
A partir de este artículo, centramos nuestra atención en la segmentación semántica de aprendizaje profundo en Transformer, que es un modelo de segmentación semántica basado en ViT. Antes de presentar formalmente la red de segmentación de Transformer, debe comprender la red de clasificación de ViT. Vision Transformer (ViT) puede considerarse como la red troncal de toda la tarea de Visuier.
El artículo que propone el modelo ViT se titula An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , publicado en octubre de 2020, aunque en comparación con algunos modelos de aplicación de tareas de visión de Transformer (como DETR), se propuso más tarde, pero como un red de clasificación visual con una estructura de Transformador pura, su trabajo sigue siendo de gran importancia innovadora.
La idea general de ViT es realizar tareas de clasificación de imágenes basadas en la estructura pura del Transformador. Los experimentos relevantes en el documento demuestran que el modelo ViT después del entrenamiento previo en conjuntos de datos a gran escala puede lograr un mejor rendimiento que CNN.
Explicación detallada del modelo ViT
En la Figura 1 se muestra una descripción general de la estructura general del modelo ViT.
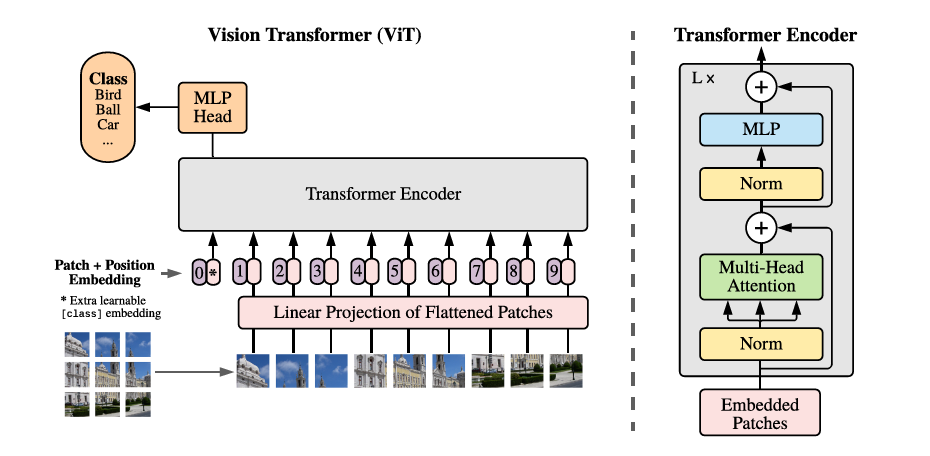
El proceso central de ViT incluye cuatro partes principales: procesamiento de bloques de imágenes (hacer parches), incrustación de parches de imágenes (incrustación de parches) y codificación de posición, codificador de transformador y procesamiento de clasificación MLP. A continuación se describe el diseño básico de ViT a partir de estas cuatro partes del proceso.
Procesamiento de bloques de imagen (hacer parches)
El primer paso puede verse como un paso de preprocesamiento de imágenes. En CNN, el procesamiento de convolución bidimensional se puede realizar directamente en la imagen y no se requiere ningún proceso de preprocesamiento especial. Sin embargo, la estructura del Transformador no puede procesar imágenes directamente y debe procesarse en bloques antes de eso.
Supongamos que una imagen x∈H×W×C ahora se divide en parches P×P×C, entonces en realidad hay parches N=HW/P2, y las dimensiones de todos los parches se pueden escribir como N×P×P×C. Luego, cada parche se aplana y la dimensión de datos correspondiente se puede escribir como N × (P2 × C). Aquí, N puede entenderse como la entrada de longitud de secuencia a Transformer, C es el número de canales de la imagen de entrada y P es el tamaño del parche de imagen.
Incrustación de bloques de imágenes (incrustación de parches)
La segmentación de imágenes es solo un proceso de preprocesamiento. Para convertir la dimensión vectorial de N×(P2×C) en una entrada bidimensional de tamaño N×D, se requiere una operación de incrustación de bloques de imagen, similar a la incrustación de palabras en NLP, la incrustación de bloques también es una forma de transformar vectores de alta dimensión en vectores de baja dimensión.
La llamada incrustación de bloque de imagen es en realidad para realizar una transformación lineal en cada vector de parche aplanado, es decir, la capa completamente conectada, y la dimensión después de la reducción de dimensión es D.
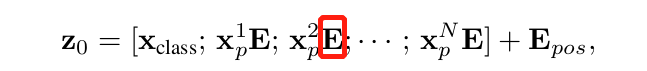
E en la fórmula anterior es la capa totalmente conectada de incrustación de bloques, su tamaño de entrada es (P2×C) y su tamaño de salida es D.
Vale la pena señalar que se agrega un vector de clasificación al vector de longitud N en la fórmula anterior, que se usa para el aprendizaje de información de categoría durante el entrenamiento de Transformer. Suponiendo que la imagen se divide en 9 parches, es decir, N=9, hay 9 vectores de entrada para el codificador del transformador, pero para estos 9 vectores, ¿qué vector debe usarse para la predicción de clasificación? Ninguno de los dos es adecuado. Un enfoque razonable es agregar artificialmente un vector de categoría, que es un vector de incrustación que se puede aprender, que se ingresa en el codificador de Transformer junto con los otros 9 vectores de incrustación de parches, y finalmente toma el primer vector como el resultado de predicción de categoría. Por lo tanto, este vector adicional puede entenderse como la información de categoría que buscan los otros 9 parches de imagen.
codificación de posición
Para mantener la información de posición espacial entre los parches de imagen de entrada, también es necesario agregar un vector de codificación de posición a la incrustación del bloque de imagen.Como se muestra en Epos en la fórmula anterior, la codificación de posición de ViT no usa el 2D actualizado El método de incrustación de posición, pero utiliza directamente La variable de incrustación de posición unidimensional aprendible del autor del artículo original encontró que 2D no mostró mejores resultados que 1D en el uso real.
Flujo directo de ViT
Después de integrar el vector de entrada incrustado de la adición de vector de categoría, la incrustación de bloque de imagen y la codificación de posición, puede ingresar directamente a la parte del codificador del transformador, que incluye principalmente dos partes: MSA y MLP. Por lo tanto, el proceso de cálculo directo del codificador de ViT se puede resumir de la siguiente manera:
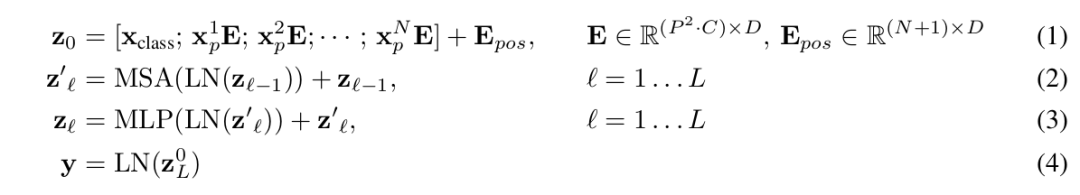
La primera fórmula es la incrustación de bloque de imagen, la adición de vector de categoría y la codificación de posición antes mencionadas, la segunda fórmula es la parte de MSA, que incluye la autoatención de varios cabezales, la conexión de salto (Agregar) y la normalización de capa (Norma). Repita los bloques L MSA; la tercera fórmula es la parte MLP, que incluye la red de avance (FFN), la conexión de salto (Agregar) y la normalización de capa (Norma), y los bloques L MSA también se pueden repetir. La cuarta fórmula es la normalización de capas. Finalmente, se utiliza un MLP como cabeza de clasificación (Classification Head).
Para mostrar más claramente la estructura del modelo ViT y los cambios de vector durante el proceso de entrenamiento, la siguiente figura muestra el diagrama de cambio de dimensión de vector de ViT.
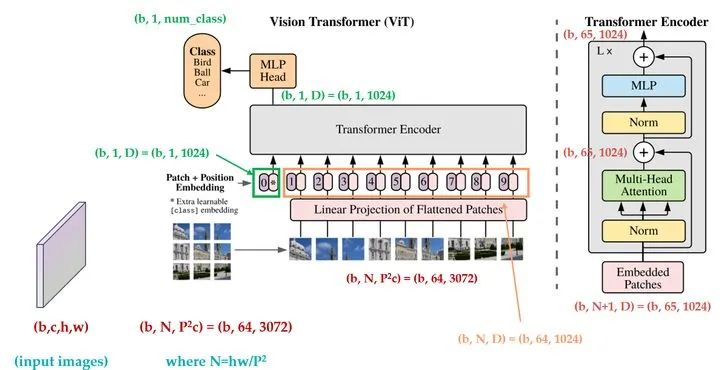
La imagen proviene de la plataforma Jishi.
Entrenamiento y experimentos de ViT
Método de entrenamiento ViT
La estrategia de capacitación básica de ViT es realizar primero una capacitación previa en un conjunto de datos grande y luego usarla para la migración en un conjunto de datos pequeño. Los grandes conjuntos de datos utilizados por ViT para el entrenamiento previo incluyen:
Conjunto de datos ILSVRC-2012 ImageNet: 1000 clases
ImageNet-21k:21k clases
JFT:Imágenes de alta resolución de 18k
Entre ellos, JFT es un conjunto de datos de imágenes a gran escala interno de Google, con alrededor de 300 millones de imágenes y 18291 categorías etiquetadas.
Los conjuntos de datos a los que migra el entrenamiento previo de ViT incluyen:
CIFAR-10/100
Oxford-IIIT Mascotas
Flores de Oxford-102
VTAB
El documento diseña tres modelos ViT de diferentes tamaños, Base, Grande y Enorme, que representan respectivamente el modelo básico, el modelo grande y el modelo súper grande. Los parámetros de los tres modelos se muestran en la siguiente tabla.
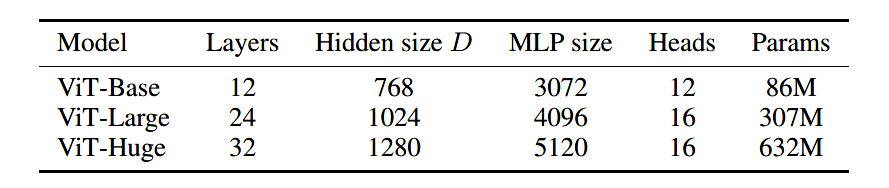
Por ejemplo, ViT-B/16 significa el modelo ViT-Base con un tamaño de parche de 16.
Diseño experimental ViT
El experimento central de ViT es implementar el método de entrenamiento antes mencionado, es decir, después del entrenamiento previo en un conjunto de datos a gran escala, migrar a un conjunto de datos pequeño para ver el efecto del modelo. Para comparar el modelo de CNN, el documento utiliza especialmente Big Transfer (BiT), que utiliza una gran ResNet para el aprendizaje de transferencia supervisado, es un modelo de CNN grande propuesto en el ECCV 2020. Otro modelo comparativo de CNN es el modelo Noisy Student en CVPR en 2020, que es un modelo de CNN a gran escala semisupervisado.
Las tasas de precisión de los modelos ViT, BiT y Nosiy Student en cada conjunto de datos pequeños después del entrenamiento previo en los tres conjuntos de datos principales se muestran en la siguiente tabla.
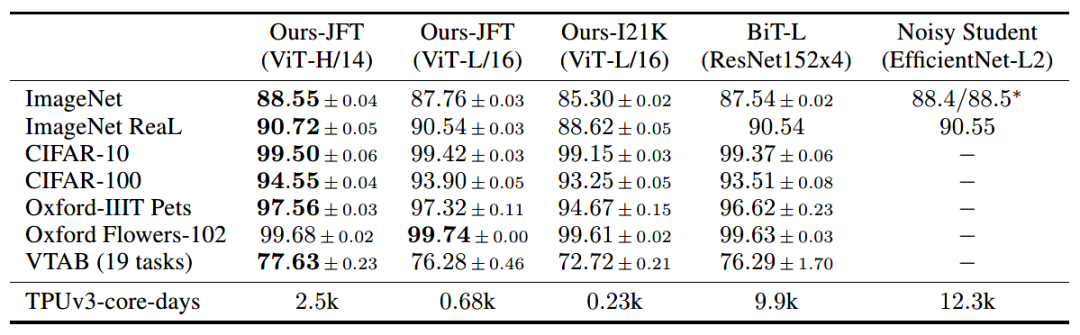
Se puede ver que después de que ViT se entrena previamente en un conjunto de datos grande, la tasa de precisión después de la migración en cada conjunto de datos pequeño supera los resultados de algunos modelos SOTA CNN. Pero para lograr este efecto de rendimiento más allá de la CNN, se requiere una combinación de grandes conjuntos de datos preentrenados y grandes modelos.
Entonces, el segundo experimento es ¿cuáles son los requisitos de ViT para el tamaño del conjunto de datos previo al entrenamiento? El artículo hace un experimento comparativo sobre este problema. El entrenamiento previo se realiza en ImageNet, ImageNet-21k y JFT-300M respectivamente. Los tres conjuntos de datos son conjuntos de datos pequeños, conjuntos de datos de escala media y conjuntos de datos muy grandes respectivamente. Los efectos del entrenamiento previo se muestran en la siguiente figura.
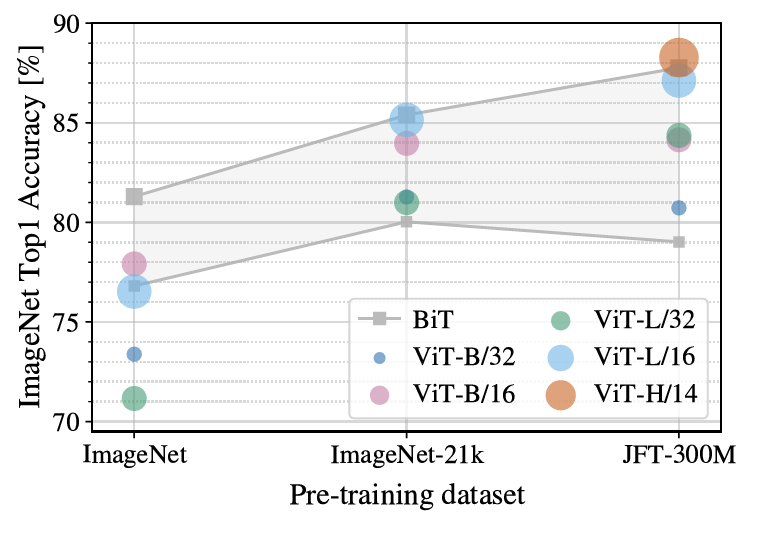
Como se puede ver en la figura, cuando se entrena previamente en el conjunto de datos más pequeño ImageNet, aunque el autor ha agregado una gran cantidad de operaciones de regularización, el rendimiento del modelo ViT-Large no es tan bueno como el modelo ViT-base, y es mucho peor que el desempeño de BiT. En el conjunto de datos ImageNet-21k de mediana escala, el rendimiento de todos es similar Solo en un conjunto de datos grande como JFT-30M, el modelo ViT puede ejercer sus ventajas y efectos.
En general, un gran conjunto de datos previo al entrenamiento junto con un modelo grande es el factor clave para que ViT logre el rendimiento de SOTA.
Uso e interpretación del código ViT
La implementación del modelo ViT actualmente tiene un marco de código abierto vit-pytorch al que se puede llamar directamente y se puede instalar directamente con pip:
pip install vit-pytorchEl uso de vit-pytorch es el siguiente:
import torch
from vit_pytorch import ViT
# 创建ViT模型实例
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# 随机化一个图像输入
img = torch.randn(1, 3, 256, 256)
# 获取输出
preds = v(img) # (1, 1000)Los significados de cada parámetro son:
image_size: tamaño de la imagen original
patch_size: el tamaño del parche de la imagen
num_classes: número de categorías
dim: tamaño de dimensión variable oculta del transformador
profundidad: capas de codificador de transformador
Cabezas: el número de cabezas en el MSA
tasa de deserción: inactivación
emb_dropout: relación de inactivación de la capa de incrustación
Centrémonos en la interpretación del código de vit.py. ViT se basa en Atención y Transformador, por lo que la lógica de construcción es la misma que la de Transformador.Después de construir los componentes subyacentes, se pueden empaquetar de acuerdo con el proceso de avance de ViT. Los componentes de construcción subyacentes requeridos por ViT incluyen la capa de normalización, FFN y Atención, y luego construyen el Transformador sobre la base de estos tres componentes, y finalmente construyen el ViT basado en el proceso de avance del Transformador y ViT. Veamos el proceso de construcción de ViT en tres pasos.
(1) La capa de normalización del componente subyacente, FFN, Atención
# 导入相关模块
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# 辅助函数,生成元组
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# 规范化层的类封装
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
# FFN
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
# Attention
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)(2) Transformador de construcción
# 基于PreNorm、Attention和FFN搭建Transformer
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x(3) Construir ViT
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
# patch数量
num_patches = (image_height // patch_height) * (image_width // patch_width)
# patch维度
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
# 定义块嵌入
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
# 定义位置编码
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
# 定义类别向量
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
# 定义MLP
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
# ViT前向流程
def forward(self, img):
# 块嵌入
x = self.to_patch_embedding(img)
b, n, _ = x.shape
# 追加类别向量
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
# 追加位置编码
x += self.pos_embedding[:, :(n + 1)]
# dropout
x = self.dropout(x)
# 输入到transformer
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
# MLP
return self.mlp_head(x)resumen
Como una investigación pionera de Visual Transformer, ViT puede considerarse como un documento de lectura obligada para comprender esta dirección. Desde la primera mitad de este año, se ha propuesto continuamente una gran cantidad de investigaciones de tareas visuales basadas en ViT, en las que ViT básicamente juega un papel similar a VGG16 o ResNet-52 en la columna vertebral de CNN. Aunque es un trabajo pionero, ViT todavía tiene muchas restricciones de uso, grandes conjuntos de datos y modelos grandes, estos dos puntos han desalentado a la mayoría de las personas. Por supuesto, estas deficiencias se han ido superando continuamente en investigaciones posteriores.
往期精彩:
深度学习论文精读[13]:Deeplab v3+
深度学习论文精读[12]:Deeplab v3
深度学习论文精读[11]:Deeplab v2
深度学习论文精读[10]:Deeplab v1
深度学习论文精读[9]:PSPNet
深度学习论文精读[8]:ParseNet
深度学习论文精读[7]:nnUNet
深度学习论文精读[6]:UNet++
深度学习论文精读[5]:Attention UNet
深度学习论文精读[4]:RefineNet
深度学习论文精读[3]:SegNet
深度学习论文精读[2]:UNet网络
深度学习论文精读[1]:FCN全卷积网络