Machine Learning (ML) los datos de prueba desde un ordenador portátil o un laboratorio de ciencias para el proceso de producción no es una gran cantidad de personas que han tenido la experiencia. científicos de datos a menudo se encargan de esta tarea difícil, porque saben que la máquina de algoritmos de aprendizaje, y puede ser su primer propuestos. Al mismo tiempo, ha habido muchos desafíos en torno a la implementación de soluciones de entorno de producción AI Inteligencia Artificial. En este artículo nos centraremos en dos aspectos de la materia que se describen:
Tema 1, la máquina de aprendizaje de cómo construir una aplicación de producción del experimento se volvió
Tema 2, las tendencias de inteligencia artificial 7 y AI aprender cómo operar la máquina y la colaboración.
En primer lugar, la producción de la máquina de aprendizaje de cómo construir una aplicación desde la dirección experimental
Cómo iniciar un ciclo de vida de producción negocio exitoso de la máquina de aprendizaje (MLOps), se transfirió a un mínimo la posibilidad de que el producto el mismo algoritmo (MVP) por ml en los experimentos de los servicios de producción de un prometedor. MVP es común en el desarrollo de productos, ya que pueden ayudar a los clientes a obtener rápidamente el producto / servicio, con suficientes características hacen que sea posible, y para promover la próxima versión basada en el uso de la retroalimentación. En el contexto de aprendizaje automático, los MVP ayudan demanda clave de producción separada de servicio ML, con el mínimo esfuerzo y la ayuda entregarlo.
MVP paso en la producción de la máquina de aprendizaje se describen los científicos y organizaciones de datos con cientos de casos de uso de la experiencia obtenida a partir de los últimos años. Como se muestra a continuación:
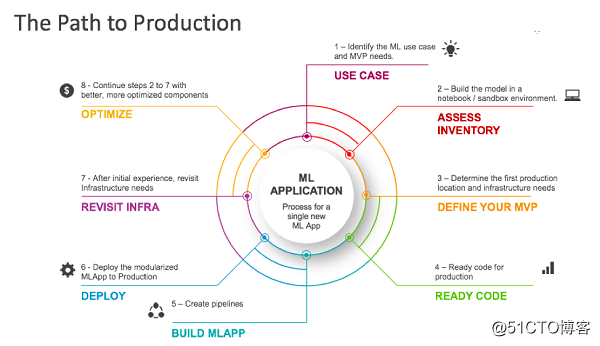
Figura 1: Producción experimental del desarrollador a la ruta de ML
Paso 1: Asegúrese de que su caso de uso:? ¿Qué le gustaría hacer
Esto puede parecer obvio, pero el primer paso es entender cuáles son los requisitos mínimos de las aplicaciones de negocio, y la brecha entre el experimento y los requisitos mínimos. Por ejemplo, si las características de las funciones que asumen que el experimental disponible de la aplicación de negocios para proporcionar más, entonces esta diferencia puede afectar la producción. La mejor manera de encontrar esta brecha es apoyar la definición de las aplicaciones de aprendizaje automático para sus aplicaciones de negocio.
Aquí hay algunas preguntas que necesita responder:
• ML desde el punto de vista, esta aplicación ML ayudará a resolver cualquier problema de negocio?
• ¿Qué necesidades de aplicaciones de lavado de predecir lo que va a recibir la entrada ??
• ¿Hay datos suficientes para entrenar el modelo y medir la efectividad? son estos datos limpios, accesibles y así sucesivamente? datos experimentales pueden ser utilizados para la limpieza manual. Producción de datos de entrenamiento también necesita ser limpiado.
• ¿Hay experimentos preliminares (en el entorno de desarrollo / notebook / laptop) muestra un camino prometedor para entregar los algoritmos necesarios para predecir la calidad /?
• ¿Cómo las necesidades de aplicación de LD y aplicaciones de negocio (REST, por lotes, etc. ) la integración?
Una vez que se han respondido a estas preguntas, se puede entender por lo general lo que se necesita en la aplicación ML MVP. Esto sentó las bases para los pasos 2 y 3.
Paso 2: se establece una lista de estado:? ¿Qué tienes
Una vez que los casos de uso, el siguiente paso es integrar el estado inicial, por lo que puede asignar el viaje hasta el destino. Un estado de activación característica típica comprende el promotor del nivel deseado de órgano de aplicación prototipo ML:
un entorno de datos del programa de software • científicos, tales como un entorno de desarrollo portátil Jupyter, R, Matlab similares. El código se realiza generalmente (prometedores) modelos y experimentos iniciales de aprendizaje automático.
• Estos datos de código ya está en un lago u otros datos en la base de datos para funcionar a través de uno o más conjuntos. Estos datos forman parte de los lagos de bases de datos de clientes y entornos normales de infraestructura del centro de datos. Estos conjuntos de datos puedan existir en los ordenadores portátiles, los datos pueden necesitar ser trasladado al lago.
• Ejecutar el código en estos entorno de desarrollo de formación, a veces hay ejemplos de modelos.
En muchos sentidos, este es similar al estado de prototipo de software de inicio a otro dominio (no-ML). Al igual que otro software, código de prototipo no se pueden estar utilizando la versión de producción esperada en todos los conectores, factor de escala y mejoras para escribir. Por ejemplo, si la versión de producción tiene que leer los datos de la nube de almacenamiento de objetos, y su necesidad experimento para leer los datos almacenados en la computadora portátil, es necesario agregar el conector de almacenamiento de objetos en el código de línea de producción. Del mismo modo, si sale el código del experimento, cuando se produce un error, es posible producir inaceptable.
También son específicos de los retos de aprendizaje automático. Por ejemplo:
• generar el modelo presentado aquí puede requerir la introducción para guiar la tubería de producción.
• Es posible que tenga que añadir específica se detecta código ML, por ejemplo, estadísticas de los informes ML, ML generar alarmas específicas, la recogida de estadísticas de detección (se realiza) para el análisis a largo plazo y otros fines.
Paso 3: Definir su producto MVP
ahora está listo para definir MVP: El primer servicio básico que va a utilizar en la producción. Para ello, es necesario determinar en primer lugar de producción, que es el primer código se ejecuta ubicación.
Esto depende en gran medida de su entorno. Una opción a corto plazo podría ser la de proporcionar la infraestructura de centro de datos para otras aplicaciones (no-ML, etc.). Usted también puede tener una visión a largo plazo, incluyendo la integración con la estrategia de software o servicios de internet y otros aspectos.
Además de determinar la primera ubicación, también es necesario abordar las siguientes cuestiones:
datos de acceso • Lake pueden ser genéricas, a menos que la organización (empresa) especialmente las restricciones de acceso conjunto específico aplicado al análisis de los datos utilizados.
• Se debe instalar el motor de la máquina de aprendizaje (Spark, TensorFlow, etc.). Si utiliza un recipiente, que puede ser muy versátil. Si utiliza el motor de análisis, puede tener una alta cuenta con ML. Necesidad de encontrar y contiene todas las dependencias (que usted necesita para ejecutar el acceso a la biblioteca de tuberías, etc.).
• la necesidad de motor de análisis y el tamaño del contenedor ajustado para asegurar que el alcance de la prueba de rendimiento inicial y de depuración es razonable. Pruebas y puesta será iterativo.
• necesidad de definir el proceso de actualización. Por ejemplo, si usted decide actualizar su código de plomería, y necesita una nueva biblioteca no se instala previamente, tendrá que considerar cómo tratar con él.
Paso 4: Preparación para la producción del código
Ahora, es necesario tener en cuenta su experimento (si los hay) que requiere el uso de código en la producción. Si usted no planea volver a entrenar el modelo de producción, el código a continuación, debe tener en cuenta sólo por el razonamiento. En este caso, una solución simple podría ser la de desplegar una tubería de inferencia predefinida proporcionada por el proveedor.
Si va a estar en un entorno de producción reciclaje o tener una costumbre exige, pero la inferencia de tuberías pre-construido no puede satisfacer esta demanda, entonces tendrá que producir para preparar el código de experimento, o construir cualquiera de su código del experimento no lo hace la nueva producción cuenta. Como parte de ello, es necesario considerar los siguientes puntos:
• Producción de extinción (el manejo de errores)
• modular para su reutilización
• Llamada de conector, para recuperar y almacenar datos entre el lugar de producción identificados en el paso 3.
• Se ahorrará donde el código (Git, etc.)?
• ¿Qué debe añadir una herramienta para asegurarse de que puede detectar problemas de producción y modelos de depuración?
Paso 5: construir una aplicaciones de aprendizaje automático
, ya que ha estado a punto todos los bloques de código, ahora se puede crear una aplicación de aprendizaje automático. Esta es la razón por la construcción de la tubería es simplemente diferente? Con el fin de realizar de forma fiable en la producción, pero también es necesario para garantizar que los mecanismos de orquestación de tubería, de gestión y de salida, así como otras versiones del modelo también está en su lugar. Esto incluye la forma de actualizar cuando un nuevo modelo está en la tubería, así como la forma de mejorar el código de plomería después de que el nuevo código en la producción.
Si va a realizar la producción de ML en marcha, se puede configurar el tiempo de ejecución de aplicaciones ML, y conectarlo con el código, y otros componentes que creó en el paso 1 a 4. La figura 2 muestra un ejemplo de visualización de una aplicación de ML generada por el tiempo de ejecución MCenter ParallelM.
Una aplicación de ejemplo ML: 2 FIG.
Paso 6: Las aplicaciones de aprendizaje de máquina desplegados en el entorno de producción
una vez que tenga una aplicación de aprendizaje automático, se puede desplegar hasta! Para implementar, lo que necesita para iniciar la aplicación ML (o tubo) y conectarlos a sus aplicaciones de negocio. Por ejemplo, si se utiliza REST, ML su aplicación creará un extremo REST al iniciar su aplicación empresarial puede llamar a cualquier predicción (ver Figura 3).
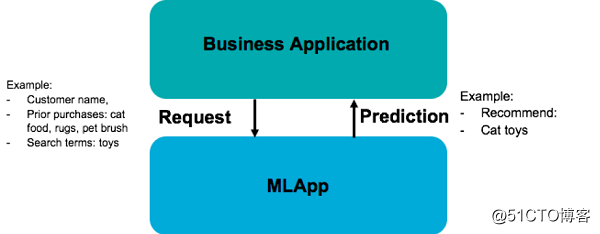
Figura 3: ML aplicación para generar un servicio REST para uso aplicaciones de negocio
Tenga en cuenta que el despliegue puede ser considerado MVP "hecho", pero este no es el final de su viaje. Un servicio de la máquina de aprendizaje exitoso tendrá una duración de meses o años, durante los cuales la necesidad de gestionar, mantener y controlar.
De acuerdo con la solución seleccionada en el paso 5, el despliegue se puede automatizar, sino que también puede ser manual. MLOps herramienta proporciona la implementación automática en tiempo de ejecución. Si usted no tiene estas herramientas cuando se ejecuta la aplicación ML, puede que tenga que escribir guiones y otro software para ayudarle a implementar y gestionar la tubería. También puede ser necesario para trabajar con su organización de TI para realizar esta tarea.
Paso 7: mejor
recuerdo, en el paso 3, se puede optar por una posición a corto plazo para ejecutar la producción ML MVP. Después del despliegue MVP pasos 5 y 6, puede requerir medidas adicionales para comprobar los resultados del MVP, y reconsiderar las decisiones críticas de infraestructura. Ahora el código / MVP al menos en la primera prueba y ejecutar la infraestructura, se puede comparar y contrastar las diferentes infraestructuras, para ver si la necesidad de mejorar.
Paso 8: optimización continua
Tenga en cuenta que los pasos 3 - 7 de repetirse en el ciclo de vida de este servicios de aplicaciones casos de uso del negocio de aprendizaje de máquina. ML aplicación en sí mismo puede ser redefinido, a cambio, la transferencia a la nueva infraestructura, y así sucesivamente. Se puede ver cómo se está utilizando MVP, lo retroalimentación que recibe de su negocio, y correspondientemente mejorado.
MLOps qué?
MLOps es una implementación práctica integral en un entorno de producción y modelo de gestión. Los pasos anteriores muestran cómo obtener MLOps iniciadas por el primer despliegue del modelo. Una vez que haya tomado los pasos anteriores, usted tendrá por lo menos uno aplicaciones de aprendizaje automático en la producción, entonces tendrá que gestionar su ciclo de vida. A continuación, puede ser necesario considerar otros aspectos de la gestión del ciclo de vida ML, como modelo de gobierno de gestión, su empresa cumple con todos los requisitos reglamentarios, KPI desarrollado para evaluar los beneficios del modelo ML para aplicaciones de negocios trae, y así sucesivamente.
En segundo lugar, la inteligencia artificial 7 tendencias operativas y AI y aprendizaje automático Cómo colaborar
La mitad superior, se describe el proceso de aprendizaje de la máquina de prueba (ML) para la implementación de producción. La mitad inferior esquema ayuda a los usuarios a simplificar y ampliar toda la máquina de aprendizaje de Inteligencia Artificial tendencias de la industria del ciclo de vida de siete. Aquí vamos a describir cada tendencia, discutir por qué es importante para el aprendizaje de máquina, y cuando la compañía decidió aprovechar la tendencia a acelerar o mejorar su práctica ML operativo, ¿qué factores se debe considerar su funcionamiento.
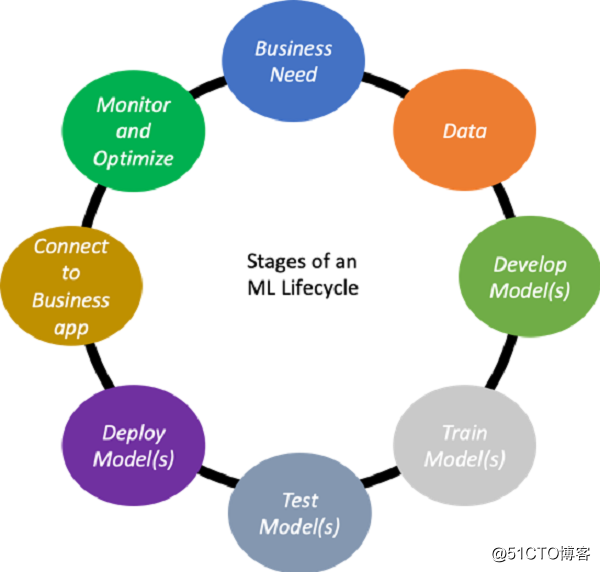
Máquina de aprendizaje del ciclo de vida (ML)
La figura 1 muestra un ciclo de vida típico de aprendizaje de máquina (ML). Con el tiempo, la función ML con respecto al negocio necesita ser optimizado aún más, este ciclo se repetirá.
Tendencia: mercado de datos
plan de estudio de muchas máquinas primer desafío es encontrar un conjunto aceptable de los datos. Los datos del mercado que tratan de resolver la escasez de recopilación de datos, sobre todo en áreas clave como la atención sanitaria y las cosas, proporcionando una: las personas pueden compartir sus datos, las empresas pueden utilizar los datos y el análisis de la plataforma de AI Inteligencia Artificial. plataforma de mercado para garantizar la seguridad, la privacidad, y proporciona un modelo económico para motivar a los participantes.
Otros datos del mercado puede proporcionar una gran cantidad de datos es difícil de obtener, pero el mercado puede proporcionar la fuente de datos y las que siguen después de los datos de gestión y garantizar la calidad de la información necesaria.
Tendencias: servicios de datos integrados
para hacer frente a otro punto de datos escasez de mercado de conjuntos de datos sintéticos. Los avances en la tecnología de aprendizaje automático ha demostrado máquina de aprendizaje en sí mismo puede generar conjuntos de datos reales para entrenar a otros algoritmos ML, sobre todo en el espacio de aprendizaje profundo. datos sintéticos es ampliamente reconocido por su potencial, ya que en comparación con las grandes organizaciones tienen acceso a grandes conjuntos de datos, inteligencia artificial IA puede proporcionar un campo de juego nivelado para las empresas más pequeñas. Los datos pueden ser anónimos versión sintética de conjuntos de datos reales, puede ser muestras reales de datos generados por el conjunto de datos ampliado también se puede simular el medio ambiente, como la formación de los vehículos autónomos en un entorno virtual.
Tendencia tres: Servicio de Etiqueta
buenos conjuntos de datos son escasos, etiquetados buenos conjuntos de datos más escasos. Para resolver este problema, se ha producido un mercado de etiquetas de datos, que a menudo se centran en los tipos de datos específicos (tales como objetos en la imagen). Algunas etiquetas de todas las zonas geográficas mediante la coordinación y software de gestión coordinada de etiquetado manual de personas. La compañía está siendo innovadora en este campo, y la máquina artificial basado en etiquetas aprender juntos, esta es una tendencia puramente humano tiene el potencial de reducir el costo de la etiqueta. Otras innovaciones en esta área incluyen que las empresas puedan interactuar directamente con el proveedor de servicios y servicio de identidad.
Tendencia cuatro: modelos de aprendizaje automático automatizados
Una vez que los conjuntos de datos apropiados para encontrar y etiquetar el siguiente reto es encontrar un algoritmo buena y una maqueta de tren. aprendizaje de las máquinas automatizadas de tecnología (AutoML) permite al algoritmo / selección del modelo y proceso de ajuste de automatización, obtener un conjunto de datos de entrada, la ejecución de un gran número de algoritmos de entrenamiento y la opción ultra-parámetro para seleccionar el despliegue modelo final recomendado. Asociado con AutoML (y a menudo previsto en el interior), caracterizado en el uso de características de profundidad de ingeniería de automatización como la tecnología de síntesis sintético. software AutoML veces se ejecutará en detección de desplazamiento del conjunto de datos de entrada. Algunos solución automatizada es SaaS productos, mientras que otros son software descargable que puede funcionar en la forma de un recipiente en la nube o medio interno.
Tendencia de cinco: contenedores prefabricados
para aquellos que puedan estar desarrollando su propio modelo, el recipiente es un patrones bien diseñados de despliegue de producción, porque hacen que cualquier código lata formación o el razonamiento en el entorno portátil y escalable bien definido ejecutar. Kubernetes y otras herramientas para un mayor apoyo de la preparación de la máquina de aprendizaje basada en contenedores ML escalabilidad y flexibilidad. Sin embargo, el montaje del contenedor puede ser una tarea difícil, debido a la necesidad de resolver la dependencia, y toda la pila para sintonizar y configurar. Pre-construidos mercado de contenedores para resolver este problema proporcionando las bibliotecas necesarias pre-instalado y configurado para contenedor preconfigurado, especialmente para entornos complejos, tales como las GPU.
Tendencia seis: el modelo de mercado
si no se desea construir sus propios modelos o formación, no es el modelo de mercado. modelo de mercado permite a los clientes algoritmos pre-construidos de compra, y en ocasiones también puede modelo de compra entrenado. Para estos casos es útil el uso de los siguientes:
(a) Los casos de uso común es suficiente, no es necesario personalizar el modelo de formación, la formación no necesita código / razón se personaliza equipo al buque;
(B) como el mecanismo de transferencia puede ser utilizado para aprender extender y personalizar el modelo básico;
(c) el usuario no tiene suficientes datos de entrenamiento para construir su propio modelo.
En el modelo de mercado, procesamiento de datos y la formación de un buen modelo para un trabajo tan importante puede ser descargado, lo que permite a los usuarios centrarse en otros aspectos de la operación. En otras palabras, un desafío clave es filtrar modelo de mercado de los contenidos, con el fin de encontrar los activos para sus necesidades.
Tendencia Siete: nivel de servicios de aplicaciones de inteligencia artificial
Por último, existen para los casos de uso común en los negocios, la inteligencia artificial a nivel de aplicación de servicio de IA puede eliminar la necesidad de aprender ML ciclo de vida de toda la operación de la máquina. La gente puede suscribirse a los servicios de Terminal Server para realizar la tarea de la inteligencia artificial, en lugar de crear modelos, la formación y el despliegue de ellos. servicios a nivel de aplicación AI Inteligencia Artificial como la visión, el análisis de vídeo, el procesamiento del lenguaje natural (NLP), procesamiento de formularios, la traducción del lenguaje natural, el reconocimiento de voz, los robots de chat y otras tareas.
Beneficios y precauciones
Todas estas tendencias permite a los usuarios simplificar o acelerar una o elemento más de las diversas etapas de funcionamiento de la máquina de aprendizaje de ciclo de vida ML, mediante la descarga de la reutilización de pre-construido, o etapa particular automatizado. Teniendo en cuenta el proceso de aprendizaje de máquinas ML iterativo es la forma de lograr (por ejemplo, el entrenamiento por lo general incluye decenas a cientos de experimentos), automatizar estos procesos pueden producir flujo de trabajo más trazable, reproducible y manejable. La externalización de estas tareas aún más fácil, sobre todo en el caso de fortalecer el modelo y el algoritmo (además de su propio entorno, ha sido probado en muchos entornos también) pueden ser utilizados para tareas básicas.
En otras palabras, antes de usar estos servicios en su entorno, hay varios factores a tener en cuenta:
1: Considere la aplicabilidad
No todas las tendencias son aplicables a todos los casos de uso. La tendencia más universal es AutoML, su amplia gama de aplicaciones. Del mismo modo, el modelo tiene una muy amplia gama de modelos y algoritmos disponibles en el mercado. conjuntos de datos sintéticos y mercados de datos tienden a utilizar clases específicas de realización, el recipiente de pre-construido puede ser específica para diferentes configuraciones de hardware (por ejemplo, GPU), que a su vez la configuración de hardware para un propósito particular. Muchos etiqueta de servicio de datos también tiene un propósito específico (por ejemplo, la clasificación de imágenes y la forma de lectura), pero una serie de empresas de consultoría hacer ofrecen servicio de etiqueta personalizada. Por último, AI Artificial servicios de Inteligencia-end a los casos de uso muy específicos.
2: Inteligencia Artificial confianza
que se despliegan más ML, el miedo humano universal del sistema de inteligencia artificial rendimiento cuadro negro de las preocupaciones de confianza y aumentar la intensidad de la supervisión. Con el fin de beneficiarse de AI Inteligencia Artificial, las empresas no sólo deben considerar el mecanismo de producción de aprender ML máquina, sino también en cuenta las preocupaciones de la comunidad de gestión de cualquier cliente. Si no se tratan, estas preocupaciones pueden batir, vergüenza corporativa, la pérdida de valor de la marca o riesgos legales en específico.
La confianza es una gama compleja y amplia de temas, pero el núcleo es la necesidad de comprender e interpretar la máquina de aprendizaje ML, ML y seguro para funcionar adecuadamente dentro del rango esperado de parámetros, desde malicioso ***. En particular, las decisiones tomadas por la producción de ML deben interpretarse - que debe proporcionar una explicación convincente. Esto se hace como la interpretación de las disposiciones de otros reglamentos en GDPR cada vez más necesario. Interpretabilidad está estrechamente relacionado con la equidad - tienen que estar convencidos de Inteligencia Artificial IA no es accidental o deliberadamente tomar decisiones sesgadas. Por ejemplo, el servicio de Amazon (Amazon) Rekognition AI Inteligencia Artificial también atrajo la atención debido a los prejuicios.
Oa un tercer sistemas de automatización de las partes, de ahí la necesidad de un entendimiento adicional en cada etapa Dado que casi todas las tendencias mencionadas anteriormente están relacionados con la máquina de aprendizaje ML ciertos aspectos del ciclo de vida de la descarga, o "outsourcing" para asegurar que la vida de la producción final ciclo para entregar los principios básicos de la confianza. Esto incluye la comprensión del algoritmo implementado, ya sea que se utilizan para los conjuntos de datos de entrenamiento sin perjuicio, y así sucesivamente. Estos requisitos no van a cambiar el ciclo de la vida misma, sino que requiere un esfuerzo extra para asegurar un seguimiento adecuado seguimiento, el seguimiento de la configuración y los informes de diagnóstico.
Considere 3: diagnóstico y operacionales de gestión de
componentes independientemente de aprendizaje de ciclo de vida ML, donde se trata de la máquina, su empresa será responsable de la gestión y el mantenimiento de la salud del servicio de ML en su ciclo de vida (además de las tendencias en la inteligencia artificial 7 totalmente externalizado servicios externos).
Si es así, los científicos e ingenieros deben entender el modelo de datos está desplegando para la formación conjunto de datos de modelo y de los parámetros de operación segura esperados de estos modelos. Dado que muchos servicios y mercados son incipientes, por lo que no hay una estandarización. Los usuarios son responsables de la comprensión de los servicios que utilizan, y para asegurar que los servicios pueden ser manejados de manera adecuada con el resto del ciclo de vida.
(编译 自: cómo pasar de la experimentación para aplicaciones de máquinas de producción el aprendizaje, el 7 de Inteligencia Artificial Tendencias y cómo trabajan con la máquina de aprendizaje operacional, 作者: Nisha Talagala)
Para obtener más información, visite la página web oficial de software Yihai http://www.frensworkz.com/