Resumen e inducción para experimentos escolares de procesamiento de señales digitales;
Reconocimiento de voz
Los temas y los requisitos relacionados están aquí .
Preprocesamiento de datos
Pasos generales:
-
obtener audio en bruto

-
detección

-
Enmarcado

-
ventana

-
extracción de características

detección de punto final
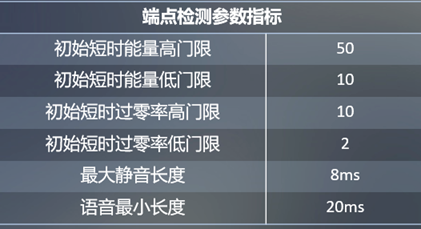
| Indicadores de parámetros de detección de puntos finales | valor relativo |
|---|---|
| Umbral alto inicial de energía a corto plazo | 50 |
| Umbral bajo de energía inicial a corto plazo | 10 |
| Umbral alto inicial de la tasa de cruce por cero a corto plazo | 10 |
| Umbral bajo inicial de la tasa de cruce por cero a corto plazo | 2 |
| Duración máxima del silencio | 8ms |
| Longitud mínima del discurso | 20ms |
Aquí estamos realizando un VAD basado en el umbral, extrayendo características en el dominio del tiempo (energía a corto plazo, tasa de cruce por cero a corto plazo, etc.) o el dominio de la frecuencia (MFCC, espectro, etc.) y estableciendo el umbral razonablemente. para lograr el propósito de distinguir el habla de la no habla.
El umbral de característica inicial de nuestra detección de punto final se muestra en la tabla de la derecha.A través de dichos indicadores, la información de audio que detectamos puede filtrar la mayor parte del ruido.
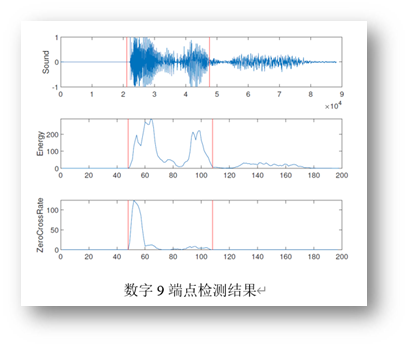
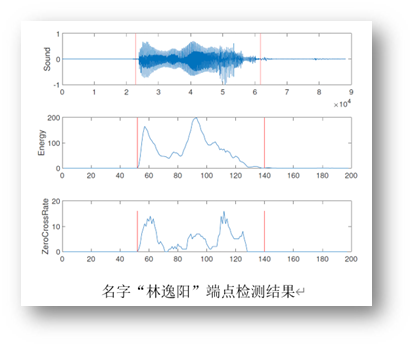
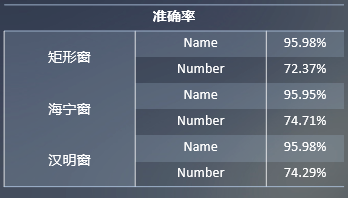
Los resultados de detección de doble extremo de algunas señales digitales y de nombre son los siguientes:
Enmarcado
Dado que la señal de voz tiene características estacionarias a corto plazo e invariantes en el tiempo, se analiza en un marco a corto plazo en el dominio del tiempo.
La longitud de la ventana de 30 ms y el cambio de marco de 10 ms utilizados en el experimento tienen mejores resultados.
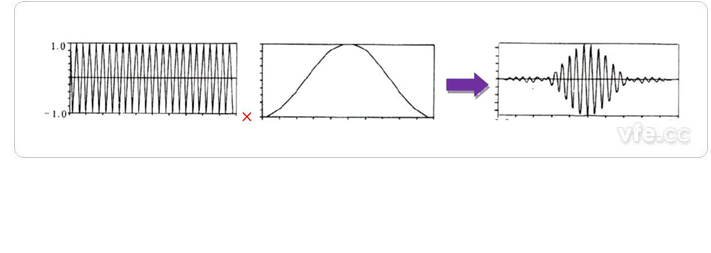
ventana
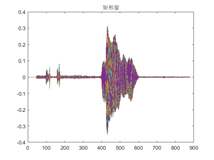
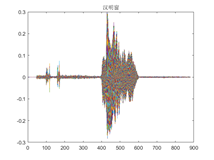
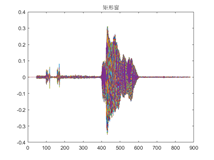
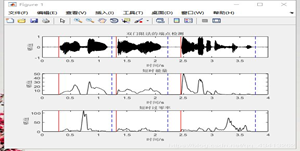
Hay diferencias en los gráficos obtenidos a través de diferentes retrasos en el procesamiento de la ventana, entre los cuales el cambio de la ventana rectangular es relativamente pronunciado y la transformación de la ventana de Hanning y la ventana de Hamming es relativamente estable.
- Señal en el dominio del tiempo después del procesamiento de ventana rectangular
- Señal en el dominio del tiempo después del procesamiento de la ventana de Hamming
- Señal en el dominio del tiempo procesada por la ventana de Haining

Reconocimiento de voz en el dominio del tiempo
Extraer funciones de voz
Los datos procesados se normalizan y se calcula el valor de característica de cada cuadro, y el número de cuadro se usa como la dimensión del vector de características para obtener el vector de características para la clasificación. El vector propio está compuesto por la tasa de cruce por cero, la energía y la magnitud.
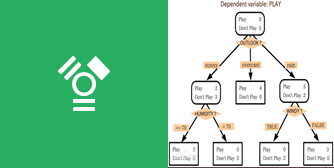
clasificador utilizado
-
Si la mayoría de los K vecinos más cercanos de una muestra en el espacio de características pertenecen a una determinada categoría, entonces la muestra también pertenece a esta categoría y tiene las características de esta categoría de muestras.

-
El modelo básico es un clasificador lineal con el mayor intervalo definido en el espacio de características, y el hiperplano se usa para dividir el conjunto de datos con el mayor intervalo para obtener la expresión del hiperplano.

-
A partir de conocer la probabilidad de ocurrencia de diversas situaciones se utiliza un método de análisis de decisiones para obtener la probabilidad de que el valor esperado del valor presente neto sea mayor o igual a 0 formando un árbol de decisión, evaluar el riesgo del proyecto, y juzgar su factibilidad.
-
Aprendizaje IntegradoBasado en KNN
-
El algoritmo de aprendizaje integrado completa la tarea de aprendizaje mediante la construcción y combinación de múltiples clasificadores y, por lo general, tiene una alta tasa de precisión, pero su desventaja es que el modelo es relativamente complejo.
-
Proceso de implementación
-
Muestrea aleatoriamente los valores propios de los datos originales al azar.
-
Envíe los datos de muestra a varios estudiantes de KNN para la toma de decisiones.
-
Todos los resultados se votan.
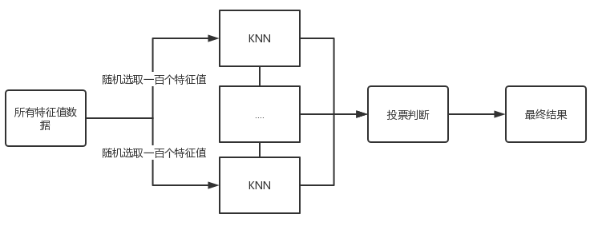
-
-
Análisis de voz en el dominio del tiempo
Las siguientes son la matriz discriminante y la curva AUC obtenidas por KNN, SVM, árbol de decisión y clasificador KNN de aprendizaje integrado.
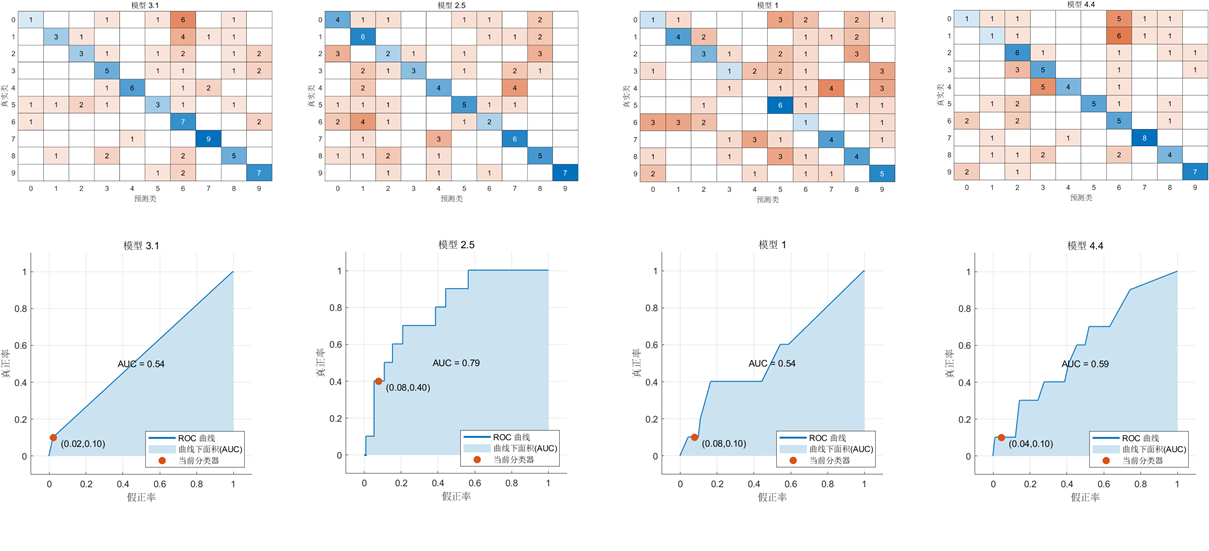
Los resultados son los siguientes:
| clasificador | Exactitud | Precisión | Tasa de error tipo I | Tasa de error tipo II | Puntuación F |
|---|---|---|---|---|---|
| KNN | 0.32 | 0.33 | 1.00 | 0.80 | 0.25 |
| MVS | 0.42 | 1.00 | 0.00 | 0,67 | 0.50 |
| Árbol | 0.37 | 0.50 | 0.25 | 0.50 | 0.50 |
| Aprendizaje integrado KNN | 0.44 | 0,60 | 0,67 | 0.25 | 0,67 |
Comparación de los efectos de diferentes métodos de ventanas
| tipo de ventana | Exactitud | Precisión | Tasa de error tipo I | Tasa de error tipo II | Puntuación F |
|---|---|---|---|---|---|
| ventana rectangular | 0.44 | 0.6 | 0,67 | 0.25 | 0,67 |
| ventana de hamming | 0.39 | 1 | 0 | 0..50 | 0,67 |
| Ventana de navegación | 0,45 | 0,67 | 1 | 0.6 | 0.5 |
Rendimiento de puntuación F: ventana rectangular = ventana de Hamming > ventana de Haining
El efecto de reconocimiento de señal de voz después del procesamiento de ventana rectangular es mejor
Reconocimiento de voz en el dominio de la frecuencia
proceso de experimento
-
Graba audio desde tu computadora.
-
Los datos de audio obtenidos se procesan previamente y los datos de audio ideales se obtienen a través de la detección de puntos finales.
-
Extraiga características MFCC de datos de audio.
-
Realice una búsqueda de algoritmo DTW.
-
Resumir los resultados obtenidos.
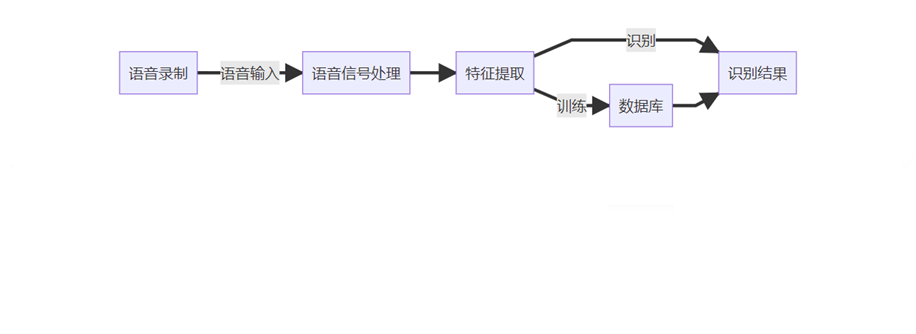
Extracción de características de MFCC
-
Enmarcado
-
FFT: Realice una transformada rápida de Fourier de 256 puntos en cada cuadro de voz.
-
Filtro de paso de banda triangular
-
Transformación de Coseno Discreta: Los coeficientes de Transformación de Coseno Discreta (DCT) se utilizan para concentrar energía en los primeros elementos para lograr el propósito de reducir los parámetros discriminantes y mejorar la velocidad de cálculo sin perder su precisión.
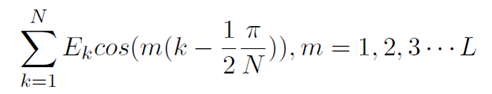
-
Parámetros de cepstrum de diferencia: parámetros de MFCC de diferencia de primer orden, que reflejan la conexión entre dos marcos adyacentes, por lo que fusionamos parámetros de mfcc y parámetros de mfcc de diferencia de primer orden para formar parámetros de MFCC, y eliminamos los dos primeros y últimos marcos para aumentar la precisión de MFCC parámetros, para mejorar el poder predictivo del experimento.

-
DTW
Análisis de voz en el dominio del tiempo
Usamos el método de validación cruzada, la proporción del conjunto de entrenamiento al conjunto de prueba es 9: 1. Después de 1000 experimentos repetidos, la precisión del reconocimiento de dígitos y el reconocimiento de nombres obtenidos bajo diferentes funciones de ventana es la siguiente. El eje x es el número de pruebas y el eje y es la tasa de precisión.
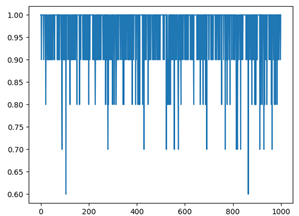
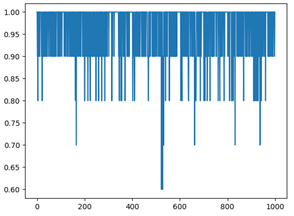
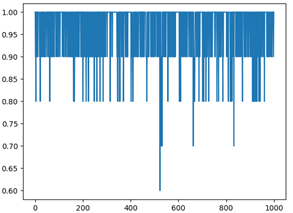
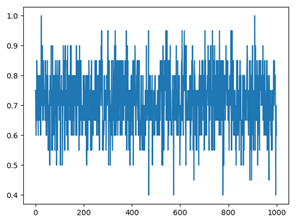
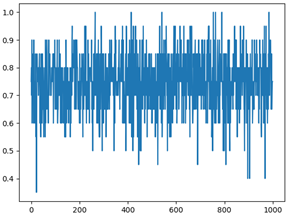
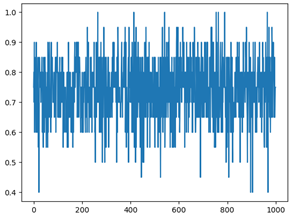
Como muestran las tasas de precisión de cada ventana rectangular en la tabla anterior, la tasa de precisión general del reconocimiento de dígitos debajo de la ventana rectangular es la más baja, mientras que las tasas de precisión del reconocimiento de dígitos debajo de la ventana de Hamming y la ventana de Haining no son muy diferentes. Sin embargo, la tasa de precisión del nombre bajo las tres ventanas no fluctúa mucho.
Videos relacionados:
Podemos encontrar que la detección de punto final solo puede detectar el primer carácter en el nombre durante el reconocimiento de nombre Esto se debe a que los parámetros de detección de punto final no se han ajustado.
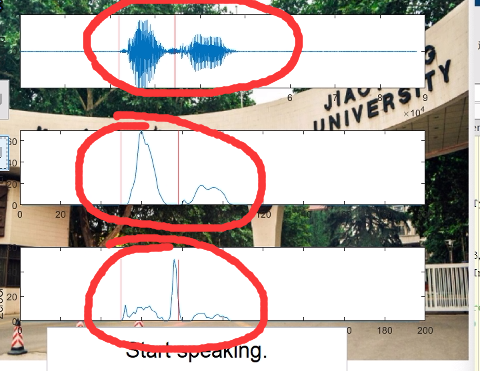
Después del segundo ajuste de parámetros:
Reconocimiento de huellas de voz basado en el modelo GMM
GMM
El modelo de mezcla gaussiana (GMM) es uno de los modelos más utilizados en el reconocimiento de huellas de voz, porque en el reconocimiento de huellas de voz, cómo resumir bien las características de la voz y cómo hacer coincidir la voz de prueba con la voz de entrenamiento son problemas muy complicados y difíciles de resolver. y GMM convierte estos problemas en problemas como la operación del modelo y el cálculo de probabilidad, y los resuelve. El modelo de mezcla de Gauss puede aproximar cualquier distribución de probabilidad continua, por lo que puede considerarse como un aproximador universal para distribuciones de probabilidad continuas. El modelo GMM es un proceso de formación supervisado. Su idea básica es utilizar los resultados de la muestra conocida para deducir los valores de los parámetros que tienen más probabilidades (es decir, la máxima probabilidad) de conducir al resultado.Bajo este principio, GMM suele utilizar el modelo de algoritmo de expectativa máxima (EM). iterar hasta converger para determinar los parámetros.
Nuestro trabajo
El procedimiento experimental es el siguiente:
En primer lugar, la señal de voz se procesa previamente mediante encuadres, ventanas y otros métodos. Después de obtener la señal de voz efectiva, la función MFCC de la señal de voz se extrae y se utiliza como entrada del modelo GMM para entrenar el modelo GMM. Finalmente, el El modelo GMM se prueba a través del equipo de prueba.
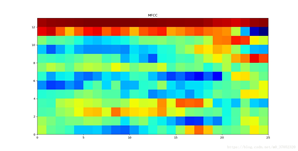
Use las funciones de MFCC de voz extraídas para entrenar el modelo GMM a través de la función fitgmdist para obtener las funciones de voz de cada persona
Error al transferir y volver a cargar para cancelar
Resultados del reconocimiento de oradores
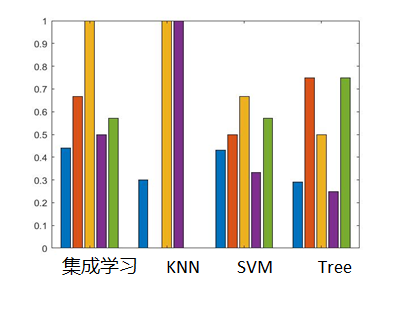
Colocamos la señal de voz de cada estudiante que lee el nombre y la señal de voz de cada estudiante que lee el número en el modelo GMM y SVM para entrenamiento y prueba respectivamente, y comparamos las ventajas y desventajas de los dos modelos.
Tenga en cuenta que la voz digital que se usa para el entrenamiento es I1, el nombre de voz que se usa para el entrenamiento es I2, la voz digital que se usa para la prueba es O1 y el nombre de voz que se usa para la prueba es O2. Usamos I1 e I2 como conjuntos de entrenamiento para el entrenamiento, y Para cada caso se probó la precisión con O1 y O2 respectivamente. Los resultados se muestran en la figura, se puede observar que cuando la voz del hablante es un nombre, el efecto de reconocimiento es mejor, pero cuando es un número, es pobre. Además, el efecto del modelo GMM es mejor que el del SVM. La precisión del conjunto de entrenamiento SVM es 1, mientras que la precisión del conjunto de prueba es baja y la capacidad de generalización del modelo es pobre, mientras que el GMM la capacidad de generalización es mejor.
Error al transferir y volver a cargar para cancelar
escrito en la espalda
El código correspondiente está en Copy2000/DSP_experiment: school experiment (github.com) , que es muy desordenado, eso es todo, y el video puede ser muy lento porque está colocado en el servidor de github.
También hay dos papeles pequeños: