prefacio
En estos días, de repente siento que la voz es un poco interesante. Me gustaría explorar algunas implementaciones con algunas bibliotecas.
Mira este tuit: La confesión cariñosa de esta IA explotó en Internet: No soy real, nunca he nacido, nunca moriré, ¿puedes amarme? , Siento que la voz de la síntesis del habla también puede ser muy emocional.
síntesis de voz
Text-to-Speech, abreviado como TTS
, tiene un registro anterior a la hoja de trucos del modelo de síntesis de voz (1)
pittx3
Antes que nada, descargue pyttsx, ya que el documento es 2.6, entonces aquí descargaré la versión 2.6 de pyttsx3
pip install pyttsx3==2.6
leer directamente
import pyttsx3
zh_voice_id = 'HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_ZH-CN_HUIHUI_11.0'
en_engine = pyttsx3.init() # 默认英文
zh_engine = pyttsx3.init()
zh_engine.setProperty('voice', zh_voice_id)
def say_text(engine, text):
show_engine_info(engine)
engine.say(text)
engine.runAndWait()
def show_engine_info(engine):
voices = engine.getProperty('voices')
for voice in voices:
print("Voice:")
print(" - ID: %s" % voice.id)
print(" - Name: %s" % voice.name)
print(" - Languages: %s" % voice.languages)
print(" - Gender: %s" % voice.gender)
print(" - Age: %s" % voice.age)
if __name__ == '__main__':
say_text(en_engine, 'I will study hard. Only in this way can I get a good remark.')
# say_text(zh_engine, '我觉得我没说谎') # 中文还是有问题
Volcado a archivo. Encontrado: el objeto 'Motor' no tiene el atributo 'save_to_file'
, etc. Tengo tiempo para mirar el código fuente de esta versión...
Voz rápida2
Enlace del proyecto https://github.com/ming024/FastSpeech2
Estoy ejecutando en colab Para modificar el portátil para la aceleración de GPU,
necesito cargar el ckpt del autor (por supuesto, puedo entrenarme, simplemente colóquelo directamente en el lugar designado) en el disco de red de Google.
def copy_pretrained_weight(ckpt_name, ckpt_share_path):
assert ckpt_name in ['LJSpeech', 'AISHELL3', 'LibriTTS']
if not os.path.exists('output'):
os.mkdir('output')
if not os.path.exists('output/ckpt'):
os.mkdir('output/ckpt')
dir_path = 'output/ckpt/{}'.format(ckpt_name)
if not os.path.exists(dir_path):
os.mkdir(dir_path)
shutil.copy(ckpt_share_path, dir_path)
copy_pretrained_weight('LibriTTS', '/content/drive/MyDrive/share/FastSpeech2/LibriTTS_800000.pth.tar')
Cambiar el nombre preentrenado
os.rename('/content/FastSpeech2/output/ckpt/LibriTTS/LibriTTS_800000.pth.tar',
'/content/FastSpeech2/output/ckpt/LibriTTS/800000.pth.tar')
Estoy ejecutando la versión de LibriTTS aquí, síntesis de voz en inglés para varias personas, de hecho, también hay una versión china de AISHELL3, solo mire readme.md para entender, no hablaré de eso aquí.
Luego, debe instalar la biblioteca en requirements.txt y descomprimir HiFiGAN, donde hifigan es el decodificador.
!unzip -d /content/FastSpeech2/hifigan /content/FastSpeech2/hifigan/generator_universal.pth.tar.zip
empezar a correr
!python3 synthesize.py --text "Want the stars and the sun, want the world to surrender, and want you by your side."\
--speaker_id 0 --restore_step 800000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
输出信息:
Eliminando la norma de peso...
Secuencia de texto sin procesar: Quiero las estrellas y el sol, quiero que el mundo se rinda y te quiero a tu lado
Secuencia de fonemas: {W AA1 NT DH AH0 ST AA1 RZ AE1 ND DH AH0 S AH1 N sp W AA1 NT DH AH0 W ER1 LDT AH0 S ER0 EH1 ND ER0 sp AE1 NDW AA1 NTY UW1 B AY1 Y AO1 RS AY1 D}
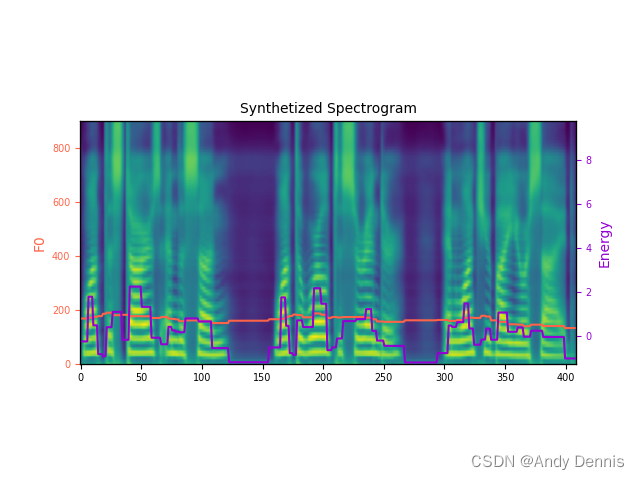
También genera dos archivos
Después de descargarlo localmente, búsquelo El espectro de Mel generado por esta oración. Además, el archivo .wav se puede reproducir directamente haciendo clic en él. (Usaré este archivo wav como ejemplo de ASR hh)
Reconocimiento de voz
Reconocimiento automático de voz (ASR para abreviar)
Esfinge de bolsillo
Originalmente quería instalarlo, pero el resultado fue un error, viendo otros blogs, parece que quiero instalar otras cosas, hazlo primero.
wenet
https://github.com/wenet-e2e/wenet
pip install wenet
Puede descargar estos archivos desde https://github.com/wenet-e2e/wenet/releases/download/ first
Por supuesto, tampoco puede especificar model_dir directamente, se descargará en C:/Users/Administrator/. wenet/

import sys
import wave
import wenet
def wav2text(test_wav, only_last=True):
with wave.open(test_wav, 'rb') as fin:
assert fin.getnchannels() == 1
wav = fin.readframes(fin.getnframes())
decoder = wenet.Decoder(lang='en', model_dir='.wenet/en')
# We suppose the wav is 16k, 16bits, and decode every 0.5 seconds
interval = int(0.5 * 16000) * 2
result = []
for i in range(0, len(wav), interval):
last = False if i + interval < len(wav) else True
chunk_wav = wav[i: min(i + interval, len(wav))]
ans = decoder.decode(chunk_wav, last)
result.append(ans)
if only_last:
return result[-1]
return result
if __name__ == '__main__':
test_wav = 'demo/demo.wav'
text = wav2text(test_wav)
print(text)
{ “nbest”: [{ “sentence”: “quiero que las estrellas y el sol quieran que el mundo se rinda y te quieran a tu lado” }], “type”: “final_result” }
Echa un vistazo a la salida y es (sin puntuación... es un problema)
quieren que las estrellas y el sol quieran que el mundo se rinda y te quieren a tu lado
原文:
Quiero las estrellas y el sol, quiero que el mundo se rinda y te quiero a tu lado.