Swin Transformer V2: Scaling Up Capacity and Resolution
I. Introduction
1. Overview
This paper proposes an upgraded version of SwinTransformerV2, with a maximum parameter value of 3 Billion, which can handle large-scale images. By increasing model capacity and input resolution, SwinTransformer achieved new records on four representative benchmark datasets.
2. The problem to be solved
-
Visual models usually face scale instability ;
-
Downstream tasks require high-resolution images, and it is unclear how to transfer low-resolution pre-trained models to high-resolution versions ;
-
When the image resolution is very large, GPU memory usage is also a problem.
3. Improvement plan
- Proposed post-normalization (Post Normalization) technology and scalable (Scaled) cosine attention to improve the stability of large visual models;
- Propose the log space continuous position offset technology to migrate the low-resolution pre-training model to the high-resolution model;
- We also share crucial implementation details that allow significant savings in GPU memory to make training large visual models feasible.
2. Method
1.A Brief Review of Swin Transformer
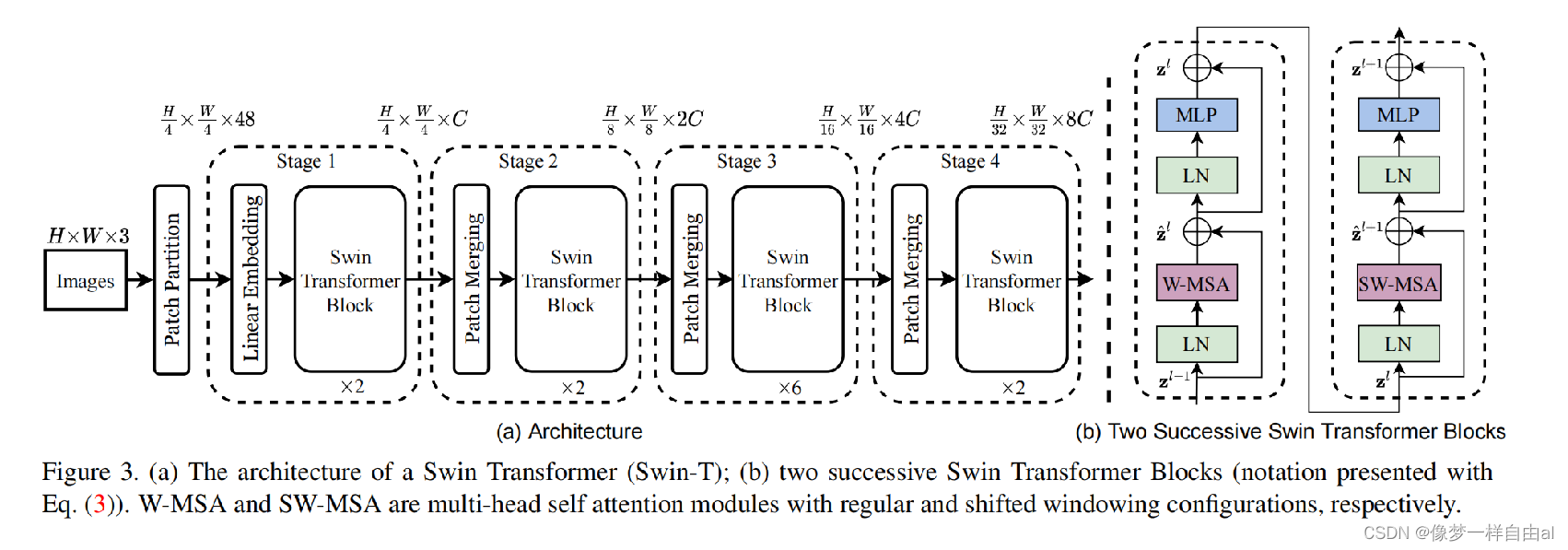
Normalization Configuration It is well known that normalization techniques are very important for the training of deeper architectures. The original SwinTransformer uses conventional pre-normalization technology, as shown in the figure below:
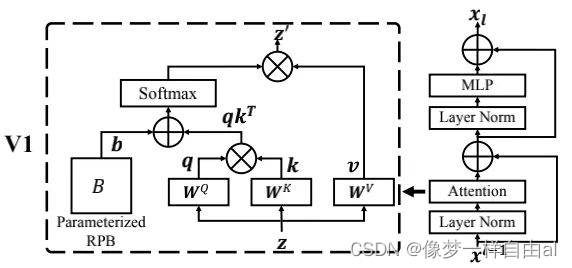
Relative position bias is a key component of the original SwinTransformer, which introduces an additional parameterized bias, the formula is as follows:
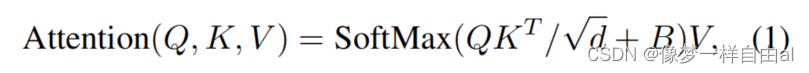
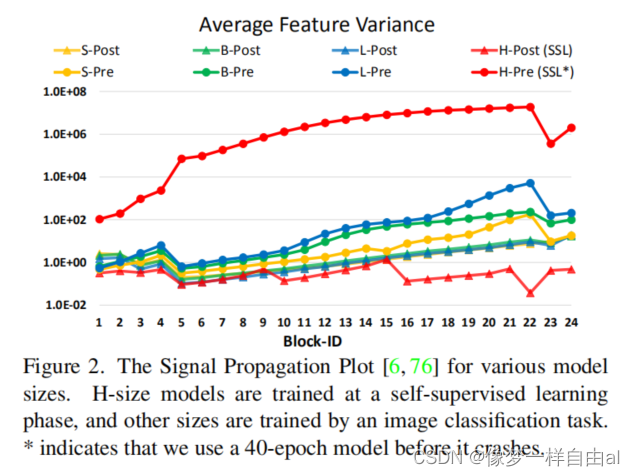
Issues in scaling up model capacity and window resolution in During the process of scaling the capacity and window resolution of SwinTransformer, the following two problems were found:
- Instability problems during capacity scaling, see the figure below:
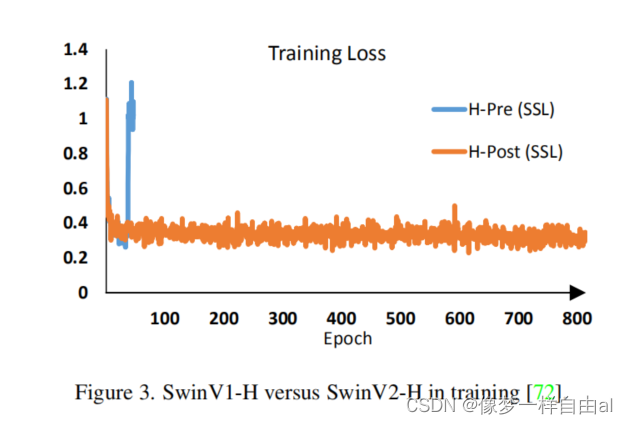
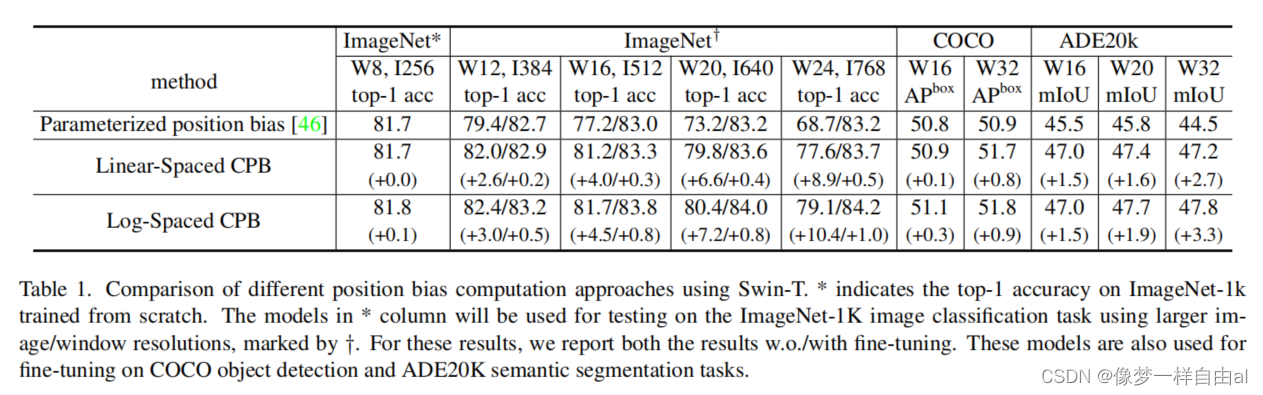
- For performance degradation issues when migrating across resolutions, see the table below:
2.Scaling up Model Capacity
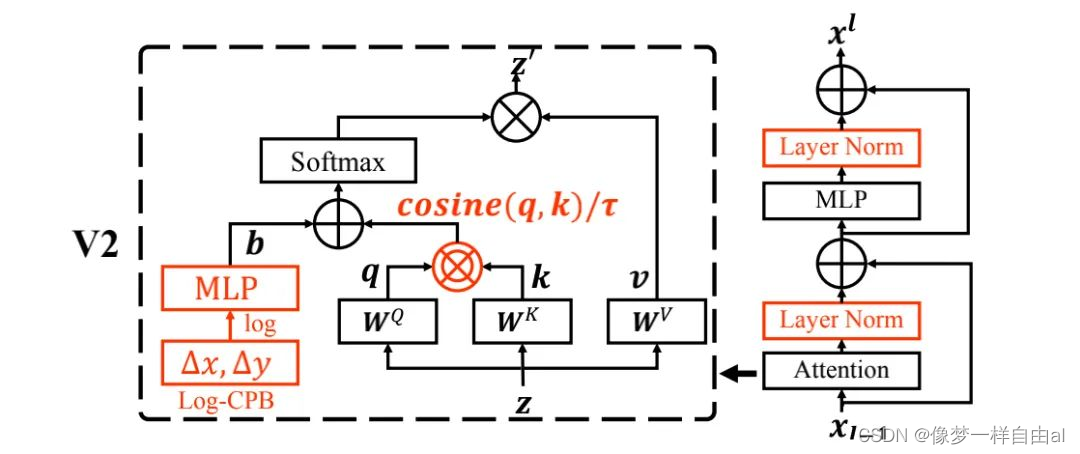
Post Normalization In order to alleviate this problem, we propose Post Normalization (post normalization): the output of each residual module is normalized and then merged with the main branch, so the amplitude of the main branch will not accumulate layer by layer. As can be seen from Figure 2 above: the activation amplitude of the model normalized after use is milder.
In the original self-attention calculation process of Scaled Cosine Attention , the pixelity of a pixel pair is calculated by the dot product of query and key. We found that in large models, the attention maps of certain modules and heads are dominated by a small number of pixel pairs. To alleviate this problem, we propose Scaled Cosine Attention (SCA), the formula is as follows:
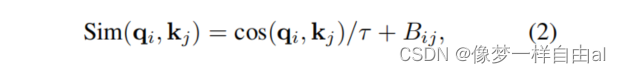
3.Scaling Up Window Resolution
Next, a log-space continuous position biasing method is introduced to enable a smooth transfer of relative position biases across window resolutions.
Continuous Relative Position Bias is different from directly optimizing the bias parameters. The continuous position bias method uses a meta-network for relative coordinates:
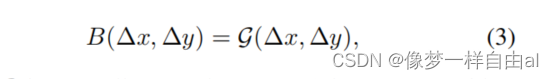
Note: G is a small network
that generates bias parameters for any relative coordinates, so it can be naturally Migrations with arbitrary variable window sizes can be performed efficiently.
Log-space Coordinates When migrating across large windows, a large proportion of the relative coordinate range needs to be extrapolated. To alleviate this problem, logarithmic space coordinates are used:
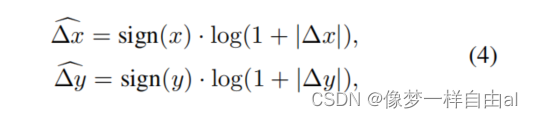
with logarithmic space coordinates, when doing block resolution migration, the required extrapolation scale will be smaller.
Table 1 gives a comparison of migration performance under different position offsets. It can be seen that when migrating to a larger window size, the logarithmic space continuous position offset has the best performance.
4. Implementation to Save GPU Memory
Another problem with large-resolution input and large-capacity models is the unacceptable GPU memory usage.
This article uses the following implementations to improve this problem:
- Zero-Redundancy Optimizer (ZeRO): The ZeRO optimizer is used to reduce GPU memory usage, which has minimal impact on the overall training speed;
- Activation check-pointing: Use checkpoint technology to save GPU usage, but it will reduce the training speed by 30%;
- Sequential Self-attention computation: Using serial computation instead of batch mode, it has little impact on the overall training speed.
5. Model Configurations
This article keeps the same stage, block and channel configuration as SwinTransformer to get four versions of SwinTransformerV2:
T(Tiny),S(Small),B(Base),L(Large)
SwinV2-T: C=96, layer number= {2,2,6,2}
SwinV2-S: C=96, layer number= {2,2,18,2}
SwinV2-B: C=128, layer number= {2,2,18,2}
SwinV2-L: C=192, layer number= {2,2,18,2}
We further scaled SwinV2 to a larger size and obtained a 658M and 3B parameter model:
SwinV2-H: C=352, layer number={2,2,18,2}
SwinV2-G: C=512, layer number={2,2,42,2}
3. Experimental results
This paper mainly conducts experiments on ImageNetV1, ImageNetV2, COCO detection, ADE20K semantic segmentation and Kinetics-400 video action classification.
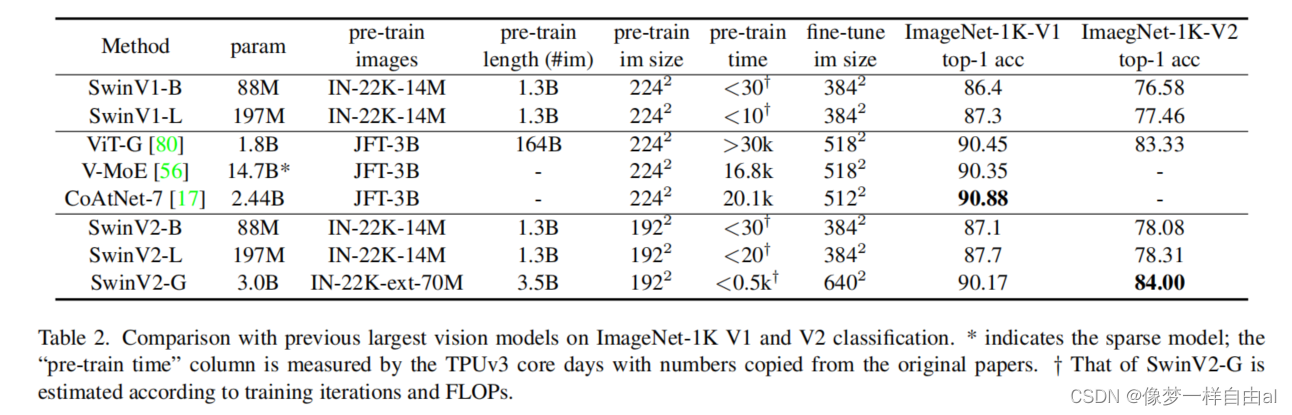
The above table gives the performance comparison on the ImageNet classification task , you can see:
- On ImageNetV1 data, SwinV2-G achieved 90.17% accuracy;
- On the ImageNetV2 data, SwinV2-G achieved an accuracy of 84.0%, 0.7% higher than the previous best;
- Compared with SwinV1, the performance of SwinV2 is improved by about 0.4~0.8%.
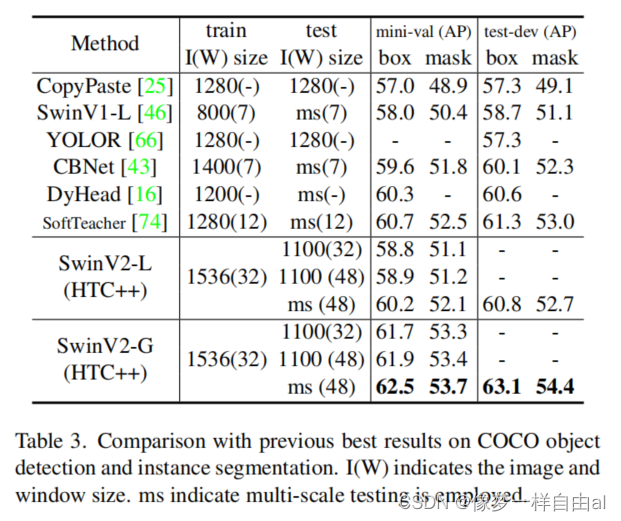
The above table compares the performance on the COCO detection task . It can be seen that the proposed scheme has achieved a box and mask mAP index of 63.1/54.4, which is 1.8/1.4 higher than the previous best.
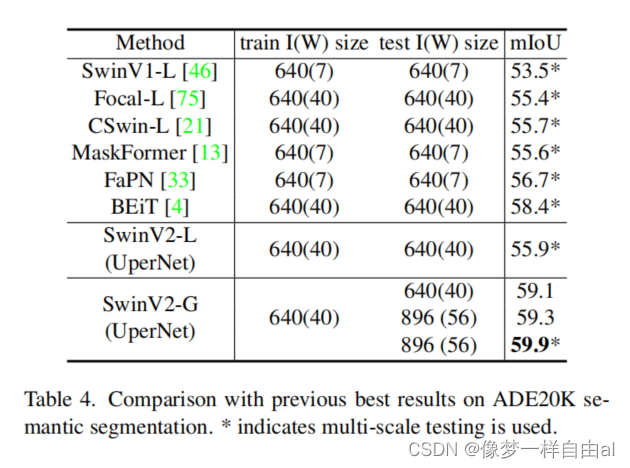
The above table compares the performance on the ADE20K semantic segmentation task . It can be seen that the proposed scheme has achieved 59.9mIoU index, which is 1.5 higher than the previous best.

The above table compares the performance on the Kinetics-400 video action classification task . It can be seen that the proposed scheme has achieved an accuracy of 86.8%, which is 1.4% higher than the previous best.
Reference:
1. Slaughter the major CV tasks on the list! The strongest backbone network: Swin Transformer V2 is here
2. [Paper reading] Swin Transformer V2: Scaling Up Capacity and Resolution
3. Detailed explanation of Swin-Transformer network structure