1. Conocimientos básicos
La tecnología de reconocimiento de voz es una tecnología que permite a las máquinas convertir las señales de voz en el texto o los comandos correspondientes a través del reconocimiento y la comprensión.
Dificultades en el reconocimiento de voz: regional, escena, fisiológico, problema de cóctel (varias personas).
Clasificación de las tareas de reconocimiento de voz: reconocimiento de palabras aisladas, reconocimiento de palabras continuas.
Flujo de procesamiento de tareas de reconocimiento de voz:
1) Preprocesamiento del habla
2) Algoritmo de reconocimiento de voz: algoritmo GMM-HMM tradicional, basado en un algoritmo de aprendizaje profundo
2. Preprocesamiento del habla
1) Digitalización: discretizar la señal de voz analógica recopilada del sensor en una señal digital
2) Preénfasis: el propósito es enfatizar la parte de alta frecuencia de la voz, eliminar la influencia de la radiación de los labios y aumentar la resolución de alta frecuencia de la voz.
3) Detección de punto final: también llamada detección de actividad de voz (Voice Activity Detection, VAD), el propósito es distinguir áreas de voz y no voz, es decir, eliminar el silencio y el ruido, y encontrar una pieza de contenido de voz realmente efectivo.
Los algoritmos VAD se pueden dividir aproximadamente en tres categorías: basados en umbrales, basados en clasificadores y basados en modelos.
4) Trama: Debido a la estacionariedad a corto plazo del habla, es necesario realizar un "análisis a corto plazo", es decir, segmentar la señal, y cada segmento se denomina trama (generalmente 10 ~ 30 ms). la segmentación se puede usar para encuadrar, sin embargo, generalmente se usa el método de superposición de segmentos, para hacer que la transición entre los encuadres sea suave y mantenga su continuidad.
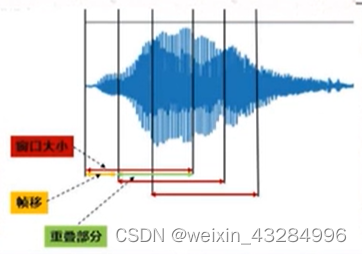
5) Ventanas: use una ventana móvil de longitud finita para ponderar para realizar el encuadre de la señal de voz. El propósito de las ventanas es reducir el efecto de truncamiento de los marcos de voz. Las ventanas comunes son: ventana rectangular, ventana de Hanning y ventana de Hamming.
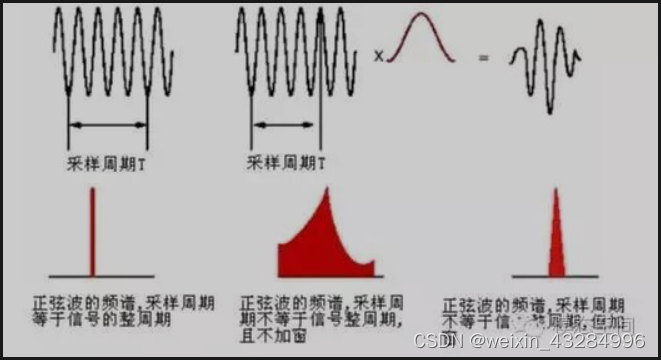
Por lo general, el truncamiento y el encuadre de la señal requieren ventanas, porque el truncamiento básicamente causará fugas en el dominio de la frecuencia, y la función de ventana puede reducir el impacto del truncamiento y mejorar la resolución del resultado de la transformación. (Ver: ¿ Qué es una fuga? )
El costo de las ventanas es que las partes en ambos extremos de una señal de cuadro se debilitan y no se les presta tanta atención como a la parte central, por lo que el método de segmentación superpuesta se puede usar para enmarcar.
3. Algoritmo de reconocimiento de voz (algoritmo GMM-HMM)
Suplemento de conocimiento:
1) Triphone significa: [fonema anterior, fonema actual, fonema siguiente] tres fonemas para representar un fonema, porque los fonemas adyacentes del mismo fonema son diferentes, la pronunciación del fonema también será diferente
2) Cada fonema consta de N estados, y N estados se utilizan para representar el fonema: todo el proceso de inicio -> estabilidad -> final
3) Una secuencia de cuadros de características a menudo tiene muchos cuadros, mucho más que el número de estados. Nuestro enfoque es generar repetidamente cada estado en orden y luego calcular la suma de las probabilidades de cada secuencia de estados.
Por ejemplo: los tres fonemas son: a, b, c, respectivamente, y el número de marcos de características es 10, entonces las secuencias de estado posibles son aaabbbcccc, aaaabbbccc, etc., sumaremos las probabilidades de todas las secuencias de estado como esta característica secuencia de cuadros por estos tres La probabilidad de que se produzca un fonema.
4) En el reconocimiento de voz, los datos de audio son el estado de observación en el HMM (puede escucharlos y verlos directamente), y el fonema correspondiente al audio es el estado oculto (el estado de observación se genera a partir del estado oculto).
5) fórmula bayesiana:
en:
: probabilidad previa, que representa el conocimiento inicial de la probabilidad de una variable aleatoria
: La probabilidad de verosimilitud, también conocida como densidad de probabilidad condicional de clase (densidad aproximada de clase), expresa el comportamiento de otra variable aleatoria relacionada con ella bajo la admisión de probabilidad condicional previa
:Probabilidad posterior. Indica la probabilidad de Y después de la condición actual de X
Proceso de entrenamiento: cada vez que se ingresa una secuencia de cuadros y una secuencia de palabras en el modelo, el proceso de entrenamiento pertenece al problema de aprendizaje en el modelo HMM, y el algoritmo EM se usa para resolverlo iterativamente.
Pasos de entrenamiento :
1) Refinar secuencias de palabras en secuencias trifónicas
2) Enumerar exhaustivamente todas las posibles secuencias de estado continuo de la secuencia trifónica actual
3) Inicialice la matriz de estado inicial (π), oculte la matriz de transición de estado (A) y genere la matriz de probabilidad de estado observada (B).
4) De acuerdo con los parámetros del modelo inicializados en el paso anterior , la probabilidad (previa) de cada secuencia de estados se obtiene a través del algoritmo hacia adelante o hacia atrás.
5) Calcular cada secuencia de estados para obtener la función de verosimilitud logarítmica del trifono actual ,
que es una variable.
6) Encuentre el Q(E-paso) esperado de la secuencia trifónica en cada secuencia de estado (a priori):
Y es la expectativa del máximo (M-step). Para obtener nuevos parámetros del modelo (método del multiplicador lagrangiano)
7) Repita los pasos 3) 4) 5) 6) hasta la convergencia.
Cuando nuestra matriz de probabilidad de estado de observación generada (matriz de emisión) está representada por GMM, tenemos n modelos gaussianos más mixtos, por lo que necesitamos sumar en diferentes modelos GMM, la fórmula es la siguiente:
donde n representa los parámetros del modelo gaussiano mixto.
Una vez finalizado el entrenamiento, se emiten los parámetros del sistema GMM-HMM
.
Proceso de reconocimiento (decodificación): De acuerdo con los parámetros del sistema GMM-HMM y la secuencia de cuadros de entrada actual, se obtiene la ruta con la máxima probabilidad.
Pasos de identificación:
1) Enumerar exhaustivamente todas las posibles secuencias de estado correspondientes a la secuencia de cuadros actual
2) De acuerdo con , se obtiene la probabilidad de que la secuencia de cuadros de característica sea generada por cada secuencia de estado
3) Una secuencia de cuadros de características es mucho más que el número de estados correspondientes a las palabras.Después de que la misma secuencia de palabras se refina en el número de estados, es necesario expandir el número de estados en la secuencia al número de cuadros de características Hay muchas posibilidades para la secuencia de estado expandida. La suma de las probabilidades de cada secuencia de estado posible se usa como la probabilidad de probabilidad de que el cuadro de características se reconozca como esta secuencia de palabras (si la secuencia de estado generada es I, entonces la probabilidad de generar una secuencia de cuadros de características es O).
4) Multiplique la probabilidad de verosimilitud de la secuencia de palabras calculada en el paso anterior y la probabilidad anterior de la secuencia de palabras en el modelo de lenguaje
como la probabilidad posterior de la secuencia de palabras
(ha aparecido la secuencia de cuadros característica O,
).
5) Encuentre la secuencia de palabras con la mayor probabilidad posterior como resultado del reconocimiento de la secuencia de cuadros de características.