1. Concepto
1.1, red neuronal recurrente
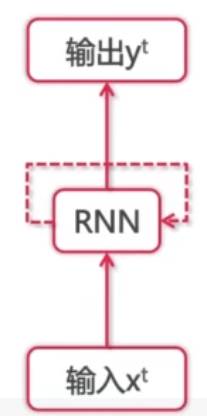
La red neuronal recurrente (RNN) es un tipo de red neuronal recurrente que toma datos de secuencia como entrada, realiza la recursión en la dirección de evolución de la secuencia y todos los nodos (unidades recurrentes) están conectados en una cadena.
La entrada de la red convolucional es solo los datos de entrada X, y además de los datos de entrada X, la salida de cada paso de la red neuronal recurrente se usará como la entrada del siguiente paso. Este ciclo, y la misma función de activación y parámetros se usan siempre. En cada ciclo, x0 se multiplica por el coeficiente U para obtener s0, y luego ingresa a la próxima vez a través del coeficiente W, que forma la propagación directa de la red neuronal recurrente.

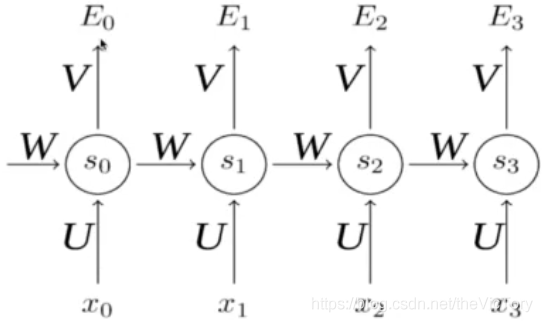
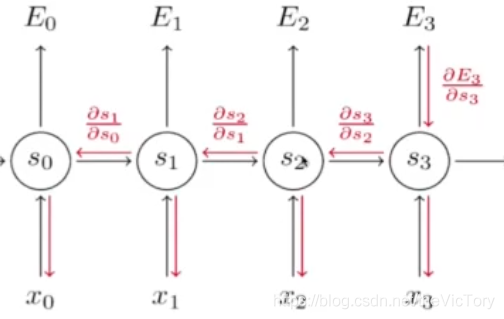
En la propagación hacia atrás, se requiere la derivada de la función de pérdida E para el parámetro W, y la fórmula en la parte inferior derecha se puede obtener mediante la regla de derivada de cadena
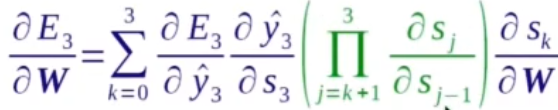
La red neuronal recurrente se compara con la red neuronal convolucional La red neuronal convolucional es una salida que produce una salida a través de la red. La red neuronal recurrente puede lograr una entrada múltiples salidas (generar descripción de imagen), múltiples entradas una salida (clasificación de texto), múltiples entradas múltiples salidas (traducción automática, comentario de video).
RNN usa la función de activación de bronceado, la salida está entre -1 y 1, y el gradiente es fácil de desaparecer. Los pasos más alejados de la salida contribuyen poco al gradiente.
La salida de la capa inferior se usa como la entrada de la capa superior para formar una red RNN multicapa, y la capa superior también se puede pasar y la conexión residual se puede usar para evitar el sobreajuste.
1.2 red de memoria a corto y largo plazo
Solo hay un parámetro W entre cada propagación de RNN. Es difícil describir una gran cantidad de requisitos de información complejos con este parámetro. Para resolver este problema , se introduce la memoria a corto plazo (LSTM) . Esta red puede llevar a cabo mecanismos selectivos, selectivamente la información de entrada y salida que necesita ser utilizada, y selectivamente olvida la información que no es necesaria. La realización del mecanismo selectivo se realiza a través de la puerta sigmoidea, la salida de la función sigmoidea se encuentra entre 0 y 1, 0 representa olvido, 1 representa memoria, 0.5 representa memoria 50%
La estructura de la red LSTM se muestra a continuación,
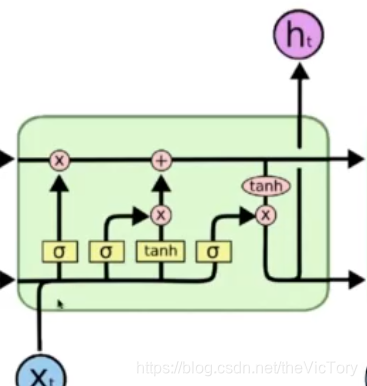
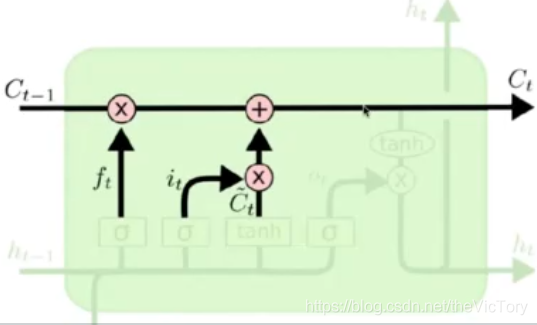
Como se muestra en la figura anterior, este es el estado implícito de la ronda actual de operaciones . El estado actual se obtiene por el producto de punto del estado anterior y el resultado de la puerta olvidada, más el resultado de los entrantes.
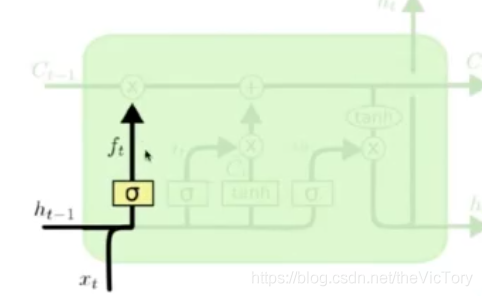
La siguiente figura muestra la estructura de la puerta de olvido: la salida ht-1 y los datos xt de la ronda anterior pasan a través de la puerta de olvido para seleccionar si se olvida, y el resultado de olvido se genera ft
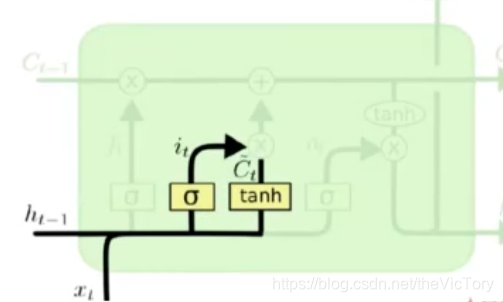
La siguiente figura muestra la estructura de la compuerta entrante : el resultado de ht-1 y xt después de la compuerta olvidada lo es y el resultado Ct de tanh se somete a una operación de producto de puntos para obtener la entrada de esta operación.
La siguiente figura muestra la estructura de la puerta de salida : el resultado de que ht-1 y xt pasan a través de la puerta de olvido es ot y el estado actual es producto de punto para producir esta salida.
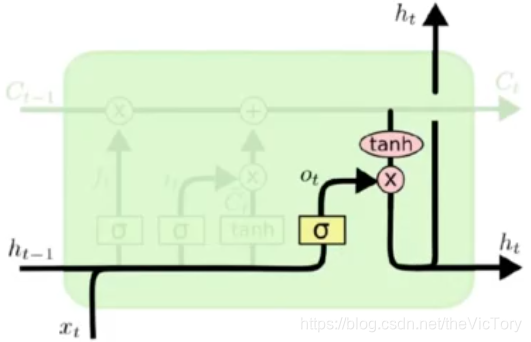
Para implementar la red LSTM de la siguiente manera, primero defina la función _generate_params para generar los parámetros requeridos para cada puerta, y llame a esta función para definir los parámetros de la puerta de entrada, puerta de salida, puerta de olvido y estado intermedio tanh. Los parámetros de cada puerta son tres, ingrese el peso y el valor de compensación de xy h.
Luego, comience cada ronda del cálculo del bucle LSTM. El cálculo de la compuerta de entrada consiste en multiplicar la matriz de entrada incrustado de entrada por el parámetro de compuerta de entrada x_in, más el resultado de multiplicar h y el parámetro correspondiente, y finalmente agregar el valor de compensación b_in para obtener la entrada a través de sigmoide Resultado de la puerta.
De manera similar, las operaciones de multiplicación de matriz y desplazamiento se realizan para obtener los resultados de la puerta olvidada y la puerta de salida. El estado intermedio tanh es similar al funcionamiento de las tres puertas, excepto que finalmente pasa la función tanh.
Multiplique el último estado oculto por la puerta olvidada más la puerta de entrada por el estado intermedio para obtener el estado oculto actual
Pase el estado actual a través de la función tanh y agregue la puerta de salida para obtener la salida actual h
Lo que se obtiene después de múltiples rondas de ciclos de entrada es la salida final de la red LSTM.
# 实现LSTM网络
# 生成Cell网格所需参数
def _generate_paramas(x_size, h_size, b_size):
x_w = tf.get_variable('x_weight', x_size)
h_w = tf.get_variable('h_weight', h_size)
bias = tf.get_variable('bias', b_size, initializer=tf.constant_initializer(0.0))
return x_w, h_w, bias
scale = 1.0 / math.sqrt(embedding_size + lstm_nodes[-1]) / 3.0
lstm_init = tf.random_uniform_initializer(-scale, scale)
with tf.variable_scope('lstm_nn', initializer=lstm_init):
# 输入门参数
with tf.variable_scope('input'):
x_in, h_in, b_in = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 输出门参数
with tf.variable_scope('output'):
x_out, h_out, b_out = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 遗忘门参数
with tf.variable_scope('forget'):
x_f, h_f, b_f = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 中间状态参数
with tf.variable_scope('mid_state'):
x_m, h_m, b_m = _generate_paramas(
x_size=[embedding_size, lstm_nodes[0]],
h_size=[lstm_nodes[0], lstm_nodes[0]],
b_size=[1, lstm_nodes[0]]
)
# 两个初始化状态,隐含状态state和初始输入h
state = tf.Variable(tf.zeros([batch_size, lstm_nodes[0]]), trainable=False)
h = tf.Variable(tf.zeros([batch_size, lstm_nodes[0]]), trainable=False)
# 遍历LSTM每轮循环,即每个词的输入过程
for i in range(max_words):
# 取出每轮输入,三维数组embedd_inputs的第二维代表训练的轮数
embedded_input = embedded_inputs[:, i, :]
# 将取出的结果reshape为二维
embedded_input = tf.reshape(embedded_input, [batch_size, embedding_size])
# 遗忘门计算
forget_gate = tf.sigmoid(tf.matmul(embedded_input, x_f) + tf.matmul(h, h_f) + b_f)
# 输入门计算
input_gate = tf.sigmoid(tf.matmul(embedded_input, x_in) + tf.matmul(h, h_in) + b_in)
# 输出门
output_gate = tf.sigmoid(tf.matmul(embedded_input, x_out) + tf.matmul(h, h_out) + b_out)
# 中间状态
mid_state = tf.tanh(tf.matmul(embedded_input, x_m) + tf.matmul(h, h_m) + b_m)
# 计算隐含状态state和输入h
state = state * forget_gate + input_gate * mid_state
h = output_gate + tf.tanh(state)
# 最后遍历的结果就是LSTM的输出
last_output = h1.3, clasificación de texto
El problema de clasificación de texto es analizar y juzgar la cadena de texto de entrada y luego generar el resultado. La cadena no se puede ingresar directamente a la red RNN, por lo que debe dividir el texto en una sola frase antes de ingresarla, codificarla en un vector e ingresar una frase en cada ronda. Cuando se ingresa la última frase, el resultado de salida también es un Vector la incrustación corresponde a una palabra en un vector, y cada dimensión del vector corresponde a un valor de coma flotante. Estos valores de coma flotante se ajustan dinámicamente para que el código de incrustación esté relacionado con el significado de la palabra. De esta manera, la entrada y la salida de la red son todos vectores, y luego la operación final de conexión completa puede corresponder a diferentes clasificaciones.
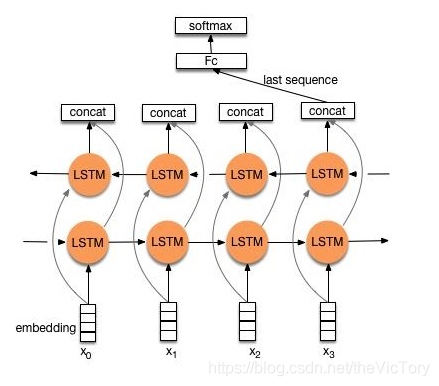
El problema que inevitablemente trae la red RNN es que el resultado final se ve afectado por la entrada más reciente, y la entrada que está más lejos puede no afectar el resultado. Este es el problema del cuello de botella de información . Para resolver este problema, se introduce un LSTM bidireccional. El LSTM bidireccional no solo aumenta la propagación de información inversa, sino que cada ronda tendrá una salida, que se combinará y luego se transmitirá a la capa completamente conectada.
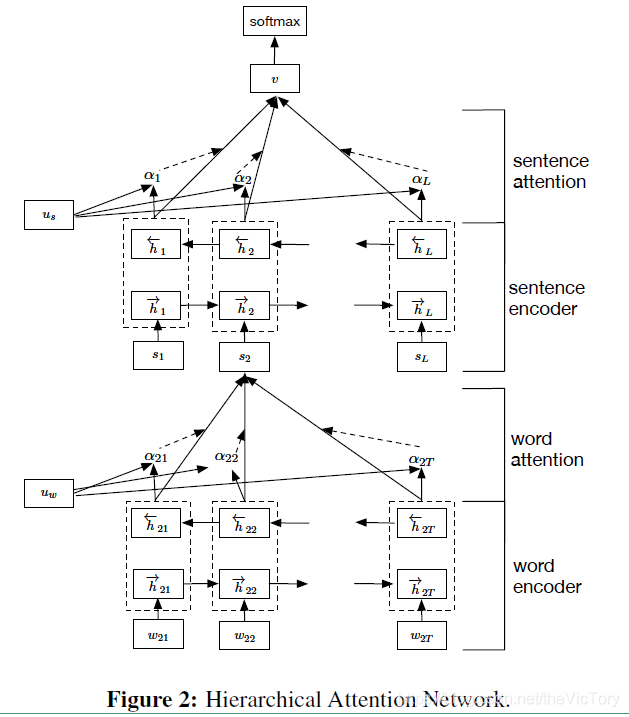
Otro modelo de clasificación de texto es HAN (Hierarchy Attention Network). Primero, el texto se divide en oraciones y niveles de palabras, las palabras de entrada se codifican y luego se agregan para obtener el código de la oración, y luego los códigos de las oraciones se agregan para obtener el código de texto final. Atención se refiere a agregar un valor ponderado antes de que se acumule cada nivel de código, y acumular el código de acuerdo con diferentes pesos.
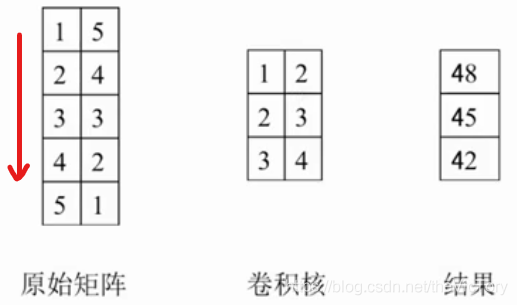
Debido a que la longitud del texto de entrada no es uniforme, la red neuronal no se puede usar para aprender directamente. Para resolver este problema, la longitud del texto de entrada se puede unificar a un valor máximo, y la red neuronal convolucional apenas se usa para aprender, es decir, TextCNN . El proceso de convolución de la red de convolución de texto utiliza convolución unidimensional multicanal, en comparación con la convolución bidimensional, la convolución unidimensional significa que el núcleo de convolución solo se mueve en una dirección. Por ejemplo, como se muestra en la figura de la izquierda, 1 × 1 + 5 × 2 + 2 × 2 + 4 × 3 + 3 × 3 + 3 × 4 = 48, y luego el núcleo de convolución se mueve hacia abajo una cuadrícula para obtener 45, y así sucesivamente. Como se muestra en la figura de la derecha a continuación, ingrese varias palabras de diferentes longitudes. Primero, llénelos a una matriz de incrustación de seis canales, y luego use un núcleo de convolución unidimensional de seis canales para convolucionar de arriba a abajo para obtener una matriz unidimensional, y luego la salida después de pasar a través de la capa de agrupación y la capa totalmente conectada.
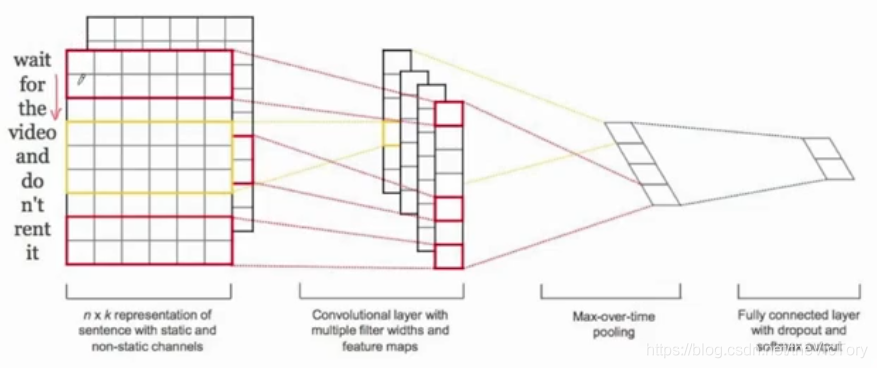
Se puede ver que la red CNN no puede manejar perfectamente el problema en serie de diferentes longitudes de entrada, pero puede procesar múltiples frases en paralelo, lo que es más eficiente, y el RNN puede manejar mejor la entrada en serie, combinando las ventajas de los dos. Constituye el modelo R-CNN . Primero, la extracción de características se realiza en la entrada a través de una red RNN bidireccional, y luego se utiliza CNN para extraer más, luego las características de cada paso se fusionan a través de la capa de agrupación y finalmente se clasifican a través de la capa completamente conectada.
No importa qué modelo necesite usar incrustación para convertir la entrada en un vector, cuando la entrada es demasiado grande, los parámetros de la capa de incrustación convertidos serán demasiado grandes, lo que no solo no es propicio para el almacenamiento, sino que también causa un ajuste excesivo, por lo que la capa de incrustación debe comprimirse. El código de incrustación original es un parámetro que corresponde a una entrada, por ejemplo, wait corresponde al parámetro x1, for corresponde a x2 y corresponde a x3. Si hay demasiadas entradas, los parámetros de codificación serán muy grandes. Puede usar dos pares de parámetros para codificar la entrada. Por ejemplo, esperar corresponde a (x1, x2), porque corresponde a (x1, x3) ..., para que pueda maximizar El número de parámetros de guardado es la compresión compartida .
2. Clasificación del texto a través del texto RNN
2.1, preprocesamiento de datos
Los archivos de conjunto de datos de clasificación de texto descargados en Internet son los siguientes, divididos en conjunto de prueba y datos de conjunto de entrenamiento, cada conjunto de entrenamiento tiene cuatro carpetas, cada carpeta es una clasificación, cada clasificación tiene 1000 archivos txt, cada uno Hay un texto de la clasificación en el archivo


Repite todos los archivos de entrenamiento a través de os.walk y divide el texto categorizado en frases individuales a través de la biblioteca jieba, separadas por espacios. Luego agregue el texto de clasificación al principio, separado por pestañas, y finalmente envíe el resultado a train_segment.txt,
# 将文件中的句子通过jieba库拆分为单个词
def segment_word(input_file, output_file):
# 循环遍历训练数据集的每一个文件
for root, folders, files in os.walk(input_file):
print('root:', root)
for folder in folders:
print('dir:', folder)
for file in files:
file_dir = os.path.join(root, file)
with open(file_dir, 'rb') as in_file:
# 读取文件中的文本
sentence = in_file.read()
# 通过jieba函数库将句子拆分为单个词组
words = jieba.cut(sentence)
# 文件夹路径最后两个字即为分类名
content = root[-2:] + '\t'
# 去除词组中的空格,排除为空的词组
for word in words:
word = word.strip(' ')
if word != '':
content += word + ' '
# 换行并将文本写入输出文件
content += '\n'
with open(output_file, 'a') as outfile:
outfile.write(content.strip(' '))Los resultados son los siguientes:

Dado que algunas frases tienen pocas ocurrencias y no son estadísticamente significativas, deben excluirse, y la frecuencia de aparición de cada frase se cuenta mediante el método get_list (). El uso del tipo de datos del diccionario que viene con Python puede lograr fácilmente estadísticas de datos de frases, el formato es {"palabra clave": frecuencia}, la frecuencia registra el número de apariciones de palabras clave. Si aparece una frase nueva, se agregará al diccionario como una nueva entrada; de lo contrario, el valor de la frecuencia será +1.
# 统计每个词出现的频率
def get_list(segment_file, out_file):
# 通过词典保存每个词组出现的频率
word_dict = {}
with open(segment_file, 'r') as seg_file:
lines = seg_file.readlines()
# 遍历文件的每一行
for line in lines:
line = line.strip('\r\n')
# 将一行按空格拆分为每个词,统计词典
for word in line.split(' '):
# 如果这个词组没有在word_dict词典中出现过,则新建词典项并设为0
word_dict.setdefault(word, 0)
# 将词典word_dict中词组word对应的项计数加一
word_dict[word] += 1
# 将词典中的列表排序,关键字为列表下标为1的项,且逆序
sorted_list = sorted(word_dict.items(), key=lambda d: d[1], reverse=True)
with open(out_file, 'w') as outfile:
# 将排序后的每条词典项写入文件
for item in sorted_list:
outfile.write('%s\t%d\n' % (item[0], item[1]))Los resultados estadísticos son los siguientes:

2.2, lectura de datos
No es posible utilizar la frase directamente para el aprendizaje de codificación. Debe convertir la frase en codificación incrustada. De acuerdo con la lista train_list recién generada, numere cada frase en el orden de adelante hacia atrás. Si la frecuencia de la frase es inferior al umbral, se excluye. Use la clase Word_list para construir los objetos de frase de los datos de entrenamiento y datos de prueba, e implemente la codificación de frase en el constructor de clase __init __ (). Y defina el método de clase oración2id para convertir la frase de oración dividida en la matriz de identificación correspondiente, si la palabra no está en la lista de frases, establezca el valor en -1.
Antes de definir la clase, primero especifique algunos hiperparámetros para su uso posterior:
# 定义超参数
embedding_size = 32 # 每个词组向量的长度
max_words = 10 # 一个句子最大词组长度
lstm_layers = 2 # lstm网络层数
lstm_nodes = [64, 64] # lstm每层结点数
fc_nodes = 64 # 全连接层结点数
batch_size = 100 # 每个批次样本数据
lstm_grads = 1.0 # lstm网络梯度
learning_rate = 0.001 # 学习率
word_threshold = 10 # 词表频率门限,低于该值的词语不统计
num_classes = 4 # 最后的分类结果有4类class Word_list:
def __init__(self, filename):
# 用词典类型来保存需要统计的词组及其频率
self._word_dic = {}
with open(filename, 'r',encoding='GB2312',errors='ignore') as f:
lines = f.readlines()
for line in lines:
word, freq = line.strip('\r\n').split('\t')
freq = int(freq)
# 如果词组的频率小于阈值,跳过不统计
if freq < word_threshold:
continue
# 词组列表中每个词组都是不重复的,按序添加到word_dic中即可,下一个词组id就是当前word_dic的长度
word_id = len(self._word_dic)
self._word_dic[word] = word_id
def sentence2id(self, sentence):
# 将以空格分割的句子返回word_dic中对应词组的id,若不存在返回-1
sentence_id = [self._word_dic.get(word, -1)
for word in sentence.split()]
return sentence_id
train_list = Word_list(train_list_dir)Defina la clase TextData para completar la lectura y la gestión de los datos, lea el archivo train_segment.txt recién procesado en la función __init __ (), divida las etiquetas de categoría y las frases de oración de acuerdo con los caracteres de tabulación, y convierta la categoría y la oración en identificación numérica . Si la frase de la oración excede el umbral máximo, entonces el exceso se trunca, si no es suficiente, se llena con -1. Defina la función de clase _shuffle_data () para limpiar datos, next_batch () para devolver datos y etiquetas por lote, y get_size () para devolver el número total de frases.
class TextData:
def __init__(self, segment_file, word_list):
self.inputs = []
self.labels = []
# 通过词典管理文本类别
self.label_dic = {'体育': 0, '校园': 1, '女性': 2, '出版': 3}
self.index = 0
with open(segment_file, 'r') as f:
lines = f.readlines()
for line in lines:
# 文本按制表符分割,前面为类别,后面为句子
label, content = line.strip('\r\n').split('\t')[0:2]
self.content_size = len(content)
# 将类别转换为数字id
label_id = self.label_dic.get(label)
# 将句子转化为embedding数组
content_id = word_list.sentence2id(content)
# 如果句子的词组长超过最大值,截取max_words长度以内的id值
content_id = content_id[0:max_words]
# 如果不够则填充-1,直到max_words长度
padding_num = max_words - len(content_id)
content_id = content_id + [-1 for i in range(padding_num)]
self.inputs.append(content_id)
self.labels.append(label_id)
self.inputs = np.asarray(self.inputs, dtype=np.int32)
self.labels = np.asarray(self.labels, dtype=np.int32)
self._shuffle_data()
# 对数据按照(input,label)对来打乱顺序
def _shuffle_data(self):
r_index = np.random.permutation(len(self.inputs))
self.inputs = self.inputs[r_index]
self.labels = self.labels[r_index]
# 返回一个批次的数据
def next_batch(self, batch_size):
# 当前索引+批次大小得到批次的结尾索引
end_index = self.index + batch_size
# 如果结尾索引大于样本总数,则打乱所有样本从头开始
if end_index > len(self.inputs):
self._shuffle_data()
self.index = 0
end_index = batch_size
# 按索引返回一个批次的数据
batch_inputs = self.inputs[self.index:end_index]
batch_labels = self.labels[self.index:end_index]
self.index = end_index
return batch_inputs, batch_labels
# 获取词表数目
def get_size(self):
return self.content_size
# 训练数据集对象
train_set = TextData(train_segment_dir, train_list)
# print(data_set.next_batch(10))
# 训练数据集词组条数
train_list_size = train_set.get_size()2.3, construya un modelo de gráfico de cálculo
Defina la función create_model para realizar la construcción del modelo de gráfico de cálculo. Primero defina los marcadores de posición de la entrada del modelo, que son la relación entre la entrada de texto de entrada, la salida de la etiqueta de salida y el dropout keep_prob.
Primero construya la capa de incrustación, extraiga los códigos de entrada y empalme en una matriz, por ejemplo, ingrese [1,8,3], luego extraiga incrustación [1], incrustación [8] e incrustación [3] para empalmar en una matriz
A continuación, se construye la red LSTM. Aquí, se construye una red de dos capas, y el número de nodos en cada capa se define en la matriz del parámetro anterior lstm_node []. La construcción de cada celda se realiza mediante la función tf.contrib.rnn.BasicLSTMCell, y luego se somete a una operación Dropout. Luego combine las dos celdas en una red LSTM e ingrese las entradas embebidas en la red LSTM a través de la función tf.nn.dynamic_rnn para obtener la salida rnn_output. Esta es una matriz tridimensional, la segunda dimensión representa el número de pasos de entrenamiento, solo tomamos el resultado de la última dimensión, es decir, el valor del subíndice es -1.
A continuación, cree una capa totalmente conectada, defina la capa completamente conectada a través de la función tf.layers.dense y luego asigne la salida a la categoría después de una operación de abandono. El parámetro num_classes del tipo de categoría obtiene el valor estimado logits
Luego puede encontrar los valores de evaluación como pérdida y precisión. Calcule el valor de pérdida de entropía cruzada entre los logits de valor pronosticado y las salidas de valor de etiqueta, luego calcule el valor pronosticado a través de arg_max y luego encuentre la tasa de precisión
A continuación, defina el método de entrenamiento y aplique recorte de gradiente a las variables para evitar que el gradiente desaparezca.
Finalmente, los valores de evaluación de entrada, como marcadores de posición y pérdidas, y otros parámetros de entrenamiento se devuelven al exterior de la función de llamada.
# 创建计算图模型
def create_model(list_size, num_classes):
# 定义输入输出占位符
inputs = tf.placeholder(tf.int32, (batch_size, max_words))
outputs = tf.placeholder(tf.int32, (batch_size,))
# 定义是否dropout的比率
keep_prob = tf.placeholder(tf.float32, name='keep_rate')
# 记录训练的总次数
global_steps = tf.Variable(tf.zeros([], tf.float32), name='global_steps', trainable=False)
# 将输入转化为embedding编码
with tf.variable_scope('embedding',
initializer=tf.random_normal_initializer(-1.0, 1.0)):
embeddings = tf.get_variable('embedding', [list_size, embedding_size], tf.float32)
# 将指定行的embedding数值抽取出来
embedded_inputs = tf.nn.embedding_lookup(embeddings, inputs)
# 实现LSTM网络
scale = 1.0 / math.sqrt(embedding_size + lstm_nodes[-1]) / 3.0
lstm_init = tf.random_uniform_initializer(-scale, scale)
with tf.variable_scope('lstm_nn', initializer=lstm_init):
# 构建两层的lstm,每层结点数为lstm_nodes[i]
cells = []
for i in range(lstm_layers):
cell = tf.contrib.rnn.BasicLSTMCell(lstm_nodes[i], state_is_tuple=True)
# 实现Dropout操作
cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=keep_prob)
cells.append(cell)
# 合并两个lstm的cell
cell = tf.contrib.rnn.MultiRNNCell(cells)
# 将embedded_inputs输入到RNN中进行训练
initial_state = cell.zero_state(batch_size, tf.float32)
# runn_output:[batch_size,num_timestep,lstm_outputs[-1]
rnn_output, _ = tf.nn.dynamic_rnn(cell, embedded_inputs, initial_state=initial_state)
last_output = rnn_output[:, -1, :]
# 构建全连接层
fc_init = tf.uniform_unit_scaling_initializer(factor=1.0)
with tf.variable_scope('fc', initializer=fc_init):
fc1 = tf.layers.dense(last_output, fc_nodes, activation=tf.nn.relu, name='fc1')
fc1_drop = tf.contrib.layers.dropout(fc1, keep_prob)
logits = tf.layers.dense(fc1_drop, num_classes, name='fc2')
# 定义评估指标
with tf.variable_scope('matrics'):
# 计算损失值
softmax_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=outputs)
loss = tf.reduce_mean(softmax_loss)
# 计算预测值,求第1维中最大值的下标,例如[1,1,5,3,2] argmax=> 2
y_pred = tf.argmax(tf.nn.softmax(logits), 1, output_type=tf.int32)
# 求准确率
correct_prediction = tf.equal(outputs, y_pred)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 定义训练方法
with tf.variable_scope('train_op'):
train_var = tf.trainable_variables()
# for var in train_var:
# print(var)
# 对梯度进行裁剪防止梯度消失或者梯度爆炸
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, train_var), clip_norm=lstm_grads)
# 将梯度应用到变量上去
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.apply_gradients(zip(grads, train_var), global_steps)
# 以元组的方式将结果返回
return ((inputs, outputs, keep_prob),
(loss, accuracy),
(train_op, global_steps))
# 调用构建函数,接收解析返回的参数
placeholders, matrics, others = create_model(train_list_size, num_classes)
inputs, outputs, keep_prob = placeholders
loss, accuracy = matrics
train_op, global_steps = others2.4 Entrenamiento
Ejecute el modelo de gráfico de cálculo a través de la sesión, obtenga los datos del conjunto de entrenamiento de train_set en lotes y complete los marcadores de posición, ejecute sess.run, obtenga los valores intermedios como el valor de pérdida, la tasa de precisión e imprima
# 进行训练
init_op = tf.global_variables_initializer()
train_keep_prob = 0.8 # 训练集的dropout比率
train_steps = 10000
with tf.Session() as sess:
sess.run(init_op)
for i in range(train_steps):
# 按批次获取训练集数据
batch_inputs, batch_labels = train_set.next_batch(batch_size)
# 运行计算图
res = sess.run([loss, accuracy, train_op, global_steps],
feed_dict={inputs: batch_inputs, outputs: batch_labels,
keep_prob: train_keep_prob})
loss_val, acc_val, _, g_step_val = res
if g_step_val % 20 == 0:
print('第%d轮训练,损失:%3.3f,准确率:%3.5f' % (g_step_val, loss_val, acc_val))
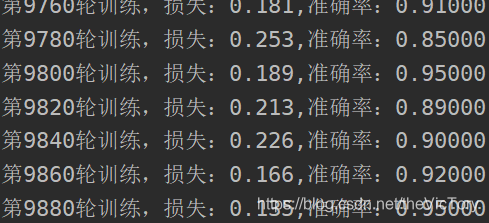
Después de 10,000 rondas de entrenamiento en mi conjunto de datos, la precisión del conjunto de entrenamiento rondaba el 90%
Código fuente y archivos de datos relacionados: https://github.com/SuperTory/MachineLearning/tree/master/TextRNN
