El rápido desarrollo de la tecnología de reconocimiento de voz ofrece infinitas posibilidades para realizar aplicaciones más inteligentes. Este artículo tiene como objetivo presentar una aplicación sencilla de grabación de audio y reconocimiento de voz basada en Python. El artículo presenta brevemente la aplicación de tecnologías relacionadas, centrándose en la grabación de audio, mientras que el reconocimiento de voz se centra en llamar a bibliotecas de reconocimiento de voz relacionadas. Este artículo primero describirá algunos conceptos básicos de audio y luego explicará en detalle cómo usar la biblioteca PyAudio y la biblioteca SpeechRecognition para implementar funciones de grabación de audio. Finalmente, cree una aplicación de muestra de reconocimiento de voz simple, que pueda monitorear el inicio y el final del audio en tiempo real, y transmitir los datos de audio grabados a la biblioteca de reconocimiento de voz Whisper para el reconocimiento de voz, y finalmente enviar los resultados del reconocimiento al PyQt5 simple. -página basada.
Vea todo el código en este artículo: Python-Study-Notes
Directorio de artículos
0 Conceptos Básicos de Audio
Con el rápido desarrollo de la tecnología de aprendizaje profundo, el reconocimiento de voz de un extremo a otro se ha utilizado ampliamente. Sin embargo, todavía necesitamos tener una cierta comprensión de los conceptos más básicos relacionados con el audio, como la frecuencia de muestreo y el número de bits de muestreo. El sonido es una onda mecánica causada por un objeto que vibra, mientras que el audio es una representación electrónica del sonido. La codificación PCM (modulación de código de pulso) es un método común para convertir una señal de audio analógica a formato digital. En este proceso, el muestreo de audio se refiere a la recopilación del valor de amplitud del sonido a intervalos fijos durante un período de tiempo para convertir la señal analógica de sonido continuo en datos digitales discretos. La frecuencia de muestreo indica la cantidad de muestras tomadas por segundo, mientras que la cantidad de bits de muestreo indica el nivel de cuantificación de cada muestra, es decir, la finura y el rango dinámico del sonido. Para obtener una introducción detallada a los conceptos de audio, consulte: Conceptos básicos del audio digital a partir de PCM .
Frecuencia de muestreo
Las señales de audio suelen ser formas de onda analógicas continuas, que deben discretizarse para poder almacenarlas. Esto se logra mediante muestreo, es decir, midiendo la amplitud de la señal sonora en intervalos de tiempo fijos. El proceso de muestreo consiste en extraer el valor de frecuencia de cada punto de la señal analógica. Cuanto mayor sea la frecuencia de muestreo, es decir, cuantos más puntos de datos se extraigan en 1 segundo, mejor será la calidad del audio, pero también aumentará los costos de almacenamiento y procesamiento. El teorema de muestreo de Nyquist-Shannon enfatiza que la frecuencia de muestreo debe ser superior al doble de la frecuencia máxima de la señal para garantizar la recuperación completa de la señal analógica original a partir de los valores muestreados. En el campo del muestreo de señales de audio, se utilizan habitualmente dos frecuencias de muestreo principales: 16 kHz y 44,1 kHz.
Por ejemplo, 16 kHz significa 16.000 muestras por segundo, y la frecuencia del sonido del habla humana oscila entre 200 Hz y 8 kHz. La frecuencia de muestreo de 16 kHz es suficiente para capturar las características de frecuencia del habla humana, al tiempo que reduce la carga de almacenamiento y procesamiento de datos de audio. Por lo tanto, la frecuencia de muestreo de voz comúnmente utilizada es 16 kHz. El oído humano puede percibir sonidos de 20 Hz a 20 kHz. Para presentar audio de alta calidad, generalmente se selecciona una frecuencia de muestreo de 44,1 kHz para cubrir el límite superior del sonido audible humano.
Bits y canales de muestra
Una señal muestreada es un valor analógico continuo y, para convertirla a formato digital, es necesario cuantificar la señal. La cuantización es el mapeo de valores analógicos continuos a valores digitales discretos, generalmente utilizando un número fijo de bits de muestreo (como 16 o 24 bits) para representar el rango de amplitud de una muestra. Por ejemplo, utilice 16 bits (16 bits), es decir, señales binarias de doble byte para representar muestras de audio, y el rango de valores de 16 bits es de -32768 a 32767, y hay 65536 valores posibles en total. Por lo tanto, la señal de audio analógica final se divide en 65536 niveles numéricos de amplitud. Un mayor número de bits de muestreo puede representar una mayor gama de amplitudes de sonido y retener información más detallada. Las profundidades de bits más utilizadas incluyen 8 bits, 16 bits y 24 bits, siendo 8 bits el requisito mínimo, 16 bits para aplicaciones generales y 24 bits para trabajos de audio profesionales.
El canal se refiere al canal de transmisión de la señal de audio en el sistema de reproducción o sistema de grabación. Un canal generalmente corresponde a una única fuente de señal de audio o flujo de señal y es responsable de transmitir esa señal a los parlantes o equipos de grabación. En un sistema estéreo, normalmente hay dos canales, a saber, el canal izquierdo y el canal derecho, que se utilizan para procesar por separado las señales de sonido izquierda y derecha de la fuente de audio para lograr un efecto estéreo espacial. El concepto de canal de sonido también se puede extender a sistemas multicanal, como 5.1 canales, 7.1 canales, etc., que pueden admitir más fuentes de audio y una experiencia de sonido más rica, como el sonido envolvente.
Formatos de codificación de audio más utilizados
Los datos de audio obtenidos mediante la codificación PCM son los más originales y deben codificarse dos veces para su almacenamiento y transmisión en red. Estos formatos de codificación de audio secundarios se recodifican y comprimen según la codificación PCM y se dividen en compresión sin pérdidas y compresión con pérdidas según el método de compresión. La compresión sin pérdidas se refiere a preservar completamente la calidad del sonido de los datos de audio en relación con la codificación PCM. Sin embargo, los archivos de audio comprimidos sin pérdidas suelen ser un poco más grandes que los archivos de audio comprimidos con pérdidas. Compresión con pérdida En el proceso de codificación, para reducir el tamaño del archivo, se sacrifica la información y la calidad del sonido de algunos datos de audio.
Los formatos de codificación de audio comunes para compresión sin pérdidas incluyen: WAV/WAEV (formato de archivo de audio de forma de onda), FLAC (códec de audio gratuito sin pérdida), AIFF (formato de archivo de intercambio de audio), etc. Los formatos de codificación de audio comunes para compresión con pérdida incluyen: MP3 (MPEG Audio Layer III), AAC (Advanced Audio Coding), WMA (Windows Media Audio), etc.
Después de obtener los datos de audio codificados, es necesario utilizar un formato de archivo adecuado para guardar los datos codificados. Una codificación de audio puede corresponder a un formato de archivo o puede corresponder a varios formatos de archivo, generalmente uno. Por ejemplo, los datos codificados en WAV corresponden al formato de archivo .wav y los datos codificados en MP3 corresponden al formato de archivo .mp3. Los datos codificados en PCM corresponden al formato de archivo .raw o .pcm, y los datos codificados en AAC corresponden al formato de archivo .acc o .mp4, etc.
Comparación de conceptos de audio y vídeo
| concepto | audio | video |
|---|---|---|
| dimensión | La información sonora transmitida por ondas sonoras es unidimensional. | La información de la imagen en movimiento transmitida a través de la secuencia de imágenes es bidimensional. |
| características principales | Incluyendo tono, volumen, ritmo, etc., expresado por frecuencia y amplitud. | Incluyendo contenido de pantalla, color, etc., representado por píxeles y colores. |
| frecuencia de señal | En términos de frecuencia de muestreo, los seres humanos son más sensibles a la percepción del sonido, por lo que la frecuencia de muestreo de audio es mucho mayor que la velocidad de cuadros de video. | En términos de velocidad de fotogramas, el vídeo se reproduce a través de múltiples imágenes fijas a una velocidad determinada para simular una animación fluida. |
| Precisión de muestreo | Se utiliza para representar el valor de amplitud del sonido, común de 16 bits. | Se utiliza para representar el valor de color y brillo de la imagen, generalmente 8 bits (256 colores) |
| tecnología de procesamiento | Ecualización, compresión, reducción de ruido, etc. | Edición, efectos especiales, codec, etc. |
| pasillo | Expresado en canales, como mono y binaural | Expresado en canales de color, como GRIS, RGB, RGBA |
| almacenamiento | Fácil de transportar y almacenar, ocupa menos espacio | Requiere mayor espacio de almacenamiento y ancho de banda para transmitir y guardar |
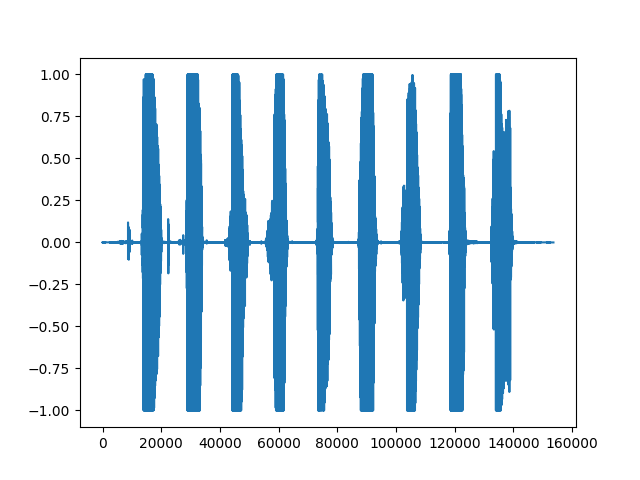
El siguiente código muestra la lectura de un archivo wav con un contenido de audio de 123456789 y el dibujo de una forma de onda de los datos de audio.
# 导入用于绘图的matplotlib库
from matplotlib import pyplot as plt
# 导入用于读取音频文件的soundfile库
# pip install soundfile
import soundfile as sf
# 从demo.wav文件中读取音频数据和采样率,data为numpy数组
data, samplerate = sf.read('asr_example_hotword.wav', dtype='float32')
# 保存音频
sf.write("output.wav", data=data, samplerate=samplerate)
# 打印音频数据的形状和打印采样率
# data为一个numpy数组,samplerate为一个整数
print('data shape: {}'.format(data.shape))
print('sample rate: {}'.format(samplerate))
# 绘制音频波形
plt.figure()
plt.plot(data)
plt.show()
El resultado de ejecutar el código es el siguiente, que representa el índice del punto de muestra de los datos de audio, es decir, el eje de tiempo del audio. Cada punto de muestra corresponde a cada cuadro de datos de audio, aumentando de izquierda a derecha. El eje vertical representa la intensidad de audio normalizada de la señal de audio en cada punto de tiempo. Los datos leídos se expresan en formato float32 y el rango de valores de muestreo numérico es -32678 ~ 32678. La biblioteca de archivos de sonido se dividirá por 32678 (2 ^ 16/2) para normalizar al intervalo [-1, 1].
1PyAudio
1.1 Introducción e instalación de PyAudio
PyAudio es una biblioteca de Python para procesar entrada y salida de audio, y la implementación de sus principales variables e interfaces depende de la versión en lenguaje C de PortAudio . PyAudio proporciona funciones para grabar audio desde un micrófono u otros dispositivos de entrada, guardar archivos de audio, procesar datos de audio en tiempo real y reproducir archivos de audio o transmisiones de audio en vivo. Además, PyAudio también le permite cumplir con diferentes requisitos de aplicaciones configurando parámetros como la frecuencia de muestreo, la profundidad de bits y la cantidad de canales, además de admitir funciones de devolución de llamada y mecanismos controlados por eventos. Consulte el sitio web oficial de PyAudio: PyAudio . La instalación de PyAudio requiere un entorno Python3.7 y superior.
El comando de instalación de PyAudio en Windows es el siguiente:
python -m pip install pyaudio
PyAudio en Linux sigue el comando de la siguiente manera:
sudo apt-get install python3-pyaudio
python -m pip install pyaudio
La versión de PyAudio utilizada en este artículo es 0.2.13.
1.2 Grabación y reproducción de audio
1.2.1 Reproducción de audio
El siguiente código muestra la reproducción de archivos de audio locales basados en PyAudio.
# wave为python处理音频标准库
import wave
import pyaudio
# 定义每次从音频文件中读取的音频采样数据点的数量
CHUNK = 1024
filepath = "demo.wav"
# 以音频二进制流形式打开音频文件
with wave.open(filepath, 'rb') as wf:
# 实例化PyAudio并初始化PortAudio系统资源
p = pyaudio.PyAudio()
# 打开音频流
# format: 指定音频流的采样格式。其中wf.getsampwidth()用于获取音频文件的采样位数(sample width)。
# 采样位数指的是每个采样点占用的字节数。通常情况下,采样位数可以是1字节(8位)、2字节(16位)等。
# channels:指定音频流的声道数。声道数可以是单声道(1)或立体声(2)
# rate:指定音频流的采样率。采样率表示每秒钟音频采样的次数,常见的采样率有44100Hz或16000Hz
# output:是否播放音频
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
# 从音频文件播放样本数据
while True:
# data为二进制数据
data = wf.readframes(CHUNK)
# len(data)表示读取数据的长度
# 在此len(data)应该等于采样点占用的字节数wf.getsampwidth()乘以CHUNK
if len(data):
stream.write(data)
else:
break
# 或者使用python3.8引入的海象运算符
# while len(data := wf.readframes(CHUNK)):
# stream.write(data)
# 关闭音频流
stream.close()
# 释放PortAudio系统资源
p.terminate()
1.2.2 Grabación de audio
El siguiente código muestra cómo llamar a la grabación del micrófono según PyAudio y guardar el resultado de la grabación como un archivo local.
import wave
import pyaudio
# 设置音频流的数据块大小
CHUNK = 1024
# 设置音频流的格式为16位整型,也就是2字节
FORMAT = pyaudio.paInt16
# 设置音频流的通道数为1
CHANNELS = 1
# 设置音频流的采样率为16KHz
RATE = 16000
# 设置录制时长为5秒
RECORD_SECONDS = 5
outfilepath = 'output.wav'
with wave.open(outfilepath, 'wb') as wf:
p = pyaudio.PyAudio()
# 设置wave文件的通道数
wf.setnchannels(CHANNELS)
# 设置wave文件的采样位数
wf.setsampwidth(p.get_sample_size(FORMAT))
# 设置wave文件的采样率
wf.setframerate(RATE)
# 打开音频流,input表示录音
stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True)
print('Recording...')
# 循环写入音频数据
for _ in range(0, RATE // CHUNK * RECORD_SECONDS):
wf.writeframes(stream.read(CHUNK))
print('Done')
stream.close()
p.terminate()
1.2.3 Grabación y reproducción de audio full duplex
Un sistema full-duplex (full-duplex) puede realizar una transmisión de datos bidireccional al mismo tiempo, mientras que un sistema semidúplex (half-duplex) solo puede realizar una transmisión de datos unidireccional al mismo tiempo. En un sistema semidúplex, cuando un dispositivo transmite datos, el otro dispositivo debe esperar a que se complete la transmisión antes de procesar los datos. El siguiente código demuestra la grabación y reproducción de audio full-duplex (full-duplex), es decir, la grabación y reproducción de audio al mismo tiempo sin esperar a que se complete una operación antes que otra.
import pyaudio
RECORD_SECONDS = 5
CHUNK = 1024
RATE = 16000
p = pyaudio.PyAudio()
# frames_per_buffer设置音频每个缓冲区的大小
stream = p.open(format=p.get_format_from_width(2),
channels=1,
rate=RATE,
input=True,
output=True,
frames_per_buffer=CHUNK)
print('recording')
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
# read读取音频然后writer播放音频
stream.write(stream.read(CHUNK))
print('done')
stream.close()
p.terminate()
1.3 El uso de la función de devolución de llamada
En el código anterior, PyAudio realiza la reproducción o grabación de audio de una manera que bloquea el hilo principal, lo que significa que el código no puede manejar otras tareas al mismo tiempo. Para resolver este problema, PyAudio proporciona una función de devolución de llamada que permite que el programa funcione sin bloqueo al realizar la entrada y salida de audio, es decir, procesar otras tareas mientras procesa la transmisión de audio. La función de devolución de llamada de PyAudio se ejecuta en un hilo separado. Cuando los datos de la transmisión de audio están disponibles, la función de devolución de llamada se llama automáticamente para procesar los datos de audio de inmediato. La función de devolución de llamada de PyAudio tiene una interfaz de parámetros fijos y la función se presenta de la siguiente manera:
def callback(in_data, # 录制的音频数据的字节流,如果没有录音则为None
frame_count, # 每个缓冲区中的帧数,本次读取的数据量
time_info, # 有关音频流时间信息的字典
status_flags) # 音频流状态的标志位
El siguiente código muestra la reproducción de audio como una función de devolución de llamada.
import wave
import time
import pyaudio
filepath = "demo.wav"
with wave.open(filepath, 'rb') as wf:
# 当音频流数据可用时,回调函数会被自动调用
def callback(in_data, frame_count, time_info, status):
# 读取了指定数量的音频帧数据
data = wf.readframes(frame_count)
# pyaudio.paContinue为常量,表示继续进行音频流的处理
# 根据需要更改为pyaudio.paAbort或pyaudio.paComplete等常量来控制处理流程的中断和结束
return (data, pyaudio.paContinue)
p = pyaudio.PyAudio()
# stream_callback设置回调函数
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True,
stream_callback=callback)
# 判断音频流是否处于活动状态
while stream.is_active():
time.sleep(0.1)
stream.close()
p.terminate()
El siguiente código muestra cómo utilizar la función de devolución de llamada para realizar el modo full-duplex de grabación y reproducción de audio. En caso de que se agote el tiempo de espera, cierre la transmisión de audio y libere los recursos relacionados llamando a stream.close(). Una vez que se cierra la transmisión de audio, no se pueden transmitir más datos de audio. Si desea continuar grabando después de una pausa durante un período de tiempo durante el proceso de grabación, puede usar stream.stop_stream() para suspender la transmisión de datos de la transmisión de audio, es decir, detener temporalmente la lectura y escritura de audio, pero mantener el objeto de flujo en el estado abierto. Posteriormente, la transmisión de datos del flujo de audio se puede reiniciar llamando a stream.start_stream().
import time
import pyaudio
# 录音时长
DURATION = 5
def callback(in_data, frame_count, time_info, status):
# in_data为麦克风输入的音频流
return (in_data, pyaudio.paContinue)
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(2),
channels=1,
rate=16000,
input=True,
output=True,
stream_callback=callback)
start = time.time()
# 当音频流处于活动状态且录音时间未达到设定时长时
while stream.is_active() and (time.time() - start) < DURATION:
time.sleep(0.1)
# 超过时长关闭音频流
stream.close()
p.terminate()
1.4 Gestión de dispositivos
PyAudio proporciona la Api del host y la Api del dispositivo para obtener dispositivos de audio, pero la Api del host y la Api del dispositivo representan diferentes niveles y funciones. detalles de la siguiente manera:
- Host Api: es una abstracción del sistema de audio subyacente, que representa la interfaz de audio disponible en el sistema y proporciona la función de interactuar con el dispositivo de audio subyacente. Cada API de host tiene sus propias características y un conjunto de funciones admitidas, como el formato de datos utilizado, la frecuencia de muestreo, etc. Las API de host comunes incluyen ALSA, PulseAudio, CoreAudio, etc.
- Api del dispositivo: se refiere a dispositivos de entrada o salida de audio específicos, como micrófonos, parlantes o auriculares. Cada dispositivo de audio pertenece a una API de host de audio específica y tiene diferentes configuraciones de parámetros, como frecuencia de muestreo, tamaño de búfer, etc.
Este artículo presenta principalmente la Api de dispositivo más utilizada. Las funciones de la Api de dispositivo en PyAudio son las siguientes:
-
get_device_info_by_index(index):
Obtenga la información detallada del dispositivo especificado a través de un índice entero. Esta función devuelve un diccionario que contiene información del dispositivo, incluido el nombre del dispositivo, el número de canales de entrada/salida, el rango de frecuencia de muestreo admitido, etc. -
get_default_input_device_info():
obtenga los detalles del dispositivo de entrada predeterminado. Esta función devuelve un diccionario que contiene información del dispositivo. -
get_default_output_device_info():
obtenga los detalles del dispositivo de salida predeterminado. Esta función devuelve un diccionario que contiene información del dispositivo. -
get_device_count():
Obtiene la cantidad de dispositivos de audio disponibles en la computadora, que pueden ser micrófonos, parlantes, interfaces de audio, etc.
El dispositivo predeterminado es el dispositivo de audio predeterminado del sistema operativo actual, y el dispositivo de entrada y salida de audio predeterminado se puede cambiar a través de la página de control de audio del sistema operativo. El siguiente código muestra el uso de estas funciones:
import pyaudio
# 获取指定设备的详细信息
def get_device_info_by_index(index):
p = pyaudio.PyAudio()
device_info = p.get_device_info_by_index(index)
p.terminate()
return device_info
# 获取默认输入设备的详细信息
def get_default_input_device_info():
p = pyaudio.PyAudio()
default_input_info = p.get_default_input_device_info()
p.terminate()
return default_input_info
# 获取默认输出设备的详细信息
def get_default_output_device_info():
p = pyaudio.PyAudio()
default_output_info = p.get_default_output_device_info()
p.terminate()
return default_output_info
# 获取计算机上可用音频设备的数量
def get_device_count():
p = pyaudio.PyAudio()
device_count = p.get_device_count()
p.terminate()
return device_count
# 示例用法
index = 0
print("可用音频设备数量:", get_device_count())
print("设备{}的信息:{}".format(index, get_device_info_by_index(index)))
print("默认录音设备的信息:", get_default_input_device_info())
print("默认播放设备的信息:", get_default_output_device_info())
Para el código anterior, el diccionario de información del dispositivo de reproducción predeterminado devuelto es el siguiente:
默认播放设备的信息:
{
'index': 3,
'structVersion': 2,
'name': '扬声器 (Realtek High Definition Au',
'hostApi': 0,
'maxInputChannels': 0,
'maxOutputChannels': 2,
'defaultLowInputLatency': 0.09,
'defaultLowOutputLatency': 0.09,
'defaultHighInputLatency': 0.18,
'defaultHighOutputLatency': 0.18,
'defaultSampleRate': 44100.0}
Este dispositivo también es el dispositivo de audio predeterminado actual del sistema y el significado de cada parámetro es el siguiente:
'index': 3: el número de índice del dispositivo, que se utiliza para identificar de forma única el dispositivo en la lista de dispositivos.'structVersion': 2: El número de versión de la estructura de información del dispositivo, utilizado para indicar la versión de la estructura de datos de la información del dispositivo.'name': '扬声器 (Realtek High Definition Au': El nombre del dispositivo, que indica que el dispositivo es un altavoz Realtek de alta definición.'hostApi': 0: Modo controlador de tarjeta de sonido del dispositivo, desde PortAudio, si desea saber más al respecto, consulte: hostApi en información de la tarjeta de sonido de pyaudio .'maxInputChannels': 0: El número máximo de canales de entrada admitidos por el dispositivo, donde 0 significa que el dispositivo no tiene función de entrada y no admite grabación.'maxOutputChannels': 2: El número máximo de canales de salida admitidos por el dispositivo, donde 2 significa que el dispositivo admite 2 canales de salida, es decir, se puede reproducir audio estéreo.'defaultLowInputLatency': 0.09: El retraso de entrada bajo predeterminado, en segundos, indica el tiempo mínimo requerido para que una señal de entrada de audio ingrese al dispositivo.'defaultLowOutputLatency': 0.09: El retraso de salida bajo predeterminado, en segundos, indica el tiempo mínimo requerido para que la señal de salida del dispositivo llegue a la salida de audio.'defaultHighInputLatency': 0.18: El retardo de entrada alto predeterminado, en segundos, indica el tiempo máximo requerido desde la señal de entrada de audio para ingresar al dispositivo.'defaultHighOutputLatency': 0.18: El retardo de salida alto predeterminado, en segundos, indica el tiempo máximo requerido para que la señal de salida del dispositivo llegue a la salida de audio.'defaultSampleRate': 44100.0: Frecuencia de muestreo predeterminada, lo que indica que la frecuencia de muestreo de audio predeterminada admitida por el dispositivo es 44100 hercios (Hz). Esta es la cantidad de muestras que toma el dispositivo de audio por unidad de tiempo, lo que afecta la calidad y el rango de frecuencia del sonido.
Si desea especificar un dispositivo para grabación o grabación de audio, especifique el índice del dispositivo en la función abierta, el código es el siguiente:
import pyaudio
p = pyaudio.PyAudio()
# 获取可用的设备数量
device_count = p.get_device_count()
# 遍历设备,打印设备信息和索引
for i in range(device_count):
device_info = p.get_device_info_by_index(i)
print(f"Device {
i}: {
device_info['name']}")
# 选择所需的录音设备的索引
input_device_index = 1
# 选择所需的播放设备的索引
output_device_index = 2
# 打开音频流,并指定设备
stream = p.open(format=p.get_format_from_width(2),
channels=1,
rate=16000,
input=True,
output=True,
input_device_index = input_device_index,
output_device_index = output_device_index)
# 操作输出设备和录音设备
# ...
2 Reconocimiento de voz
2.1 Introducción e instalación de SpeechRecognition
SpeechRecognition es una biblioteca de Python para reconocimiento de voz que admite múltiples motores de reconocimiento de voz para convertir audio en texto. La dirección del almacén de código abierto de SpeechRecognition es: Speech_recognition . Basado en la biblioteca PyAudio, SpeechRecognition encapsula funciones de grabación de audio más completas y completas. Este artículo presenta principalmente el uso de SpeechRecognition para grabar audio. La grabación de audio mediante SpeechRecognition requiere un entorno Python3.8 y superior, y una versión mínima de PyAudio 0.2.11. Después de instalar PyAudio, el comando de instalación de SpeechRecognition es el siguiente:
pip install SpeechRecognition
Las principales clases de SpeechRecognition son:
Datos de audio
La clase AudioData se utiliza para representar datos de voz, los principales parámetros y funciones son los siguientes:
parámetro
frame_data: datos de flujo de bytes de audiosample_rate: frecuencia de muestreo de audiosample_width: número de muestras de audio
función
get_segment: Devuelve el objeto AudioData de los datos de audio dentro del período de tiempo especificadoget_raw_data: devuelve el flujo de bytes sin procesar de los datos de audioget_wav_data: Devuelve el flujo de bytes en formato wav de los datos de audio.get_aiff_data: Devuelve el flujo de bytes en formato aiff de los datos de audio.get_flac_data: Devuelve el flujo de bytes en formato flac de los datos de audio.
Micrófono
La clase Micrófono es una clase que encapsula PyAudio y se utiliza para controlar las funciones del dispositivo de micrófono, por lo tanto, los parámetros de construcción y los principales parámetros y funciones de PyAudio son los siguientes:
parámetro
device_index: El número de índice del dispositivo de micrófono, si no se especifica, utilizará la configuración de entrada de audio predeterminada de PyAudio.format: El formato de muestra es un entero de 16 bits; si no se especifica, se utilizará la configuración de entrada de audio predeterminada de PyAudio.SAMPLE_WIDTH: El número de muestras de audio; si no se especifica, se utilizará la configuración de entrada de audio predeterminada de PyAudio.SAMPLE_RATE: La frecuencia de muestreo, no especificada, utilizará la configuración de entrada de audio predeterminada de PyAudioCHUNK: Número de fotogramas almacenados en cada búfer, el valor predeterminado es 1024audio: objeto PyAudiostream: La transmisión de audio se abrió llamando a la función de apertura de PyAudio
función
get_pyaudio: Se utiliza para obtener el número de versión de PyAudio y llamar a la biblioteca de PyAudio.list_microphone_names: Devuelve una lista de los nombres de todos los dispositivos de micrófono disponibles en el sistema actuallist_working_microphones: Devuelve una lista de los nombres de todos los dispositivos de micrófono que funcionan en el sistema actual. El funcionamiento de un dispositivo de micrófono se evalúa, para un determinado dispositivo, al intentar grabar un breve segmento de audio y luego verificar si los datos de audio con una cierta cantidad de energía de audio se graban con éxito.
Clase de reconocedor
La clase Recognizer es la clase principal para el reconocimiento de voz. Proporciona una serie de parámetros y funciones para procesar la entrada de audio. Los principales parámetros y funciones son los siguientes:
parámetro
energy_threshold = 300: Se utiliza para grabar la energía de audio más baja, según la raíz cuadrática media de audio RMS para calcular la energía.dynamic_energy_threshold = True: Si se debe utilizar el umbral de energía dinámicadynamic_energy_adjustment_damping = 0.15: coeficiente de amortiguación para el ajuste del umbral de energíadynamic_energy_ratio = 1.5: relación de energía dinámicapause_threshold = 0.8: Duración en segundos de audio sin voz antes de que se considere terminada una frase completaoperation_timeout = None: Tiempo de espera (en segundos) después de que se inicia la operación interna (como una solicitud de API). Si no se establece ningún tiempo de espera, seráNonephrase_threshold = 0.3: La duración mínima (en segundos) requerida para que se considere un discurso; el discurso por debajo de este valor se ignorará (se usa para filtrar el ruido).non_speaking_duration = 0.5: Duración del audio que no es de voz en segundos
función
record: leer datos de una fuente de audioadjust_for_ambient_noise: se utiliza para ajustar automáticamente el parámetro umbral_energía según el nivel de ruido ambiental del micrófono antes de grabar audio.listen: Grabación de audio, el resultado devuelve la clase AudioDatalisten_in_background: Se utiliza para grabar audio en segundo plano y llamar a la función de devolución de llamada.
La función de escucha de la clase Recognizer se divide en tres etapas para cada grabación:
-
Inicio de grabación
Esta fase significa que se inicia la grabación pero no se introduce ningún sonido. Si el valor de energía del fragmento de sonido obtenido actualmente es inferior aenergy_threshold, se considera que no hay entrada de sonido. Una vez que el valor de energía del clip de sonido obtenido actualmente sea superior aenergy_threshold, ingrese a la siguiente etapa. Esta etapa guardará hastanon_speaking_durationla duración del clip de audio. Si esdynamic_energy_thresholdVerdadero, se ajustará dinámicamente según el entornoenergy_threshold.
La función de escucha proporciona parámetros de entradatimeoutpara controlar la duración de esta etapa. Si la grabación permanece en esta etapatimeoutdurante segundos, la grabación se detendrá y se devolverá un mensaje de error.timeoutEl valor predeterminado es Ninguno. -
Grabación
Esta etapa significa que hay entrada de sonido. Si el valor de energía del clip de sonido cae por debajoenergy_thresholdcontinuamente durante más depause_threshold2 segundos, la grabación finaliza. En esta etapa, el umbral_energía siempre ha sido un valor fijo y no se ajustará dinámicamente.
La función de escucha proporciona parámetros de entradaphrase_time_limitpara controlar la duración máxima de esta etapa, y laphrase_time_limitgrabación finalizará si la grabación permanece en esta etapa durante segundos. -
Fin de grabación
En esta etapa, si el tiempo del segmento de sonido obtenido en la etapa de grabación es inferior aphrase_threshold2 segundos, no se devolverá el resultado de la grabación y se ingresará a la siguiente etapa de inicio de grabación. Si excede losphrase_thresholdsegundos, convierta el clip de audio en una secuencia de audio y devuélvalo como un objeto AudioData.
2.2 Código de muestra
grabación de audio
import speech_recognition as sr
# 创建一个Recognizer对象,用于语音识别
r = sr.Recognizer()
# 设置相关阈值
r.non_speaking_duration = 0.3
r.pause_threshold = 0.5
# 创建一个Microphone对象,设置采样率为16000
# 构造函数所需参数device_index=None, sample_rate=None, chunk_size=1024
msr = sr.Microphone(sample_rate=16000)
# 打开麦克风
with msr as source:
# 如果想连续录音,该段代码使用for循环
# 进行环境噪音适应,duration为适应时间,不能小于0.5
# 如果无噪声适应要求,该段代码可以注释
r.adjust_for_ambient_noise(source, duration=0.5)
print("开始录音")
# 使用Recognizer监听麦克风录音
# phrase_time_limit=None表示不设置时间限制
audio = r.listen(source, phrase_time_limit=None)
print("录音结束")
# 将录音数据写入.wav格式文件
with open("microphone-results.wav", "wb") as f:
# audio.get_wav_data()获得wav格式的音频二进制数据
f.write(audio.get_wav_data())
# 将录音数据写入.raw格式文件
with open("microphone-results.raw", "wb") as f:
f.write(audio.get_raw_data())
# 将录音数据写入.aiff格式文件
with open("microphone-results.aiff", "wb") as f:
f.write(audio.get_aiff_data())
# 将录音数据写入.flac格式文件
with open("microphone-results.flac", "wb") as f:
f.write(audio.get_flac_data())
lectura de archivos de audio
# 导入speech_recognition库,别名为sr
import speech_recognition as sr
# 创建一个Recognizer对象r,用于语音识别
r = sr.Recognizer()
# 设置音频文件路径
filepath = "demo.wav"
# 使用AudioFile打开音频文件作为音频源
with sr.AudioFile(filepath) as source:
# 使用record方法记录从音频源中提取的2秒音频,从第1秒开始
audio = r.record(source, offset=1, duration=2)
# 创建一个文件用于保存提取的音频数据
with open("microphone-results.wav", "wb") as f:
# 将提取的音频数据写入文件
f.write(audio.get_wav_data())
El uso de funciones de devolución de llamada.
import time
import speech_recognition as sr
# 这是从后台线程调用的回调函数
def callback(recognizer, audio):
# recognizer是Recognizer对象的实例。audio是从麦克风捕获到的音频数据
print(type(audio))
r = sr.Recognizer()
m = sr.Microphone()
with m as source:
# 我们只需要在开始监听之前校准一次
r.adjust_for_ambient_noise(source)
# 在后台开始监听
stop_listening = r.listen_in_background(m, callback)
# 进行一些无关的计算,持续5秒钟
for _ in range(50):
# 即使主线程正在做其他事情,我们仍然在监听
time.sleep(0.1)
# 调用此函数请求停止后台监听
stop_listening(wait_for_stop=False)
Vista del dispositivo de micrófono
import speech_recognition as sr
# 获取麦克风设备名称列表
def list_microphone_names():
mic_list = sr.Microphone.list_microphone_names()
for index, mic_name in enumerate(mic_list):
print("Microphone {}: {}".format(index, mic_name))
print("\n")
# 获取可用的工作麦克风列表
def list_working_microphones():
mic_list = sr.Microphone.list_working_microphones()
for index, mic_name in mic_list.items():
print("Microphone {}: {}".format(index, mic_name))
print("\n")
# 获得pyaudio对象
def get_pyaudio():
audio = sr.Microphone.get_pyaudio().PyAudio()
# 获取默认音频输入设备信息
print(audio.get_default_input_device_info())
print("\n")
return audio
print("所有麦克风列表")
list_microphone_names()
print("可运行麦克风列表")
list_working_microphones()
print("默认音频输入设备信息")
get_pyaudio()
3 Ejemplo de aplicación de reconocimiento de voz
Este ejemplo proporciona una aplicación de muestra de reconocimiento de voz sin transmisión basada en la biblioteca SpeechRecognition y la biblioteca de reconocimiento de voz Whisper. En términos generales, el reconocimiento de voz se divide en reconocimiento de voz en streaming y reconocimiento de voz sin streaming:
- La transmisión de reconocimiento de voz se refiere a realizar el reconocimiento de voz en tiempo real durante el proceso de entrada de voz, es decir, generar los resultados del reconocimiento mientras se reciben datos de voz, para lograr un reconocimiento de voz con un alto rendimiento en tiempo real. En el reconocimiento de voz por transmisión, la voz se divide en pequeños flujos y los resultados del reconocimiento se pueden obtener en tiempo real enviando estos flujos continuamente. A medida que aumenta la entrada de voz, el reconocimiento de voz en streaming también puede optimizar la salida de resultados parciales. El reconocimiento de voz en streaming tiene una tasa de precisión relativamente baja, pero es altamente en tiempo real y es adecuado para escenarios que requieren una respuesta rápida, como asistentes de voz en tiempo real, servicio telefónico al cliente, registros de reuniones, etc. Técnicamente, el reconocimiento de voz en streaming necesita procesar transmisiones de audio en tiempo real, lo que requiere algoritmos con baja latencia y alto rendimiento, y normalmente utiliza varias estrategias de optimización para mejorar el rendimiento en tiempo real.
- El reconocimiento de voz sin transmisión se refiere a analizar y reconocer la entrada de voz completa de una vez después de esperar a que finalice la entrada de voz. El reconocimiento de voz sin transmisión tiene alta precisión y es adecuado para algunos escenarios que no requieren respuesta en tiempo real o no reconocen todo el habla a la vez, como reconocimiento de comandos, transcripción de voz, búsqueda de voz, traducción de voz, etc. Técnicamente, el reconocimiento de voz sin transmisión se centra en la precisión general y la comprensión semántica del habla y, por lo general, utiliza modelos y algoritmos complejos para mejorar la precisión del reconocimiento.
Whisper es la biblioteca de modelos de reconocimiento de voz multilingüe general de código abierto de OpenAI. Whisper utiliza un modelo Transformer de secuencia a secuencia que admite el reconocimiento de voz en varios idiomas y su nivel de reconocimiento de inglés es cercano al de los humanos. Para la instalación y el uso de Whisper, consulte el repositorio de código abierto de Whisper o el artículo de referencia: Tutorial de voz a texto de Whisper . El ejemplo de reconocimiento de voz proporcionado implementa una detección simple de inicio y finalización de voz, y realiza el reconocimiento de voz correspondiente y la visualización de resultados. La estructura del código del programa es la siguiente:
.
├── asr.py 语音识别类
├── record.py 录音类
└── run.py 界面类
Después de instalar la biblioteca SpeechRecognition y la biblioteca Whisper, ejecute el archivo run.py para abrir la aplicación de muestra.
clase de interfaz
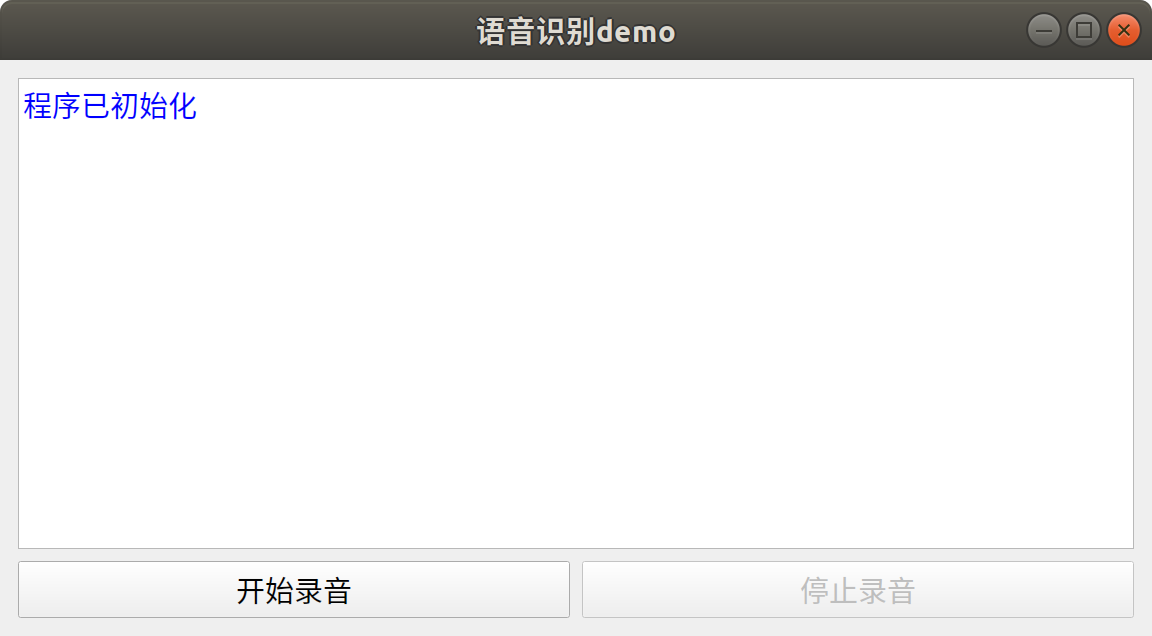
La clase de interfaz proporciona una interfaz de aplicación simple escrita en base a PyQt5, como se muestra a continuación. Cuando se inicializa la interfaz, la clase de grabación y la clase de reconocimiento de voz se inicializarán al mismo tiempo. Después de hacer clic en el botón Iniciar grabación, el programa monitoreará automáticamente el principio y el final del audio hablado en un bucle. Después de cada discurso, el programa realizará automáticamente el reconocimiento de voz y mostrará los resultados del reconocimiento en la interfaz. Al hacer clic en el botón Detener, se esperará a que finalice la grabación y se detendrá el monitoreo de voz.
# run.py
from PyQt5 import QtGui
from PyQt5.QtWidgets import *
from PyQt5.QtCore import QSize, Qt
import sys
from record import AudioHandle
class Window(QMainWindow):
"""
界面类
"""
def __init__(self):
super().__init__()
# --- 设置标题
self.setWindowTitle('语音识别demo')
# --- 设置窗口尺寸
# 获取系统桌面尺寸
desktop = app.desktop()
# 设置界面初始尺寸
self.width = int(desktop.screenGeometry().width() * 0.3)
self.height = int(0.5 * self.width)
self.resize(self.width, self.height)
# 设置窗口最小值
self.minWidth = 300
self.setMinimumSize(QSize(self.minWidth, int(0.5 * self.minWidth)))
# --- 创建组件
self.showBox = QTextEdit()
self.showBox.setReadOnly(True)
self.startBtn = QPushButton("开始录音")
self.stopBtn = QPushButton("停止录音")
self.stopBtn.setEnabled(False)
# --- 组件初始化
self.initUI()
# --- 初始化音频类
self.ahl = AudioHandle()
# 连接用于传递信息的信号
self.ahl.infoSignal.connect(self.showInfo)
self.showInfo("<font color='blue'>{}</font>".format("程序已初始化"))
def initUI(self) -> None:
"""
界面初始化
"""
# 设置整体布局
mainLayout = QVBoxLayout()
mainLayout.addWidget(self.showBox)
# 设置底部水平布局
blayout = QHBoxLayout()
blayout.addWidget(self.startBtn)
blayout.addWidget(self.stopBtn)
mainLayout.addLayout(blayout)
mainWidget = QWidget()
mainWidget.setLayout(mainLayout)
self.setCentralWidget(mainWidget)
# 设置事件
self.startBtn.clicked.connect(self.record)
self.stopBtn.clicked.connect(self.record)
def record(self) -> None:
"""
录音控制
"""
sender = self.sender()
if sender.text() == "开始录音":
self.stopBtn.setEnabled(True)
self.startBtn.setEnabled(False)
# 开启录音线程
self.ahl.start()
elif sender.text() == "停止录音":
self.stopBtn.setEnabled(False)
# waitDialog用于等待录音停止
waitDialog = QProgressDialog("正在停止录音...", None, 0, 0)
waitDialog.setWindowTitle("请等待")
waitDialog.setWindowModality(Qt.ApplicationModal)
waitDialog.setCancelButton(None)
waitDialog.setRange(0, 0)
# 设置 Marquee 模式
waitDialog.setWindowFlag(Qt.WindowContextHelpButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowCloseButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowMaximizeButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowMinimizeButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowTitleHint, False)
# 关闭对话框边框
waitDialog.setWindowFlags(self.windowFlags() | Qt.FramelessWindowHint)
# 连接关闭信号,即ahl线程结束则waitDialog关闭
self.ahl.finished.connect(waitDialog.accept)
# 结束录音线程
self.ahl.stop()
if self.ahl.isRunning():
# 显示对话框
waitDialog.exec_()
# 关闭对话框
self.ahl.finished.disconnect(waitDialog.accept)
waitDialog.close()
self.startBtn.setEnabled(True)
def showInfo(self, text: str) -> None:
"""
信息展示函数
:param text: 输入文字,可支持html
"""
self.showBox.append(text)
if not self.ahl.running:
self.stopBtn.click()
def closeEvent(self, event: QtGui.QCloseEvent):
"""
重写退出事件
:param event: 事件对象
"""
# 点击停止按钮
if self.ahl.running:
self.stopBtn.click()
del self.ahl
event.accept()
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = Window()
# 获取默认图标
default_icon = app.style().standardIcon(QStyle.SP_MediaVolume)
# 设置窗口图标为默认图标
ex.setWindowIcon(default_icon)
ex.show()
sys.exit(app.exec_())
Grabación
La clase de grabación se puede utilizar para monitorear la entrada de audio desde el micrófono y llamar a la clase de reconocimiento de voz para su reconocimiento. La función de juzgar automáticamente el inicio y el final del habla se puede realizar configurando parámetros como la frecuencia de muestreo, el tiempo de adaptación y el tiempo máximo de grabación. Al mismo tiempo, a través del mecanismo de señal de PyQt5, se muestran diferentes tipos de información en la interfaz, incluida información de advertencia y resultados de reconocimiento.
# record.py
import speech_recognition as sr
from PyQt5.QtCore import QThread, pyqtSignal
import time, os
import numpy as np
from asr import ASR
class AudioHandle(QThread):
"""
录音控制类
"""
# 用于展示信息的pyqt信号
infoSignal = pyqtSignal(str)
def __init__(self, sampleRate: int = 16000, adjustTime: int = 1, phraseLimitTime: int = 5,
saveAudio: bool = False, hotWord: str = ""):
"""
:param sampleRate: 采样率
:param adjustTime: 适应环境时长/s
:param phraseLimitTime: 录音最长时长/s
:param saveAudio: 是否保存音频
:param hotWord: 热词数据
"""
super(AudioHandle, self).__init__()
self.sampleRate = sampleRate
self.duration = adjustTime
self.phraseTime = phraseLimitTime
# 用于设置运行状态
self.running = False
self.rec = sr.Recognizer()
# 麦克风对象
self.mic = sr.Microphone(sample_rate=self.sampleRate)
# 语音识别模型对象
# hotWord为需要优先识别的热词
# 输入"秦剑 无憾"表示优先匹配该字符串中的字符
self.asr = ASR(prompt=hotWord)
self.saveAudio = saveAudio
self.savePath = "output"
def run(self) -> None:
self.listen()
def stop(self) -> None:
self.running = False
def setInfo(self, text: str, type: str = "info") -> None:
"""
展示信息
:param text: 文本
:param type: 文本类型
"""
nowTime = time.strftime("%H:%M:%S", time.localtime())
if type == "info":
self.infoSignal.emit("<font color='blue'>{} {}</font>".format(nowTime, text))
elif type == "text":
self.infoSignal.emit("<font color='green'>{} {}</font>".format(nowTime, text))
else:
self.infoSignal.emit("<font color='red'>{} {}</font>".format(nowTime, text))
def listen(self) -> None:
"""
语音监听函数
"""
try:
with self.mic as source:
self.setInfo("录音开始")
self.running = True
while self.running:
# 设备监控
audioIndex = self.mic.audio.get_default_input_device_info()['index']
workAudio = self.mic.list_working_microphones()
if len(workAudio) == 0 or audioIndex not in workAudio:
self.setInfo("未检测到有效音频输入设备!!!", type='warning')
break
self.rec.adjust_for_ambient_noise(source, duration=self.duration)
self.setInfo("正在录音")
# self.running为否无法立即退出该函数,如果想立即退出则需要重写该函数
audio = self.rec.listen(source, phrase_time_limit=self.phraseTime)
# 将音频二进制数据转换为numpy类型
audionp = self.bytes2np(audio.frame_data)
if self.saveAudio:
self.saveWav(audio)
# 判断音频rms值是否超过经验阈值,如果没超过表明为环境噪声
if np.sqrt(np.mean(audionp ** 2)) < 0.02:
continue
self.setInfo("音频正在识别")
# 识别语音
result = self.asr.predict(audionp)
self.setInfo(f"识别结果为:{
result}", "text")
except Exception as e:
self.setInfo(e, "warning")
finally:
self.setInfo("录音停止")
self.running = False
def bytes2np(self, inp: bytes, sampleWidth: int = 2) -> np.ndarray:
"""
将音频二进制数据转换为numpy类型
:param inp: 输入音频二进制流
:param sampleWidth: 音频采样宽度
:return: 音频numpy数组
"""
# 使用np.frombuffer函数将字节序列转换为numpy数组
tmp = np.frombuffer(inp, dtype=np.int16 if sampleWidth == 2 else np.int8)
# 确保tmp为numpy数组
tmp = np.asarray(tmp)
# 获取tmp数组元素的数据类型信息
i = np.iinfo(tmp.dtype)
# 计算tmp元素的绝对最大值
absmax = 2 ** (i.bits - 1)
# 计算tmp元素的偏移量
offset = i.min + absmax
# 将tmp数组元素转换为浮点型,并进行归一化
array = np.frombuffer((tmp.astype(np.float32) - offset) / absmax, dtype=np.float32)
# 返回转换后的numpy数组
return array
def saveWav(self, audio: sr.AudioData) -> None:
"""
保存语音结果
:param audio: AudioData音频对象
"""
nowTime = time.strftime("%H_%M_%S", time.localtime())
os.makedirs(self.savePath, exist_ok=True)
with open("{}/{}.wav".format(self.savePath, nowTime), 'wb') as f:
f.write(audio.get_wav_data())
Reconocimiento de voz
La clase de Reconocimiento de voz utiliza Whisper para el reconocimiento de voz. Cuando utilice Whisper para el reconocimiento de voz, puede especificar el mensaje inicial configurando el parámetro inicial_prompt. El parámetro inicial_prompt es una cadena que se utiliza para proporcionar información contextual inicial antes de que el modelo genere texto. Pasar esta información al modelo Whisper le ayuda a comprender mejor el contexto y el contexto de la tarea. Al establecer un mensaje inicial apropiado, el modelo puede guiarse para generar respuestas relacionadas con un tema específico o proporcionar algún conocimiento previo en el diálogo. Por ejemplo, reconocimiento de vocabulario interesante, ya sea que el resultado sean caracteres simplificados o tradicionales. inicial_prompt no es un parámetro obligatorio; si no existe un mensaje inicial, puede optar por no usarlo, dejando al modelo completamente libre para generar respuestas. Sin embargo, cabe señalar que si la voz de entrada es ruido ambiental o se utiliza un modelo pequeño de Whisper, la configuración de inicial_prompt puede hacer que la salida del reconocimiento de voz sea inicial_prompt.
Whisper ofrece 5 modelos de modelos, 4 de los cuales admiten versiones en inglés sencillo para equilibrar la velocidad y la precisión. Cuanto más grande sea el modelo Whisper, mayor será la precisión y menor la velocidad. Este artículo utiliza el modelo pequeño de forma predeterminada. Estos son los nombres de los modelos, los requisitos aproximados de memoria de video y las velocidades relativas para estos modelos disponibles:
| modelo | Cantidad de parámetros | solo modelo ingles | modelo multilingüe | memoria de video requerida | Velocidad relativa |
|---|---|---|---|---|---|
| diminuto | 39M | tiny.en |
tiny |
~1GB | ~32x |
| base | 74M | base.en |
base |
~1GB | ~16x |
| pequeño | 244M | small.en |
small |
~2GB | ~6x |
| medio | 769M | medium.en |
medium |
~5GB | ~2x |
| grande | 1550M | N / A | large |
~10GB | 1x |
# asr.py
import whisper
import numpy as np
class ASR:
"""
语音识别模型类
"""
def __init__(self, modelType: str = "small", prompt: str = ""):
"""
:param modelType: whisper模型类型
:param prompt: 提示词
"""
# 模型默认使用cuda运行,没gpu跑模型很慢。
# 使用device="cpu"即可改为cpu运行
self.model = whisper.load_model(modelType, device="cuda")
# prompt作用就是提示模型输出指定类型的文字
# 这里使用简体中文就是告诉模型尽可能输出简体中文的识别结果
self.prompt = "简体中文" + prompt
def predict(self, audio: np.ndarray) -> str:
"""
语音识别
:param audio: 输入的numpy音频数组
:return: 输出识别的字符串结果
"""
# prompt在whisper中用法是作为transformer模型交叉注意力模块的初始值。transformer为自回归模型,会逐个生成识别文字,
# 如果输入的语音为空,initial_prompt的设置可能会导致语音识别输出结果为initial_prompt
result = self.model.transcribe(audio.astype(np.float32), initial_prompt=self.prompt)
return result["text"]