cálculo
El cálculo me enseñó por qué el área de una elipse = π \piπ ab.

Regla de derivación de funciones implícitas
¿Cómo entender la función extrema de Lagrange?
Todas las cosas se pueden integrar (¿todas las funciones pueden encontrar la función original?) - el número es el universo
Álgebra lineal
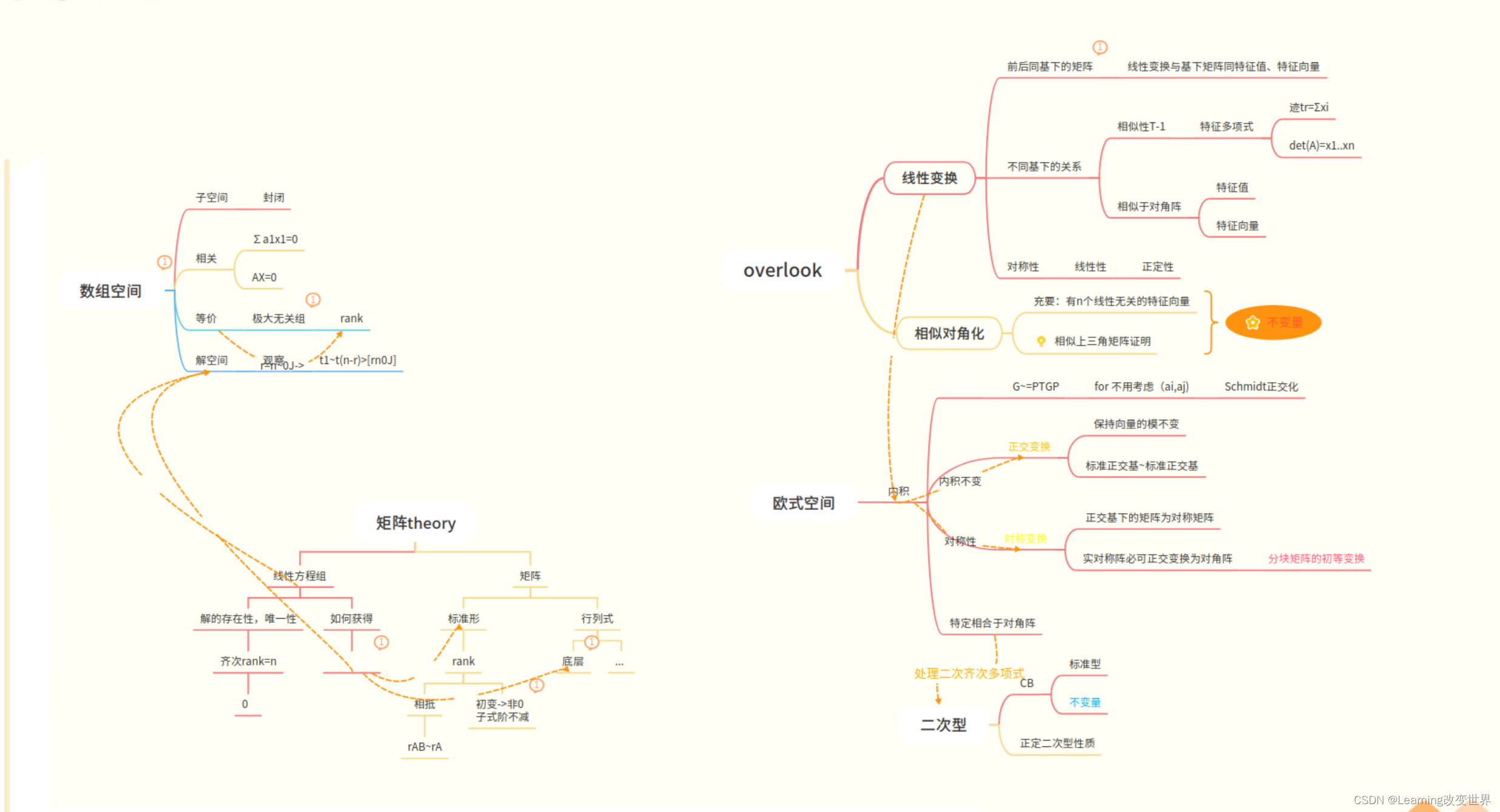
- Sin duda, Gitmind&Blog es el mejor lugar para tomar notas!
teoría de probabilidad
- ¿Qué es la distribución binomial negativa?
- La función de las tres principales variables de distribución, media, varianza: la esencia es el cálculo, el punto clave es la memoria (comprensión)
- Distribución chi-cuadrado, originada en τ \tauτ函数——τ ( x ) = ∫ 0 + ∞ e − ttx − 1 dt \tau(x)=\int_0^{+\infin} e^{-t}t^{x-1}dtt ( x )=∫0+ ∞mi- t tx − 1 ret,prop1:τ ( x + 1 ) = x τ ( x ) \tau(x+1)=x\ \tau(x)t ( x+1 )=x τ ( x )
producirkn ( x ) = mi − x / 2 x − ( norte − 2 ) / 2 τ ( norte / 2 ) 2 norte / 2 k_n(x)=\frac{e^{-x/2 }x^{-(n-2)/2}}{\tau(n/2)2^{n/2}}kn( X )=τ ( norte /2 ) 2n /2mi− x /2 x− ( norte − 2 ) / 2, registrado como xn 2 x_n^2Xnorte2, satisfaciendo la ley de la adición;
Demostración: la densidad de probabilidad del cuadrado de la distribución normal es la misma que la de la distribución chi-cuadrada de primer orden , y la densidad de probabilidad de la distribución normal es la misma que la de la distribución chi-cuadrada por inducción en la cálculo;
inclusión 1:Xi corresponde con la distribución del índice,2 λ X i \lambda X_iλ Xyocumple con x 2 2 x_2^2X22
- Distribución chi-cuadrado seguida de distribución T y distribución F
- La distribución normal es la suma de variables independientes e idénticamente distribuidas (y otras estadísticas) en n n → + ∞ n\rightarrow +\infinnorte→+ una aproximación de ∞
Estadística Matemática

tubería común:
- Dada la distribución variable, muestra conocida, parámetros estimados (estimación puntual) o parámetros de juicio (prueba paramétrica); la
estimación bayesiana obtiene el valor estimado ← \leftarrow← suma de probabilidades condicionales = 1 - La distribución de parámetros y variables es conocida (o forzada por el método de muestra grande/beyas), y el intervalo de muestra se estima de acuerdo con una probabilidad dada (estimación de intervalo);
- También es posible juzgar la confianza de la distribución de variables (prueba de bondad de ajuste) cuando se conocen los parámetros y las muestras.
- 3 pivotes visibles = distribución variable, parámetro, muestra
- Las tres distribuciones principales nacen para la posterior estimación de intervalos y pruebas de parámetros.
- ¿Cómo estimar bayesiana la varianza de la distribución normal?
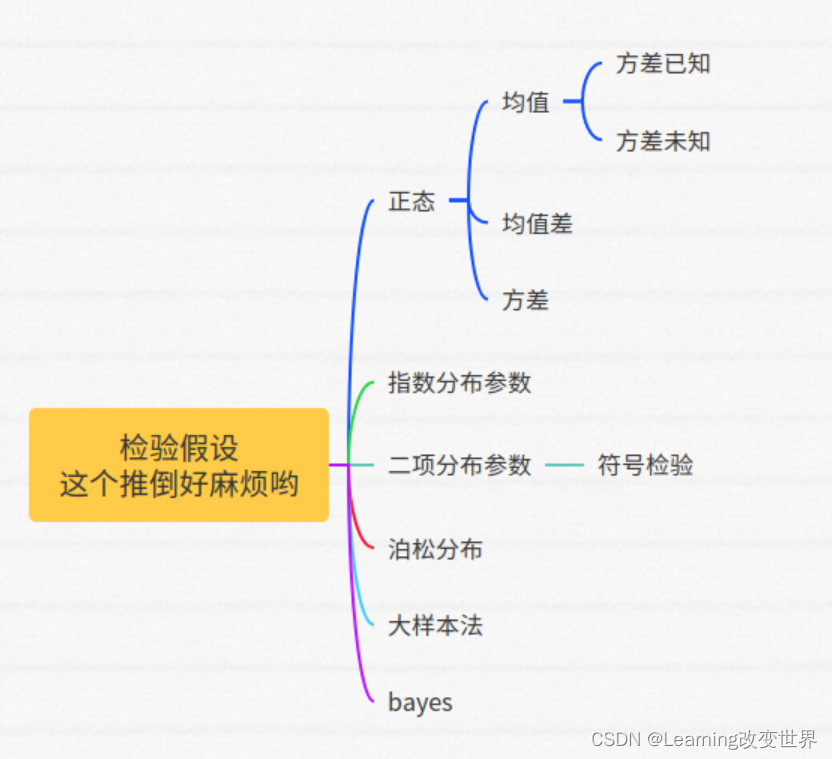
Proceso de (especificar nivel α \alphaα da una prueba de la hipótesis para el parámetro):
- Dada una muestra y supuestos (distribución de variables)
- Error tipo I = Los parámetros se ajustan a la distribución, pero la muestra se desvía de la norma
- Representa el primer tipo de probabilidad de error (según la hipótesis dada H y la prueba con la pelota ( X ‾ ≥ C \overline X \geq CX≥c )
- La identidad se transforma en una función de muestra, utilizando las conclusiones clásicas, correspondientes a las funciones de distribución de las tres estadísticas principales,
- Según "con nivel α \alphaα ” (para cualquier H0 satisfactoria), siempre que el valor máximo de la función de distribución≤ α \leq \alpha≤α , el parámetro C en la prueba de solución de la ecuación lineal en una variable