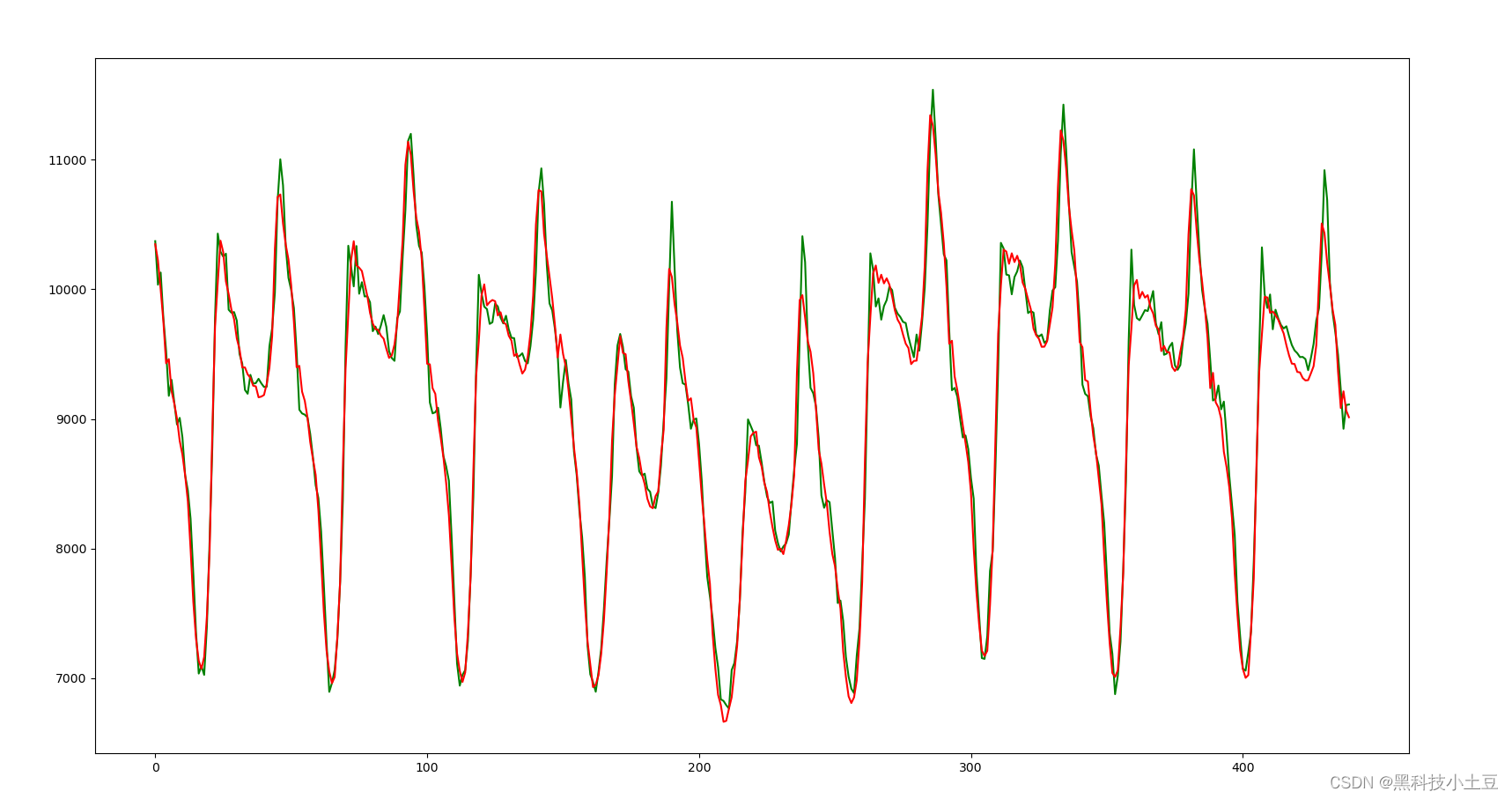
На основе модели прогнозирования временных рядов Transformer
Особенности: 1. Однопараметрический и многопараметрический вход, свободное переключение
2. Одноэтапный прогноз, многоэтапный прогноз, автоматическое переключение
3. На основе архитектуры Pytorch
4. Несколько показателей оценки (MAE, MSE, R2, MAPE и т. д.)
5. Данные считываются из файла excel, легко заменяются
6. Стандартная структура, данные разделены на набор для обучения, набор для проверки и набор для тестирования.
Весь полный код, код, который гарантированно запустится, можно увидеть здесь.
http://t.csdn.cn/obJlC ![]() http://t.csdn.cn/obJlC
http://t.csdn.cn/obJlC
! ! ! Если первая ссылка не открывается, пожалуйста, нажмите на личную домашнюю страницу, чтобы просмотреть мое личное введение.
(После поиска товара нажмите на аватарку, чтобы увидеть все коды)
Блог Black Technology Little Potato_CSDN Blog-Deep Learning, Blogger in 32 MCU Field

Модель Transformer — это нейросетевая модель, основанная на механизме внутреннего внимания, предложенном Google в 2017 году, для обработки последовательностей (sequence-to-sequence) задач обработки естественного языка. По сравнению с моделями традиционной рекуррентной нейронной сети (RNN) и сверточной нейронной сети (CNN), модели Transformer не нужно иметь дело с временными отношениями входной последовательности, и она может лучше фиксировать глобальные отношения между последовательностями и повышать производительность. модель.
Модель преобразователя является производной от структуры кодировщик-декодер, где кодировщик используется для преобразования входной последовательности в набор векторов признаков, а декодер используется для преобразования этих векторов признаков в выходную последовательность. Transformer использует механизм внутреннего внимания, чтобы заменить механизм кругового мнения в традиционной модели RNN.
К достоинствам модели Трансформер можно отнести:
- Модель Transformer обрабатывает данные последовательности с помощью механизма внутреннего внимания, который может напрямую моделировать всю последовательность, фиксировать глобальную взаимосвязь между последовательностями и значительно повышать эффективность и точность моделирования.
- Механизм внимания с несколькими головками в модели Transformer делает его более интерпретируемым и способным лучше обрабатывать более длинные последовательности и крупномасштабные данные.
Таким образом, модель Transformer представляет собой мощную модель глубокого обучения, подходящую для обработки естественного языка, языкового перевода, обработки векторных слов и других областей, и она хорошо справляется с такими задачами, как генерация текста, анализ настроений и интеллектуальные ответы на вопросы.
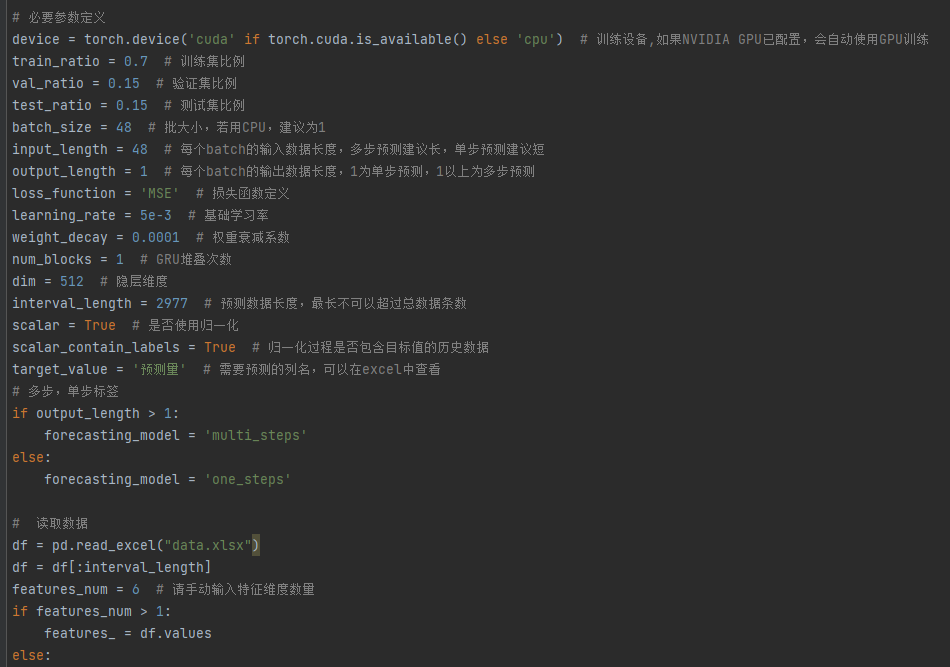
train_ratio = 0.7 # 训练集比例
val_ratio = 0.15 # 验证集比例
test_ratio = 0.15 # 测试集比例
input_length = 48 # 输入数据长度,多步预测建议长,单步预测建议短
output_length = 1 # 输出数据长度,1为单步预测,1以上为多步预测 请注意,随着输出长度的增长,模型训练时间呈指数级增长
learning_rate = 0.1 # 学习率
estimators = 100 # 迭代次数
max_depth = 5 # 树模型的最大深度
interval_length = 2000 # 预测数据长度,最长不可以超过总数据条数
scalar = True # 是否使用归一化
scalar_contain_labels = True # 归一化过程是否包含目标值的历史数据
target_value = 'load' # 需要预测的列名,可以在excel中查看