los resultados de la ronda anterior de modelos.
El siguiente es un nuevo algoritmo obtenido combinando árboles de decisión con estos marcos de algoritmos:
- Embolsado + Árbol de decisión = Bosque aleatorio
- AdaBoost + Árbol de decisión = Árbol impulsado
- Aumento de gradiente + árbol de decisión = GBDT
bosque aleatorio
Muestreo de autoservicio
El bosque aleatorio es un algoritmo basado en la idea de aprendizaje conjunto en bolsas. Utiliza múltiples árboles de decisión para la integración. Al mismo tiempo, aumenta la aleatoriedad del modelo y mejora la capacidad de generalización del modelo al introducir selección de características aleatorias y muestra muestreo aleatorio. A continuación se muestra un ejemplo sencillo para ilustrar el proceso de cálculo del bosque aleatorio.
Supongamos que tenemos un conjunto de datos con 1000 muestras, cada muestra contiene 5 características. Queremos clasificar este conjunto de datos utilizando Random Forest.
Primero, necesitamos muestrear aleatoriamente el conjunto de datos y seleccionar aleatoriamente 1000 muestras del conjunto de datos original con reemplazo (el muestreo con reemplazo significa que la misma muestra se puede muestrear varias veces, por ejemplo, se muestrea una muestra 1, registre Póngala en una bolsa, vuelva a colocarla en el conjunto de datos original y luego extraiga uno de los 1000 en el conjunto de datos original. Puede ser la muestra 1 o puede ser la muestra 100. Cada vez, se extrae de 1000 y 1000 es veces, si tiene suerte, puede obtener 1000 muestras1. Por supuesto, esto es casi imposible. No comprenda que simplemente coloca un dato del conjunto de datos de origen en el conjunto de muestreo de autoservicio y nunca lo coloca El conjunto de muestreo de autoservicio es solo una copia de la muestra), este nuevo conjunto de datos es una "bolsa", que llamamos "muestra de arranque". Algunas muestras de este conjunto de muestreo de autoservicio pueden aparecer repetidamente y es posible que otras muestras no se muestreen. Este proceso se llama arranque.
A continuación, debemos entrenar este conjunto de muestreo de arranque utilizando un clasificador basado en árbol de decisión. Al entrenar un árbol de decisión, necesitamos seleccionar características aleatoriamente en cada nodo. Específicamente, seleccionamos aleatoriamente una cierta cantidad de características de las características originales cada vez y luego seleccionamos las características óptimas de estas características para la partición. Este proceso se llama selección aleatoria de características.
Después de entrenar el primer árbol de decisión, podemos predecir las muestras restantes y registrar los resultados de la predicción de cada muestra. Luego, seleccionamos aleatoriamente 1000 muestras del conjunto de datos original con reemplazo para formar un nuevo conjunto de muestreo de autoservicio, entrenamos un segundo árbol de decisión usando el mismo método y registramos los resultados de predicción de cada muestra.
Este proceso se repite hasta que se entrene el número especificado de árboles de decisión. Finalmente, podemos votar los resultados de la predicción de cada muestra para obtener el resultado de la predicción final del bosque aleatorio.
Cabe señalar que los árboles de decisión en bosques aleatorios generalmente se entrenan en paralelo, es decir, cada árbol de decisión se puede entrenar en un núcleo de CPU independiente, acelerando así el proceso de entrenamiento del modelo. Además, el árbol de decisión en el bosque aleatorio puede utilizar algunas estrategias de poda para evitar el sobreajuste, como el límite mínimo de número de muestras, el límite máximo de profundidad, etc.
Datos de pronóstico
Tenga en cuenta que el algoritmo de aprendizaje conjunto no selecciona un modelo de varios modelos mediante el entrenamiento de datos, sino que varios modelos ingresan predicciones de resultados y el resultado final se obtiene mediante métodos como la votación o el promedio.
El bosque aleatorio es un método de aprendizaje conjunto que se basa en el algoritmo del árbol de decisión. El proceso de predicción de datos por bosque aleatorio es el siguiente:
-
Se seleccionan aleatoriamente n muestras del conjunto de entrenamiento con el reemplazo como subconjunto, y el tamaño de este subconjunto es el mismo que el tamaño del conjunto de entrenamiento.
-
Para este subconjunto, k características se seleccionan aleatoriamente, donde k es un hiperparámetro fijo, que generalmente es menor que el número total de características.
-
En base a este subconjunto y k características, se entrena un modelo de árbol de decisión.
-
Repita los pasos de 1 a 3 m veces para obtener m modelos de árboles de decisión.
-
Para un nuevo punto de datos, introdúzcalo en cada modelo de árbol de decisión para obtener m resultados de predicción.
-
Para problemas de clasificación, se utiliza la votación y la categoría con más votos entre los m resultados de predicción se utiliza como resultado de predicción final. Para problemas de regresión, el valor promedio se utiliza para promediar m resultados de predicción como resultado de predicción final.
Cabe señalar que en el bosque aleatorio, cada modelo de árbol de decisión se entrena de forma independiente, por lo que el entrenamiento y la predicción se pueden realizar en paralelo, mejorando así la eficiencia del modelo.
Pronóstico de lirios
El conjunto de datos de iris es un conjunto de datos multivariados etiquetados que contiene mediciones de tres especies diferentes de iris (Iris mountaina, Iris versicolor e Iris virginia). Estas medidas (características) incluyen la longitud del sépalo, el ancho del sépalo, la longitud del pétalo y el ancho del pétalo. Cada muestra contiene estas cuatro mediciones, para un total de 150 muestras.
El propósito de este conjunto de datos es diferenciar entre diferentes variedades de flores de iris utilizando estas medidas. Este es un problema de aprendizaje automático muy común y se usa ampliamente para comparar algoritmos de clasificación y agrupamiento.
El conjunto de datos Iris es uno de los conjuntos de datos más utilizados en el campo del aprendizaje automático y se utiliza ampliamente en visualización de datos, evaluación de modelos, selección de características y comparación de algoritmos.
Primero cargamos el conjunto de datos de iris usando la función load_iris en la biblioteca sklearn. Luego, usamos la función train_test_split para dividir el conjunto de datos en conjuntos de entrenamiento y prueba con una proporción de 0,3.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 加载鸢尾花数据集
iris = load_iris()
# 打印特征数和数据集大小
print("Number of features: ", len(iris.feature_names))
print("Number of samples: ", len(iris.data))
print(iris.target)
Producción:
Number of features: 4
Number of samples: 150
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
Luego, usamos la función train_test_split para dividir el conjunto de datos en conjuntos de entrenamiento y prueba con una proporción de 0,3.
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3,random_state=2)
Utilice árboles de decisión directamente para la predicción.
from sklearn.tree import DecisionTreeClassifier
# 定义决策树分类器
clf = DecisionTreeClassifier(random_state=1)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
accuracy = clf.score(X_test, y_test)
print("Accuracy:", accuracy)
Salida: Precisión: 0,9555555555555556
RandomForestClassifier es un modelo de clasificación basado en el algoritmo de bosque aleatorio. Tiene algunos parámetros importantes. Los explicaré en detalle a continuación.
-
n_estimators: Indica el número de árboles de decisión al construir un bosque aleatorio, el valor predeterminado es 100. Cuanto mayores sean los n_estimadores, la precisión y la estabilidad del modelo mejorarán relativamente, pero el tiempo de entrenamiento aumentará, por lo que es necesario equilibrar la precisión y el costo de tiempo.
-
criterio: Indica el índice para medir la calidad de la división, puede elegir "gini" o "entropía". El valor predeterminado es "gini", lo que significa que el coeficiente de Gini se utiliza para medir la calidad de la división. Y "entropía" significa utilizar la ganancia de información para medir la calidad de la división. En términos generales, elegir el coeficiente de Gini es más rápido que obtener información, pero en algunos casos la ganancia de información puede funcionar mejor.
-
max_ Depth: indica la profundidad máxima del árbol de decisión, el valor predeterminado es Ninguno, lo que significa que no hay límite para la profundidad. Si establece max_ Depth en un valor menor, puede evitar el sobreajuste, pero puede afectar la precisión del modelo.
-
min_samples_split: indica el número mínimo de muestras de un nodo antes de realizar la división del nodo. El valor predeterminado es 2. Si establece min_samples_split en un valor mayor, puede evitar que el árbol de decisión se sobreajuste en áreas locales, pero puede hacer que el árbol de decisión no se ajuste lo suficiente.
-
min_samples_leaf: indica el número mínimo de muestras de nodos hoja, el valor predeterminado es 1. Si establece min_samples_leaf en un valor menor, puede hacer que el modelo sea más flexible, pero puede hacer que el árbol de decisión se ajuste demasiado.
-
max_features: indica la cantidad de características que se considerarán al determinar la división de nodos. Puede ingresar un número entero, de punto flotante, una cadena o Ninguno. Si se ingresa un número entero, significa que el número de características consideradas es el valor entero; si se ingresa un número de punto flotante, significa que el número de características consideradas es el número total de características multiplicado por el valor de punto flotante; si la cadena " auto", significa que las características consideradas El número es el número total de características; si se ingresa la cadena "sqrt", significa que la cantidad de características consideradas es la raíz cuadrada del número total de características; si la cadena Se ingresa "log2", significa que el número de características consideradas es la base 2 del número total de características. El logaritmo de; si se ingresa Ninguno, significa que el número de características consideradas es el número total de características. En términos generales, el rendimiento de los bosques aleatorios es relativamente estable, por lo que max_features se puede establecer en el valor predeterminado Ninguno.
-
random_state: representa una semilla aleatoria, que se utiliza para controlar la generación de patrones aleatorios y hacer que los patrones aleatorios sean repetibles. Si random_state se establece en un número entero, significa usar el número entero como semilla aleatoria; si se establece en Ninguno, significa usar la semilla aleatoria predeterminada.
Usa bosques aleatorios
# 创建随机森林分类器,指定决策树数量为100,其他参数采用默认值
rfc = RandomForestClassifier(n_estimators=100)
# 使用训练数据集进行训练
rfc.fit(X_train, y_train)
# 使用测试数据集进行预测
y_pred = rfc.predict(X_test)
# 计算模型的准确率
accuracy = rfc.score(X_test, y_test)
print("Accuracy:", accuracy)
Salida: Precisión: 0.9777777777777777
AdaBoost
AdaBoost (Adaptive Boosting) es un método de aprendizaje conjunto cuyo propósito es combinar múltiples clasificadores débiles en un clasificador fuerte. Su idea central es que cada sesión de entrenamiento fortalece el peso de las muestras que fueron mal clasificadas en el entrenamiento anterior y reduce el peso de aquellas muestras que fueron clasificadas correctamente. De esta forma, en cada sesión de entrenamiento, el modelo prestará más atención a las muestras con malos resultados de clasificación previa, de modo que todo el modelo pueda adaptarse mejor al conjunto de datos.
Proceso algorítmico y fórmulas.
El proceso y la fórmula del algoritmo AdaBoost son los siguientes:
-
Inicialice el peso de los datos de entrenamiento: para un conjunto de entrenamiento D con N muestras, el peso de cada muestra se inicializa en 1/N.
-
Para t=1,2,…T, haga lo siguiente:
a. Según la distribución de peso de los datos de entrenamiento actuales, utilice un clasificador base (como un árbol de decisión) para el entrenamiento.
b) Calcule la tasa de error (tasa de error) del clasificador base: para muestras clasificadas incorrectamente, el peso aumenta; para muestras clasificadas correctamente, el peso disminuye.
c.Calcule el peso del clasificador base: el peso del clasificador base está relacionado con su tasa de error. Cuanto menor sea la tasa de error del clasificador base, mayor será su peso.
d.Actualice el peso de los datos de entrenamiento: de acuerdo con el peso del clasificador base, actualice la distribución de peso de los datos de entrenamiento para que el peso de las muestras con una gran tasa de error del clasificador base aumente y el peso de las muestras con una La pequeña tasa de error disminuye.
-
El clasificador final es la suma ponderada de los clasificadores base, siendo los pesos los pesos de cada clasificador base.
La fórmula del algoritmo AdaBoost es la siguiente:
Paso 1: Inicializar pesos
re 1 ( yo ) = 1 norte , yo = 1 , 2 , . . . , N D_1(i)=\frac{1}{N}, i=1,2,...,ND1( yo )=norte1,i=1 ,2 ,... ,norte
Paso 2: Para t=1,2,...T, realice las siguientes operaciones:
a. Clasificador base de entrenamiento
G t ( x ) : X → { − 1 , 1 } G_t(x):\mathcal{X}\rightarrow\{-1,1\}GRAMOt( x ):X→{ -1 , _1 }
b. Calcular la tasa de error
ϵ t = P ( G t ( xi ) ≠ yi ) = ∑ i = 1 ND t ( i ) [ G t ( xi ) ≠ yi ] \epsilon_t=P(G_t(x_i)\ne y_i)=\sum_{i =1}^N D_t(i)[G_t(x_i)\ne y_i]ϵt=PAG ( GRAMOt( xyo)=yyo)=∑yo = 1norteDt( yo ) [ GRAMOt( xyo)=yyo]
c.Calcular el peso del clasificador base.
α t = 1 2 ln 1 − ϵ t ϵ t \alpha_t=\frac{1}{2}\ln\frac{1-\epsilon_t}{\epsilon_t}at=21enϵt1 − ϵt
D. Actualizar pesos
D t + 1 ( yo ) = D t ( yo ) exp ( − α tyi G t ( xi ) ) Z t , yo = 1 , 2 , . . . , norte D_{t+1}(i)=\frac{D_t(i)\exp(-\alpha_ty_iG_t(x_i))}{Z_t},i=1,2,...,NDt + 1( yo )=ztDt( yo )e x p ( − atyyoGRAMOt( xyo) ),i=1 ,2 ,... ,N
dentro,Z t Z_tztes el factor de normalización tal que D t + 1 D_{t+1}Dt + 1se convierte en una distribución de probabilidad.
Paso 3: clasificador final
f ( x ) = signo ( ∑ t = 1 T α t G t ( x ) ) f(x)=\operatorname{sign}\left(\sum_{t=1}^T\alpha_tG_t(x)\right )f ( x )=firmar( ∑t = 1tatGRAMOt( x ) )
Entre ellos, signo (x) signo(x)s i g n ( x ) es una función de signo. Si x ≥ 0, entoncessigno ( x ) = 1 \operatorname{sign}(x)=1signo ( x )=1 ; de lo contrario,signo ( x ) = − 1 \operatorname{sign}(x)=-1signo ( x )=− 1。
Pronóstico de lirios
El módulo sklearn.ensemble proporciona muchos métodos de integración, AdaBoost, Bagging, Random Forest, etc. Esta vez usé AdaBoostClassifier.
Primero echemos un vistazo a la función AdaBoostClassifier, que tiene 5 parámetros en total:

La descripción de los parámetros es la siguiente:
- base_estimator: parámetro opcional, el valor predeterminado es DecisionTreeClassifier. En teoría, puede elegir cualquier alumno de clasificación o regresión, pero debe admitir ponderaciones de muestra. Lo que usamos comúnmente es el árbol de decisión CART o la red neuronal MLP. El valor predeterminado es un árbol de decisión, es decir, AdaBoostClassifier usa el árbol de clasificación CART DecisionTreeClassifier de manera predeterminada, y AdaBoostRegressor usa el árbol de regresión CART DecisionTreeRegressor de manera predeterminada. Otro punto a tener en cuenta es que si el algoritmo AdaBoostClassifier que elegimos es SAMME.R, nuestro alumno de clasificación débil también debe admitir la predicción de probabilidad, es decir, el método de predicción correspondiente al alumno de clasificación débil en scikit-learn es además de predecir Predict_proba. también es necesario.
- algoritmo: parámetro opcional, el valor predeterminado es SAMME.R. scikit-learn implementa dos algoritmos de clasificación Adaboost, SAMME y SAMME.R. La principal diferencia entre los dos es la medición del peso del estudiante débil: SAMME usa el efecto de clasificar el conjunto de muestras como el peso del estudiante débil, mientras que SAMME.R usa la probabilidad predicha de clasificar el conjunto de muestras como el peso del estudiante débil. Dado que SAMME.R utiliza valores continuos de medidas de probabilidad, la iteración es generalmente más rápida que SAMME, por lo que el valor del algoritmo predeterminado de AdaBoostClassifier también es SAMME.R. Generalmente usamos el SAMME.R predeterminado, pero debe tenerse en cuenta que si se usa SAMME.R, el parámetro de aprendizaje de clasificación débil base_estimator debe restringirse a clasificadores que admitan la predicción de probabilidad. El algoritmo SAMME no tiene esta limitación.
- n_estimators: tipo entero, parámetro opcional, el valor predeterminado es 50. El número máximo de iteraciones del alumno débil, o el número máximo de alumnos débiles. En términos generales, si n_estimators es demasiado pequeño, es fácil sobreajustar. Si n_estimators es demasiado grande, es fácil sobreajustar. Generalmente, se elige un valor moderado. El valor predeterminado es 50. En el proceso de ajuste de parámetros real, a menudo consideramos n_estimators y el parámetro learning_rate que se presenta a continuación.
- learning_rate: tipo de punto flotante, parámetro opcional, el valor predeterminado es 1.0. El coeficiente de reducción de peso de cada alumno débil varía de 0 a 1. Para el mismo efecto de ajuste del conjunto de entrenamiento, una v más pequeña significa que necesitamos más iteraciones del alumno débil. Por lo general, utilizamos el tamaño del paso y el número máximo de iteraciones juntos para determinar el efecto de ajuste del algoritmo. Por lo tanto, estos dos parámetros n_estimators y learning_rate deben ajustarse juntos. En términos generales, puede comenzar a ajustar los parámetros desde una v más pequeña, el valor predeterminado es 1.
- random_state: tipo entero, parámetro opcional, el valor predeterminado es Ninguno. Si es una instancia de RandomState, random_state es el generador de números aleatorios; si es Ninguno, el generador de números aleatorios es la instancia de RandomState utilizada por np.random.
#%%
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf = AdaBoostClassifier(n_estimators=50, learning_rate=1.0, random_state=42)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print("Accuracy:", accuracy)
Salida: Precisión: 1,0
Opciones de aprendizaje integradas
AdaBoost y Random Forest son métodos de aprendizaje conjunto que crean un clasificador sólido combinando múltiples clasificadores débiles (o árboles de decisión). Aunque todos pueden mejorar la precisión de la clasificación, su rendimiento puede diferir según diferentes conjuntos de datos y escenarios.
En términos generales, el bosque aleatorio es adecuado para procesar datos de alta dimensión y conjuntos de datos ruidosos porque puede seleccionar características y muestras al azar para construir múltiples árboles de decisión, reduciendo así el riesgo de sobreajuste. AdaBoost es adecuado para procesar datos de baja dimensión y problemas de clasificación complejos porque puede entrenar múltiples clasificadores débiles ajustando pesos y remuestreo, y combinándolos para obtener un clasificador más fuerte.
Por lo tanto, AdaBoost generalmente puede mostrar una mejor precisión de clasificación cuando se trata de conjuntos de datos complejos de baja dimensión, mientras que los bosques aleatorios pueden ser más adecuados cuando se trata de conjuntos de datos de alta dimensión. Sin embargo, esta es sólo una situación general: en aplicaciones específicas, es necesario seleccionar algoritmos apropiados en función de las características y necesidades del conjunto de datos.