En primer lugar, la idea de la agrupación
Se refiere a la llamada algoritmo de agrupamiento divide automáticamente los datos en una pila de etiquetas sin categorías de métodos pertenecientes al método de aprendizaje no supervisado, que es para asegurar que el mismo tipo de datos con características similares, como se muestra a continuación:
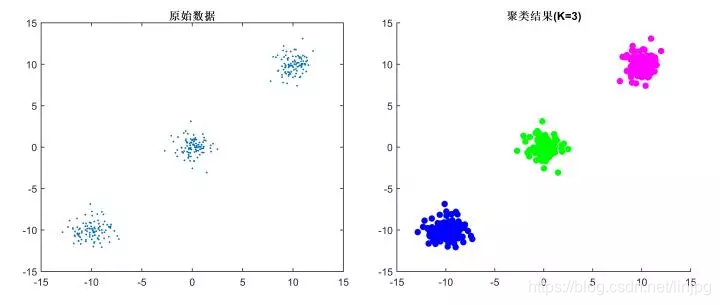
La distancia entre la muestra o una similitud (resistencia cercanía), más similares, más pequeñas son las muestras de diferencia agrupan en un grupo (cluster), y finalmente formar una pluralidad de agrupaciones, el interior de la muestra con un alto racimos de similitud, diferente diferencias entre alta clúster.
algoritmo de agrupamiento dos, k-medias
Conceptos relacionados:
El número de grupos que se obtiene: valor K
Centroide: vector media de cada grupo, es decir, el vector puede ser un promedio para cada dimensión
Las mediciones de distancia: la distancia euclídea y la similitud coseno usado (el primero de normalización)

proceso algorítmico:
1, la determinación de un primer valor de k, es decir, que queremos obtener el conjunto de datos a través de un conjunto de k clusters.
2, seleccionados al azar como los puntos k de datos de los datos centroide.
3, el conjunto de datos para cada punto, para calcular la distancia a cada centroide (por ejemplo, la distancia euclídea), de la cual cerca del centroide, que se divide en el conjunto de centroide pertenece.
4, después de todo la colección bien de la normalización de datos, un total de k conjuntos. Y luego volver a calcular el centro de gravedad de cada conjunto.
5, si la distancia es inferior a algunos entre el nuevo centroide calculado y el centroide original de un umbral establecido (es decir, no la posición vuelve a calcular el cambio centroide, estabilizar, o convergencia), podemos asumir que el clúster se ha alcanzado los resultados deseados, el algoritmo termina.
6, si el original y nuevo centroide cambio distancia centroide en gran medida, 3-5 requiere un paso iterativo.
En tercer lugar, los principios matemáticos

heurísticamente K-medias utiliza muy simple, con un conjunto de gráficos se describirán en la siguiente imagen:
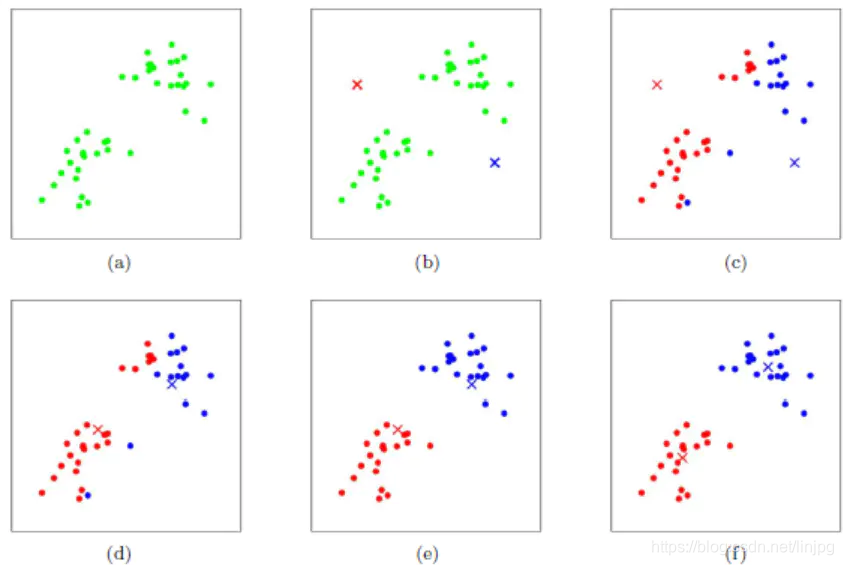
figura que expresa un conjunto de datos iniciales, se supone k = 2. En la figura b, se seleccionaron al azar dos k clase correspondiente al centroide de clase, es decir, el centroide rojo de la figura y el centroide azul y cada buscamos distancia en este caso todos los puntos a dos centroides, y marcar cada muestra la categoría de la muestra y las categorías de distancia del centroide más pequeños, como se muestra en la figura C, y después de la muestra se calcula a partir de los centroides de los centroides rojo y azul, llegamos después de la primera iteración para la categoría de todos los puntos de muestra. En este punto nos encontramos con puntos rojos y azules en nuestra marca presente sus nuevos centroides se muestran en la Fig. D, se ha producido la posición del centro de gravedad del nuevo cambio centroide rojo y azul. Las figuras E y F en la figura c se repitió el proceso y el d, es decir, todos los puntos marcados categoría categoría más cercana centroide y el centroide de la novedad. Finalmente conseguimos las dos categorías figura en el f.
En cuarto lugar, ejemplos
Sistema de coordenadas tiene seis puntos:
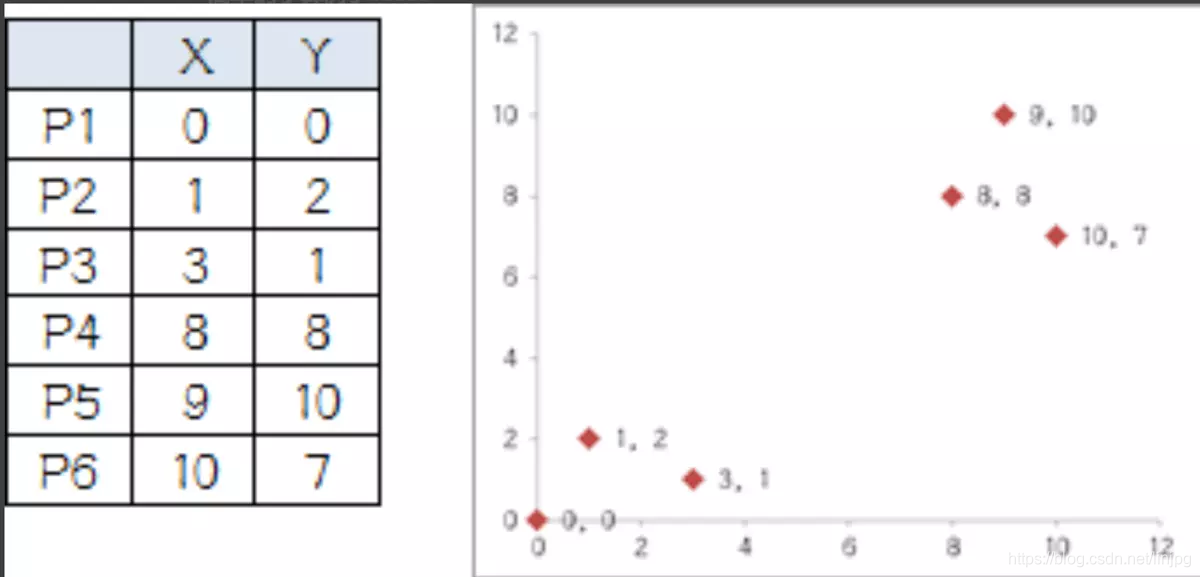
1, hemos dividido en dos grupos, por lo que K es igual a 2, se seleccionaron al azar dos puntos: P1 y P2
2, los puntos restantes se calculan mediante el teorema de Pitágoras para los dos puntos de esta:

3, después de que el primer resultado agrupación:
组A:P1
组B:P2、P3、P4、P5、P6
4, calcular el grupo A y el centroide del grupo B:
A组质心还是P1=(0,0)
B组新的质心坐标为:P哥=((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)
5, cada punto se calcula de nuevo la distancia centroide:
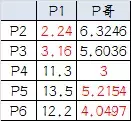
6, el resultado segunda agrupación:
组A:P1、P2、P3
组B:P4、P5、P6
7, el centroide se calcula de nuevo:
P哥1=(1.33,1)
P哥2=(9,8.33)
8, calculado de nuevo para cada punto de la distancia al centroide:
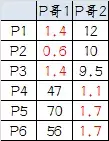
9, la tercera resultados de agrupamiento:
组A:P1、P2、P3
组B:P4、P5、P6
Se puede encontrar, los resultados del tercer grupo y los resultados del segundo grupo explicación consistente ha convergido, el agrupamiento final.
Cinco, K-medias ventajas y desventajas
ventajas:
1, el principio es simple, es muy fácil de lograr una convergencia rápida.
2, cuando el resultado es un conjunto denso, y la diferencia entre el clúster y el cluster Obviamente, es mejor.
3, los principales parámetros que necesite ajustar los parámetros de sólo el número de grupos k.
desventajas:
1, valor de K requerida de antemano dado el valor estimado de K en muchos casos es muy difícil.
2, K-medias algoritmo para seleccionar los diferentes resultados de la agrupación, sensibles centroides iniciales obtenidos punto semilla aleatoria es completamente diferente, una gran influencia en los resultados.
3, más sensible al ruido y los valores atípicos. Para la detección de valores atípicos.
4, el método iterativo, solamente puede obtener una solución óptima parcial, pero no puede obtener la solución óptima global.
En sexto lugar, detalles
1, el valor de K dado, ¿cómo?
A: varias categorías dependiendo de la experiencia y los sentimientos personales, la práctica habitual es tratar un valor de K pocos, dividida en varias categorías verse mejor interpretación de los resultados, más en línea con el propósito de análisis y así sucesivamente. Los valores de k diferentes o puede ser calculada para comparar E, K tiene un valor mínimo de E.
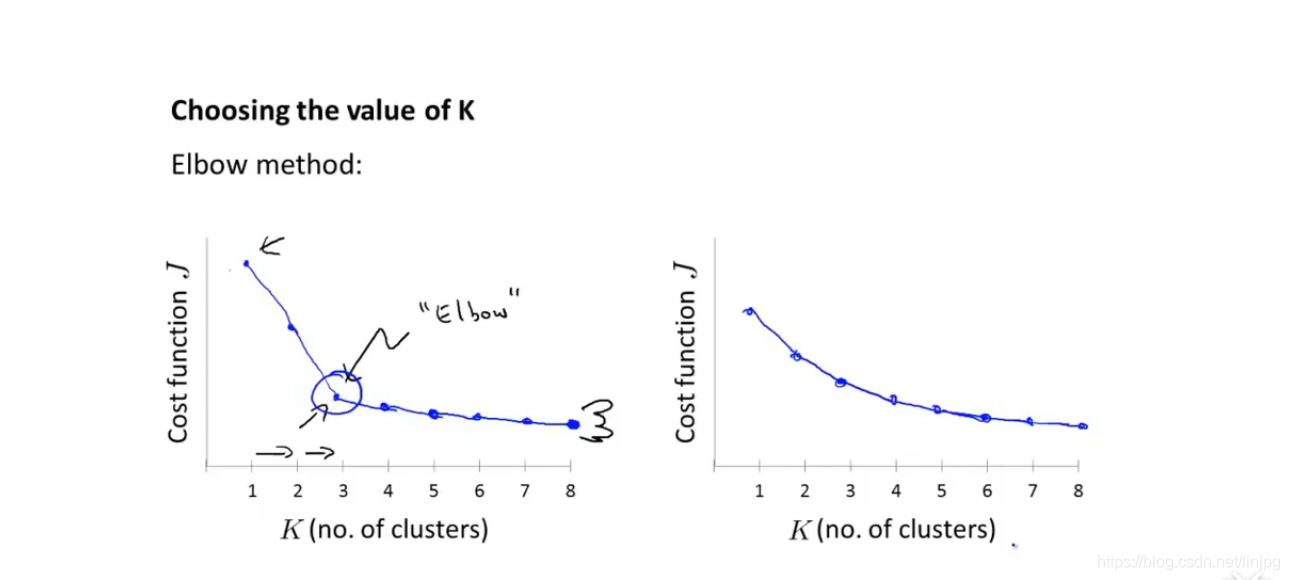
El maestro puede referir a Andrew Ng dijo que el video dentro del método codo, el costo de cada función que se ven inmersos en una función, cuando la curva se vuelve suave, el número de K puede ser una constante
2, la inicial K centroide cómo la elección?
A: El método más común es la selección aleatoria, la selección de centro inicial de masa de la agrupación final de afectar a los resultados, por lo que el algoritmo debe ejecutar varias veces, lo que resulta más razonables, que utilizará los resultados. Por supuesto, hay algunos métodos de optimización, el primero es para seleccionar un punto más alejado de uno al otro, específicamente, para seleccionar el primer punto y el segundo punto se selecciona de cuando el primer punto más lejano, y seleccionar la tercera puntos, el tercer punto a la primera, la segunda y la distancia mínima entre dos puntos, y así sucesivamente. El segundo es conseguir que los resultados de la agrupación en base a otros algoritmos de agrupamiento (como agrupación jerárquica), los resultados de cada categoría a elegir un punto.
3, sobre los valores atípicos?
A: El valor atípico está lejos de enteros los puntos, muy inusual, muy específicas de datos antes de la agrupación de estos valores extremos debe ser "grande", "muy pequeño" y similares son removidos, de lo contrario los resultados de la agrupación afectadas. Sin embargo, los valores atípicos muy a menudo en el valor de su propio análisis, los valores atípicos se pueden analizar por separado como una clase.
4, la unidad para ser coherentes!
A: Por ejemplo, la unidad es m X, Y son los metros, la distancia calculada en unidades o arroz, que tiene sentido. Pero si X es m, Y t se calcula utilizando la fórmula de la distancia será "metros cuadrados" con "toneladas de plaza" para abrir la plaza, la última cosa que no se calcula sentido matemático, que es un problema.
5, la normalización
A: Si los datos de X en su conjunto son relativamente pequeñas, tales como el número está entre 1 y 10, Y es grande, tal como el número es más que 1000, entonces, en el cálculo de la distancia Y cuando el papel de la gran X muchos, X distancia del impacto es casi insignificante, es también un problema. datos Así, si el cálculo de la distancia euclidiana seleccionado de la agrupación K-medias, el conjunto de datos ha aparecido en el caso de lo anterior, debe normalizarse (normalización), de escala de los datos a punto de hacerlo caer una pequeña sección específica.
Referencia algoritmo k-medias agrupación
[subtítulos en inglés] cursos de aprendizaje automático Andrew Ng
