traducción de tesis
Resumen
Los seres humanos aprenden el lenguaje escuchando, hablando, escribiendo, leyendo e interactuando con el mundo real multimodal. Si bien los marcos de pre-entrenamiento de idiomas existentes demuestran la efectividad del aprendizaje autosupervisado basado en texto, este documento explora la idea de un modelo de lenguaje que utiliza la visión como una señal de supervisión. Encontramos que el principal impedimento para esta exploración es la gran diferencia de tamaño y distribución entre los conjuntos de datos de lenguaje basados en visión y los corpus de lenguaje puro. Por lo tanto, desarrollamos una técnica llamada "vokenización" para extender la alineación multimodal a los datos lingüísticos solo asignando contextualmente tokens lingüísticos a imágenes relevantes (que llamamos "vokens"). El "vokenizer" se entrena en un conjunto de datos relativamente pequeño de subtítulos de imágenes, que luego se aplica para generar vokens para grandes corpus de idiomas. Los modelos de lenguaje supervisados visualmente entrenados con estos vokens generados por contexto muestran mejoras consistentes en múltiples tareas de lenguaje puro como GLUE, SQuAD y SWAG.
1. Introducción
Al aprender a comprender el idioma, la mayoría de las personas utilizan múltiples modalidades, no solo texto y audio, y aprovechan especialmente las modalidades visuales. Como afirma Bloom (2002), señalar visualmente es un paso importante en el aprendizaje del significado de las palabras para la mayoría de los niños. Sin embargo, los marcos de preformación de idiomas existentes se basan en el aprendizaje del contexto y solo utilizan el contexto del idioma como autosupervisión. Por ejemplo, word2vec (Mikolov et al., 2013) usa una bolsa de palabras envolvente; ELMo (Peters et al., 2018) y GPT (Radford et al., 2018) usan contexto posterior; BERT (Devlin et al., 2019) usa tokens enmascarados aleatoriamente. Si bien estos marcos autosupervisados han logrado un gran progreso en la comprensión del lenguaje humano, no toman prestada información subyacente del mundo visual externo (consulte la motivación para el trabajo relacionado reciente de Bender y Koller (2020) y Bisk et al. (2020)).
En este artículo, presentamos un modelo de lenguaje supervisado visualmente que imita el aprendizaje del lenguaje humano con orientación visual (Bloom, 2002).
Como se muestra en la figura a continuación, el modelo toma tokens de idioma como entrada y utiliza imágenes asociadas con los tokens como supervisión visual. Nos referimos a estas imágenes como vokens (es decir, tokens visuales), ya que actúan como visualizaciones de los tokens correspondientes. Suponiendo que existe un gran conjunto de datos alineados de token-vokens, el modelo puede aprender la tarea de predicción de tokens de estos vokens.
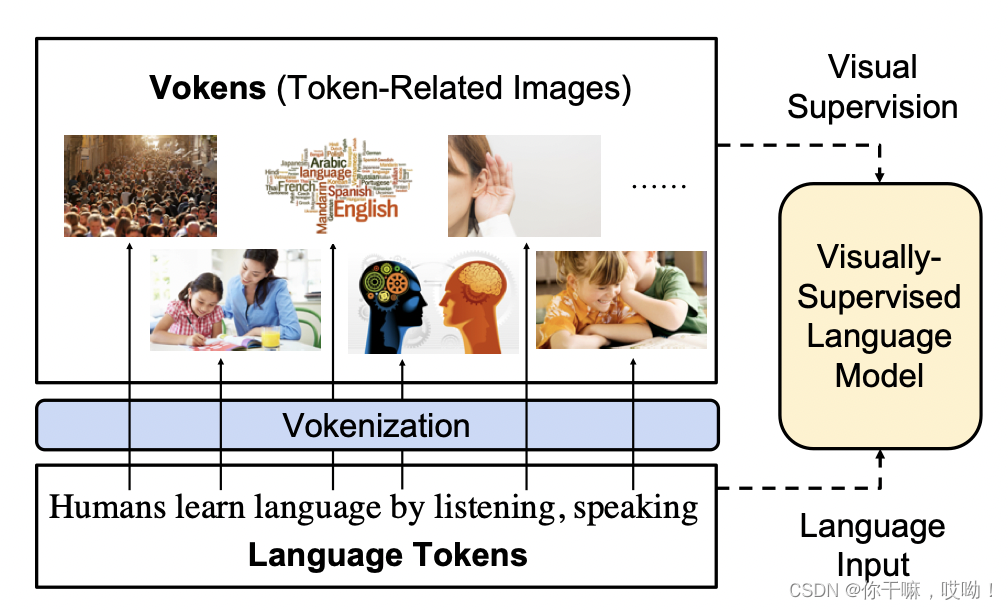
Desafortunadamente, todavía no existen conjuntos de datos alineados con marcadores vocales, por lo que la creación de conjuntos de datos con una correspondencia uno a uno entre la visión y el lenguaje sigue siendo un gran desafío.
2. Modelo de lenguaje visual supervisado
El aprendizaje de la representación del lenguaje contextual está impulsado por la autosupervisión sin considerar conexiones explícitas (base) con el mundo externo. En esta sección, presentamos la idea de un modelo de lenguaje supervisado visualmente y discutimos los desafíos de crearlo con supervisión visual.
2.1 Vokens: Fichas visuales
Para proporcionar supervisión visual para los modelos de lenguaje, asumimos la existencia de un corpus de texto donde cada token se alinea con una imagen asociada (aunque estas anotaciones vocales no existen actualmente, intentaremos generar vokens a través del proceso de vokenización en la Sección 3). Por lo tanto, estas imágenes pueden considerarse como visualizaciones etiquetadas, y las llamamos "vokens". En base a estos vokens, proponemos una nueva tarea de pre-entrenamiento del lenguaje: la clasificación de vokens.
2.2 Tarea de clasificación Voken
La mayoría de los modelos de columna vertebral del lenguaje (por ejemplo, ELMo (Peters et al., 2018), GPT (Radford et al., 2018), BERT (Devlin et al., 2019)) para oraciones s = wis = {w_i }s=wyoCada token genera una representación de características locales hi {h_i}hyo. Y sin modificar el esquema del modelo.
Supongamos que los vokens provienen del conjunto finito XXX , usamos una capa lineal y una capa softmax para ocultar la salidahi h_ihyoConvertir a distribución de probabilidad pi p_ipagyo, entonces la pérdida de clasificación vocal es la probabilidad logarítmica negativa de todas las vocales correspondientes:
h 1 , h 2 , . . . , hl = lm ( w 1 , w 2 , . . . , wl ) h_1,h_2,..., h_l =lm(w_1,w_2,...,w_l)h1,h2,... ,hyo=l m ( w1,w2,... ,wyo)
pi ( v ∣ s ) = softmaxv { W hi + b } p_i(v|s)=softmax_v \lbrace Wh_i+b\rbracepagyo( v ∣ s )=así que f t máxv{
W hyo+b }
LVOKEN − CLS ( s ) = − ∑ i = 1 llogpi ( v ( wi ; s ) ∣ s ) \mathcal{L}_{VOKEN-CLS}(s)=-\sum_{i=1}^llog p_i(v(w_i;s)|s)LV O K EN − C L S( s )=−yo = 1∑yoiniciar sesión _ _yo( v ( wyo;s ) ∣ s )
2.3 Pantalla
Esta tarea se puede integrar fácilmente en el marco actual de pre-entrenamiento de idiomas.El siguiente es el flujo de algoritmo del modelo de pre-entrenamiento de idiomas:
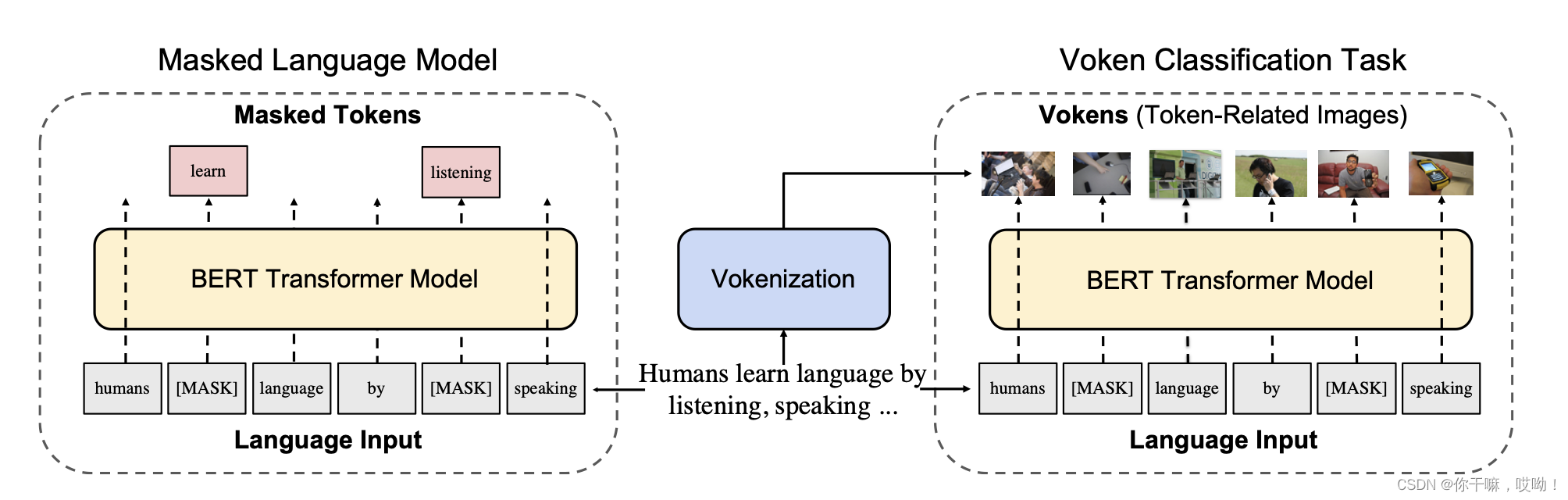
La figura anterior muestra un ejemplo de implementación de la tarea de clasificación vocal para BERT supervisado visualmente, que proporciona supervisión visual para BERT (Devlin et al., 2019). La tarea de entrenamiento previo BERT original se basa principalmente en cubrir el modelo de lenguaje: la parte principal del discurso se cubre aleatoriamente con una máscara, y el modelo necesita predecir estas partes faltantes del contexto del lenguaje.
Para simplificar, usamos ss respectivamentes ys ^ \ que ss^ indica el conjunto de fichas y el conjunto de fichas de máscara. parte desenmascaradasss ys ^ \ que ss^ El conjunto de diferencias se registra como:s \ s ^ s \backslash \hat ss \s^
Supongamos qi q_iqyoderecho iiLa distribución de probabilidad condicional de i marcas, la pérdida del modelo de lenguaje enmascarado (MLM) es la verosimilitud logarítmica negativa del token de máscara:
LMLM ( s , s ^ ) = − ∑ wi ∈ s ^ logqi ( wi ∣ s \ s ^ ) \ mathcal{L}_{MLM}(s,\hat s)=-\sum_{w_i \in \hat s}log q_i(w_i|s \backslash \hat s)LM L M( s ,s^ )=−wyo∈s^∑lo siento _ _yo( wyo∣ s \s^ )
Sin cambiar el modelo y la entrada del modelo, calculamos la pérdida de clasificación vocal para todos los tokens (como se muestra en el lado derecho de la Figura 2):
LVOKEN − CLS ( s , s ^ ) = − ∑ wi ∈ slogpi ( v ( wi ; s ) ∣ s \ s ^ ) \mathcal{L}_{VOKEN-CLS}(s,\hat s)=-\sum_{w_i \in s}log p_i(v(w_i;s)|s \backslash \que s)LV O K EN − C L S( s ,s^ )=−wyo∈ s∑iniciar sesión _ _yo( v ( wyo;s ) ∣ s \s^ )
El modelo de lenguaje de máscara supervisado visualmente suma las proporciones de estas dos pérdidas para obtener la función de pérdida final
LVLM ( s , s ^ ) = LVOKEN − CLS ( s , s ^ ) + λ LMLM ( s , s ^ ) \mathcal{ L}_{VLM}(s,\hat s)=\mathcal{L}_{VOKEN-CLS}(s,\hat s)+\lambda \mathcal{L}_{MLM}(s ,\que s)LV L M( s ,s^ )=LV O K EN − C L S( s ,s^ )+λL _M L M( s ,s^ )
donde λ es un hiperparámetro que controla el equilibrio entre la tarea de clasificación vocal y la tarea del modelo de lenguaje enmascarado. Este enfoque puede mejorar el rendimiento y la capacidad de generalización de los modelos de lenguaje.
Los dos desafíos de crear Vokens
El potencial para la supervisión externa utilizando Vokens existentes se presentó en las secciones anteriores. Sin embargo, actualmente carecemos de anotaciones densas desde tokens hasta imágenes. El concepto más similar a Vokens es la localización de frases (por ejemplo, en la entidad Flickr30K (Young et al., 2014; Plummer et al., 2017)). Debido al costoso proceso de recopilación de localizaciones de frases, la cobertura y el volumen de anotaciones no pueden cumplir con nuestros requisitos. Además de la localización de frases, las fuentes de datos más prometedoras son los conjuntos de datos de subtítulos de imágenes con asignaciones de oración a imagen (o que se encuentran en documentos multimodales, como en Hessel et al. (2019)). Los subtítulos de imágenes pertenecen a un tipo específico de lenguaje llamado lenguaje basado en entidades (Roy y Pentland, 2002; Hermann et al., 2017), que tiene una base explícita para la presencia externa o el comportamiento físico. Sin embargo, el lenguaje basado en entidades es muy diferente de otros tipos de lenguaje natural, como noticias, Wikipedia y libros de texto. Para ilustrar esto, enumeramos tres conjuntos de datos de subtítulos de imágenes en la Tabla 1 (es decir, MS COCO (Lin et al., 2014), Visual Genome (Krishna et al., 2017) y Subtítulos conceptuales (Sharma et al., 2018)) y claves estadísticas de tres corpus de idiomas para otros tipos de idiomas, a saber, Wiki103 (Merity et al., 2017), Wikipedia en inglés y CNN/Daily Mail (See et al., 2017).
Vokenización
En esta sección, desarrollamos un marco que puede generar vokens. La idea básica es aprender un "vokenizador" a partir de un conjunto de datos de imagen y texto y usarlo para anotar un gran corpus de idioma (es decir, Wikipedia en inglés), cerrando así la brecha entre el idioma base y otros tipos de lenguaje natural. Primero ilustramos el proceso de vokenización y luego describimos cómo implementarlo.
3.1 Proceso de Vokenización
Como se muestra en la figura anterior, la vocalización es la oración s = (w 1 , w 2 , . . . , wl ) s = (w_1, w_2, ..., w_l)s=(w1,w2,... ,wyo) para cada token wi w_ienwyoAsigne una imagen relacionada v ( wi ; s ) v(w_i; s)v ( wyo;s ) proceso. Tomamos esta imagenv ( wi ; s ) v(w_i; s)v ( wyo;s ) se llama "voken" (token de visualización).
En lugar de usar un modelo generativo para crear esta imagen, comenzamos con un conjunto de imágenes X = x 1 , x 2 , . . . , xn X = {x_1, x_2, ..., x_n}X=X1,x2,... ,xnFunción de puntuación de recuperación y correlación de imagen de marcador r θ ( wi , x ; s ) r_θ(w_i,x; s)ri( wyo,x ;s ) imágenes relacionadas. Esto está dado porθ θθ función de puntuación parametrizadar θ ( wi , x ; s ) r_θ(w_i,x; s)ri( wyo,x ;s ) , mida la marcawi w_iwyoe imagen xxCorrelación entre x .
Suponemos que el parámetro óptimo de esta función es θ ∗ θ*θ ∗ ,v ( wi ; s ) v(w_i; s )
asociado con la oración sv ( wyo;s ) se realizan maximizando su puntaje de correlaciónr θ r_θriImagen x ∈ X x \in XX∈X:
v ( wi ; s ) = argmaxx ∈ V r θ ∗ ( wi , x ; s ) v(w_i;s)= argmax_{x \in V}r_θ * (w_i,x;s)v ( wyo;s )=a r g máx _x ∈ Vri∗( wyo,x ;s )
Gracias al conjunto de imágenes xxX en realidad crea un vocabulario limitado para vokens, por lo que podemos aprovechar la tarea de clasificación de vokens para supervisar visualmente el entrenamiento de modelos de lenguaje. A continuación, discutiremos la implementación detallada de este proceso de vokenización.
3.2 Modelo de coincidencia de token de contexto e imagen
El núcleo del proceso de votanización es un modelo contextual de emparejamiento Token-Image.
El modelo comienza con una oración sss y una imagenxxx como entrada, y la oraciónsss consta de una serie de tokens{ w 1 , w 2 , . . . , wl } , \lbrace w_1,w_2,...,w_l \rbrace,{ w1,w2,... ,wyo} , composición.
输出r θ ( wi , x ; s ) r_θ(w_i,x;s)ri( wyo,x ;s )是tokenwi ∈ s w_i \in swyo∈Puntuación de afinidad entre s y la imagen x considerando la oración completa sss como contexto.
Modelado para construir la función de puntaje de relevanciar θ ( wi , x ; s ) r_θ(w_i,x;s)ri( wyo,x ;s ) modelo,
Lo descomponemos en representación de características lingüísticas f θ ( wi ; s ) f_θ(w_i;s)Fi( wyo;s ) y representación de características visualesg θ ( x ) g_θ(x)gramoiProducto interior de ( x ) :
r θ ( wi , x ; s ) = f θ ( wi ; s ) T gramo θ ( x ) r_θ(w_i,x;s) = f_θ(w_i;s)^Tg_θ(x)ri( wyo,x ;s )=Fi( wyo;s )Tg _i( X )
Estas dos representaciones de características son generadas por codificadores lingüísticos y visuales, respectivamente. El codificador de lenguaje primero usa el modelo BERTBASE previamente entrenado (Devlin et al., 2019) para token discreto { wi } \lbrace w_i\rbrace{ wyo} contexto incrustado en el vector de salida oculto{ hola } \lbrace hola \rbrace En { hola } :
h 1 , h 2 , . . . , hl = bert ( w 1 , w 2 , . . . , wl ) h_1,h_2,...,h_l = bert(w_1,w_2,...,w_l)h1,h2,... ,hyo=bert ( w _ _1,w2,... ,wyo)
Luego aplicamos un perceptrón multicapa (MLP) wmlp θ w{mlpθ}w m lpθ par salida ocultahola h_ihyoRealizar reducción de dimensionalidad. Para simplificar el proceso de recuperación en la Sección 3.1, las características lingüísticas finales se normalizan a un vector de la norma 1 dividiendo su norma euclidiana por su propio valor:
f θ ( wi ; s ) = wmlp θ ( hola ) ∣ ∣ wmlp θ ( hola ) ∣ ∣ f_θ(w_i;s) = \frac{w_{mlpθ}(h_i)}{||w_{mlpθ}(h_i) ||}Fi( wyo;s )=∣∣ conm lpθ( hyo) ∣∣wm lpθ( hyo)
Por otro lado, el codificador visual primero extrae incrustaciones visuales del ResNeXt previamente entrenado (Xie et al., 2017). Similar al codificador de idioma, luego aplique la capa MLP xmlp θ x_{mlpθ}Xm lpθy capa de normalización L2:
e = R es N e X t ( x ) e=ResNext(x)mi=R es norte mi Xt ( x )
gramo θ ( x ) = xmlp θ ( mi ) ∣ ∣ xmlp θ ( mi ) ∣ ∣ g_θ(x)=\frac{x_{mlpθ}(e)}{||x_{mlpθ }(e)||}gramoi( X )=∣∣x _m lpθ( mi ) ∣∣Xm lpθ( e )
tren
Dado que las anotaciones densas de tokens a imágenes no existen y son difíciles de generar, elegimos entrenar modelos de coincidencia de token e imagen a partir de conjuntos de datos de subtítulos de imágenes supervisados débilmente, como MS COCO (Lin et al., 2014). Estos conjuntos de datos consisten en pares de oraciones e imágenes ( sk , xk ) (s_k,x_k)( sk,Xk) , donde la oraciónsk s_kskdescribe la imagen xk x_kXkcontenido visual en .
Para establecer la correspondencia entre tokens e imágenes, ponemos la oración sk s_kskTodos los marcadores en la imagen xk x_kXkpar. A continuación, se optimiza el modelo, sin pérdida de generalidad, maximizando la puntuación de correlación entre estos pares alineados de marcador-imagen y los pares no alineados.
Supongamos ( s , x ) (s,x)( s ,x ) es el punto de datos del texto de la imagen, seleccionamos aleatoriamente otra imagenx ′ x′x ′ , satisfaciendo la condiciónx ′ ≠ xx′≠xx '=x _ Luego usamos la pérdida de bisagra para optimizar los pesosθ θθ tal que el par positivo etiqueta-imagenr θ ( wi , x ; s ) r_θ(w_i,x;s)ri( wyo,x ;s ) es al menos mejor que el par negativor θ ( wi , x ′ ; s ) r_θ(w_i,x′;s)ri( wyo,x ' ;s )高一个实方M。
L θ ( s , X , X ′ ) = ∑ yo = 1 lmax { 0 , METRO − r θ ( wi , X ; s ) + r θ ( wi , X ′ ; s ) } \ mathcal{L}_θ(s,x,x′)=\sum_{i=1}^l max \lbrace0,M−r_θ(w_i,x;s)+ r_θ(w_i,x′;s)\rbraceLi( s ,x ,x ' )=yo = 1∑yomáximo x {
0 ,METRO−ri( wyo,x ;s )+ri( wyo,x ' ;s )}
Intuitivamente, esta pérdida de bisagra max { 0 , M − pos + neg } max \lbrace 0, M−pos + neg\rbrace se minimiza cuando la diferencia de puntuación es menor que el borde Mmáx { 0 ,METRO _ −pos _+ne g } intentará aumentar la puntuación de los pares positivos y disminuir la puntuación de los pares negativos. De lo contrario (si la diferencia ≥ M límite), ambas puntuaciones permanecen sin cambios.
razonamiento
Dado que la puntuación de relevancia se descompone en una representación característica f θ ( wi ; s ) f_θ(w_i;s)Fi( wyo;s )和g θ ( v ) g_θ(v)gramoi( v ) , por lo que el problema de recuperación de la Sección 3.1 se puede formular como una búsqueda máxima del producto interno (Mussmann y Ermon, 2016). Además, dado que los vectores son norma-1, el vector con el producto interno más grande es el mismo que el vector más cercano en el espacio euclidiano (es decir, el vecino más cercano (Knuth, 1973)).