Directorio de artículos
detalles de la misión
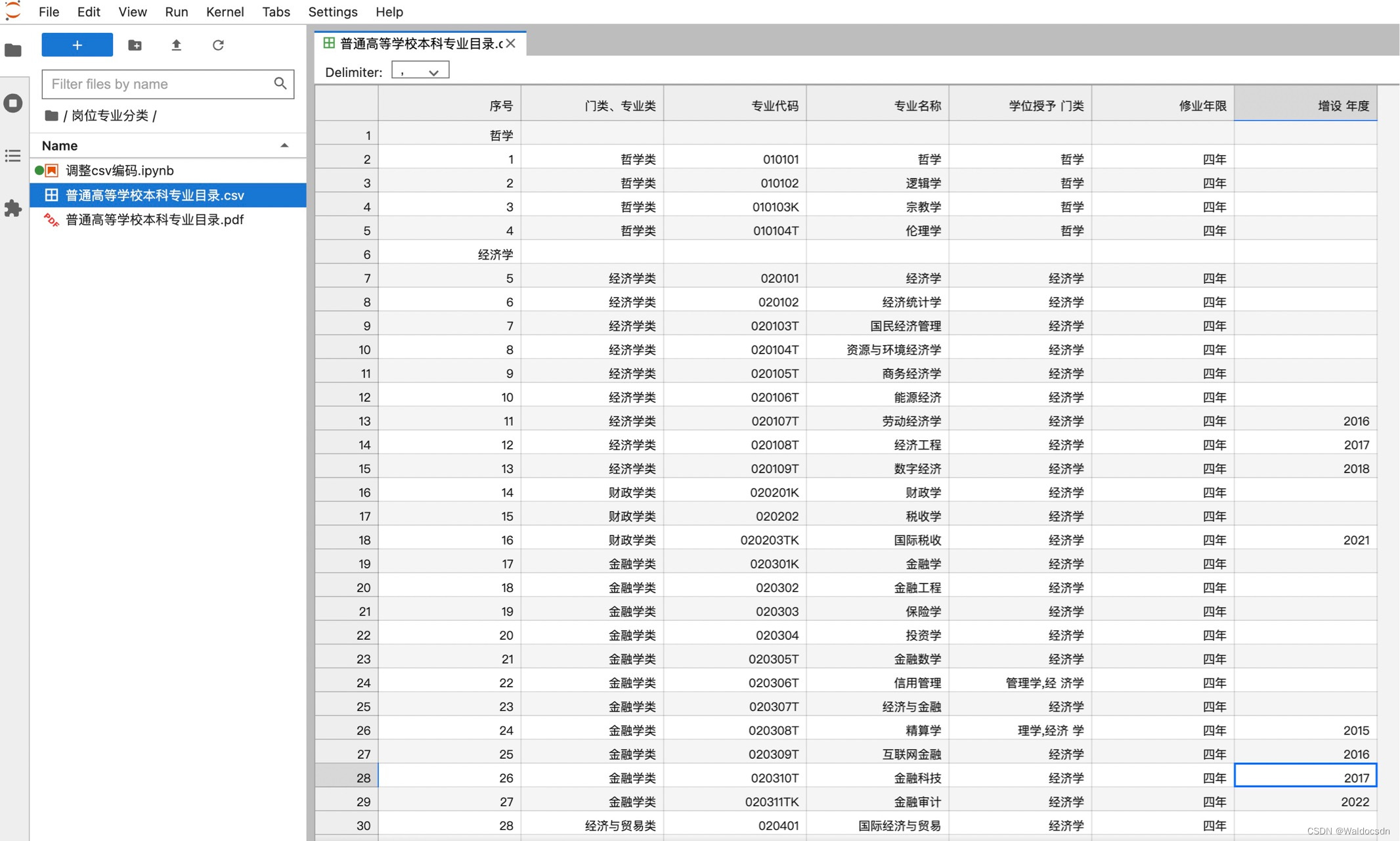
Convierta el archivo pdf llamado "Catálogo principal de pregrado de instituciones generales de educación superior.pdf" en un archivo csv. Cada página de este pdf es una tabla con 7 columnas.
A continuación se muestran la primera y la segunda página del pdf:
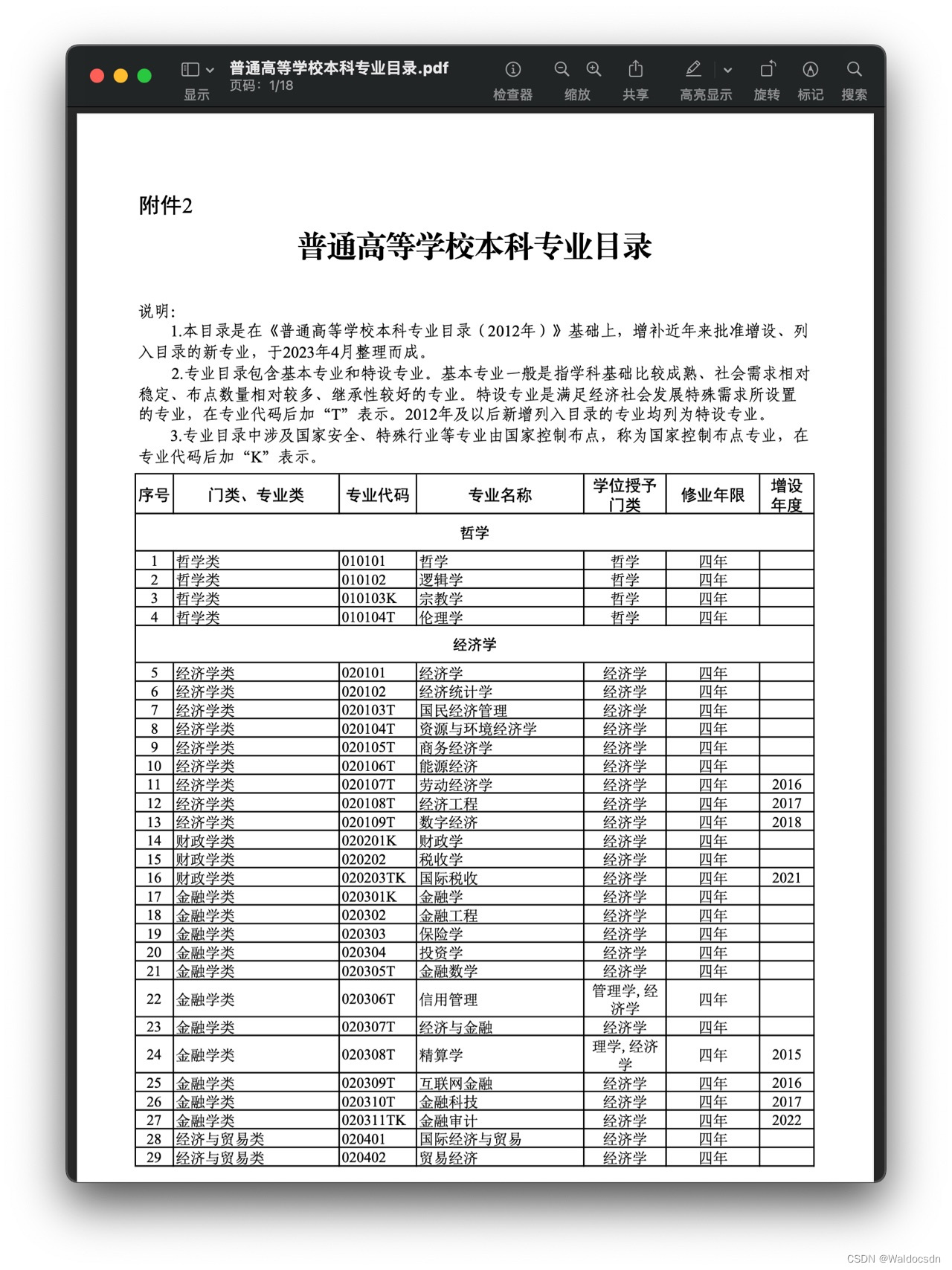
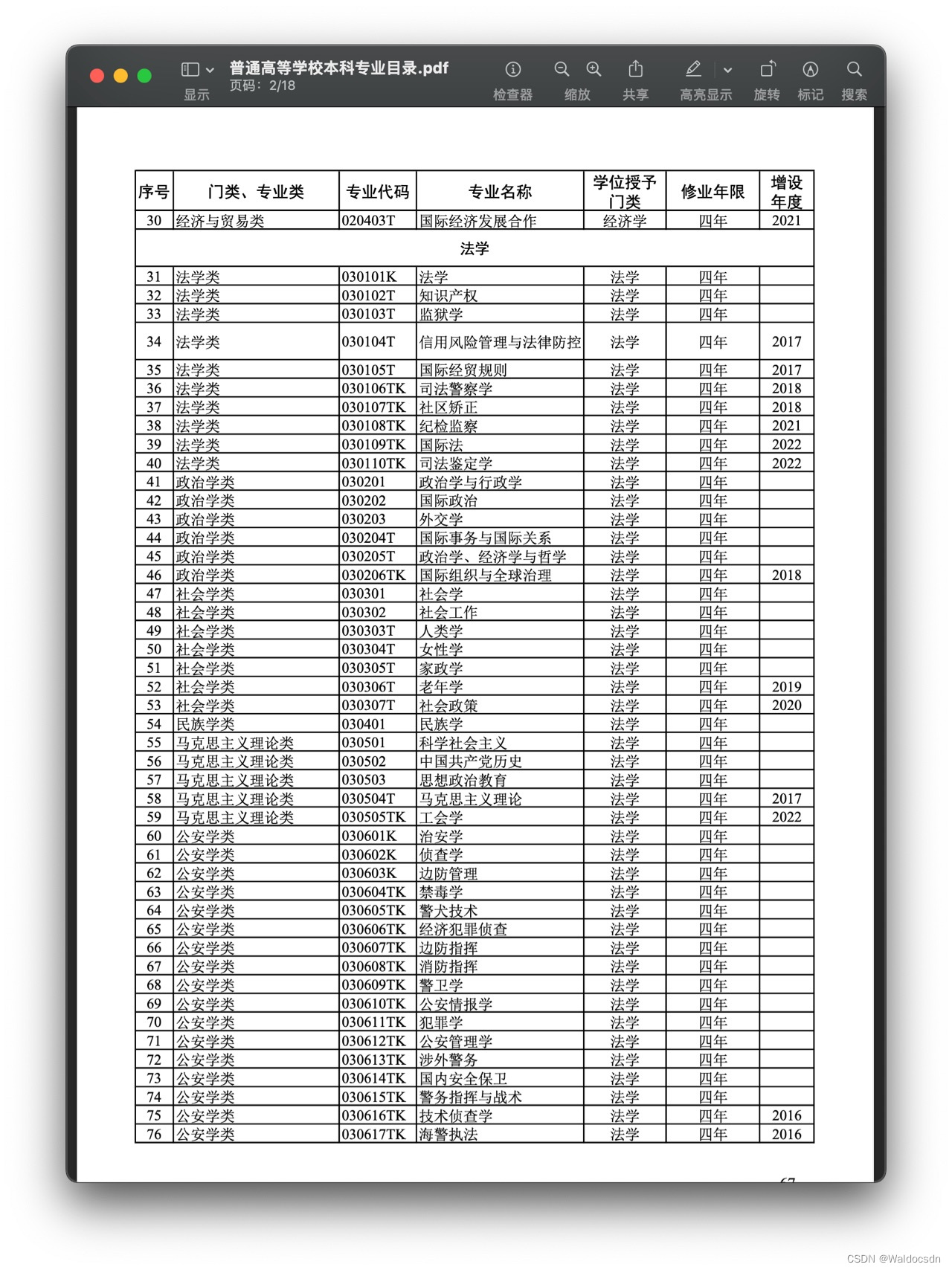
El enlace en pdf del catálogo principal de pregrado de colegios y universidades ordinarias de 2023
Enlace: https://pan.baidu.com/s/14acDd_L7AtXgKyq_LAV5Rg?pwd=hmne Código de extracción: hmne
el código
Hay varias bibliotecas en Python que se pueden usar para hacer esto. El siguiente es un código de muestra que se usa pdfplumberpara leer un archivo PDF y pandasguardar los datos en un archivo csv usando
Nota: Este código asume que las tablas en el archivo pdf son claramente identificables por líneas, y este método puede no funcionar para todos los archivos pdf, porque la estructura y el contenido del pdf pueden tener un impacto en el análisis.
import pdfplumber
import pandas as pd
def convert_pdf_to_csv(pdf_file):
# 打开pdf文件
with pdfplumber.open(pdf_file) as pdf:
# 初始化一个空的DataFrame用于存储所有页的数据
df_all = pd.DataFrame()
# 遍历每一页
for page in pdf.pages:
# 提取表格数据
tables = page.extract_tables()
for table in tables:
# 将表格数据转化为DataFrame
df = pd.DataFrame(table[1:], columns=table[0])
df_all = pd.concat([df_all, df])
# 保存为csv文件
df_all.to_csv(pdf_file.replace('.pdf', '.csv'), index=False)
# 使用函数
convert_pdf_to_csv("普通高等学校本科专业目录.pdf")
El código anterior iterará a través de cada página en el PDF y extraerá los datos tabulares de cada página. Los datos se combinarán y guardarán en un archivo CSV. El nombre del archivo CSV final será el mismo que el nombre del archivo PDF de entrada, pero con la extensión ".csv".
análisis de código
Este código se ejecuta en el entorno de Python. Primero, necesita importar dos bibliotecas: pdfplumbery pandas.
-
import pdfplumber:pdfplumberes una biblioteca de Python para extraer texto, tablas y metadatos en archivos PDF. -
import pandas as pd:pandases una biblioteca de análisis de datos de Python, que se usa principalmente aquí para crear y manipular DataFrame (una estructura de datos etiquetada bidimensional) y guardar DataFrame como un archivo csv.
Luego, defina una convert_pdf_to_csvfunción llamada , que acepte un parámetro pdf_fileque represente el nombre del archivo PDF que se va a convertir.
-
with pdfplumber.open(pdf_file) as pdf: La función a utilizarpdfplumberparaopenabrir el archivo PDF.withLa declaración se usa para envolver el contexto de la operación del archivo para garantizar que el archivo se cierre correctamente después de que se complete la operación. -
df_all = pd.DataFrame(): Inicialice un DataFrame vacío para almacenar los datos tabulares extraídos de cada página del PDF. -
for page in pdf.pages: Iterar a través de cada página del PDF. -
tables = page.extract_tables(): La función utilizadapdfplumberparaextract_tablesextraer los datos de la tabla de cada página, esto devuelve una lista, cada elemento representa una tabla en una página, la tabla en sí también es una lista, que contiene los datos de la fila. -
for table in tables: Para cada tabla extraída. -
df = pd.DataFrame(table[1:], columns=table[0]): Convierta datos tabulares en un DataFrame. Aquí se supone que la primera fila de la tabla es el nombre de la columna, por lo que la usamostable[0]como nombre de la columna y el restotable[1:]como datos. -
df_all = pd.concat([df_all, df]): combina el marco de datos de la página actual (df) con el marco de datos total (df_all). -
df_all.to_csv(pdf_file.replace('.pdf', '.csv'), index=False): Guarde el DataFrame final como un archivo csv. El nombre del archivo se obtiene reemplazando la parte '.pdf' del nombre del archivo PDF original con '.csv'. El parámetroindex=Falseindica que el índice no se incluye al guardar el csv.
La última línea es llamar a esta función para convertir el archivo PDF especificado en un archivo CSV.
ejecutar captura de pantalla