Categoría: Catálogo General de "Entendimiento Profundo del Aprendizaje Profundo"
Artículos Relacionados:
GPT (Transformador Generativo Pre-Entrenado): Conocimientos Básicos
GPT (Transformador Generativo Pre-Entrenado): Uso de GPT en Diferentes Tareas GPT
( Transformador Generativo Pre-Entrenado) : GPT-2 y aprendizaje de disparos cero
GPT (transformador preentrenado generativo): GPT-3 y aprendizaje de pocos disparos
GPT-3 solía ser el modelo de lenguaje previo al entrenamiento más grande, sorprendente y controvertido. El documento que presenta GPT-3 tiene 72 páginas e incluye ideas de diseño de modelos, derivación teórica, resultados experimentales y diseño experimental. El modelo GPT-3 es demasiado grande, con 175 000 millones de parámetros. Incluso si es de código abierto, no se puede implementar como un modelo de lenguaje preentrenado para uso personal debido al gran modelo y los requisitos de potencia informática.
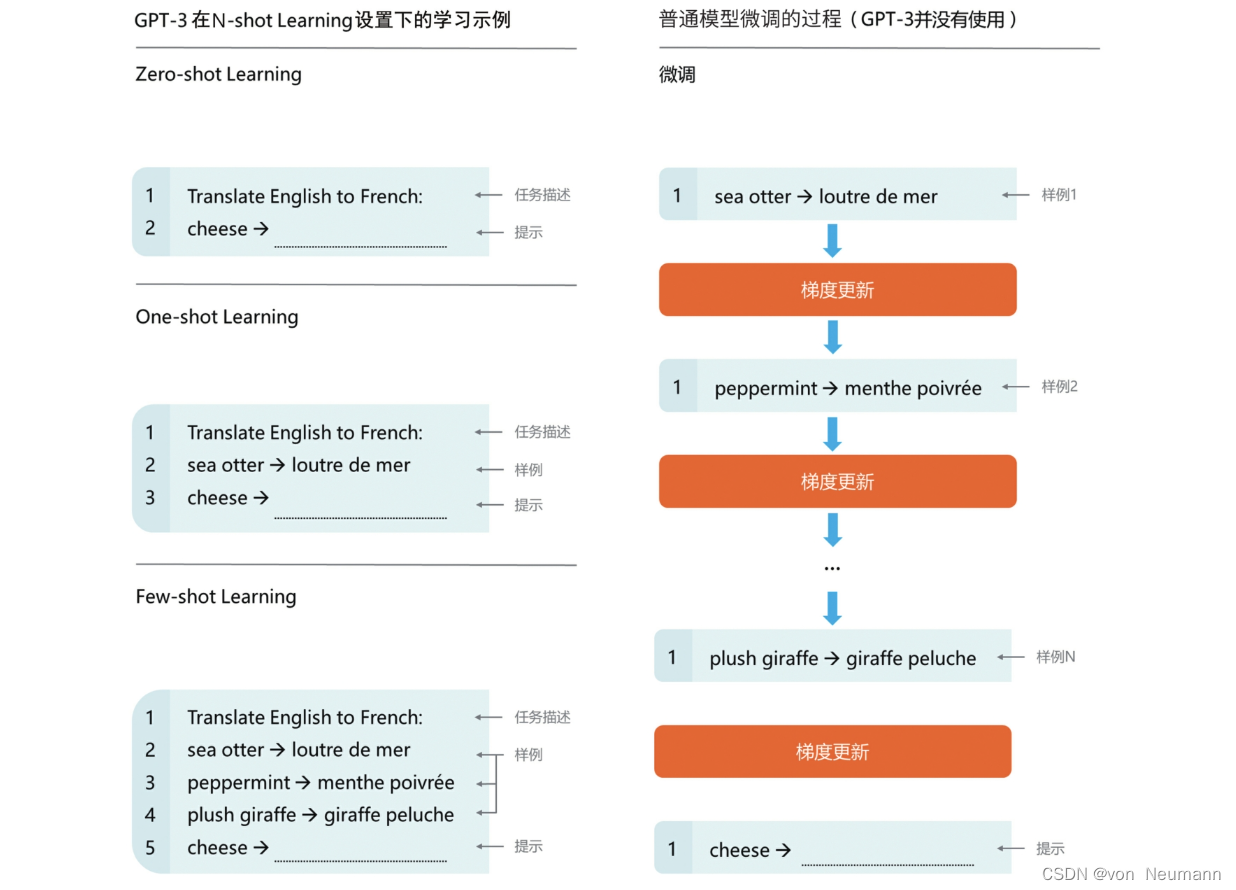
En comparación con el rendimiento sorprendente de GPT-2 en la configuración de aprendizaje Zero-shot presentada en el artículo " Comprensión profunda del aprendizaje profundo - GPT (Transformador preentrenado generativo): GPT-2 y aprendizaje Zero-shot" , GPT- 3 está en El rendimiento en la configuración de aprendizaje de pocos disparos es suficiente para sorprender a todos. En la evaluación del rendimiento de las tareas posteriores de procesamiento del lenguaje natural, el rendimiento de GPT-2 en la configuración de aprendizaje de cero disparos es muy inferior al del modelo SOTA, mientras que el rendimiento de GPT-3 en la configuración de aprendizaje de pocos disparos es el mejor. mismo que el del modelo SOTA en ese momento, incluso más allá del modelo SOTA. La siguiente figura muestra un ejemplo de traducción automática usando GPT-3 con una pequeña cantidad de muestras. El lado derecho de la siguiente figura muestra el proceso de ajuste fino del modelo común. El modelo se entrena con una gran cantidad de corpus de entrenamiento, y el gradiente se actualiza iterativamente usando datos de tareas específicos. Solo después de que el entrenamiento converja, el modelo puede tener buena capacidad de traducción. El lado izquierdo de la siguiente figura es un ejemplo de aprendizaje de GPT-3 en la configuración de aprendizaje N-shot. En la configuración de aprendizaje Zero-shot, solo se requiere una descripción de la tarea y GPT-3 puede traducir; en One-shot Configuración de aprendizaje, además de brindar una descripción de la tarea, se debe proporcionar una muestra de traducción antes de que GPT-3 pueda traducir; en Configuración de aprendizaje de pocas tomas, además de brindar una descripción de la tarea, se deben brindar más datos de capacitación (todavía es es una pequeña cantidad de muestras, mucho menos que los datos de entrenamiento requeridos para el proceso de ajuste, pero GPT-3 puede lograr mejores traducciones). En general, cuantos más datos de muestra se proporcionen, mejor será el rendimiento de GPT-3 en una tarea determinada. No solo eso, si tiene el mismo rendimiento en la misma tarea, GPT-3 requiere muchos menos datos de entrenamiento de ajuste fino que el modelo SOTA.
GPT-3 tiene un rendimiento excelente en muchos conjuntos de datos de procesamiento de lenguaje natural, incluidas las tareas comunes de procesamiento de lenguaje natural, como la respuesta a preguntas y el llenado de texto. La capacidad de generación de texto de GPT-3 es suficiente para alcanzar el reino de los falsos,
Lee las palabras y forma una oración.
Dada una palabra nueva y su significado, haz una oración usando la palabra nueva. Esta es una tarea que los estudiantes de primaria a menudo encuentran cuando aprenden nuevas palabras Al hacer oraciones, podemos juzgar si los estudiantes dominan el verdadero significado de las palabras. El artículo Language Models are Few-shot Learners ofrece el siguiente ejemplo:
Un "Burringo" es un automóvil con una aceleración muy rápida. Un ejemplo de una oración que usa la palabra Burringo es: En nuestro garaje tenemos un Burringo que mi padre conduce al trabajo todos los días. GPT-3 recibió el texto original de entrada: "
Burringo "Es un auto que acelera rápido, usa Burringo en una oración.
El resultado de la formación de oraciones proporcionado por GPT-3: Tengo un Burringo en mi garaje y mi padre lo lleva al trabajo todos los días.
Aunque no logró reflejar las características de la aceleración rápida, GPT-3 captó con precisión la característica más importante de la palabra "Burringo", es decir, representa el significado del automóvil.
Vamos a inventar una nueva palabra con una parte verbal del verbo para ver si GPT-3 puede captar bien el significado de la nueva palabra:
"Screeg" algo es blandir una espada contra eso. Un ejemplo de una oración que usa la palabra screeg es: Nos gritamos el uno al otro durante varios minutos y luego salimos y comimos helado. GPT-3 recibió el texto original de
entrada : "screeg" se refiere a esgrima, use screeg para hacer una oración.
Resultados de creación de oraciones proporcionados por GPT-3: Golpeamos espadas por un tiempo, luego salimos a comer helado.
Para los verbos, GPT-3 también capta muy bien y las oraciones son muy fluidas.
corrección de errores gramaticales
GPT-3 no solo puede generar texto de la nada, sino también oraciones correctas. Dada una oración con un error gramatical, permita que GPT-3 la modifique:
Pobre entrada en inglés: el paciente murió.
Buena salida en inglés: El paciente murió.
El verbo en la oración original se usó incorrectamente, y había un extra. GPT-3 eliminó automáticamente la palabra y la modificó en una oración con gramática correcta y semántica suave. Veamos un ejemplo más difícil:
Pobre entrada en inglés: Hoy he ido a la tienda a comprar muchas botellas de agua.
Buena salida en ingles:Hoy fui a la tienda a comprar unas botellas de agua.
Aquí hay dos tipos de errores en la oración original: el primer tipo son errores de tiempo, GPT-3 eliminó el have en la oración; el segundo tipo son errores de singular y plural, al cambiar compras por comprar y cambiar algunas botellas por algunas botellas para corregir. El efecto de corrección de errores de GPT-3 es equivalente al del sistema de corrección automática de errores basado en reglas expertas, e incluso puede funcionar mejor en el contexto de oraciones complejas y tiempos caóticos.
Además de los ejemplos en el documento original, después de que OpenAI abrió la interfaz GPT-3 limitada, los internautas también intentaron otras tareas interesantes, como permitir que GPT-3 escribiera código, diseñar la interfaz de usuario de la página web y algunos internautas incluso enseñaron a GPT-3 a jugar al ajedrez, generar estados financieros. Y GPT-3 tiene un rendimiento notable en varias tareas, que está mucho más allá de la imaginación de las personas. Con su enorme modelo y altos costos de capacitación, GPT-3 puede describirse como el techo del modelo generativo de lenguaje previo a la capacitación en ese momento. Modelo.
La controversia GPT-3
Si bien GPT-3, que es tan grande y popular, ha ganado muchos elogios, también ha sido cuestionado por muchos académicos en el país y en el extranjero que analizaron racionalmente los defectos de GPT-3. A continuación se recopilan y resumen algunos puntos de vista aceptados, para que los lectores puedan comprender GPT-3 de manera más completa.
- GPT-3 no tiene una capacidad de razonamiento lógico real: en la tarea de preguntas y respuestas, si GPT-3 recibe la pregunta "¿cuántos ojos tiene el sol?", GPT-3 responderá "el sol tiene un ojo", es decir, GPT-3 no juzga si la pregunta es significativa, y si su respuesta se basa en el entrenamiento de un corpus a gran escala, en lugar de una derivación lógica, y no puede dar una respuesta más allá del alcance del corpus de entrenamiento.
- GPT-3 tiene el riesgo de generar mal contenido: al generar texto, debido a que el corpus de entrenamiento proviene de Internet, el corpus que contiene discriminación racial o discriminación sexual no se puede filtrar por completo, lo que resulta en una cierta probabilidad de que el texto generado por GPT-3 expresará discriminación y prejuicio.Incluso se pueden cometer errores en los juicios morales y en el derecho profesional.
- GPT-3 tiene un desempeño deficiente en preguntas altamente procedimentales: GPT-3 tiene un desempeño deficiente en respuesta a preguntas en materias STEM (Ciencia, Tecnología, Ingeniería, Matemáticas), porque es más probable que GPT-3 adquiera y recuerde conocimiento declarativo, en lugar de comprender conocimiento. Julian Togelius, profesor asociado de la Universidad de Nueva York e investigador de IA de juegos, comentó sobre GPT-3: Es como un estudiante inteligente que no revisó con cuidado, tratando de decir tonterías para salir del paso en el examen. Combina hechos conocidos y mentiras para que parezca una narración fluida.
Si bien se ha cuestionado la credibilidad de los resultados de GPT-3, su gran cantidad de parámetros y los altos costos de capacitación también impiden su uso generalizado. Aun así, GPT-3 fue una vez el modelo de lenguaje preentrenado más grande y mejor, y su verdadero significado radica en revelar la esquina del velo de la inteligencia artificial general. Geoffrey Hinton, el padre del aprendizaje profundo, comentó sobre GPT-3 de la siguiente manera: si el futuro se calcula en función del excelente rendimiento de GPT-3, entonces la vida y todo en el mundo son solo 4,398 billones de parámetros. Con el desarrollo del aprendizaje profundo, si hay una estructura de modelo que reemplaza al Transformador, o si la escala de parámetros del modelo se expande 1000 veces, puede haber un modelo de inteligencia artificial general que pueda aprender el razonamiento y el pensamiento lógico.
Referencias:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning [J] Nature, 2015 [
2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning [J] . arXiv preprint arXiv:2106.11342, 2021.
[3] Che Wanxiang, Cui Yiming, Guo Jiang. Procesamiento del lenguaje natural: un método basado en el modelo de preentrenamiento [M]. Electronic Industry Press, 2021. [4] Shao Hao, Liu
Yifeng . Modelo de lenguaje previo al entrenamiento [M]. Electronic Industry Press, 2021.
[5] He Han. Introducción al procesamiento del lenguaje natural [M]. People's Posts and Telecommunications Press, 2019 [
6] Sudharsan Ravichandiran. BERT Basic Tutorial: Transformer Large Práctica modelo[ M]. People's Posts and Telecommunications Press, 2023
[7] Wu Maogui, Wang Hongxing. Simple Embedding: Principle Analysis and Application Practice [M]. Machinery Industry Press, 2021.