Gracias al desarrollo de datos, estructuras de modelos y potencia de computación paralela, la aplicación de modelos de lenguajes grandes se está desarrollando rápidamente y los modelos de redes neuronales de lenguajes grandes se han convertido en una tecnología que no se puede ignorar.
GPT ha logrado avances revolucionarios en las tareas de PNL de procesamiento de lenguaje natural. El modelo de difusión tiene el potencial de convertirse en el representante de la próxima generación de modelos de generación de imágenes. Tiene mayor precisión, escalabilidad y paralelismo, tanto en términos de calidad como de eficiencia. Se ha mejorado. El transformador y el modelo de difusión son jugadores populares en la dirección de AIGC. La razón principal no es que sean más eficientes (como menos parámetros para obtener mejores resultados), sino que aportan escalabilidad y paralelismo, es decir, producen vigorosamente milagros. Tiene una manera de ejercer su fuerza.
Para ver ejemplos de transformadores y juguetes de traducción basados en pytorch, consulte el blog.
La ola de IA desde 2012 tiene tres características principales:
- Versatilidad: una arquitectura a menudo puede resolver múltiples problemas y el mismo conjunto de modelos puede procesar tanto texto como imágenes.
- Potente: las redes neuronales y el aprendizaje profundo van mucho más allá de los métodos tradicionales, pueden lograr habilidades similares a las humanas y han superado a los humanos en algunas tareas específicas.
- Escalabilidad: trabaje duro para crear milagros: cuanto más grande sea el modelo, mayor será el rendimiento (por supuesto, la arquitectura aplicada al modelo grande también está en constante evolución)
Este artículo presenta principalmente la historia del desarrollo del modelo de lenguaje grande en 2017 y más allá. Este año, se propuso la piedra angular de la estructura de la red neuronal del modelo de lenguaje grande actual, y el lanzamiento de chatGPT parece ser una singularidad en la IA. Los acontecimientos tienen el potencial de reescribir la historia humana. Por lo tanto, es significativo dedicar mucho tiempo a presentar la historia del desarrollo de esta tecnología.
Las empresas y aplicaciones que amplían la tecnología de modelos de lenguaje y las aplicaciones relacionadas están mostrando una tendencia de desarrollo espectacular. Puede ver los últimos modelos de lenguaje de gran tamaño de código abierto en la clasificación de enlaces de puntuación en el sitio web oficial de Huggingface. Desde el punto de vista actual, es probable que LlaMA de Meta sea el primer y más exitoso modelo comercial de lenguaje grande de código abierto.

Hablemos de LlaMA más adelante, primero veamos la historia del desarrollo de modelos de lenguaje grandes desde la historia del desarrollo.
Una breve historia del desarrollo.
Aquí tomamos como ejemplo los modelos con gran influencia, porque muchos modelos de lenguajes grandes son de código cerrado y ninguno de estos modelos de código cerrado puede superar el modelo OpenAI del mismo período, por lo que ya no se enumeran aquí. El mejor modelo de lenguaje grande de código abierto es actualmente LLaMA. La historia de evolución de estos dos modelos en esta imagen representa la historia de desarrollo del modelo de lenguaje grande general.

El Transformer propuesto por Google en 2017 es un modelo codificador-decodificador para seq2seq para traducción automática, y este modelo fue visto por OpenAI, que se estableció a fines de 2015. En ese momento, el cofundador y científico jefe de OpenAI, Ilya Sutskevi Ver, del diálogo público entre Yilya Sutsk y Huang Renxun el segundo día después de la conferencia GPT-4, de hecho, OpenAI ha tenido durante mucho tiempo el conocimiento de grandes modelos y grandes datos para realizar inteligencia, y Transformer, la arquitectura es Muy adecuado para grandes potencias informáticas, por lo que OpenAI lo adoptó naturalmente.
A juzgar por la situación de desarrollo actual, OpenAI parece querer convertir la red neuronal en una inteligencia artificial real. El primero es entrenar el modelo de red neuronal del texto, que recopila una gran cantidad de datos de texto de varios canales, como Internet. La naturaleza de estos datos de texto es Lo anterior es una especie de mapeo del mundo. OpenAI quiere que el modelo comprenda el mundo a través de esta capa de relación de mapeo y luego propone un modelo multimodal en GPT-4, que puede no solo procesa texto, sino también procesa imágenes.El propósito de OpenAI es dotar al modelo de capacidad visual humana, para que pueda comprender el mundo desde la dimensión de la fusión y el mapeo de la visión y el texto.
Tabla 1: Tiempo de liberación, volumen de parámetros y volumen de entrenamiento de GPT en el pasado
| Modelo | tiempo de liberación | capas | recuento de cabezas | longitud del vector de palabra | Cantidad de parámetros | La cantidad de datos previos al entrenamiento. |
|---|---|---|---|---|---|---|
| GPT-1 | junio 2018 | 12 | 12 | 768 | 117 millones | alrededor de 5 GB |
| Base BERT/grande | octubre 2018 | 24/12 | 12/16 | 110 millones/340 millones | ||
| GPT-2 | febrero 2019 | 48 | - | 1600 | 1,5 mil millones | 40GB |
| GPT-3 | mayo 2020 | 96 | 96 | 12888 | 175 mil millones | 45TB |
| GPT3.5 | ||||||
| Llama | febrero 2023 | 7 mil millones/13 mil millones/33 mil millones/65 mil millones | 4,5 TB | |||
| Llama-2 | julio 2023 | 7 mil millones ~ 70 mil millones | 6,3 TB |
GPT
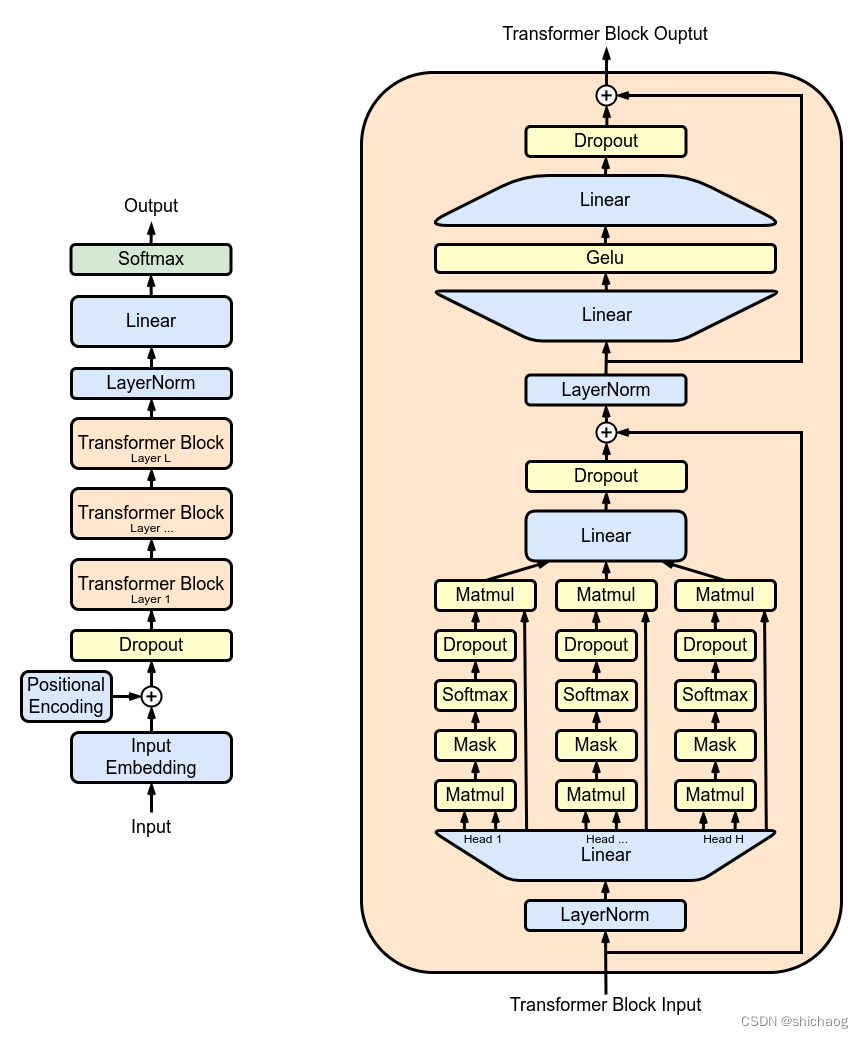
GPT, o Transformador preentrenado generativo, es un modelo preentrenado basado en la parte decodificadora de la estructura Transformer propuesta por Google en 2017 como infraestructura modelo. Transformer es una nueva arquitectura de red neuronal basada en el mecanismo de autoatención propuesto por Google. En la actualidad, la dirección del procesamiento del lenguaje natural adopta básicamente esta arquitectura. La ventaja de esta arquitectura es que abandona por completo la estructura de bucle tradicional y la reemplaza con Atención: El mecanismo de fuerza se utiliza para calcular representaciones implícitas de la entrada y salida del modelo. Si no está familiarizado con la estructura de Transformer, consulte el artículo del blog "".
Los artículos publicados actualmente incluyen texto de preentrenamiento GPT-1, GPT-2, GPT-3, chatGPT, GPT-4 es un modelo multimodal (a julio de 2023, no hay ningún documento oficial) e imágenes de preentrenamiento iGPT. . El modelo de lenguaje grande de OpenAI fue originalmente uno de muchos modelos de lenguaje, y no llamó la atención en absoluto hasta el lanzamiento de GPT-3, lo que hizo que la industria se diera cuenta de que el modelo es lo suficientemente grande como para lograr tanto memoria como generalización.
GPT utiliza la estructura del Decodificador de Transformer y realiza algunos cambios en el Decodificador del Transformador. El Decodificador original contiene dos estructuras de Atención de múltiples cabezales, y GPT solo retiene la Atención de múltiples cabezales de la Máscara, como se muestra en la figura siguiente.
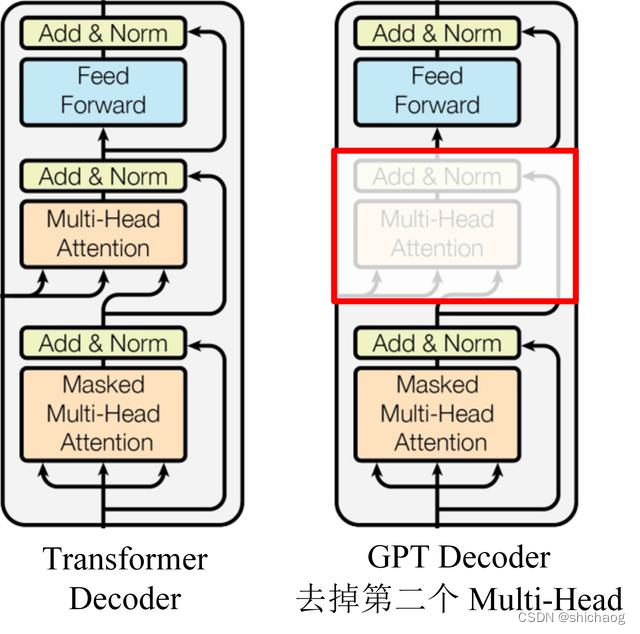
GPT utiliza secuencias de oraciones para predecir la siguiente palabra, por lo que se utiliza Mask Multi-Head Attention para cubrir el contexto de las palabras y evitar la fuga de información. Por ejemplo, dada una oración que contiene 4 palabras [A, B, C, D], GPT necesita usar A para predecir B, usar [A, B] para predecir C y usar [A, B, C] para predecir D . Si usa A para predecir B, debe enmascarar [B, C, D].
¿Por qué GPT solo usa la parte del Decodificador? El modelo de lenguaje usa lo anterior para predecir la siguiente palabra, porque el Decodificador usa la autoatención múltiple enmascarada para enmascarar el contenido detrás de la palabra, por lo que el Decodificador es un modelo de lenguaje listo para usar. Y debido a que no se utiliza el codificador, no es necesario prestar atención al codificador-decodificador.
GPT 1-3
El proceso de entrenamiento de GPT-1 es un entrenamiento previo no supervisado y un ajuste fino supervisado. Primero, se entrena previamente un modelo general y luego se ajusta en cada subtarea, lo que reduce la molestia de personalizar el modelo de diseño para cada tarea en métodos tradicionales. .
Después de entrenar previamente el modelo del transformador, no importa cómo cambie la subtarea, el modelo en sí no cambia, sino que ajusta la capa de entrada frontal y la capa de salida posterior.
Las estructuras de los modelos GPT-1 y GPT-2 son similares, excepto que tanto el modelo GPT-2 como el conjunto de datos son más grandes (Tabla 1). GPT-2 propone el concepto de entrenamiento multitarea y tiro cero, la idea de que "todo el aprendizaje supervisado es un subconjunto del modelo de lenguaje no supervisado", que es el predecesor del Prompt Learning. Las noticias generadas por GPT-2 son suficientes para engañar a la mayoría de los seres humanos y lograr el efecto de falsedad, y muchos portales también han ordenado prohibir el uso de noticias generadas por GPT-2.
El efecto de GPT-3 supera con creces al de GPT-2. GPT-3 introduce el concepto de pocos disparos. GPT-3 introduce el concepto de un transformador disperso de autoatención dispersa. Puede entenderse como un transformador disperso de autoatención más eficiente. capa de atención Excepto Además de poder completar tareas comunes de PNL, también puede escribir código en lenguajes como SQL y JavaScript, y también tiene un buen rendimiento en operaciones matemáticas simples. El entrenamiento de GPT-3 utiliza el aprendizaje en contexto, que es un tipo de metaaprendizaje. La idea central del metaaprendizaje es encontrar un rango de inicialización adecuado a través de una pequeña cantidad de datos, para que el modelo pueda acelerarse. Se ajusta a un conjunto de datos limitado y logra buenos resultados. En comparación con GPT-2, el modelo y los parámetros de GPT-3 son más grandes, lo que también mejora la comprensión de la industria de los modelos de lenguaje "grandes" desde la comprensión hasta la etapa de acción.
GPT-3 utiliza casi todos los datos de texto en Internet como corpus de entrenamiento, y los datos de entrenamiento filtrados alcanzan los 500 mil millones de palabras, de las cuales los enormes datos de Wikipedia solo representan el 0,6%.
GPT-3 también ha recibido algunas críticas, porque el modelo de preentrenamiento se entrena en un modelo con una gran cantidad de parámetros a través de datos masivos. Dado que los datos de entrenamiento masivo no se han limpiado manualmente, habrá datos falsos y sesgados. Inútiles, dañinos, no acordes con los valores humanos y muestras de entrenamiento malvadas, por lo que nadie puede garantizar que el modelo de preentrenamiento no genere respuestas similares. Esta es la motivación para InstructGPT y ChatGPT. El documento los resume con 3H La optimización objetivos, a saber, alta calidad, parecidos a los humanos y de alta diversidad.
Los documentos técnicos publicados por OpenAI en esta etapa son los siguientes:
2018 GPT-1 "Mejorar la comprensión del lenguaje con aprendizaje no supervisado" "Mejorar la comprensión del lenguaje mediante entrenamiento previo generativo"
2019 GPT-2 "Los modelos de lenguaje son estudiantes multitarea sin supervisión"
2020 GPT- 3/chatGPT "Los modelos de lenguaje aprenden con pocas posibilidades"
2022 InstructGPT (es el modelo de preparación de GPT-4, por lo que también se llama GPT-3.5) "Entrenamiento de modelos de lenguaje para seguir instrucciones con retroalimentación humana"
BERT
Documento: https://arxiv.org/abs/1810.04805
El nombre completo de BERT es Representación de codificador bidireccional de Transformers (representación de codificación bidireccional de Transformers). El modelo de lenguaje de procesamiento de lenguaje natural previo al entrenamiento no supervisado propuesto por Google en el documento "Preentrenamiento de transformadores bidireccionales profundos para la comprensión del lenguaje" es Modelos de lenguaje de procesamiento de lenguaje natural en los últimos años Modelos de hitos aceptados por dominio.
El modelo BERT es un modelo de procesamiento de lenguaje natural compuesto por un modelo de lenguaje pre-entrenado y que utiliza el modo de ajuste fino para resolver tareas posteriores. Ese año, logró resultados de última generación en 11 tareas de PNL, incluidas tareas en los campos de NER y respuesta a preguntas.
La innovación de BERT es que el Transformer Decoder (incluida la Masked Multi-Head Attention) se utiliza como extractor y se utiliza el método de entrenamiento de máscara coincidente. BERT utiliza una estructura de codificación dual y, por lo tanto, no tiene la capacidad de generar texto, pero BERT utiliza toda la información contextual de cada palabra en el proceso de codificación del texto de entrada, en comparación con un codificador unidireccional que solo puede usar pre-codificación. Ordenar información para extraer semántica. La capacidad de extracción de información semántica de BERT es más fuerte.
Introducción al proceso de formación de InstructGPT
Este modelo se basa en GPT-3 y se propuso debido a las críticas a GPT-3. Esto se deriva de un artículo de 2022. Muchos modelos de lenguaje grandes posteriores, ya sean de código abierto o de código cerrado, utilizan RLHF (aprendizaje por refuerzo). A partir de comentarios humanos), este modelo es al menos un modelo de ajuste fino basado en GPT-3.
SFT y el aprendizaje por refuerzo hacen que este modelo esté disponible comercialmente. Es uno de los núcleos. Aquí hay una breve introducción. Consulte el siguiente artículo para obtener más detalles.

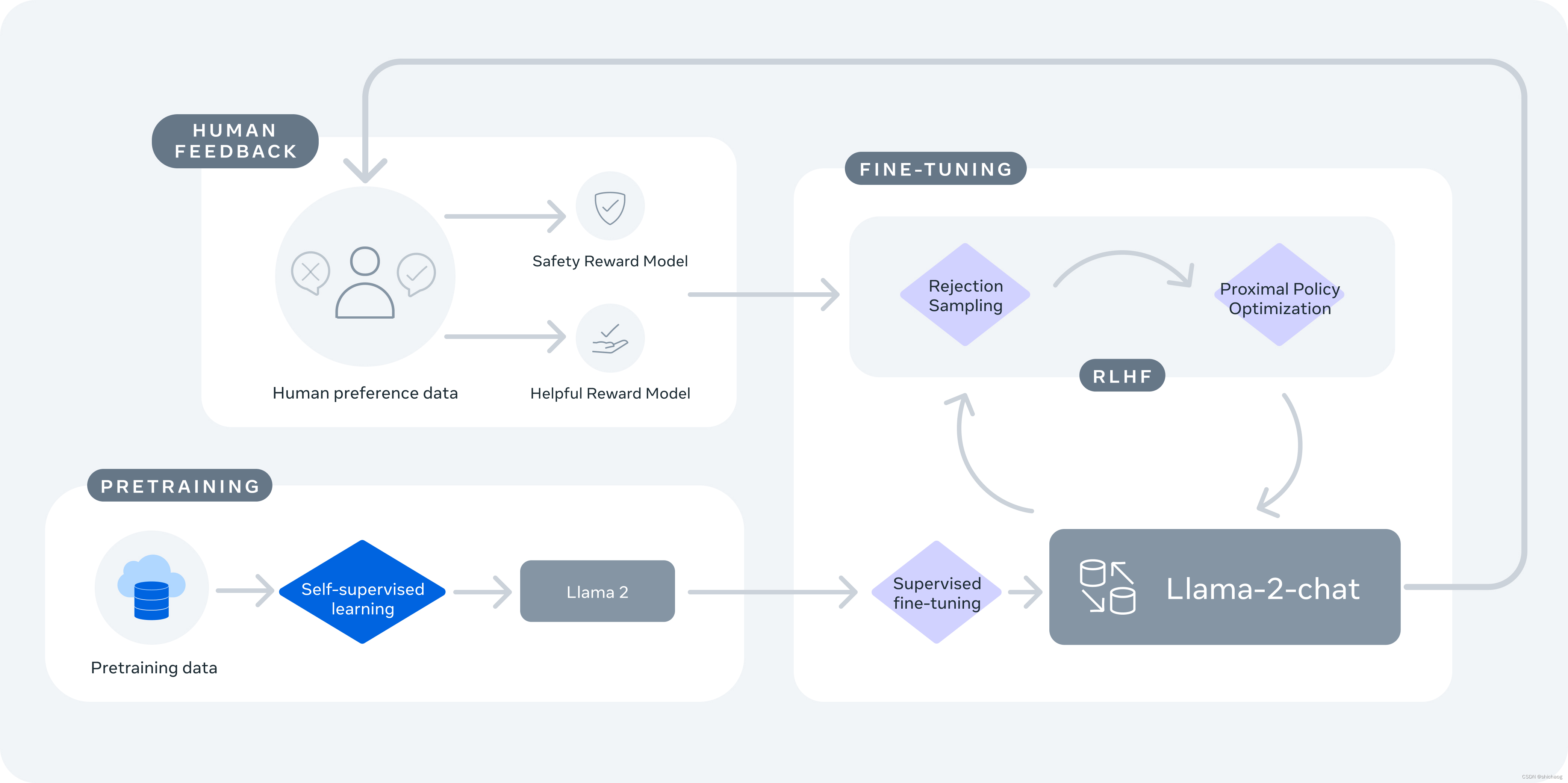
El proceso de capacitación completo se muestra en la figura anterior, donde el entrenamiento previo en la primera columna de la izquierda es el modelo GPT-3 de aprendizaje autosupervisado, y el aumento de Instruct en InstructGPT se encuentra en los siguientes tres pasos. Esto también es algo que muchos estudiantes de doctorado en laboratorios sin recursos económicos están investigando y, por supuesto, muchas empresas también están investigando. Las empresas poderosas quieren hacerse cargo de estas cuatro partes.
ChatGPT e InstructGPT son iguales en términos de estructura del modelo y métodos de entrenamiento. Ambos utilizan el aprendizaje por instrucción (Instruction Learning) y el aprendizaje por refuerzo con retroalimentación humana (Reinforcement Learning from Human Feedback, RLHF) para guiar el entrenamiento del modelo. La única diferencia es la recopilación de datos difieren en la forma.
El resultado del aprendizaje autosupervisado a veces es perjudicial y el costo del aprendizaje supervisado completamente etiquetado bajo ciertas condiciones, la respuesta es segura, el techo no es alto, pero el aprendizaje por refuerzo no es así, ya no hay etiquetas artificiales, no hay Respuesta correcta, solo lo bueno es mejor que lo malo La respuesta se realiza mediante puntuación, por lo que el aprendizaje por refuerzo es una de las técnicas que se deben utilizar para los modelos mejor clasificados en Huggingface.
El proceso de ajuste anunciado por OpenAI se divide principalmente en tres partes:
1. Aprendizaje de ajuste fino supervisado (SFT), que recopila un conjunto de datos sobre cómo genera el modelo esperado escrito artificialmente y lo utiliza para entrenar un modelo generativo (GPT3). .5 -based)
2. Entrene el modelo de recompensa (RM) y recopile un conjunto de datos ordenados entre múltiples salidas del modelo anotado manualmente. Y entrenar un modelo de recompensa para predecir qué salida del modelo prefiere el usuario
3. Generar de forma iterativa y continua el modelo basado en el aprendizaje por refuerzo (PPO). Utilice este modelo de recompensa como función de activación para ajustar el modelo generativo entrenado mediante aprendizaje supervisado.
El proceso se muestra en la siguiente figura que se encuentra en el sitio web oficial.
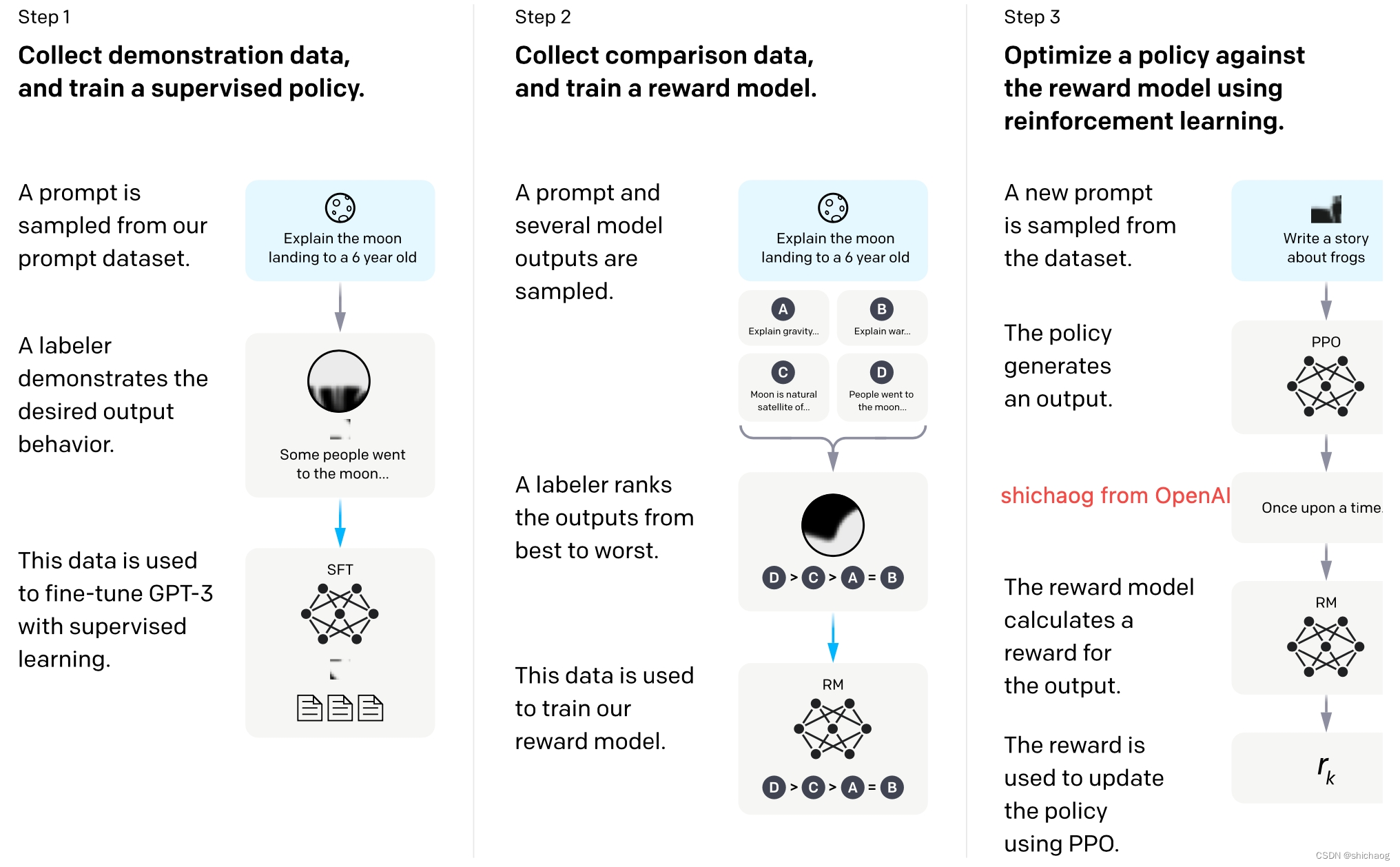
El modelo es muy importante y los datos también son muy importantes: los datos del ajuste fino de tres pasos son los siguientes:
La razón por la que se necesita el modelo SFT: es posible que el modelo GPT3 no necesariamente pueda generar respuestas de acuerdo con instrucciones humanas, que sean útiles y seguras, y requiere el etiquetado manual de los datos para su ajuste.
La razón por la que se necesita el modelo RM: el etiquetado discriminativo de la clasificación de etiquetas, el costo es mucho menor que el etiquetado generativo de generar respuestas.
La razón para necesitar el modelo RL: al ajustar el modelo SFT, la distribución de las respuestas generadas también cambiará, lo que provocará desviaciones en la puntuación del modelo RM y se requiere aprendizaje por refuerzo.
En primer lugar, debemos recopilar conjuntos de preguntas y conjuntos de indicaciones: los anotadores escriben estas preguntas, escriben algunas instrucciones y los usuarios envían algunas preguntas para las que desean obtener respuestas. Primero entrene un modelo más básico, pruébelo para los usuarios y, al mismo tiempo, continúe recopilando las preguntas enviadas por los usuarios. Al dividir el conjunto de datos, se divide según la ID del usuario, porque el problema del mismo usuario será similar y no es adecuado que aparezca en el conjunto de entrenamiento y en el conjunto de verificación al mismo tiempo.
conjunto de datos SFT
GPT-3 es un modelo generativo basado en el aprendizaje rápido, por lo que el conjunto de datos SFT también es una muestra compuesta por pares de respuesta rápida. Parte de los datos SFT provienen de PlayGround de OpenAI y la otra parte es el estándar de 40 personas contratadas por OpenAI y 40 En muchos casos, el etiquetado de alta calidad es un requisito previo para el entrenamiento del modelo. En este conjunto de datos, el contenido del trabajo del etiquetador es escribir instrucciones basadas en el contenido, y las instrucciones escritas deben cumplir con los siguientes tres puntos:
- Tarea simple: los anotadores asignan cualquier tarea simple, al tiempo que garantizan la diversidad de tareas;
- Tarea de pocas posibilidades: el anotador proporciona una instrucción y múltiples pares de consulta-respuesta de la instrucción;
- Relacionado con el usuario: obtenga casos de uso de la interfaz y permita que los anotadores escriban instrucciones basadas en esos casos de uso;
13 000 datos. Los anotadores escriben respuestas directamente a las preguntas del conjunto de preguntas de ahora. Por lo general, esta etapa requiere decenas de miles de datos etiquetados de alta calidad.
conjunto de datos RM
El conjunto de datos de RM se utiliza para entrenar el modelo de recompensa en el segundo paso. El objetivo de la recompensa es alinear las evaluaciones humanas, y esta recompensa se proporciona mediante puntuación manual, porque la inteligencia artificial puede otorgar calificaciones más bajas a elementos dañinos, inútiles, sesgados y etc., lo que dificulta que el modelo genere esos contenidos. El método de Instruct GPT/ChatGPT es dejar que el modelo genere de 4 a 10 respuestas a la misma pregunta y luego ordenar manualmente estas respuestas generadas de buenas a malas. 33000 datos. Los anotadores clasifican las respuestas.
Su artículo InstructGPT muestra cómo funciona este proceso.

conjunto de datos de PPO
El aprendizaje por refuerzo guía el entrenamiento del modelo a través del mecanismo de recompensa, que puede considerarse como la función de pérdida del mecanismo de entrenamiento del modelo tradicional. El cálculo de la recompensa es más flexible y diverso que la función de pérdida (la recompensa de AlphaGO es el resultado del juego), y el costo de esto es que el cálculo de la recompensa no es derivable, por lo que no se puede utilizar directamente para la retropropagación. La idea del aprendizaje por refuerzo es ajustar la función de pérdida muestreando una gran cantidad de recompensas para lograr el entrenamiento del modelo. De manera similar, la retroalimentación humana no es derivable, por lo que también podemos usar la retroalimentación artificial como recompensa por el aprendizaje por refuerzo, y así nació el aprendizaje por refuerzo basado en la retroalimentación humana.
RLHF se remonta al "Aprendizaje por refuerzo profundo a partir de preferencias humanas" publicado por Google en 2017. Utiliza anotaciones manuales como retroalimentación para mejorar el rendimiento del aprendizaje por refuerzo en robots simulados y juegos de Atari.
PPO (Optimización de políticas próximas) es un nuevo tipo de algoritmo de gradiente de políticas. Este algoritmo es muy sensible al tamaño del paso, pero es difícil dar un tamaño de paso adecuado. Si la diferencia entre las políticas antiguas y nuevas durante el proceso de capacitación es Demasiado grande, no favorece el aprendizaje. El algoritmo PPO propone una nueva función objetivo que puede actualizar lotes pequeños en múltiples pasos de entrenamiento, lo que resuelve el problema de que el tamaño del paso en el algoritmo de gradiente de políticas es difícil de determinar.
El conjunto de datos PPO de InstructGPT no está marcado y proviene de la API de usuario de GPT-3. 31000 datos. Solo se necesitan las preguntas del conjunto de indicaciones, no se requiere etiquetado. Porque la anotación en este paso la califica el modelo RM. 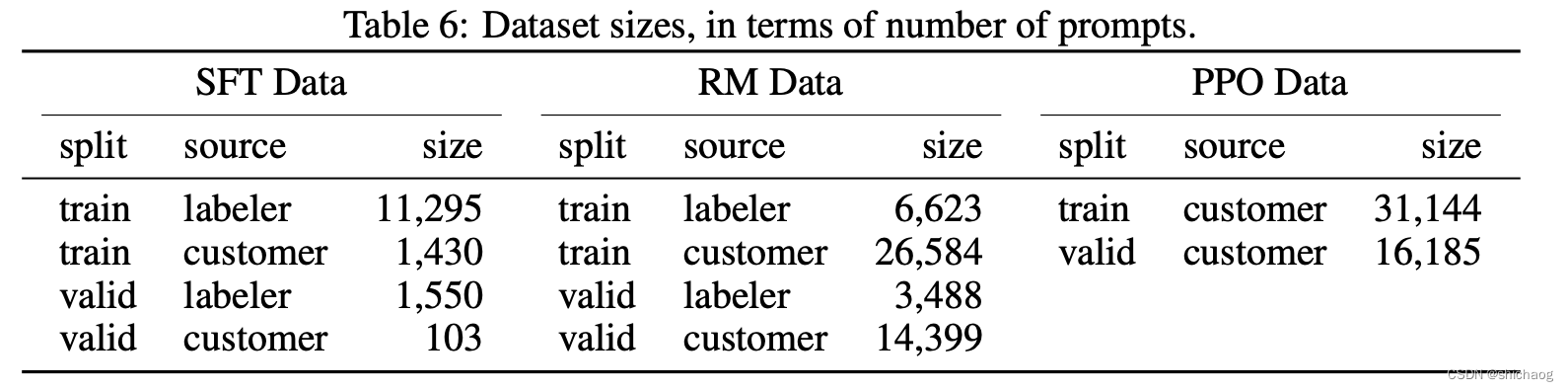
El 96% del conjunto de datos está en inglés y menos del 4% de los otros 20 idiomas. El proceso completo desde el preentrenamiento hasta el aprendizaje por refuerzo es el siguiente:
GPT-4
Para que la red neuronal comprenda mejor el mundo y, por tanto, sea más inteligente, la capacidad visual parece ser una capacidad indispensable.
La multimodalidad, aprendiendo de texto e imágenes, puede responder a solicitudes de entrada de texto e imágenes, y las imágenes pueden mejorar la red neuronal, lo que ampliará enormemente su utilidad, porque los humanos son animales visuales y un tercio de la corteza cerebral humana. Uno para el procesamiento visual.
En comparación con ChatGPT, GPT-4 ha alcanzado el nivel humano en muchos aspectos, como GRE, abogado, médico y otros exámenes, GPT-4 puede predecir la siguiente palabra con mayor precisión que ChatGPT, lo que significa que el modelo tendrá más comprensión, en Además, el modelo afina algunas imágenes de alta calidad mediante variantes de aprendizaje por refuerzo.
Modelo de lenguaje grande de código abierto Llama
El código fuente de Llama de Meta es un modelo de lenguaje grande de código abierto. El documento oficial principal tiene los siguientes dos artículos. La estructura del Transformer no ha cambiado mucho, pero el rendimiento de su LLaMA-13B es mejor que el GPT-3 (175B) de OpenAI. lo cual es suficiente Un modelo que es más de diez veces más pequeño es comparable a un modelo con 175 mil millones de parámetros.
《LLaMA: Modelos de lenguaje básico abiertos y eficientes》
《LLama 2: Modelos de lenguaje básico abierto y afinados》
| conjunto de datos previo al entrenamiento | parámetros del modelo | estructura del modelo | licencia | longitud del texto | atención de consultas agrupadas (GQA) | Fichas | A100-80GB 400W entrenamiento/tiempo requerido | optimizador | |
|---|---|---|---|---|---|---|---|---|---|
| Llama | 4,5 TB | 6,3 mil millones, 13 mil millones, 32,5 mil millones, 62,5 mil millones | Transformadores autorregresivos | investigación | 2k | 6.3B, 13B/1,0T; 33B, 65B/1,4T | 7B 82.432h 13B 135.168h 33B 530.432h 65B 1.022.362h | AdamW | |
| LLaMA-2/LlaMA-2-chat | 6,3 TB (aumento del 40 % en comparación con LLaMA) | 6.3B, 13B y 70B | Transformadores autorregresivos | investigacion y comercial | 4k | 34B/70B | 2.0T | 7B 184.320h 13B 368.640h 70B 1.720.320h |
El modelo de parámetros LLaMA 65B utiliza 2048 GPU A100 para obtener el modelo de preentrenamiento después de 21 días de entrenamiento, cuyo proceso de preentrenamiento costó alrededor de 5 millones de dólares estadounidenses.
Llama-2 primero utiliza capacitación con información de texto disponible públicamente, luego usa SFT para realizar ajustes finos y luego usa aprendizaje por refuerzo a partir de retroalimentación humana (RLHF) para refinar. RLHF incluye muestreo de rechazo y optimización de políticas próximas (PPO).
Llama-2-chat utiliza RLHF (aprendizaje por refuerzo a partir de comentarios humanos) para garantizar la seguridad y la utilidad. LlaMA-2-chat es el resultado de varios meses de investigación y aplicaciones iterativas, incluido el ajuste de instrucciones, RLHF, potencia informática y recursos de anotación.
La dirección de los grandes modelos lingüísticos en el futuro.
La "inteligencia" proviene de los datos, la potencia informática y la estructura del modelo. Los resultados del modelo se desarrollan en dos direcciones: instrumentalización y humanización inteligente.
1. El primero son los datos: en unos años, los datos públicos en Internet se rastrearán para el entrenamiento del modelo, y es muy probable que los datos generados por el nuevo modelo de lenguaje se rastreen y luego se ingresen en el modelo. ¿Esta es la causa por la que el modelo se atascó en el autorrefuerzo? Parece que el modelo en sí también requiere resultados del modelo de lenguaje grande e inverso.
2. Según la arquitectura RLHF existente, existen los siguientes problemas:
a. El proceso de ajuste fino es un proceso de sellar la función del modelo, no un proceso de creación de la nada, por lo que la capacidad del modelo aún Depende del ajuste, lo que reducirá las tareas generales de degradación del rendimiento de la PNL.
b. El valor de salida del modelo cumple con la escena específica del modelo;
c. El costo del etiquetado manual es relativamente alto y el aprendizaje por refuerzo InstructGPT emplea a 40 personas para la capacitación.
3. La forma de preentrenamiento + ajuste fino de modelos grandes seguirá existiendo, pero tanto el preentrenamiento como el ajuste fino evolucionarán. La dirección de la evolución de los modelos grandes radica en el procesamiento general de tareas, mientras que el fino -El ajuste aún necesita ir más allá, además de apuntar a escenarios específicos, reducir el umbral y el costo del ajuste fino, como LoRA.
Aprendizaje de disparo cero | Aprendizaje de un disparo | Aprendizaje de pocos disparos es un método de aprendizaje propuesto debido a los datos etiquetados limitados o al costo.
4. La función de costo utilizada por el método PPO no representa preferencias humanas flexibles, por lo que es más fácil lograr avances con esta dirección del algoritmo que otros módulos; 5. El método actual
de RLHF tiende a tener la misma preferencia para todos Salida de probabilidad, pero Las preferencias de las personas son diversas, lo que significa que el supuesto de la misma probabilidad de preferencia no se cumple. Por eso ahora las respuestas generadas no son tan agradables a la vista. Por ejemplo, cuando miras las noticias, el diseño del editor de noticias determina lo que ve la audiencia, pero después de que Toutiao recopila las preferencias personales, todos ven cosas diferentes, es decir, la probabilidad de la misma recomendación para diferentes personas es diferente.
6. En la etapa SFT, se deben entrenar todos los parámetros (aunque el tiempo de capacitación se puede acortar), pero esto no es amigable para los laboratorios de secundaria y las empresas de nueva creación. Se necesita SFT con 2 o 4 tarjetas A100, por lo que es basado en la parte congelada, como los parámetros (LoRA), solo la iteración de relativamente pocos parámetros de ajuste fino será una dirección 7.
La PC al final implementará modelos localmente, modelos de lenguaje grande, modelos generativos de imágenes e IA integrada en herramientas. por lo tanto, cuantificación, SIMD, GPU, poda, etc., el método de optimización todavía se usa para intentar implementar al final
8. Además de la memoria y la capacidad de generalización hasta cierto punto, personalmente creo que ya tengo la percepción principal. lógica y capacidades de conciencia. Si es superior al 50%, es solo la lógica de la materia inorgánica, pero es un tipo de conciencia. Si está dotado de conciencia de supervivencia (es posible hasta cierto punto), lo hará también tienen conciencia de supervivencia. El modelo supergrande y la red neuronal multimodal ampliarán sus límites de aplicación en la percepción, la comprensión y el procesamiento general de tareas, y las aplicaciones de herramientas de IA generativa seguirán liderando. Una de las direcciones futuras es la verdadera "Homo sapiens" consciente.
*