AFM
(Leyendo el artículo) Estimación Ctr-Análisis del modelo AFM del sistema de recomendación



self.P.shape
Out[18]: torch.Size([4])
Si hay 39 dominios, entonces hay m ⋅ (m - 1) 2 \ frac {m \ cdot (m-1)} {2}2m ⋅ ( m - 1 )= 741 interacciones de entidades , WW de la capa de atenciónW es una matriz de 4x4,hhh es una capa de salida 4x1, aij = [741], normalizada por softmax
DCN
(Leyendo el artículo) Predicción CTR-modelo DCN análisis del sistema de recomendación
Alguien en el área de comentarios conoce al autor
Desmitificando Deep & Cross: Cómo construir automáticamente características cruzadas de alto orden
DCN implementado con tensorflow
Está a solo un paso de jugar el modelo de red profunda y cruzada de nivel empresarial
xl_w.shape
Out[9]: torch.Size([32, 1, 1])
dot_.shape
Out[10]: torch.Size([32, 117, 1])
x_l.shape
Out[11]: torch.Size([32, 117, 1])
xl_w.shape
Out[9]: torch.Size([32, 1, 1])
dot_.shape
Out[10]: torch.Size([32, 117, 1])
x_l.shape
Out[11]: torch.Size([32, 117, 1])
(Leyendo el artículo) Predicción CTR-modelo DCN análisis del sistema de recomendación

Suponga que hay 117 características, producto interno y propio, la característica se deja con 1, multiplicado por el peso, el número de columnas de peso es el mismo que la característica 117.
NFM
FM también se puede considerar como una arquitectura de red neuronal, es decir, el NFM con la capa oculta eliminada.
La diferencia más importante de NFM es la capa de bi-interacción. Tanto Wide & Deep como DeepCross reemplazan Bi-Interaction con concatenación.
La mayor desventaja de la operación de Concatenación es que no considera ninguna información de combinación de características, por lo que todo depende del MLP posterior para aprender la combinación de características, pero desafortunadamente, la optimización del aprendizaje de MLP es muy difícil.
El uso de Bi-Interaction tiene en cuenta la combinación de características de segundo orden, de modo que la representación de entrada contiene más información y reduce la presión de aprendizaje de la parte MLP posterior, por lo que puede usar un modelo más simple (solo se usa una capa oculta en el experimento) para obtener mejores resultados.
Casi sesgado por un cierto código, veamos la implementación oficial
https://github.com/guoyang9/NFM-pyorch
DESDE

Hay 3 muestras, por lo que la función de secuencia es como máximo de 3 filas. La secuencia más larga tiene 4 elementos y los demás se rellenan con 0.
deepctr_torch/models/basemodel.py:185El código pasado , el número de ejes de todos los tensores se normaliza a 2
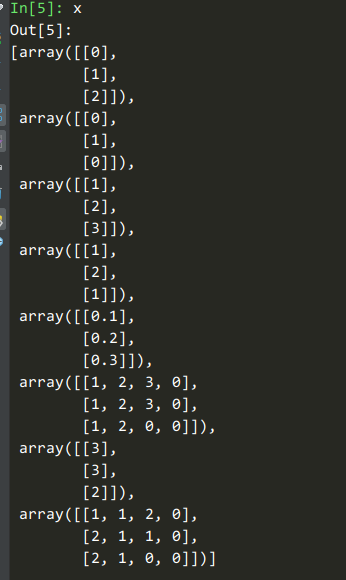
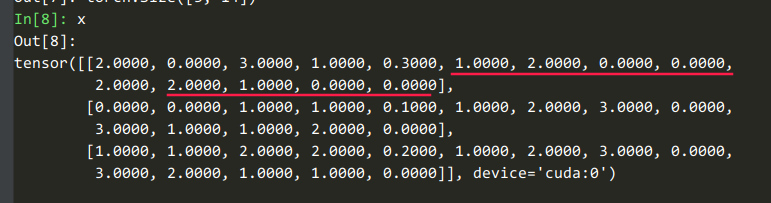
6 características sin secuencia, 2 características de secuencia con longitud de secuencia 4, 6 + 4x2 = 14
Ingresardeepctr_torch.models.din.DIN#forward
input_from_feature_columnsEsta función se utiliza para extraer características densas y escasas.
_, dense_value_list = self.input_from_feature_columns(...
dense_value_list
Out[10]:
[tensor([[0.3000],
[0.1000],
[0.2000]], device='cuda:0')]
query_emb_listSí sparse_feature_columnsincrustado
self.history_feature_list # 用户指定的
Out[16]: ['item', 'item_gender']
self.history_fc_names # 系统指定的, 前缀是 hist_
Out[17]: ['hist_item', 'hist_item_gender']
query_emb_listEstá ['item', 'item_gender']haciendo Embed:
query_emb_list[0].shape
Out[21]: torch.Size([3, 1, 8])
query_emb_listEstá ['hist_item', 'hist_item_gender']haciendo Embed:
keys_emb_list[0].shape
Out[20]: torch.Size([3, 4, 8])
Mirando hacia atrás en este pequeño fragmento de código del constructor DIN, es fácil determinar si se trata de una variable dispersa de longitud variable o una variable histórica:
Empalme en la dimensión de incrustación
# concatenate
query_emb = torch.cat(query_emb_list, dim=-1) # [B, 1, E]
keys_emb = torch.cat(keys_emb_list, dim=-1)
keys_emb.shape
Out[24]: torch.Size([3, 4, 16]) # 16 = 8 * 2
keys_length
Out[29]: tensor([2, 3, 3], device='cuda:0')
verdeepctr_torch.layers.sequence.AttentionSequencePoolingLayer#forward
verdeepctr_torch.layers.core.LocalActivationUnit#forward
queries = query.expand(-1, user_behavior_len, -1)
query.shape
Out[38]: torch.Size([3, 1, 16])
queries.shape
Out[37]: torch.Size([3, 4, 16])
Copie la consulta en el eje de longitud de secuencia para que coincida con las claves
En el eje de inserción, [consulta, clave, elemento menos, producto del elemento]
attention_input.shape
Out[40]: torch.Size([3, 4, 64])
attention_output.shape
Out[39]: torch.Size([3, 4, 16])
Esto es deepctr_torch.layers.core.DNNun poco interesante
self.dnn
Out[41]:
DNN(
(dropout): Dropout(p=0)
(linears): ModuleList(
(0): Linear(in_features=64, out_features=64, bias=True)
(1): Linear(in_features=64, out_features=16, bias=True)
)
(activation_layers): ModuleList(
(0): Dice(
(bn): BatchNorm1d(64, eps=1e-08, momentum=0.1, affine=True, track_running_stats=True)
(sigmoid): Sigmoid()
)
(1): Dice(
(bn): BatchNorm1d(16, eps=1e-08, momentum=0.1, affine=True, track_running_stats=True)
(sigmoid): Sigmoid()
)
)
)
Tenga en cuenta que aquí se deben reunir varios dominios de funciones para obtener una atención única.
Creo que se puede entender que un usuario ha visitado muchos elementos y los elementos tienen muchos atributos, como [item_id, cat_id, brand_id]. Necesitamos considerar estos atributos de manera integral, pero al reflejar el peso de un artículo, solo puede haber un peso (en lugar de un peso para cada atributo).
(Hay posibilidad de mejora)
attention_score.shape
Out[42]: torch.Size([3, 4, 1])
Atrás deepctr_torch.models.din.DIN#forward, después de usar Atención, equivale a un promedio ponderado de la secuencia histórica.