
1 Descripción del caso (Red neuronal convolucional gráfica)
El conjunto de datos CORA contiene las palabras clave y la información de clasificación de cada artículo, así como la información de citas mutuas entre artículos. Cree un modelo de IA, analice la información del papel en el conjunto de datos y prediga la categoría de papeles de clasificación desconocida según las características de clasificación de los papeles existentes.
1.1 Características del uso de redes neuronales convolucionales gráficas
La clasificación se implementa utilizando una red neuronal gráfica. La diferencia con el modelo de aprendizaje profundo es que la red neuronal gráfica utilizará las características del propio texto y la relación entre los documentos para el procesamiento, y solo se necesita una pequeña cantidad de muestras para lograr buenos resultados.
1.2 Conjunto de datos CORA
El conjunto de datos de CORA se compila a partir de documentos de aprendizaje automático, registrando las palabras clave utilizadas en cada documento y la relación entre los documentos.
1.2.1 Contenidos de CORA
Los artículos en el conjunto de datos CORA se dividen en 7 categorías: basados en casos, algoritmos genéticos, redes neuronales, métodos probabilísticos, aprendizaje por refuerzo, aprendizaje por reglas y teoría.
1.2.2 Composición de la CORA
Hay un total de 2708 artículos en el conjunto de datos, cada uno de los cuales cita o es citado por al menos otro artículo. Hay 2708 artículos en todo el corpus. Al mismo tiempo, se eliminaron las raíces, las palabras vacías y las palabras de baja frecuencia en todos los artículos, quedando 1433 palabras clave como características individuales de los artículos.

1.2.3 Descripción de archivo y estructura del conjunto de datos CORA
(1) Descripción de la tesis en formato de archivo de contenido:
<id-de-papel><atributos-de-palabra><etiqueta-de-clase>
La primera entrada de cada línea contiene el ID de cadena único del artículo, seguido de un valor binario que indica si cada palabra del vocabulario está presente (representada por 1) o ausente (representada por 0) en el artículo. El último elemento de la fila contiene la etiqueta de clase del artículo.
(2) El archivo de citas contiene el gráfico de citas del corpus, y cada línea describe un enlace en el siguiente formato:
<id ofreferencepaper><id ofreference paper>
Cada fila contiene dos identificaciones de papel. La primera entrada es el ID del artículo citado y la segunda ID representa el artículo que contiene la cita. La dirección de los enlaces es de derecha a izquierda. Si una línea está representada por "papel2 papel1", entonces la conexión es "papel2->papel1"
2 Escritura de código
2.1 Combate de código: Introducir módulos básicos y configurar el entorno de ejecución----Cora_GNN.py (Parte 1)
from pathlib import Path # 引入提升路径的兼容性
# 引入矩阵运算的相关库
import numpy as np
import pandas as pd
from scipy.sparse import coo_matrix,csr_matrix,diags,eye
# 引入深度学习框架库
import torch
from torch import nn
import torch.nn.functional as F
# 引入绘图库
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 1.1 导入基础模块,并设置运行环境
# 输出计算资源情况
device = torch.device('cuda')if torch.cuda.is_available() else torch.device('cpu')
print(device) # 输出 cuda
# 输出样本路径
path = Path('./data/cora')
print(path) # 输出 cudaResultado de salida:
2.2 Implementación de código: lectura y análisis de datos en papel----Cora_GNN.py (Parte 2)
# 1.2 读取并解析论文数据
# 读取论文内容数据,将其转化为数据
paper_features_label = np.genfromtxt(path/'cora.content',dtype=np.str_) # 使用Path对象的路径构造,实例化的内容为cora.content。path/'cora.content'表示路径为'data/cora/cora.content'的字符串
print(paper_features_label,np.shape(paper_features_label)) # 打印数据集内容与数据的形状
# 取出数据集中的第一列:论文ID
papers = paper_features_label[:,0].astype(np.int32)
print("论文ID序列:",papers) # 输出所有论文ID
# 论文重新编号,并将其映射到论文ID中,实现论文的统一管理
paper2idx = {k:v for v,k in enumerate(papers)}
# 将数据中间部分的字标签取出,转化成矩阵
features = csr_matrix(paper_features_label[:,1:-1],dtype=np.float32)
print("字标签矩阵的形状:",np.shape(features)) # 字标签矩阵的形状
# 将数据的最后一项的文章分类属性取出,转化为分类的索引
labels = paper_features_label[:,-1]
lbl2idx = { k:v for v,k in enumerate(sorted(np.unique(labels)))}
labels = [lbl2idx[e] for e in labels]
print("论文类别的索引号:",lbl2idx,labels[:5])producción:

2.3 Leer y analizar datos relacionales en papel
Cargue los datos de relación de los artículos, convierta la relación representada por el ID del artículo en los datos en una relación renumerada, trate cada artículo como un vértice y la relación de citas entre artículos como un borde, de modo que los datos de relación de los artículos puedan usar un representado por la estructura del gráfico.

Calcule la matriz de adyacencia de esta estructura gráfica y conviértala en una matriz de adyacencia gráfica no dirigida.
2.3.1 Implementación del Código: Matriz de Transformación----Cora_GNN.py (Parte 3)
# 1.3 读取并解析论文关系数据
# 读取论文关系数据,并将其转化为数据
edges = np.genfromtxt(path/'cora.cites',dtype=np.int32) # 将数据集中论文的引用关系以数据的形式读入
print(edges,np.shape(edges))
# 转化为新编号节点间的关系:将数据集中论文ID表示的关系转化为重新编号后的关系
edges = np.asarray([paper2idx[e] for e in edges.flatten()],np.int32).reshape(edges.shape)
print("新编号节点间的对应关系:",edges,edges.shape)
# 计算邻接矩阵,行与列都是论文个数:由论文引用关系所表示的图结构生成邻接矩阵。
adj = coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(len(labels), len(labels)), dtype=np.float32)
# 生成无向图对称矩阵:将有向图的邻接矩阵转化为无向图的邻接矩阵。Tip:转化为无向图的原因:主要用于对论文的分类,论文的引用关系主要提供单个特征之间的关联,故更看重是不是有关系,所以无向图即可。
adj_long = adj.multiply(adj.T < adj)
adj = adj_long + adj_long.Tproducción:
2.4 Datos matriciales de la estructura del gráfico de procesamiento
Los datos de la matriz de la estructura del gráfico se procesan para que muestren mejor las características de la estructura del gráfico y participan en el cálculo del modelo de la red neuronal.
2.4.1 Procedimiento para el procesamiento de datos matriciales de estructura gráfica
1. Normalice los datos de características de cada nodo.
2. Sumar 1 a la diagonal de la matriz de adyacencia: porque en la tarea de clasificación, la función principal de la matriz de adyacencia es ayudar a la clasificación de nodos a través de la asociación entre papeles. Para los nodos de la diagonal, el sentido de la representación es la relación entre sí misma y sí misma. Establecer los nodos diagonales en 1 (gráfico de bucle automático) indica que los nodos también ayudarán con la tarea de clasificación.
3. Normalizar la matriz de adyacencia después de complementar por 1.

2.4.2 Implementación del código: datos de matriz de la estructura del gráfico de procesamiento----Cora_GNN.py (Parte 4)
# 1.4 加工图结构的矩阵数据
def normalize(mx): # 定义函数,对矩阵的数据进行归一化处理
rowsum = np.array(mx.sum(1)) # 计算每一篇论文的字数==>02 对A中的边数求和,计算出矩阵A的度矩阵D^的特征向量
r_inv = (rowsum ** -1).flatten() # 取总字数的倒数==>03 对矩阵A的度矩阵D^的特征向量求逆,并得到D^逆的特征向量
r_inv[np.isinf(r_inv)] = 0.0 # 将NaN值取为0
r_mat_inv = diags(r_inv) # 将总字数的倒数变为对角矩阵===》对图结构的度矩阵求逆==>04 D^逆的特征向量转化为对角矩阵,得到D^逆
mx = r_mat_inv.dot(mx) # 左乘一个矩阵,相当于每个元素除以总数===》对每个论文顶点的边进行归一化处理==>05 计算D^逆与A加入自环(对角线为1)的邻接矩阵所得A^的点积,得到拉普拉斯矩阵。
return mx
# 对features矩阵进行归一化处理(每行总和为1)
features = normalize(features) #在函数normalize()中,分为两步对邻接矩阵进行处理。1、将每篇论文总字数的倒数变成对角矩阵。该操作相当于对图结构的度矩阵求逆。2、用度矩阵的逆左乘邻接矩阵,相当于对图中每个论文顶点的边进行归一化处理。
# 对邻接矩阵的对角线添1,将其变为自循环图,同时对其进行归一化处理
adj = normalize(adj + eye(adj.shape[0])) # 对角线补1==>01实现加入自环的邻接矩阵A2.5 Convertir datos en tensores y asignar recursos informáticos
Convierta los datos de matriz de estructura gráfica procesados en un tipo de tensor compatible con PyTorch y divídalo en 3 partes para entrenamiento, prueba y validación.
2.5.1 Implementación de código: convertir datos en tensores y asignar recursos informáticos----Cora_GNN.py (Parte 5)
# 1.5 将数据转化为张量,并分配运算资源
adj = torch.FloatTensor(adj.todense()) # 节点间关系 todense()方法将其转换回稠密矩阵。
features = torch.FloatTensor(features.todense()) # 节点自身的特征
labels = torch.LongTensor(labels) # 对每个节点的分类标签
# 划分数据集
n_train = 200 # 训练数据集大小
n_val = 300 # 验证数据集大小
n_test = len(features) - n_train - n_val # 测试数据集大小
np.random.seed(34)
idxs = np.random.permutation(len(features)) # 将原有的索引打乱顺序
# 计算每个数据集的索引
idx_train = torch.LongTensor(idxs[:n_train]) # 根据指定训练数据集的大小并划分出其对应的训练数据集索引
idx_val = torch.LongTensor(idxs[n_train:n_train+n_val])# 根据指定验证数据集的大小并划分出其对应的验证数据集索引
idx_test = torch.LongTensor(idxs[n_train+n_val:])# 根据指定测试数据集的大小并划分出其对应的测试数据集索引
# 分配运算资源
adj = adj.to(device)
features = features.to(device)
labels = labels.to(device)
idx_train = idx_train.to(device)
idx_val = idx_val.to(device)
idx_test = idx_test.to(device)2.6 Convolución de gráficos
La esencia de la convolución de gráficos es la transformación de dimensiones, es decir, transformar los datos de características de cada nodo con una dimensión en datos de características de nodo sin dimensión.
La operación de convolución de gráficos combina las características del nodo de entrada, los parámetros de peso y la matriz de adyacencia procesada para realizar una operación de producto escalar.
El parámetro de ponderación es una matriz de tamaño in×out, donde in representa la dimensión de la característica del nodo de entrada y out representa la dimensión de la característica final que se generará. La función de los parámetros de peso en la transformación de dimensiones se entiende como el peso de una red completamente conectada, pero en la convolución de gráficos, realizará más operaciones de producto escalar de la información de relación de nodo que las redes completamente conectadas.
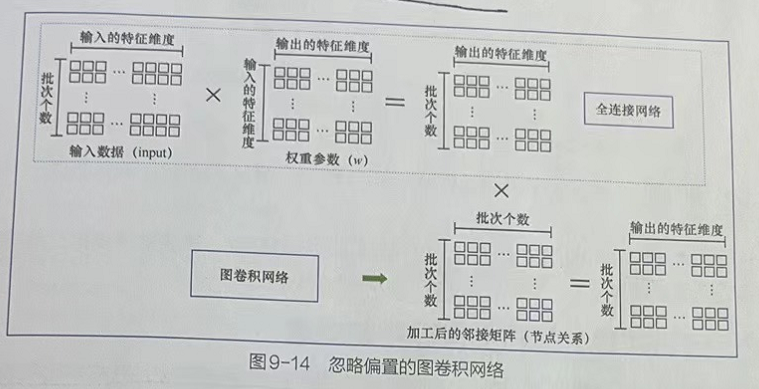
Como se muestra en la figura anterior, se enumera la relación entre la red completamente conectada y la red convolucional del gráfico después de ignorar el sesgo. Se puede ver claramente a partir de esto que la red convolucional gráfica en realidad agrega información de relación de nodo sobre la base de la red completamente conectada.
2.6.1 Implementación del código: defina la función de activación de Mish y la clase de operación de convolución gráfica----Cora_GNN.py (Parte 6)
Agregue sesgo a la base del algoritmo que se muestra en la figura anterior y defina la clase GraphConvolution
# 1.6 定义Mish激活函数与图卷积操作类
def mish(x): # 性能优于RElu函数
return x * (torch.tanh(F.softplus(x)))
# 图卷积类
class GraphConvolution(nn.Module):
def __init__(self,f_in,f_out,use_bias = True,activation=mish):
# super(GraphConvolution, self).__init__()
super().__init__()
self.f_in = f_in
self.f_out = f_out
self.use_bias = use_bias
self.activation = activation
self.weight = nn.Parameter(torch.FloatTensor(f_in, f_out))
self.bias = nn.Parameter(torch.FloatTensor(f_out)) if use_bias else None
self.initialize_weights()
def initialize_weights(self):# 对参数进行初始化
if self.activation is None: # 初始化权重
nn.init.xavier_uniform_(self.weight)
else:
nn.init.kaiming_uniform_(self.weight, nonlinearity='leaky_relu')
if self.use_bias:
nn.init.zeros_(self.bias)
def forward(self,input,adj): # 实现模型的正向处理流程
support = torch.mm(input,self.weight) # 节点特征与权重点积:torch.mm()实现矩阵的相乘,仅支持二位矩阵。若是多维矩则使用torch.matmul()
output = torch.mm(adj,support) # 将加工后的邻接矩阵放入点积运算
if self.use_bias:
output.add_(self.bias) # 加入偏置
if self.activation is not None:
output = self.activation(output) # 激活函数处理
return output2.7 Construcción de convolución de gráficos multicapa
Defina la clase GCN para apilar las capas de convolución de gráficos completadas por la clase GraphConvolution para formar una red de convolución de gráficos de varias capas. Al mismo tiempo, se implementan las funciones de capacitación y evaluación para el modelo de red.
2.7.1 Implementación de código: Convolución de gráfico multicapa----Cora_GNN.py (Parte 7)
# 1.7 搭建多层图卷积网络模型
class GCN(nn.Module):
def __init__(self, f_in, n_classes, hidden=[16], dropout_p=0.5): # 实现多层图卷积网络,该网的搭建方法与全连接网络的搭建一致,只是将全连接层转化成GraphConvolution所实现的图卷积层
# super(GCN, self).__init__()
super().__init__()
layers = []
# 根据参数构建多层网络
for f_in, f_out in zip([f_in] + hidden[:-1], hidden):
# python 在list上的“+=”的重载函数是extend()函数,而不是+
# layers = [GraphConvolution(f_in, f_out)] + layers
layers += [GraphConvolution(f_in, f_out)]
self.layers = nn.Sequential(*layers)
self.dropout_p = dropout_p
# 构建输出层
self.out_layer = GraphConvolution(f_out, n_classes, activation=None)
def forward(self, x, adj): # 实现前向处理过程
for layer in self.layers:
x = layer(x,adj)
# 函数方式调用dropout():必须指定模型的运行状态,即Training标志,这样可减少很多麻烦
F.dropout(x,self.dropout_p,training=self.training,inplace=True)
return self.out_layer(x,adj)
n_labels = labels.max().item() + 1 # 获取分类个数7
n_features = features.shape[1] # 获取节点特征维度 1433
print(n_labels,n_features) # 输出7与1433
def accuracy(output,y): # 定义函数计算准确率
return (output.argmax(1) == y).type(torch.float32).mean().item()
### 定义函数来实现模型的训练过程。与深度学习任务不同,图卷积在训练时需要传入样本间的关系数据。
# 因为该关系数据是与节点数相等的方阵,所以传入的样本数也要与节点数相同,在计算loss值时,可以通过索引从总的运算结果中取出训练集的结果。
def step(): # 定义函数来训练模型 Tip:在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入
model.train()
optimizer.zero_grad()
output = model(features,adj) # 将全部数据载入模型,只用训练数据计算损失
loss = F.cross_entropy(output[idx_train],labels[idx_train])
acc = accuracy(output[idx_train],labels[idx_train]) # 计算准确率
loss.backward()
optimizer.step()
return loss.item(),acc
def evaluate(idx): # 定义函数来评估模型 Tip:在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入
model.eval()
output = model(features, adj) # 将全部数据载入模型,用指定索引评估模型结果
loss = F.cross_entropy(output[idx], labels[idx]).item()
return loss, accuracy(output[idx], labels[idx])2.8 Optimizador de guardabosques
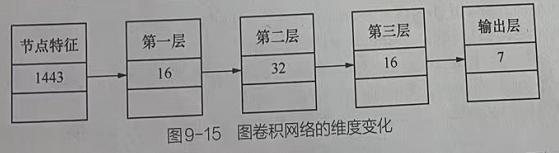
El número de capas de la red neuronal convolucional gráfica no debe ser demasiado, generalmente alrededor de 3 capas. Este ejemplo implementará una red neuronal convolucional de gráficos de 3 capas, y los cambios dimensionales de cada capa se muestran en la Figura 9-15.
Entrene el modelo usando sentencias de bucle y visualice los resultados del modelo.
2.8.1 Implementación de código: entrenar el modelo con Ranger Optimizer y visualizar los resultados ---- Cora_GNN.py (Parte 8)
# 1.8 使用Ranger优化器训练模型并可视化
model = GCN(n_features, n_labels, hidden=[16, 32, 16]).to(device)
from tqdm import tqdm
from Cora_ranger import * # 引入Ranger优化器
optimizer = Ranger(model.parameters()) # 使用Ranger优化器
# 训练模型
epochs = 1000
print_steps = 50
train_loss, train_acc = [], []
val_loss, val_acc = [], []
for i in tqdm(range(epochs)):
tl,ta = step()
train_loss = train_loss + [tl]
train_acc = train_acc + [ta]
if (i+1) % print_steps == 0 or i == 0:
tl,ta = evaluate(idx_train)
vl,va = evaluate(idx_val)
val_loss = val_loss + [vl]
val_acc = val_acc + [va]
print(f'{i + 1:6d}/{epochs}: train_loss={tl:.4f}, train_acc={ta:.4f}' + f', val_loss={vl:.4f}, val_acc={va:.4f}')
# 输出最终结果
final_train, final_val, final_test = evaluate(idx_train), evaluate(idx_val), evaluate(idx_test)
print(f'Train : loss={final_train[0]:.4f}, accuracy={final_train[1]:.4f}')
print(f'Validation: loss={final_val[0]:.4f}, accuracy={final_val[1]:.4f}')
print(f'Test : loss={final_test[0]:.4f}, accuracy={final_test[1]:.4f}')
# 可视化训练过程
fig, axes = plt.subplots(1, 2, figsize=(15,5))
ax = axes[0]
axes[0].plot(train_loss[::print_steps] + [train_loss[-1]], label='Train')
axes[0].plot(val_loss, label='Validation')
axes[1].plot(train_acc[::print_steps] + [train_acc[-1]], label='Train')
axes[1].plot(val_acc, label='Validation')
for ax,t in zip(axes, ['Loss', 'Accuracy']): ax.legend(), ax.set_title(t, size=15)
# 输出模型的预测结果
output = model(features, adj)
samples = 10
idx_sample = idx_test[torch.randperm(len(idx_test))[:samples]]
# 将样本标签与预测结果进行比较
idx2lbl = {v:k for k,v in lbl2idx.items()}
df = pd.DataFrame({'Real': [idx2lbl[e] for e in labels[idx_sample].tolist()],'Pred': [idx2lbl[e] for e in output[idx_sample].argmax(1).tolist()]})
print(df)2.7 Resumen de los resultados del programa
2.7.1 Proceso de formación
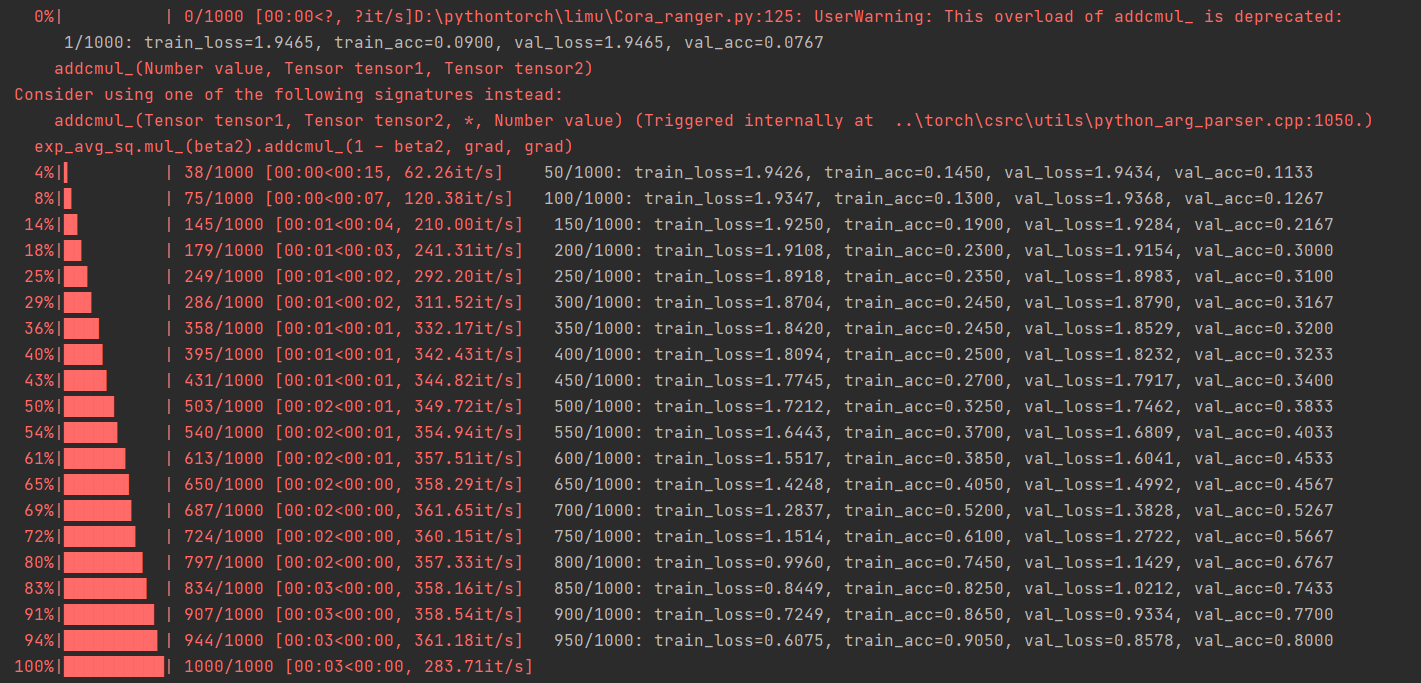
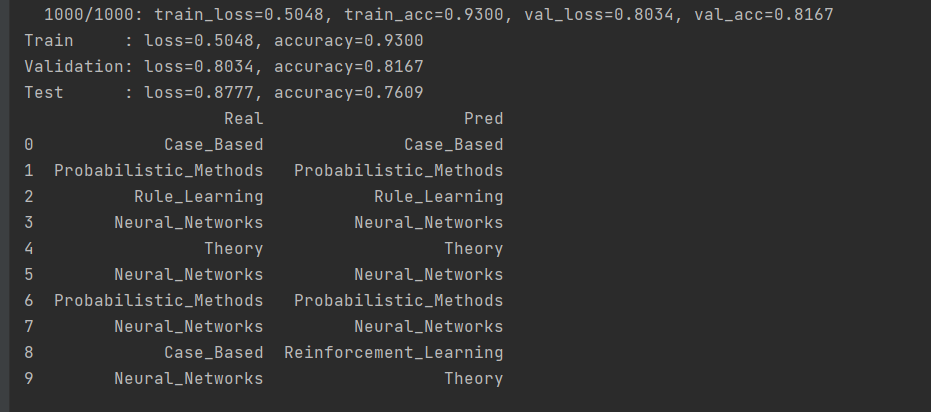
2.7.3 Resultados de la verificación
2.8 Conclusión
Se puede ver a partir de los resultados del entrenamiento que el modelo tiene una buena capacidad de ajuste. Vale la pena mencionar que el modelo convolucional de grafos usa muy pocas muestras de entrenamiento, solo 200 de 2708 muestras se usan para entrenamiento. Debido a que se agrega la información de relación entre las muestras, la dependencia del modelo en el tamaño de la muestra se reduce considerablemente. Esta es también la ventaja del modelo de red neuronal gráfica.
3 Código Resumen
3.1 Cora_GNN.py
from pathlib import Path # 引入提升路径的兼容性
# 引入矩阵运算的相关库
import numpy as np
import pandas as pd
from scipy.sparse import coo_matrix,csr_matrix,diags,eye
# 引入深度学习框架库
import torch
from torch import nn
import torch.nn.functional as F
# 引入绘图库
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 1.1 导入基础模块,并设置运行环境
# 输出计算资源情况
device = torch.device('cuda')if torch.cuda.is_available() else torch.device('cpu')
print(device) # 输出 cuda
# 输出样本路径
path = Path('./data/cora')
print(path) # 输出 cuda
# 1.2 读取并解析论文数据
# 读取论文内容数据,将其转化为数据
paper_features_label = np.genfromtxt(path/'cora.content',dtype=np.str_) # 使用Path对象的路径构造,实例化的内容为cora.content。path/'cora.content'表示路径为'data/cora/cora.content'的字符串
print(paper_features_label,np.shape(paper_features_label)) # 打印数据集内容与数据的形状
# 取出数据集中的第一列:论文ID
papers = paper_features_label[:,0].astype(np.int32)
print("论文ID序列:",papers) # 输出所有论文ID
# 论文重新编号,并将其映射到论文ID中,实现论文的统一管理
paper2idx = {k:v for v,k in enumerate(papers)}
# 将数据中间部分的字标签取出,转化成矩阵
features = csr_matrix(paper_features_label[:,1:-1],dtype=np.float32)
print("字标签矩阵的形状:",np.shape(features)) # 字标签矩阵的形状
# 将数据的最后一项的文章分类属性取出,转化为分类的索引
labels = paper_features_label[:,-1]
lbl2idx = { k:v for v,k in enumerate(sorted(np.unique(labels)))}
labels = [lbl2idx[e] for e in labels]
print("论文类别的索引号:",lbl2idx,labels[:5])
# 1.3 读取并解析论文关系数据
# 读取论文关系数据,并将其转化为数据
edges = np.genfromtxt(path/'cora.cites',dtype=np.int32) # 将数据集中论文的引用关系以数据的形式读入
print(edges,np.shape(edges))
# 转化为新编号节点间的关系:将数据集中论文ID表示的关系转化为重新编号后的关系
edges = np.asarray([paper2idx[e] for e in edges.flatten()],np.int32).reshape(edges.shape)
print("新编号节点间的对应关系:",edges,edges.shape)
# 计算邻接矩阵,行与列都是论文个数:由论文引用关系所表示的图结构生成邻接矩阵。
adj = coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(len(labels), len(labels)), dtype=np.float32)
# 生成无向图对称矩阵:将有向图的邻接矩阵转化为无向图的邻接矩阵。Tip:转化为无向图的原因:主要用于对论文的分类,论文的引用关系主要提供单个特征之间的关联,故更看重是不是有关系,所以无向图即可。
adj_long = adj.multiply(adj.T < adj)
adj = adj_long + adj_long.T
# 1.4 加工图结构的矩阵数据
def normalize(mx): # 定义函数,对矩阵的数据进行归一化处理
rowsum = np.array(mx.sum(1)) # 计算每一篇论文的字数==>02 对A中的边数求和,计算出矩阵A的度矩阵D^的特征向量
r_inv = (rowsum ** -1).flatten() # 取总字数的倒数==>03 对矩阵A的度矩阵D^的特征向量求逆,并得到D^逆的特征向量
r_inv[np.isinf(r_inv)] = 0.0 # 将NaN值取为0
r_mat_inv = diags(r_inv) # 将总字数的倒数变为对角矩阵===》对图结构的度矩阵求逆==>04 D^逆的特征向量转化为对角矩阵,得到D^逆
mx = r_mat_inv.dot(mx) # 左乘一个矩阵,相当于每个元素除以总数===》对每个论文顶点的边进行归一化处理==>05 计算D^逆与A加入自环(对角线为1)的邻接矩阵所得A^的点积,得到拉普拉斯矩阵。
return mx
# 对features矩阵进行归一化处理(每行总和为1)
features = normalize(features) #在函数normalize()中,分为两步对邻接矩阵进行处理。1、将每篇论文总字数的倒数变成对角矩阵。该操作相当于对图结构的度矩阵求逆。2、用度矩阵的逆左乘邻接矩阵,相当于对图中每个论文顶点的边进行归一化处理。
# 对邻接矩阵的对角线添1,将其变为自循环图,同时对其进行归一化处理
adj = normalize(adj + eye(adj.shape[0])) # 对角线补1==>01实现加入自环的邻接矩阵A
# 1.5 将数据转化为张量,并分配运算资源
adj = torch.FloatTensor(adj.todense()) # 节点间关系 todense()方法将其转换回稠密矩阵。
features = torch.FloatTensor(features.todense()) # 节点自身的特征
labels = torch.LongTensor(labels) # 对每个节点的分类标签
# 划分数据集
n_train = 200 # 训练数据集大小
n_val = 300 # 验证数据集大小
n_test = len(features) - n_train - n_val # 测试数据集大小
np.random.seed(34)
idxs = np.random.permutation(len(features)) # 将原有的索引打乱顺序
# 计算每个数据集的索引
idx_train = torch.LongTensor(idxs[:n_train]) # 根据指定训练数据集的大小并划分出其对应的训练数据集索引
idx_val = torch.LongTensor(idxs[n_train:n_train+n_val])# 根据指定验证数据集的大小并划分出其对应的验证数据集索引
idx_test = torch.LongTensor(idxs[n_train+n_val:])# 根据指定测试数据集的大小并划分出其对应的测试数据集索引
# 分配运算资源
adj = adj.to(device)
features = features.to(device)
labels = labels.to(device)
idx_train = idx_train.to(device)
idx_val = idx_val.to(device)
idx_test = idx_test.to(device)
# 1.6 定义Mish激活函数与图卷积操作类
def mish(x): # 性能优于RElu函数
return x * (torch.tanh(F.softplus(x)))
# 图卷积类
class GraphConvolution(nn.Module):
def __init__(self,f_in,f_out,use_bias = True,activation=mish):
# super(GraphConvolution, self).__init__()
super().__init__()
self.f_in = f_in
self.f_out = f_out
self.use_bias = use_bias
self.activation = activation
self.weight = nn.Parameter(torch.FloatTensor(f_in, f_out))
self.bias = nn.Parameter(torch.FloatTensor(f_out)) if use_bias else None
self.initialize_weights()
def initialize_weights(self):# 对参数进行初始化
if self.activation is None: # 初始化权重
nn.init.xavier_uniform_(self.weight)
else:
nn.init.kaiming_uniform_(self.weight, nonlinearity='leaky_relu')
if self.use_bias:
nn.init.zeros_(self.bias)
def forward(self,input,adj): # 实现模型的正向处理流程
support = torch.mm(input,self.weight) # 节点特征与权重点积:torch.mm()实现矩阵的相乘,仅支持二位矩阵。若是多维矩则使用torch.matmul()
output = torch.mm(adj,support) # 将加工后的邻接矩阵放入点积运算
if self.use_bias:
output.add_(self.bias) # 加入偏置
if self.activation is not None:
output = self.activation(output) # 激活函数处理
return output
# 1.7 搭建多层图卷积网络模型
class GCN(nn.Module):
def __init__(self, f_in, n_classes, hidden=[16], dropout_p=0.5): # 实现多层图卷积网络,该网的搭建方法与全连接网络的搭建一致,只是将全连接层转化成GraphConvolution所实现的图卷积层
# super(GCN, self).__init__()
super().__init__()
layers = []
# 根据参数构建多层网络
for f_in, f_out in zip([f_in] + hidden[:-1], hidden):
# python 在list上的“+=”的重载函数是extend()函数,而不是+
# layers = [GraphConvolution(f_in, f_out)] + layers
layers += [GraphConvolution(f_in, f_out)]
self.layers = nn.Sequential(*layers)
self.dropout_p = dropout_p
# 构建输出层
self.out_layer = GraphConvolution(f_out, n_classes, activation=None)
def forward(self, x, adj): # 实现前向处理过程
for layer in self.layers:
x = layer(x,adj)
# 函数方式调用dropout():必须指定模型的运行状态,即Training标志,这样可减少很多麻烦
F.dropout(x,self.dropout_p,training=self.training,inplace=True)
return self.out_layer(x,adj)
n_labels = labels.max().item() + 1 # 获取分类个数7
n_features = features.shape[1] # 获取节点特征维度 1433
print(n_labels,n_features) # 输出7与1433
def accuracy(output,y): # 定义函数计算准确率
return (output.argmax(1) == y).type(torch.float32).mean().item()
### 定义函数来实现模型的训练过程。与深度学习任务不同,图卷积在训练时需要传入样本间的关系数据。
# 因为该关系数据是与节点数相等的方阵,所以传入的样本数也要与节点数相同,在计算loss值时,可以通过索引从总的运算结果中取出训练集的结果。
def step(): # 定义函数来训练模型 Tip:在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入
model.train()
optimizer.zero_grad()
output = model(features,adj) # 将全部数据载入模型,只用训练数据计算损失
loss = F.cross_entropy(output[idx_train],labels[idx_train])
acc = accuracy(output[idx_train],labels[idx_train]) # 计算准确率
loss.backward()
optimizer.step()
return loss.item(),acc
def evaluate(idx): # 定义函数来评估模型 Tip:在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入
model.eval()
output = model(features, adj) # 将全部数据载入模型,用指定索引评估模型结果
loss = F.cross_entropy(output[idx], labels[idx]).item()
return loss, accuracy(output[idx], labels[idx])
# 1.8 使用Ranger优化器训练模型并可视化
model = GCN(n_features, n_labels, hidden=[16, 32, 16]).to(device)
from tqdm import tqdm
from Cora_ranger import * # 引入Ranger优化器
optimizer = Ranger(model.parameters()) # 使用Ranger优化器
# 训练模型
epochs = 1000
print_steps = 50
train_loss, train_acc = [], []
val_loss, val_acc = [], []
for i in tqdm(range(epochs)):
tl,ta = step()
train_loss = train_loss + [tl]
train_acc = train_acc + [ta]
if (i+1) % print_steps == 0 or i == 0:
tl,ta = evaluate(idx_train)
vl,va = evaluate(idx_val)
val_loss = val_loss + [vl]
val_acc = val_acc + [va]
print(f'{i + 1:6d}/{epochs}: train_loss={tl:.4f}, train_acc={ta:.4f}' + f', val_loss={vl:.4f}, val_acc={va:.4f}')
# 输出最终结果
final_train, final_val, final_test = evaluate(idx_train), evaluate(idx_val), evaluate(idx_test)
print(f'Train : loss={final_train[0]:.4f}, accuracy={final_train[1]:.4f}')
print(f'Validation: loss={final_val[0]:.4f}, accuracy={final_val[1]:.4f}')
print(f'Test : loss={final_test[0]:.4f}, accuracy={final_test[1]:.4f}')
# 可视化训练过程
fig, axes = plt.subplots(1, 2, figsize=(15,5))
ax = axes[0]
axes[0].plot(train_loss[::print_steps] + [train_loss[-1]], label='Train')
axes[0].plot(val_loss, label='Validation')
axes[1].plot(train_acc[::print_steps] + [train_acc[-1]], label='Train')
axes[1].plot(val_acc, label='Validation')
for ax,t in zip(axes, ['Loss', 'Accuracy']): ax.legend(), ax.set_title(t, size=15)
# 输出模型的预测结果
output = model(features, adj)
samples = 10
idx_sample = idx_test[torch.randperm(len(idx_test))[:samples]]
# 将样本标签与预测结果进行比较
idx2lbl = {v:k for k,v in lbl2idx.items()}
df = pd.DataFrame({'Real': [idx2lbl[e] for e in labels[idx_sample].tolist()],'Pred': [idx2lbl[e] for e in output[idx_sample].argmax(1).tolist()]})
print(df)3.2 Cora_ranger.py
#Ranger deep learning optimizer - RAdam + Lookahead combined.
#https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
#Ranger has now been used to capture 12 records on the FastAI leaderboard.
#This version = 9.3.19
#Credits:
#RAdam --> https://github.com/LiyuanLucasLiu/RAdam
#Lookahead --> rewritten by lessw2020, but big thanks to Github @LonePatient and @RWightman for ideas from their code.
#Lookahead paper --> MZhang,G Hinton https://arxiv.org/abs/1907.08610
#summary of changes:
#full code integration with all updates at param level instead of group, moves slow weights into state dict (from generic weights),
#supports group learning rates (thanks @SHolderbach), fixes sporadic load from saved model issues.
#changes 8/31/19 - fix references to *self*.N_sma_threshold;
#changed eps to 1e-5 as better default than 1e-8.
import math
import torch
from torch.optim.optimizer import Optimizer, required
import itertools as it
class Ranger(Optimizer):
def __init__(self, params, lr=1e-3, alpha=0.5, k=6, N_sma_threshhold=5, betas=(.95,0.999), eps=1e-5, weight_decay=0):
#parameter checks
if not 0.0 <= alpha <= 1.0:
raise ValueError(f'Invalid slow update rate: {alpha}')
if not 1 <= k:
raise ValueError(f'Invalid lookahead steps: {k}')
if not lr > 0:
raise ValueError(f'Invalid Learning Rate: {lr}')
if not eps > 0:
raise ValueError(f'Invalid eps: {eps}')
#parameter comments:
# beta1 (momentum) of .95 seems to work better than .90...
#N_sma_threshold of 5 seems better in testing than 4.
#In both cases, worth testing on your dataset (.90 vs .95, 4 vs 5) to make sure which works best for you.
#prep defaults and init torch.optim base
defaults = dict(lr=lr, alpha=alpha, k=k, step_counter=0, betas=betas, N_sma_threshhold=N_sma_threshhold, eps=eps, weight_decay=weight_decay)
super().__init__(params,defaults)
#adjustable threshold
self.N_sma_threshhold = N_sma_threshhold
#now we can get to work...
#removed as we now use step from RAdam...no need for duplicate step counting
#for group in self.param_groups:
# group["step_counter"] = 0
#print("group step counter init")
#look ahead params
self.alpha = alpha
self.k = k
#radam buffer for state
self.radam_buffer = [[None,None,None] for ind in range(10)]
#self.first_run_check=0
#lookahead weights
#9/2/19 - lookahead param tensors have been moved to state storage.
#This should resolve issues with load/save where weights were left in GPU memory from first load, slowing down future runs.
#self.slow_weights = [[p.clone().detach() for p in group['params']]
# for group in self.param_groups]
#don't use grad for lookahead weights
#for w in it.chain(*self.slow_weights):
# w.requires_grad = False
def __setstate__(self, state):
print("set state called")
super(Ranger, self).__setstate__(state)
def step(self, closure=None):
loss = None
#note - below is commented out b/c I have other work that passes back the loss as a float, and thus not a callable closure.
#Uncomment if you need to use the actual closure...
#if closure is not None:
#loss = closure()
#Evaluate averages and grad, update param tensors
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('Ranger optimizer does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p] #get state dict for this param
if len(state) == 0: #if first time to run...init dictionary with our desired entries
#if self.first_run_check==0:
#self.first_run_check=1
#print("Initializing slow buffer...should not see this at load from saved model!")
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
#look ahead weight storage now in state dict
state['slow_buffer'] = torch.empty_like(p.data)
state['slow_buffer'].copy_(p.data)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
#begin computations
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
#compute variance mov avg
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
#compute mean moving avg
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
buffered = self.radam_buffer[int(state['step'] % 10)]
if state['step'] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state['step']
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
if N_sma > self.N_sma_threshhold:
step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
else:
step_size = 1.0 / (1 - beta1 ** state['step'])
buffered[2] = step_size
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
if N_sma > self.N_sma_threshhold:
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
else:
p_data_fp32.add_(-step_size * group['lr'], exp_avg)
p.data.copy_(p_data_fp32)
#integrated look ahead...
#we do it at the param level instead of group level
if state['step'] % group['k'] == 0:
slow_p = state['slow_buffer'] #get access to slow param tensor
slow_p.add_(self.alpha, p.data - slow_p) #(fast weights - slow weights) * alpha
p.data.copy_(slow_p) #copy interpolated weights to RAdam param tensor
return loss