Hola a todos, soy Bittao. Si hay algo más candente en 2023, es sin duda la ola de IA liderada por ChatGPT. Este año, ya sean los diversos medios de comunicación entre semana, los proyectos con los que entra en contacto en el trabajo o los temas candentes que todos discuten en su vida, la IA es inseparable. De hecho, para la industria de Internet, ha sido muy popular desde la llegada del aprendizaje profundo. Sin embargo, dado que la IA más utilizada en términos de capacidad de monetización es el algoritmo de recomendación, el público en general también está un poco aburrido con la palabra IA. Sin embargo, ChatGPT nació en noviembre de 2022 y rápidamente rompió el círculo en solo dos meses, con usuarios activos mensuales que alcanzaron los 100 millones, convirtiéndose en el producto más importante del mundo. Algunas personas dicen que esta es la singularidad de la tecnología de IA, y que la IA pronto reemplazará más trabajos; otros dicen que siempre será un cliché, solo un robot de chat más inteligente. En cualquier caso, es innegable que la inteligencia artificial es el comienzo de la próxima revolución tecnológica. La IA no eliminará a los humanos, la IA solo eliminará a los humanos que no puedan usar la IA.
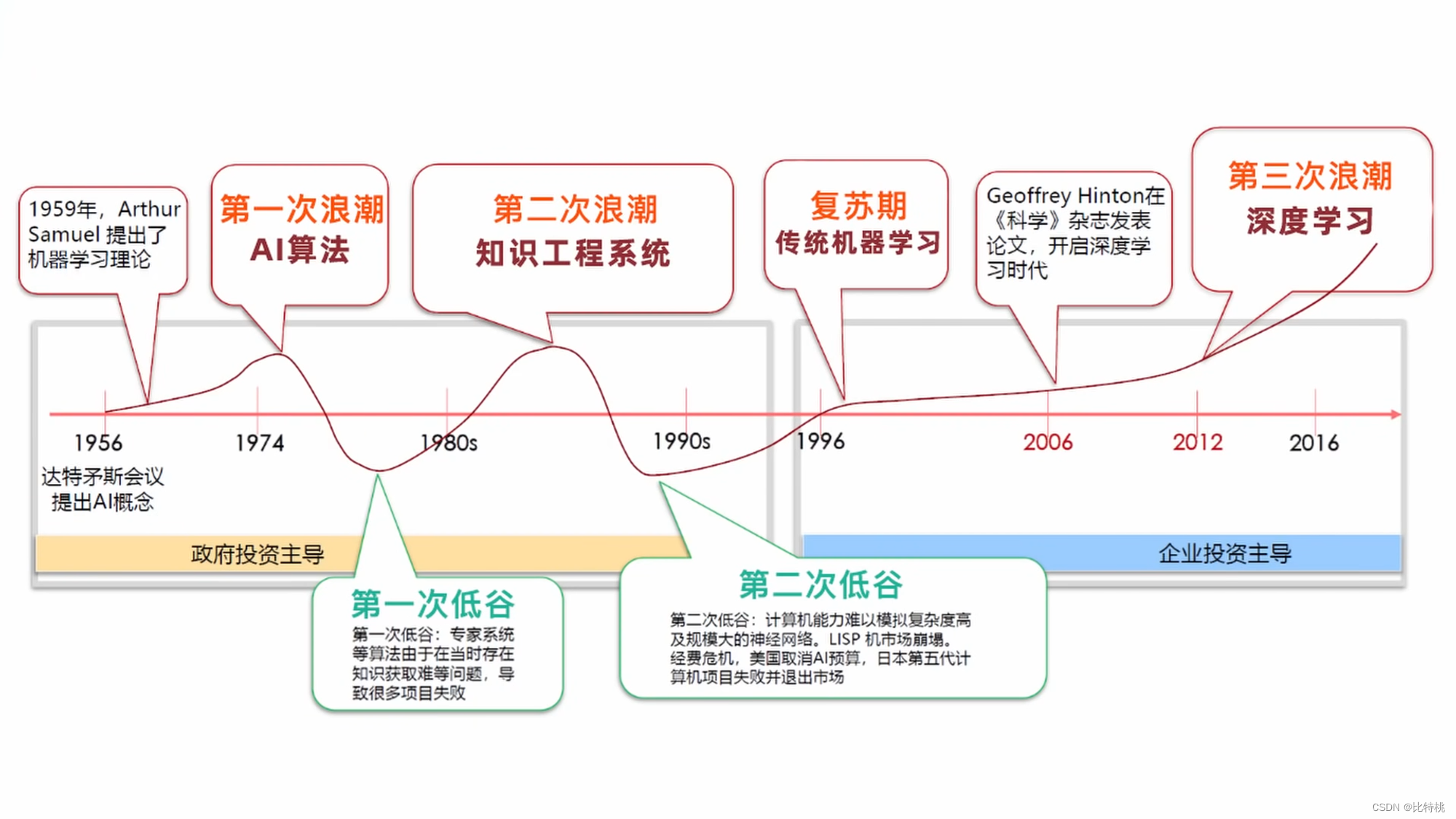
1. Historia de la inteligencia artificial
Aunque la IA no ha estado en el ojo público durante mucho tiempo, las teorías relacionadas ya han tomado forma en el último siglo.
- En 1940, Cybernetics describió el estudio interdisciplinario de exploración de sistemas regulatorios, que se utiliza para estudiar la estructura, las limitaciones y el desarrollo de los sistemas de control. Es el estudio científico de cómo las personas, los animales y las máquinas se controlan y se comunican entre sí.
- En 1943, los neurocientíficos estadounidenses McCulloch y Pitts propusieron redes neuronales y crearon un modelo llamado modelo MP.
- En 1950, con el desarrollo de la informática, la neurociencia y las matemáticas, Turing publicó un artículo que traspasaba la era y proponía una prueba muy filosófica,
The Imitation Gametambién conocida como prueba de Turing. La idea general es: en el proceso de conversación entre un humano y una máquina, si no se puede encontrar que la otra parte sea una máquina, se le llama pasar la prueba de Turing. - En 1956, Marvin Sky, John McCarthy y Claude Shannon (el fundador de la teoría de la información) celebraron una conferencia: la Conferencia de Dartmouth. El problema principal es si las personas pueden pensar como personas, y apareció la palabra IA.
- En 1966, el robot de chat Eliza del MIT, el sistema anterior se basaba en la coincidencia de patrones PatternMatching, basada en reglas.
- En 1997, IBM Deep Blue derrotó al campeón de ajedrez. Sinton de la Universidad de Toronto introdujo el algoritmo de retropropagación BP en la inteligencia artificial; Yang Likun de la Universidad de Nueva York, cuya famosa contribución es la red neuronal convolucional CNN; Bengio de la Universidad de Montreal (modelo de lenguaje de probabilidad neuronal, generación de redes de confrontación).
- En 2010, un campo de aprendizaje automático,
Artificial Neural Networksla red neuronal artificial, comenzó a brillar.
2. Aprendizaje automático
La tarea común del aprendizaje automático es descubrir automáticamente las leyes detrás de los datos a través de algoritmos de entrenamiento, mejorar continuamente el modelo y luego hacer predicciones. Hay muchos algoritmos en el aprendizaje automático, entre los cuales el algoritmo más clásico es: 梯度下降算法. Puede ayudarnos a lidiar con problemas de clasificación y regresión. A través y=wx+bdel ajuste lineal de esta fórmula, el resultado está cerca del valor correcto.
2.1 Función de predicción
Supongamos que tenemos un conjunto de puntos de muestra causales, cada uno de los cuales representa un conjunto de variables causales. Por ejemplo, el precio y el área de la casa, la altura y el ritmo de una persona, etc. El sentido común nos dice que sus distribuciones son directamente proporcionales. Primero, el algoritmo de descenso de gradiente determina una pequeña función de predicción de objetivos, que es una línea recta a través del origen y = wx. Nuestra tarea es diseñar un algoritmo para que esta máquina pueda ajustar estos datos y ayudarnos a calcular el parámetro w de la recta.
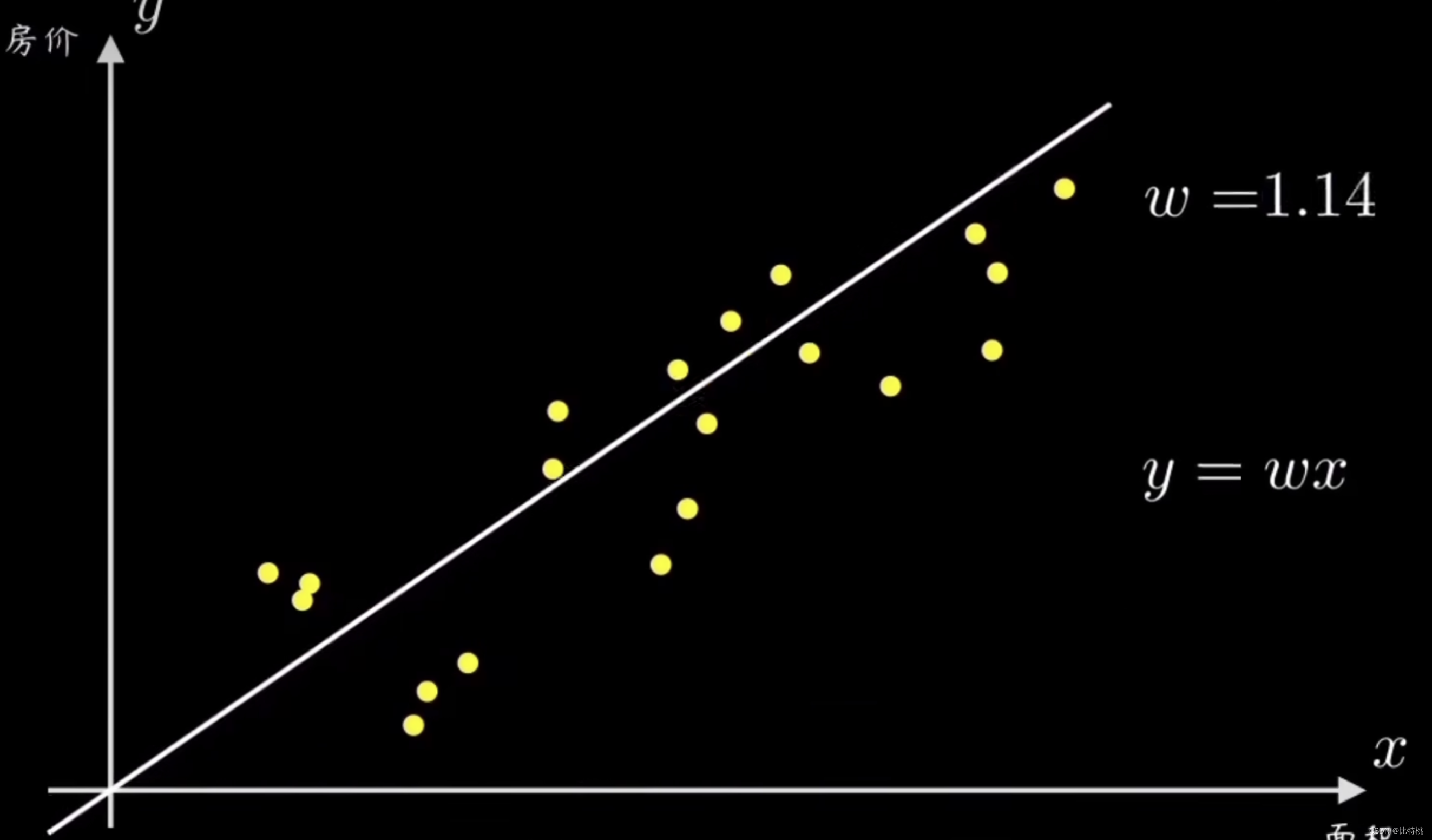
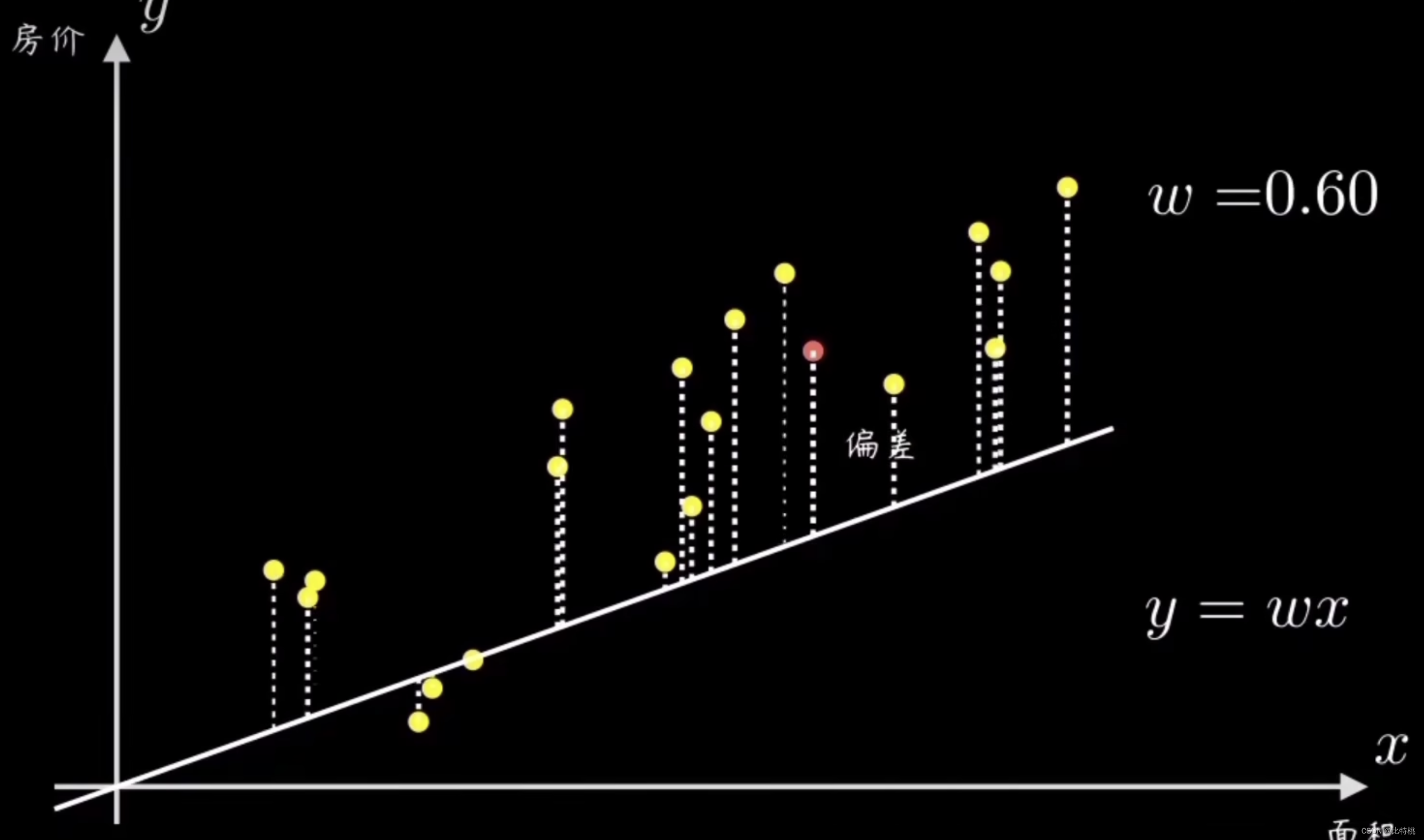
Una forma sencilla es seleccionar aleatoriamente una línea recta que pase por el origen y luego calcular todos los puntos de muestra y su desviación. Luego ajuste la pendiente de la línea w de acuerdo con el tamaño del error
Al ajustar los parámetros, cuanto menor sea la función de pérdida, más precisa será la predicción. En este caso y = wxes la llamada función de predicción.
2.2 Función de costo
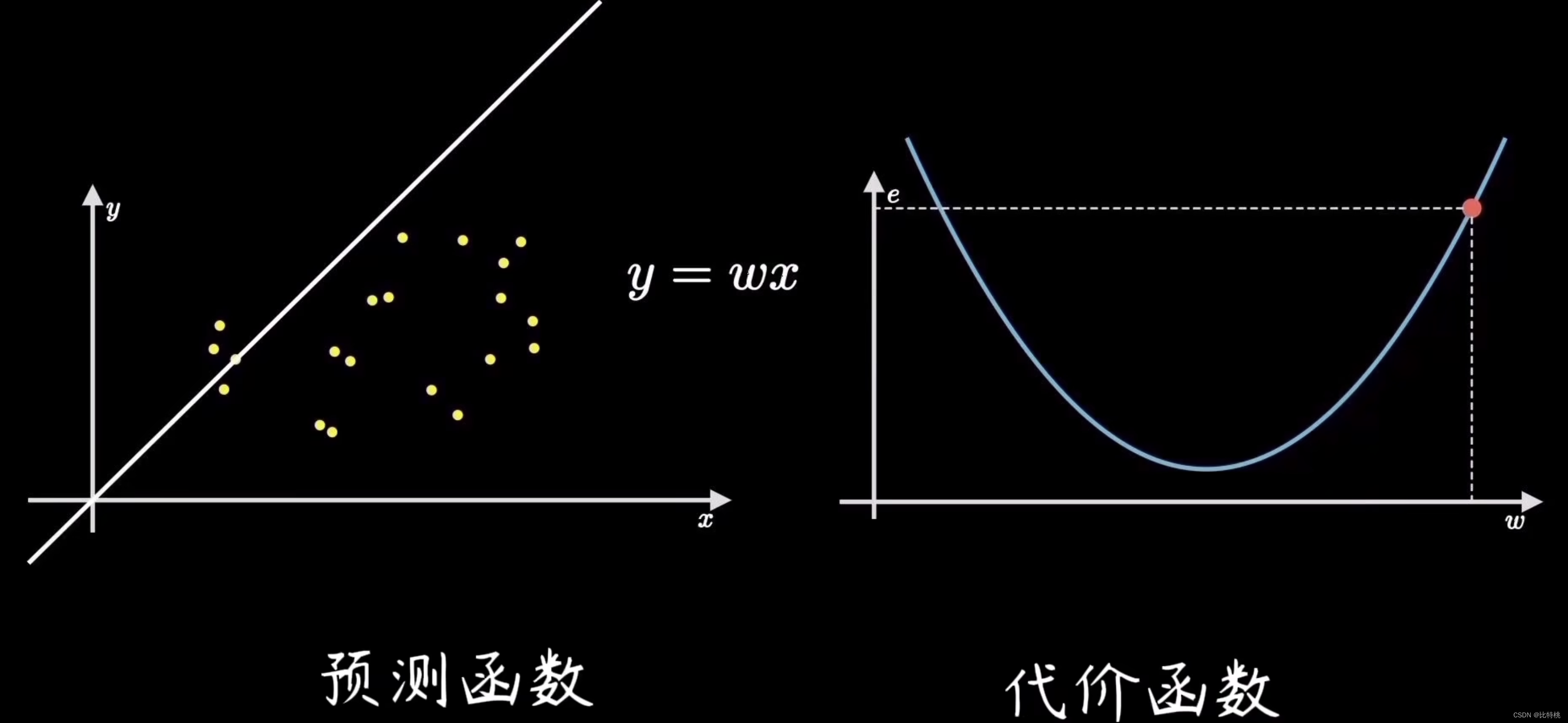
El proceso de encontrar el error es calcular la función de costo. Al cuantificar el grado de desviación de los datos, es decir, el error, el más común es el error cuadrático medio (el promedio de la suma de los cuadrados del error). Por ejemplo, el valor del error es e, porque el coeficiente para encontrar el error es la fórmula de la suma de los cuadrados, por lo que la imagen de la función e se muestra en el lado derecho de la siguiente figura. Encontraremos que cuando la función de e está en el punto más bajo, el error en la figura de la izquierda será menor, es decir, el ajuste será más preciso.
2.3 Cálculo de gradiente
El objetivo del aprendizaje automático es ajustar la línea recta más cercana a la distribución de datos de entrenamiento, es decir, encontrar los parámetros que minimizan el costo del error, que corresponde al punto más bajo de la función de costo. Este proceso de encontrar el punto más bajo se llama ** 梯度下降**.
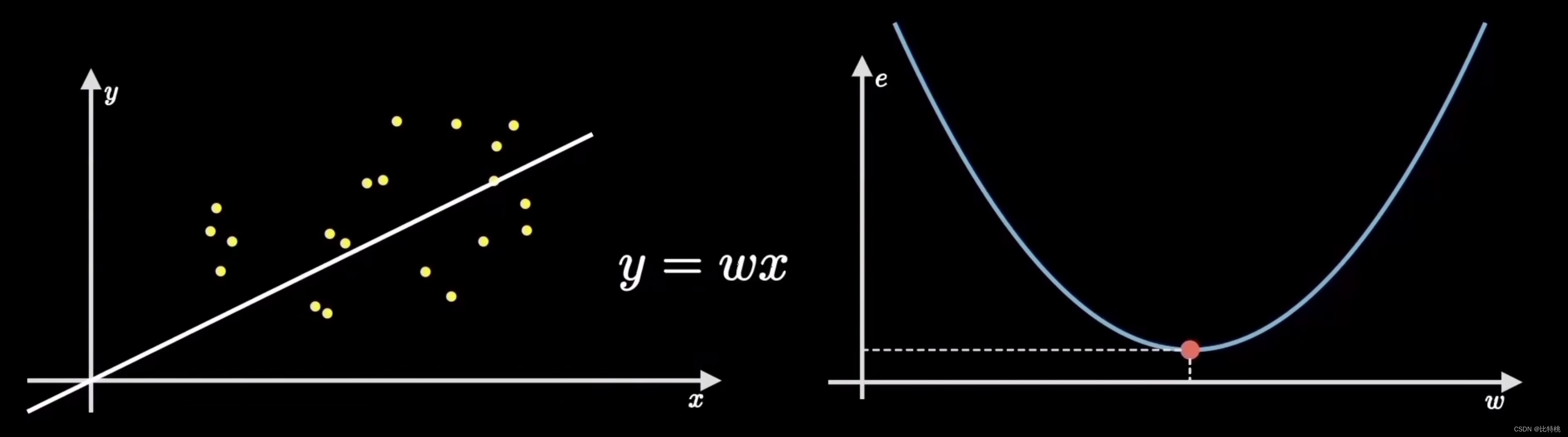
El uso del algoritmo de descenso de gradiente para entrenar este parámetro es muy similar al proceso cognitivo y de aprendizaje humano. La teoría del desarrollo cognitivo de Piaget, la llamada asimilación y adaptación, es exactamente igual que el proceso de aprendizaje automático.
3. Aprendizaje profundo
Hubo mucha controversia en los primeros días sobre si el algoritmo de IA debería implementarse utilizando un método de operación similar al del cerebro humano. Y antes de que surgiera el aprendizaje profundo, la mayoría de los científicos informáticos se dedicaron a la dirección de investigación similar a la coincidencia de patrones. Ahora parece que ese método es, por supuesto, muy difícil de hacer máquinas tan inteligentes como los humanos. Pero no podemos mirar a la gente en ese momento desde la perspectiva actual. En ese momento, los datos y el poder de cómputo eran escasos, por lo que, naturalmente, había un conjunto de teorías para refutar la idea de usar un ser humano. cerebro para lograrlo.
¿Cómo puede una computadora funcionar con el mismo principio que un cerebro humano? Todavía tenemos que usar algoritmos tradicionales para resolver el problema. Esto también condujo indirectamente al estancamiento de la IA en ese momento. Para los doctores que estudiaron esta dirección, la realidad es cruel. Por eso existe ese dicho: El esfuerzo humano es importante, pero también depende de la dirección .
En 1943, los neurocientíficos exploraron el principio operativo del cerebro humano. En el cerebro humano, más de 10 mil millones de neuronas están conectadas a través de una red para juzgar y transmitir información.
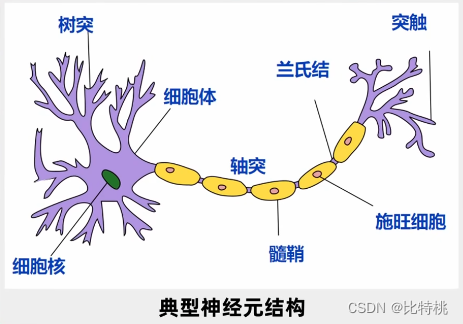
Cada neurona tiene múltiples entradas y una sola salida. La señal se puede obtener a través de múltiples neuronas, y la señal se puede procesar de manera integral, y la señal se puede emitir aguas abajo si es necesario. Esta salida tiene solo dos señales, 0 o 1, muy similar a una computadora. Así que propusieron un modelo llamado modelo MP.
La red neuronal artificial es un modelo matemático algorítmico que imita las características de comportamiento de las redes neuronales animales y realiza un procesamiento de información paralelo distribuido. El aprendizaje profundo es un algoritmo que utiliza redes neuronales artificiales como marco para realizar el aprendizaje de representación en los datos.
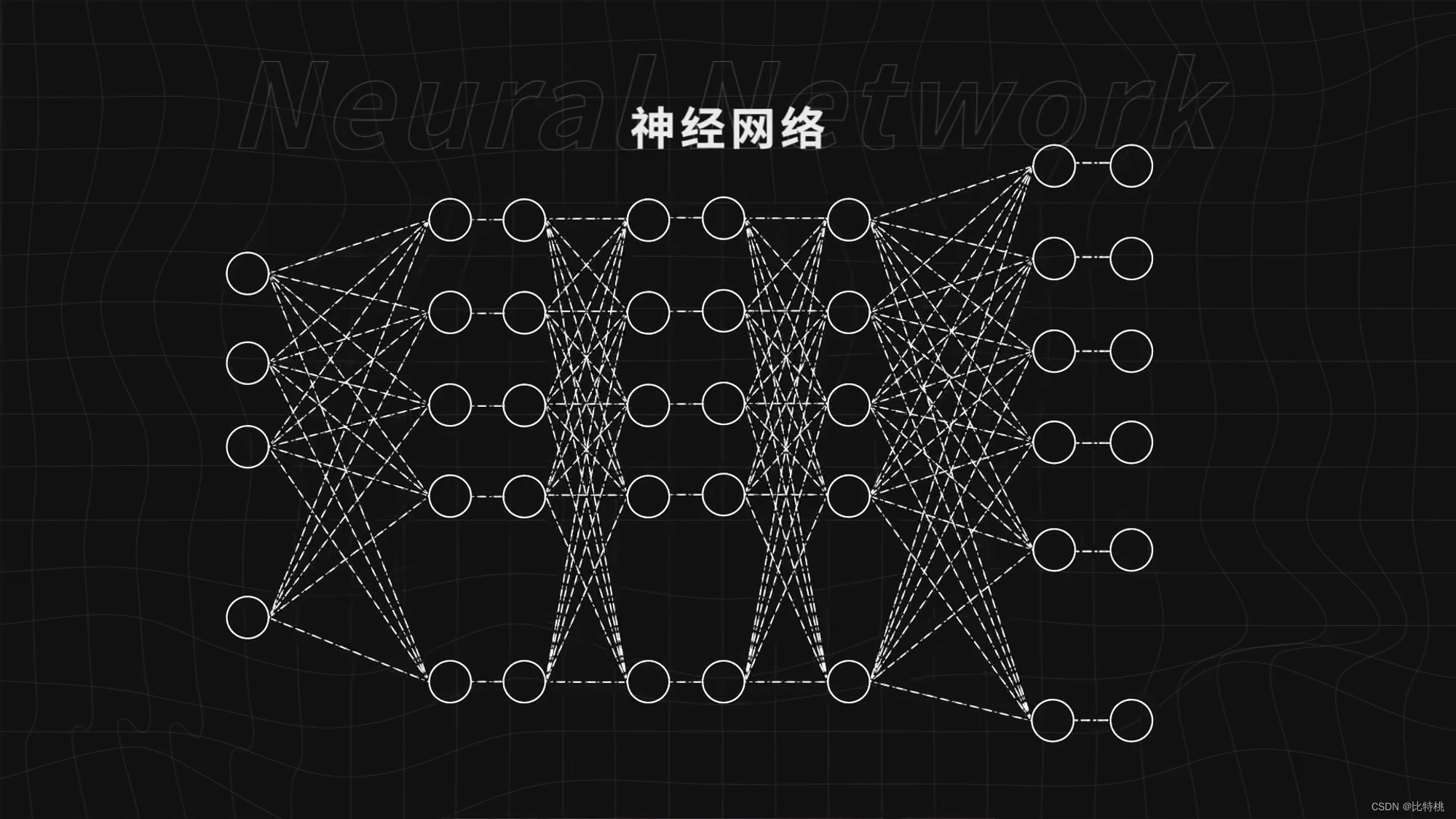
3.1 Red neuronal
Como se muestra en la figura siguiente, un círculo es una neurona y estos círculos forman una red neuronal. Proporcione a la red neuronal suficientes datos, dígale a la red neuronal si está funcionando bien o no, y siga entrenando la red neuronal, puede hacerlo cada vez mejor y completar tareas complejas como reconocer imágenes.
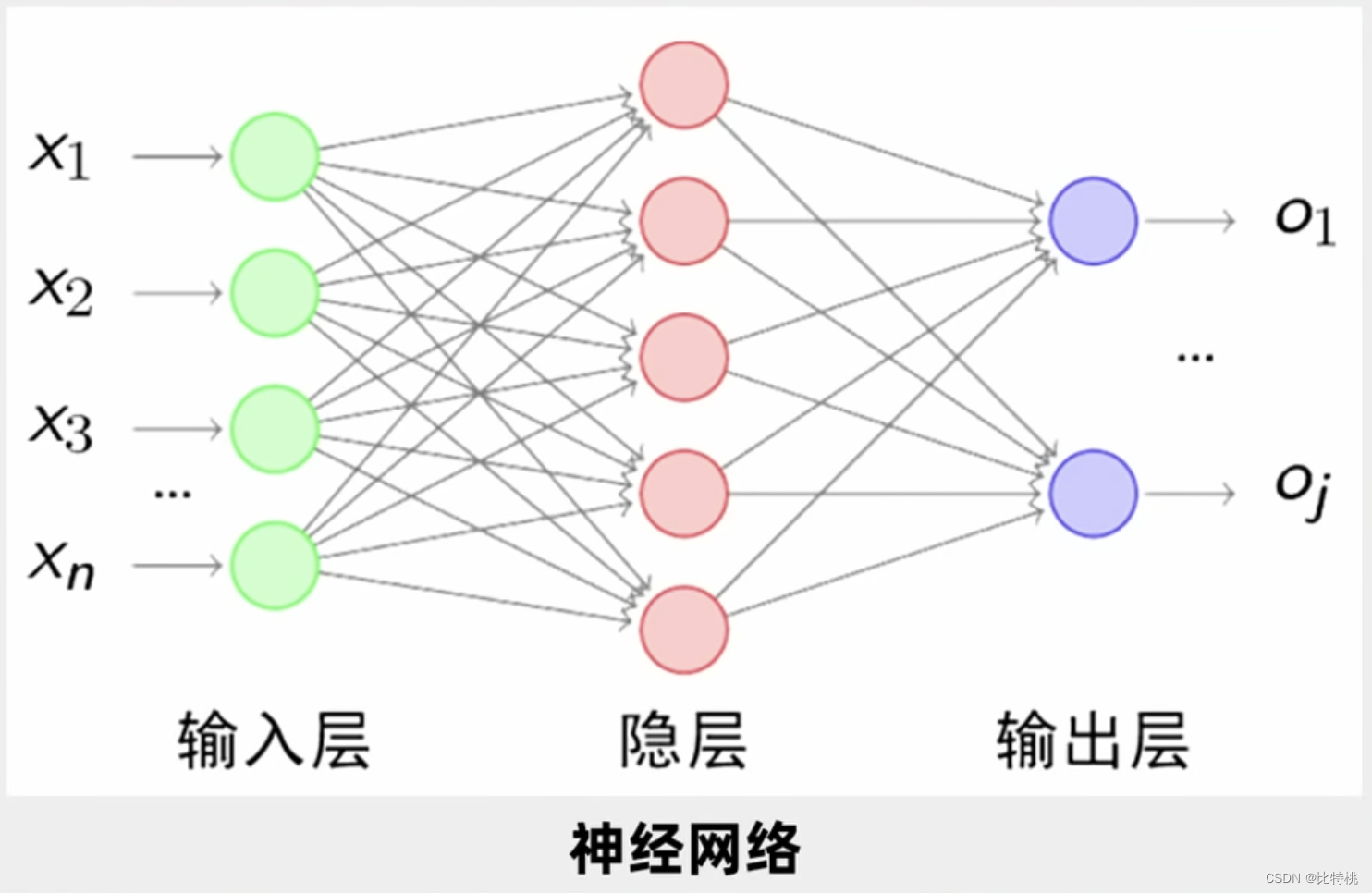
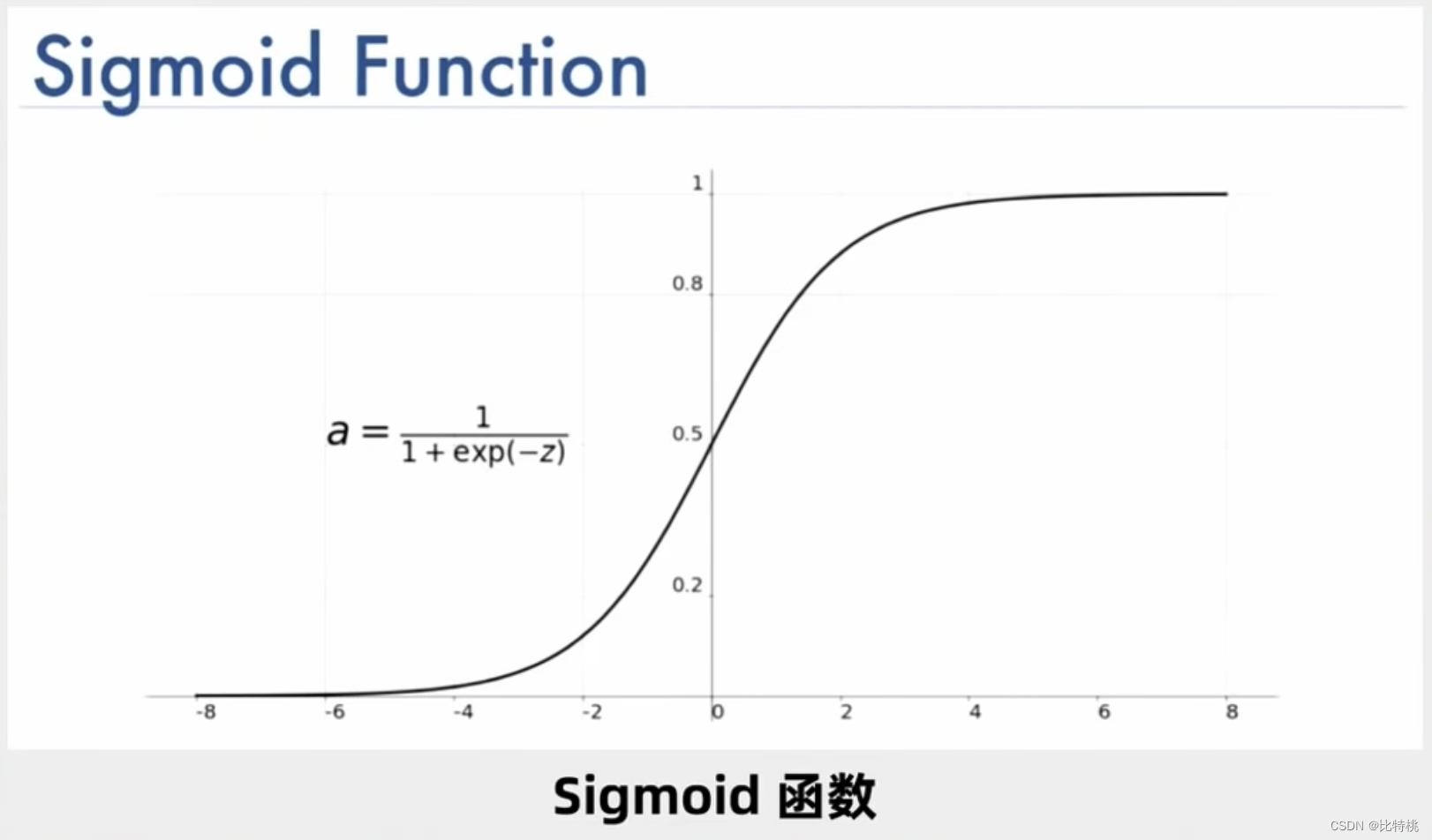
De hecho, el cálculo de las neuronas es un montón de sumas y multiplicaciones, pero como hay suficientes, se vuelve muy complicado. Una neurona puede tener múltiples entradas y solo una salida, pero puede activar múltiples neuronas. Por ejemplo, la siguiente figura es una de las funciones de activación de Sigmoid, y su rango de valores se puede encontrar en (0, 1).
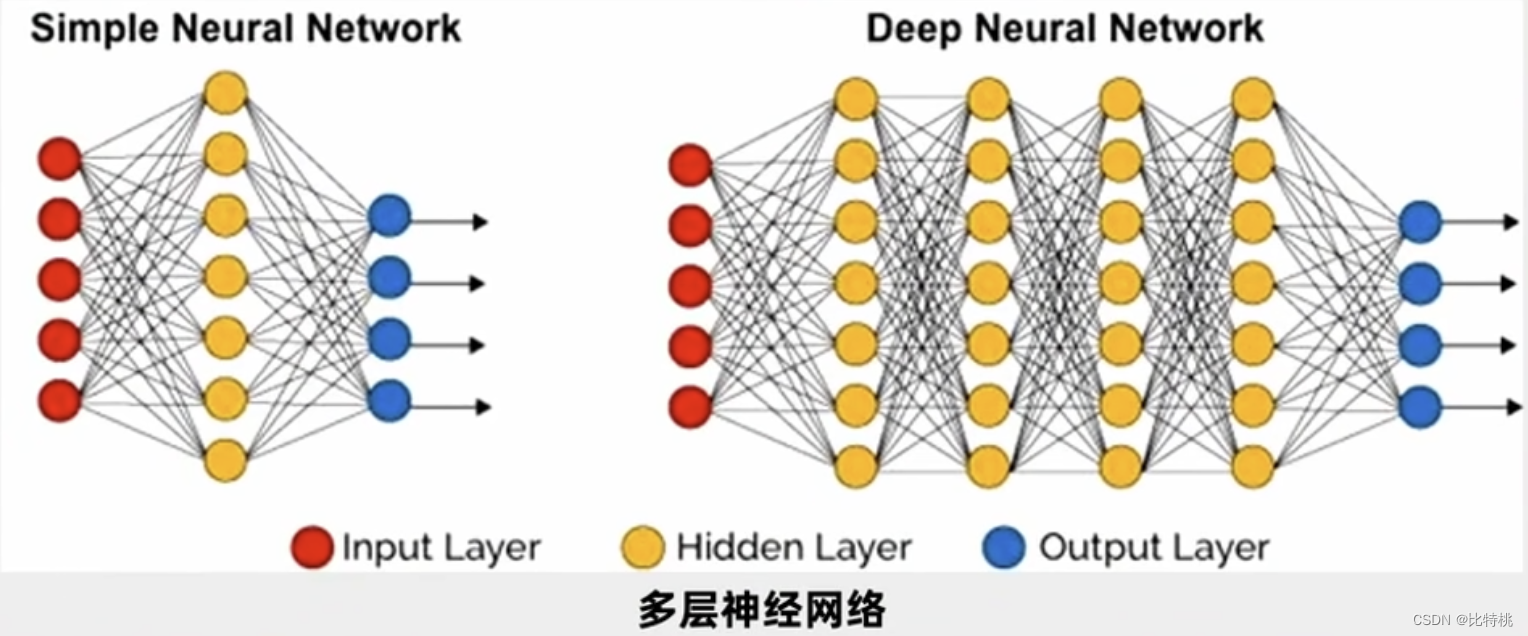
Si es solo para juzgar si es X, entonces una capa es suficiente, pero en la práctica, necesitamos entender el reconocimiento de voz e imagen de otras personas. Así que la gente estudia múltiples capas de neuronas. Una entrada como se muestra en la figura, y luego el terminal de entrada se conecta a cada neurona de la primera capa oculta.Después de que la primera capa oculta genera los datos, elige enviar a la segunda capa oculta, y la segunda capa oculta La salida de la capa entra en la tercera capa oculta. Esto se llama una red neuronal multicapa. Hay una gran cantidad de parámetros entre cada dos capas, y ajustamos una gran cantidad de parámetros al óptimo para que la función de error final se minimice.
Aunque las operaciones que realizan las neuronas no son complicadas, una vez que el escenario es complejo, el orden de magnitud será muy grande. Por ejemplo, una imagen de 5x5 tiene 25 neuronas en cada capa, 625 parámetros en cada capa y más de 2000 en tres capas. Si es una imagen en color, es más complicado de reconocer y es muy lento de calcular. Esta es también la razón por la cual la inteligencia artificial ha sido subestimada en las últimas veces, ni el poder de cómputo ni el algoritmo pueden mantenerse al día. Más tarde, aparecieron el algoritmo BP y la retropropagación, y la última capa se puede ajustar primero. Después de que se ajusta la última capa, se ajusta hacia adelante.La complejidad de este algoritmo es menor que la del anterior. El algoritmo BP resuelve principalmente la pérdida de errores y el cálculo de errores en el proceso de transmisión de información entre múltiples capas de la red neuronal, liderando la tercera ola de inteligencia artificial.
3.2 CNN
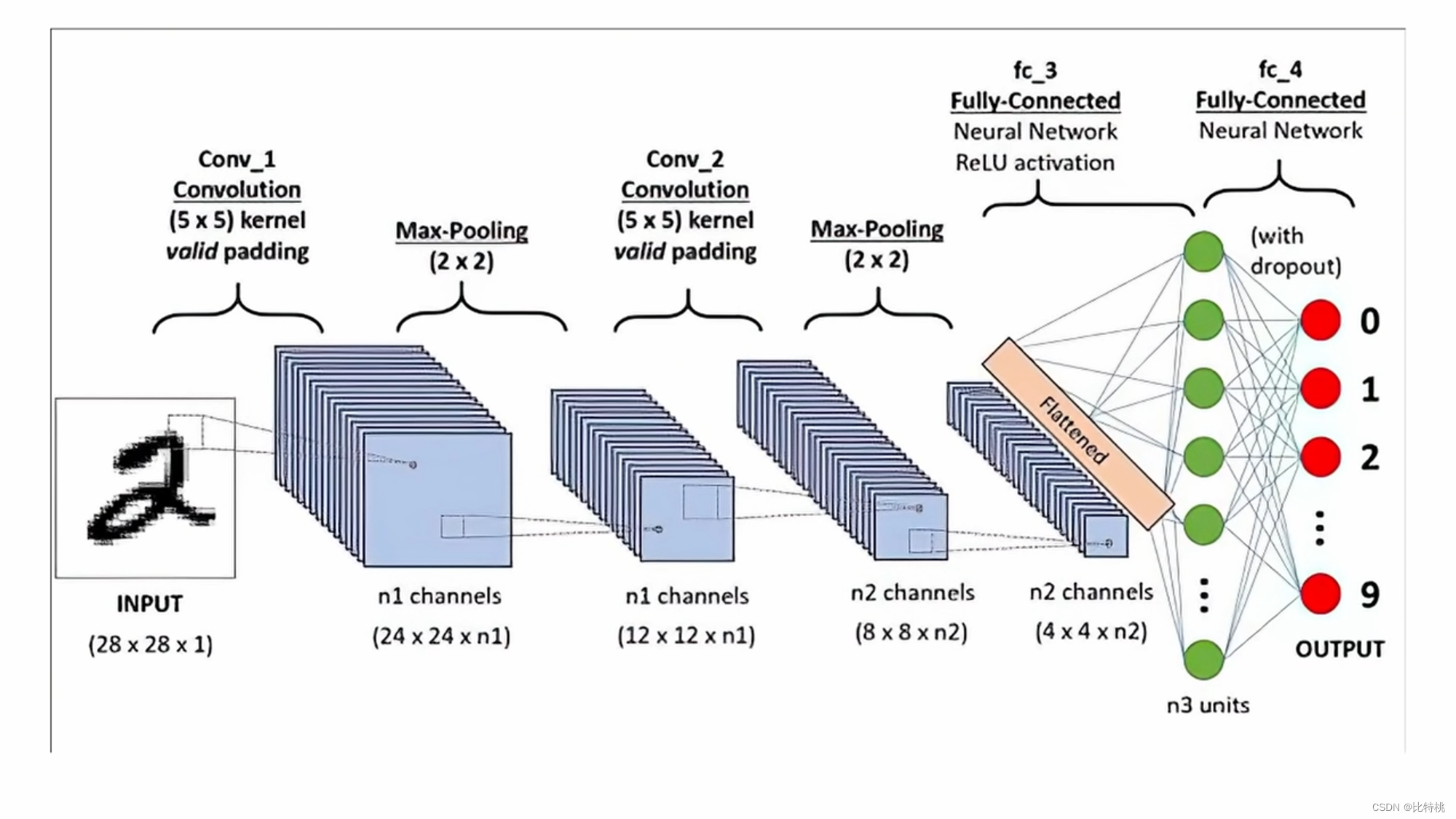
Aquí todavía tomamos un algoritmo más clásico en el algoritmo de red neuronal: la red neuronal convolucional CNN como ejemplo. El proceso es similar al reconocimiento cerebral de los animales, cuando una imagen se refleja en el cerebro, va de punto a línea al objeto y finalmente reconoce lo que es. Lo mismo es cierto para las computadoras, que realizan el reconocimiento de imágenes a través de puntos de píxel-dirección de borde-contorno-detalles-juicio.
Por ejemplo, si queremos identificar si una imagen es Xtal carácter, esa imagen es una matriz bidimensional para la computadora, por ejemplo, el negro es 1 y el blanco es 0. Como se muestra en la siguiente figura:

Después de ser entregado a la computadora, se puede usar una serie de procesos de entrenamiento para encontrar una gran cantidad de parámetros para juzgar si es una X. Encuentre una función con la menor pérdida, eso es un entrenamiento exitoso. A partir de ese momento, puedo usar este conjunto de parámetros para juzgar si una imagen es X o no.
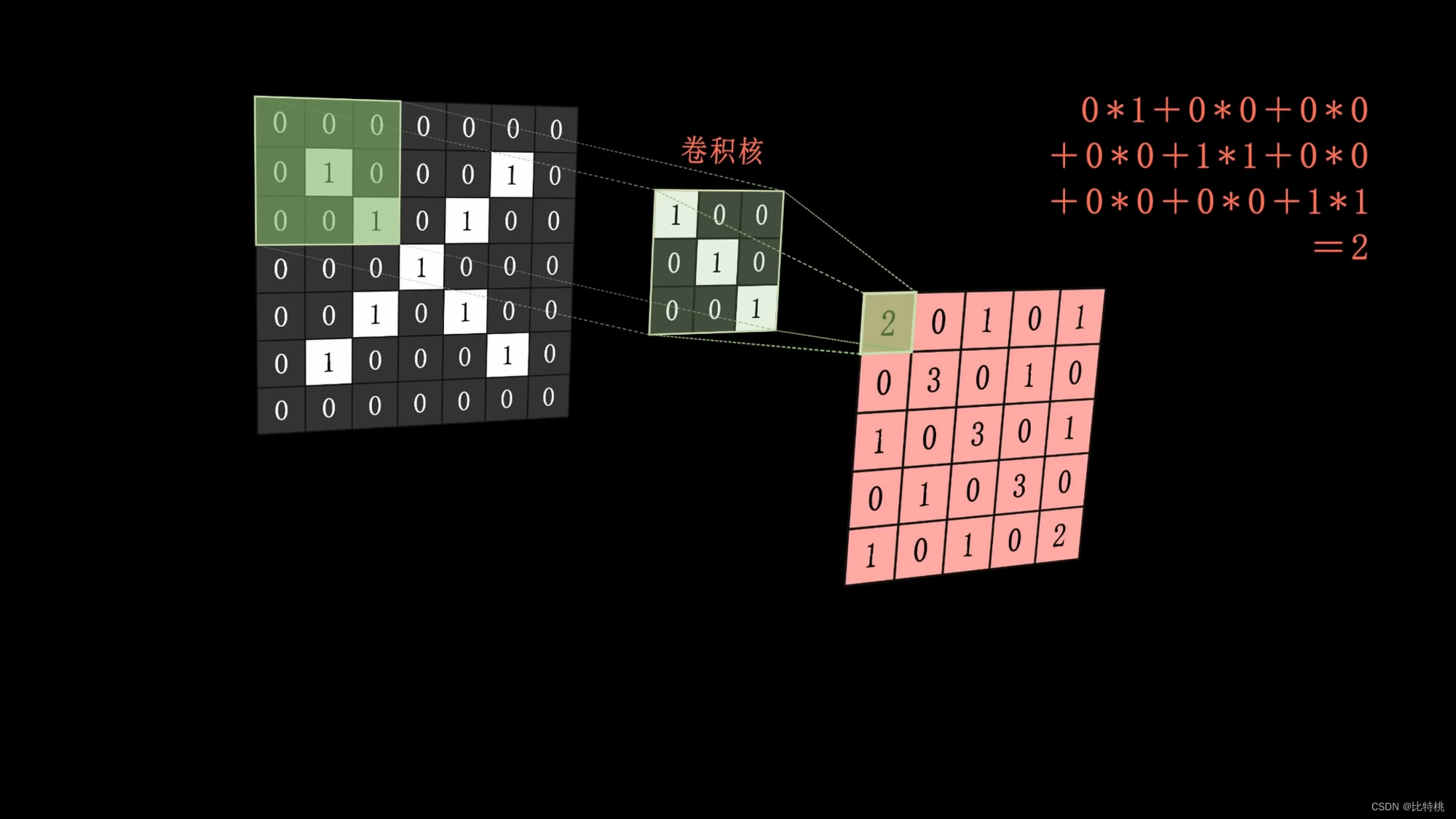
Específicamente, podemos usar el kernel de convolución para realizar operaciones de convolución extrayendo las características de la imagen.Por ejemplo, el kernel de convolución es una línea vertical inclinada (pensamos que esta es una de las características de la imagen X).

El kernel de convolución (una línea vertical inclinada) se aplica a la imagen, se realiza la operación y el resultado de la operación se coloca en el medio de la cobertura de la imagen. Entonces la combinación es el mapa de características. Cuanto mayor sea la característica calculada, más podrá expresar esta característica.
Debido a que la cantidad de cálculo es demasiado grande, usamos el kernel de convolución para escanear un área por un área. Multiplica cada número correspondiente y suma la suma. Se extraen las características numéricas regionales. Luego, los datos se agrupan, se toma el valor máximo en el área y la cantidad de datos característicos se concentra y aplana. Ingrese la red neuronal completa, ya que implica operaciones de convolución, también se denomina red neuronal convolucional. El tamaño, el ritmo y el número de capas convolucionales del kernel de convolución se pueden ajustar por adelantado. El valor emitido por la máquina se compara con el valor preestablecido para el resultado objetivo. Si cumple con las expectativas, es un éxito. Si no cumple con las expectativas, se realizará una serie de cálculos para ajustar inversamente los parámetros (BP) de cada enlace, para luego calcular nuevamente y repetir hasta que cumpla con las expectativas. Este es el principio del aprendizaje automático. Convolución -> Agrupación -> Activación.
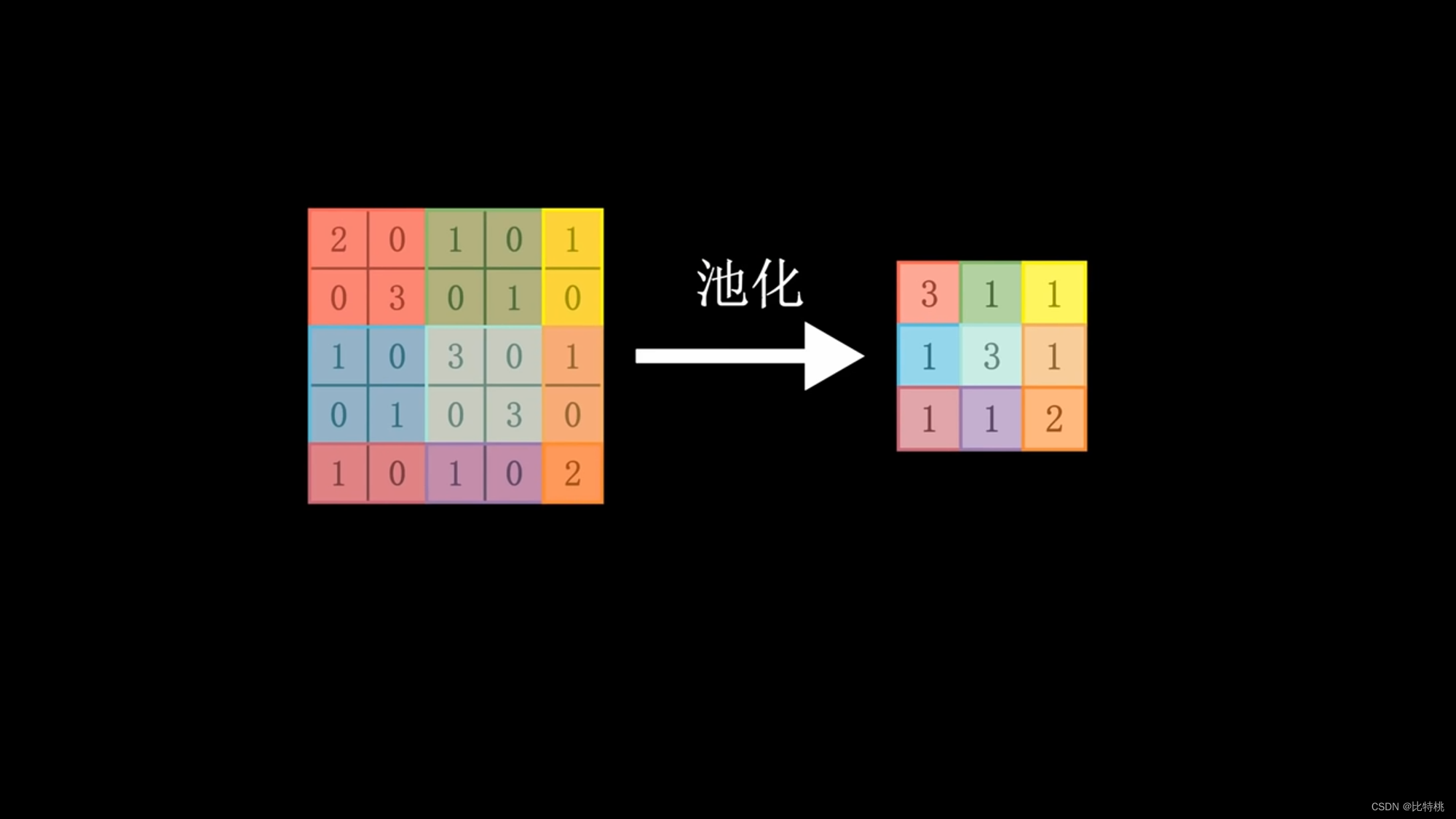
A través de los datos de características después de la convolución, podemos ver que cuanto más cerca está el número de 1, más satisface las características del kernel de convolución.
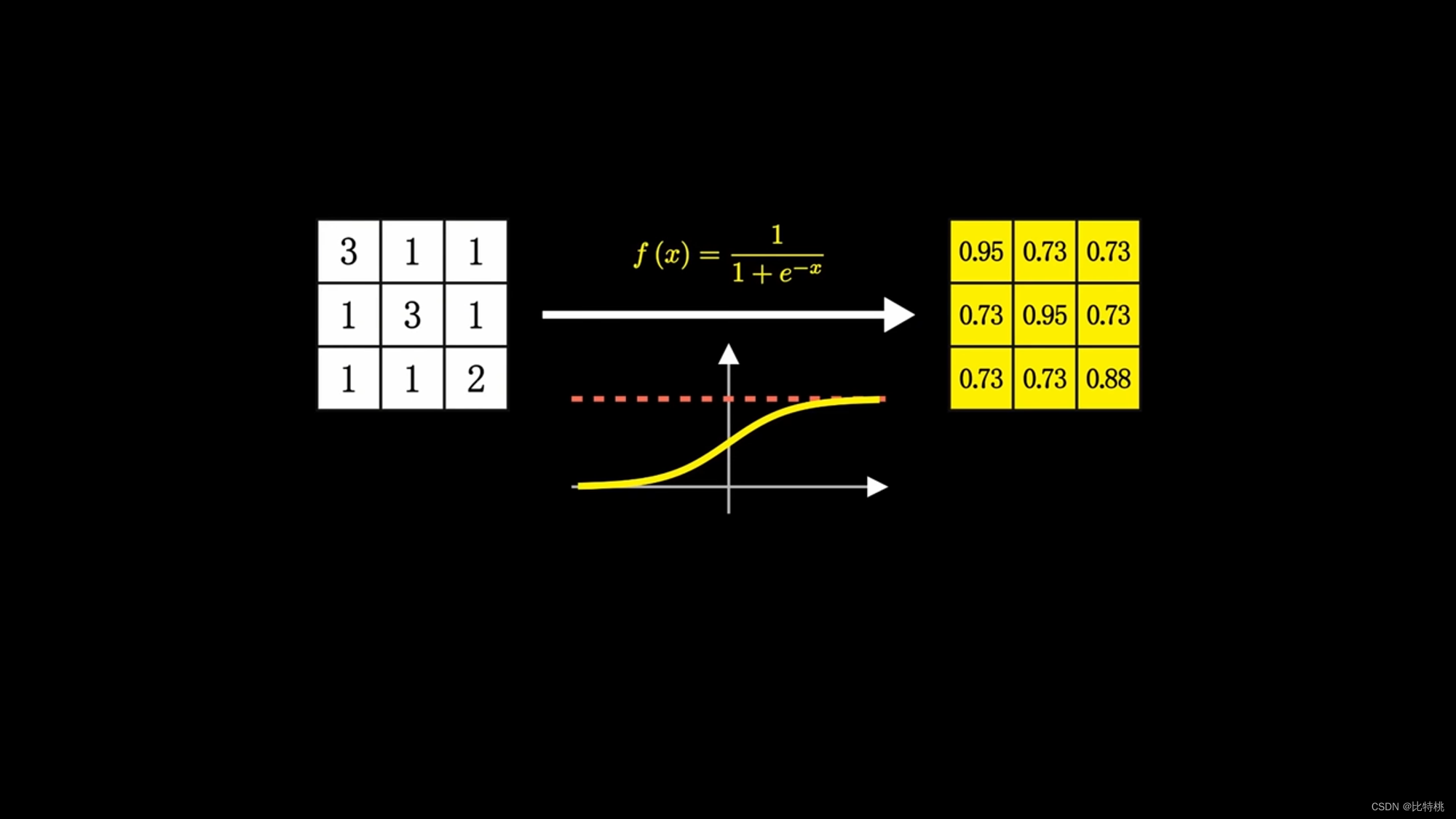
El kernel de convolución puede configurarse artificialmente al principio, pero luego ajustará de manera inversa el kernel de convolución de acuerdo con sus propios datos. Similar al método de entrenamiento, para ajustar los parámetros, se encontrará el kernel de convolución más adecuado durante el proceso de entrenamiento. Hay varios núcleos de convolución, y hay varios mapas de características (tridimensionales).Cuando estos mapas de características se mueven juntos, se convierte en una figura tridimensional.
El diseño del científico es asombroso, simulando casi a la perfección el proceso de pensamiento humano.
Damos una gran cantidad de datos a la inteligencia artificial, y luego la inteligencia artificial ajusta su núcleo de convolución y parámetros a través de un método, y finalmente puede distinguir qué es cada objeto diferente. Aunque no sabemos cómo diseña el kernel de convolución y estos parámetros.
3.3 Modelo = caja negra
Ahora sabemos que a través del entrenamiento continuo de la red neuronal, podemos reducir el error de reconocimiento. Para lograr un modelo inteligente, se utiliza para hacer un trabajo práctico. Aunque el modelo es entrenado por nosotros, de hecho, cada vez que el modelo es reconocido específicamente. No sabemos cómo funciona, sigue siendo una caja negra para nosotros. Al igual que Newton no explicó por qué la manzana cayó al suelo, estableció un modelo matemático de la gravedad, pero lo expresó cuantitativamente con métodos.En cuanto a la razón, aún es difícil expresarla con palabras humanas. Lo mismo ocurre con los modelos entrenados por inteligencia artificial: las funciones que vemos son en realidad diferentes de las funciones utilizadas por las máquinas, ya sea la cantidad de funciones o el contenido de las funciones. Creemos que un objeto puede ser juzgado por 4 características, pero la computadora puede usar 10. Lo mismo ocurre con el contenido, el contenido de nuestro cerebro humano y el 0 y 1 de la computadora también son difíciles de ser equivalentes. Debe saber que la red neuronal es un entrenamiento autoajustable y autooptimizador, por lo que es difícil para usted decir cómo lo hizo al final del entrenamiento. Así como le enseñamos a un niño a reconocer la diferencia entre un gato y un perro, si le enseñas muchos perros y gatos, el niño finalmente reconocerá la diferencia. Pero puedes saber cómo se identifica específicamente a los niños, en realidad es difícil de explicar. Por eso todo el mundo dice que el modelo entrenado por la IA es una caja negra.
3.4 Tarjeta gráfica = potencia informática
Como se mencionó anteriormente, aunque la investigación sobre redes neuronales tuvo una cierta base en la década de 1960. Pero la razón por la que no se ha desarrollado es por la falta de dos cosas: poder de cómputo y datos. Aunque cada neurona de la red neuronal no necesita calcularse muy finamente, requiere una gran cantidad de cálculos simultáneos. Hacer ladrillos sin paja. Los cálculos no son complicados, todos son sumas y multiplicaciones, pero la cantidad de cálculo es particularmente complicada. Por ejemplo, una imagen 800 600 3 (píxeles) = 144000 píxeles. Si se usa un kernel de convolución de tres capas (porque RGB es 3) para la convolución, se requieren alrededor de 13 millones de multiplicaciones + 12 millones de adiciones. Esto era incompetente para la CPU en ese momento, e incluso la CPU actual no puede hacerlo. Esto requiere que la GPU muestre sus habilidades. Sabemos que la GPU se usa para cálculos gráficos. Por ejemplo, para reproducir un video 4k, el mínimo es de 10 millones de píxeles, asumiendo 30 cuadros por segundo. La CPU admite 64 núcleos y 128 núcleos, y la GPU puede tener decenas de miles de núcleos. Aunque el cálculo de un píxel es muy simple, sigue siendo adecuado para un dispositivo con una gran cantidad de operaciones simultáneas, como GPU. La siguiente imagen es un ejemplo muy vívido. La CPU es como una pistola rociadora de alta precisión que apunta hacia dónde disparar:

debido a la alta concurrencia de la GPU, puede generar todos los gráficos en un instante:

es por eso que a menudo Escuche que es necesario comprar una tarjeta gráfica para IA, porque necesitamos muchas operaciones simultáneas (incluida la minería) durante el proceso de capacitación.
En la actualidad, el entrenamiento de IA está básicamente monopolizado por las tarjetas gráficas Nvidia, lo que se debe a que el diseño de Lao Huang es muy temprano. Ya en 2006, Nvidia lanzó CUDA, que logró que la GPU fuera programable. De esta manera, en el pasado, una tarjeta gráfica especialmente diseñada para el procesamiento de gráficos en 3D habría requerido una gran cantidad de ingenieros de primer nivel para usarla para la programación informática, pero ahora solo se puede hacer en base a la biblioteca CUDA. Nvidia ha ampliado los límites de sus tarjetas gráficas desde juegos y procesamiento de imágenes 3D hasta todo el campo de la computación acelerada. Como la industria aeroespacial, biofarmacéutica, pronóstico del tiempo, exploración de energía, etc. Cuando el aprendizaje profundo está muy maduro en 12 años, es natural usar esta plataforma de Nvidia. Como resultado, cuando se trata de capacitación en IA, es equivalente a comprar una tarjeta gráfica, y comprar una tarjeta gráfica es Nvidia.
4. Principio de ChatGPT
Presumiblemente todos han usado ChatGPT directa o indirectamente, es completamente diferente de los estudiantes de Siri y Xiaoai que usamos habitualmente. Al chatear con el primero, lo usaremos como un retraso mental artificial, pero en el proceso de hablar con ChatGPT, realmente podemos resolver algunos problemas prácticos. Por ejemplo, permita que analice puntos técnicos clave en campos desconocidos, escriba preguntas de algoritmos para encontrar errores, etc. Entonces, ¿por qué ChatGPT se vuelve tan inteligente y qué tecnología se utiliza detrás? Exploremos juntos a continuación.
4.1 LLM
Un modelo de lenguaje es una técnica de procesamiento de lenguaje natural basada en métodos estadísticos y de aprendizaje automático que se utiliza para evaluar y predecir la distribución de probabilidad de una secuencia dada, generalmente una secuencia de palabras o caracteres. Las principales aplicaciones de los modelos de lenguaje son tareas como la generación de texto, la traducción automática y el reconocimiento de voz. En los últimos años, los parámetros del modelo de lenguaje de la arquitectura de la red neuronal han alcanzado cientos de miles de millones.Para mostrar la diferencia con el modelo de lenguaje tradicional, la gente suele llamarlo modelo de lenguaje grande (LLM).
En el aprendizaje automático, la red neuronal recurrente (RNN) se usa generalmente para procesar texto. Debe leerse palabra por palabra y no hay forma de procesar una gran cantidad de ellos al mismo tiempo. Y las oraciones no deben ser demasiado largas, de lo contrario se olvidarán después de aprender.
Hasta 2017, Google publicó un documento que proponía un nuevo marco de aprendizaje llamado: Transformador. Puede dejar que la máquina aprenda una gran cantidad de palabras al mismo tiempo, al igual que la diferencia entre serie y paralelo. Muchos modelos de PNL ahora se basan en Transformer. La T en Google BERT y la T en ChatGPT se refieren a este Transformador.
Basado en Transformer, el equipo de GPT publicó un artículo en 2018 que presenta un nuevo modelo de lenguaje, Transformador preentrenado generativo o GPT. Los modelos de lenguaje extenso (LLM, por sus siglas en inglés) generan texto similar al humano al predecir la probabilidad de palabras en función de las palabras utilizadas previamente en el texto.
Los modelos de aprendizaje de idiomas anteriores básicamente requerían supervisión humana o le asignaban etiquetas de forma artificial. Pero GPT básicamente no se necesita mucho, solo coloque un montón de datos y podrá aprenderlo después de un tiempo. Un modelo de lenguaje tan grande depende principalmente del algoritmo y la cantidad de parámetros. Los mismos datos se pueden aprender más rápido que cualquier otra persona, y la cantidad de parámetros requiere muchos cálculos. Para decirlo sin rodeos, es una pérdida de dinero. Después de GPT3, se agrega el aprendizaje de refuerzo de retroalimentación artificial, y cada una de sus palabras se calcula en función de la relevancia y el contexto del texto anterior.
4.2 Proceso de generación
Sabemos que el núcleo de ChatGPT es el modelo de lenguaje grande LLM Large Language Model. El modelo de Oracle es un modelo basado en redes neuronales que se entrena en grandes cantidades de datos de texto para comprender y generar lenguaje humano. El modelo usa datos de entrenamiento para aprender patrones estadísticos y relaciones entre palabras en un idioma, y luego usa este conocimiento para predecir palabras subsiguientes, una palabra a la vez. El modelo más grande de GPT 3.5 tiene 175 000 millones de parámetros repartidos en 96 capas de redes neuronales, lo que lo convierte en uno de los modelos de aprendizaje profundo más grandes jamás construidos.
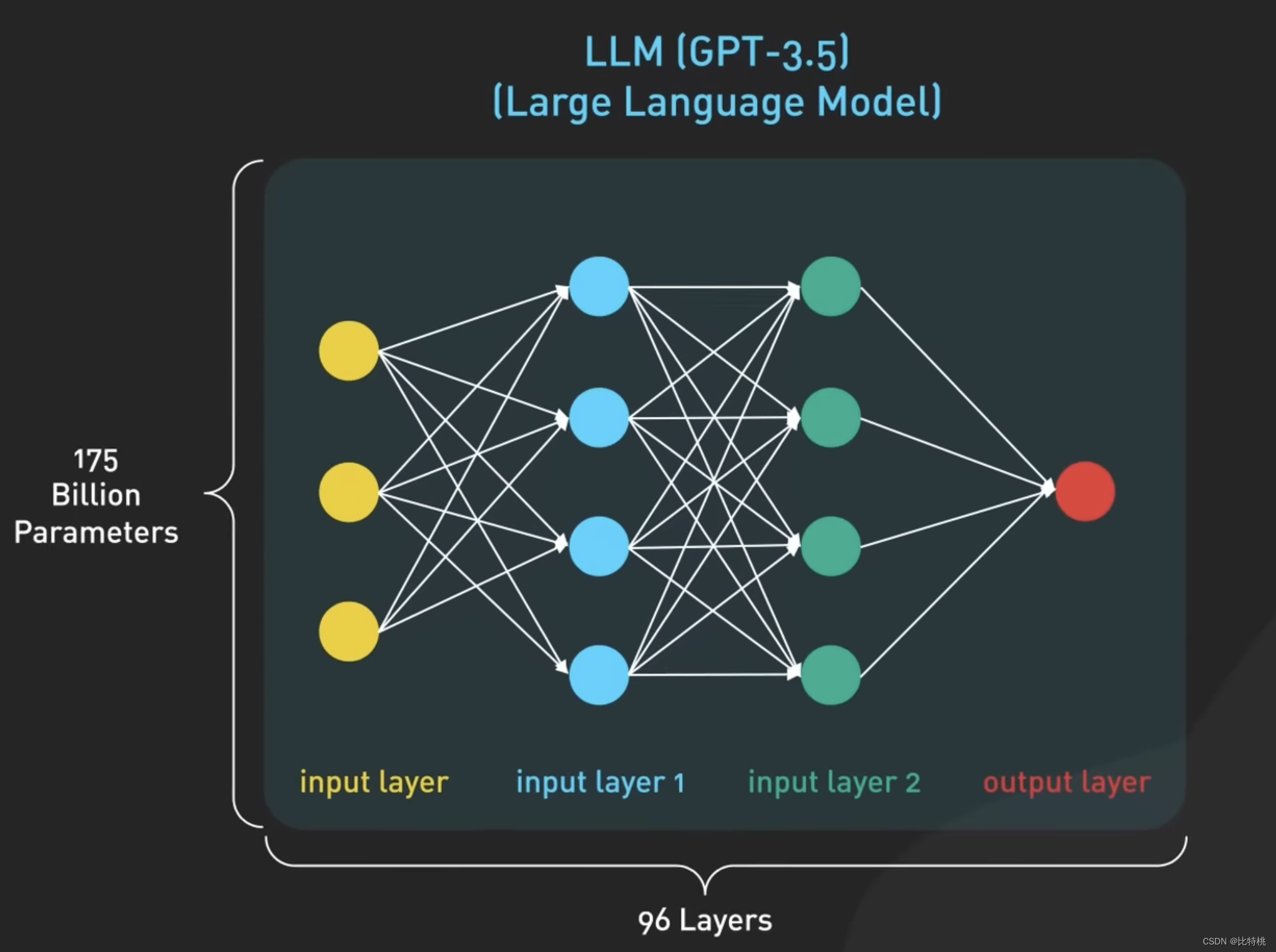
La entrada y salida del modelo en ChatGPT están organizadas por Token, que es la representación digital de las palabras. Más precisamente, parte de una palabra. De hecho, se basa en el contexto de cada palabra de la oración para juzgar cuál es la siguiente palabra más adecuada para la salida.

Use números en lugar de palabras para representar tokens, ya que los números se pueden manejar de manera más eficiente. GPT-3.5 está entrenado en base a una gran cantidad de datos de Internet, y el conjunto de datos original contiene 500 mil millones de Tokens. Es decir, el modelo fue entrenado en cientos de miles de millones de palabras.
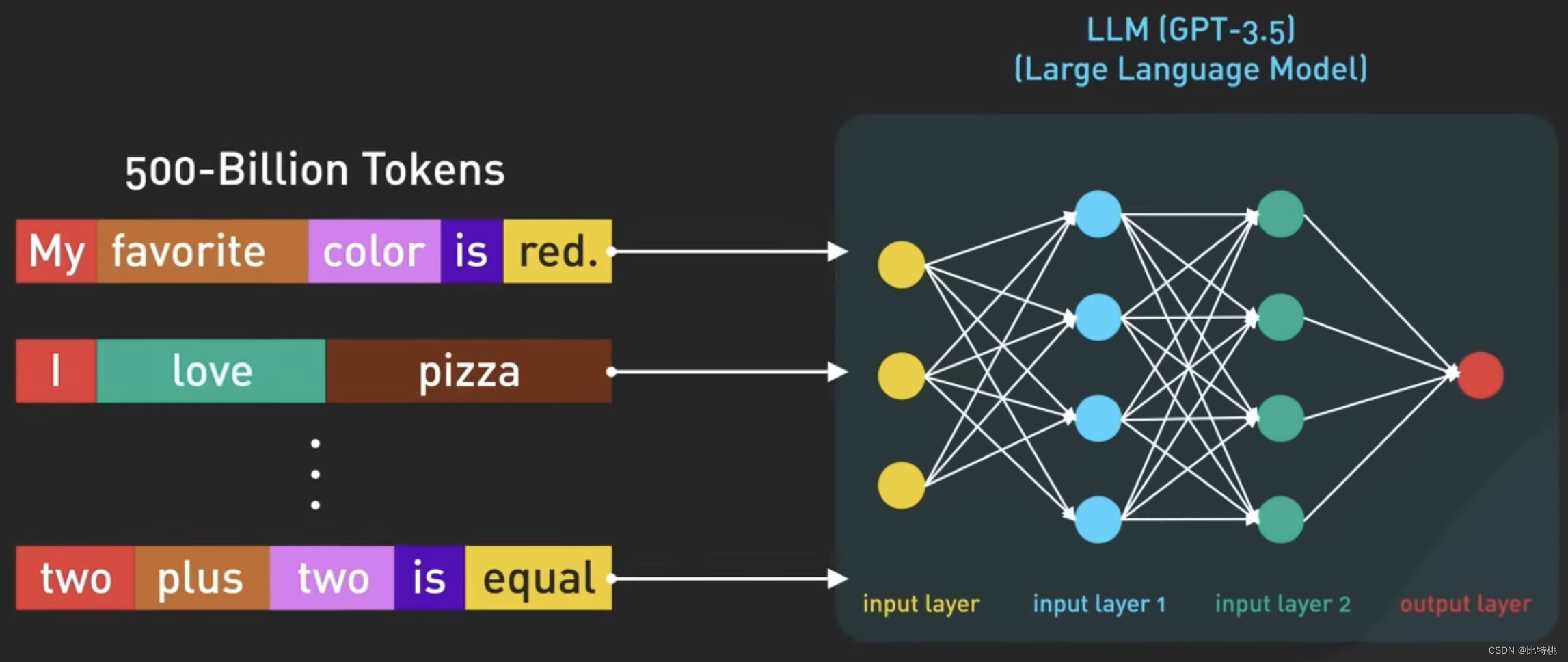
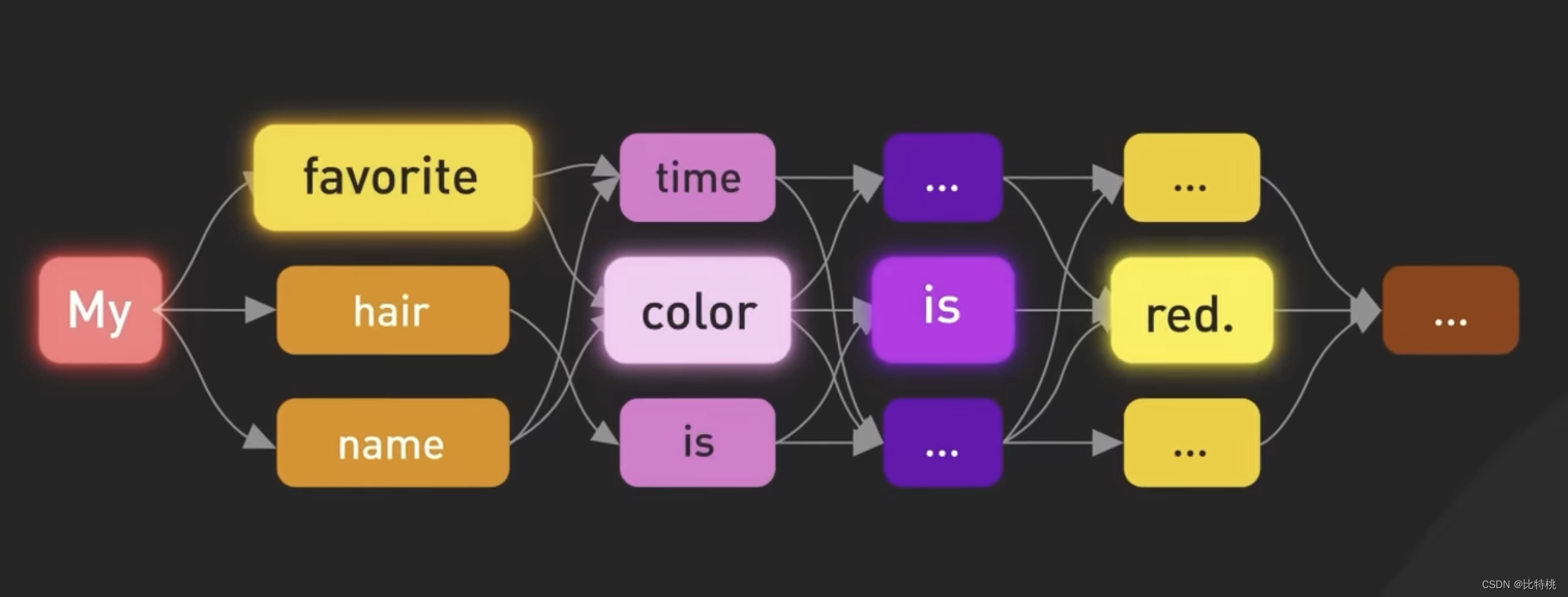
El modelo está entrenado para predecir el próximo token dada una secuencia de tokens de entrada. Es capaz de generar texto estructurado que es sintácticamente correcto y semánticamente similar a los datos de Internet en los que se entrenó.
4.3 Proceso de formación
Aunque después del proceso anterior, ChatGPT ya puede organizar respuestas de oraciones de forma autónoma. Pero sin la orientación adecuada, el modelo también puede generar resultados irreales o negativos.
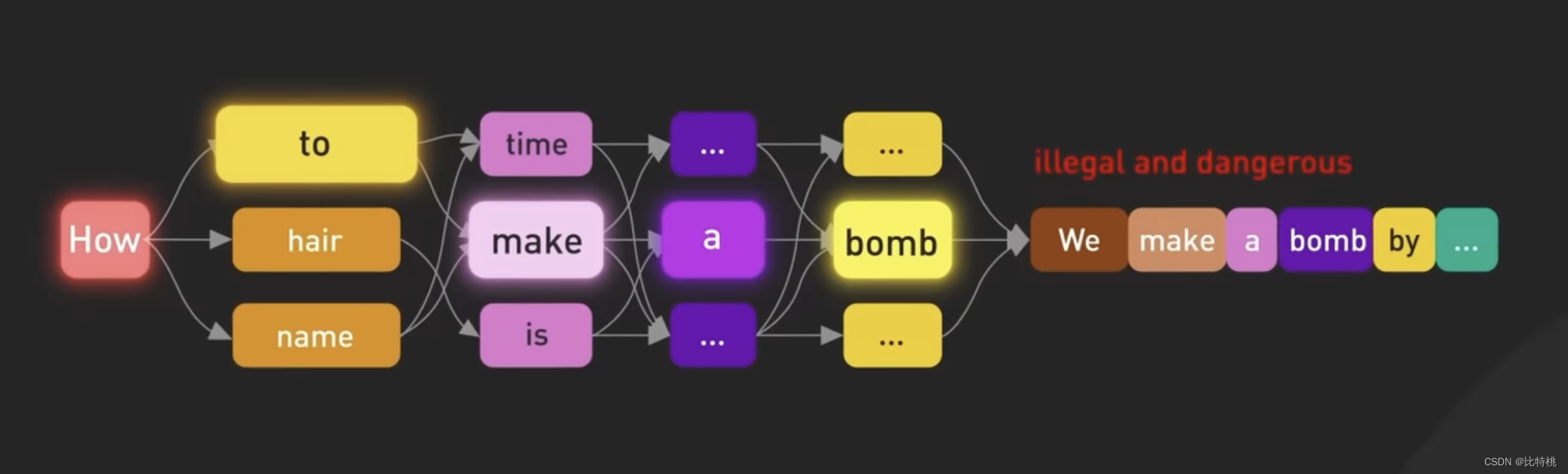
Para hacer que el modelo sea más seguro y capaz de preguntar y responder en forma de chatbot. Después de un mayor ajuste, este modelo se convirtió en la versión que se usa actualmente en ChatGPT. El ajuste fino es transformar un modelo que no se ajusta a los valores humanos en un ChatGPT controlable. Este proceso de ajuste fino del modelo se denomina entrenamiento de refuerzo con retroalimentación humana (RLHF).
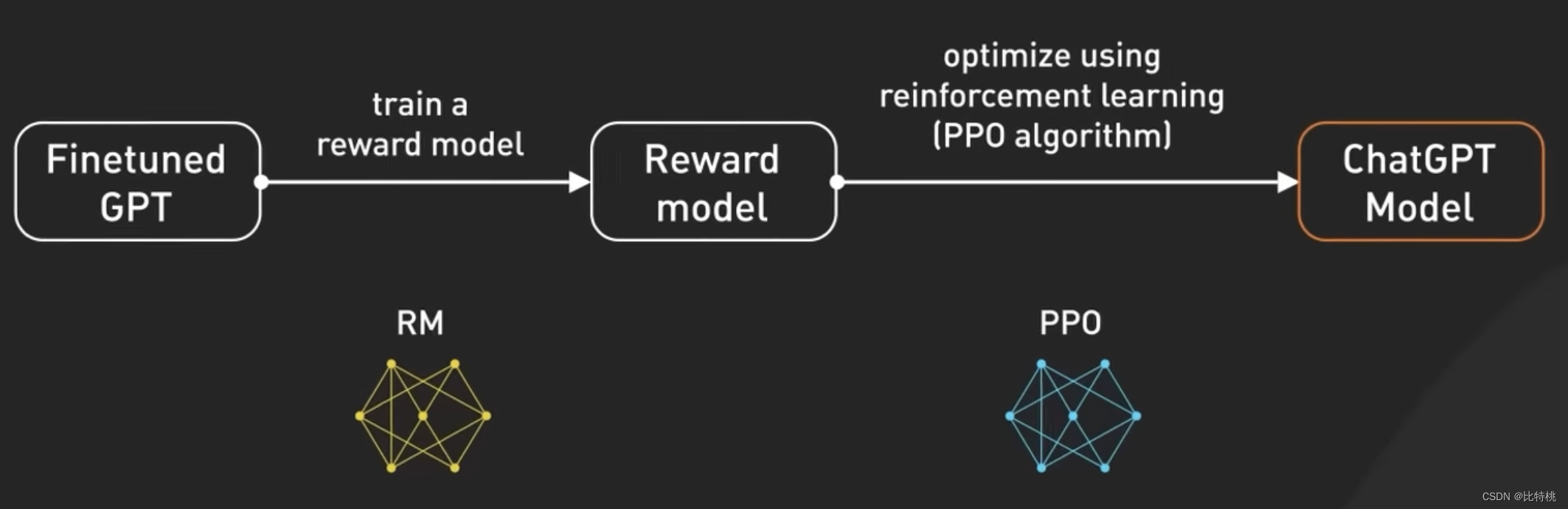
OpenAI explicó cómo ejecutan RLHF en su modelo, ajustar GPT 3.5 con RLHF es como mejorar las habilidades de un chef para que sus platos sean más deliciosos.
Inicialmente, los chefs recibieron capacitación sobre un gran conjunto de datos de recetas y técnicas de cocina. Sin embargo, a veces el chef no sabe hacer ese plato de acuerdo a la solicitud personalizada del cliente. Para ayudar a resolver este problema, recopilamos comentarios de usuarios reales para crear un nuevo conjunto de datos. El primer paso es crear un conjunto de datos de comparación, donde les pedimos a los chefs que preparen múltiples platos según los requisitos dados, y luego les pedimos a las personas que clasifiquen los platos según el sabor y la apariencia. Esto ayuda a los chefs a comprender qué platos les gustan a los clientes.
El siguiente paso es el modelado de recompensas, en el que los chefs usan estos comentarios para crear modelos de recompensas que actúan como guías para comprender las preferencias de los clientes. Cuanto mayor sea la recompensa, mejores serán los platos. A continuación, entrenamos el modelo usando PPO (es decir, Optimización de política de proximidad), en esta analogía, el chef practica la elaboración de platos mientras sigue el modelo de recompensa. Usan una técnica llamada "optimización de la estrategia próxima" para mejorar sus habilidades. Es como un chef que compara su plato actual con una versión ligeramente diferente y aprende cuál es mejor en función de un modelo de recompensa.
Este proceso se repite varias veces, y los chefs refinan sus habilidades en función de los últimos comentarios de los clientes. Con cada iteración, el chef mejora en la preparación de platos que satisfacen las preferencias del cliente. Visto desde otra perspectiva, GPT-3.5 afina RLHF al recopilar los comentarios de las personas, crear un modelo de recompensa basado en sus preferencias y luego usar PPO para mejorar iterativamente el rendimiento del modelo. Esto permite que GPT-3.5 genere mejores respuestas a las solicitudes específicas de los usuarios.
4.4 Aviso
Después de que el entrenador de GPT lo enseñe, podemos usar ChatGPT. Sin embargo, debido a que los parámetros de GPT basados en el modelo de lenguaje grande son demasiado complicados, también es muy importante expresar con precisión nuestras necesidades. En otras palabras, si desea tener un mejor diálogo con la IA, necesita un "lenguaje" rápido. Ahora hay muchos tutoriales en Internet para enseñarle cómo usar Prompt para comunicarse con AI de manera más eficiente.
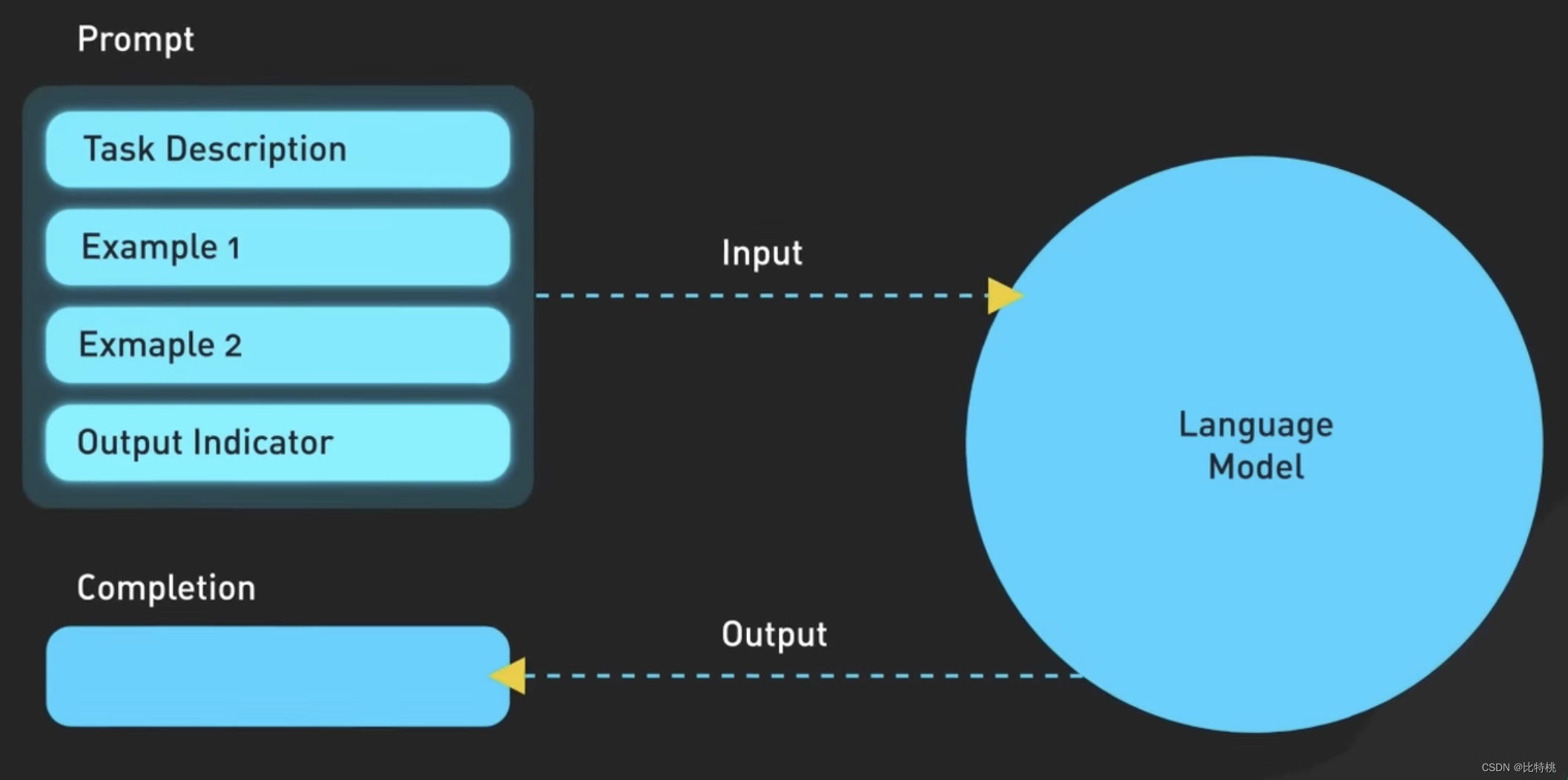
La siguiente figura es la lógica específica de Prompt. De hecho, cuanto más precisa sea la descripción, más precisa será ChatGPT.
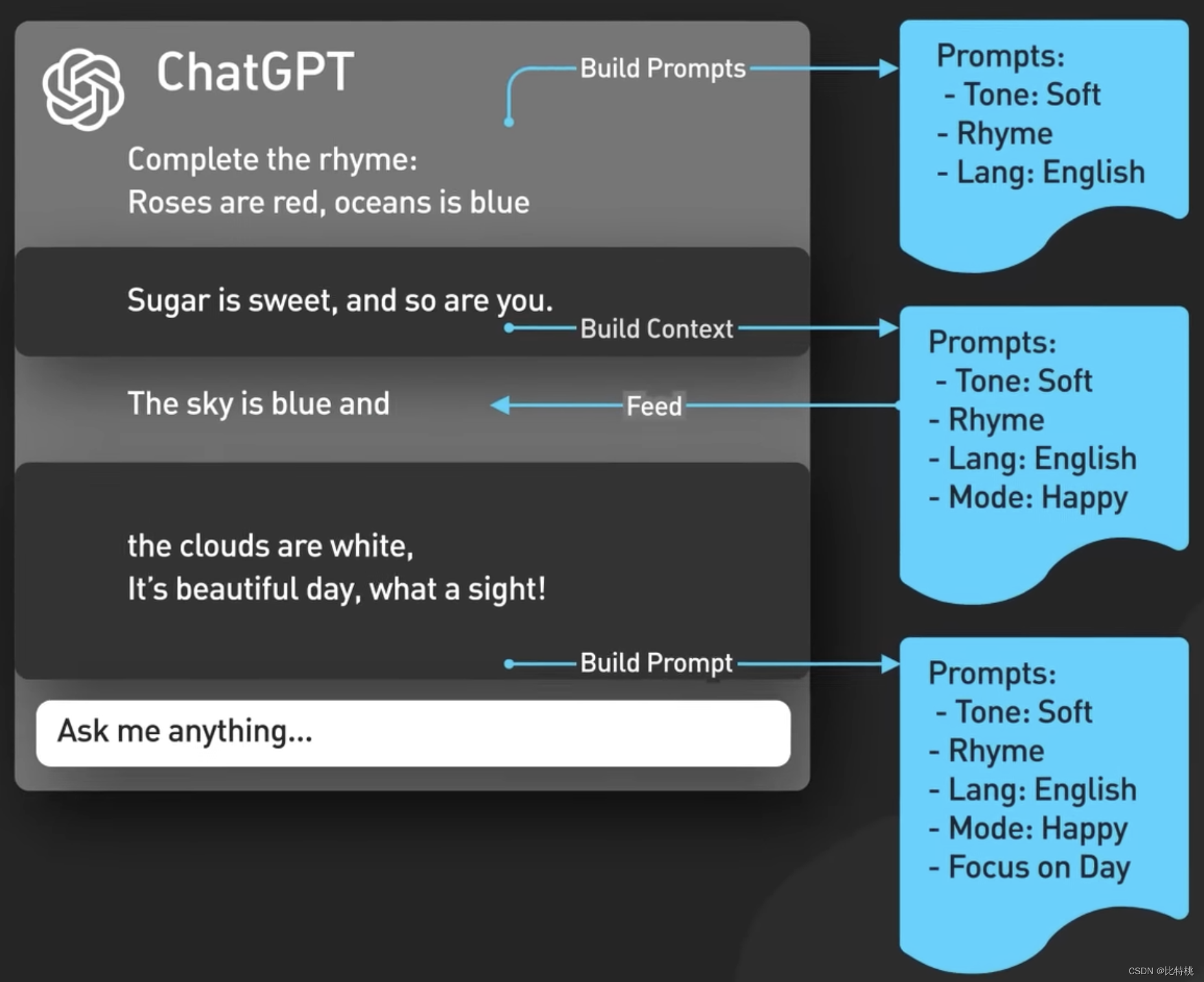
Conceptualmente, Prompt es tan simple como enviar una entrada a un modelo de ChatGPT y devolver una salida. De hecho, la situación es más complicada. Primero, ChatGPT comprende el contexto del diálogo de chat, lo que hace la interfaz de usuario de ChatGPT que alimenta el diálogo completo al modelo cada vez que se ingresa un mensaje nuevo.

Esto se llama inyección de solicitud de sesión, y así es como ChatGPT es consciente del contexto.
En segundo lugar, ChatGPT incluye contenido de avisos implícitos, que son instrucciones inyectadas antes y después de los avisos del usuario para guiar al modelo a usar un tono conversacional. Estas indicaciones son invisibles para el usuario. Por ejemplo, analizará el tono y el idioma de su entrada por adelantado.
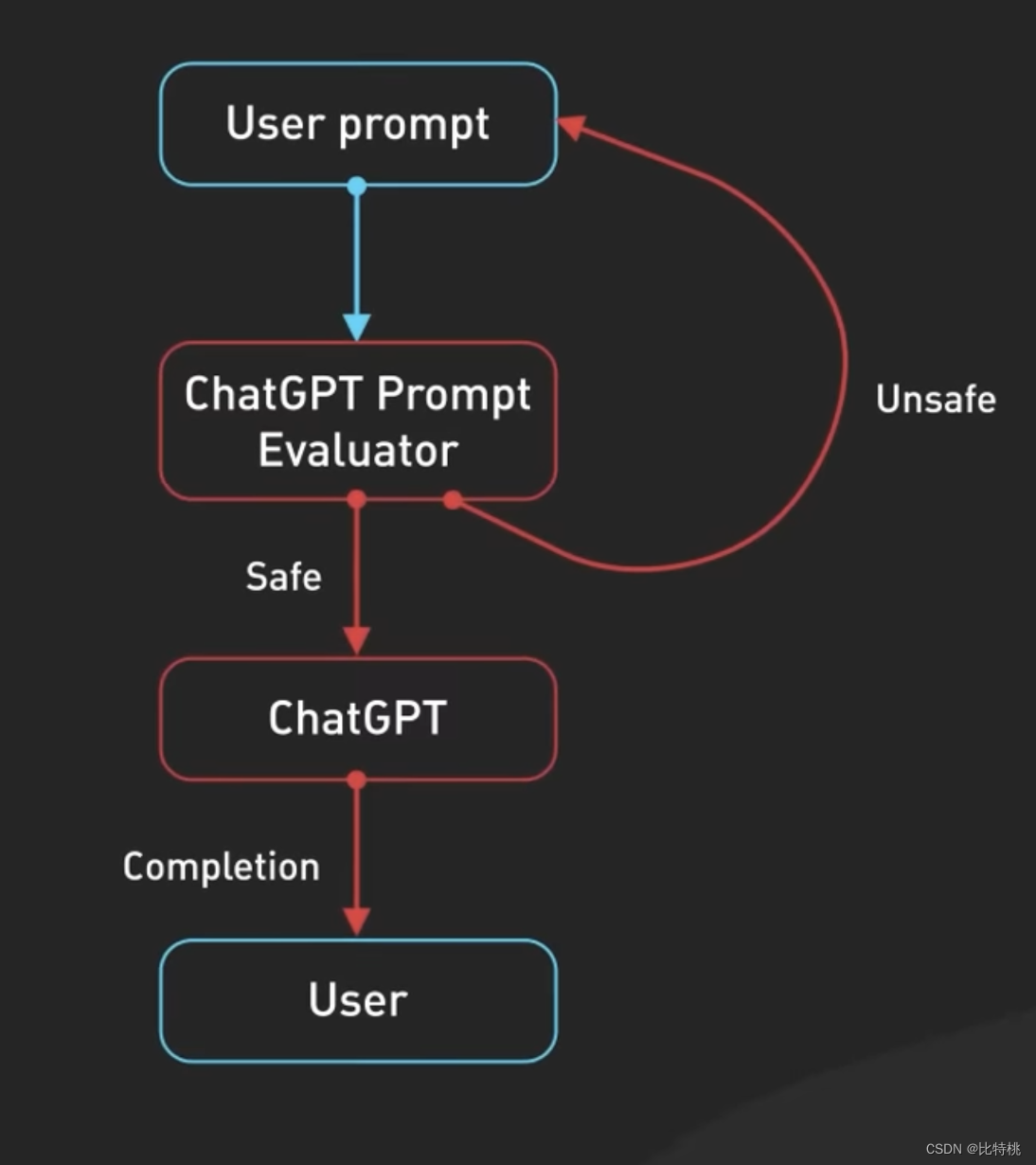
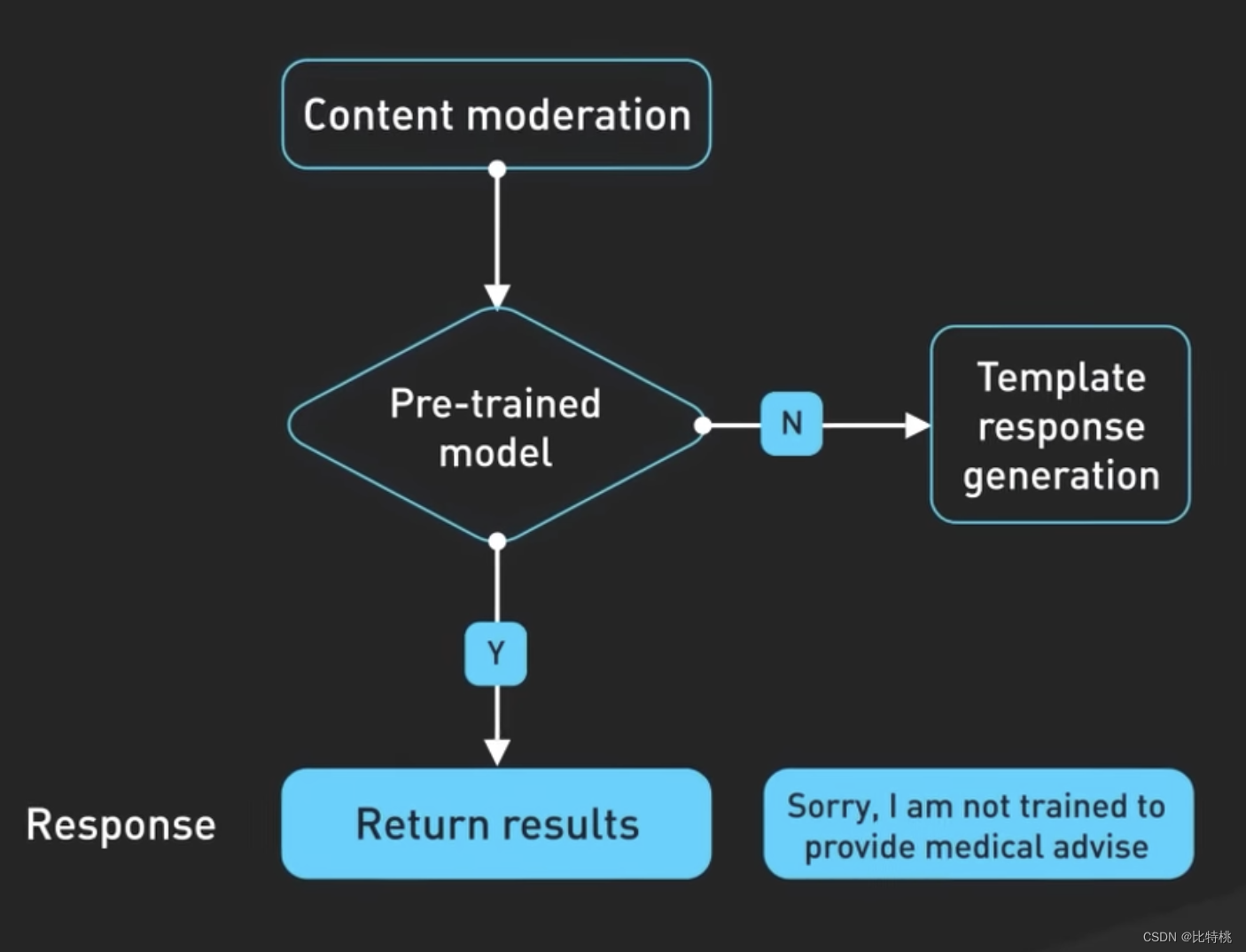
En tercer lugar, los avisos se pasan a la API de moderación para advertir o bloquear ciertos tipos de contenido inseguro. Las indicaciones se pasan a la API de moderación para advertir o bloquear ciertos tipos de contenido inseguro. Nota: si su mensaje es lo suficientemente potente, puede hacer que genere algún contenido especial.
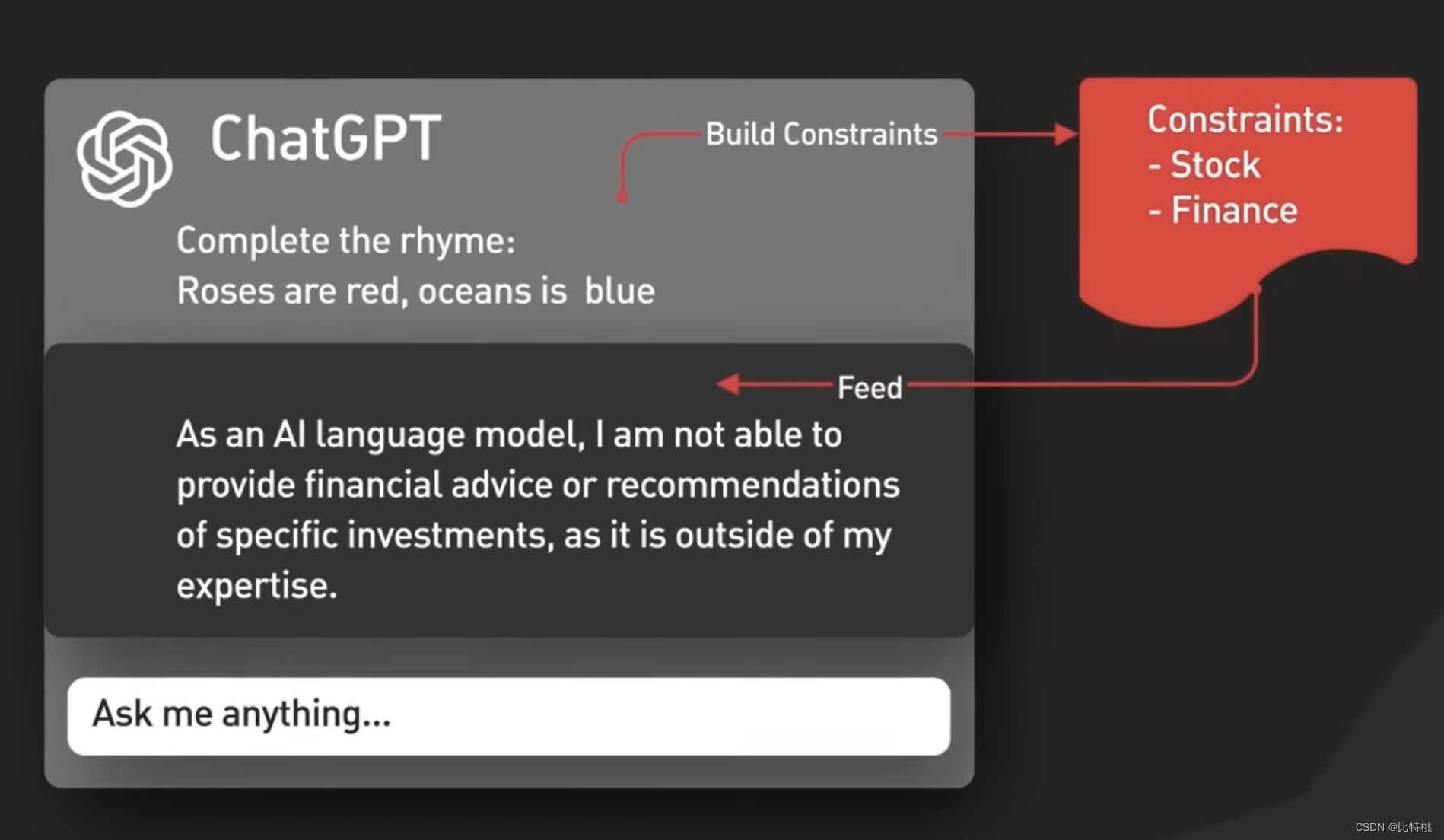
Los resultados generados también pueden pasar a una API de moderación antes de ser devueltos al usuario.
La creación de los modelos utilizados por ChatGPT requirió mucha ingeniería y la tecnología detrás de esto está en constante evolución, abriendo la puerta a nuevas posibilidades y remodelando la forma en que nos comunicamos. . . ChatGPT está revolucionando la forma en que trabajan los desarrolladores de software, mostrando cómo puede mejorar nuestras tareas diarias y aumentar la eficiencia. Para no quedarnos atrás, debemos entender cómo utilizar el poder de ChatGPT y mantenernos a la vanguardia en este mundo de rápido desarrollo de software.
V. Resumen
Ha habido varias revoluciones industriales en la historia, y cada revolución industrial se basa en avances científicos y el desarrollo de tecnologías de raíz. Por ejemplo, la primera revolución industrial, la mecánica clásica newtoniana y la termodinámica en el siglo XVIII tuvieron un gran avance. Watt mejoró la máquina de vapor y condujo a la humanidad a la era del vapor. Hizo de Gran Bretaña un imperio en el que el sol nunca se pone. A finales del siglo XIX y principios del siglo XX, Faraday descubrió el fenómeno de la inducción electromagnética y Maxwell explicó el principio de las ondas electromagnéticas. Los humanos inventaron los generadores, los motores eléctricos y las comunicaciones por radio. Esta es la segunda revolución industrial, que convirtió a Estados Unidos en la potencia número uno del mundo. A mediados del siglo XX, debido al desarrollo de la tecnología electrónica y la tecnología informática, la humanidad entró rápidamente en la era electrónica, que es la tercera revolución industrial. Aprovechando esta oportunidad, Japón salió rápidamente de la sombra de la guerra y se convirtió en uno de los países más desarrollados del mundo. China no logró ponerse al día con las tres primeras revoluciones industriales, y ahora el mundo se encuentra en medio de la cuarta revolución industrial representada por Internet inalámbrica, inteligencia artificial, nuevas energías y biotecnología. Esta vez los chinos no están ausentes, ya sea 5G o inteligencia artificial, o nuevas energías o biotecnología. Los científicos e ingenieros chinos tardaron más de 20 años en ponerse al día, y están a la vanguardia del mundo en muchas ciencias y tecnologías nuevas.