Escriba el título del catálogo aquí
- Capítulo 1. Descripción general de Hadoop
- Capítulo 2 Construcción del entorno operativo Hadoop (enfoque de desarrollo)
- Capítulo 3 Modo de operación de Hadoop (Modo completamente distribuido: Enfoque de desarrollo)
-
- 3.1 Escriba el script de distribución del clúster xsync
- 3.2 Configuración de inicio de sesión sin contraseña SSH (después de la configuración, puede directamente "usuario ssh" para cambiar de usuario)
- 3.3 configuración de clúster
- 3.4 Prueba de clúster básica
- 3.5 Configurar el servidor de historial
- 3.6 Configurar el servidor de historial
- Capítulo 4 Resumen del método de inicio / detención de clúster
- Capítulo 5 Escritura de scripts comunes para clústeres de Hadoop
Capítulo 1. Descripción general de Hadoop
- Es una infraestructura de sistema distribuida
- La principal solución son los datos masivosalmacenamientoY datos masivosanálisis caculateproblema
- Características de Hadoop:Un monton、alta velocidad、Diverso、Densidad de valor bajo
- Ventajas de Hadoop (4 de alto):Alta fiabilidad、Alta escalabilidad、Alta eficiencia、Alta tolerancia a fallos
1.1 Análisis de procesos de negocio del departamento de Big Data, estructura organizativa del departamento (enfoque)

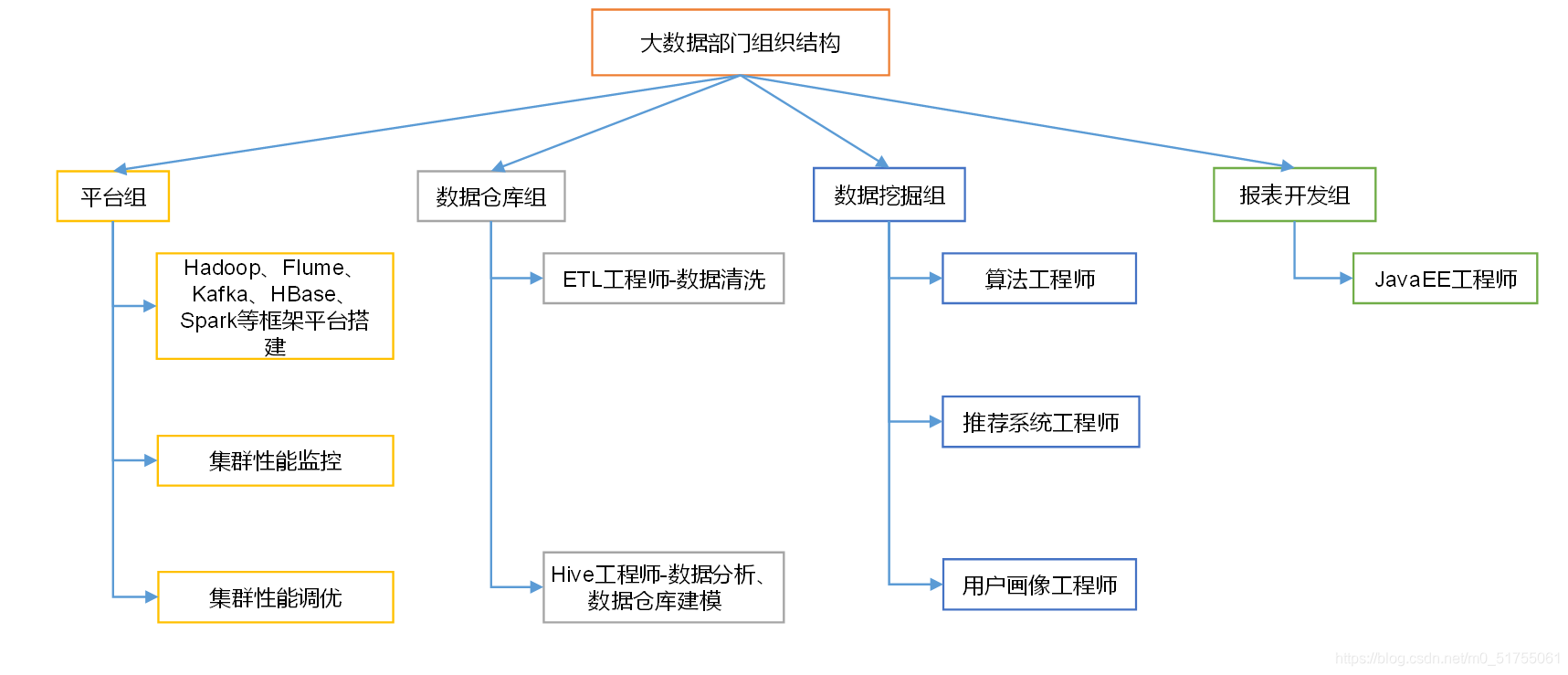
Grupo de plataformas : lo principal es recopilar datos. Asegurar el funcionamiento estable de cada marco, tecnología parcial
Grupo de almacenamiento de datos (alta demanda) :
- Limpieza de datos: a menudo realizada por pasantes
- Análisis de datos de ingenieros de HIVE, modelado de almacenamiento de datos: negocio parcial
Data Mining Group (buen desarrollo) : intente desarrollar en esta dirección
1.2 Composición de Hadoop (enfoque de entrevista)
Diferencias entre Hadoop 1.x, 2.xy 3.x
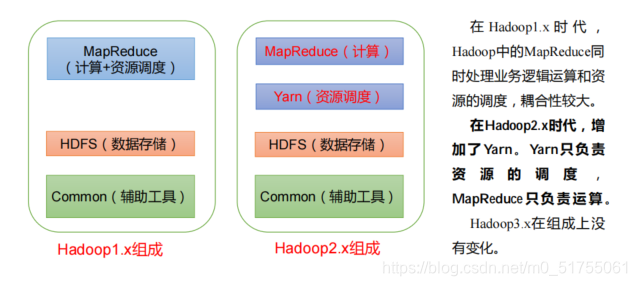
1.2.1 Arquitectura HDFS: sistema de archivos distribuido
NameNode (nn) 、 DataNode (dn) 、 SecondaryNameNode

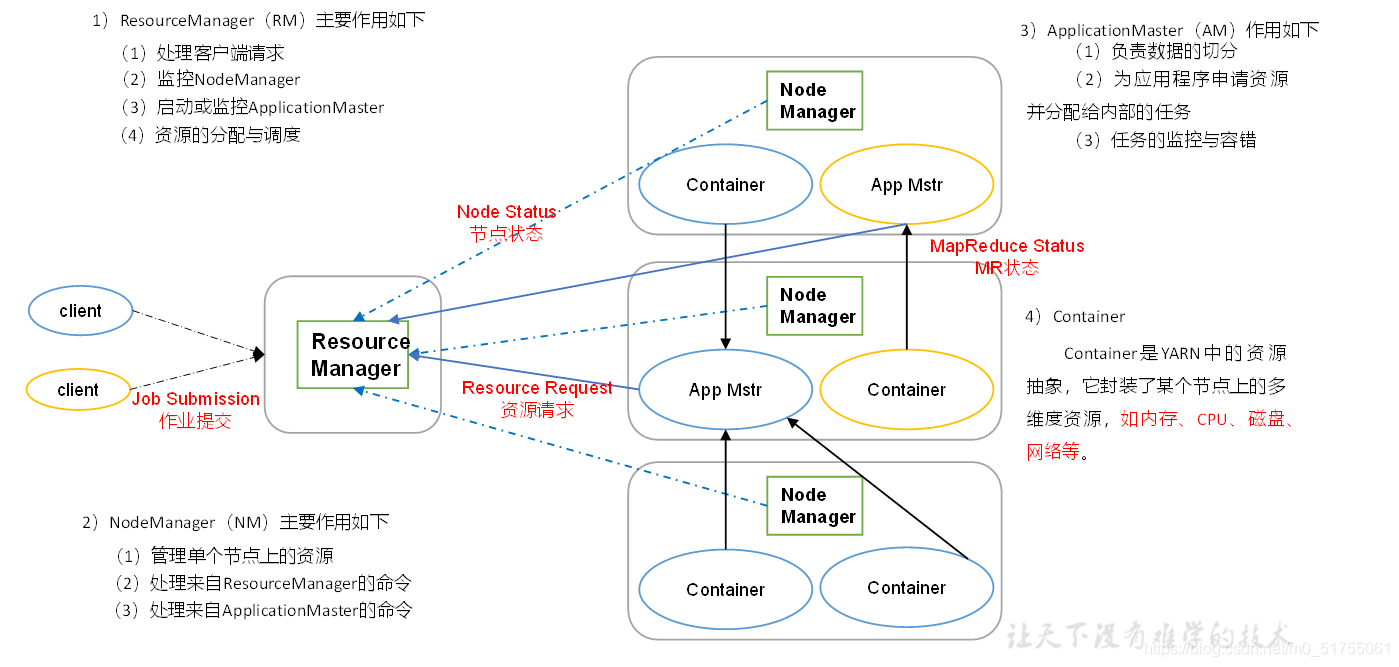
1.2.2 YARN: Administrador de recursos para Hadoop
- ResourceManager (RM): el jefe de todos los recursos del clúster (memoria, CPU, etc.)
- NodeManager (NM): jefe de recursos del servidor de un solo nodo (por lo que cada nodo debe implementarse)
- ApplicationMaster (AM): el jefe de una sola tarea
- Contenedor : un contenedor, que es un servidor bastante independiente, que encapsula los recursos necesarios para la operación de la tarea, comoMemoria, CPU, disco, redEsperar
1.2.3 Arquitectura MapReduce: Map (procesamiento de datos en paralelo) y Reduce (resumen de los resultados de los datos)
MapReduce divide el proceso de cálculo en dos etapas: Mapa y Reducir
- Procesamiento paralelo de datos de entrada en la etapa Mapa
- Resumir los resultados del mapa en la fase Reducir
1.3 Ecosistema tecnológico de Big Data
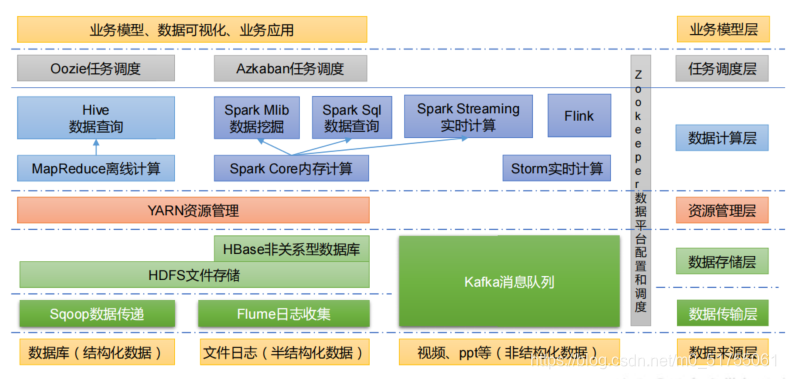
Los términos técnicos involucrados en la figura se estudiarán por separado más adelante.
1.4 Diagrama del marco del sistema recomendado
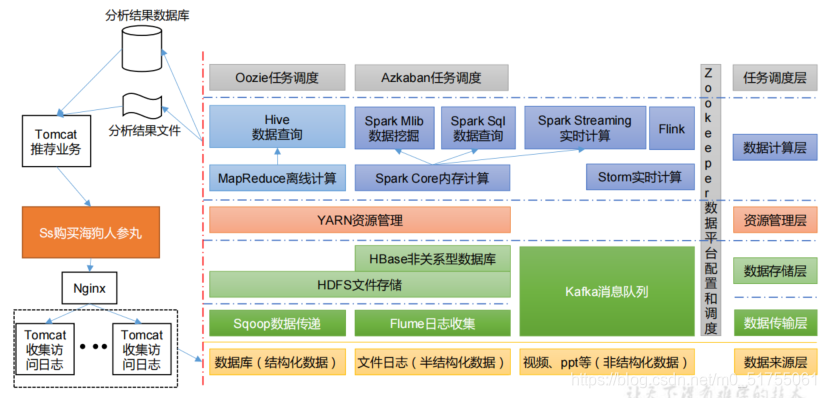
1.5 La relación entre HDFS, YARN y MapReduce
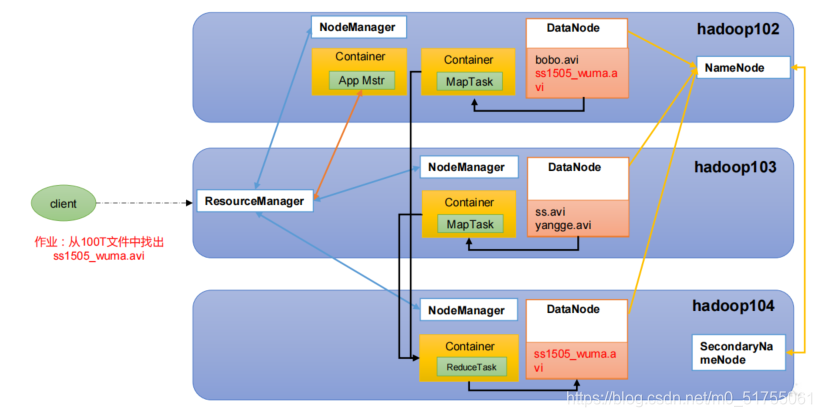
Capítulo 2 Construcción del entorno operativo Hadoop (enfoque de desarrollo)
2.1 Preparación del entorno de la máquina virtual
1. Clonar una máquina virtual
2. Modifique la IP estática de la máquina virtual clonada.
3. Modifique el nombre de host
4. Apague el firewall
- Cerrar: systemctl detener firewalld
- 开启 : systemctl deshabilita firewalld.service
5. Crear usuario atguigu
6. Configure el usuario atguigu para que tenga privilegios de root, lo cual es conveniente para agregar sudo para ejecutar comandos de privilegios de root más adelante.
[root@hadoop100 ~]# vim /etc/sudoers
Modifique el archivo / etc / sudoers,Debajo de la línea% ruedaAgregue una línea de la siguiente manera:
atguigu ALL=(ALL) NOPASSWD:ALL
7. Cree las carpetas del módulo y del software en el directorio / opt, y modifique el usuario y el grupo al
que pertenecen. Modifique el propietario y el grupo del módulo y las carpetas del software para que sean usuarios atguigu
[root@hadoop100 ~]# chown atguigu:atguigu /opt/module
[root@hadoop100 ~]# chown atguigu:atguigu /opt/software
8. Desinstale el JDK que viene con la máquina virtual
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e
--nodeps
9. Reinicie la máquina virtual
2.2 Clonar una máquina virtual (tome hadoop102 como ejemplo a continuación)
1. Utilice la máquina de plantilla hadoop100 para clonar tres máquinas virtuales: hadoop102 hadoop103 hadoop104
2. Modificar la IP estática de la máquina virtual clonada
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
Nota: Asegúrese de que la dirección IP y la dirección del editor de red virtual en el archivo ifcfg-ens33 del sistema Linux sean las mismas que la dirección IP de la red VM8 del sistema Windows.
3. Modificar el nombre de host de la máquina clon
[root@hadoop100 ~]# vim /etc/hostname
hadoop102
4. Configure el archivo de hosts de asignación de nombres de host de clon de Linux, abra / etc / hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
5. Reinicie la máquina de clonación hadoop102
6.Modificar el archivo de mapeo de host de Windows (archivo de hosts)
2.3 Instalar JDK en hadoop102
1. Desinstalar el JDK existente
Nota: Antes de instalar el JDK, asegúrese de eliminar el JDK que viene con la máquina virtual por adelantado.
2. Importe el JDK a la carpeta del software en el directorio opt
- Utilice la herramienta de transferencia Xftp
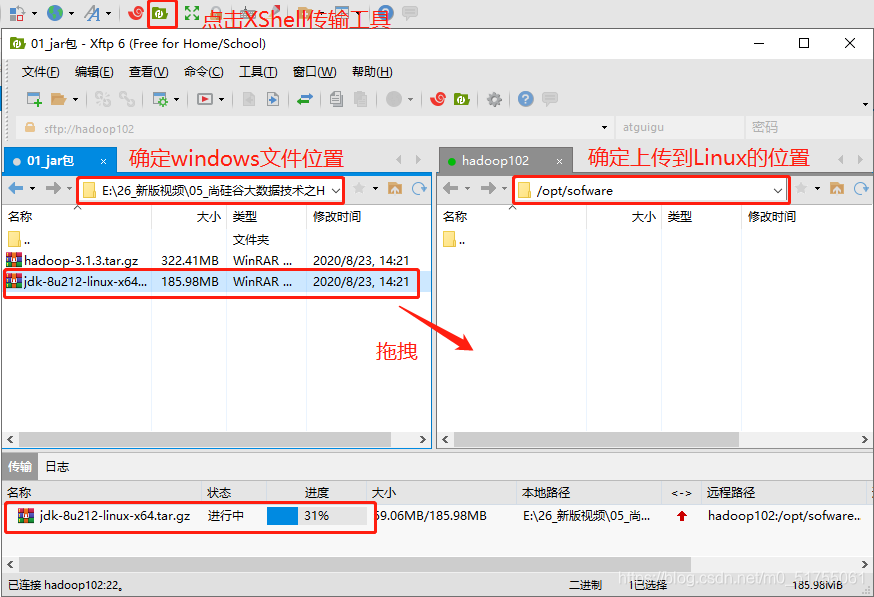
- SecureCRT o Xshelll, ingrese la ruta donde se necesita jdk, luego "alt + p" ingrese al modo sftp, seleccione jdk1.8 y arrástrelo en
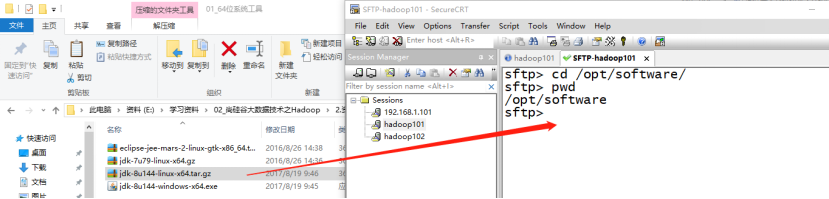
3. Descomprima el JDK en el directorio / opt / module
[atguigu@hadoop102 software]$ tar -zxvf jdk-8u212-linuxx64.tar.gz -C /opt/module/
4.Configurar las variables de entorno de JDK
Cree un nuevo archivo /etc/profile.d/my_env.sh
[atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
Nota: obtenga el archivo / etc / profile para que la nueva variable de entorno PATH surta efecto
[atguigu@hadoop102 ~]$ source /etc/profile
5. Pruebe si el JDK se instaló correctamente y luego reinicie
2.4 Instalar Hadoop en hadoop102
Pasos: básicamente lo mismo que instalar jdk, al configurar las variables de entorno, agregue lo siguiente al final del archivo my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
2.5 Estructura de directorios de Hadoop
[atguigu@hadoop102 hadoop-3.1.3]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5 月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5 月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5 月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5 月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5 月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5 月 22 2017 share
Catálogo importante

Capítulo 3 Modo de operación de Hadoop (Modo completamente distribuido: Enfoque de desarrollo)
Análisis:
1) Preparar 3 clientes (cerrar firewall, IP estática, nombre de host) 2) Instalar JDK
3) Configurar variables de entorno
4) Instalar Hadoop
5) Configurar variables de entorno
6) Configurar clúster
7) Inicio de un solo punto
8) Configurar ssh
9) Ensamblar y probar el clúster
3.1 Escriba el script de distribución del clúster xsync
1. Cree un archivo xsync en el directorio / home / atguigu / bin
[atguigu@hadoop102 opt]$ cd /home/atguigu
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 ~]$ cd bin
[atguigu@hadoop102 bin]$ vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
2. Modifique el script xsync para tener permisos de ejecución
[atguigu@hadoop102 bin]$ chmod +x xsync
3.Copie el script en / bin para que se pueda llamar globalmente
[atguigu@hadoop102 bin]$ sudo cp xsync /bin/
3.2 Configuración de inicio de sesión sin contraseña SSH (después de la configuración, puede directamente "usuario ssh" para cambiar de usuario)
1. Principio de inicio de sesión sin contraseña
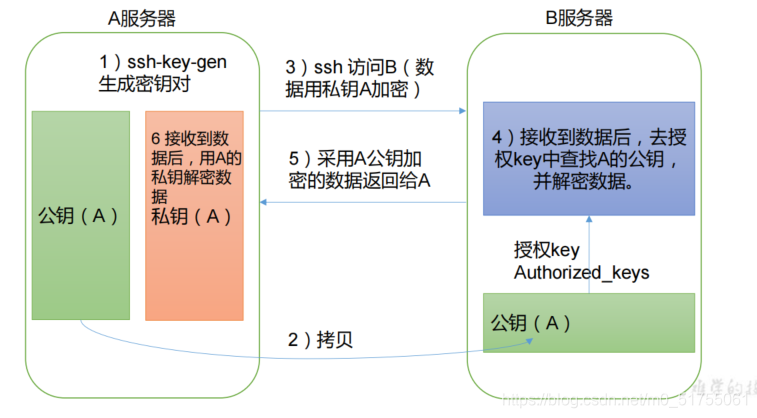
2.
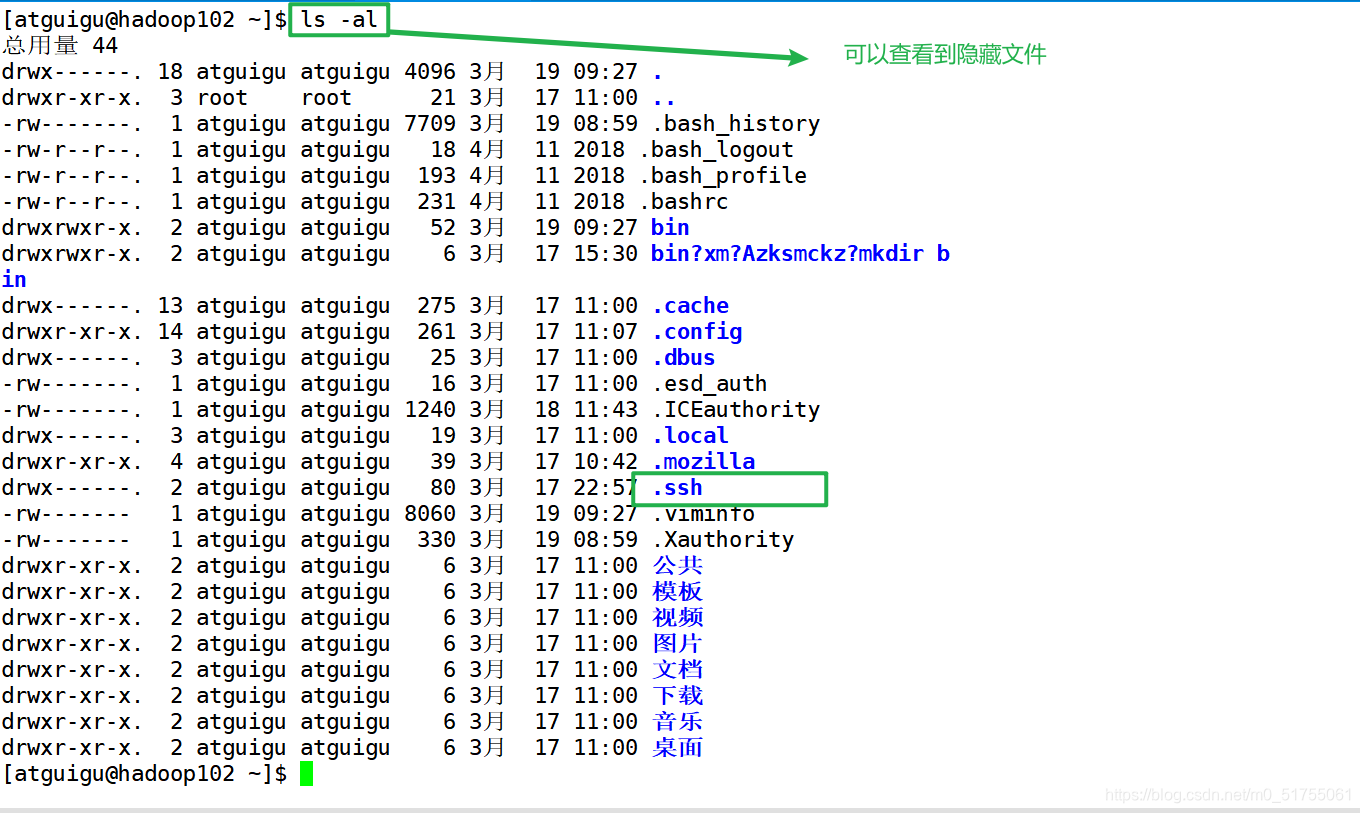
Explicación de la función de archivo en la carpeta .ssh (~ / .ssh) para generar claves públicas y privadas
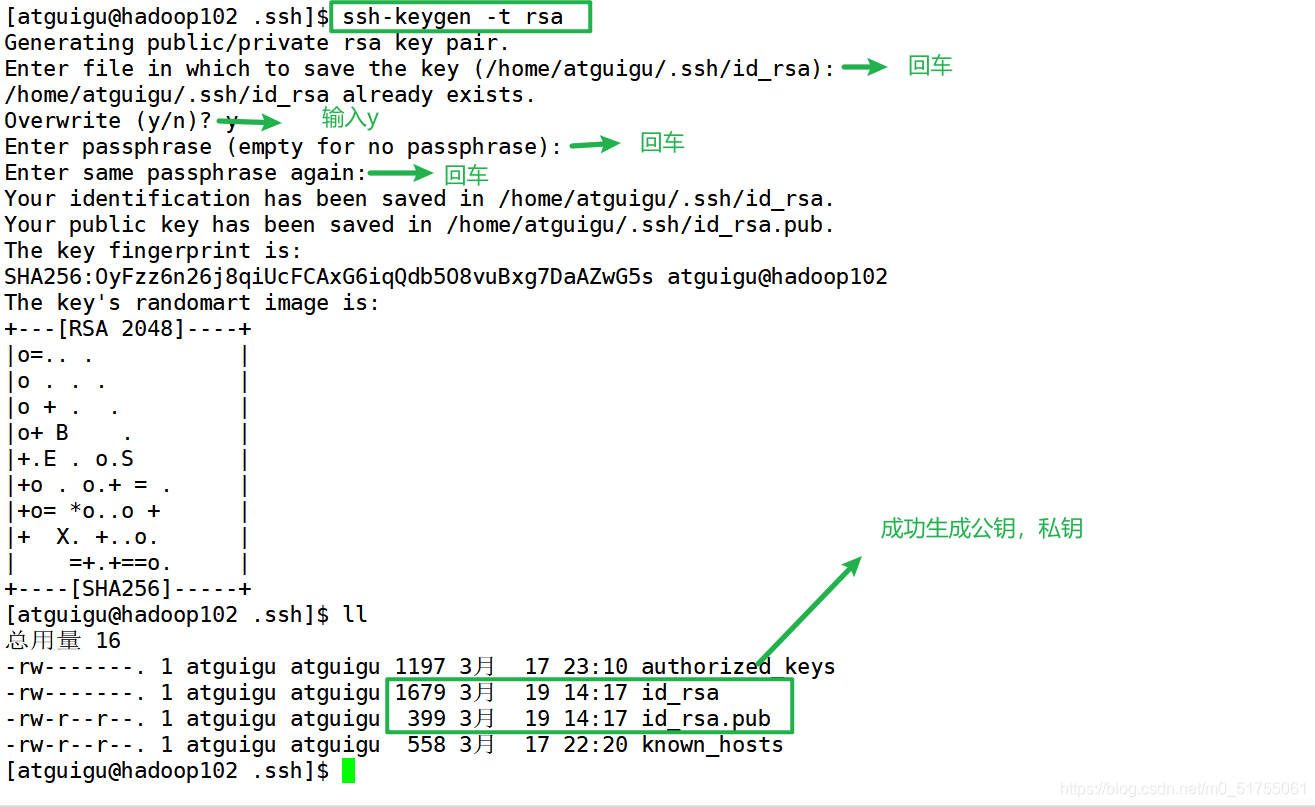
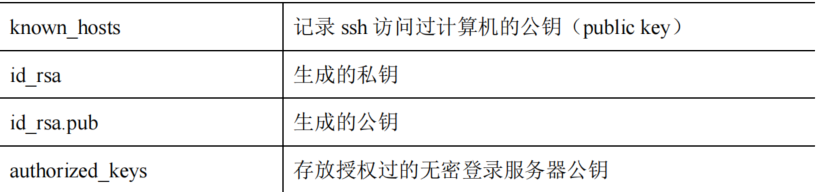
3. Copie la clave pública en la máquina de destino para iniciar sesión sin secreto
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
Nota: ¡Cada nodo debe hacer esto! ! ! , Y los usuarios son diferentes, si otros usuarios también necesitan configurar, use el mismo método
3.3 configuración de clúster
3.3.1 Planificación de la implementación del clúster
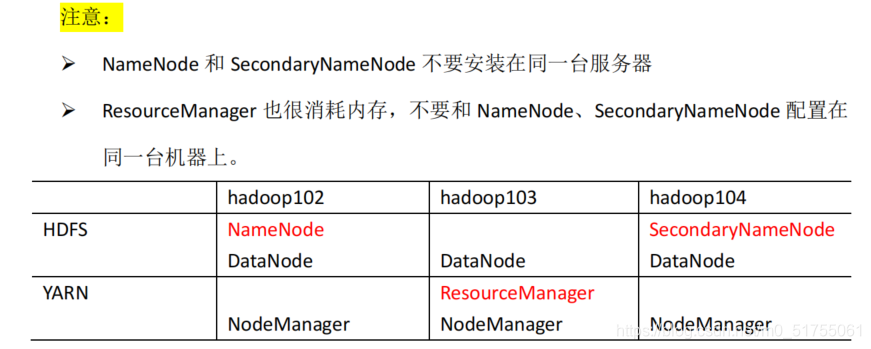
3.3.2 Declaración de configuración (core-site.xml, hdfs-site.xml, yarn-site.xml, mapped-site.xml)
- Los archivos de configuración de Hadoop se dividen en dos categorías: archivos de configuración predeterminados y archivos de configuración personalizados. Solo cuando los usuarios desean modificar un determinado valor de configuración predeterminado, deben modificar el archivo de configuración personalizado y cambiar el valor del atributo correspondiente.
- Archivo de configuración predeterminado : la ubicación donde se almacena el archivo en el paquete jar de Hadoop
- Archivo de configuración personalizado :core-site.xml 、 hdfs-site.xml 、 yarn-site.xml 、 mapred-site.xml
- Los cuatro archivos de configuración se almacenan en la ruta $ HADOOP_HOME / etc / hadoop, y el usuario puede modificar la configuración nuevamente de acuerdo con los requisitos del proyecto.
Distribuir el archivo de configuración de Hadoop configurado en el clúster
3.3.3 Configuración del clúster de grupo (iniciar varios nodos a la vez)
1. Configurar trabajadores
[atguigu@hadoop102 hadoop]$ vim /opt/module/hadoop-
3.1.3/etc/hadoop/workers
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
¡Recuerda sincronizar todos los nodos! !
2. Iniciar el clúster
- El clúster se inicia por primera vez y el NameNode debe formatearse en el nodo hadoop102
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
- Iniciar HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
- Configurado El nodo ResourceManager (hadoop103) inicia YARN
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
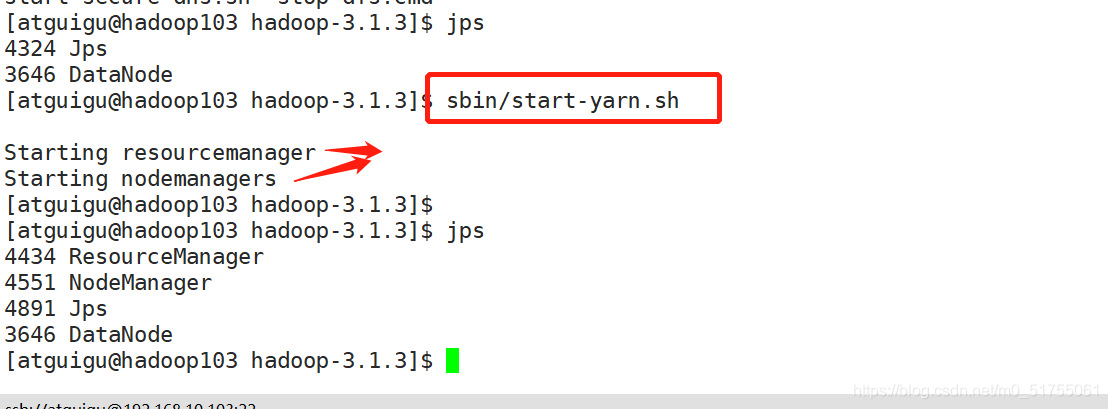
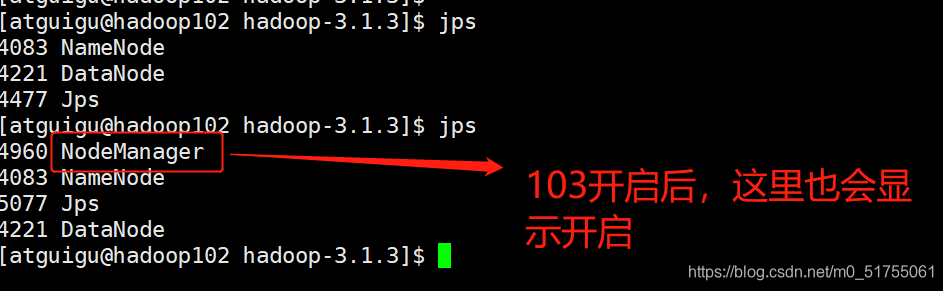
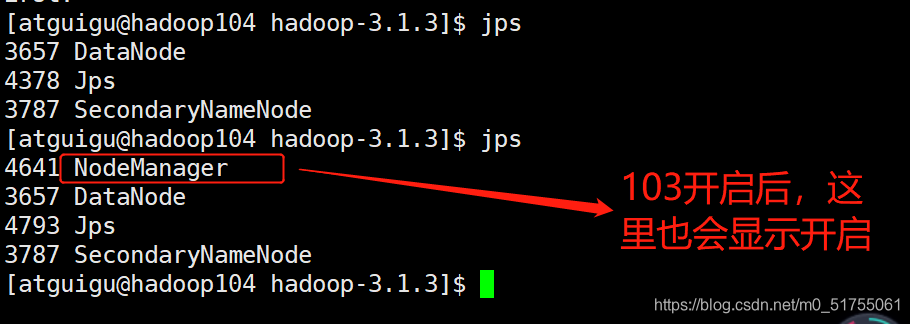
Prácticas capturas de pantalla
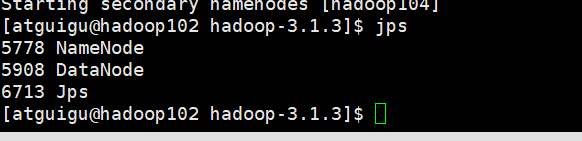

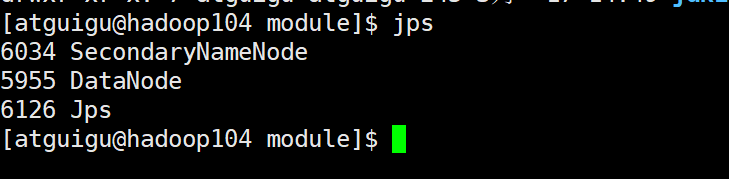
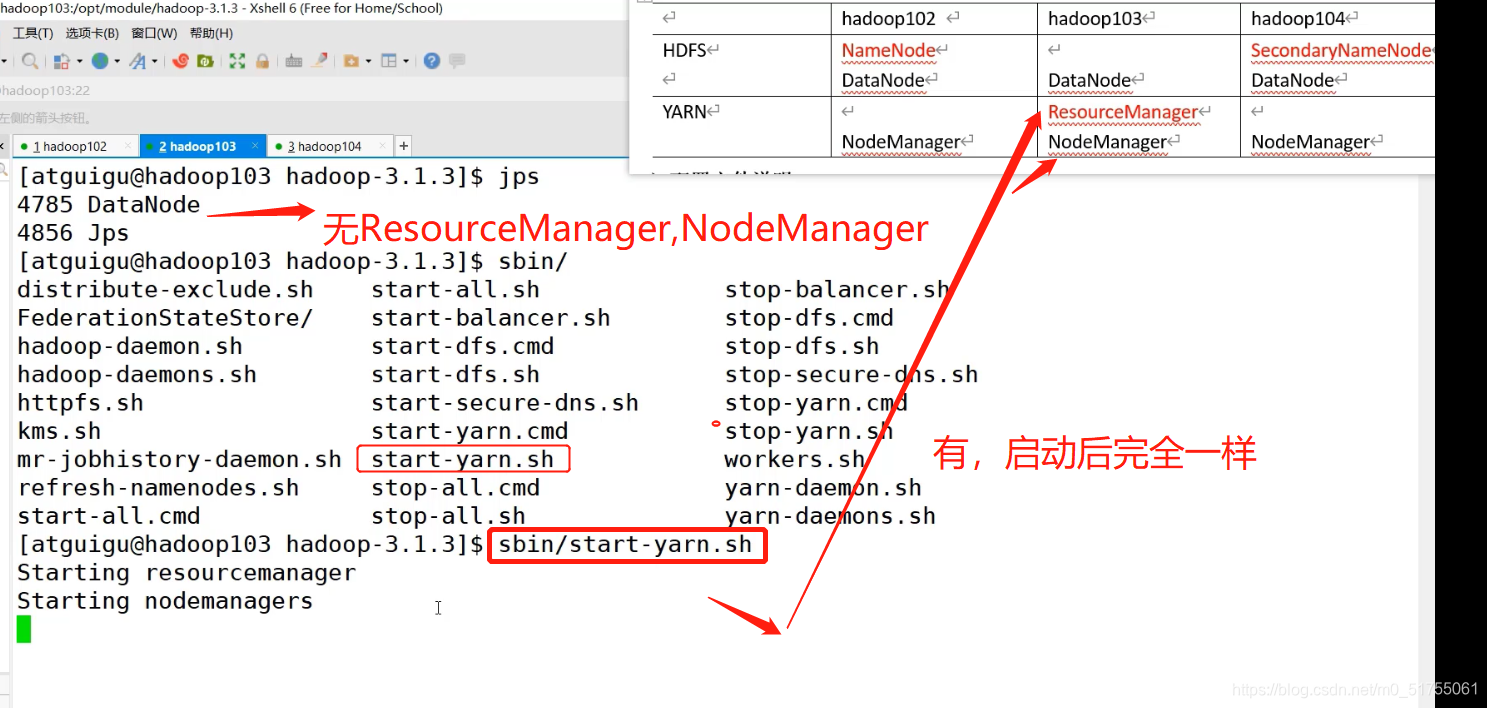
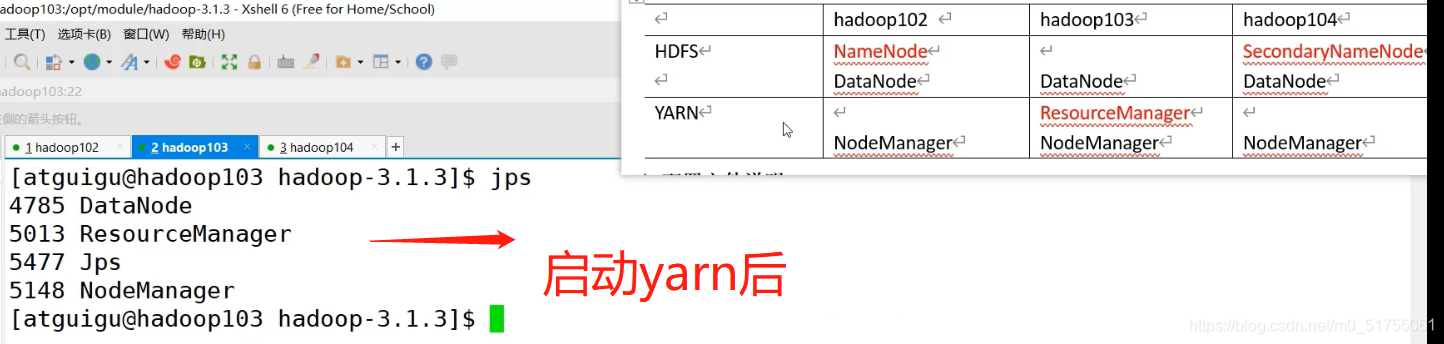
3.4 Prueba de clúster básica
Cree un directorio en HDFS:

cargue archivos:
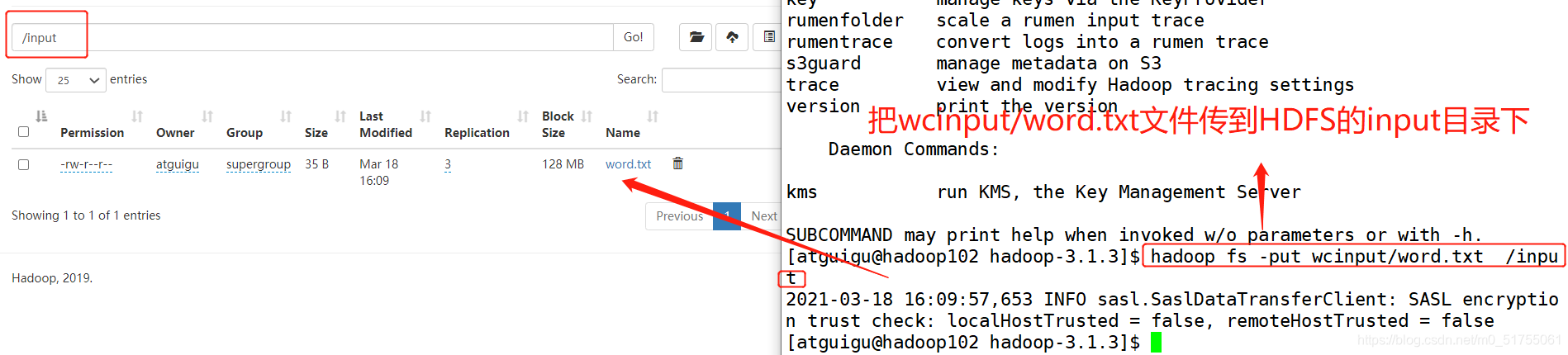


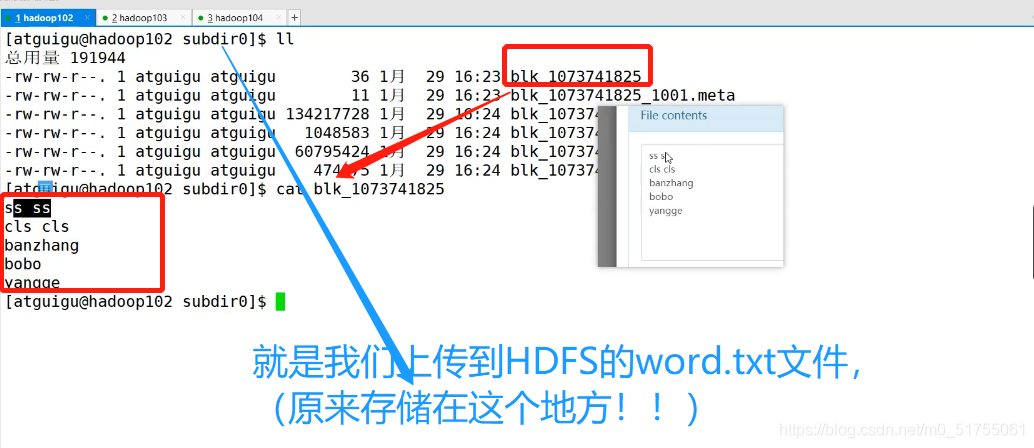
Ver la ruta de almacenamiento de archivos HDFS:
[atguigu@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-962968270-
192.168.10.102-1616034469344/current/finalized/subdir0/subdir0
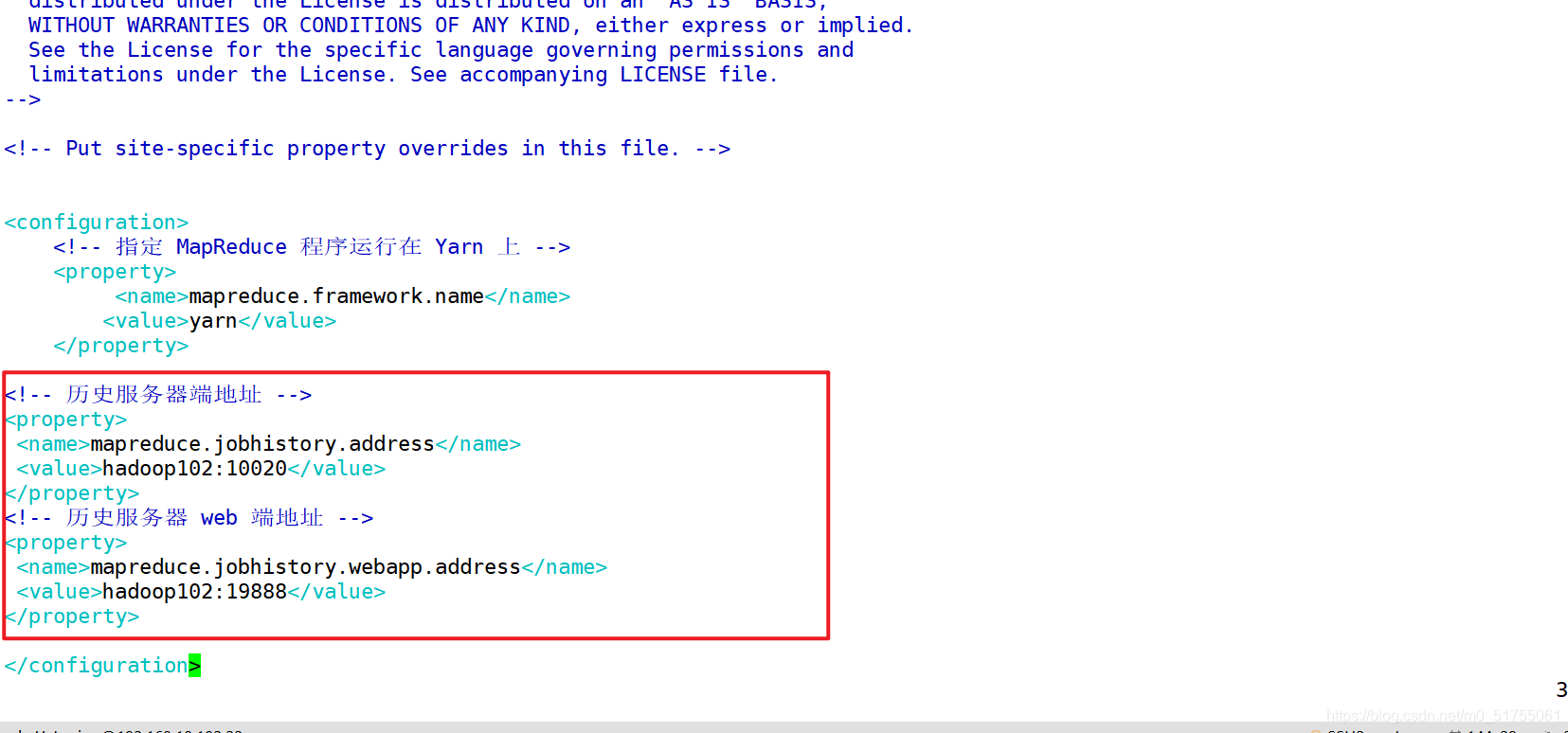
3.5 Configurar el servidor de historial
1. 1. Ubicación mapred-site.xml
2. Configuración de distribución
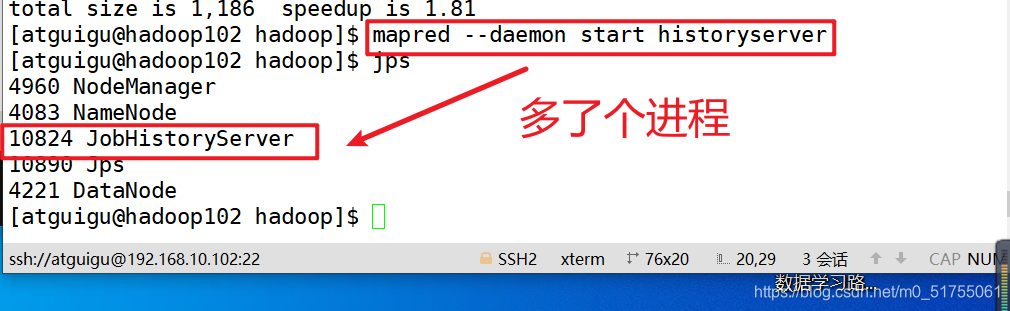
3. Inicie el servidor de historial en hadoop102
4. Verifique si el servidor de historial está iniciado
3.6 Configurar el servidor de historial
Nota: Para habilitar la función de agregación de registros, debe reiniciar NodeManager, ResourceManager e HistoryServer.
1. 1. Colocación yarn-site.xml
2. Configuración de distribución
3. Cierre NodeManager, ResourceManager e HistoryServer
4. Inicie NodeManager, ResourceManage e HistoryServer
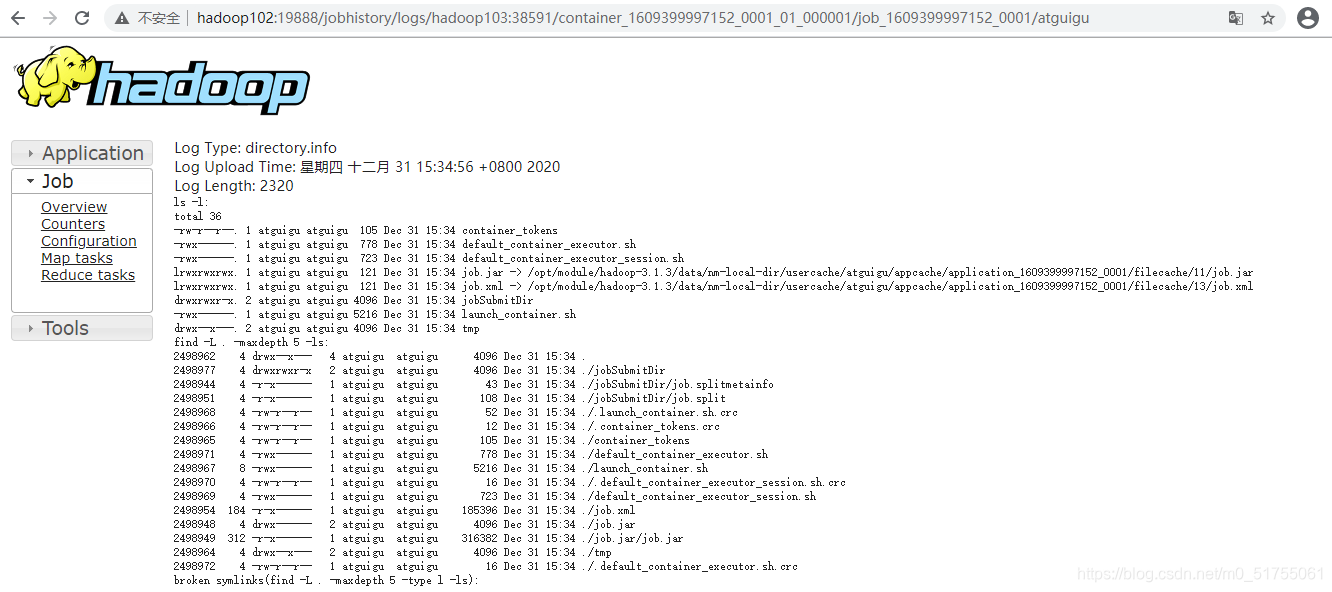
5. Ver registro
- Dirección del servidor de historial: http: // hadoop102: 19888 / jobhistory
- Lista de tareas históricas
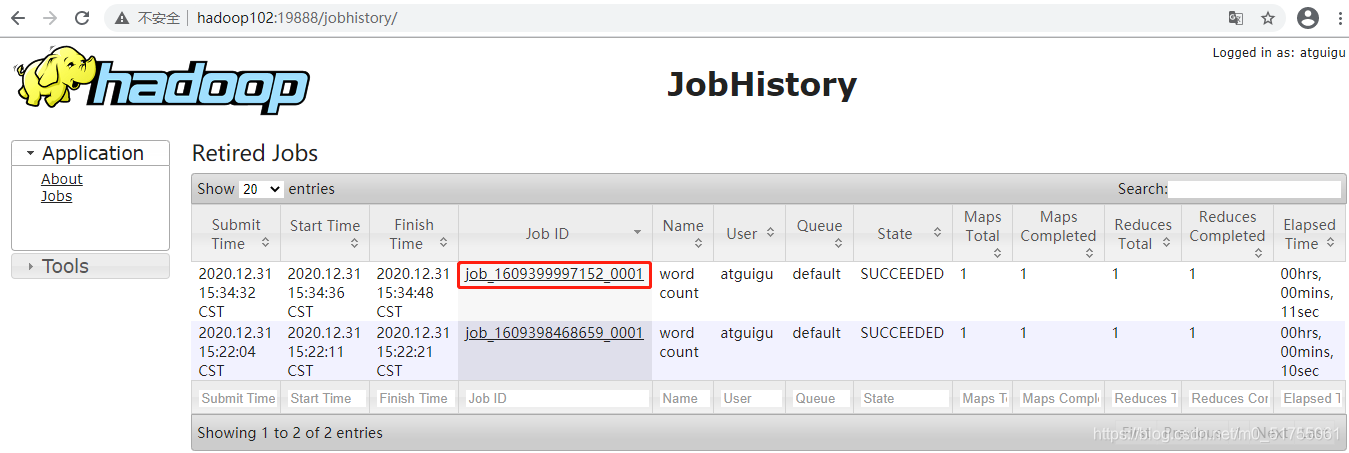
- Ver registro de ejecución de tareas
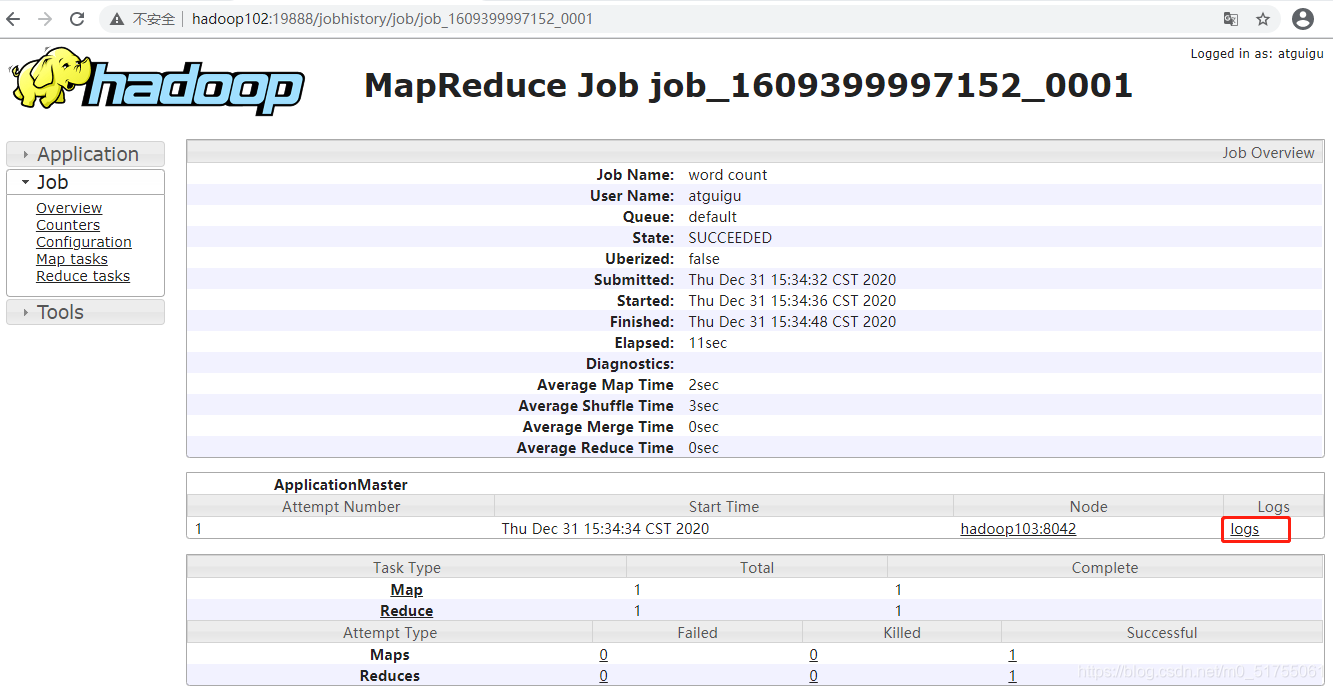
- Ejecutar detalles del registro
Capítulo 4 Resumen del método de inicio / detención de clúster
4.1 Arranque / parada de cada módulo por separado (la configuración de ssh es un requisito previo)
(1) Iniciar / detener HDFS como un todo
start-dfs.sh/stop-dfs.sh
(2) Iniciar / detener YARN como un todo
start-yarn.sh/stop-yarn.sh
4.2 Cada componente del servicio se inicia / detiene uno por uno
(1) Iniciar / detener componentes HDFS por separado
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2) Iniciar / detener YARN
yarn --daemon start/stop resourcemanager/nodemanager
Capítulo 5 Escritura de scripts comunes para clústeres de Hadoop
5.1 Script de inicio y cierre del clúster de Hadoop (incluido HDFS, Yarn, Historyserver): myhadoop.sh
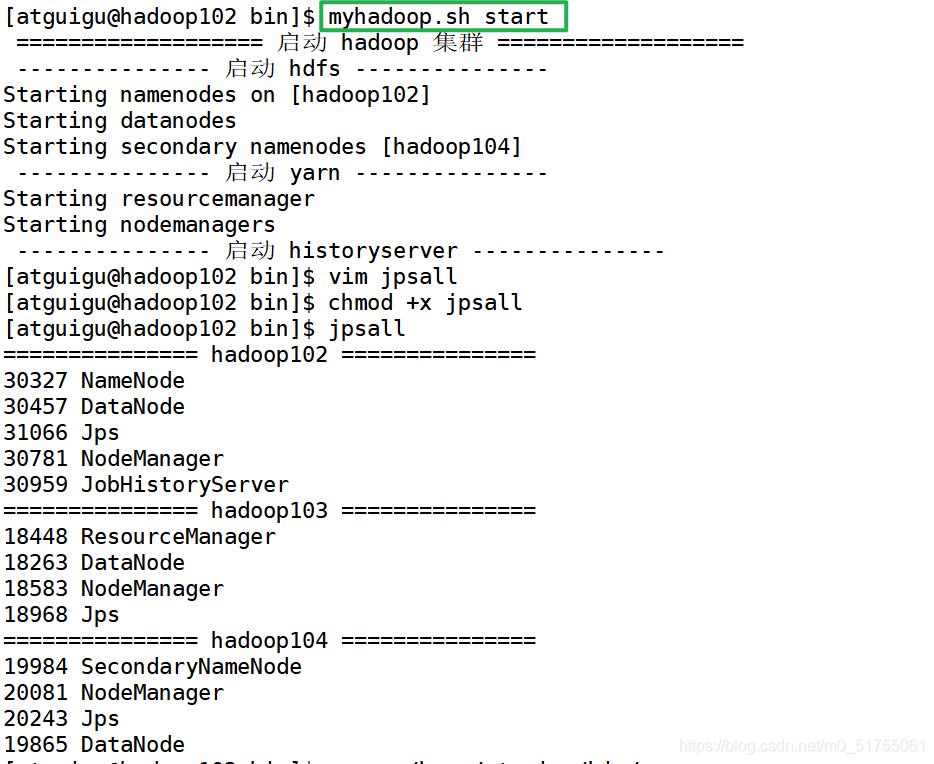
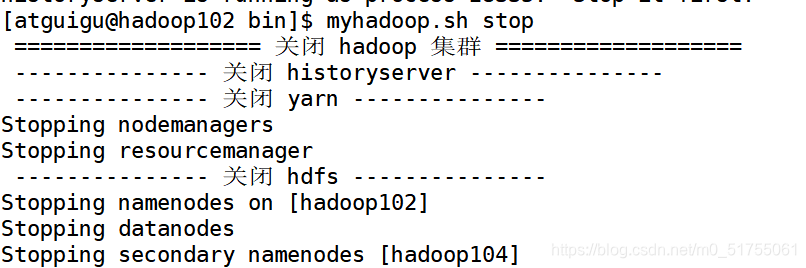
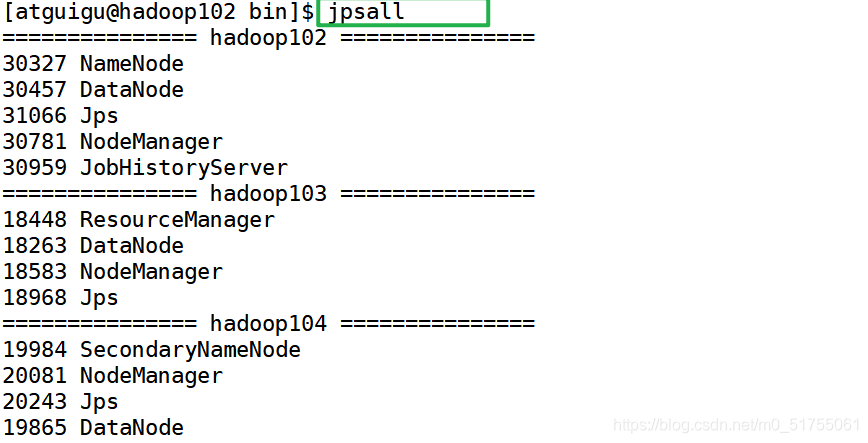
5.2 Ver los scripts de proceso de Java de tres servidores: jpsall
5.3 Sincronización de la hora del clúster
- Si el servidor se encuentra en un entorno de red pública (se puede conectar a la red externa), no se requiere la sincronización de la hora del clúster, Porque el servidor se calibrará regularmente con la hora de la red pública;
- Si el servidor está en el entorno de red interna, se debe configurar la sincronización de la hora del clúster, de lo contrario, si el tiempo es demasiado largo, se producirá una desviación de tiempo, lo que provocará que el tiempo de ejecución del clúster no esté sincronizado.