-
Resolver el problema
A veces, subir documentos a Claude2 para su análisis tiene un límite de tamaño, por lo que es necesario cortar el documento pdf en varios documentos más pequeños, por lo que se publica este artículo.
¿Cómo hacer un PDF del tamaño que quieras con Python y PyMuPDF?
PDF es un formato de archivo ampliamente utilizado que se puede ver e imprimir en cualquier dispositivo. Sin embargo, a veces es posible que solo necesite ver las primeras páginas de un archivo PDF en lugar del archivo completo. En tales casos, puede ser útil convertir el archivo PDF en un nuevo archivo que contenga solo el número de páginas especificado. Este artículo describe cómo usar Python y el módulo PyMuPDF para lograr esta tarea.
-
Instalar el módulo PyMuPDF
Antes de usar PyMuPDF, primero debemos instalarlo. PyMuPDF se puede instalar con el siguiente comando:
pip install PyMuPDF-
Importar módulos PyMuPDF y wxPython
A continuación, necesitamos importar los módulos PyMuPDF y wxPython:
import fitz
import wx-
Crear una interfaz GUI
Para facilitar a los usuarios la entrada de la cantidad de archivos PDF y números de página, crearemos una interfaz GUI simple. Usaremos el módulo wxPython para crear la interfaz GUI. Aquí hay un ejemplo de código:
class PDFExtractorFrame(wx.Frame):
def __init__(self, *args, **kw):
super(PDFExtractorFrame, self).__init__(*args, **kw)
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
self.file_picker = wx.FilePickerCtrl(panel, message="选择PDF文件", wildcard="PDF Files (*.pdf)|*.pdf",
style=wx.FLP_DEFAULT_STYLE | wx.FLP_USE_TEXTCTRL)
vbox.Add(self.file_picker, 0, wx.EXPAND | wx.ALL, 10)
self.page_input = wx.TextCtrl(panel, value="1", style=wx.TE_PROCESS_ENTER)
vbox.Add(self.page_input, 0, wx.EXPAND | wx.ALL, 10)
extract_button = wx.Button(panel, label="提取", size=(70, 30))
extract_button.Bind(wx.EVT_BUTTON, self.on_extract)
vbox.Add(extract_button, 0, wx.ALIGN_CENTER | wx.ALL, 10)
panel.SetSizer(vbox)
self.Bind(wx.EVT_TEXT_ENTER, self.on_extract, self.page_input)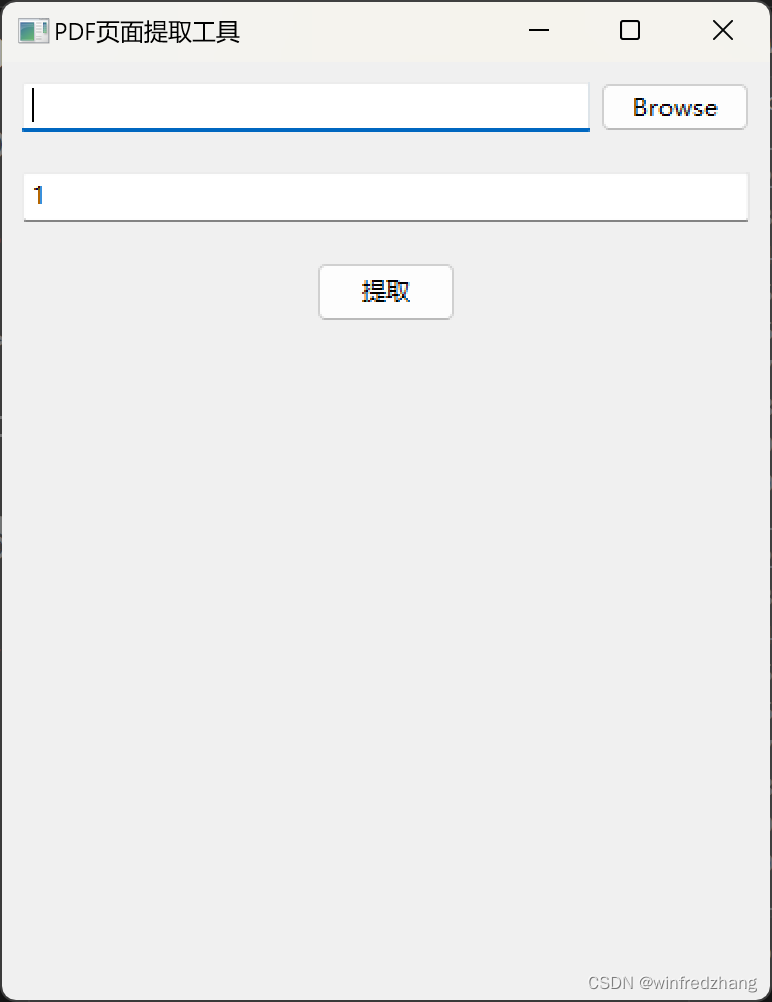
Este código crea una clase wx.Frame llamada PDFExtractorFrame y crea elementos de interfaz GUI en su constructor. Crea un objeto wx.Panel y dos objetos wx.BoxSizer para colocar los elementos de la GUI. En esta interfaz GUI, los usuarios pueden seleccionar un archivo PDF e ingresar el número de páginas que desea conservar.
-
Implementar la función de conversión
A continuación, necesitamos implementar la función de conversión. Usaremos el módulo PyMuPDF para abrir un archivo PDF y usarlo para copiar un número específico de páginas. Aquí hay un ejemplo de código:
def extract_pages(self, input_pdf, page_number, output_pdf):
# 打开PDF文档
pdf_document = fitz.open(input_pdf)
total_pages = pdf_document.page_count
# 确保页码不超过文档的总页数
page_number = min(page_number, total_pages)
# 创建新的PDF文档,只包含指定页码之前的内容
pdf_writer = fitz.open()
for page in range(page_number):
pdf_writer.insert_pdf(pdf_document, from_page=page, to_page=page)
# 保存新的PDF文档到指定路径
pdf_writer.save(output_pdf)
pdf_writer.close()
pdf_document.close()Este código usa las funciones del módulo PyMuPDF para convertir un archivo PDF en un nuevo archivo PDF que contiene solo las primeras N páginas. Esta función toma como parámetros la ruta del archivo PDF de origen, el número de páginas a extraer y la ruta de salida del nuevo archivo PDF, y devuelve Ninguno. La siguiente es una descripción detallada de la función:
- input_pdf: la ruta del archivo PDF de origen.
- page_number: El número de página a buscar.
- output_pdf: la ruta de salida del nuevo archivo PDF.
Esta función usa la función fitz.open() para abrir el archivo PDF de entrada y obtener su número total de páginas. Si el número especificado de números de página supera el número total de páginas del documento, se establece en el número total de páginas del documento.
Antes de crear un nuevo documento PDF, esta función crea un objeto de documento PDF vacío. A continuación, copia cada página del archivo PDF de origen mediante la función insert_pdf() y la inserta en un nuevo objeto de documento PDF. La función copia solo el número especificado de páginas.
Finalmente, la función usa la función save() para guardar el nuevo documento PDF en la ruta de salida especificada y usa la función close() para cerrar todos los objetos de documentos PDF abiertos para liberar recursos.
-
ejecutar la aplicación
 |
 |
-
código completo
import fitz # PyMuPDF
import wx
class PDFExtractorApp(wx.App):
def OnInit(self):
self.frame = PDFExtractorFrame(None, title="PDF页面提取工具")
self.SetTopWindow(self.frame)
self.frame.Show()
return True
class PDFExtractorFrame(wx.Frame):
def __init__(self, *args, **kw):
super(PDFExtractorFrame, self).__init__(*args, **kw)
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
self.file_picker = wx.FilePickerCtrl(panel, message="选择PDF文件", wildcard="PDF Files (*.pdf)|*.pdf",
style=wx.FLP_DEFAULT_STYLE | wx.FLP_USE_TEXTCTRL)
vbox.Add(self.file_picker, 0, wx.EXPAND | wx.ALL, 10)
self.page_input = wx.TextCtrl(panel, value="1", style=wx.TE_PROCESS_ENTER)
vbox.Add(self.page_input, 0, wx.EXPAND | wx.ALL, 10)
extract_button = wx.Button(panel, label="提取", size=(70, 30))
extract_button.Bind(wx.EVT_BUTTON, self.on_extract)
vbox.Add(extract_button, 0, wx.ALIGN_CENTER | wx.ALL, 10)
panel.SetSizer(vbox)
self.Bind(wx.EVT_TEXT_ENTER, self.on_extract, self.page_input)
def on_extract(self, event):
input_pdf = self.file_picker.GetPath()
output_pdf = "output.pdf"
try:
page_number = int(self.page_input.GetValue())
self.extract_pages(input_pdf, page_number, output_pdf)
wx.MessageBox("PDF页面提取完成!", "成功", wx.OK | wx.ICON_INFORMATION)
except ValueError:
wx.MessageBox("无效的页码输入!", "错误", wx.OK | wx.ICON_ERROR)
def extract_pages(self, input_pdf, page_number, output_pdf):
# 打开PDF文档
pdf_document = fitz.open(input_pdf)
total_pages = pdf_document.page_count
# 确保页码不超过文档的总页数
page_number = min(page_number, total_pages)
# 创建新的PDF文档,只包含指定页码之前的内容
pdf_writer = fitz.open()
for page in range(page_number):
pdf_writer.insert_pdf(pdf_document, from_page=page, to_page=page)
# 保存新的PDF文档到指定路径
pdf_writer.save(output_pdf)
pdf_writer.close()
pdf_document.close()
if __name__ == '__main__':
app = PDFExtractorApp()
app.MainLoop()
C:\pythoncode\new\copypdfsaveas.py