【Introducción】
【题目】:URetinex-Net: Retinex-based Deep Unfolding Network for Low-light Image Enhancement
【会议】:2022-CVPR
【机构】:深圳大学
【作者】:Wenhui Wu, Jian Weng, Pingping Zhang, Xu Wang, Wenhan Yang, Jianmin Jiang
【paper】:https://openaccess.thecvf.com/CVPR2022
【video】:https://www.youtube.com/watch?v=MJZ5HT1jGrA
【code_Pytorch】:https://github.com/AndersonYong/URetinex-Net【Hacer una pregunta】
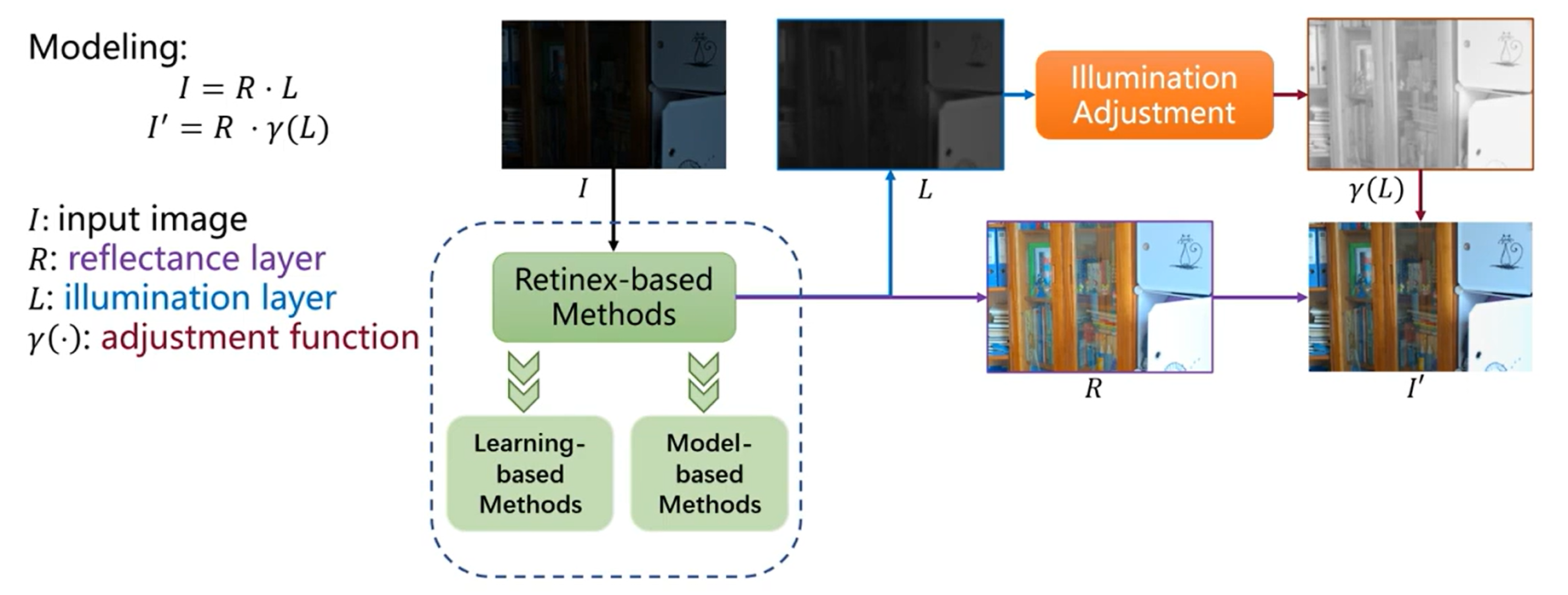
Los antecedentes hechos a mano y las soluciones impulsadas por la optimización comúnmente utilizadas por los métodos basados en modelos de Retinex conducen a una falta de adaptabilidad y eficiencia cuando se trata de imágenes con poca luz.
Métodos basados en modelos: al depender de antecedentes hechos a mano, el proceso de optimización lleva mucho tiempo.
Métodos basados en el aprendizaje: la inferencia guiada es rápida pero carece de interpretabilidad.
【solución】
Se propone una red de despliegue profundo basada en Retinex (URetinex-Net), que expande un problema de optimización en una red aprendible para descomponer imágenes con poca luz en capas de reflexión e iluminación. Al formular el problema de descomposición como un modelo de regularización previo implícito, se diseñan cuidadosamente tres módulos basados en el aprendizaje, responsables de la inicialización dependiente de los datos, la optimización eficiente del desenrollado y la mejora de la iluminación especificada por el usuario, respectivamente. En particular, el módulo de optimización de despliegue propuesto logra la supresión del ruido y la preservación de los detalles de los resultados de la descomposición final mediante la introducción de dos redes para adaptarse de manera adaptativa a los antecedentes implícitos de una manera basada en datos.
【Innovación】
- La URetinex-Net propuesta para el problema LLIE incluye tres módulos de aprendizaje: módulo de inicialización, módulo de optimización de expansión y módulo de ajuste de iluminación.
- Módulo de inicialización: estime simultáneamente la reflectancia y la iluminancia de la entrada a través de un método de aprendizaje en un marco unificado.
- Módulo de optimización expandido: expande un problema de optimización en una red aprendible, ajusta de forma adaptativa los antecedentes implícitos de una manera basada en datos y logra la supresión de ruido y la preservación de detalles del resultado de descomposición final.
- Módulo de ajuste de iluminación: mejora la iluminación de forma flexible con proporciones definidas por el usuario.
【Modelo de fórmula】


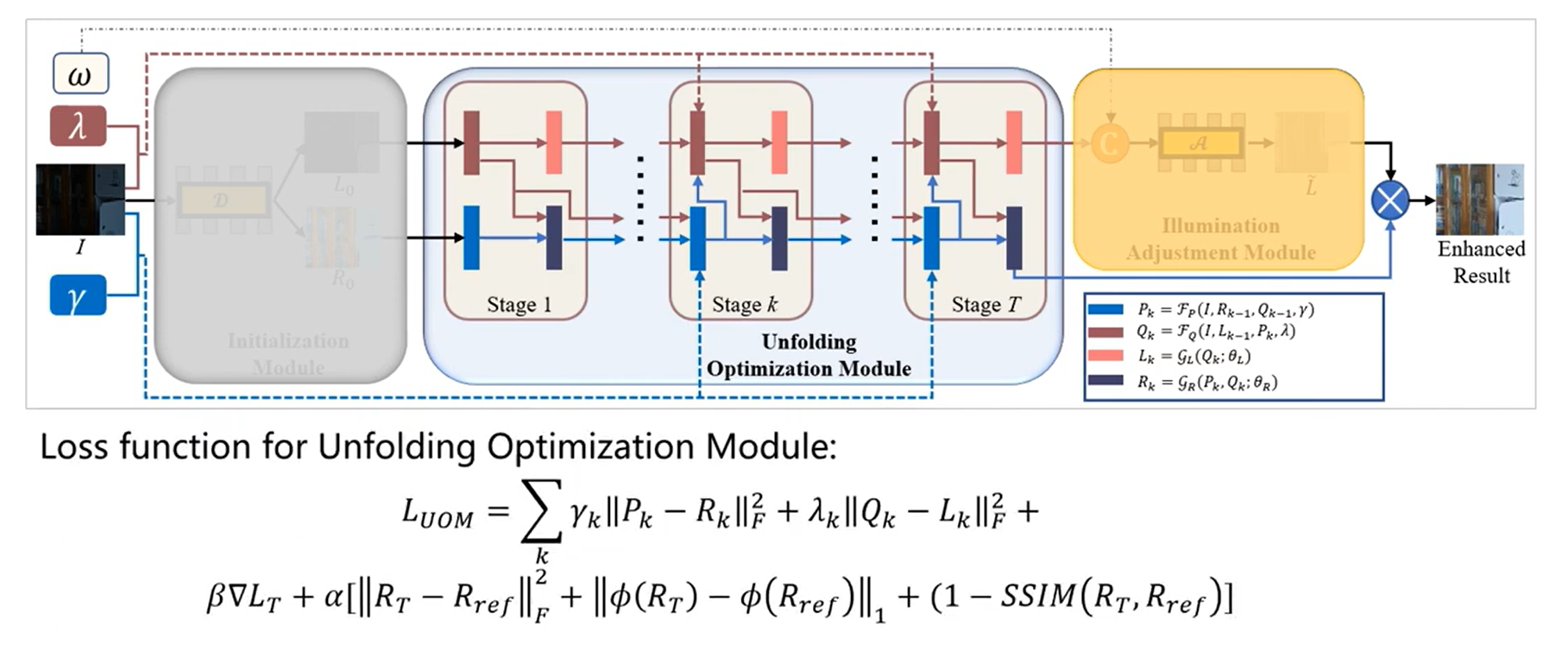
【Estructura de la red URetinex-Net】
URetinex-Net para problemas de LLIE consta de tres módulos de aprendizaje:
- Primero, el albedo inicial y la iluminación se generan al pasar la imagen del objetivo con poca luz al módulo de inicialización.
- Posteriormente, el módulo de optimización de despliegue refina iterativamente las capas de reflexión e iluminación (ß y ɻ son parámetros de penalización)
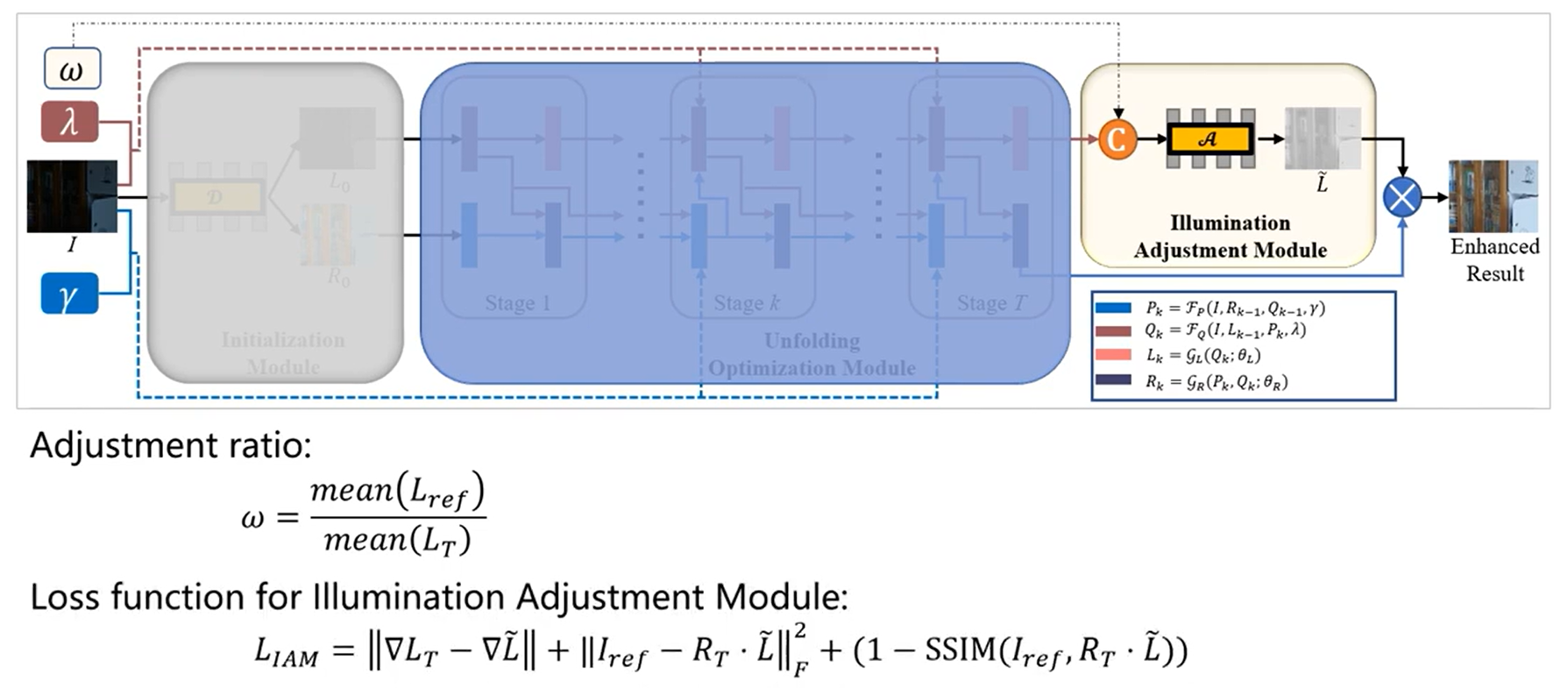
- Finalmente, el módulo de ajuste de iluminación emite la imagen mejorada de acuerdo con la escala w definida por el usuario.
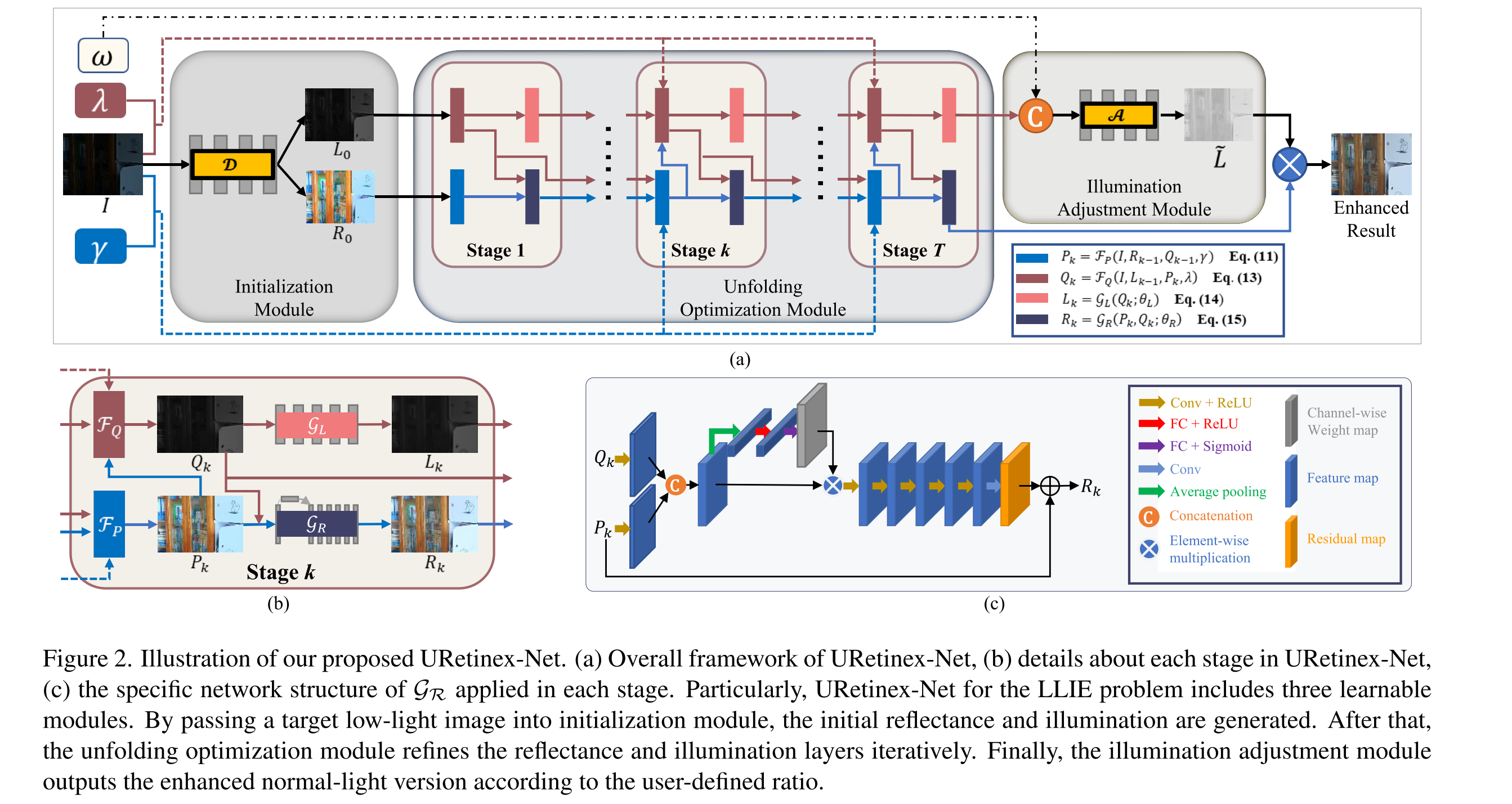
Figura 2 (a) El marco general de URetinex-Net, (b) los detalles de cada etapa en URetinex-Net, (c) la estructura de red específica de la red de eliminación de ruido GR aplicada en cada etapa.
Inicializar el módulo
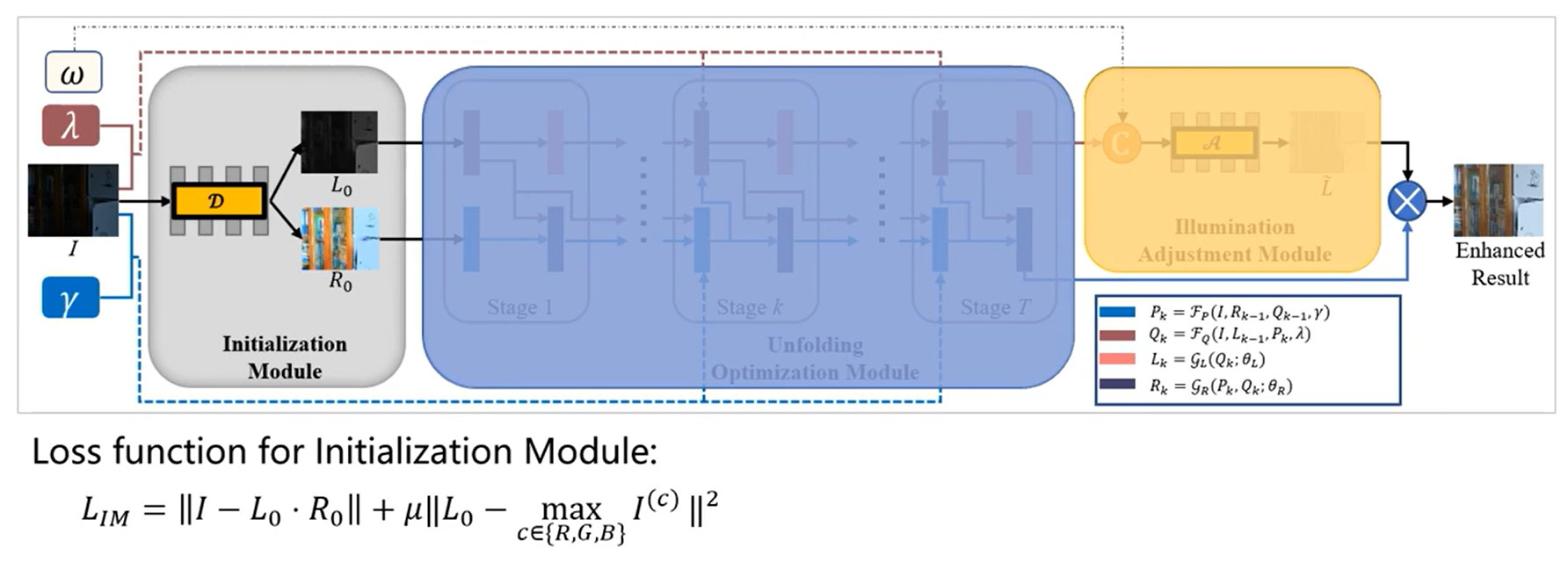
- Función de pérdida: el primer elemento es la pérdida de reconstrucción, y el segundo elemento es mantener la estructura general de I.
- Estructura: El módulo de inicialización consta de tres capas Conv+LeakyReLU seguidas de capas Conv y ReLU. El tamaño del núcleo de toda la capa convolucional se establece en 3*3.
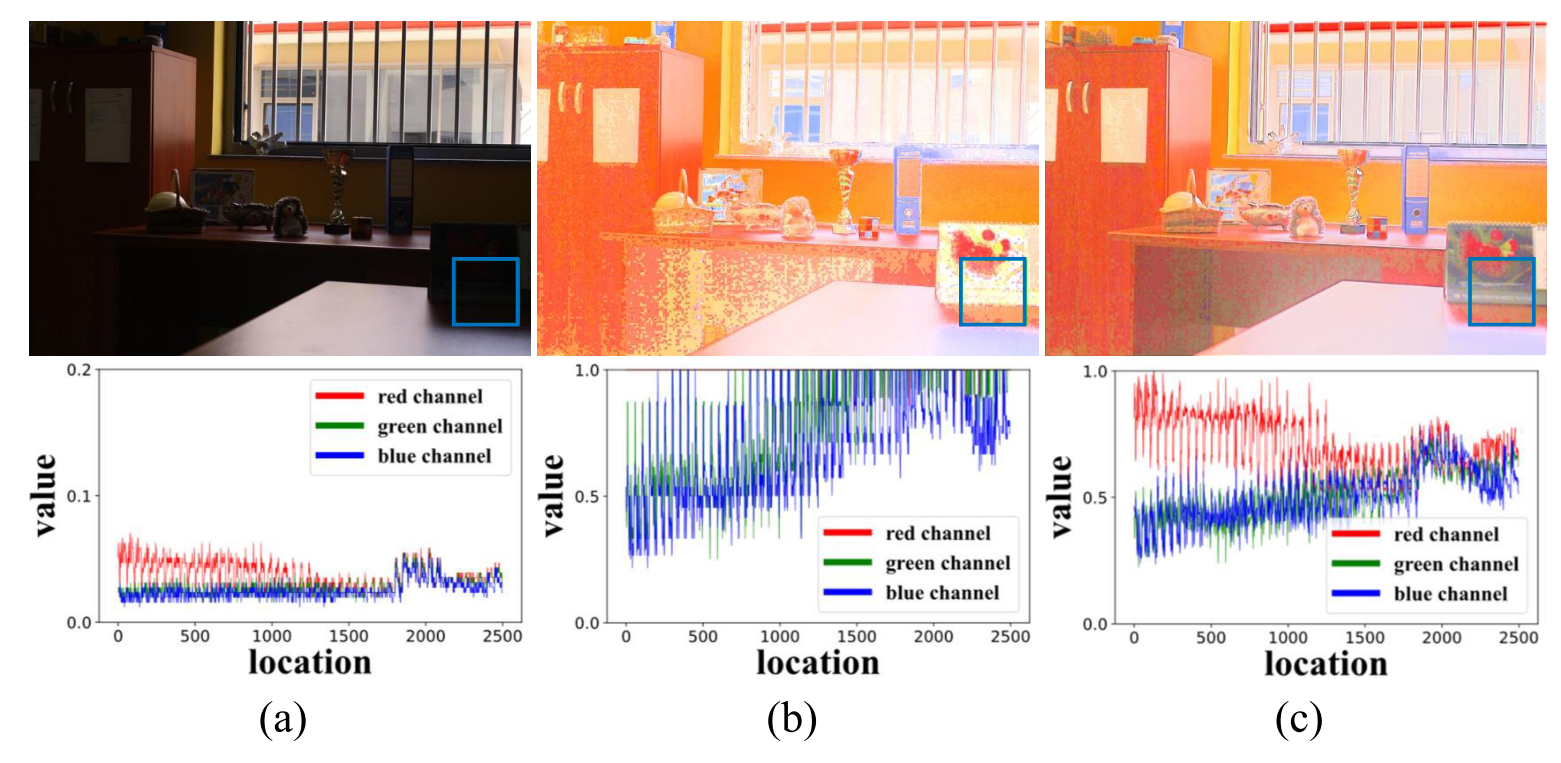
- Efecto: Figura 3: Características estadísticas de un parche en una imagen con poca luz Obviamente, la inicialización rígida (b) cambia las estadísticas de intensidad de los tres canales {R, G, B} de la imagen original con poca luz, mientras que la módulo de inicialización en este documento (c) están bien conservados.
Inicialización rígida: la iluminación inicial L0 se inicializa encontrando el valor máximo de los tres canales de color, y la reflectancia inicial R0 se puede derivar en consecuencia mediante R0=I/L0.
Ampliar el módulo de optimización
Propósito: Evitar el diseño de regularización explícito y restaurar de forma adaptativa la iluminación y la reflectancia en una forma de aprendizaje profundo.
Supervisado: La reflectancia de la imagen de luz normal se utiliza como referencia. La restricción de suavidad consciente de la estructura [34] se impone a la iluminación de la imagen de luz normal, y luego la función de pérdida de la descomposición de la imagen de luz normal es la siguiente:
![]()
Función de pérdida: el módulo de optimización desenrollado se entrena de manera integral, donde los parámetros y las arquitecturas de red de GR y GL se comparten en diferentes etapas. Durante la optimización de la red desplegada, la reflectancia de luz normal Rα generada por nuestro módulo de inicialización se usa como referencia. En términos de función de pérdida, utilizamos la suma de la función de pérdida de reflectividad e iluminancia, incluida la pérdida del error cuadrático medio (MSE) entre Pk y Rk en cada etapa, la pérdida de MSE, la pérdida de similitud estructural y la reflectividad de recuperación final RT La pérdida perceptual, la pérdida MSE entre Qk y Lk en cada etapa, y la pérdida de cambio total en Lk en cada etapa. La función de pérdida del módulo de optimización desplegado es la siguiente:
⌀(·) indica el extractor de características avanzado entrenado previamente en ImageNet por la red VGG19, y Rref indica la reflectancia de la imagen de luz normal.
Estructura: en lugar de introducir datos previos hechos a mano para diseñar manualmente una función de pérdida específica, se desarrolla un enfoque basado en el aprendizaje para explorar datos previos implícitos a partir de datos del mundo real. En otras palabras, se introducen dos redes denominadas GL y GR para actualizar L y R respectivamente.
La red simple totalmente convolucional de GL, que tiene cinco capas CONV, y luego aprende un previo implícito en L a través de la activación de RELU, de modo que el previo se puede aprender de los datos de entrenamiento y evitar el diseño de términos de regularización complejos.
Optimice los resultados de la descomposición de cada etapa del módulo desenrollado:

Módulo de ajuste de luz
Toma el nivel de luz bajo L y la relación de mejora específica del usuario w como entrada
Estructura: El módulo de inicialización consta de tres capas Conv+LeakyReLU seguidas de capas Conv y ReLU. El tamaño del núcleo de toda la capa convolucional se establece en 5*5.
[conjunto de datos, método de comparación, índice de evaluación]
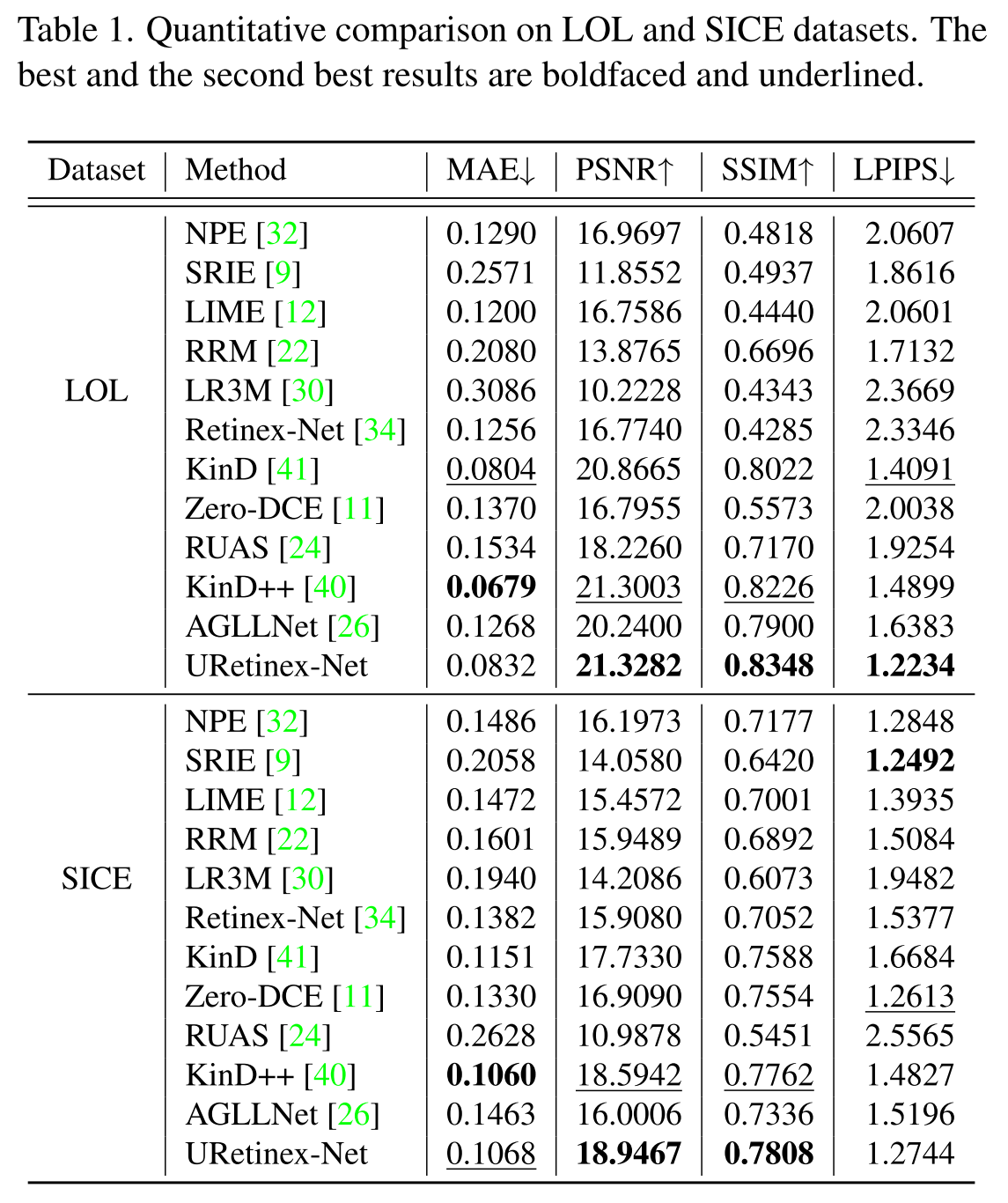
【Resultados experimentales】


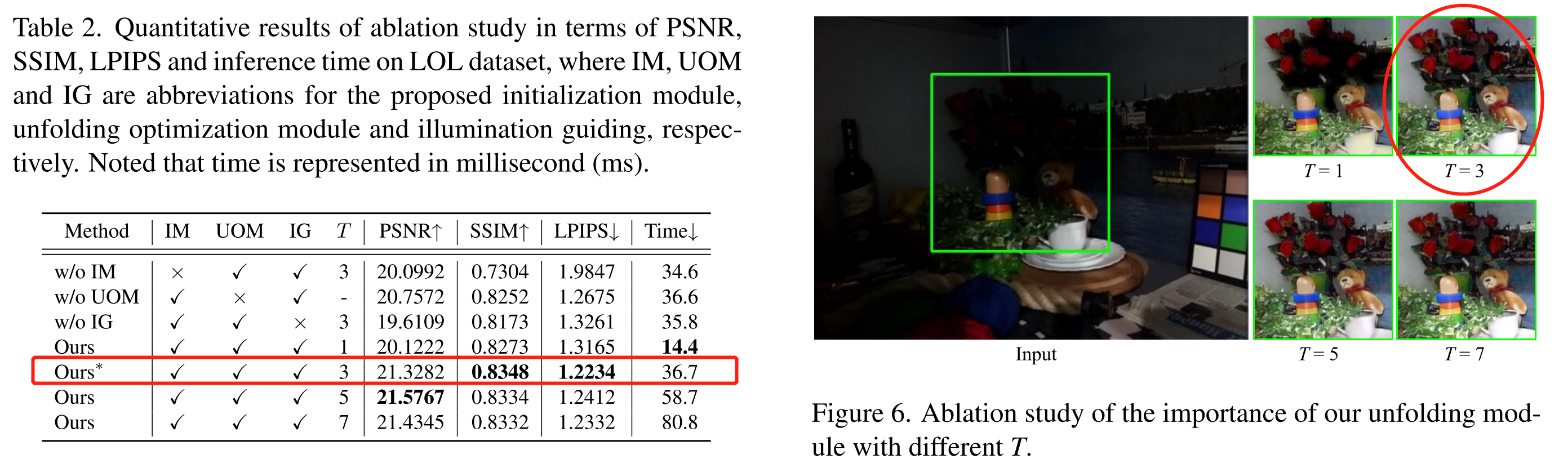
【Investigación de ablación】
Para ilustrar la efectividad del módulo de optimización de despliegue, simplemente apilamos las redes de tiempos GR y GL T y descartamos la optimización de despliegue , manteniendo la misma capacidad de red que URetinex-Net. Finalmente, se estudia el rendimiento de URetinex-Net bajo diferentes elecciones de etapa T.
Tabla 2: donde IM, UOM e IG son las abreviaturas del módulo de inicialización propuesto, el módulo de optimización y el módulo de iluminación, respectivamente.
Figura 6: Por comparación visual en la figura, todavía hay una conservación deficiente de los detalles y una distorsión del color en los resultados de mejora en T=1, mientras que se pueden obtener resultados más limpios utilizando la optimización de desenvolvimiento. En función del equilibrio entre la calidad de la imagen y el tiempo de inferencia, se elige T=3 como configuración predeterminada.