Preparación ambiental:
Instalado de antemano, pycharm
abre Archivo ——> Configuración ——> Proyecto ——> Proyecto Interpriter
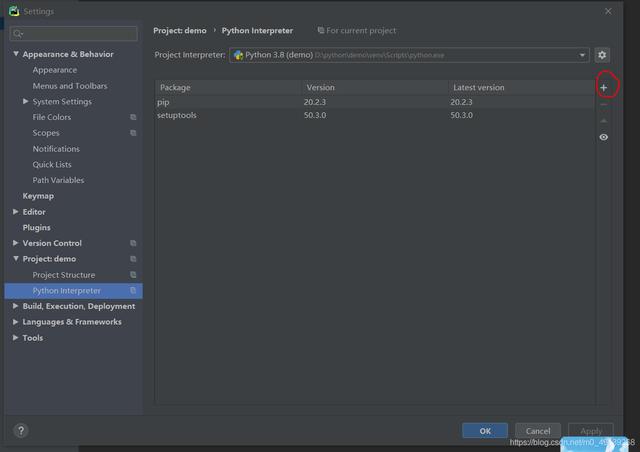
Haga clic en el signo más (en el círculo rojo de la imagen)
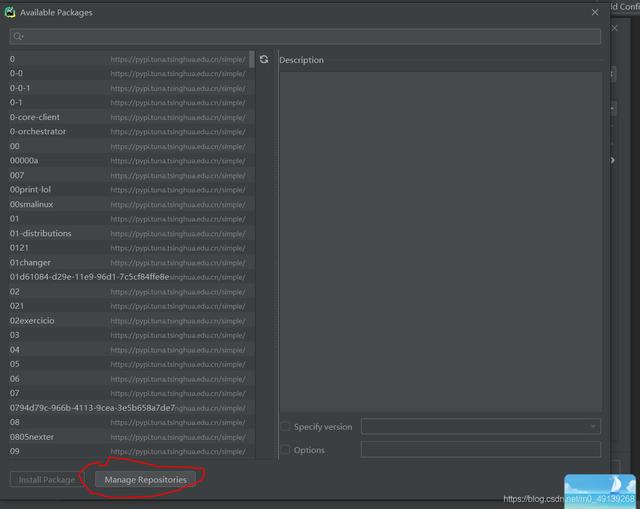
Haga clic en el botón en el círculo rojo
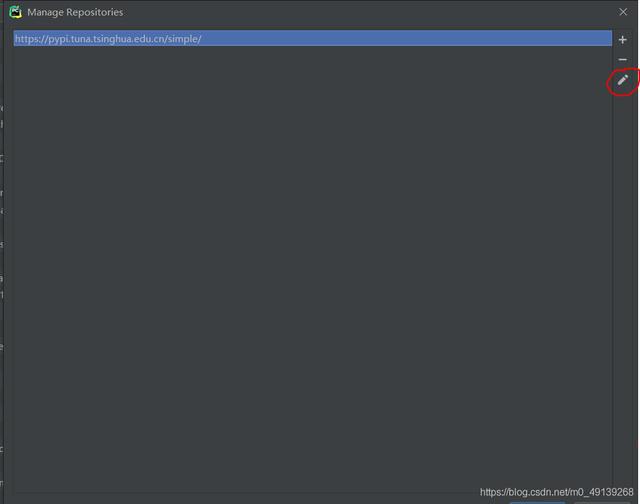
Seleccione el primero, haga clic en el lápiz y reemplace el enlace original con (se ha reemplazado aquí):
https://pypi.tuna.tsinghua.edu.cn/simple/ Después de
hacer clic en Aceptar, ingrese request-html y presione Enter para
seleccionar Haga clic en Instalar paquete después de las solicitudes-html

Espere a que la instalación se realice correctamente, cierre
Analizando el código fuente de la página web
Contenido de ejemplo:
rastrea el contenido deseado de todos los artículos de un determinado bloguero.
Antecedentes de ejemplo:
obtenga el título, la hora y el volumen de lectura de cada artículo de todos los artículos del blogger (https://me.csdn.net/weixin_44286745).
- Importe el método HTMLSession en request_html y cree su objeto
desde request_html importar sesión HTMLSession = HTMLSession () 123
- Utilice obtener solicitud para que el sitio web sea rastreado y obtenga el código fuente de la página.
html = session.get ("https://me.csdn.net/weixin_44286745") .html
12
- Encuentra todos los artículos
allBlog = html.xpath ("// dl [@ class = 'tab_page_list']")
1
- Ingrese a la página de inicio del sitio web (en este ejemplo: https://me.csdn.net/weixin_44286745)
- Haga clic derecho en el espacio en blanco del artículo para ubicar la etiqueta de este artículo
- Opere como otros artículos y luego busque las etiquetas comunes de todos los artículos (la clase de todos los artículos aquí es 'my_tab_page_con')
- xpath puede atravesar las diversas etiquetas y atributos de html para localizar y extraer la información que necesitamos.
- Análisis de la página web para obtener el título, volumen de lectura, fecha.
for i in allBlog:
title = i.xpath ("dl / dt / h3 / a") [0] .text
views = i.xpath ("// div [@ class = 'tab_page_b_l fl']") [0] .text
fecha = i.xpath ("// div [@ class = 'tab_page_b_r fr']") [0] .text
print (título + '' + vistas + '' + fecha)
12345
Análisis web:
- Debido a que hay varios artículos, se obtienen por separado utilizando un bucle for, y el código anterior ha obtenido todos los artículos, por lo que significa un artículo.
- La segunda línea de código obtiene el título del artículo, que es similar a obtener el artículo. Coloque el mouse sobre el título y haga clic con el botón derecho para verificar. Debido a que el artículo solo tiene un título, puede usar la ruta absoluta para llegar a la posición del título capa por etiqueta.
- Lo que devuelve xpath es una lista, queremos la primera, por lo que necesitamos agregar un subíndice (solo hay un elemento en la lista), y lo que queremos generar es texto, por lo que el texto obtiene el texto.
- La lectura de volumen y tiempo también son operaciones repetidas
- Puede usar una ruta relativa o una ruta absoluta. Generalmente, se usa una ruta relativa y el formato se modela a partir del código.
- La quinta línea de código, se genera cada vez que se obtiene información sobre un artículo, y toda la información se puede obtener después de recorrerla.
Código completo:
from request_html import HTMLSession
session = HTMLSession ()
html = session.get ("https://me.csdn.net/weixin_44286745") .html
allBlog = html.xpath ("// dl [@ class = 'tab_page_list']" )
para i en allBlog:
title = i.xpath ("dl / dt / h3 / a") [0] .text
views = i.xpath ("// div [@ class = 'tab_page_b_l fl']") [0 ] .text
date = i.xpath ("// div [@ class = 'tab_page_b_r fr']") [0] .text
print (title + '' + views + '' + date)
1234567891011121314
Puede rastrear otras cosas usted mismo, como imágenes de artículos, ¡pruébelo! ! !
Continuará
Solicitar vía html
Haga clic aquí para obtener el código completo del proyecto