Enlace de descarga del artículo: https://arxiv.org/abs/2010.11929
Directorio de artículos
- introducción
- 1. Transformador en profundidad
- 2. De CNN a Vision Transformer
- 3. Cómo funciona el Transformador de Visión
- 4. Variantes de ViT y trabajos relacionados
- 5. Ventajas y desventajas de ViT
introducción
1. Comparación entre VIT y CNN tradicional
Existen varias diferencias clave entre ViT (Vision Transformer) y la red neuronal convolucional tradicional (CNN) en el procesamiento de imágenes:
1. Estructura del modelo:
- ViT: basado principalmente en la estructura Transformer, no se utilizan capas convolucionales.
- CNN: utilice capas convolucionales, de agrupación y totalmente conectadas.
2. Procesamiento de entradas:
- ViT: divide una imagen en varios fragmentos de tamaño fijo y los procesa todos a la vez.
- CNN: escanea gradualmente la imagen completa a través de ventanas convolucionales.
3. Complejidad computacional:
- ViT: La complejidad computacional puede ser mayor debido al mecanismo de autoatención.
- CNN: normalmente es más fácil de optimizar y tiene una complejidad computacional relativamente baja.
4. Dependencias de datos:
- ViT: normalmente requiere más datos y recursos informáticos para una formación eficaz.
- CNN: Relativamente más fácil de entrenar en conjuntos de datos pequeños.
2. ¿Por qué se necesita Transformer en la tarea de imagen?
En la historia del aprendizaje profundo, las redes neuronales convolucionales (CNN) han sido durante mucho tiempo la arquitectura principal para procesar tareas de imágenes. Sin embargo, con la aplicación exitosa de Transformer a tareas de procesamiento del lenguaje natural (PNL), los investigadores comenzaron a considerar su potencial en la visión por computadora.
Mecanismo de atención global flexible
- Contexto global: a diferencia de CNN con campos receptivos locales, Transformer tiene un campo receptivo global, que le permite fusionar información en toda la imagen. Este contexto global puede resultar muy útil en determinadas tareas, como la segmentación de imágenes, la detección de objetos y la interacción multiobjeto.
Interpretabilidad y atención a la visualización.
- Mejor interpretabilidad: Gracias al mecanismo de autoatención, podemos visualizar fácilmente las regiones en las que se enfoca el modelo al tomar decisiones, lo que aumenta la interpretabilidad del modelo.
secuencia a secuenciar tarea
- Salida de secuencia más fácil de manejar: en tareas como los subtítulos de imágenes, resulta más sencillo considerar información tanto de imagen como de texto, ya que ambas pueden manejarse con una arquitectura Transformer similar.
adaptabilidad
- Más fácil de adaptar a diferentes escalas y formas: Transformer no depende de filtros de tamaño fijo, por lo que, en teoría, es más fácil de adaptar a una amplia variedad de entradas.
1. Transformador en profundidad
1.1 El origen de Transformer: un gran avance en el campo de la PNL
El modelo Transformer fue propuesto originalmente por investigadores de Google en el artículo de 2017 "Attention Is All You Need". Este modelo introduce una nueva arquitectura, basada principalmente en el mecanismo de autoatención, y resuelve con éxito una serie de tareas en el procesamiento del lenguaje natural (NLP) en ese momento. A continuación se muestran algunos avances e influencias importantes de Transformer en el campo de la PNL:
1. Una nueva perspectiva sobre los problemas de modelado de secuencias
Las redes tradicionales RNN (red neuronal recurrente) y LSTM (memoria a corto plazo) encuentran el problema de la desaparición o explosión del gradiente cuando procesan secuencias largas debido a su naturaleza recursiva. Transformador pasadomecanismo de autoatencionCapta con éxito las dependencias dentro de la secuencia y es capaz de procesar toda la secuencia en paralelo, superando así a RNN y LSTM en muchos aspectos.
2. Mecanismo de autoatención
El mecanismo de autoatención en el modelo Transformer permite que el modelo establezca dependencias directas entre entradas en diferentes ubicaciones, lo que facilita que el modelo comprenda la relación contextual dentro de una oración o documento. Este mecanismo es especialmente adecuado para tareas como traducción automática, resumen de texto, sistemas de respuesta a preguntas, etc. que necesitan capturar dependencias a larga distancia.
3. Escalabilidad
por suparalelismoCon una complejidad de tiempo relativamente menor, la arquitectura Transformer hace un uso más eficiente del hardware moderno. Esto permite a los investigadores entrenar modelos más grandes y potentes que logran un mejor rendimiento.
4. La arquitectura de Transformer para el aprendizaje multimodal y multitarea
es muy flexible y se puede extender fácilmente a otros tipos de datos y tareas, incluidosEntrada de imagen, audio y multimodal.. Este punto ha sido ampliamente confirmado en investigaciones y aplicaciones posteriores.
5. Entrenamiento previo y ajuste fino
La arquitectura Transformer es adecuada para flujos de trabajo de entrenamiento previo y ajuste fino. Grandes modelos previamente entrenados, como BERT, GPT y T5, se basan en Transformer y establecen nuevos puntos de referencia de rendimiento en una variedad de tareas de PNL.
1.2 Composición básica del transformador
1.2.1 Mecanismo de Autoatención
psicológicamente hablando
- Los animales necesitan centrarse eficazmente en puntos destacables en entornos complejos.
- Marco psicológico: los humanos eligen puntos de atención basándose en señales volitivas e involuntarias (Nota: Lo casual aquí no significa casualmente, porque está traducido, lo casual aquí debería significar observación activa y observación inactiva, y también puede entenderse como deliberado e involuntario .)
Imaginemos que tenemos cinco objetos frente a nosotros: un periódico, un trabajo de investigación, una taza de café, un cuaderno y un libro. Todos los productos de papel están impresos en blanco y negro, excepto las tazas de café que son rojas. En otras palabras, esta taza de café destaca y llama la atención en este entorno visual, atrayendo involuntariamente la atención de las personas. Entonces ponemos la vista más aguda en el café.
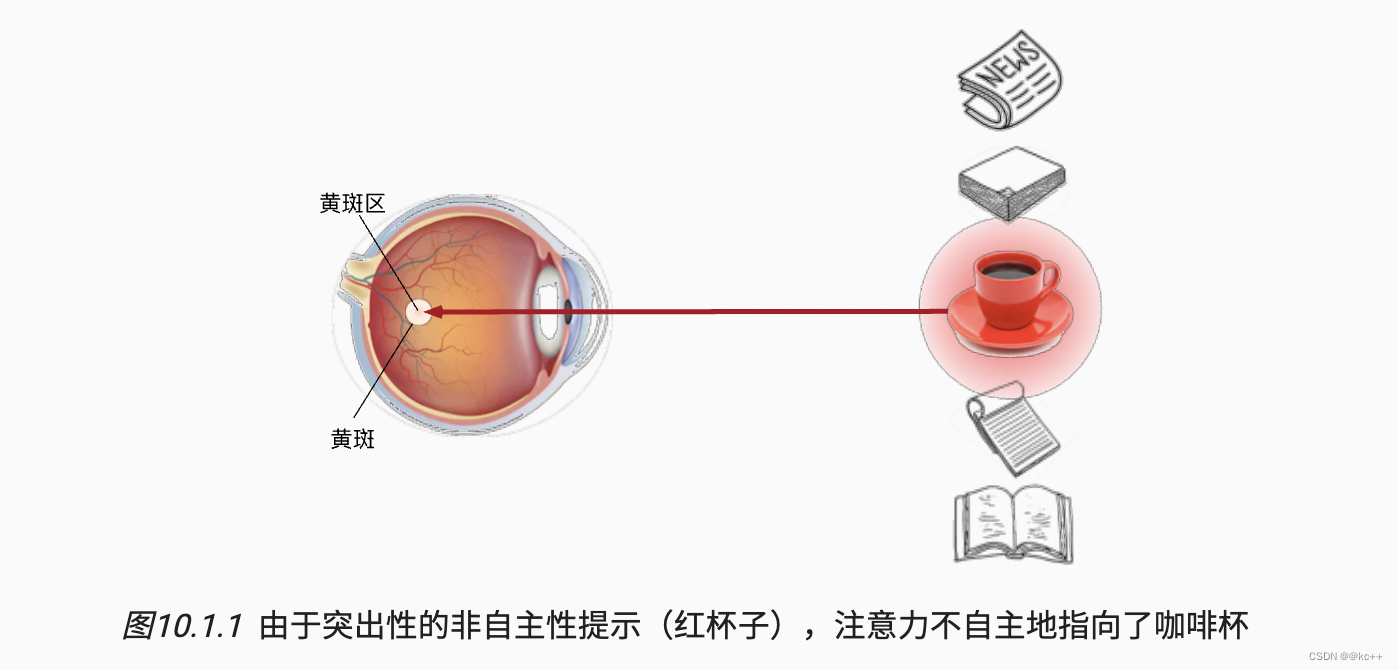
Y el querer leer se ha convertido en una pista aleatoria.
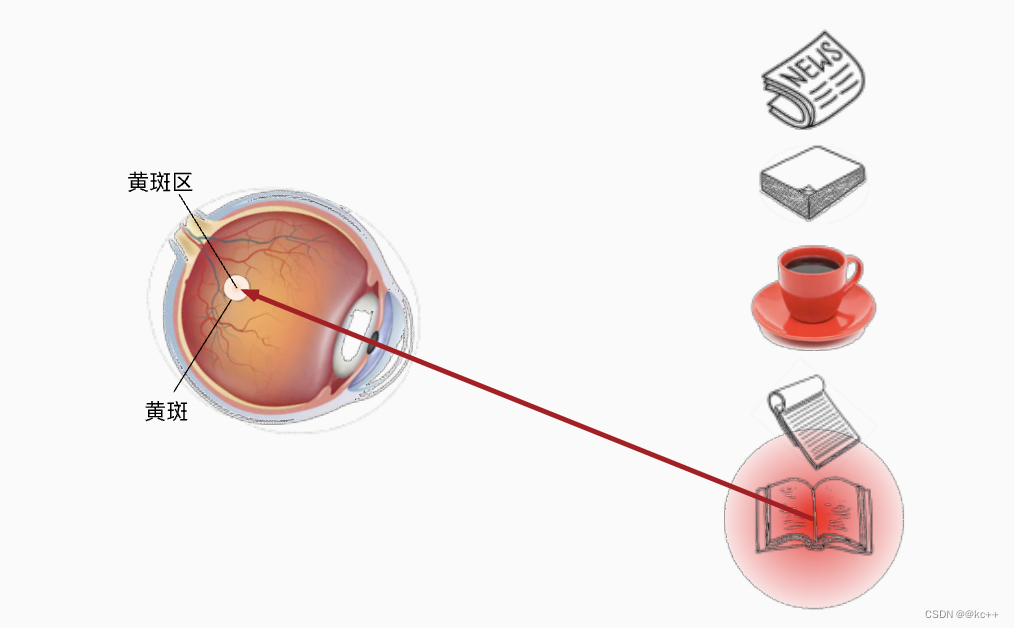
mecanismo de atención
- existirArquitectura tradicional de CNNmedio. Las capas de convolución, agrupación y completamente conectadas solo consideran pistas involuntarias
- Luego se muestra que el mecanismo de atención considera señales aleatorias.
-
- Las pistas aleatorias se llaman consultas.
-
- Cada entrada es un par de valor (valor) y pista no aleatoria (clave) (Aquí la entrada puede entenderse como el entorno.)
-
- Algunas entradas están sesgadas a través de la capa de agrupación de atención , porque hemos agregado algunas pistas aleatorias y podemos sesgar algunas entradas en ella.
proceso de cálculo
- Cálculo del producto escalar: para una consulta determinada, realice un producto escalar con cada clave para medir la similitud entre la consulta y cada clave.
- Escala: escala el resultado del producto escalar (normalmente dividiendo por la raíz cuadrada de la dimensión del vector clave).
- Función de activación: Aplicar la función de activación Softmax para que la suma de pesos sea 1 y entre 0 y 1.
- Suma ponderada: Realiza una suma ponderada del vector de valores utilizando los pesos resultantes.
- Salida: Transforme la suma ponderada a través de una capa opcional completamente conectada (Lineal), produciendo la salida en esa posición.
Atención de múltiples cabezas (Atención de múltiples cabezas)
Para capturar diferentes dependencias de manera más abundante, generalmente se usa la atención de múltiples cabezas. En atención de múltiples cabezas, el modelo mantiene múltiples conjuntos de consultas independientes, matrices de ponderación para claves y valores, y los calcula en paralelo. La salida de cada cabezal se concatena y combina a través de una capa completamente conectada.
1.2.2 Redes neuronales de retroalimentación
Las redes neuronales de retroalimentación (FFNN) son la arquitectura de red neuronal más antigua y simple. La característica de este tipo de red es que los datos se propagan en una sola dirección en la red: desde la capa de entrada, pasando por la capa oculta y finalmente hasta la capa de salida. Este flujo unidireccional de datos es de donde proviene el nombre "feedforward".
Estructura y componentes
- Capa de entrada: esta capa recibe datos de entrada sin procesar y los pasa a la siguiente capa.
- Capas ocultas: una red puede contener una o más capas ocultas, cada una de las cuales consta de varias neuronas. Estas capas capturan los patrones complejos de los datos de entrada.
- Capa de salida: según los requisitos de la tarea (como clasificación, regresión, etc.), la capa de salida genera el resultado final de la red.
Funciones de activación
Para introducir la no linealidad, cada neurona suele tener una función de activación. Las funciones de activación más utilizadas son:
- ReLU (Unidad lineal rectificada)
- Sigmoideo
- Tanh (tangente hiperbólica)
- ReLU con fugas, ReLU paramétrico, etc.
Entrenamiento
Las redes neuronales Feedforward generalmente se entrenan utilizando el algoritmo de retropropagación, que implica:
- Propagación hacia adelante: a partir de la capa de entrada, los datos fluyen a través de la red para generar resultados previstos.
- Cálculo de pérdidas: calcule la pérdida en función de la producción prevista y el objetivo real.
- Propagación hacia atrás: Calcula el gradiente de pérdida con respecto a cada peso y actualiza los pesos en la red.
Aplicación en Transformer
Aunque la arquitectura Transformer se centra principalmente en el mecanismo de autoatención, tiene una red neuronal de retroalimentación (generalmente una red de dos capas) después de cada módulo de atención. Esto introduce potencia informática adicional al modelo y ayuda a capturar diferentes características de los datos.
1.2.3 Conexiones residuales
En la arquitectura Transformer, la conexión residual juega un papel muy crítico. Aparecen después de las capas de Autoatención y de Redes neuronales de retroalimentación y, a menudo, se usan junto con la Normalización de capas.
Estructura y función
En Transformer, la salida de cada subcapa (como la autoatención de múltiples cabezales o la red neuronal de retroalimentación) se agrega a la entrada de esta subcapa para formar una conexión residual. Esta estructura de conexión se puede expresar como:
Salida=Subcapa(x)+x
o más generalmente:
Salida=LayerNorm(Subcapa(x)+x)
Aquí Sublayer (x) es la salida de una subcapa (como la autoatención de múltiples cabezales o una red neuronal de retroalimentación), y LayerNorm es la normalización de la capa.
1.2.4 Normalización de capas
Justificación
La idea central de la normalización de capas es normalizar cada muestra en cada capa de forma independiente para que la salida de cada capa tenga aproximadamente la misma escala. La normalización de capas se aplica después de capas convolucionales o completamente conectadas, pero generalmente antes de las funciones de activación.
Expresado matemáticamente como:

Aplicación en Transformer En
la arquitectura Transformer, la normalización de capas generalmente se usa junto con conexiones residuales (Conexiones Residuales). Cada conexión residual va seguida de un paso de normalización de capas para estabilizar el entrenamiento del modelo. Esta combinación ayuda al modelo a mantener la estabilidad numérica durante el entrenamiento, especialmente para modelos muy profundos.
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
ventaja
- Estabilidad numérica: la normalización de capas ayuda a evitar el problema del gradiente que desaparece o explota, lo que hace que el modelo sea más fácil de entrenar.
- Convergencia acelerada: al ajustar la escala de cada capa, la normalización de capas puede acelerar la convergencia del modelo.
- Adaptabilidad: la normalización de capas es aplicable a arquitecturas de red de diferentes tipos y profundidades, incluidas las redes neuronales recurrentes (RNN).
defecto
- Dependencia de la longitud de la secuencia: la normalización de capas puede no ser tan efectiva como la normalización por lotes cuando se trata de secuencias de longitud variable.
- Complejidad del modelo: se introducen parámetros adicionales que se pueden aprender, lo que puede aumentar la complejidad del modelo.
2. De CNN a Vision Transformer
Tanto las redes neuronales convolucionales (CNN) como Vision Transformer (ViT) son modelos populares para tareas de procesamiento de imágenes, pero tienen diferentes filosofías de diseño y alcances de aplicación. La evolución entre ambos se describe brevemente a continuación.
2.1 Limitaciones de las CNN
1. Campo receptivo local
CNN procesa imágenes a través de campos receptivos locales, lo cual es una limitación en algunas tareas. Si bien este diseño es útil para identificar estructuras locales en imágenes, puede no ser adecuado para capturarlarga distanciadependencias.
2. Calcule el costo
al procesarimagen de alta resolución, el costo computacional de la operación de convolución puede ser muy alto.
3. Supuesto de estructura espacial
CNN supone que los datos de entrada tienen algunaestructura espacial o temporal inherente. Esto hace que las CNN no sean fáciles de aplicar a datos sin una estructura espacial clara.
4. Eficiencia de los parámetros
En términos de eficiencia de los parámetros, incluso si se utilizan varias técnicas (como normalización por lotes, conexión residual, etc.), CNN aún puede ser inferior al modelo Transformer.
2.2 Surgimiento y motivación de Vision Transformer
Vision Transformer fue propuesto por primera vez por Google Research en 2020 y su diseño se inspiró en el modelo Transformer para el procesamiento del lenguaje natural.
1. Atención global
A diferencia de CNN, ViT utiliza un mecanismo de autoatención global, que puede manejar mejor ladependencias de larga distancia。
2.
Pase ViT de eficiencia computacionalautoatenciónyred neuronal de avancepara lograr eficiencia computacional, especialmente cuando se trata de imágenes de alta resolución.
3. Modularidad y escalabilidad
ViT tiene buena modularidad y escalabilidad y puede ajustar fácilmente el tamaño y la complejidad del modelo.
4. La eficiencia de los parámetros
se realiza en una gran cantidad de conjuntos de datos.Pre-entrenamientoFinalmente, ViT generalmente exhibe un alto grado de eficiencia de parámetros, es decir, funciona mejor que CNN con la misma cantidad de parámetros.
5. Aplicación multimodal
Dado que ViT noSupuestos espaciales codificados, también es más fácil de aplicar a otros tipos de datos y tareas.
3. Cómo funciona el Transformador de Visión
3.1 Entrada: dividir la imagen en parches
Entrada: dividir la imagen en parches
- Segmentación de imágenes: Vision Transformer (ViT) primero divide la imagen de entrada en múltiplestrozos de tamaño fijo(parches). Estos pequeños trozos suelen sercuadrado, por ejemplo 16x16 píxeles.
- Unidimensionalización: cada pequeño bloque se aplana en unavectores 1D。
- fusionar: todos estos vectores 1D son entoncesconcatenado en una secuencia, como entrada del codificador Transformer.
3.2 Incrustación: incrustación lineal e incrustación de posición
- Incrustación lineal: los bloques pequeños se incrustan a través de una capa lineal (generalmente una capa completamente conectada) para transformarlos en vectores de dimensiones adecuadas. Esto equivale a pasar un terreno muy poco profundo.capa CNNRealizar extracción de características.
- Incrustación posicional: debido al pequeñoLa información de posición original se pierde durante 1D, por lo que es necesario agregar incorporaciones de posición para ayudar al modelo a identificar las posiciones relativas o absolutas de estos parches.
- unir: Incrustaciones lineales e incrustaciones posicionalesgeneralmente se suman para generar una secuencia de incrustación que incluye información posicional.
3.3 Codificador de transformador
- Capa de autoatención: esta capa utiliza un mecanismo de autoatención para analizar cada elemento en la secuencia de entrada (es decir, cada parche y su posición correspondiente incrustada) para representar mejor la relación entre los distintos parches.
- Red neuronal de retroalimentación: la salida de la capa de autoatención se alimenta a una red neuronal de retroalimentación.
- Conexión residual y normalización de capas: después de la capa de autoatención y la red neuronal de retroalimentación, habrá operaciones de normalización de capas y conexiones residuales para promover la estabilidad y eficiencia del entrenamiento del modelo.
- Codificador apilado: todos los componentes anteriores se apilan varias veces (p. ej., 12 o 24 veces, etc.) para formar un codificador Transformer completo.
- Cabezal de clasificación: para tareas de clasificación, es común tomar el primer elemento de la secuencia de salida del codificador (generalmente correspondiente a un token especial "[CLS]") y pasarlo a través de una capa completamente conectada para su clasificación.
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
Ninguna capa en el codificador Transformer cambia la forma de su entrada.
3.4 Cabezal de salida: Tarea de clasificación
En el modelo Vision Transformer (ViT), el cabezal de salida para tareas de clasificación suele ser unCapa completamente conectada (lineal), una capa que asigna la salida del codificador Transformer al número de etiquetas de clase. En la mayoría de las implementaciones, se suele utilizar Transformer.CodificadorproducciónFunciones en la primera posición (generalmente correspondientes a la etiqueta especial [CLS] agregada)。
4. Variantes de ViT y trabajos relacionados
Con el éxito de Vision Transformer (ViT) en tareas de clasificación de imágenes, muchos investigadores comenzaron a explorar sus variantes y mejoras. A continuación se muestran algunas variantes notables y trabajos relacionados para un análisis general:
4.1 DeiT (Transformador de imágenes con eficiencia de datos)
4.1.1 Descripción general
- Concepto: DeiT se centra en cómo utilizar los datos de forma más eficaz. ViT estándar requiere una gran cantidad de datos y recursos informáticos para la capacitación previa, pero DeiT adopta una estrategia de capacitación más eficiente, especialmenteaumento de datosydestilación del conocimiento, para mejorar esto.
- Características principales: usodestilación del conocimientoy diferentes técnicas de entrenamiento comoProgramación de la tasa de aprendizaje y aumento de datos, para reducir la dependencia de una gran cantidad de datos etiquetados.
import torch
import torch.nn as nn
import torch.nn.functional as F
# 分割图像到patch
class PatchEmbedding(nn.Module):
def __init__(self, patch_size, in_channels, embed_dim):
super().__init__()
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # [B, C, H, W]
x = x.flatten(2).transpose(1, 2) # [B, num_patches, embed_dim]
return x
# DeiT 模型主体
class DeiT(nn.Module):
def __init__(self, patch_size, in_channels, embed_dim, num_heads, num_layers, num_classes):
super().__init__()
# 分割图像到patch并嵌入
self.patch_embed = PatchEmbedding(patch_size, in_channels, embed_dim)
# 特殊的 [CLS] token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 位置嵌入
num_patches = (224 // patch_size) ** 2
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# Transformer 编码器
encoder_layer = nn.TransformerEncoderLayer(embed_dim, num_heads)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)
# 分类器头
self.fc = nn.Linear(embed_dim, num_classes)
def forward(self, x):
B = x.size(0)
# 分割图像到patch并嵌入
x = self.patch_embed(x)
# 添加 [CLS] token
cls_token = self.cls_token.repeat(B, 1, 1)
x = torch.cat([cls_token, x], dim=1)
# 添加位置嵌入
x += self.pos_embed
# 通过 Transformer
x = self.transformer(x)
# 只取 [CLS] 对应的输出用于分类任务
x = x[:, 0]
# 分类器
x = self.fc(x)
return x
# 参数
patch_size = 16
in_channels = 3
embed_dim = 768
num_heads = 12
num_layers = 12
num_classes = 1000 # 假设是一个1000分类问题
# 初始化模型
model = DeiT(patch_size, in_channels, embed_dim, num_heads, num_layers, num_classes)
# 假数据
x = torch.randn(32, 3, 224, 224) # 32张3通道224x224大小的图片
# 模型前向推断
logits = model(x)
4.1.2 Destilación del conocimiento
La destilación de conocimientos (KD) es una técnica de compresión de modelos para transferir conocimientos de un modelo grande y complejo (a menudo denominado "modelo de profesor") a un modelo más pequeño y simple (a menudo denominado "modelo de estudiante"). ). El objetivo es reducir el tamaño del modelo y el tiempo de inferencia manteniendo un rendimiento similar al de los modelos más grandes.
principio de funcionamiento
- Modelo de profesor: normalmente un profesor previamente formado.modelo grande, utilizado para generaretiqueta suave(etiquetas suaves), es decir, la distribución de probabilidad de categoría.
- Modelo de estudiante: generalmente un modelo relativamente pequeño que necesita ser entrenado paraimitar el modelo del maestro。
- Pérdida por destilación: en la destilación de conocimientos más básicos, la formación del modelo de estudiante no solo requiereMinimice la pérdida frente a las etiquetas verdaderas (como la pérdida de entropía cruzada), pero también minimice la pérdida frente a las etiquetas suaves predichas por el modelo del profesor.。
Ejemplo de código simple de destilación de conocimiento
Supongamos que tenemos un modelo de maestro (teacher_model) y un modelo de estudiante (student_model), el siguiente es un ejemplo simple de destilación de conocimiento usando PyTorch:
import torch
import torch.nn.functional as F
# 假定 teacher_model 和 student_model 已经定义并初始化
# teacher_model = ...
# student_model = ...
# 数据加载器
# data_loader = ...
# 优化器
optimizer = torch.optim.Adam(student_model.parameters(), lr=0.001)
# 温度参数和软标签权重
temperature = 2.0
alpha = 0.9
# 训练循环
for data, labels in data_loader:
optimizer.zero_grad()
# 正向传播:教师和学生模型
teacher_output = teacher_model(data).detach() # 注意:通常不会计算教师模型的梯度
student_output = student_model(data)
# 计算损失
hard_loss = F.cross_entropy(student_output, labels) # 与真实标签的损失
soft_loss = F.kl_div(F.log_softmax(student_output/temperature, dim=1),
F.softmax(teacher_output/temperature, dim=1)) # 与软标签的损失
loss = alpha * soft_loss + (1 - alpha) * hard_loss
# 反向传播和优化
loss.backward()
optimizer.step()
Escenarios de aplicación
La destilación de conocimientos no solo es adecuada para la compresión de modelos, sino que también se puede utilizar para mejorar el rendimiento de modelos pequeños en algunas aplicaciones específicas, como en DeiT (Transformador de imágenes eficiente en datos) para mejorar la eficiencia de los datos.
4.1.3 Modelo de transformador optimizado mediante destilación de conocimientos
A continuación asumimos que hay un modelo Transformer grande (modelo de maestro) que ha sido entrenado y un modelo Transformer más pequeño (modelo de estudiante).
Nota: Para simplificar, utilizamos el módulo nn.Transformer como una implementación simple de Transformer. También puedes reemplazarlo con modelos más complejos según sea necesario.
La función de pérdida consta de dos partes: una es la pérdida entre el modelo de estudiante y las etiquetas reales, y la otra es la divergencia de Kullback-Leibler entre los resultados del modelo de estudiante y maestro.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 定义简单的 Transformer 模型
class SimpleTransformer(nn.Module):
def __init__(self, d_model, nhead, num_layers, num_classes):
super(SimpleTransformer, self).__init__()
self.encoder = nn.Transformer(d_model, nhead, num_layers)
self.classifier = nn.Linear(d_model, num_classes)
def forward(self, x):
x = self.encoder(x)
x = x.mean(dim=1)
x = self.classifier(x)
return x
# 定义损失函数
def distillation_loss(y, labels, teacher_output, T=2.0, alpha=0.5):
return nn.CrossEntropyLoss()(y, labels) * (1. - alpha) + (alpha * T * T) * nn.KLDivLoss()(F.log_softmax(y/T, dim=1),
F.softmax(teacher_output/T, dim=1))
# 假设我们有一些数据
# 注意:这里使用随机数据仅作为示例
N = 100 # 数据点数量
d_model = 32 # 嵌入维度
nhead = 2 # 多头注意力的头数
num_layers = 2 # Transformer 层的数量
num_classes = 10 # 分类数
T = 2.0 # 温度参数
alpha = 0.5 # 蒸馏损失的权重因子
x = torch.randn(N, 10, d_model)
labels = torch.randint(0, num_classes, (N,))
# 初始化教师和学生模型
teacher_model = SimpleTransformer(d_model, nhead, num_layers, num_classes)
student_model = SimpleTransformer(d_model, nhead, num_layers, num_classes)
# 设置优化器
optimizer = optim.Adam(student_model.parameters(), lr=0.001)
# 模拟训练过程
for epoch in range(10):
# 前向传播
teacher_output = teacher_model(x).detach() # 通常来说,教师模型是预先训练好的,因此不需要计算梯度
student_output = student_model(x)
# 计算损失
loss = distillation_loss(student_output, labels, teacher_output, T, alpha)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {
epoch+1}, Loss: {
loss.item()}")
4.2 Modelos híbridos (ViT + CNN)
Los modelos híbridos combinan las ventajas de Vision Transformer (ViT) y Convolutional Neural Network (CNN) para lograr capacidades de reconocimiento de imágenes más potentes. Estos modelos suelen utilizar una CNN como extractor de características cuya salida se utiliza como entrada para ViT.
4.2.1 ¿Por qué modelos mixtos?
- Funciones locales y globales: las CNN son muy buenas para capturarcaracterísticas locales, y el transformador puede manejardependencias globales. La combinación de los dos permite una comprensión más completa de la imagen.
- Eficiencia computacional: las CNN son generalmente más eficientes en el procesamiento de datos de imágenes. a través deLa interfaz del modelo utiliza CNN., lo que puede reducir la complejidad computacional de Transformer.
- Eficiencia de datos: uso de CNNLas funciones previamente entrenadas pueden mejorar la eficiencia de los datos del modelo., que es especialmente útil para tareas con menos datos de entrenamiento.
4.2.2 Infraestructura
En un modelo híbrido típico, CNN se usa generalmente como extractor de características, mientras que ViT se usa como codificación y clasificación de características.
- Extracción de características: utilice una capa CNN (probablemente una red previamente entrenada como ResNet o VGG) para extraer características de la imagen de entrada.
- Bloqueo e incrustación de imágenes: bloquee la salida de CNN y conviértala en una secuencia adecuada para Transformer a través de una capa de incrustación lineal (u otros métodos).
- Codificación de transformador: codificación adicional de funciones utilizando ViT.
- Cabezal de clasificación: finalmente, se utiliza una capa completamente conectada para la clasificación.
4.2.3 Ejemplos
import torch
import torch.nn as nn
# 假设使用 ResNet 的某个版本作为特征提取器
class FeatureExtractor(nn.Module):
def __init__(self, ...):
super().__init__()
# 定义 CNN 结构,例如一个简化的 ResNet
...
def forward(self, x):
# 通过 CNN 提取特征
return x
# ViT 作为编码器
class ViTEncoder(nn.Module):
def __init__(self, ...):
super().__init__()
# 定义 Transformer 结构
...
def forward(self, x):
# 通过 Transformer 编码特征
return x
# 混合模型
class HybridModel(nn.Module):
def __init__(self, ...):
super().__init__()
self.feature_extractor = FeatureExtractor(...)
self.vit_encoder = ViTEncoder(...)
self.classifier = nn.Linear(...)
def forward(self, x):
x = self.feature_extractor(x) # CNN 特征提取
x = self.vit_encoder(x) # Transformer 编码
x = self.classifier(x) # 分类头
return x
4.3 Transformador giratorio
Swin Transformer es una arquitectura Transformer para tareas de visión por computadora, que propone un mecanismo de autoatención basado en ventanas deslizantes. Este enfoque combina las ventajas de las redes neuronales convolucionales (CNN) y los transformadores, con el objetivo de lograr una mayor eficiencia y rendimiento del modelo.
4.3.1 Características principales
- Extracción de características jerárquicas: similar a CNN, Swin Transformer realizaExtracción de características multicapa, cada capa reducirá la resolución, pero aquí se implementa a través de Transformer.
- Autoatención de ventana corredera: usos de Swin TransformerMecanismo de autoatención de ventana corredera, el mecanismo sólo considerainformación del contexto local, en lugar del tradicional Transformerinformación del contexto global. esteComplejidad computacional reducida。
- Fragmentación y fusión: en múltiples niveles, el Swin Transformer pasaFragmentando y fusionandocamino, paso a pasoreducir la longitud de la secuencia,yAumentar la dimensión de la característica, para lograr una extracción de características de mayor nivel.
- Flexibilidad: Swin Transformer se puede utilizar para una variedad de tareas de visión por computadora, como clasificación de imágenes, detección de objetos y segmentación semántica.
4.3.2 Infraestructura
- Incrustación de parches: divida la imagen en varios parches pequeños (parches) y luego usecapa de incrustación linealpara incrustar.
- Bloques Swin Transformer: Consta de múltiples capas Swin Transformer, cada una con uno o más mecanismos de autoatención de ventana deslizante y redes neuronales de retroalimentación.
- Cabeza: Según tareas específicas (como clasificación, detección, etc.), en el Swin Transformerúltima capaAñade diferentes estructuras de cabeza.
4.3.3 Ejemplo de código
- PatchEmbedding: esta parte es responsable de cortar la imagen de entrada en pedazos pequeños e incrustarlos.
- WindowAttention: esto es específico de Swin Transformer y se utiliza para cálculos de autoatención dentro de la ventana local.
- SwinBlock: consta de una capa de atención de ventana y un perceptrón multicapa (MLP).
- SwinTransformer: la arquitectura del modelo final.
import torch
import torch.nn as nn
import torch.nn.functional as F
# 切分图像为patches
class PatchEmbedding(nn.Module):
def __init__(self, in_channels, out_dim, patch_size):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.conv(x)
x = x.flatten(2).transpose(1, 2)
return x
# 滑窗注意力
class WindowAttention(nn.Module):
def __init__(self, dim, heads, window_size):
super().__init__()
self.dim = dim
self.heads = heads
self.window_size = window_size
self.query = nn.Linear(dim, dim)
self.key = nn.Linear(dim, dim)
self.value = nn.Linear(dim, dim)
def forward(self, x):
# 假设 x 的形状为 [batch_size, num_patches, dim]
# 分割为多个窗口
windows = x.view(x.size(0), self.window_size, self.window_size, self.dim)
# 计算 q, k, v
q = self.query(windows)
k = self.key(windows)
v = self.value(windows)
# 注意力计算
attn = torch.einsum('bqhd,bkhd->bhqk', q, k)
attn = F.softmax(attn, dim=-1)
# 输出
out = torch.einsum('bhqk,bkhd->bqhd', attn, v)
out = out.contiguous().view(x.size(0), self.window_size * self.window_size, self.dim)
return out
# Swin Transformer Block
class SwinBlock(nn.Module):
def __init__(self, dim, heads, window_size):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = WindowAttention(dim, heads, window_size)
self.norm2 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, dim),
nn.GELU(),
nn.Linear(dim, dim)
)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
# Swin Transformer 模型
class SwinTransformer(nn.Module):
def __init__(self, in_channels, out_dim, patch_size, num_classes):
super().__init__()
self.patch_embedding = PatchEmbedding(in_channels, out_dim, patch_size)
# 假设我们有 4 个 Swin Blocks 和窗口大小为 8
self.blocks = nn.ModuleList([
SwinBlock(out_dim, 8, 8) for _ in range(4)
])
self.global_avg_pool = nn.AdaptiveAvgPool1d(1)
self.fc = nn.Linear(out_dim, num_classes)
def forward(self, x):
x = self.patch_embedding(x)
for block in self.blocks:
x = block(x)
x = self.global_avg_pool(x.mean(dim=1))
x = self.fc(x.squeeze(-1))
return x
# 测试模型
if __name__ == '__main__':
model = SwinTransformer(3, 128, 4, 10)
x = torch.randn(16, 3, 32, 32) # 假设有 16 张 32x32 的图像
y = model(x)
print(y.shape) # 应该输出 torch.Size([16, 10])
5. Ventajas y desventajas de ViT
5.1 Ventajas frente a CNN
- Mejor manejo de dependencias a larga distancia: la arquitectura Transformer fue diseñada originalmente para capturardependencia a larga distancia, que es muy útil en algunas tareas complejas de reconocimiento de imágenes.
- Eficiencia de parámetros: ViT tiene potencialLogre el mismo rendimiento que CNN con menos parámetros。
- Interpretabilidad: El resultado del mecanismo de autoatención.Se puede utilizar para analizar el modelo para cada parte de la imagen.Inquietud, lo cual es útil para la interpretación del modelo.
- Flexibilidad y generalización: El transformador no depende deFiltros de tamaño fijo o regiones locales., teniendo así el potencial de generalizarse mejor a diferentes tipos y estructuras de datos visuales.
- Capacitación de un extremo a otro: en comparación con algunas arquitecturas CNN especialmente diseñadas, ViT se puede entrenar desde el principio hasta el final con una arquitectura unificada.
5.2 Desafíos y limitaciones de ViT
- Complejidad computacional: paraimagen grande, la complejidad computacional del mecanismo de autoatención global puede ser muy alta. Esta es una de las razones por las que ViT se utilizó principalmente en el campo de la PNL al principio.
- Dependiente de los datos: ViT generalmente requiereUna gran cantidad de datos etiquetados para un entrenamiento eficaz. Esto puede ser un problema en escenarios donde no hay muchos datos etiquetados.
- Entrenamiento inestable: las arquitecturas de transformadores suelen ser más rápidas que las CNNmás difícil de entrenar, especialmente en ausencia de suficientes recursos informáticos y datos.
- El procesamiento de características locales no es tan bueno como CNN: dado que no hay una operación de convolución incorporada, ViT puede estar en algunosTareas que dependen de características locales.(como el reconocimiento de texturas) no es tan bueno como una CNN especialmente diseñada.
- Consumo de memoria: especialmente en imágenes grandes o secuencias largas, los modelos Transformer (incluido ViT) a menudonecesito más memoria。
- Riesgo de sobreajuste: debido a la gran complejidad del modelo y al número de parámetros, ViTmás propenso al sobreajuste, especialmente cuando la cantidad de datos es pequeña.