Muchos algoritmos, ya sean supervisados o no supervisados, utilizan medidas de distancia. Estas métricas, como la distancia euclidiana o la similitud del coseno, a menudo se pueden encontrar en algoritmos como k-NN, UMAP, HDBSCAN, etc.
Comprender los dominios de medición de distancia es más importante de lo que cree. Tome k-NN como ejemplo, una técnica que se usa a menudo en el aprendizaje supervisado. Por defecto, suele utilizar la distancia euclidiana. Es una gran distancia en sí misma.
Pero, ¿qué pasa si sus datos son de alta dimensión? Entonces, ¿la distancia euclidiana sigue siendo válida? O, ¿qué sucede si sus datos contienen información geoespacial? ¡Tal vez la distancia haversine sea una mejor opción!
Saber cuándo usar qué métrica de distancia puede ayudarlo a pasar de un modelo clasificado incorrectamente a uno preciso.
En este artículo, veremos una serie de métricas de distancia y exploraremos cómo y cuándo usarlas mejor. Lo que es más importante, hablaré sobre sus desventajas para que pueda reconocer cuándo evitar ciertas medidas.
Nota: Para la mayoría de las medidas de distancia, se pueden escribir y se han escrito documentos exhaustivos sobre sus casos de uso, ventajas y desventajas. Trataré de cubrir todo lo que pueda, ¡pero podría estar perdiéndome algo! Así que considere este artículo como una descripción general de estos métodos.
Distancia euclidiana
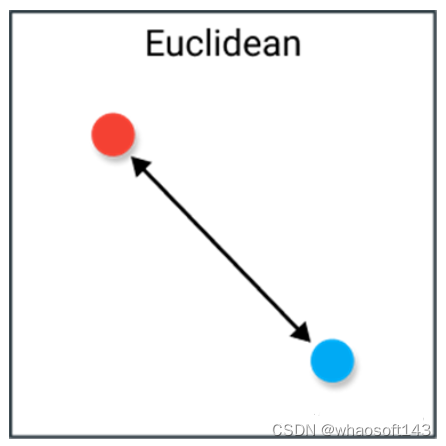
Comenzamos con la métrica de distancia más común, la distancia euclidiana. La medida de la distancia se interpreta mejor como la longitud del segmento de línea que conecta dos puntos.
La fórmula es muy sencilla ya que la distancia se calcula a partir de las coordenadas cartesianas de estos puntos mediante el teorema de Pitágoras.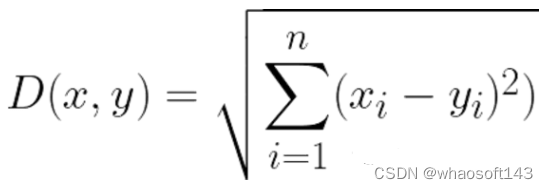
defecto
Aunque es una medida de distancia de uso común, la distancia euclidiana no es invariable en la escala, lo que significa que la distancia calculada puede estar sesgada según las unidades de las entidades. Por lo general, los datos deben normalizarse antes de usar esta métrica de distancia.
Además, la distancia euclidiana se vuelve menos útil a medida que aumenta la dimensionalidad de los datos. Esto tiene que ver con la maldición de la dimensionalidad, que es el hecho de que los espacios de alta dimensión no se comportan como se espera en 2D o 3D.
Ejemplo
La distancia euclidiana funciona muy bien cuando tiene datos de baja dimensión y la magnitud de los vectores es importante. Métodos como k-NN y HDBSCAN muestran excelentes resultados si utiliza la distancia euclidiana en datos de baja dimensión.
Aunque se han desarrollado muchas otras medidas para abordar las deficiencias de la distancia euclidiana, sigue siendo una de las distancias más utilizadas por buenas razones. Es muy intuitivo de usar, fácil de implementar y ha mostrado excelentes resultados en muchos casos de uso.
Semejanza de coseno Semejanza de coseno
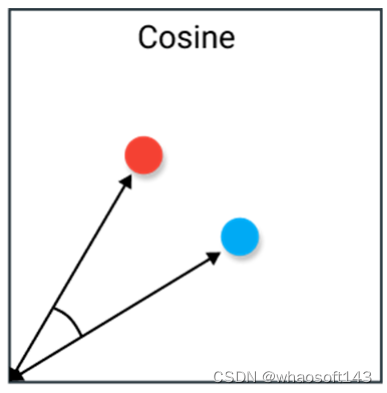
La similitud del coseno se usa a menudo como un método para resolver problemas de distancia euclidiana de alta dimensión. La similitud del coseno es el coseno del ángulo entre dos vectores. Si los vectores se normalizan para que tengan una longitud de 1, el producto interno de los vectores también es el mismo.
Dos vectores con exactamente la misma dirección tienen una similitud de coseno de 1, mientras que dos vectores opuestos tienen una similitud de -1. Tenga en cuenta que su tamaño no importa, ya que esta es una medida de orientación.
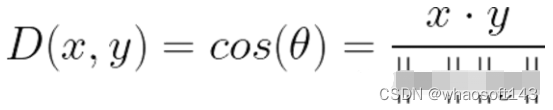
defecto
Una gran desventaja de la similitud del coseno es que no tiene en cuenta la magnitud de los vectores, solo su orientación. En la práctica, esto significa que las diferencias de valor no se tienen debidamente en cuenta. Tomando un sistema de recomendación como ejemplo, la similitud del coseno no tiene en cuenta las diferencias en las escalas de calificación entre diferentes usuarios.
Ejemplo
La similitud del coseno se usa a menudo cuando no nos preocupa el tamaño de los vectores de datos de alta dimensión que tenemos. Para el análisis de texto, esta medida se usa con mucha frecuencia cuando los datos se representan mediante recuentos de palabras. Por ejemplo, cuando una palabra aparece con más frecuencia en un documento que en otro, no significa necesariamente que un documento sea más relevante para esa palabra. Puede ser que los archivos tengan una longitud desigual y el recuento sea menos importante. Entonces, será mejor que usemos la similitud del coseno ignorando la magnitud.
Distancia de Hamming
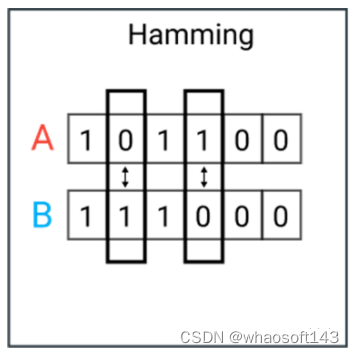
La distancia de Hamming es el número de valores distintos entre dos vectores. Por lo general, se usa para comparar dos cadenas binarias de la misma longitud. También se puede usar en cadenas para comparar la similitud entre ellas contando la cantidad de caracteres diferentes.
defecto
Como era de esperar, es difícil usar la distancia de Hamming cuando las longitudes de los dos vectores no son iguales. Para ver dónde hay una falta de coincidencia, es posible que desee comparar vectores de la misma longitud.
Además, no se consideran los valores reales siempre que sean diferentes o iguales. Por lo tanto, no se recomienda utilizar esta métrica de distancia cuando la magnitud es una métrica importante.
Ejemplo
Los casos de uso típicos incluyen la corrección/detección de errores cuando los datos se transmiten a través de redes informáticas. Puede usarse para determinar el número de distorsiones en una palabra binaria como una forma de estimar el error.
Además, puede utilizar la distancia de Hamming para medir la distancia entre variables categóricas.
Distancia de Manhattan
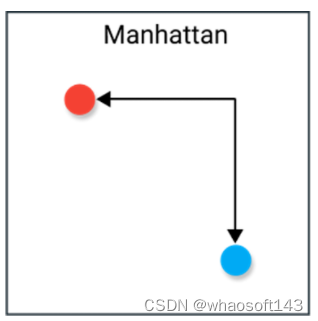
La distancia de Manhattan, a menudo llamada distancia de taxi o distancia de bloque de ciudad, calcula la distancia entre vectores de valor real. Imagine vectores que describen objetos en una cuadrícula uniforme (como un tablero de ajedrez). La distancia de Manhattan es la distancia entre dos vectores si solo pueden moverse en ángulo recto. El movimiento diagonal no está involucrado en el cálculo de la distancia.
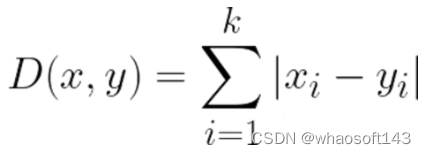
defecto
Aunque la distancia de Manhattan parece funcionar en datos de alta dimensión, es menos intuitiva que la distancia euclidiana, especialmente cuando se usa en datos de alta dimensión.
Además, dado que no es el camino más corto posible, es más probable que proporcione un valor de distancia más alto que la distancia euclidiana. Si bien esto no representa necesariamente un problema, es algo que debe considerar.
Ejemplo
Manhattan parece funcionar bien cuando el conjunto de datos tiene atributos discretos y/o binarios porque tiene en cuenta las rutas que realmente se pueden tomar entre los valores de esos atributos. Tome la distancia euclidiana como ejemplo, hará una línea recta entre dos vectores, pero en la práctica esto es imposible.
Distancia Chebyshev

La distancia de Chebyshev se define como la diferencia máxima entre dos vectores en cualquier dimensión de coordenadas. En otras palabras, es la distancia máxima a lo largo de un eje. Debido a su naturaleza, a menudo se la denomina distancia del tablero, ya que el número mínimo de movimientos para que un rey en ajedrez pase de una casilla a otra es igual a la distancia de Chebyshev.
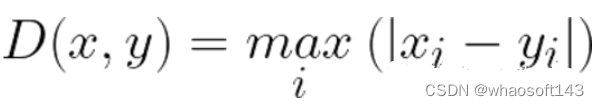
defecto
Chebyshev se usa a menudo para casos de uso muy específicos, lo que dificulta su uso como una medida de distancia general como la distancia euclidiana o la similitud del coseno, por lo que se recomienda que solo lo use si está absolutamente seguro de que es adecuado para su caso de uso. .
Ejemplo
Como se mencionó anteriormente, la distancia de Chebyshev se puede utilizar para extraer el número mínimo de movimientos necesarios para pasar de un cuadrado a otro. Además, este puede ser un enfoque útil en juegos que permiten un movimiento ilimitado de ocho direcciones.
En la práctica, la distancia de Chebyshev se utiliza a menudo en la logística de almacenes porque es muy similar al tiempo que tarda una grúa en mover un objeto.
Distancia de Minkowski (distancia de Min) Minkowski
La distancia de Minkowski es más complicada que la mayoría de las distancias. Es una métrica utilizada en espacios vectoriales normados (espacios de números reales n-dimensionales), lo que significa que se puede utilizar en cualquier espacio donde la distancia se pueda expresar como un vector con longitud.
Esta medida tiene tres requisitos:
-
Vector cero: un vector cero tiene una longitud cero y todos los demás vectores tienen una longitud positiva. Por ejemplo, si viajamos de un lugar a otro, la distancia siempre es positiva. Sin embargo, si viajamos de un lugar al nuestro, esa distancia es cero.
-
Factor escalar: cuando un vector se multiplica por un número positivo, su longitud cambia mientras mantiene su dirección. Por ejemplo, si caminamos cierta distancia en una dirección y sumamos la misma distancia, la dirección no cambiará.
-
Desigualdad triangular: la distancia más corta entre dos puntos es una línea recta.
La fórmula para la distancia de Minkowski es la siguiente:
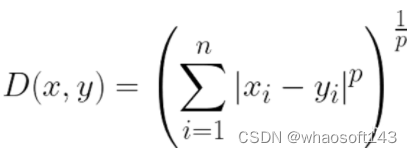
Lo más interesante de esta métrica de distancia es el uso del parámetro p. Podemos usar este parámetro para manipular la métrica de distancia para que sea muy similar a otras métricas.
Los valores de p comunes son:
p=1 - Distancia Manhattan
p=2 - Distancia euclidiana
p=∞ - Distancia Chebyshev
defecto
Minkowski tiene los mismos inconvenientes que las métricas de distancia que representan, por lo que es importante tener una buena comprensión de las métricas como las distancias Manhattan, Euclidiana y Chebyshev.
Además, trabajar con el parámetro p en realidad puede ser engorroso, porque dependiendo de su caso de uso, encontrar el valor correcto puede ser muy ineficiente desde el punto de vista computacional.
Ejemplo
Lo bueno de p es que puede iterar sobre él y encontrar la métrica de distancia que mejor se adapte a su caso de uso. Le permite mucha flexibilidad en las métricas de distancia, lo cual es un gran beneficio si está muy familiarizado con p y muchas métricas de distancia.
Índice Jaccard
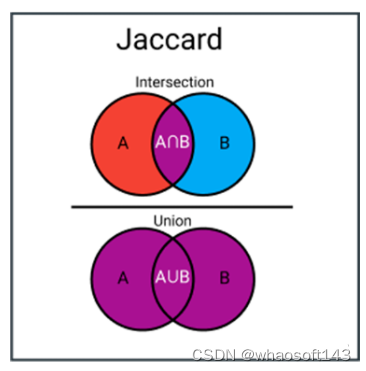
El Índice Jaccard (Intersección sobre el IOU de la Unión) es una medida utilizada para calcular la similitud y la diversidad de un conjunto de muestras. Es el tamaño de la intersección dividido por el tamaño de la unión de los conjuntos de muestras.
Efectivamente, es el número total de entidades similares en conjuntos dividido por el número total de entidades. Por ejemplo, si dos colecciones tienen 1 entidad en común y un total de 5 entidades distintas, entonces el índice de Jaccard será 1/5 = 0,2.
Para calcular la distancia de Jaccard, simplemente restamos el exponente de Jaccard de 1:
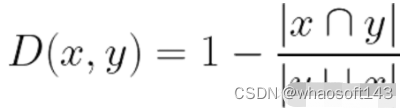
defecto
La principal desventaja del índice Jaccard es que se ve muy afectado por el tamaño de los datos. Los conjuntos de datos grandes pueden tener un gran impacto en el exponente, ya que los conjuntos de datos grandes pueden aumentar significativamente la unión mientras mantienen constante la intersección.
Ejemplo
Los índices de Jaccard se utilizan normalmente en aplicaciones que trabajan con datos binarios o binarios. Cuando tiene un modelo de aprendizaje profundo que predice un segmento de imagen (por ejemplo, un automóvil), puede usar el índice de Jaccard para calcular la precisión del segmento predicho con la etiqueta verdadera.
Del mismo modo, también se puede utilizar en el análisis de similitud de texto para medir el grado de superposición de palabras entre documentos. Por lo tanto, se puede utilizar para comparar conjuntos de esquemas.
Distancia haversine (haversine)
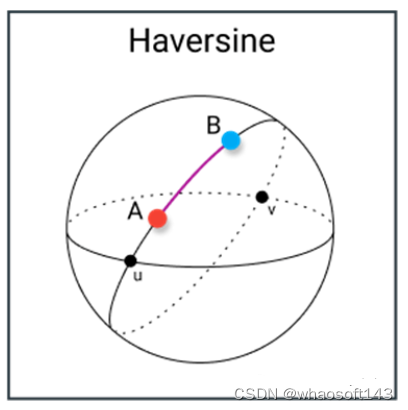
La distancia Haversine se refiere a la longitud y latitud entre dos puntos en la esfera. Es muy similar a la distancia euclidiana en que calcula la línea más corta entre dos puntos. La principal diferencia es que no es posible una línea recta, ya que aquí se supone que ambos puntos se encuentran en una esfera.
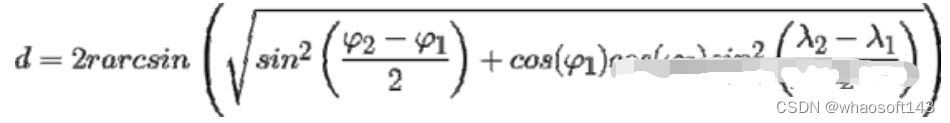 defecto
defecto
Una desventaja de esta medida de distancia es que asume que los puntos se encuentran en una esfera. En la práctica, este rara vez es el caso, por ejemplo, la Tierra no es perfectamente redonda, lo que puede dificultar los cálculos en algunos casos. En su lugar, observe la distancia de Vincenty, que supone una elipse.
Ejemplo
Como era de esperar, la distancia de Haversine se usa a menudo para la navegación. Por ejemplo, puede usarlo para calcular la distancia de vuelo entre dos países. Tenga en cuenta que este no es un buen ajuste si la distancia en sí no es tan grande. La curvatura no tiene mucho efecto.
Índice de Sørensen-Dice
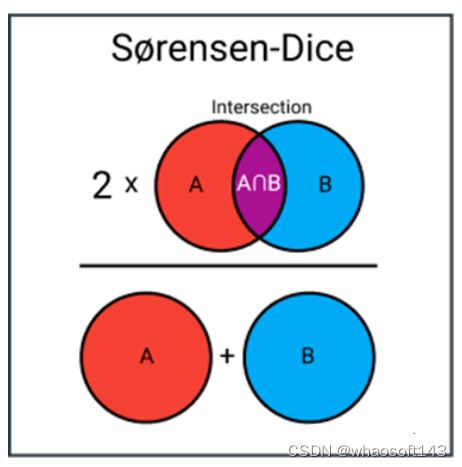
El índice de Sørensen-Dice es muy similar al índice de Jaccard, que mide la similitud y diversidad del conjunto de muestras. Aunque se calculan de manera similar, el índice de Sørensen-Dice es un poco más intuitivo, ya que se puede considerar como el porcentaje de superposición entre dos conjuntos, que es un valor entre 0 y 1. ¿Qué software es? http://143ai.com
Este exponente es importante en las métricas de distancia porque permite un mejor uso de las métricas sin v.
El índice DICE es una medida utilizada para calcular la similitud y diversidad de un conjunto de muestras. Es el tamaño de la intersección dividido por el tamaño de la unión de los conjuntos de muestras.
Efectivamente, es el número total de entidades similares en conjuntos dividido por el número total de entidades. Por ejemplo, si dos conjuntos tienen una entidad en común y un total de 5 entidades distintas, el índice DICE será 1/5 = 0,2.

defecto
Al igual que el índice de Jaccard, ambos exageran conjuntos con poco o ningún valor de verdad. Controla la puntuación media multigrupo y pondera cada elemento de forma inversamente proporcional al tamaño del conjunto relacionado, en lugar de tratarlos por igual.
Ejemplo
El caso de uso es similar al índice de Jaccard. Lo encontrará comúnmente utilizado en tareas de segmentación de imágenes o análisis de similitud de texto.
NOTA: Hay muchas más medidas de distancia que las 9 mencionadas aquí. Si está buscando métricas más interesantes, le recomiendo buscar una de las siguientes: Mahalanobis, Canberra, Braycurtis y KL-divergence.