Introducción:
en el trabajo y estudio diario, es posible que necesitemos buscar y extraer contenido específico en archivos PDF. Este artículo presentará cómo implementar una herramienta de búsqueda de contenido PDF simple utilizando el lenguaje de programación Python y la biblioteca de interfaz gráfica de usuario wxPython. Usaremos el módulo PyMuPDF para procesar archivos PDF y combinaremos wxPython para crear una interfaz fácil de usar.
C:\pythoncode\new\pdffindcontent.py
Preparación
Antes de comenzar, asegúrese de haber instalado Python y los módulos correspondientes. Puede utilizar pip para instalar los módulos wxPython y PyMuPDF. Para conocer métodos de instalación específicos, consulte la documentación oficial.
Crear una interfaz GUI
Primero necesitamos crear una interfaz GUI para que los usuarios seleccionen archivos PDF para buscar e ingresar lo que buscan. Usamos la biblioteca wxPython para crear la interfaz.
def __init__(self, parent, title):
super(PDFSearchFrame, self).__init__(parent, title=title, size=(800, 600))
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
# 选择文件按钮
file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_OPEN|wx.FLP_FILE_MUST_EXIST)
file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.on_file_selected)
vbox.Add(file_picker, 0, wx.EXPAND|wx.ALL, 10)
# 输入框和按钮
hbox = wx.BoxSizer(wx.HORIZONTAL)
self.search_text = wx.TextCtrl(panel)
search_button = wx.Button(panel, label='搜索')
search_button.Bind(wx.EVT_BUTTON, self.on_search)
hbox.Add(self.search_text, 1, wx.EXPAND|wx.ALL, 5)
hbox.Add(search_button, 0, wx.ALL, 5)
vbox.Add(hbox, 0, wx.EXPAND|wx.ALL, 10)
# 显示框
self.display_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE|wx.TE_READONLY)
vbox.Add(self.display_text, 1, wx.EXPAND|wx.ALL, 10)
panel.SetSizer(vbox)
self.Show()
En el código anterior, hemos creado una PDFSearchFrameclase de ventana llamada, que hereda de la wx.Frameclase wxPython. En el constructor de esta clase, creamos varios componentes de la interfaz, incluido el botón de selección de archivos, el cuadro de entrada y el botón de búsqueda, y el cuadro de visualización.
Búsqueda y extracción de contenido PDF.
A continuación, debemos agregar al código la funcionalidad de búsqueda y extracción de contenido PDF. Usaremos el módulo PyMuPDF para procesar archivos PDF.
# 导入所需模块
import wx
import fitz
def on_search(self, event):
search_text = self.search_text.GetValue()
if not search_text or not self.pdf_path:
return
doc = fitz.open(self.pdf_path)
matches = []
for page in doc:
text = page.get_text().lower()
if search_text.lower() in text:
matches.append((page.number, text))
self.display_text.SetValue('')
if matches:
for page_num, text in matches:
self.display_text.AppendText(f"Page {
page_num}:\n{
text}\n\n")
else:
self.display_text.AppendText("未找到匹配的内容。")
doc.close()
En el código anterior, agregamos on_searchel código de búsqueda y extracción de contenido PDF en el método. Primero, usamos fitz.openla función para abrir el archivo PDF seleccionado e iterar por el contenido de texto de cada página. Luego convertimos el contenido del texto a minúsculas y verificamos si el texto de búsqueda está allí. Si se encuentran coincidencias adecuadas, las almacenamos en matchesuna lista. Finalmente, mostramos los resultados coincidentes en el cuadro de visualización y, si no se encuentra ningún contenido coincidente, se mostrará la información del mensaje correspondiente.
todos los codigos
import wx
import fitz
class PDFSearchFrame(wx.Frame):
def __init__(self, parent, title):
super(PDFSearchFrame, self).__init__(parent, title=title, size=(800, 600))
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
# 选择文件按钮
file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_OPEN|wx.FLP_FILE_MUST_EXIST)
file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.on_file_selected)
vbox.Add(file_picker, 0, wx.EXPAND|wx.ALL, 10)
# 输入框和按钮
hbox = wx.BoxSizer(wx.HORIZONTAL)
self.search_text = wx.TextCtrl(panel)
search_button = wx.Button(panel, label='搜索')
search_button.Bind(wx.EVT_BUTTON, self.on_search)
hbox.Add(self.search_text, 1, wx.EXPAND|wx.ALL, 5)
hbox.Add(search_button, 0, wx.ALL, 5)
vbox.Add(hbox, 0, wx.EXPAND|wx.ALL, 10)
# 显示框
self.display_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE|wx.TE_READONLY)
vbox.Add(self.display_text, 1, wx.EXPAND|wx.ALL, 10)
panel.SetSizer(vbox)
self.Show()
def on_file_selected(self, event):
self.pdf_path = event.GetPath()
def on_search(self, event):
search_text = self.search_text.GetValue()
if not search_text or not self.pdf_path:
return
doc = fitz.open(self.pdf_path)
matches = []
for page in doc:
text = page.get_text().lower()
if search_text.lower() in text:
matches.append((page.number, text))
self.display_text.SetValue('')
if matches:
for page_num, text in matches:
self.display_text.AppendText(f"Page {
page_num}:\n{
text}\n\n")
else:
self.display_text.AppendText("未找到匹配的内容。")
doc.close()
if __name__ == '__main__':
app = wx.App()
PDFSearchFrame(None, title="PDF搜索")
app.MainLoop()
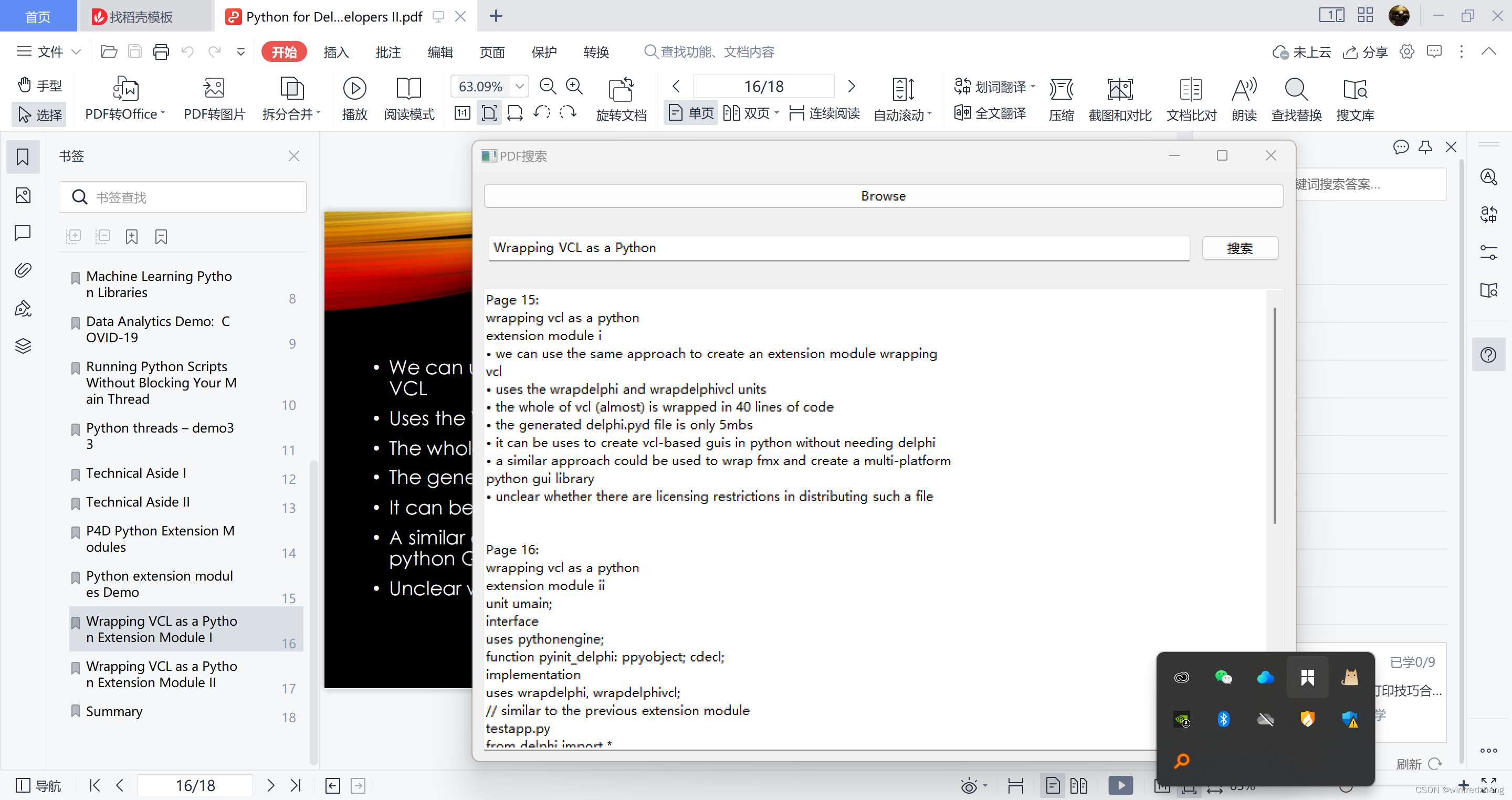
ejecuta el programa
Después de completar los pasos anteriores, podemos guardar y ejecutar el programa. Aparecerá una ventana con una herramienta de búsqueda de contenido PDF con función de búsqueda. Podemos seleccionar el archivo PDF para buscar, ingresar el contenido que queremos encontrar y hacer clic en el botón de búsqueda. El programa mostrará los resultados coincidentes en el cuadro de visualización, incluido el número de página encontrada y el contenido del texto correspondiente.
Resumen:
este artículo presenta cómo utilizar la biblioteca Python y wxPython para implementar una herramienta de búsqueda de contenido PDF sencilla. Al combinar el módulo PyMuPDF y la interfaz gráfica wxPython, podemos seleccionar fácilmente el archivo PDF e ingresar el contenido que queremos encontrar en el cuadro de entrada. El programa buscará contenido coincidente y extraerá el contenido de la página encontrada en el cuadro de visualización. Esta herramienta puede ayudarnos a encontrar y extraer rápidamente contenido específico en archivos PDF y mejorar la eficiencia del trabajo.
Palabras clave: Python, wxPython, PDF, búsqueda de contenido, PyMuPDF