El artículo "Una revisión de las arquitecturas de redes neuronales convolucionales y sus optimizaciones" señaló que con la profundización de la arquitectura de red, el problema de la desaparición, explosión o degradación del gradiente se vuelve cada vez más grave. La idea de conexiones entre capas es una solución eficaz a los problemas existentes, ya que permite a la red transferir información entre capas no adyacentes. Por lo tanto, en este artículo, se presentan principalmente las siguientes redes con ideas de conexión entre capas: Highway Networks, ResNet, Pyramidal Net, ResNext, DenseNet, CondenseNet, CSPNet, D3Net.

Tabla de contenido
2.4 Publicaciones de blog relacionadas
3.3 Publicaciones de blog relacionadas
4.4 Publicaciones de blog relacionadas
6.4 Publicaciones de blog relacionadas
7.2 Publicaciones de blog relacionadas
1.Redes de Carreteras
En 2015, la estructura de red (Highway Networks) propuesta por Rupesh Kumar Srivastava et al., inspirada en el mecanismo de puerta LSTM, resolvió el problema del entrenamiento de redes neuronales profundas. Highway Networks es una nueva estructura de red neuronal diseñada para resolver redes neuronales profundas. La red es difícil de entrenar. Highway Networks permite que la información pase a través de las capas de la red neuronal profunda a alta velocidad y sin obstáculos a través del mecanismo de puerta, lo que alivia efectivamente el problema de los gradientes, de modo que la red neuronal profunda ya no tiene el efecto de una red neuronal superficial. Las redes de carreteras se pueden entrenar directamente mediante descenso de gradiente estocástico y pueden utilizar una variedad de funciones de activación, lo que abre la posibilidad de estudiar arquitecturas extremadamente profundas y eficientes.
Documento: "Redes de Carreteras"
https://arxiv.org/pdf/1505.00387.pdf
Contribución: Introducir conexiones entre capas, asignando dos unidades de compuerta en una capa;
Desventajas: más recursos informáticos y mayor tiempo de formación;
2.ResNet
La propuesta de la red residual profunda (ResNet) es un hito en la historia de las imágenes de CNN. Cuando se publicó ResNet en 2015, ganó el primer lugar en cinco competencias como clasificación y detección de imágenes, y actualizó el modelo de CNN nuevamente. en ImageNet. Hasta el día de hoy, todavía se pueden ver conexiones residuales en todos lados en varios modelos de última generación, y sus citas en artículos ocupan el primer lugar en el campo del CV.
Él y otros propusieron ResNet utilizando la ruta de desvío en la red de carreteras e introdujeron el concepto de aprendizaje residual para resolver el problema de la degradación (rápida saturación de precisión, la tasa de error aumenta a medida que se profundiza). ResNet hereda la idea de conexión entre capas de la red de carreteras. La diferencia es que su mecanismo de activación está desbloqueado en lugar de aprenderse en todo momento, lo que ayuda a reducir en gran medida la complejidad de la red. A través de la conexión de acceso directo, ResNet pasa la entrada a través de capas y la agrega al resultado de la convolución, para entrenar completamente la red subyacente y mejorar significativamente la tasa de precisión.
2.1 Estructura residual
La llamada conexión residual se refiere a la suma de la salida de la capa superficial y la salida de la capa profunda como entrada de la siguiente etapa. El resultado de esto es que el peso de esta capa necesita aprender un mapeo de x a H(x). Después de usar el enlace residual, el mapeo que el peso necesita aprender pasa a ser de x -> H(x) - x, que es F(x). De esta manera, en el proceso de retropropagación, es más fácil que el gradiente de pequeña pérdida llegue a las neuronas poco profundas.
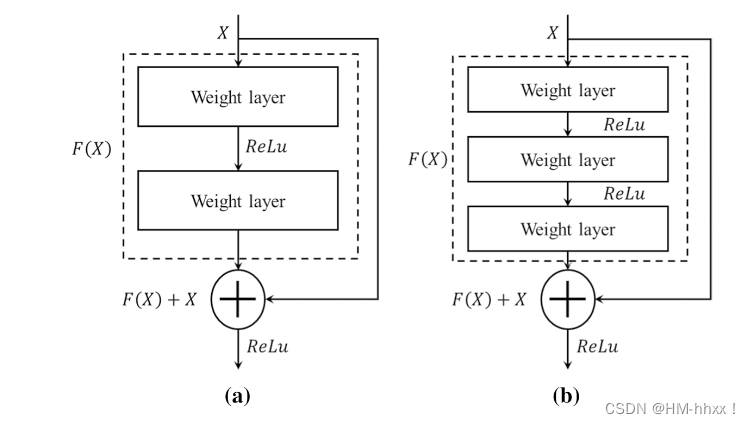
(Arquitectura del módulo residual: a. Enlace entre dos capas; b. Enlace entre tres capas)
La curva en el lado derecho de la figura se llama conexión residual (conexión residual). Al saltar frente a la función de activación, la salida antes de la capa anterior (o varias capas) se suma a la salida calculada por esta capa, y el resultado de la suma se ingresa a la función de activación como salida de esta capa.
2.2 Estructura de la red
La red ResNet se refiere a la red VGG19, que se modifica en función de ella, y el enlace residual que se muestra en la figura anterior se agrega a través del mecanismo de cortocircuito. Además, los cambios se reflejan principalmente en el hecho de que ResNet utiliza directamente la convolución de stride=2 para reducir la resolución (reemplazando la agrupación en VGG) y reemplaza la capa completamente conectada con la capa de agrupación promedio global (que puede recibir entradas de diferentes tamaños.imagen), y la capa del modelo se vuelve obviamente más profunda. La similitud es que ambos presentan extracción mediante el apilamiento de convoluciones 3X3.
Un principio de diseño importante de ResNet es: cuando el tamaño del mapa de características se reduce a la mitad, el número de mapas de características se duplica, lo que hasta cierto punto alivia la pérdida de información causada por la reducción del tamaño del mapa de características (en otras palabras, la información de entrada Las características se extraen de la dimensión espacial a la dimensión del canal).
Como se puede ver en la figura anterior, ResNet agrega enlaces residuales entre cada dos capas en comparación con las redes convolucionales ordinarias, donde la línea de puntos indica que la cantidad de mapas de características ha cambiado.
En el artículo original de ResNet, el autor proporcionó cinco niveles diferentes de estructuras de modelo, a saber, 18 capas, 34 capas, 50 capas, 101 capas y 152 capas. La figura anterior muestra la estructura del modelo de 34 capas. La siguiente figura muestra los parámetros estructurales de todos los modelos:
En la capa 50, los módulos residuales utilizados en las capas 101 y 152 son diferentes de los de las capas 18 y 3. La razón principal es que la cantidad de parámetros en la red profunda es demasiado grande. Para reducir los parámetros, la dimensión del canal se reduce mediante una convolución 1X1 antes de una convolución 3X3.
2.3 Artículos
论文:《Aprendizaje residual profundo para el reconocimiento de imágenes》
https://arxiv.org/pdf/1512.03385.pdf
Contribución: introdujo el módulo residual;
Defecto: la información de la característica se descarta en el proceso de avance;
2.4 Publicaciones de blog relacionadas
3.Red piramidal
Han y otros desarrollaron la red piramidal (red piramidal) en 2017. A diferencia de la fuerte disminución en el ancho espacial causada por el aumento de profundidad en ResNet, la red aumenta gradualmente el ancho de cada unidad residual. En cambio, la pirámide aditiva se usa para aumentar gradualmente la dimensionalidad, y también se usa un mapa de identidad conectado directamente y lleno de ceros para distribuir la presión que se concentra en una sola unidad residual debido a la reducción de muestreo a todas las unidades residuales. La red es más amplia, la precisión es muy alta, supera a DenseNet y está más generalizada.
3.1 Estructura de la red
1. Diagrama esquemático de varias estructuras residuales.

(a. Unidad residual básica; b. Unidad residual de cuello de botella; c. Unidad residual amplia; d. Unidad residual de pirámide; e. Unidad de cuello de botella residual de pirámide)
3.2 Artículos
Artículo: "Redes residuales piramidales profundas"
https://arxiv.org/pdf/1610.02915v4.pdf
Contribución: la red se va ampliando progresivamente;
Desventaja: alto costo de cálculo;
3.3 Publicaciones de blog relacionadas
Enlaces a artículos relacionados:
1. Colección de modelos CNN |18 PyramidNet-Zhihu ;
4.Resiguiente
La mayor contribución de ResNext radica en la actualización del bloque residual y adopta la estrategia de división, transformación y fusión , que es esencialmente convolución de grupo , pero no necesita diseñar manualmente estructuras complejas como Inception y no combina información de diferentes tamaños de campos receptivos. Al igual que Inception, ResNeXt topológicamente consistente también es más compatible con GPU y otro hardware (por lo que esta estructura se ejecuta más rápido). ResNeXt amplía aún más la arquitectura de la red, mejora la precisión del reconocimiento y reduce la cantidad de hiperparámetros sin aumentar la complejidad de la red.
Vale la pena señalar que la estrategia de división, transformación y fusión en realidad se refleja en la idea de apilamiento de VGG e Inception, pero la división de VGG es la función de transformación en sí, y ResNeXt e Inception son características de entrada divididas.
4.1 Arquitectura de red
1. Estructura del bloque ResNext:

(Izquierda: un bloque de ResNet; Derecha: bloque ResNext con cardinalidad = 32)
4.2 Convolución grupal
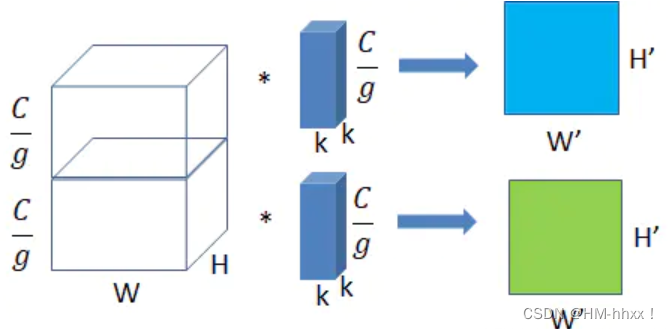
Convolución grupal: el prototipo de convolución grupal en realidad se remonta a AlexNet, el creador del aprendizaje profundo en 2012. Debido a las limitaciones del hardware en ese momento, el autor tuvo que dividir la operación de convolución para ejecutarla en dos GPU y los parámetros de las dos GPU no se compartieron. Si se utilizan g grupos, la cantidad de cálculo es 1/g de convolución ordinaria.
4.3 Tesis
论文:《Transformaciones residuales agregadas para redes neuronales profundas》
https://arxiv.org/pdf/1611.05431v2.pdf
Contribución: Introducir la convolución grupal;
Desventaja: alto costo de cálculo;
4.4 Publicaciones de blog relacionadas
5.Red densa
DenseNet es una arquitectura CNN con conexiones densas, que toma prestada la idea típica de conexiones entre capas en ResNet. Como Mejor Artículo de CVPR en 2017, DenseNet rompió con el pensamiento estereotipado de mejorar el rendimiento de la red profundizando el número de capas de red (VGG, ResNet) y ampliando la estructura de la red (GoogLeNet). Desde la perspectiva de las características, a través de la reutilización de características. y la configuración de derivación (Bypass), que no solo reduce en gran medida la cantidad de parámetros de la red, sino que también alivia el problema de dispersión de gradiente hasta cierto punto.
5.1 Arquitectura de red
1. Estructura de bloque denso:
La siguiente figura muestra un bloque denso de 5 capas con una tasa de crecimiento de k = 4. Cada capa toma todos los mapas de características anteriores como entrada.

2. Estructura de la red DenseNet (diagrama de estructura DenseNet)
Una DenseNet con 3 bloques densos. Las capas entre dos bloques adyacentes se denominan capas de transición y cambian el tamaño de los mapas de características mediante convolución y agrupación.
Cada capa en DenseNet está conectada a cada capa de manera anticipada, lo que mejora más a fondo el efecto de la convolución profunda entre capas. El bloque Hi en DenseNet es una función compuesta BN - ReLU - Conv, que consta de 3 operaciones consecutivas de BN, ReLU y convolución 3 × 3 (Conv). El módulo básico de DenseNet se llama Bloques Denso, y cada módulo toma como entrada los mapas de características de todos los Bloques Denso anteriores. A diferencia de ResNet, que utiliza suma directa, Dense Blocks combina múltiples entradas previas en serie. Esta forma de conexión permite un flujo de información y gradientes más eficientes entre redes, reduciendo significativamente la cantidad de parámetros de DenseNet.
5.2 Ventajas de la red
Varias ventajas de DenseNet:
-
1. Se redujo el gradiente de fuga (el gradiente desaparece)
-
2. Se mejoró la transferencia de funciones, haciendo un uso más eficaz de las funciones de diferentes capas.
-
3. La red es más fácil de entrenar y tiene cierto efecto regular.
-
4. Debido a que toda la red no es profunda, la cantidad de parámetros se reduce hasta cierto punto.
Desventajas: Ocupa memoria. Durante el proceso de cálculo, es necesario mantener el mapa de características poco profundo para poder unirlo con el mapa de características posterior. Aunque el número de parámetros es pequeño, hay muchos productos intermedios (mapas de características) en el proceso de entrenamiento.
5.3 Artículos
Título: "Redes convolucionales densamente conectadas"
https://arxiv.org/pdf/1608.06993.pdf
Contribución: flujo global de información entre capas;
Defecto: cálculo repetido de información de gradiente;
6.CondenseNet
Gao y otros modificaron DenseNet y propusieron una red ligera CondenseNet. La red integra métodos como convolución de grupo aprendido, conexión densa y poda. El autor agregó una nueva capa de índice para implementar la convolución agrupada de capas convolucionales posteriores y modificó el número de canales de entrada de las capas convolucionales de la red para aumentar exponencialmente. Además, CondenseNet extiende la aplicación del enfoque densamente conectado adoptado por DenseNet en bloques densos a cada capa de la red. Los experimentos muestran que CondenseNet supera a las redes ligeras de última generación MobileNet y ShuffleNet.
6.1 Arquitectura de red
Estructura de red:
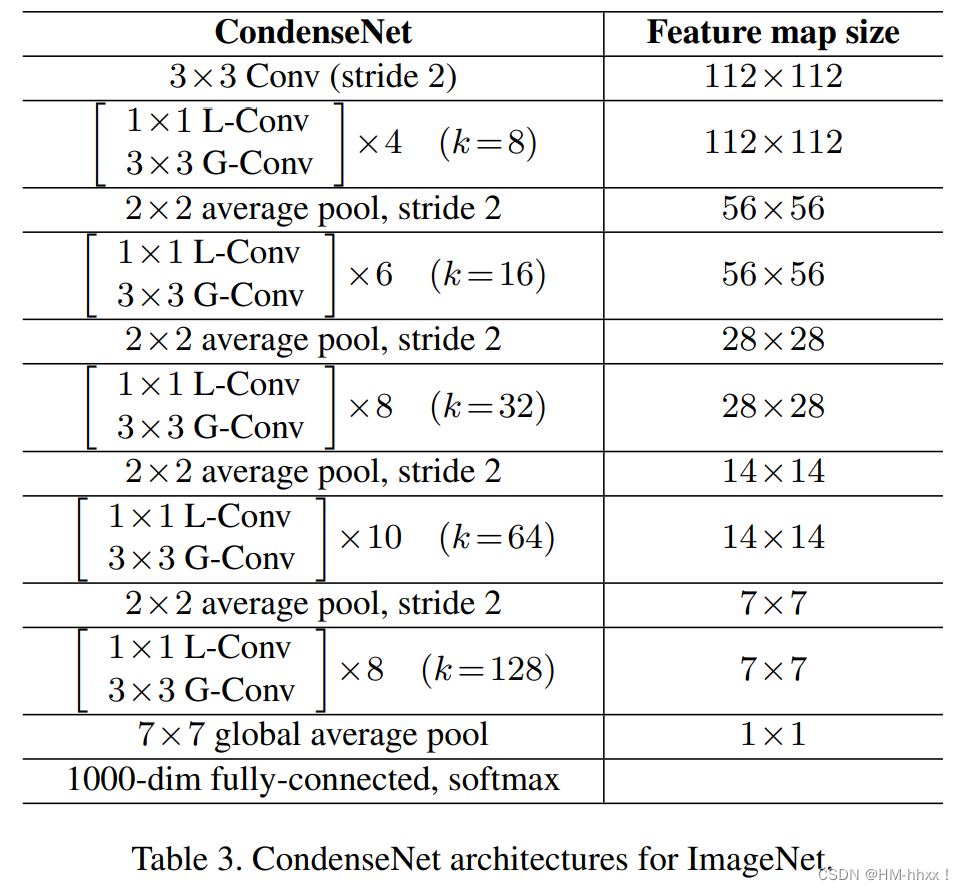
Donde L-Conv: convolución de grupo aprendida;G-Conv: convolución de grupo;
Convolución de grupo (G-Conv):
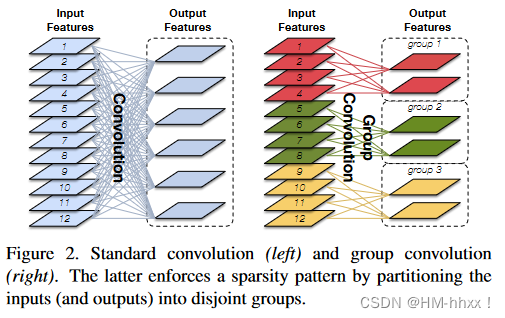
En la siguiente figura, la imagen de la izquierda es una operación de convolución normal y la imagen de la derecha es una operación de convolución de grupo. La sobrecarga de cálculo se puede reducir mediante la convolución de grupo. Si se utilizan G grupos para hacerlo, la cantidad de cálculo es 1/G de la convolución normal.
Convolución agrupada que se puede aprender (L-Conv):
En densanet, debido al uso de convolución 1 × 1, la cantidad de canales es grande, por lo que el autor usa convolución grupal para reducir la cantidad de cálculo.
L-Conv se puede dividir principalmente en tres etapas: etapa de condensación, etapa de optimización y etapa de prueba. La etapa de enriquecimiento se utiliza para eliminar funciones inútiles y la etapa de optimización se utiliza para optimizar la red eliminada.
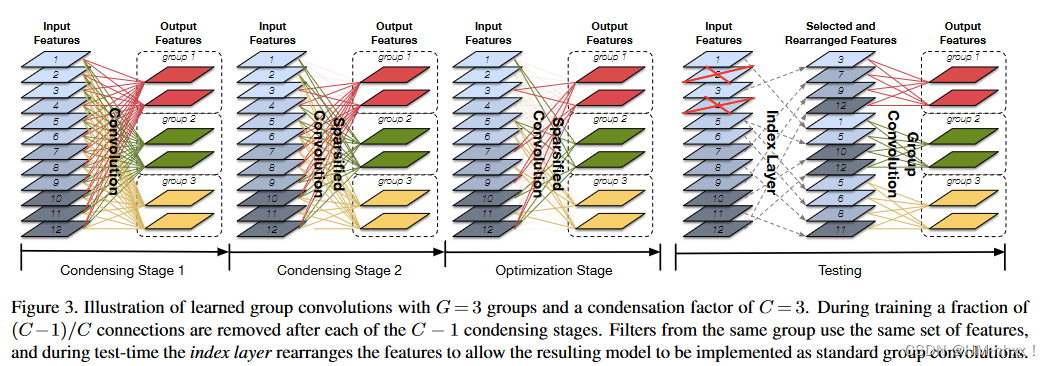
En la figura anterior, se ilustra una convolución de grupo aprendida con G = 3 y factor de condensación C = 3. Durante el proceso de entrenamiento, una parte de las conexiones (C-1)/C se eliminan después de cada etapa de condensación C-1, es decir, solo se mantienen las conexiones 1/C. Los filtros del mismo grupo utilizan el mismo conjunto de características y, durante las pruebas, la capa de índice reorganiza las características para permitir que el modelo resultante se implemente como una convolución de grupo estándar.
1. La condensación de la etapa 1 es un proceso de convolución ordinario; el término regular del lazo agrupado se utiliza al entrenar la red, de modo que las características aprendidas presentarán una distribución dispersa estructurada y la ventaja es que la parte de poda no afectará excesivamente la precisión;
2. La etapa de condensación 2 es la poda, que es el proceso de selección automática de grupos. CondenseNet con una tasa de concentración de C tendrá etapas de concentración C-1 y las características se podarán después de que se complete el entrenamiento de cada etapa de concentración. Es decir, después de la etapa de enriquecimiento C-1, las únicas características se conservan. La poda de CondenseNet no elimina directamente esta característica, sino que establece la característica podada en 0 en forma de máscara, por lo que durante el entrenamiento En el proceso de CondenseNet, el tiempo de CondenseNet no se ha reducido, pero se necesitará más memoria de video para guardar la máscara;
3. La etapa de optimización se realiza bajo la premisa de que se determina el grupo, es decir, se elimina el mapa de características de entrada que no es muy importante en cada grupo y se optimizarán individualmente los pesos de la red podada. Una vez completada la poda, la relación entre el número correspondiente de canales de entrada residuales en cada grupo y el número de todos los canales de entrada es el factor de enriquecimiento C. Como se muestra en la figura, hay 12 canales de entrada, si C se establece en 3, se debe reservar un tercio de los canales para cada grupo, es decir, 12/3 = 4. Y el proceso de poda también lo define C. Dado un factor de enriquecimiento C, la fase de enriquecimiento consta de pasos C-1, donde el primer paso es un entrenamiento de regularización escaso y regular y los pasos C-2 restantes se podan. Para cada etapa de enriquecimiento, corte 1/C del número de canales. Durante la fase de optimización, se vuelve a cortar 1/C. Por tanto, en la fase de entrenamiento sólo queda el canal 1/C;
4. La parte de Prueba es principalmente una operación de capa de índice y una operación de grupo regular. Después de la poda en el proceso de entrenamiento, obtenemos una estructura de coeficientes. En la actualidad, esta forma no se puede calcular en la forma de convolución de grupo tradicional. Si se usa la forma de máscara en el proceso de capacitación, el significado de poda ya no existirá. . Para resolver este problema, CondenseNet introdujo una capa de índice (capa de índice) durante la prueba, cuya función es reorganizar el mapa de características de entrada para facilitar la operación eficiente de la convolución del grupo.
6.2 Mejora de la estructura

1. Tasa de crecimiento exponencialmente creciente:
La capa convolucional de alto nivel puede depender más de las características de los niveles medio y alto, y menos de las características de la capa inferior. Para reflejar la importancia de las diferentes capas, el autor introduce una tasa de crecimiento k que aumenta exponencialmente. Se utiliza la misma k en el mismo bloque. A medida que aumenta el número de bloques, el valor de k aumenta exponencialmente. De este modo se fortalece la conexión de la capa cercana y se debilita la conexión de la capa lejana. Al aumentar gradualmente la tasa de crecimiento, una capa posterior recibe menos canales de salida de la capa inferior, mientras que recibe más canales de salida de la capa cercana.
2. Conexión totalmente densa:
En Densenet, la conexión densa solo existe dentro del bloque denso, y la conexión densa completa significa que cada capa tiene una relación de conexión densa con otras capas anteriores. Dado que los bloques densos tienen diferentes tamaños de características, cuando tomamos como entrada un mapa de características con un tamaño más alto, se reduce la muestra a una capa de menor tamaño utilizando la agrupación promedio.
6.3 Artículos
Resumen: 《CondenseNet: una DenseNet eficiente que utiliza convoluciones grupales aprendidas》
https://arxiv.org/pdf/1711.09224.pdf
Contribución: introducir convolución de grupo que se pueda aprender, conexión completamente densa y adoptar una tasa de crecimiento exponencial
Desventajas: el diseño de la red es complejo y requiere conjuntos de datos a gran escala;
6.4 Publicaciones de blog relacionadas
1. Blog de flores CondenseNet_Drunk Kan Chang'an-Blog CSDN
7.CSPNet
En 2019, Wang et al. creyeron que la red de DenseNet tiene una gran cantidad de información de gradiente que se reutiliza para actualizar los pesos de diferentes bloques densos, lo que significa que los bloques densos aprenden repetidamente la misma información (Wang et al. 2020a). Con esto en mente, propusieron una estructura de red llamada CSPNet que maximiza la diferencia en las combinaciones de gradientes agregando capas de transición parciales.
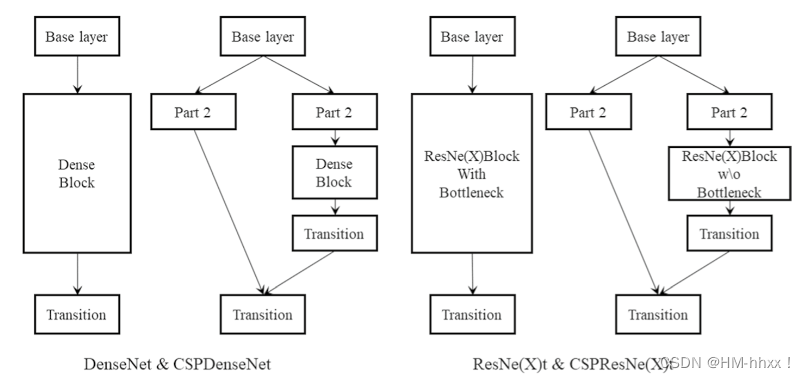
CSPNet divide el mapa de características en dos partes mediante la introducción de un módulo de conexión local entre etapas y realiza interacción de información entre las dos partes para mejorar la capacidad expresiva de las características.
La idea central de CSPNet es fusionar mapas de características de alta resolución y mapas de características de baja resolución mediante la introducción de conexiones locales en diferentes etapas de la red. Esta fusión puede capturar mejor información a diferentes escalas, mejorando así el rendimiento del modelo. CSPNet también adopta una estrategia de reordenamiento de rutas, que mejora aún más la capacidad expresiva del modelo al reorganizar los canales en el mapa de características.
El efecto de combinar CSPNet con diferentes backbones:
7.1 Tesis
论文:《CSPNet: una nueva columna vertebral que puede mejorar la capacidad de aprendizaje de CNN》
Contribución: capacidad de aprendizaje de CNN mejorada, la sensibilidad puede mantener la precisión al tiempo que es liviana, reducir los cuellos de botella informáticos y la duplicación de información de gradiente de DenseNet y reducir los costos de memoria
Defecto: Extracción optimizable de características multiescala;
7.2 Publicaciones de blog relacionadas
1. Análisis de aprendizaje profundo de CSPNet: se busca programador
2. Explicación detallada de CSPNET_Blog de leche pura de Beijing-Blog de CSDN
8.D3Net
En 2021, Takahashi y otros introdujeron una arquitectura de red de expansión múltiple densamente conectada (D3Net) para la tarea de predicción densa de alta resolución, combinando convolución multicapa con la arquitectura DenseNet para obtener una percepción aumentada exponencialmente en cada área de capa.
En las redes neuronales convolucionales tradicionales, cada capa convolucional generalmente solo está conectada al mapa de características de la capa anterior. Mientras que en una red convolucional multidilatada densamente conectada, la salida de cada capa convolucional se concatena con la salida de todas las capas anteriores. Este diseño densamente conectado facilita el flujo y la transmisión de información, lo que permite a la red conocer mejor los detalles y la información contextual de la imagen.
Además, la convolución de expansión múltiple es una técnica que introduce una tasa de dilatación en la operación de convolución. Al aumentar la tasa de agujeros del núcleo de convolución, se puede ampliar el tamaño del campo receptivo para capturar una gama más amplia de información contextual. La convolución multidilatada puede mejorar la capacidad de percepción del modelo sin aumentar los parámetros de la red ni el cálculo.
Las redes convolucionales multidilatadas densamente conectadas funcionan bien en tareas de predicción densas, como segmentación semántica, segmentación de instancias y segmentación de imágenes, etc. Puede extraer de manera eficiente características en imágenes y generar predicciones a nivel de píxeles.
En resumen, las redes convolucionales densamente conectadas y multidilatadas son un modelo poderoso para tareas de predicción densa, que combinan las ventajas de las convoluciones densamente conectadas y multidilatadas para procesar de manera eficiente datos de imágenes y generar resultados de predicción precisos.
8.1 Tesis
Descripción: "Redes convolucionales multidilatadas densamente conectadas para tareas de predicción densas"
Contribución: capacidad de aprendizaje de CNN mejorada, la sensibilidad puede mantener la precisión al tiempo que es liviana, reducir los cuellos de botella informáticos y la duplicación de información de gradiente de DenseNet y reducir los costos de memoria
Defecto: Extracción optimizable de características multiescala;