Tecnología de reconocimiento de voz Kaldi (7) ----- GMM
Directorio de artículos
entrenamiento GMM
En el artículo anterior, hablamos sobre las ventajas de GMM en comparación con DTW, entonces, ¿cómo obtenemos la capacitación de GMM?
El proceso de formación de GMM es el siguiente:
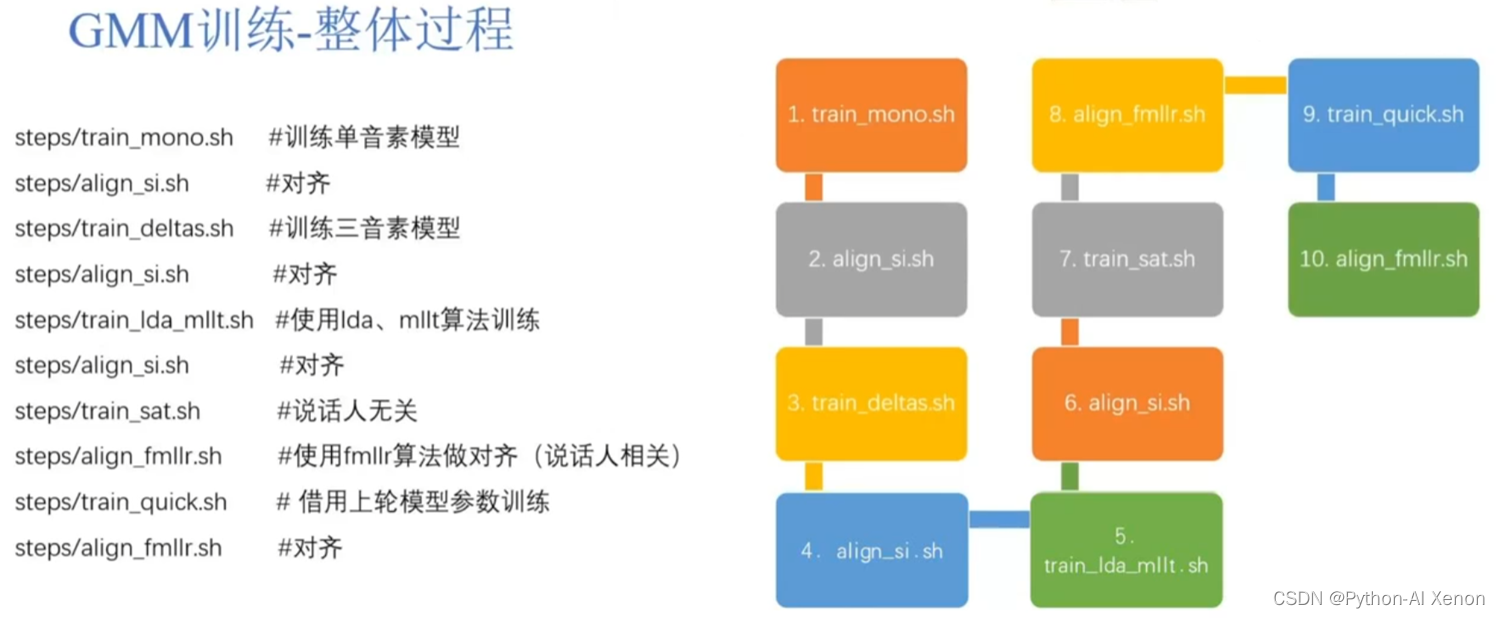
Todo el proceso se divide en 10 enlaces, de los cuales 5 están relacionados con la alineación, para facilitar la comprensión, solo se discuten 2 de estos 10 enlaces (modelo de entrenamiento de factor único train_mono y alineación align_si), y los demás se llevan a cabo básicamente . Optimización, todos los involucrados en esta área pueden Baidu por sí mismos en el futuro. El proceso general es entrenar primero un modelo gaussiano, usar el modelo gaussiano para alinear los datos de entrenamiento y luego usar los datos alineados para entrenar un modelo gaussiano. Por ejemplo (la imagen de arriba a la derecha), primero entrene un modelo monofónico, luego use el modelo monofónico para alinear los datos de entrenamiento y luego, en función de estos datos alineados, entrene un modelo trifónico y luego use el modelo trifónico para align Alinee los datos de entrenamiento, luego use lda, mllt y otros algoritmos para reevaluar el modelo GMM, luego alinee los datos de entrenamiento, luego realice operaciones relacionadas e independientes del hablante en el modelo, y finalmente alinee los datos de entrenamiento nuevamente. Todo el proceso del modelo de formación GMM es así. En general, cuanto mejor se entrena el modelo, más precisa será la alineación, lo que mejorará la precisión del reconocimiento de voz.
Entrenamiento GMM: proceso de entrenamiento mono
Echemos un vistazo a cómo se entrena el modelo monofónico. Primero, para entrenar un modelo, debe haber un modelo inicial y luego un entrenamiento iterativo en este modelo inicial. Entonces, kaldi llama a gmm-init-mono para inicializar el modelo, que usa las funciones en los datos de entrenamiento para inicializar el modelo. Después de inicializar el modelo, es hora de hacer un gráfico. Hay varias entradas para este gráfico, incluido el modelo inicializado, L.fst en el archivo lang y el texto en el diccionario y los datos de entrenamiento. El resultado generado es un oración hasta el nivel del fonema Paquete comprimido (gz) del fst.
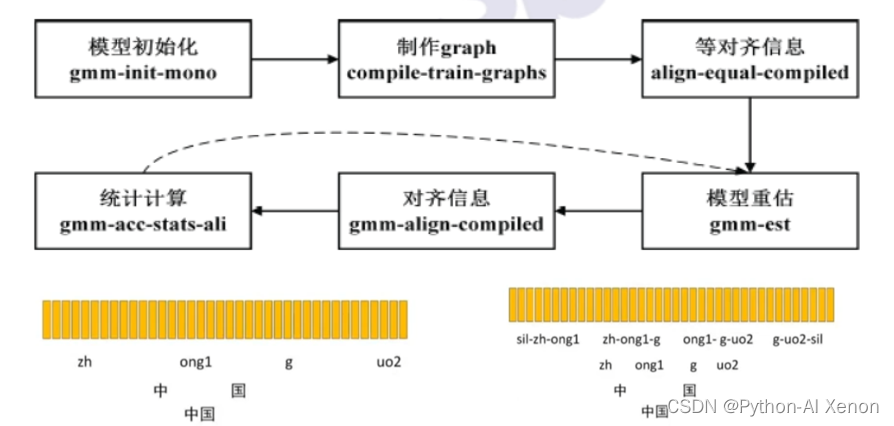
Una vez que hayamos completado los dos primeros pasos, es necesario alinear cómo usar las características que extrajimos para que se correspondan con el mapa FST que hicimos. El tercer paso utiliza alineación uniforme (alineación igual en la figura).Como se mencionó anteriormente, FST divide la oración del archivo de etiqueta en palabras, palabras, fonemas y luego el estado en HMM.
Para facilitar la comprensión, solo refinamos los fonemas en la imagen, dividimos la palabra (China) en caracteres (Zhongheguo) y luego la dividimos en fonemas (zh, ong1, g, uo2), cada palabra tiene 2 fonemas, un total de 4 fonemas, las barras verticales amarillas de arriba representan una característica de cuadro (característica MFCC), la alineación uniforme aquí es asumir que hay 4 fonemas y 100 características de cuadro, cada fonema se divide uniformemente en 25 características de cuadro, respectivamente Encuentra la media y la varianza de estas 25 características de cuadro, y puede obtener el modelo gaussiano correspondiente.
La parte inferior de la imagen es nuestro modelo trifónico (teniendo en cuenta la copronunciación), el modelo trifónico tiene una gran cantidad de datos, por lo que la agrupación de árboles de decisión se usa en kaldi para agrupar algunos fonemas con una pronunciación similar en una categoría. Luego, concéntrese en el entrenamiento. . Después de la alineación uniforme, volveremos a evaluar el modelo. El modelo de inicialización se selecciona aleatoriamente de parte de los datos de entrenamiento. Ahora hemos contado las características de todos los datos de audio y, a través de la alineación uniforme, el estado correspondiente y el salto de cada función de cuadro. probabilidad de giro. Con base en esta información, reevaluamos el modelo. El siguiente paso es alinear los datos con el modelo reevaluado (paso 5). En este momento, en lugar de usar una alineación uniforme, usamos las estadísticas después de la reevaluación. modelo Combinado con el fst anterior para generar nueva información de alineación, este proceso puede entenderse simplemente como un modelo que decodifica el conjunto de entrenamiento y coloca las características correspondientes a cada marco de datos en el GMM correspondiente a cada fonema o cada estado para calcular el probabilidad, el fonema con mayor probabilidad es el fonema correspondiente a este marco, como dijimos anteriormente, cada fonema corresponde a 25 marcos, después de este paso, el fonema correspondiente cambia (asumiendo que el primer fonema corresponde a 20 marcos). Con base en esta información de alineación, podemos calcular estadísticamente la relación entre la cantidad de saltos de cada fonema y la cantidad total de saltos, de modo que podamos volver a estimar la probabilidad de salto de cada estado en la red HMM y luego actualizar estos estados. probabilidades de transición y cada Después de la información de alineación de un marco, podemos volver a evaluar nuestro modelo GMM (salte del paso 6 al paso 4). De esta manera, el modelo se vuelve a evaluar repetidamente, se genera nueva información de alineación, la transición se calcula la probabilidad y luego se vuelve a evaluar el modelo. Nosotros establecemos el número específico de veces como esta, y el valor predeterminado es 40 veces.
train_mono.sh se usa para entrenar GMM
Echemos un vistazo a cómo se entrena el modelo monofónico en Kaldi llamando al script train_mono.sh en la carpeta de pasos. En particular, si usa parámetros de subprocesos múltiples, la cantidad de nj no puede exceder la cantidad de altavoces (spekerid), que divide la cantidad de subprocesos según la cantidad de altavoces.
uso de train_mono.sh:
./steps/train_mono.sh
Usage: steps/train_mono.sh [options] <data-dir> <lang-dir> <exp-dir>
e.g.: steps/train_mono.sh data/train.1k data/lang exp/mono
main options (for others, see top of script file)
--config <config-file> # config containing options
--nj <nj> # number of parallel jobs
--cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs.
Referencia: Primeros pasos con Kaldi en detalle documento oficial train_mono.sh
Primero prepara el entorno kaldi
. ~/kaldi/utils/path.sh
mkdir H_learn
cd ~/kaldi/data
luego ejecuta el script
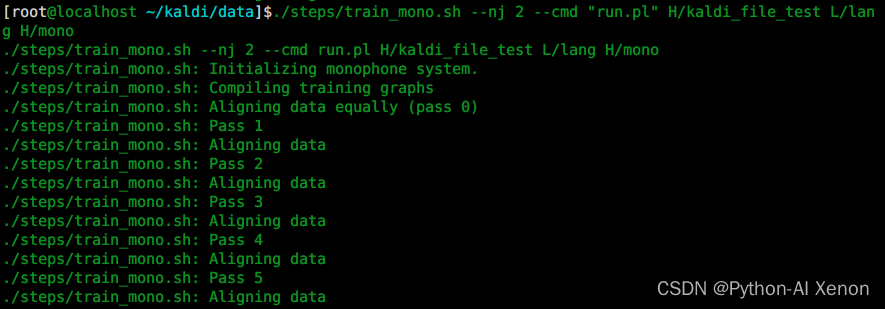
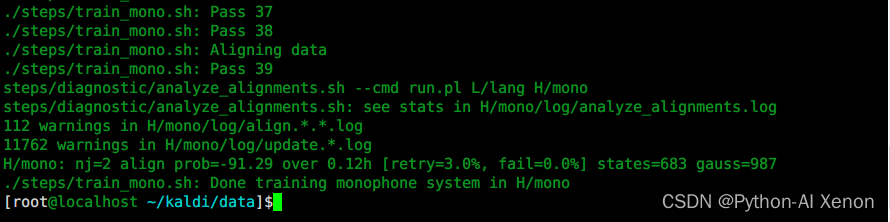
./steps/train_mono.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono
Explicación detallada del parámetro:
El primer parámetro: –nj Se entrenan varios subprocesos en paralelo ( nota: si se extraen las características de cada altavoz, el número de nj no puede exceder el número de altavoces ) El segundo parámetro: run.pl ejecuta el tercero Parámetros
locales
: carpeta de funciones (incluidas las funciones de cmvn y mfcc originales, consulte la publicación de blog de la columna cinco)
cuarto parámetro: carpeta lang (carpeta lang en la carpeta L)
quinto parámetro: carpeta de datos de entrenamiento GMM de salida (modelo monofónico)
Entrenar GMM—Generar archivos
Después de usar train_mono.sh para entrenar el modelo monofónico, generamos estos archivos. Lo primero y más importante es el modelo (mdl, donde 0.mdl representa el modelo inicializado; 40.mdl representa el resultado de 40 iteraciones; final.mdl representa el modelo final), seguido del archivo al final de occs, que puede entenderse simplemente como una estadística global, contando la información de cada fonema o cada fonema correspondiente a varios estados. ali..gz es la información de alineación, y la información de alineación se actualizará cada vez que se itere el modelo. fst..gz es información de cuadrícula, que es parte de la información FST que mencionamos anteriormente. tree es un árbol de decisión, que reúne algunos fonemas con pronunciación similar en una categoría, lo cual es conveniente para el cálculo. El registro es el registro generado durante el proceso de entrenamiento.Si ocurre un error durante el proceso de entrenamiento, básicamente puede encontrar el mensaje de error correspondiente en él.

*.mdl: el modelo 0.mdl representa el modelo inicializado, 40.mdl representa el resultado de 40 iteraciones, final.mdl representa el resultado final.
*.occs: el número de ocurrencias de cada pdf
ali.*.gz: información de alineación
fst.*.gz:
árbol de información de cuadrícula:
registro de árbol de decisión: registro de proceso de entrenamiento
Entrenamiento GMM: vista del modelo final
Convierta final.mdllos datos a texto y salida a final_mdl.txttexto (--binary=false significa no usar datos binarios)
gmm-copy --binary=false final.mdl final_mdl.txt
vim final_mdl.txt Abra el archivo de la siguiente manera:
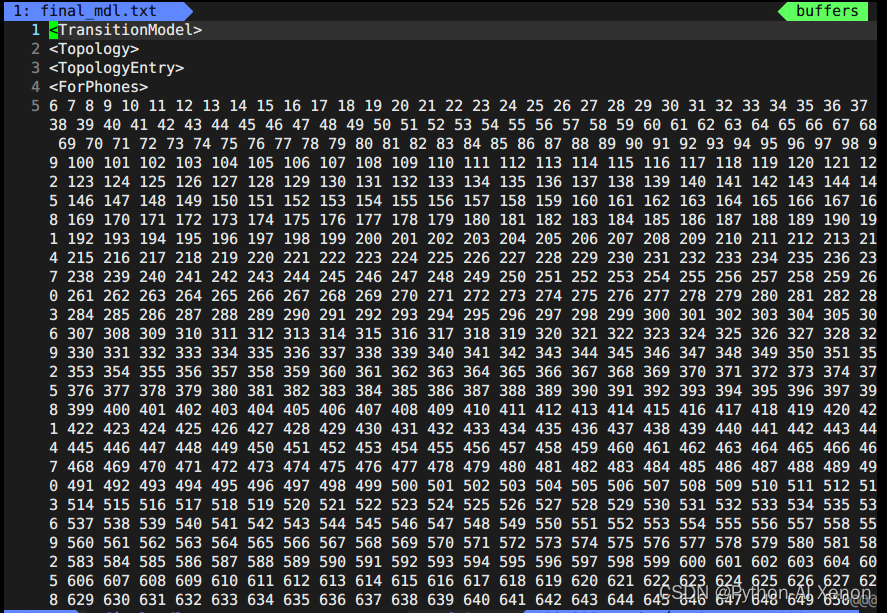
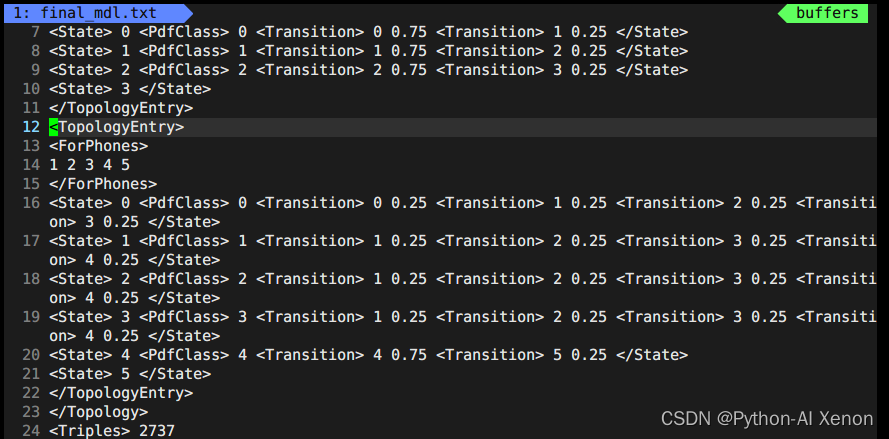
Esta parte de la información está en el archivo topo generado cuando generamos G.fst antes de las primeras 23 líneas. Podemos dibujar los estados HMM correspondientes, es decir, los estados 6-909 comparten un estado HMM3 y 1-5 (fonemas silenciosos) comparten un estado HMM5. La línea 24, 2727, representa el número de grupos de nuestro árbol de decisión. En la información del árbol de decisiones: la primera columna es el índice de fonemas (phone-id), la segunda columna es el estado HMM y la tercera columna es el índice PDF (clase del árbol de decisiones)
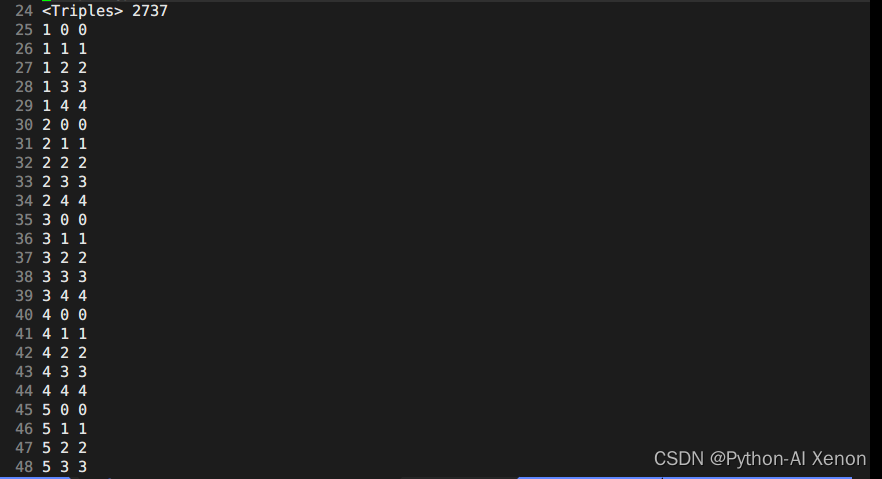
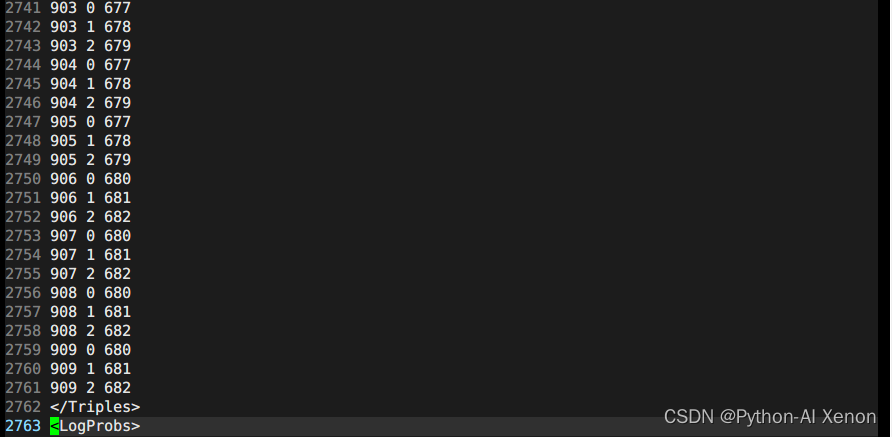
Podemos ver que nuestros fonemas tienen un total de 909, entonces, ¿por qué se pueden agrupar en 2737 categorías? Como se puede ver en la figura, desde la línea 25 hasta la línea 49 en la segunda columna de 25 líneas, todos pertenecen a fonemas mudos (¿por qué? Los números de serie son todos 0-4, 5 estados, solo los fonemas mudos tienen 5 estados) . Finalmente, podemos obtener la fórmula para el número de grupos como:
El número de clases del árbol de decisión = número de fonemas silenciosos * 5 + fonemas no silenciosos * 3


Dado que hay mucha otra información en el árbol de decisión, puede abrir la información del árbol de decisión local para verla usted mismo. La información en <LogProbs> es la probabilidad de transición de cada clase, y el número en <dimensión> es 3 veces la entrada característica (MFCC).Es porque las características de entrada han hecho una diferencia de primer orden y una diferencia de segundo orden, además de que la característica original es el número 39, <numpdfs> es el número de clases de nuestro árbol de decisión, y cada clase puede corresponder a un modelo de mezcla gaussiana (GMM). La siguiente es la descripción de los 656 GMM en la figura. La descripción de un modelo gaussiano solo necesita la media y la varianza (conócela). Si es un gaussiano mixto, se requieren múltiples combinaciones de gaussianas. Cada El peso de la gaussiana en el gaussiana mixta. Por ejemplo, hay 2 pesos en el peso <pesos> en la figura anterior, entonces significa que la gaussiana mixta que describe la probabilidad de este fonema está compuesta por 2 gaussianas individuales. Los pesos respectivos son XXX, XXX, el El promedio tiene 39 columnas, un Gaussiano corresponde a un promedio de 39 dimensiones y dos Gaussianos tienen dos promedios. Asimismo, la varianza es la misma. Además de los pesos, también hay un hiperparámetro <gconsts>, que también es un gaussiano correspondiente a uno. No hay demasiada introducción en profundidad aquí.
Capacitación de GMM: vista final.occs
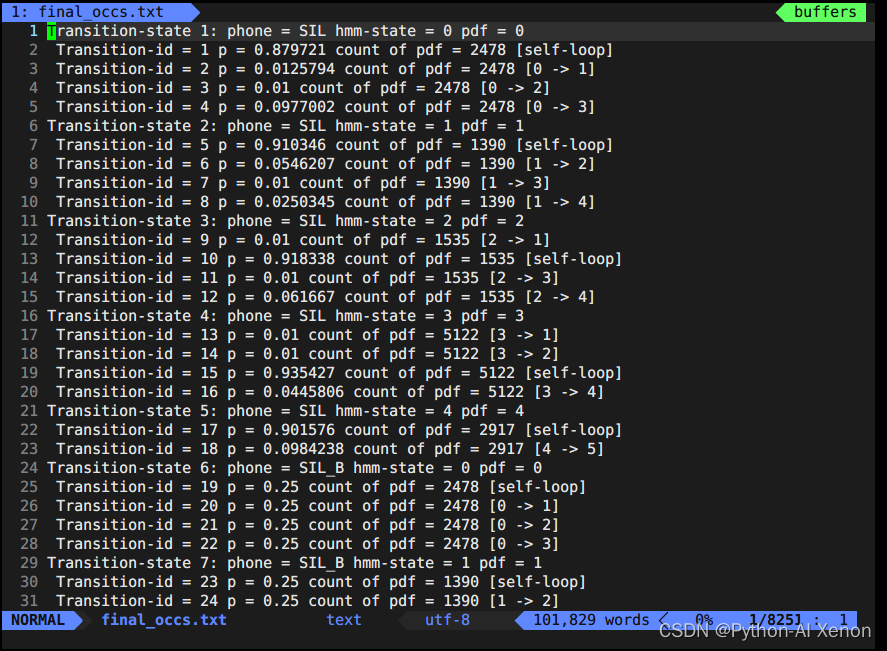
A continuación, veamos el archivo final.occs, que puede entenderse simplemente como una estadística global, que cuenta información sobre cada fonema oa cuántos estados corresponde cada fonema. Es decir, una descripción de cada red HMM. Mencionamos anteriormente que cada fonema se puede subdividir en BEIS (correspondientes a varios estados), sabemos que el fonema mudo HMM tiene 5 estados (BEIS + 5 estados de sí mismo), y el fonema no mudo BEI tiene 3 estados. occs es dividir cada fonema y hacer estadísticas por separado. Transition-state es una descripción de cada estado, donde el número en el recuento de pdf indica la cantidad de veces que aparece este borde.
Estadísticas de cada fonema o información de varios estados correspondientes a cada fonema
show-transitions phones.txt final.mdl final.occs > final_occs.txt
vim final_occs.txtAbra el archivo de la siguiente manera:
Capacitación de GMM: ver información de alineación
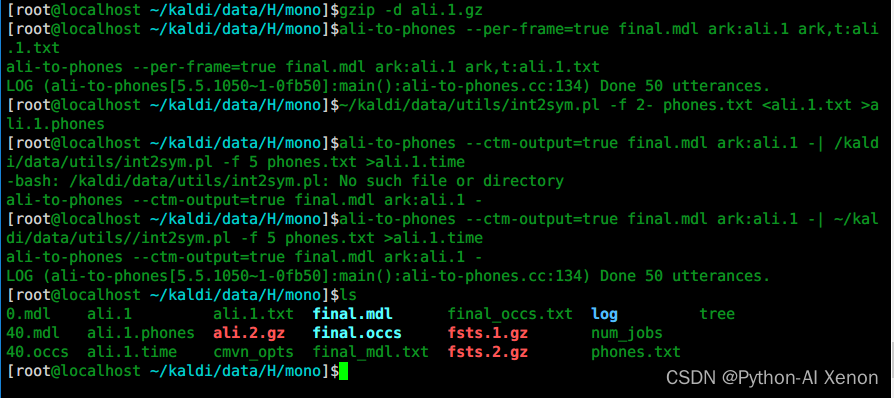
# 1 解压
gzip -d ali.1.gz
Las funciones se mencionan a nivel de marco, y el entrenamiento también se entrena a nivel de marco.¿Cuál es el resultado del entrenamiento? Puede usar el comando ali-to-phones para verificar qué marcos corresponden a qué fonema. Cada número en la figura representa una ID de fonema. Para facilitar la visualización, necesitamos convertir la ID de fonema al fonema correspondiente.
# 2 使用ali-to-phones进行查看
ali-to-phones --per-frame=true final.mdl ark:ali.1 ark,t:ali.1.txt
¿Cuál es el fonema correspondiente a cada phone-id? Use el script int2sym.pl para convertir la identificación del fonema al fonema correspondiente, y podemos ver la información de tiempo de cada fonema.
# 3 将音素id转换为对应的音素
~/kaldi/data/utils/int2sym.pl -f 2- phones.txt <ali.1.txt >ali.1.phones
¿Cuánto dura cada fonema? Por ejemplo, esta oración "fijó veintinueve grados", puede verificarla a través del software de visualización de audio. Dado que estamos usando un modelo de entrenamiento de un solo fonema, es posible que la alineación no sea completamente precisa, por lo que es necesario entrenar el modelo. repetidamente.
# 4 各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -| ~/kaldi/data/utils//int2sym.pl -f 5 phones.txt >ali.1.time
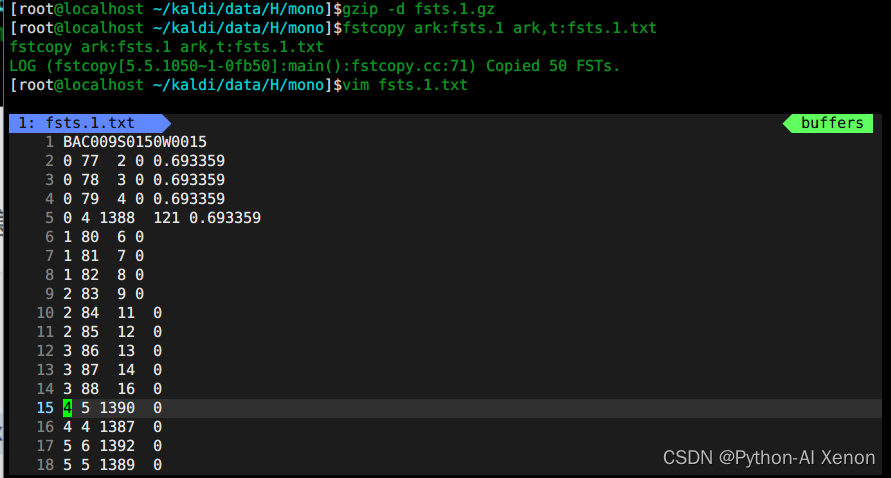
Formación GMM: vista fsts.*.gz
Lo que se almacena aquí es la primera información de estructura de red correspondiente a cada declaración, por lo que no entraré en detalles aquí.
# 1、解压
gzip -d fsts.1.gz
# 2、查看
fstcopy ark:fsts.1 ark,t:fsts.1.txt
vim fsts.1.txt
Entrenamiento de GMM: vista de árbol de decisión de árbol
- vista de texto
tree-info tree

num-pdfs 683 significa: el número de clases del árbol de decisión, que se dividen en 683 clases en
total.La
posición del árbol de decisión es 0, si es un fonema 3, aquí es 1 (central significa el fonema medio, el frente es 0, y la parte de atrás es 2)
- árbol de decisión visual
draw-tree phones.txt tree | dot -Gsize=8,10.5 -Tps | ps2pdf - tree.pdf
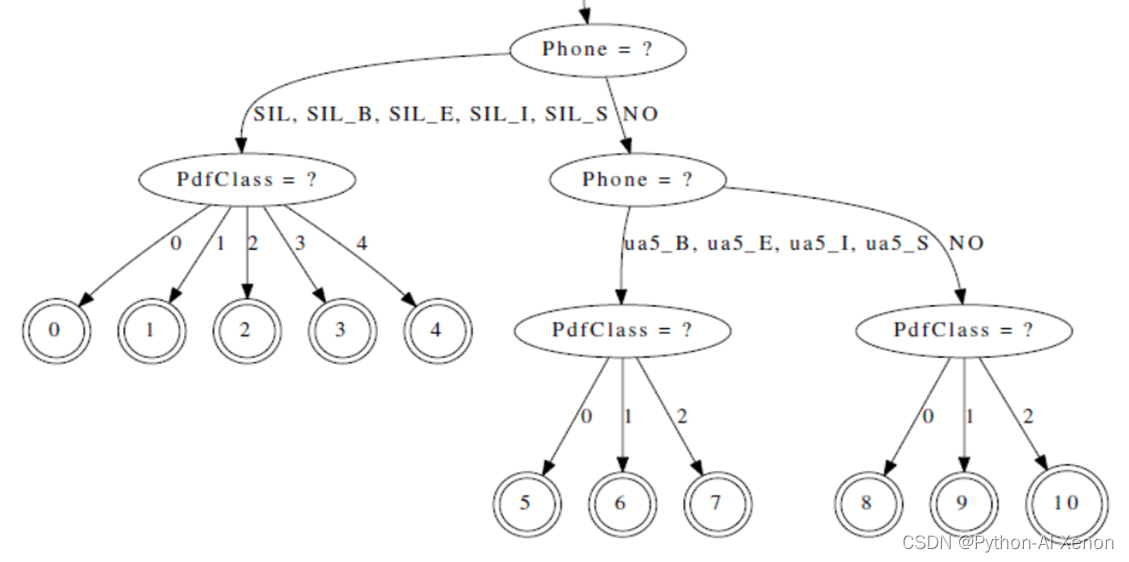
El árbol de decisión se puede dibujar visualmente a través del comando dibujar árbol. Dado que el árbol de decisión es muy grande, solo una parte de él se intercepta aquí y no se muestra completamente. Puede abrirlo en pdf para verlo. Como se puede ver en la figura anterior, el fonema silencioso SIL es un nodo hijo, correspondiente a 5 nodos (0-4 nodos), y el fonema ua5 corresponde a 3 nodos (5-7 nodos), lo que corresponde a lo mencionado arriba (5 estados para fonemas silenciados, 3 estados para fonemas no silenciados)
align_si.sh para la alineación
para alineación
Después de entrenar el modelo monofónico, podemos usar el modelo monofónico para alinear los datos de entrenamiento. El comando de alineación es align_si.sh, este es el segundo paso del modelo de entrenamiento GMM.
cd ~/kaldi/data
./steps/align_si.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono H/mono_ali
Explicación detallada del parámetro:
El primer parámetro: –nj Se entrenan varios subprocesos en paralelo ( nota: si se extraen las características de cada altavoz, el número de nj no puede exceder el número de altavoces ) El segundo parámetro: run.pl ejecuta el tercero Parámetros
locales
: carpeta de funciones (incluidas las funciones cmvn y mfcc originales)
cuarto parámetro: carpeta lang (carpeta lang en la carpeta L)
quinto parámetro: carpeta del modelo de entrenamiento monofónico
sexto parámetro: carpeta de datos después de la alineación para
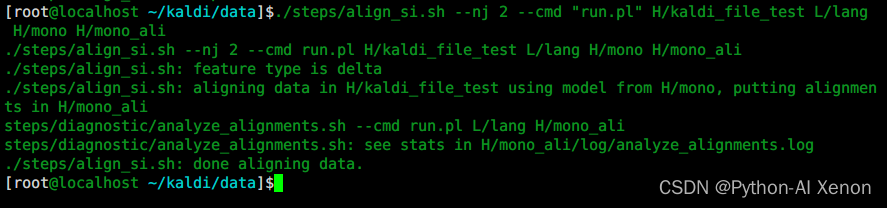
Entrenamiento GMM: vea el contenido generado por mono_ali.sh

# 1、解压
gzip -d ali.1.gz
# 2、生成各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -|~/kaldi/data/utils/int2sym.pl -f 5 phones.txt >ali.1.time
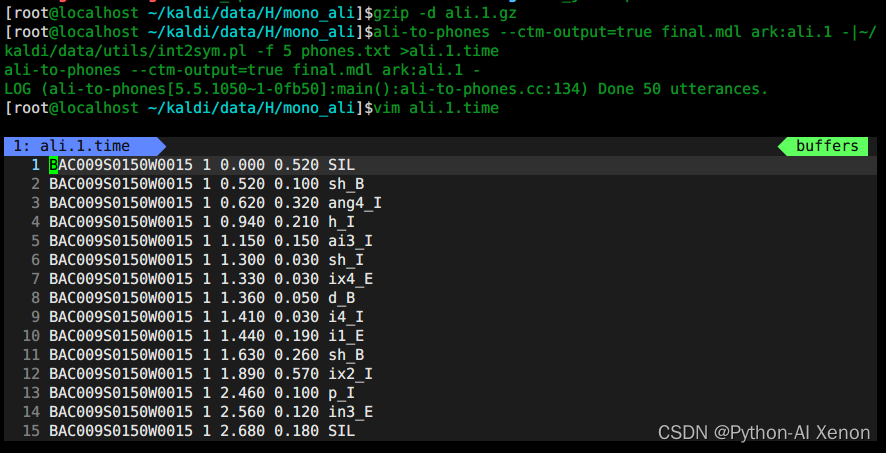
pd: Del mismo modo, también podemos usar el comando ali-to-phones para ver la información de alineación.
Entrenamiento de GMM: comparación de la información de alineación mono y mono_ali
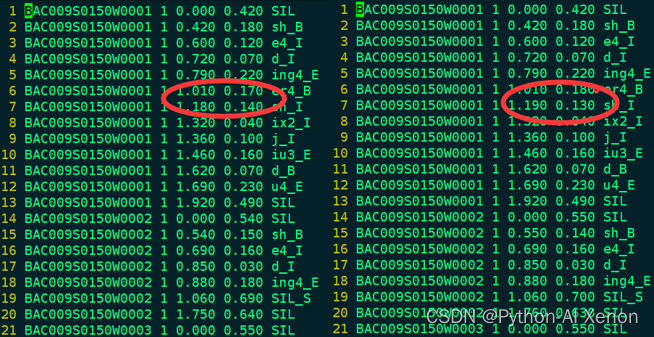
Podemos comparar nuestra información alineada con la información de alineación cuando entrenamos a Mono. Se puede ver que el número total de líneas de los dos archivos no es muy diferente, y la mayor parte de la información de alineación no es muy diferente, lo que indica que la capacidad de alineación de el modelo de monofono es asi, y necesita ser cambiado Nuevo algoritmo para mejorar la capacidad de alineacion del modelo.