Directorio de artículos
I. Introducción
Documento: Aprender a mejorar imágenes con poca luz mediante un
código de estimación de curva profunda de referencia cero: https://github.com/Li-Chongyi/Zero-DCE_extension
Contribuciones en papel:
- Por primera vez, se propone una red mejorada con poca luz que no requiere datos de entrenamiento emparejados para evitar el riesgo de sobreajuste y generalizarse bien en diferentes condiciones de iluminación;
- Diseñe una curva de alto orden píxel por píxel que pueda realizar de manera eficiente un mapeo de brillo en un amplio rango dinámico a través de múltiples iteraciones;
- Demostrar el potencial de entrenar redes de aumento de imágenes mediante una función sin pérdida de referencia en ausencia de imágenes de referencia ;
- La red Zero-DCE propuesta puede mantener la capacidad de mejora al tiempo que reduce la carga computacional , proporcionando múltiples opciones para equilibrar la capacidad de mejora y la sobrecarga computacional.
2. Comprensión de algoritmos
2.1 Curva de mejora con poca luz
Inspirándose en la curva de ajuste de brillo en PS, el autor intenta diseñar una curva que asigne automáticamente una imagen con poca luz a una versión mejorada, y los parámetros de la curva adaptativa solo están relacionados con la imagen de entrada. Dado que es una curva de ajuste, es natural pensar en utilizar una red neuronal con una gran capacidad de ajuste para resolverla. El autor cree que dicha curva debería tener las siguientes propiedades:
- Cada valor de píxel de la imagen mejorada debe estar en el rango normalizado de [0,1] para evitar la pérdida de información causada por el truncamiento por desbordamiento;
- La curva debe ser monótona para preservar la diferencia entre píxeles adyacentes;
- La forma es lo más simple posible y se puede diferenciar en el proceso de retropropagación de gradiente;
Con base en las tres características anteriores, el autor diseñó la siguiente curva cuadrática:
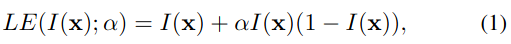
donde xxx representa las coordenadas de píxeles,α ∈ [ − 1 , 1 ] \alpha \in[-1,1]a∈[ -1 , _1 ] es un parámetro que se puede aprender y que controla tanto la progresión de la curva como el nivel de exposición. Cada píxel de entrada debe normalizarse a [0,1] y luego la curva se aplica a los tres canales de RGB en lugar de solo al canal de brillo, lo que puede preservar el color inherente y reducir el riesgo de sobresaturación.
Múltiples iteraciones de la fórmula (1) pueden obtener la curva de alto orden que se muestra en la fórmula (2), que puede manejar escenas con poca luz más desafiantes, nnn es el número de iteraciones, que en este artículo se establece en 8.
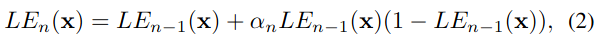
Si todos los píxeles de una sola imagen usan una curva, es equivalente a un mapeo global y es fácil causar sobreexposición o subexposición local. Si cada píxel de la imagen de entrada corresponde a una curva de alto orden, el problema se puede resolver y la operación es relativamente simple, como se muestra en la fórmula (3), el coeficiente α \alphaα se cambia a una matriz de coeficientesA \mathcal{A}A es suficiente, por lo que cada píxel tiene un coeficiente correspondiente.
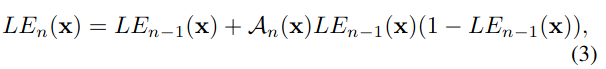
2.2 Marco general
El marco general es relativamente simple: ingresa una imagen RGB y genera 3 ∗ n = 3 ∗ 8 3*n=3*8 a través de DCE-Net3∗norte=3∗8 Un total de 24 mapas de coeficientes (3 canales en RGB), y luego cada matriz de coeficientes se sustituye en la fórmula para resolver iterativamente la imagen mejorada final.
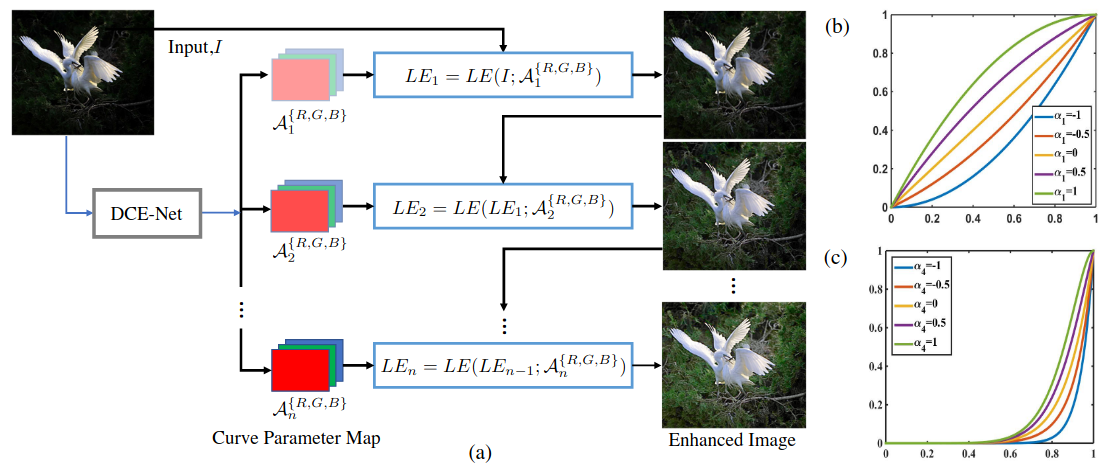
gráfico de coeficientesA \mathcal{A}En un ejemplo de A , se puede ver que para cualquier canal RGB, el valor del área brillante es relativamente pequeño y el valor del área oscura es grande.
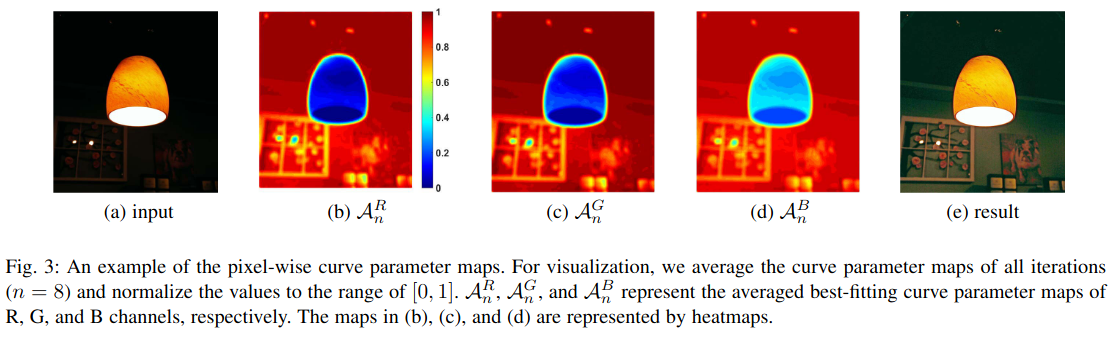
2.3 Estructura de la red
La estructura de la red también es muy simple. Solo hay 7 capas convolucionales en total y se agregan conexiones de omisión. Tenga en cuenta que la última convolución va seguida de la función de activación de Tanh para garantizar que los coeficientes de salida caigan en [-1,1]. rango. Debido a las 8 iteraciones, se aplican curvas separadas a los tres canales de RGB, por lo que el canal de salida es 24.

2.4 Función de pérdida
Dado que no existe una imagen de referencia, el autor diseña una función de pérdida total que consta de cuatro funciones de pérdida sin referencia desde las cuatro perspectivas de consistencia espacial, control de exposición, constancia de color y continuidad espacial.
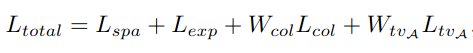
2.4.1 Consistencia espacial
La diferencia entre la imagen original y las regiones adyacentes de la imagen mejorada se mantiene lo más cercana posible para garantizar que la imagen mejorada sea espacialmente consistente con la imagen mejorada previamente.
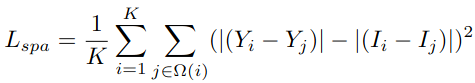
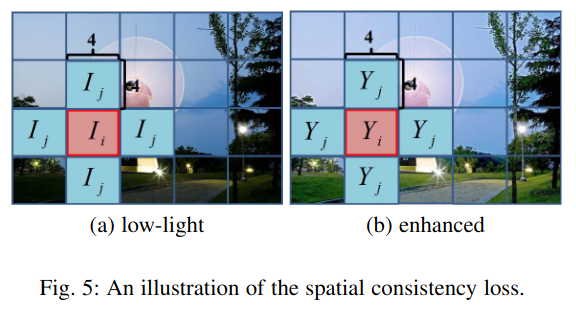
La siguiente figura puede explicar claramente la pérdida de consistencia espacial: la imagen original y la imagen mejorada se dividen en varias áreas locales con un tamaño de 4x4: I i − I j I_i-I_jIyo−Ij和Y i − Y j Y_i-Y_jYyo−Yjy calcula la diferencia entre los valores absolutos de los dos. (El código fuente abierto del autor también está escrito de manera muy clara, utilizando agrupación y convolución promedio)
2.4.2 Control de exposición
Para evitar la sobreexposición o subexposición en áreas locales, la imagen mejorada se divide en MMM áreas locales con un tamaño de 16x16, el brillo promedio de cada área localYYY está limitado aEECerca de E , el texto estableceE = 0,6 E=0,6mi=0,6
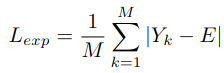
2.4.3 Constancia del color
Según la hipótesis del mundo en escala de grises, para una imagen con una gran cantidad de cambios de color, el valor promedio de los tres componentes de color de R, G y B tiende al mismo valor de escala de grises K. Para la imagen mejorada, los valores medios de los tres canales de R, G y B deben ser cercanos. Con base en esta suposición, el autor estableció una pérdida constante de color para garantizar que el color de la imagen mejorada sea normal. El formulario es relativamente simple: el MSE del valor promedio se calcula para cada uno de los tres canales y luego se suma.
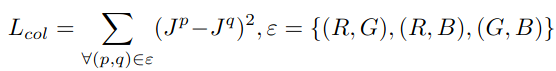
2.4.4 Suavizado de iluminación
Para mantener la relación monótona entre píxeles adyacentes, en cada mapa de parámetros de curva A \mathcal{A}Agregar una pérdida de suavizado de iluminación en A , que es la pérdida de variación total común, promueve la continuidad espacial de la imagen mejorada al limitar los gradientes horizontales y verticales.
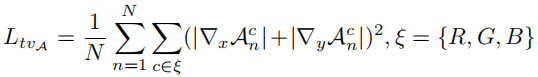
2.5 DCE cero++
Aunque la velocidad de Zero-DCE ya ha superado varios algoritmos de mejora de la luz oscura, el autor propuso una versión más ligera de Zero-DCE++ ajustando la estructura de la red, con solo 10k parámetros. Para una imagen con un tamaño de 1200×900×3, La inferencia de FPS en tiempo real en una sola GPU/CPU puede alcanzar 1000/11. Las mejoras son las siguientes:
- Reemplace las convoluciones ordinarias con convoluciones separables en profundidad;
- Los autores encuentran que el mapa de parámetros de la curva A \mathcal{A} para cada etapa de iteraciónA es similar en la mayoría de los casos, así que reduzca el número de mapas de parámetros de 24 a 3 y reutilice 3 mapas de parámetros por iteración para abordar la mayoría de los escenarios (A n \mathcal{A}_nAnortese convierte en A \mathcal{A}A , cada iteración usaA \mathcal{A}Una);
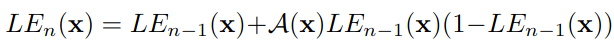
- El método propuesto no es sensible al tamaño de la imagen de entrada, por lo que la imagen reducida se puede utilizar como entrada de red y luego el mapa de parámetros de la curva de salida se muestra nuevamente a la resolución original para mejorar la imagen.