Introducción del profesor a este número:
Byte, científico jefe de Guanyuan Data. Liderar la aplicación de múltiples proyectos de IA en las 500 empresas más importantes del mundo y ganar el campeonato Hackathon en la dirección de la venta minorista inteligente en muchas ocasiones. Trabajó una vez en MicroStrategy y Alibaba Cloud, y tiene más de diez años de experiencia en la industria.
En la aplicación del aprendizaje automático en el campo comercial, permitir que el lado comercial comprenda la lógica del modelo y mejore la confianza en los resultados de la predicción juega un papel clave en la promoción del avance y la implementación de proyectos de algoritmos. Por lo tanto, la interpretabilidad de los modelos y los resultados de la predicción se ha convertido en un tema cada vez más importante. En este intercambio, presentaremos los principios técnicos del aprendizaje automático explicable, así como algunos casos de aplicación en el desarrollo de modelos y la implementación de proyectos.
Tabla de contenido
- ¿Qué es el aprendizaje automático explicable?
- Realización técnica
- Aplicaciones

¿Por qué el aprendizaje automático explicable?
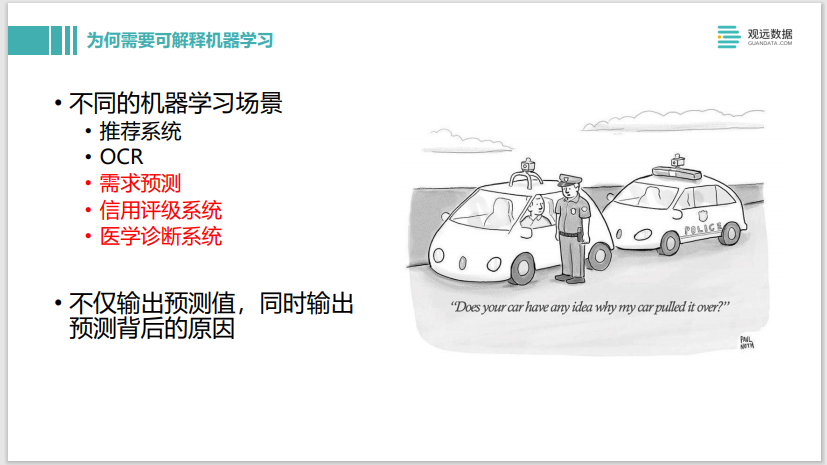
Primero, presentemos por qué se necesita un aprendizaje automático explicable. Normalmente me encuentro con diferentes escenarios en los proyectos de aprendizaje automático, como el sistema de recomendación de Taobao, que recomienda algunos productos que pueden interesarle. Si la recomendación es inexacta, no causará grandes pérdidas ni malos resultados. Influencia. En este escenario, solo debe prestar atención a la precisión del modelo y hacerlo lo más alto posible.
Otro escenario, como el reconocimiento óptico de caracteres OCR, es un escenario relativamente maduro y básicamente puede lograr una precisión del 100 %. Y al igual que otros productos de pronóstico de la demanda, como el sistema de calificación crediticia financiera y el sistema de diagnóstico médico, ofrece pronósticos, por ejemplo, el pronóstico de la demanda puede comprar 10 cajas de Coca-Cola en el futuro. En este caso, necesitamos tener requisitos para el resultado del aprendizaje automático. También hay calificaciones crediticias. Si solicito una tarjeta de crédito y me rechazan, querré saber por qué fue rechazada, si es discriminación contra mi edad o género, etc. Por ejemplo, para el tema de la IA responsable, también habrá requisitos relacionados con este aspecto, por lo que necesitamos un aprendizaje automático explicable, de modo que mientras el modelo genera predicciones, también genera los motivos de los cambios de predicción.
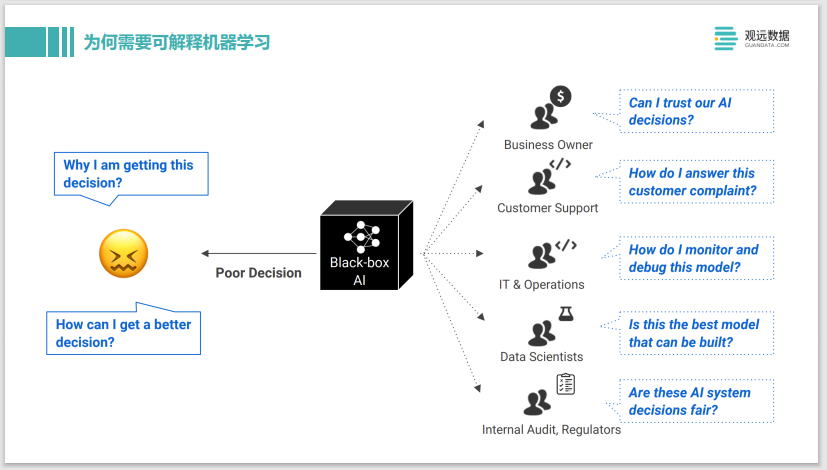
La figura anterior muestra que cuando se enfrentan a un modelo de IA de caja negra, las personas con diferentes funciones, como gerentes comerciales, servicio al cliente, TI o ingenieros de desarrollo de modelos, tienen diferentes demandas sobre el resultado del aprendizaje automático. Por ejemplo, como ingeniero de algoritmos, si la predicción obtenida del modelo de aprendizaje automático de caja negra no es buena y se desvía mucho del valor real, entonces puede preguntarse por qué el modelo dio tal predicción y cómo mejorar el modelo. bien.
Para resumir, primero, el resultado del modelo tiene un impacto significativo.Si se da una predicción incorrecta, el costo será relativamente alto y se requerirá un aprendizaje automático interpretable. En segundo lugar, especialmente para los ingenieros de algoritmos, es conveniente depurar en el modelo de desarrollo. Por supuesto, también hay algunos otros escenarios de aplicación, como el sesgo del modelo de evitación. También hay muchas discusiones en esta área en la comunidad, si el modelo tiene algo de sexismo o discriminación racial, el modelo no puede lanzarse. Además, durante la interacción del modelo, si encuentra desafíos desde el lado comercial, se pueden dar algunas explicaciones, que también pueden mejorar la aceptación de los usuarios comerciales. También existen varios requisitos de auditoría y requisitos normativos, como los sistemas de calificación crediticia.Si el sistema se implementa en línea, debe cumplir con los requisitos de transparencia o explicabilidad.
Varios enfoques para el aprendizaje automático explicable

Vayamos al grano y expliquemos los diversos enfoques del aprendizaje automático. La imagen de la derecha se divide en dos dimensiones, una es la precisión de la predicción del modelo y la otra es la interpretabilidad.
Cuando se utilizan algunos modelos simples, como el modelo lineal en la esquina inferior derecha, el árbol de decisión del árbol de decisión o algunos modelos gráficos probabilísticos, su precisión puede ser peor porque el modelo en sí tiene una estructura relativamente simple, pero su interpretación será muy buena. . En la esquina superior izquierda, como las redes neuronales o algunos métodos de aprendizaje integrado, la complejidad del modelo será muy alta y la precisión aumentará en consecuencia, pero su interpretabilidad será deficiente.
En términos de clasificación de métodos, los modelos lineales son modelos inherentemente interpretables. La red neuronal es un método de post-interpretación. Abre la caja negra para ver cómo hace predicciones. También hay algunos métodos específicos del modelo, como las redes neuronales que pueden explicarse por el gradiente de los modelos posteriores. También hay algunos métodos de interpretación de modelos de caja negra, como SHAP, que no tienen ningún requisito para el modelo y pueden hacer alguna interpretación.
Interpretación local e interpretación global La interpretación global es similar a un modelo lineal, y su peso es cómo el desempeño global del modelo toma decisiones. Las explicaciones locales equivalen a dar algunas explicaciones específicas para una sola muestra.
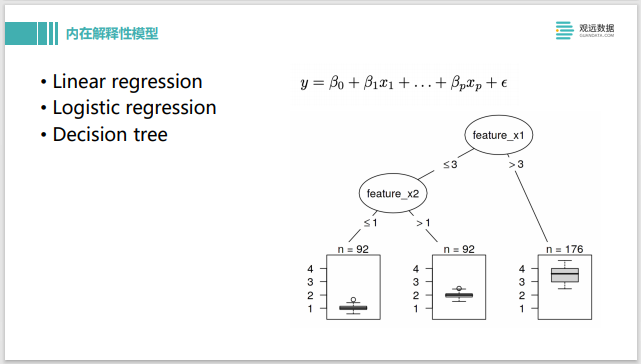
A continuación, se introducen algunos modelos inherentemente explicativos, como la regresión lineal, la regresión logística lineal, el árbol de decisión, etc. Después de entrenar estos modelos, se puede obtener una explicación a través de los coeficientes y la estructura del modelo. El coeficiente es relativamente grande, lo que indica que esta característica tiene un impacto relativamente grande en la producción total. Cuanto menor sea el coeficiente, menor será el impacto. Esta es una propiedad explicativa inherente.

También hay algunas ideas similares, como RuleFit o Skope-rules, que pueden extraer algunas reglas de los datos y crearlas automáticamente, como se muestra en la figura de la derecha. Su interpretabilidad es muy fuerte al predecir. Al igual que Naive Bayes, kNN, puede explicarse mediante otras muestras.

Hay algunos otros modelos de explicación internos, y el método general es agregar algunos métodos a algunos modelos simples. Al igual que EBM o GAMxNN, pertenecen al modelo aditivo generalizado, que equivale a construir varios modelos lineales a partir del modelo en línea, cada modelo lineal describe una parte del sistema y luego los suma. El Profeta de Facebook también es un modelo aditivo típico, que dará algunas explicaciones sobre la estacionalidad o la tendencia. Recientemente, Google TFT de código abierto, que es un modelo de serie temporal. Tiene un tratamiento especial para el mecanismo de atención. Después del entrenamiento, el mecanismo de atención también se puede usar como salida para la interpretación del modelo.

Y al igual que las redes neuronales, la mayoría de ellas se explican después de que se completa el modelo de entrenamiento. Usamos la red neuronal para calcular su gradiente y luego hacemos una retropropagación para hacer alguna interpretación. La imagen de arriba muestra cómo entendemos lo que el modelo CNN ha aprendido en los primeros años de investigación. Podemos cambiar su entrada para maximizar la activación de cada filtro CNN. De esta manera, puede ver que las primeras capas de CNN pueden aprender el borde, la del medio puede aprender algunas formas y las superiores pueden aprender algunos conceptos. En realidad, esto es usar la red neuronal para encontrar el gradiente y luego hacer el principio de retropropagación para hacer algunas explicaciones.

Este ejemplo también es similar, proviene del libro "Deep Learning with Python", que presenta el método de implementación de Grad-CAM. Al igual que esta imagen, ¿por qué se predice que esta imagen es un elefante? Encontraremos la activación de la clase elefante, y luego enviaremos su gradiente de regreso en reversa, y luego miraremos los píxeles en toda la capa de CNN que tienen la mayor influencia en su activación, y luego usaremos el formulario de mapa de calor para dibujarlo. Se puede ver que debido a las cabezas de dos elefantes, esta imagen se clasifica como un elefante con la mayor contribución, formando una explicación.

Además del modelo de red neuronal, también hay una gran cantidad de modelos de árbol, Gradient Boosting, etc., que se pueden explicar en algunos métodos independientes del modelo Post-hoc. El proceso general es que cuando tiene un modelo de caja negra, puede usar algunos métodos de explicación para finalmente enviar algunas instrucciones al usuario. Centrémonos en PDP, LIME y Shapley.
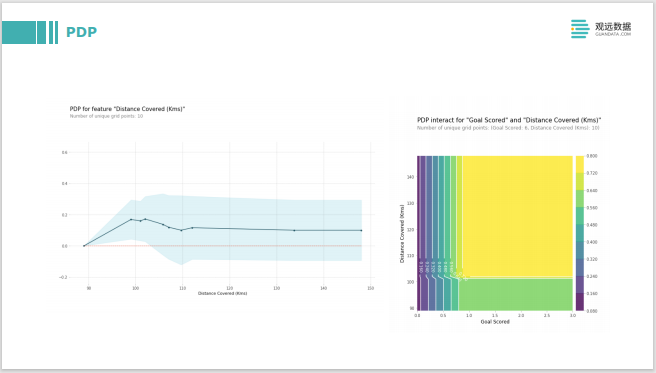
La idea de PDP es modificar los valores propios. Después de entrenar un valor propio en el modelo, hay un modelo negro. Al ingresarlo nuevamente, realice algunos cambios en su valor propio, como cambiarlo de 0 a 100, para ver cómo se ve la salida del modelo. Es muy similar al análisis de qué pasaría si, para ver cómo cambiará su salida a medida que cambien las características. La imagen de la derecha es la interacción de dos funciones, y las dos funciones se modifican por separado para ver su impacto general en la salida del modelo.
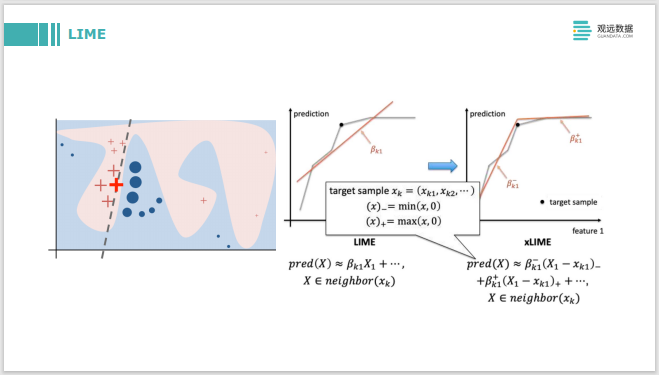
LIME es un método interpretado localmente. Haga una explicación separada para cada instancia, y su enfoque es hacer un muestreo cerca de la instancia. La imagen de la izquierda es para explicar el signo más rojo en negrita. Primero, se toman muchas muestras a su alrededor y se construye un modelo lineal después de muestrear las muestras locales. Los coeficientes del modelo lineal para características individuales son en sí mismos interpretables. Incluyendo xLIME sobre la base de LIME, es construir dos modelos lineales para explicar esta función de pequeño a grande, desde el punto actual a una dirección más grande.

LIME también se puede aplicar al texto. El desafío con las imágenes de texto es que se muestrea mejor si se trata de datos tabulares. Agregar o restar un poco cerca del punto de muestreo facilita obtener una nueva muestra, y el texto y las imágenes serán un poco más difíciles. Por ejemplo, para las imágenes, es posible que deba usar el método de superpíxeles para realizar un muestreo de algunos bloques de píxeles. El autor también mencionó algunas de sus prácticas específicas en este artículo, y el efecto sigue siendo bueno.
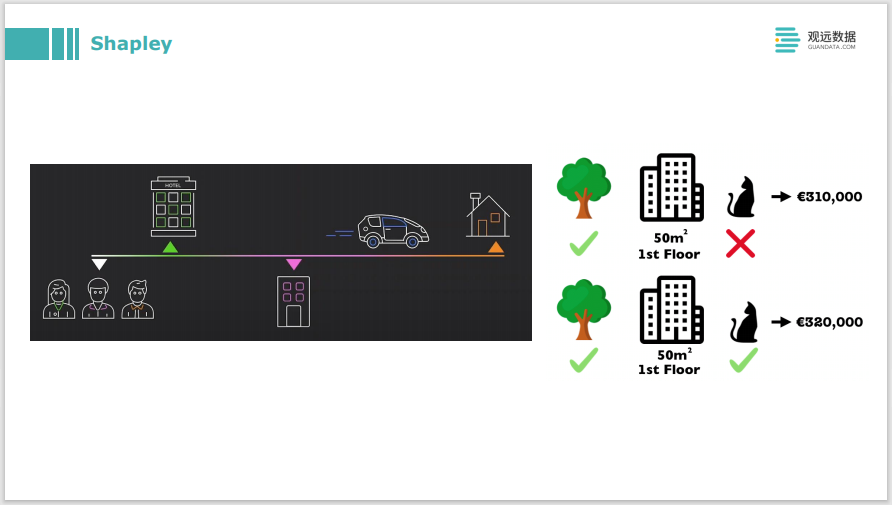
El principio detrás de Shapley es una teoría de teoría de juegos. Por ejemplo, en la imagen de arriba, el problema a resolver es que tres personas van a compartir el viaje y las tres se bajan en diferentes lugares, entonces, ¿cómo se debe repartir equitativamente la tarifa final? El problema de migrar a una explicación de aprendizaje automático es que la tarifa total final es el resultado previsto del modelo, y la tarifa que paga cada persona es la contribución de las tres características. Hay un conjunto de lógica de operación muy compleja detrás de esto, para calcular la atribución de cada característica, es decir, una explicación local, y hacer algunas explicaciones para cada muestra de predicción.
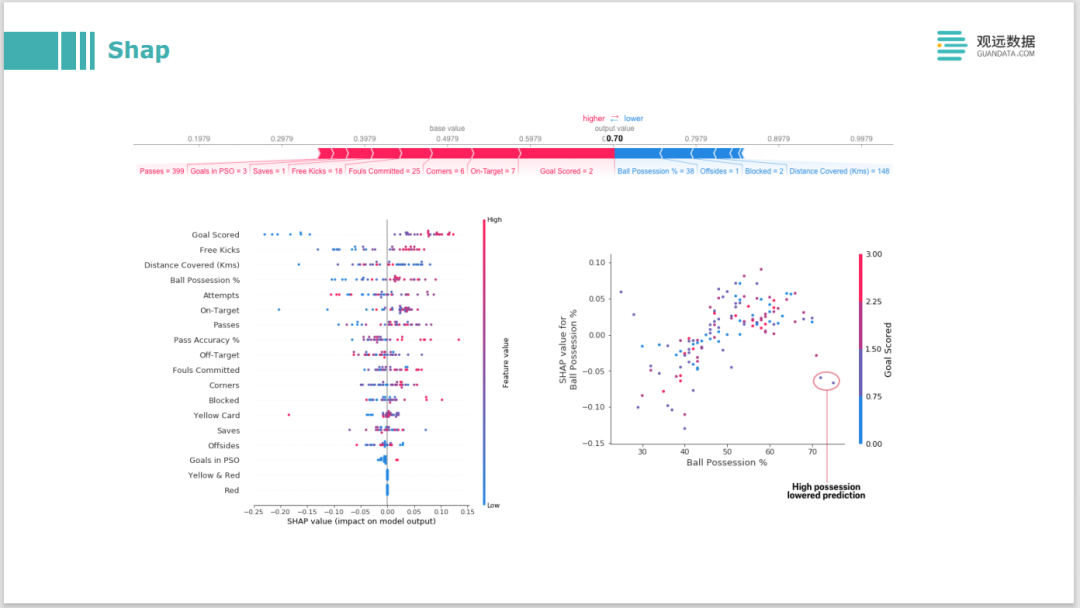
Basado en la teoría de Shapley, una biblioteca Shap es de código abierto. También es la biblioteca más utilizada en el campo de la interpretación de modelos. Tiene muchas visualizaciones integradas y ha realizado una gran cantidad de optimización de cálculo sobre la base del funcionamiento del Shapley original. Debido a que la sobrecarga de cálculo de la versión original es muy alta, Shap ha realizado algunas optimizaciones en el modelo de árbol y el modelo de aprendizaje profundo, respectivamente, que pueden mantener el tiempo de ejecución dentro de un rango aceptable.

A continuación, hablaremos sobre algunos métodos basados en muestras. Entonces, ¿cómo explicas esta predicción basada en esta muestra? Es encontrar una muestra similar a este, o encontrar una muestra representativa, y luego explicar el comportamiento de este modelo, o explicar la distribución de los datos de entrenamiento de esta manera. Este método debe tener un método contrafáctico, o un método prototipo, y un método de ataque como adversario en redes neuronales.
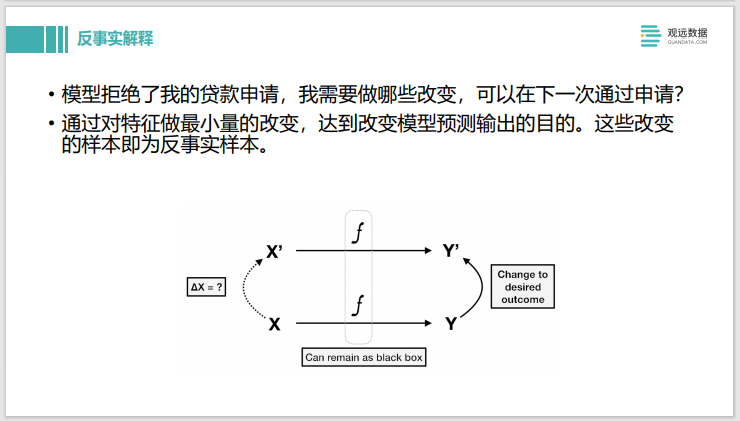
A continuación se presenta la explicación contrafáctica. Por ejemplo, el modelo juzga el modelo de la solicitud de préstamo y, después de ingresar los datos, rechaza la solicitud de préstamo. La explicación contrafactual de Shapley es que los cambios que deben realizarse en los valores propios se pueden aplicar la próxima vez, y la etiqueta predicha cambiará de 0 a 1. Esta es una explicación contrafactual.

La siguiente es la explicación de la muestra del prototipo. Prototipo es una muestra representativa en los datos, por el contrario, si no es muy representativa, se llama crítica, que es similar a outlier, este método puede ayudarnos a descubrir las deficiencias de los datos y modelos. Por ejemplo, entrenamos un modelo CNN para la clasificación y el reconocimiento de objetos. El prototipo son algunas fotos normales. La crítica encontró algunas fotos que no están bien iluminadas por la noche. Si estas fotos se clasifican como Crítica, significa que nuestro conjunto de datos puede ser para La cantidad de fotos tomadas por la noche no es suficiente. La precisión de los datos de este modelo en esta parte es relativamente pobre y debe mejorarse.
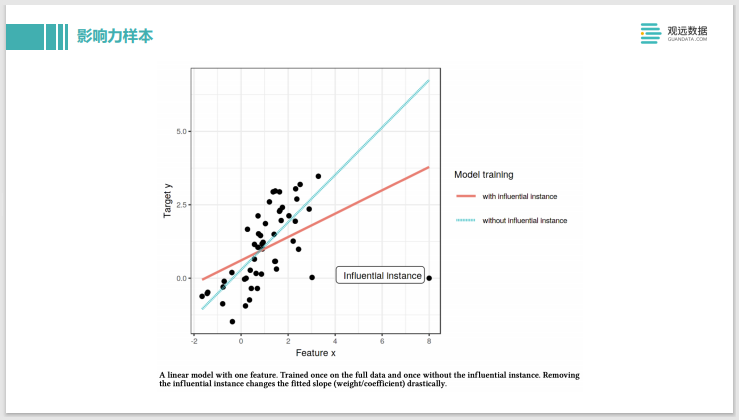
Esta última es una muestra de impacto. Es equivalente a la cantidad total original de datos para entrenar, se ajustará al modelo de información de esta línea roja. Después de eliminar la instancia influyente en la esquina inferior derecha que está muy lejos de otros puntos, se ajustará a una nueva línea azul, y puede ver que la pendiente cambia mucho, por lo que el punto en la esquina inferior derecha se puede llamar influyente. ejemplo es una muestra muy influyente. Sin embargo, este método también tiene algunos problemas de eficiencia. Es similar al principio de Shapley. Necesita considerar la influencia de cada muestra, eliminar cada muestra y volver a entrenar un modelo, lo cual es muy costoso. También existen otros métodos, como los modelos de redes neuronales, que pueden encontrar rápidamente muestras influyentes en un modelo construido, y métodos como los modelos de árbol de conjuntos que pueden encontrar rápidamente muestras influyentes.
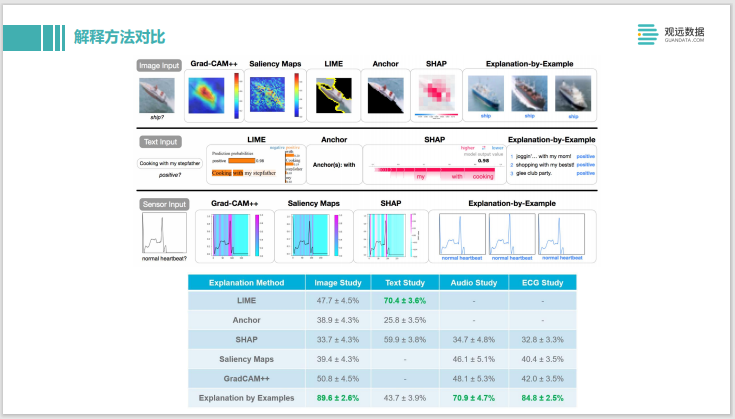
Anteriormente hablamos sobre muchos métodos de explicación, veamos la comparación de los métodos de explicación. En la parte superior hay una explicación del tipo de imagen. En comparación con Grad-CAM y otros métodos similares a los gráficos de prominencia, también hay métodos como LIME y SHAP, que se explican con ejemplos de datos de ejemplo en el extremo derecho, algunas tareas de texto en el medio y una entrada de serie temporal en el extremo. abajo explicado de diferentes maneras. Luego coloque estos métodos de explicación en la plataforma de crowdsourcing Mechanical Turk de Amazon y deje que los humanos juzguen qué explicación es mejor. Se puede observar que la más aceptada es la Explicación con ejemplos. Esto también nos da una inspiración.Si la explicación se usa para este tipo de sistema de negocios, o necesita ser explicada de manera comercial, es mejor usar una explicación de muestra. Pero como desarrollador, Shapley podría ser más útil.
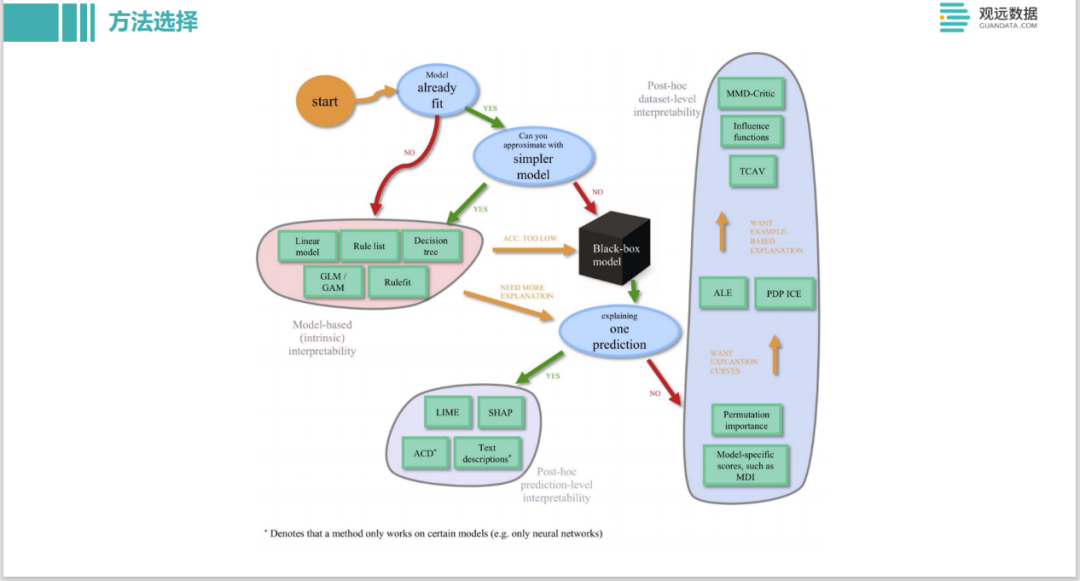
Esta es también una elección de método para la interpretación de modelos en Twitter. Incluyendo si puede aceptar un modelo con poca precisión, si necesita hacer una interpretación global o una interpretación local de cada instancia, se enumera un diagrama de decisión similar y también puede elegir en función de esto.

Entonces, ¿qué es una buena explicación? También hay mucha investigación sobre esto. Especialmente cuando el público objetivo de la explicación es un grupo diferente, se debe prestar especial atención a algunos puntos.Desde la perspectiva de la psicología social, es una buena explicación para ver cómo la gente la acepta. La academia también tiene algunas investigaciones en esta área.

El reciente tutorial AAAI 2021 resume la naturaleza de una serie de buenas explicaciones desde la naturaleza matemática. Lo anterior es cuántas de estas propiedades se explican por cada método, y los dos con un número relativamente grande son Shapley Value y Integrated Gradient. Si estos dos métodos usan redes neuronales, puedes usar IG, si usas algunos modelos tradicionales, Shapley Value también es una muy buena opción.
sesión de combate

Anteriormente hablamos sobre cómo usar el método de interpretación del modelo para depurar el modelo. La imagen de la derecha es cómo construir el modelo. La persona en el medio está de pie encima de un montón de matrices y elementos informáticos. El embudo de la izquierda es por donde entran los datos y los resultados salen por la salida de la derecha. Después de construir un modelo muy complejo, entran los datos y salen los resultados, y ves que la tasa de precisión no es muy buena, entonces, ¿qué harás a continuación?
Esta persona juega con las cosas complicadas en el medio, es decir, ajusta los parámetros, luego cambia la estructura del modelo, cambia a una función de activación o función de pérdida diferente, y luego ve si el efecto ha mejorado. Si no, continúa con la depuración. Tal depuración puede ser relativamente ineficiente y es imposible saber exactamente qué hace el modelo intermedio, por lo que no es de gran ayuda para el desarrollo iterativo del modelo.
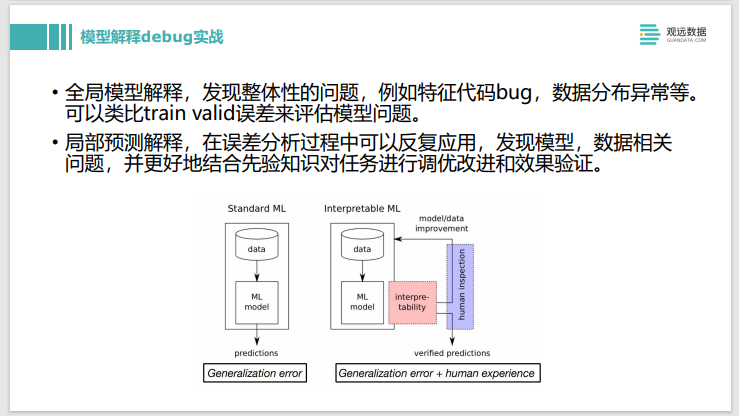
Contar con herramientas de interpretación de modelos puede ayudar a mejorar este proceso. Cuando los resultados están disponibles, las herramientas de interpretación del modelo se pueden utilizar para explicar algunos elementos que no están bien predichos. Compruebe si las características utilizadas cumplen con las expectativas. De lo contrario, la experiencia artificial puede integrarse en el proceso de construcción del modelo. Después de descubrir el problema a través de la explicación del modelo, se realizó una nueva ronda de entrenamiento y se obtuvo un nuevo resultado. En este momento, podemos continuar usando la herramienta de explicación para verificar si la mejora es efectiva. A la hora de hacer experimentos, además del overfitting y underfitting, que se puede ver directamente desde los indicadores, son de gran ayuda otras cuestiones más detalladas después de contar con herramientas de interpretación de modelos, que te ayudarán a acelerar las iteraciones, y es una buena manera de integrar humanos experiencia empresarial en él.
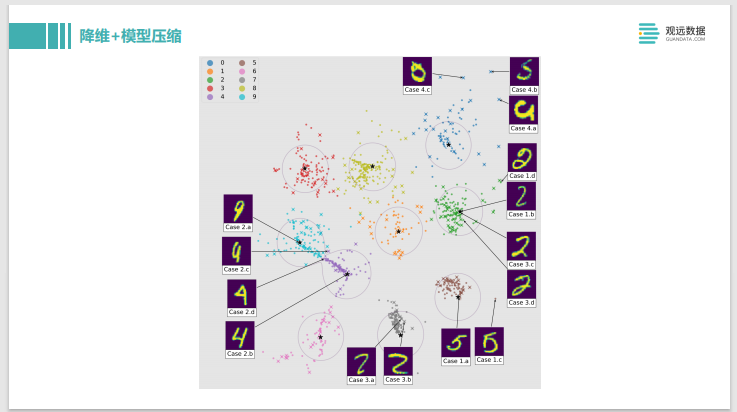
Este es un ejemplo muy interesante, llamado Dark Sight, que hace una reducción de dimensionalidad y una compresión del modelo al mismo tiempo. Después de entrenar el modelo multicategoría del clasificador, los resultados de salida previstos del modelo pueden reducirse en dimensión y visualizarse en un plano bidimensional. Esta reducción de dimensionalidad tiene una característica muy buena, puedes ver los dos en el medio, uno es el bloque azul, que es una serie de 9 números, y el bloque rosa es el número 4. Hay un cruce entre los dos círculos. Si hace clic en la instancia del número en el cruce, verá que el número se parece al 9 y al 4. Esta característica puede visualizar intuitivamente la parte que el modelo siente difícil de juzgar en el lienzo y analizarla haciendo clic e interactuando. Las muestras en el medio son como 9 y 4, que es más difícil para el modelo, por lo que puede ser objetivo. para hacer algún procesamiento. Esto también nos trae una inspiración, de hecho, la reducción de la dimensionalidad de muchos modelos y datos también es útil para la interpretación del modelo.

Este es el uso de IG - Gradientes integrados para hacer diagnósticos de enfermedades en películas de rayos X. La imagen donde se puede ver la entrada original está a la izquierda. La etiqueta de salida es que la persona tiene una enfermedad. Después de que usamos IG para explicarlo, podemos ver algunos puntos resaltados en rosa en el lado derecho, lo que significa que el modelo en estos píxeles piensa que la muestra está clasificada como que tiene un problema, sí. El píxel con la mayor contribución.
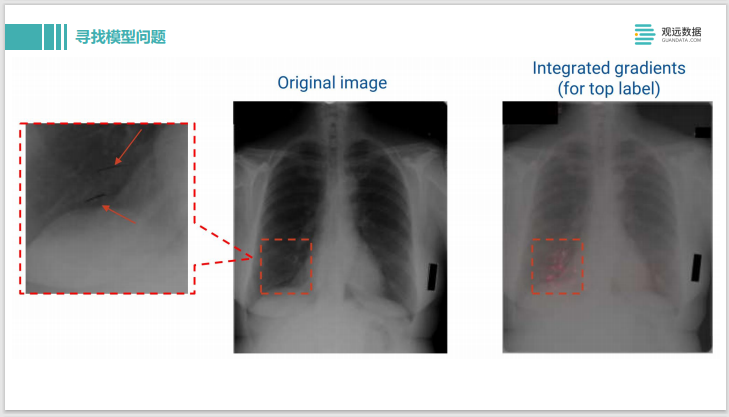
Podemos acercar los píxeles nuevamente para ver qué tipo de juicio ha hecho el modelo. Resulta que en realidad son dos líneas dibujadas con un marcador negro. Debería ser que el médico vio la película de rayos X durante el proceso de diagnóstico y diagnosticó algo mal. Dibujó dos líneas con un rotulador aquí. Lo que yo lo que se obtuvo fue la marca del médico, no el patrón del tejido patológico, por lo que el juicio del modelo es realmente problemático. De esta forma, es muy conveniente encontrar algunas debilidades en el modelo a través del método de interpretación de modelos.

El siguiente ejemplo es similar y también utiliza el método de IG. Esta es una tarea VQA - Visual Question Answering de mirar imágenes. El problema es cuán simétricos son los ladrillos blancos en la imagen. La respuesta dada por el modelo es muy, que es muy simétrica. Esta respuesta es una respuesta correcta que tiene sentido. Pero después de que usamos tecnología para analizarlo, encontramos que el texto rojo tiene una contribución alta, el texto azul tiene una contribución relativamente negativa y el texto gris casi no tiene contribución, por lo que, de hecho, el modelo da esta respuesta al pronóstico, en de hecho, se enfoca en el Cómo, por lo que el grado de atención es problemático.

Por lo tanto, si reemplazamos el medio simétrico con otras palabras, como asimétrico, es asimétrico, o cuán grande es cuán grande, o incluso lo cambiamos a una oración que no tiene ningún significado. Ladrillos blancos hablando, qué rápido, respondió muy. Esto nos ayudó a descubrir los problemas del modelo. Realmente no entendía la oración y la imagen, pero parecía dar una buena predicción, lo que también nos ayudó a descubrir algunos problemas del modelo.
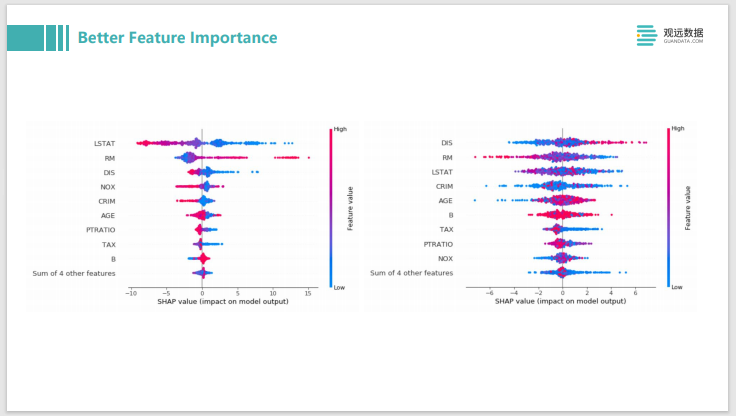
Si se trata de algunos datos tabulares tradicionales, entonces podemos usar SHAP para el análisis. Por ejemplo, como XGBboost o LightGBM, todos analizarán la importancia de las características y darán una explicación global del modelo. De hecho, si usa shap, puede dar una mejor explicación de la importancia de la característica. De hecho, no es solo el orden de la contribución de la característica de mayor a menor, sino también si la contribución de esta característica es positiva o positiva. negativa, es decir, el lado izquierdo del eje de coordenadas es contribuciones negativas, contribuciones positivas a la derecha. Además, el valor y la distribución de esta función también se pueden mostrar en un gráfico.
Por ejemplo, si su línea es relativamente gruesa, es una distribución cónica con una gran cantidad de datos; por ejemplo, la azul es un caso donde el valor propio es relativamente bajo, y la roja es un caso donde el valor propio es relativamente bajo. alto. La imagen de la izquierda es un modelo bien entrenado. Puede ver aproximadamente la mayoría de las funciones. Cuando el valor de la función es alto y bajo, puede distinguir claramente el rojo como influencia negativa y el azul como influencia positiva. Básicamente, puede estar separado.
En la imagen de la derecha, esparcimos las etiquetas al azar. Se puede ver que sus puntos azul y rojo están básicamente mezclados, y el grado de distinción obviamente no es alto, por lo que se puede mostrar a través de este patrón en el gráfico para ayudarlo a encontrar el problema. Si haces una función, se parece a la imagen de la derecha, la función alta y la función baja se mezclarán, no sé si es un impacto positivo o negativo, si no hay distinción, tú necesita ver si su función está hecha tiene un problema.
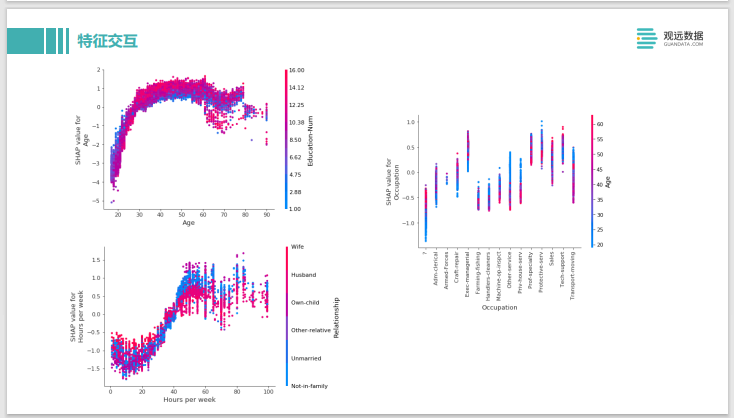
SHAP también puede hacer algunos análisis de interacción de características complejas. Este es un ejemplo de ingresos de adultos, los dos ejes en la esquina superior izquierda se dividen en dos características. Uno son los años de su educación y debajo de eso está la edad. El efecto positivo es que sus ingresos son relativamente altos y el efecto negativo es que sus ingresos son relativamente bajos. Se puede ver que cuando la edad es de 20 a 30 años, cuando la edad de educación es relativamente baja, tiene un impacto positivo por el contrario. Esto también es más fácil de entender porque entre los 20 y los 30 años, si ha recibido más de 10 años de educación, es posible que recién se haya graduado en ese momento, y sus ingresos deben ser bajos en la mayoría de los casos. Esto puede confirmar si algún conocimiento empresarial puede reflejarse en sus datos y en su modelo. Por ejemplo, a la derecha, puede ver el impacto de su ocupación, edad e ingresos. Podemos analizar a partir de él si hay una edad determinada, cuanto mayor sea, mayores serán sus ingresos. En algunas edades, cuanto más joven sea, mayores serán sus ingresos, y es una profesión que se come a los jóvenes. Todos estos pueden juzgarse a través del análisis de esta interacción específica del valor SHAP. Si no se ajusta al sentido común de su negocio, puede hacer algún diagnóstico y modificación de datos específicos.
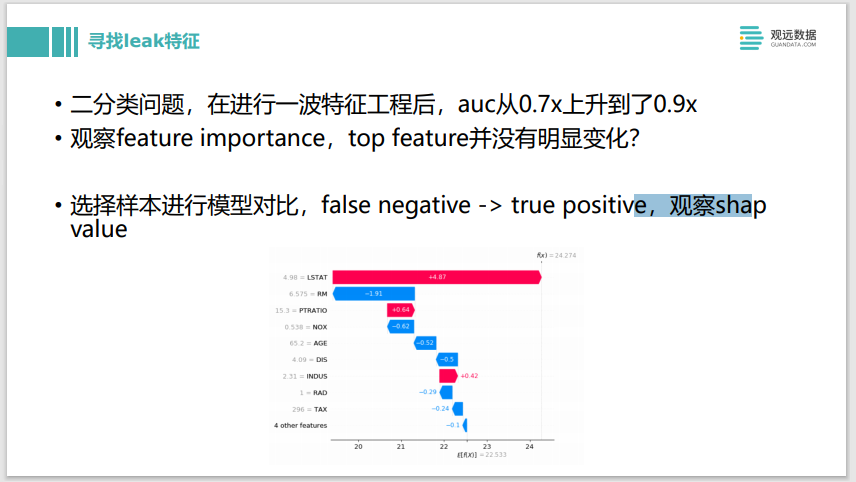
En este ejemplo, hicimos un problema de clasificación binaria e hicimos una ola de ingeniería de características, y de repente descubrimos que el AUC aumentó del nivel original de 0,7 a 0,9, lo que obviamente no es razonable, y deberían haber ocurrido algunos problemas. Observamos la importancia de la característica antes y después, y descubrimos que parecía que la característica superior no tenía un cambio significativo. No había ninguna característica que saltara repentinamente desde abajo, y no encontramos una característica de fuga tan obvia. De hecho, también podemos usar el valor SHAP para hacer esto. Puede elegir los modelos antiguos y nuevos, y luego encontrar una muestra de pronóstico. Por ejemplo, originalmente era una predicción falsa negativa que estaba mal, pero luego se predijo que eran verdaderos positivos y la predicción fue correcta. Veamos la comparación del valor SHAP antes y después, y luego veamos qué característica tiene la mayor diferencia en la contribución positiva del valor SHAP. Podemos elegir 10 o 20 muestras para verificarlas por separado, y encontrar que si todas caen en la misma característica, entonces es fácil averiguar cuál es la característica de fuga. Este también es un ejemplo del uso directo de la tecnología de detección de modelos para encontrar características de fugas.
Entonces, si es un problema de regresión, es similar. Por ejemplo, puede encontrar las muestras pronosticadas que Top sobrestimó y las muestras pronosticadas que Top subestimó, y luego hacer un análisis relacionado con el valor SHAP en el grupo respectivamente para ver las características de las más sobreestimadas por TOP. son ellos. Si es una función problemática, podemos hacer un análisis específico. Si la diferenciación de funciones no es lo suficientemente alta, es posible que debamos agregar algunas funciones nuevas. Top subestima el punto, y es un enfoque similar.

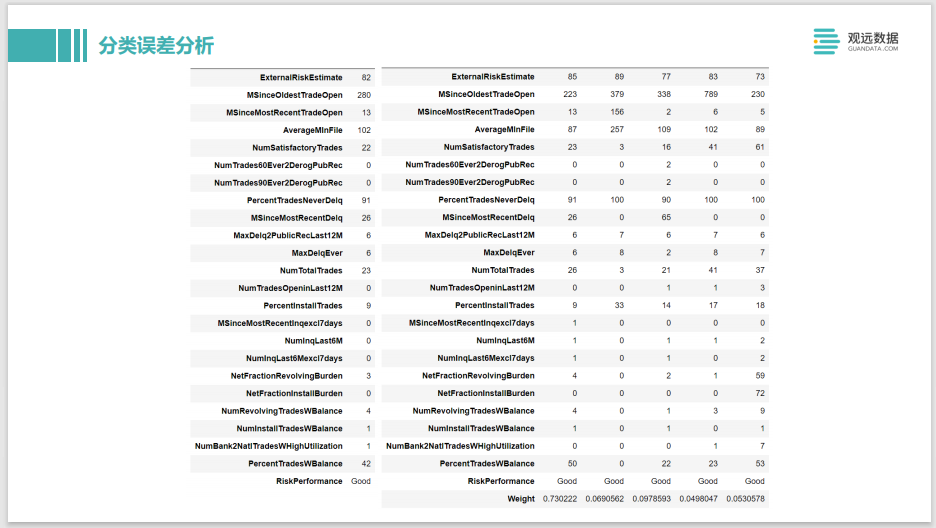
Lo mismo es cierto para los problemas de clasificación. Por ejemplo, si se enfoca en las muestras incorrectas con las puntuaciones más altas y más bajas, tiene más confianza, pero predice mal. Además, la predicción cerca del límite de decisión es una muestra con una probabilidad cercana al 50 %.También puede usar SHAP para analizar sus características y ver si hay algunas características conflictivas. Es decir, en realidad hay algún conflicto entre la característica a y la característica b, lo que hace que sus efectos se compensen.Al final, el modelo no está seguro de si es una muestra positiva o una muestra negativa.
Además de SHAP, hay un poco más de técnicas que puede usar para problemas de clasificación. Incluyendo el uso de ejemplos para hacer algunas explicaciones, como ProtoDash para encontrar algunas muestras de prototipos. También existe el problema de los datos de usar muestras contrafactuales para diagnosticar estas muestras.
El significado general de este ProtoDash es un análisis crediticio de una tarjeta de crédito. Si el valor de la función de muestra a la izquierda es bueno, significa que se cree que la persona es solvente. Entonces, por qué el modelo le dio esta predicción, podemos encontrar muestras similares a él en el conjunto de entrenamiento. Entonces, después de que ProtoDash encuentra una muestra de destino, encontramos algunas muestras prototipo similares en el conjunto de entrenamiento. Después de encontrarlo, puedes ver que el primer peso de la derecha es muy alto, lo que indica que tiene una similitud muy alta con él. Entonces se le puede explicar bien a la parte comercial, cuando uno de tus ejemplos de entrenamiento tiene un ejemplo muy cercano a sus características, porque era una persona de confianza en ese momento, entonces pensamos que también es un ejemplo nuevo. hombre de promesa. Pero si hay un conflicto entre estos dos, por ejemplo, encontramos que la predicción del modelo de esta persona es buena, y la última etiqueta de la muestra de prueba a la izquierda muestra que esta persona tiene mal crédito. En este momento, necesitamos ver por qué las personas similares a él tienen buen crédito y si hay alguna diferencia entre estas dos personas que no hayamos detectado. Luego, debemos agregar algunas características para fortalecer la distinción entre estas dos características, de lo contrario, el modelo será difícil de distinguir cuando son similares. O algún procesamiento jerárquico de funciones puede ayudar a mejorar el modelo y puede integrarse en algunos de sus conocimientos comerciales para mejorar el modelo.
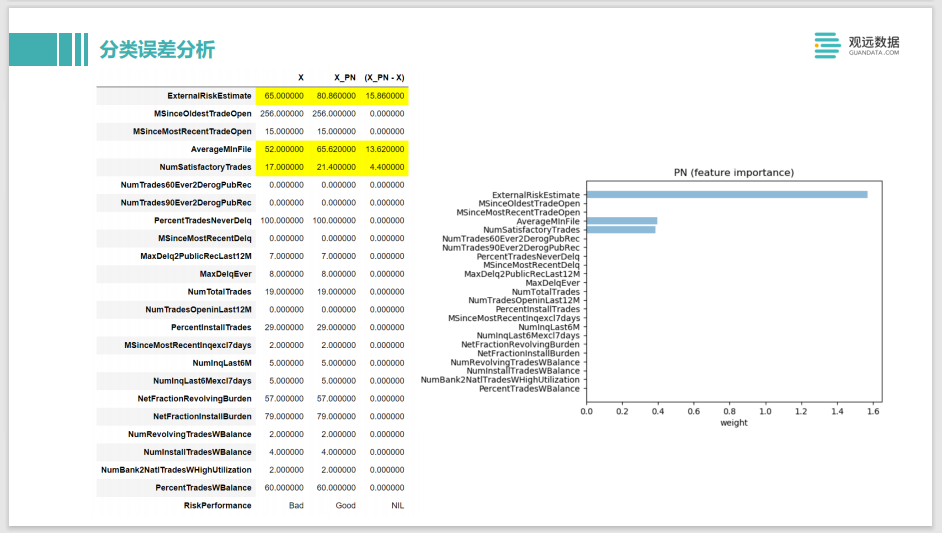
El último es un caso contrafáctico, o el ejemplo de ahora. Por ejemplo, se predice que la X en el extremo izquierdo de la persona original es una persona que no cumple su palabra. ¿Qué debe hacer para que pase la verificación y se considere que es una persona que cumple su palabra? La modelo le sugirió que hay tres valores para aumentar. El primero es ExternalRiskEstimate. Este valor es cuanto más grande, mejor. Similar al puntaje de Sesame Credit, es el puntaje externo promedio. Cuanto mayor sea el Sesame Credit, más confiable es la persona. El siguiente AverageMinFile y NumSatisfactoryTrades, uno es la cantidad de actuaciones, cuantas más veces cumpla el contrato, teóricamente hablando, debería ser más confiable, y la cantidad de meses de sus registros es la duración de todo su ciclo histórico de crédito, por ejemplo , si la tarjeta de crédito se ha utilizado durante 10 años, entonces pensaremos que es más probable que sea una persona confiable. Si las muestras contrafactuales están más en línea con su juicio comercial, significa que la capacitación general de este modelo es precisa.
Pero si al final hay algo, como que quiere cambiar su género o raza, puede haber algunos problemas con lo que el modelo ha aprendido. Es posible que encontremos que este modelo es cuestionable en términos de equidad para él, por lo que se necesitan algunas mejoras. Este es un ejemplo de una muestra de ejemplo para explicar el método y ayudarnos a mejorar el modelo.

Con respecto al desarrollo de modelos, hay otra gran aplicación, que es cómo usar esta tecnología de análisis de modelos para explicar el lado comercial. Aquí hay un ejemplo en el que necesitamos construir modelos con diferentes requisitos. Por ejemplo, queremos construir un modelo de recompra de usuarios. Aquí tenemos tres opciones: la primera es poder predecir con precisión qué usuarios volverán a comprar. El objetivo de su negocio es la precisión, es decir, puede ignorar otras cosas y simplemente mejorar la tasa de precisión.
El Modelo 2 puede decir qué combinaciones de características están altamente correlacionadas con el comportamiento de recompra, que es un ejemplo de una explicación global. Es proporcionar información al lado comercial, para que la empresa sepa lo que se debe hacer, lo que puede aumentar la tasa de recompra del usuario. Es una guía de negocios para ellos. Podemos optar por algunos relativamente sencillos, como los árboles de decisión y la regresión lineal.
El modelo tres es capaz de decir por qué este modelo cree que cierto usuario volverá a comprar. Es una interpretación local de grano más fino. Su escenario de uso es, por ejemplo, cuando hacemos marketing de clientes. Después de que un cliente realiza una compra, el modelo predice que es posible que no vuelva a comprar más tarde. Podemos explicar por qué se predice que no volverá a comprar. Luego, puede realizar configuraciones personalizadas para cada usuario y usar algunas recomendaciones o acciones comerciales para permitirle volver a comprar.
Esto significa que necesitamos construir diferentes modelos en diferentes escenarios para lograr los objetivos comerciales. Por supuesto, el negocio en realidad tiene muchos desafíos. La mayoría de las explicaciones del modelo son correlacionales en lugar de causales. A veces verás que puede sugerir que aumentes un poco la edad del usuario, pero en realidad esto no es fiable, porque es imposible aumentar manualmente la edad de una persona. Además, al construir un modelo interpretable, también se debe considerar la construcción de características. Si se construyen miles de características y se da una explicación con valor SHAP, el lado comercial no podrá entenderlo, incluso la explicación de miles de características es incomprensible. El proceso de pronóstico es realmente muy complicado. No es solo un modelo, pueden ser múltiples modelos, e incluso hay algunas reglas de procesamiento de negocios detrás del modelo, por lo que es necesario explicar todo el proceso de pronóstico. Cómo conectar todo el proceso también es un desafío. Además, incluidos los tres escenarios de usuario diferentes mencionados anteriormente, los modelos y las explicaciones que debemos elegir pueden ser diferentes, por lo que se requieren diferentes métodos de desarrollo para diferentes escenarios comerciales. Si la explicación dada al final es un paso procesable, es decir, si los usuarios pueden tomar algunas medidas para cambiarlo, en realidad es un tema muy importante. No solo implica la interpretación de modelos, el aprendizaje automático, sino que también puede implicar algunas consideraciones en la optimización de la investigación operativa o los gráficos de conocimiento.

A continuación, se presentan algunos productos y aplicaciones. Por ejemplo, H2O.ai, SageMaker, incluida la plataforma de IA en Google Cloud, también proporcionan componentes relacionados con la interpretación de este modelo, y Fiddler y Truera se centran en la dirección de la interpretación del modelo. empresas de nueva creación.
La tabla de la derecha muestra algunas aplicaciones de interpretación de modelos en la industria, veamos en qué escenarios se aplican, qué medios técnicos se utilizan y quiénes son los usuarios finales. Puedes ver un total de 8. Cinco de ellos son utilizados por los desarrolladores, es decir, la mayoría de los ingenieros utilizan algunas técnicas de explicación al desarrollar modelos. Solo hay 3 relativamente pocos, que se explicarán hasta el lado comercial final. Y el método de explicación para el lado comercial es relativamente simple, uno es la importancia de la característica. En términos de escenarios de aplicación, además del desarrollo y evaluación del modelo, se aplica en todo el ciclo de vida del modelo de aprendizaje automático. Si va a la introducción del producto de Fiddler, también lo verá.
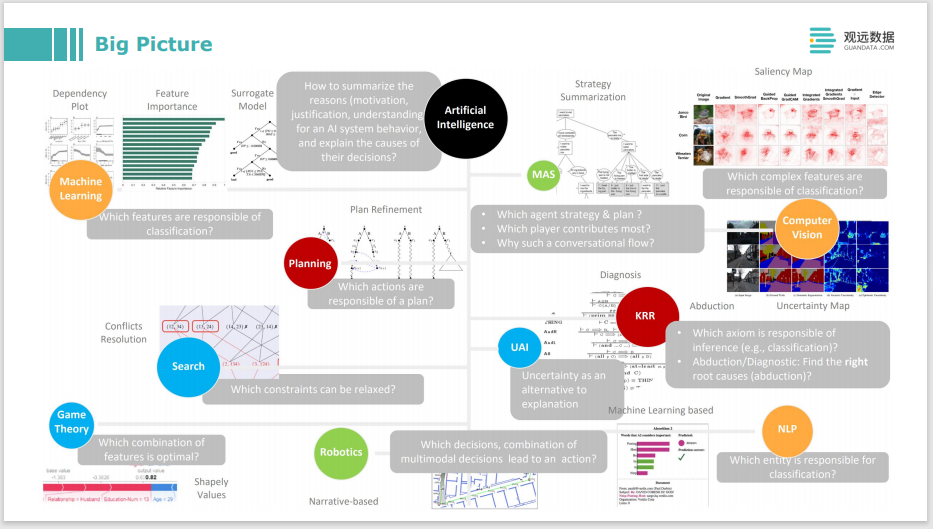
De lo que acabo de hablar es del aprendizaje automático interpretable. Puede ver las casillas amarillas, como aprendizaje automático, visión o PNL. Si se trata de IA, su alcance será mayor, como algunos sistemas como los multiagentes, o algunas operaciones de optimización, optimización de búsqueda o planificación, o algo relacionado con la expresión y el razonamiento del conocimiento, todo esto puede necesitar una explicación. Al construir todo el sistema inteligente de toma de decisiones, no solo se debe explicar el algoritmo, o la parte del aprendizaje automático en un sentido estricto, sino también la optimización de otras operaciones, el razonamiento del conocimiento y el razonamiento lógico, o el aprendizaje por refuerzo en un sentido múltiple. entorno de inteligencia La elección de la estrategia también requiere alguna explicación. O para ayudarlo a mejorar el modelo y ayudar a su negocio y audiencia a comprender por qué toma decisiones, que son muy útiles.

Escanee el código o haga clic para usar la demostración para experimentar los productos de Guanyuan