1. 注意メカニズム
重要性: 人間の注意メカニズムは、情報処理の効率と精度を大幅に向上させます。
公式:

1) 自己注意メカニズム
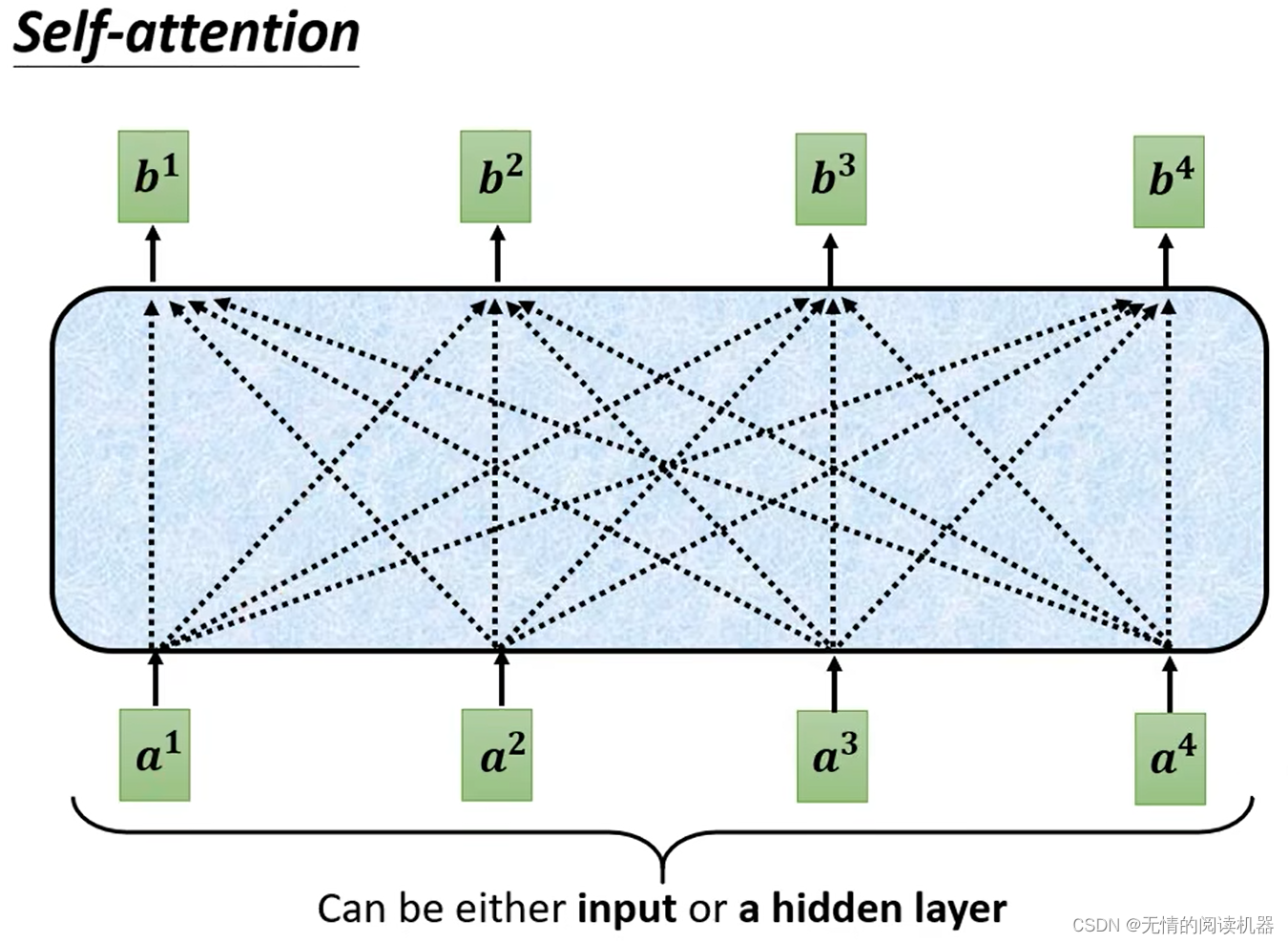
b はすべての a を考慮して生成されます。
例として、b1 ベクトルの生成を取り上げます。
1.シーケンスaで、a1に関連する他のベクトルを見つけます
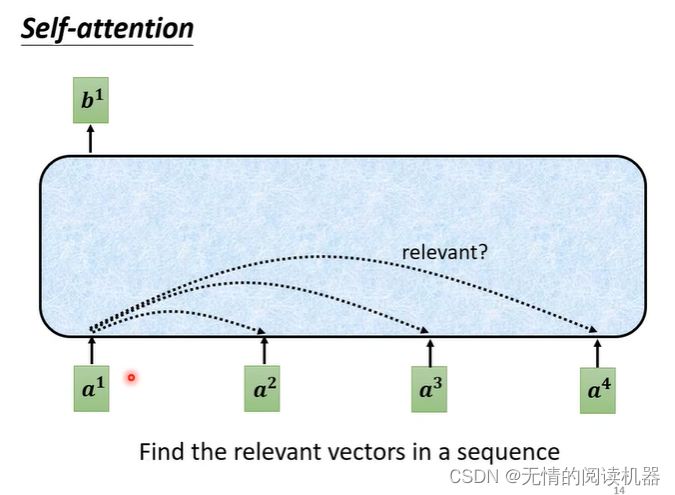
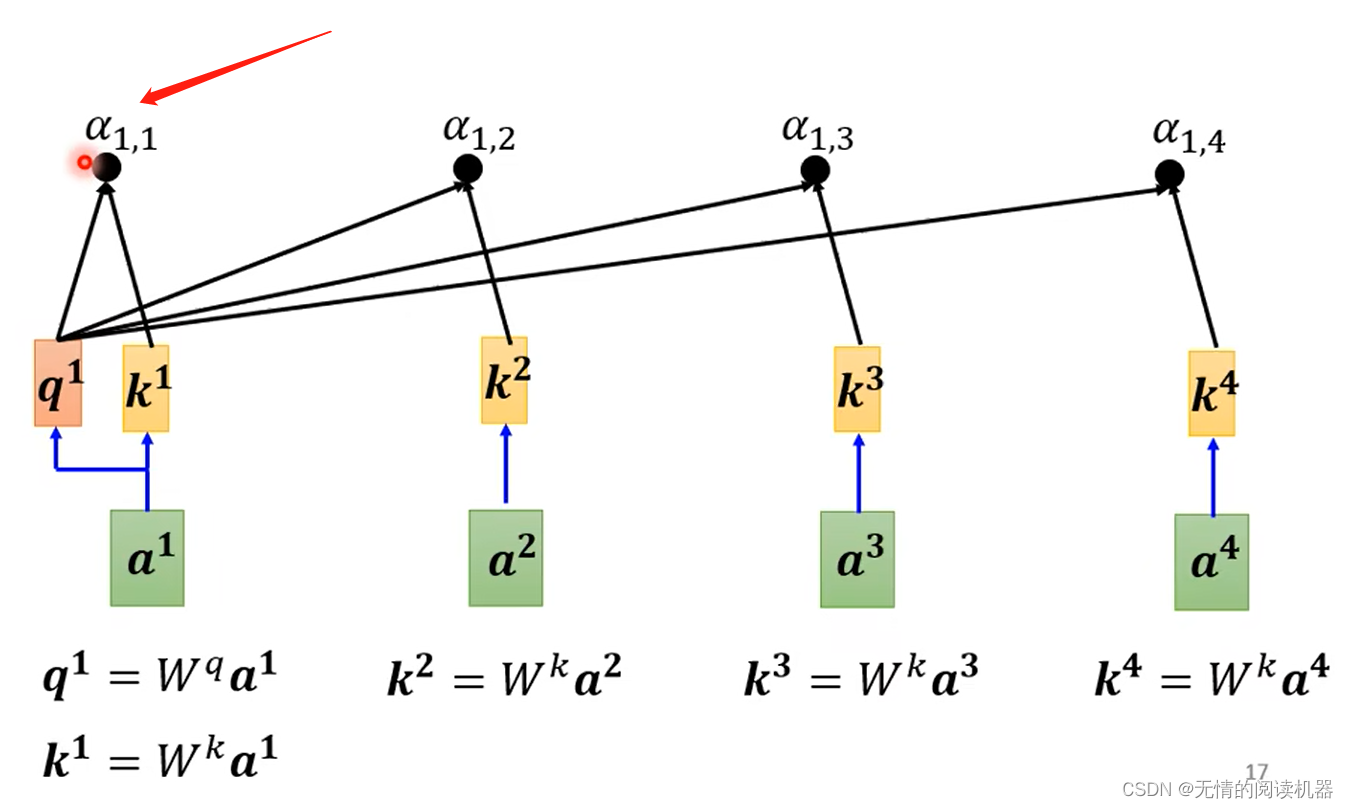
2. 各ベクトルが a1 に関連付けられている程度。値 α を使用して表します。
では、この値はどのように計算されるのでしょうか。
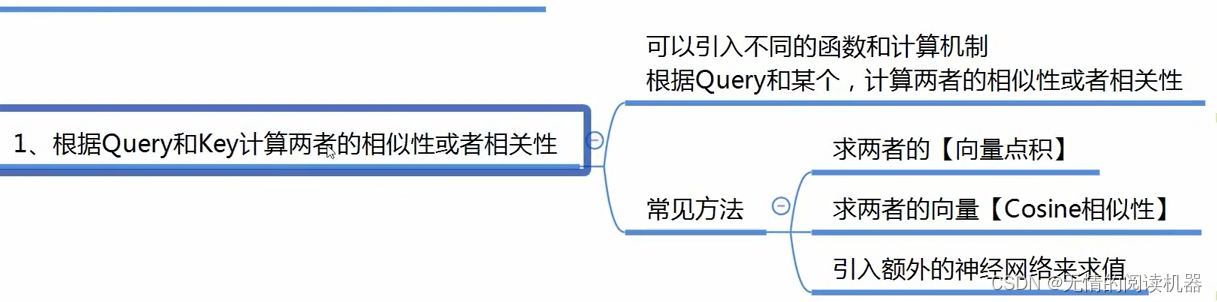
計算には多くの方法があります。
私の理解:関連度は、質問(質問)とキー(回答)の一致度に相当します


自分との関係も大事
次に、これらの相関をソフトマックスに入れて、最終的な相関を取得します

最後に v を掛けて最終値を取得します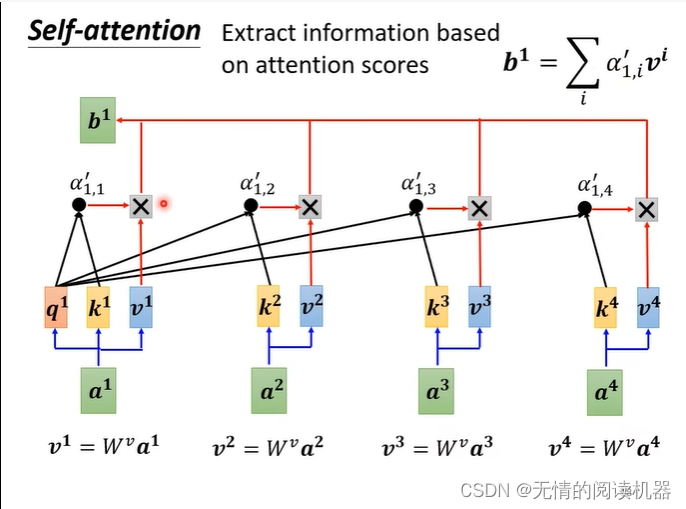
以上がマクロの理解ですが、行列の掛け算からもう一度見てみましょう
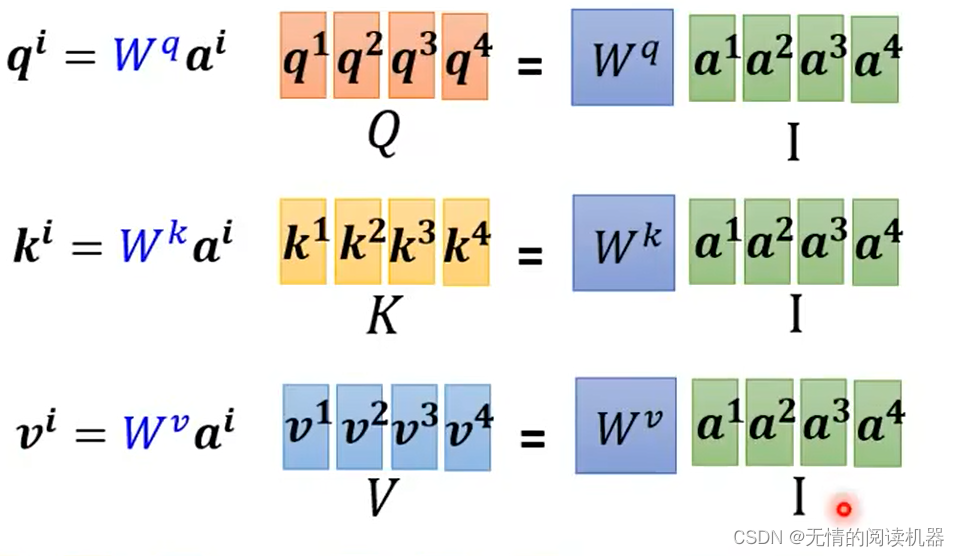
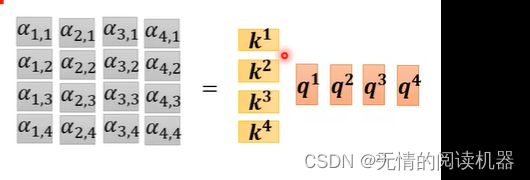


プロセス全体で学習する w 行列は 3 つだけです。

2) 多頭自己注意
ヘッド 1 はヘッド 1 に対してのみカウントされ、ヘッド 2 はヘッド 2 に対してのみカウントされ、ヘッド n はヘッド n に対してのみカウントされます。
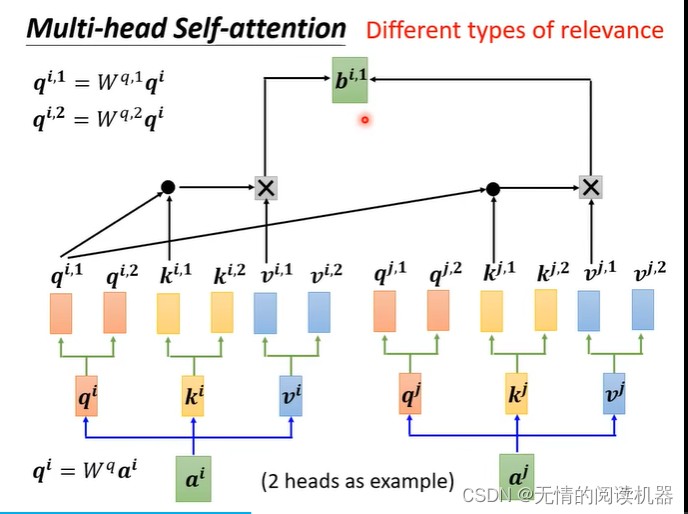
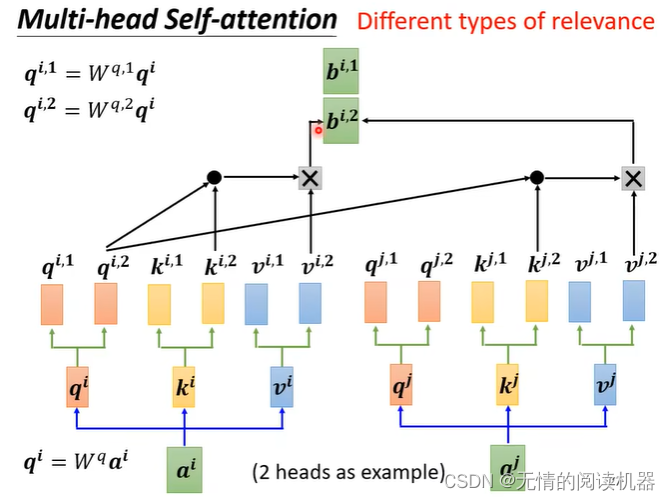
行列を乗算して最終的な bi を取得し、それを次のレイヤーに渡します

マルチヘッド Attention の本質は、パラメーターの合計量が変更されていない場合に Attention 計算のために元の高次元空間の異なる部分空間に同じクエリ、キー、および値をマップし、最後のステップで異なる部分空間をマージすることです。サブスペースの注目情報。これにより、各ヘッドの Attention を計算する際に各ベクトルの次元が削減され、ある意味ではオーバーフィッティングが防止されます; Attention は異なるサブスペースで異なる分布を持っているため、マルチヘッド Attention は実際にシーケンスを探します異なる角度間の関係、および最終的なスプライシング ステップでは、異なるサブスペースでキャプチャされた関係が再び結合されます。
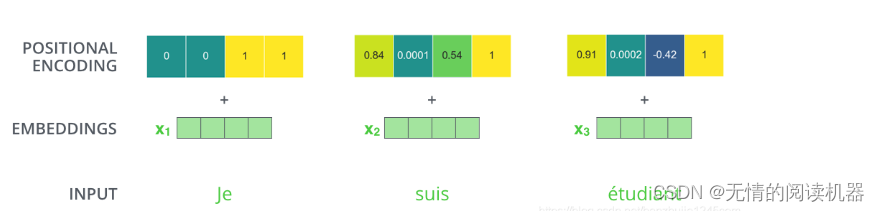
3) 位置情報
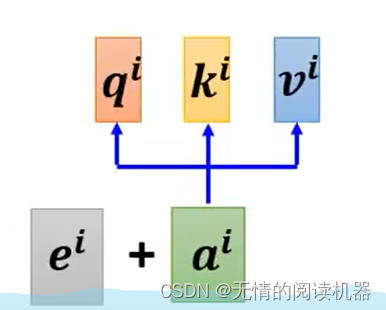
位置情報の恩恵を受けて、ベクトルは整っていると考えられます。
3) 注意メカニズム
意義:膨大な情報の中から、問題解決に最も役立つ情報を得ることができます。コンピューティング リソースを節約し、モデルの効率と機能を向上させます。
たとえば、黒板を見て知識を学ぶ場合、隅や隅は無効な情報であり、教師が黒板をノックする場所は注意すべき有効な情報です。

x1 はトム、x2 はチェイス、x3 はジェリー、最初にエンコードしてからデコードすると、y1 トム、y2 がチェイス、y3 がジェリーになります。
気晴らしモデルを使用すると、計算は次のようになります。重要度は同じです。
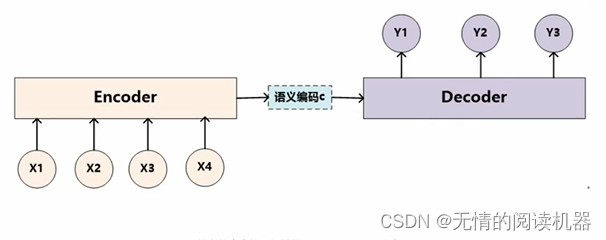

エンコーダー/デコーダー フレームワーク
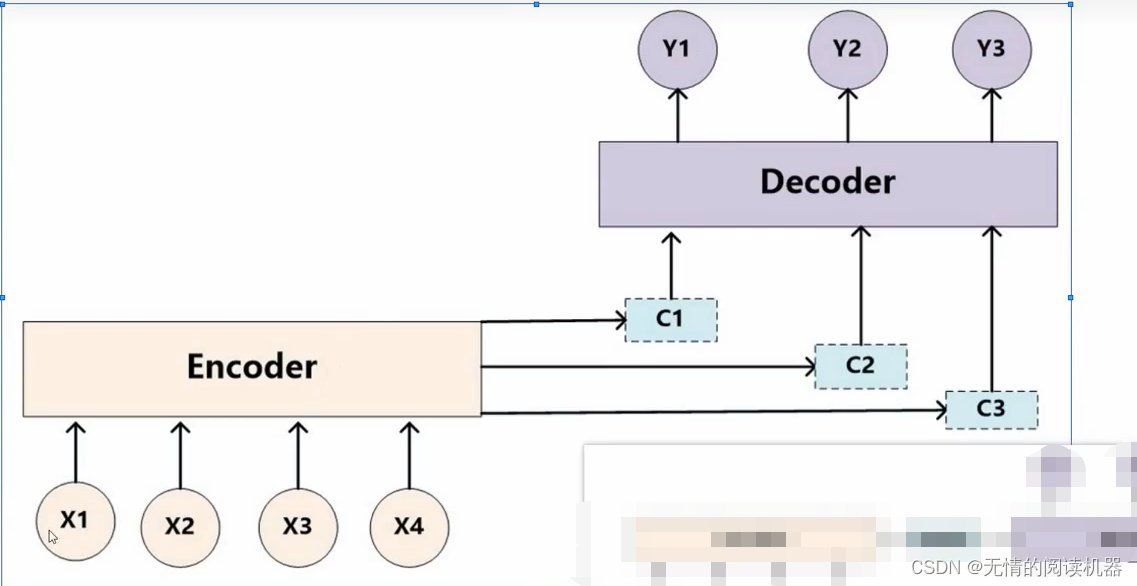
 したがって、注意の概念を深めます。
したがって、注意の概念を深めます。


計算プロセスは自己注意に似ています
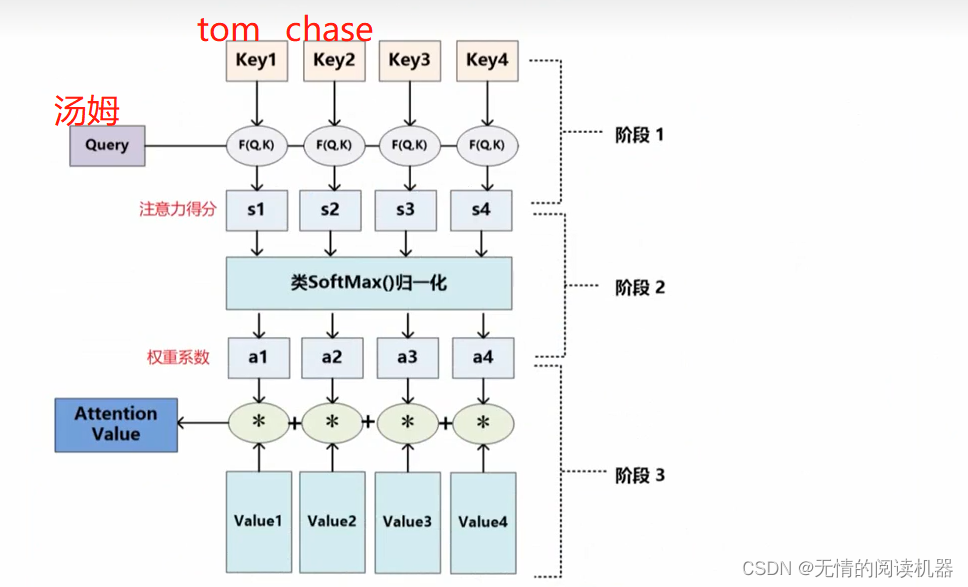
ここで、F(Q,K) は類似度の計算方法であり、その方法は一意ではありません
2.変圧器
1) 構造
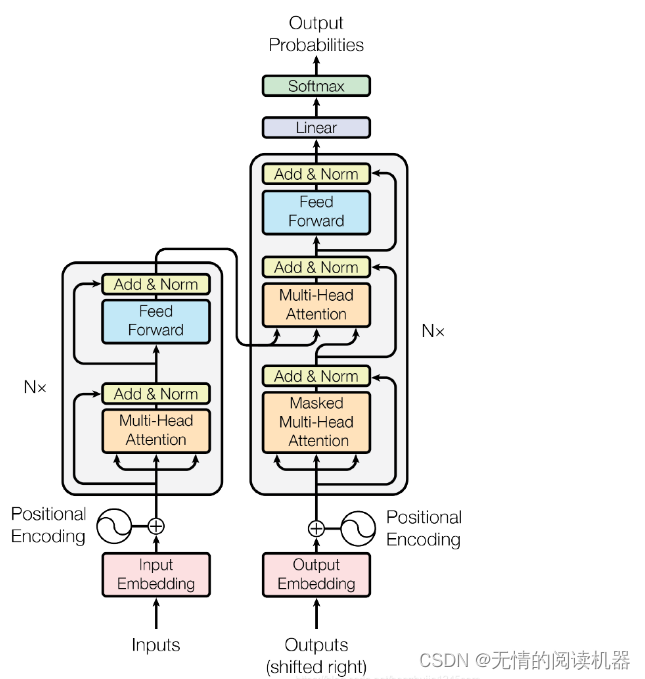

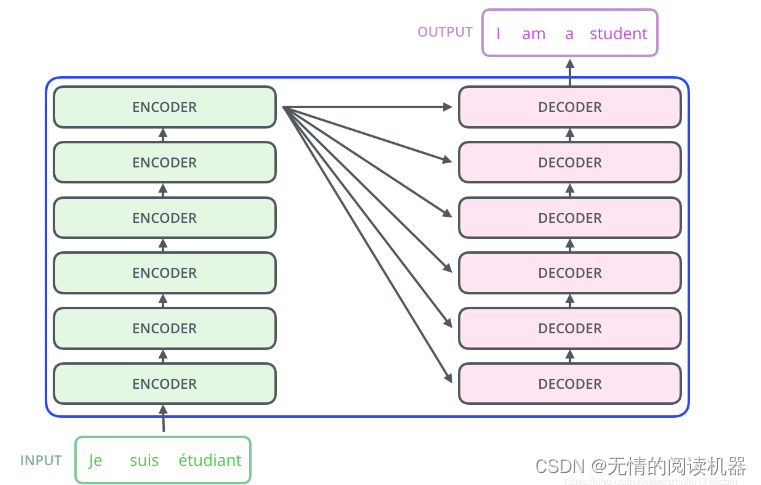
Transformer は本質的に Encoder-Decoder アーキテクチャです。したがって、中間部分の Transformer は、エンコード コンポーネントとデコード コンポーネントの 2 つの部分に分けることができます。

この論文のエンコーダとデコーダは6層を使用しています
各エンコーダーは、Self-Attention レイヤー (自己注意層) と Position-wise Feed Forward Network (フィードフォワード ネットワーク、略して FFN) の 2 つのサブレイヤーで構成されます。各エンコーダーの構造は同じですが、異なる重みパラメーターを使用します。位置フィードフォワード ネットワークは完全に接続されたフィードフォワード ネットワークであり、各位置の単語はまったく同じフィードフォワード ニューラル ネットワークを通過します。2 つの線形変換、つまり 2 つの全結合層で構成され、最初の全結合層の活性化関数が ReLU 活性化関数です。
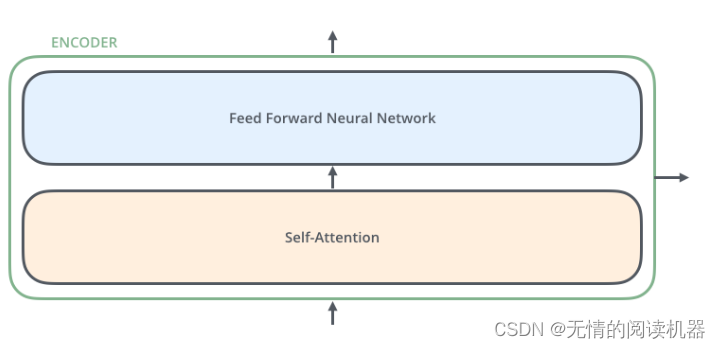
各エンコーダーの各サブレイヤー (Self-Attention レイヤーと FFN レイヤー) には残差接続があり、レイヤーの正規化操作を実行します. 全体の計算プロセスは次のように表現できます:
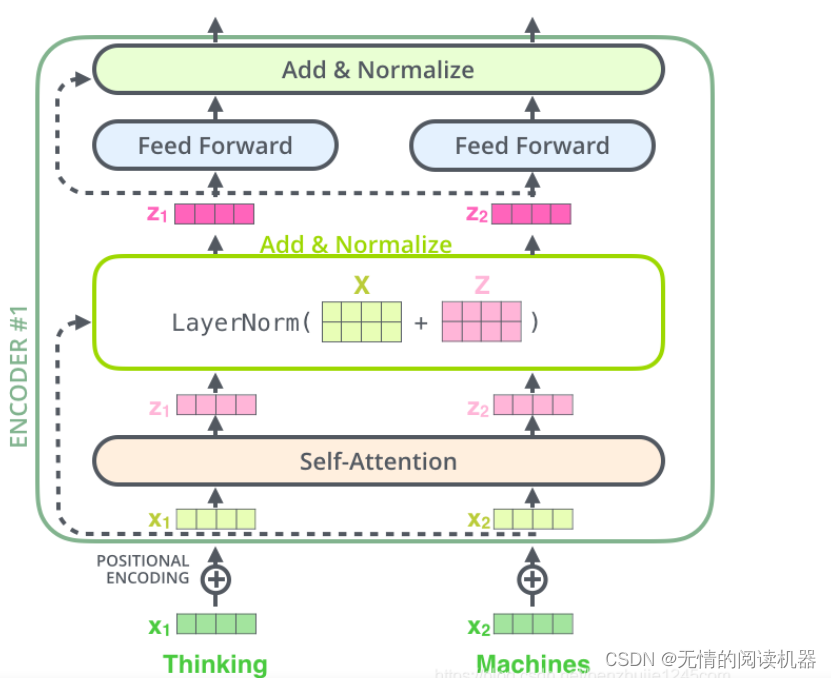
2) 位置エンコーディング
ロケーションコードについてもう一言