Directorio de artículos
Parte de este artículo se reproduce de: https://zhuanlan.zhihu.com/p/530377846 solo para registros de aprendizaje~
1. Antecedentes
Esta parte está tomada de: https://zhuanlan.zhihu.com/p/536642987
Una variedad de algoritmos de uso común son la base para construir todo el sistema, y el algoritmo de filtro de Kalman, como uno de los algoritmos más utilizados en el circuito cerrado de todo el sistema de conducción automática a lo largo de la percepción , el posicionamiento , la toma de decisiones y el control . , es naturalmente lo más importante en el aprendizaje .
El seguimiento de objetivos requiere el filtrado de Kalman, la fusión multisensor requiere el filtrado de Kalman, el posicionamiento y el mapeo requieren el filtrado de Kalman, y el seguimiento y control de la trayectoria todavía usa el filtrado de Kalman.
Este gran algoritmo se ha utilizado en innumerables proyectos académicos de ingeniería desde su nacimiento en la década de 1960. Ya sea que estudies control, electrónica, comunicaciones, computación, vehículos o mecánica, debes haber escuchado y aprendido más o menos sobre este algoritmo. Pero creo que tendrá el mismo sentimiento que yo, es decir, lo que dijo el maestro siempre siente que el significado no es tan bueno, y siempre siento que no he entendido profundamente la esencia de eso.
Aquí hay algunos enlaces para lectura adicional:
Aquí hay una respuesta de Kent Zeng en Zhihu, sobre la explicación popular del filtrado de kalman
Suponga que tiene dos sensores que miden la misma señal. Pero sus lecturas no son siempre las mismas, ¿qué debo hacer?
Toma el promedio.
Y supongamos que sabe que el sensor más caro debería ser más preciso y el más barato debería ser peor. ¿Hay una mejor manera que tomando el promedio?
Peso promedio.
¿Cómo pesar?
Suponiendo que los errores de los dos sensores se ajustan a la distribución normal, suponiendo que conoce la varianza de las dos distribuciones normales, utilizando estos dos valores de varianza (aquí se omiten algunas fórmulas matemáticas), puede obtener pesos "óptimos".
A continuación, aquí viene el punto clave: supongamos que solo tiene un sensor, pero también tiene un modelo matemático. El modelo puede ayudarlo a calcular un valor, pero no es tan preciso. ¿qué hacer?
Tome el promedio ponderado del valor calculado por el modelo y el valor medido por el sensor (como dos sensores).
Bien, el último punto: tu modelo es en realidad solo un tamaño de paso, es decir, conociendo x(k), puedo encontrar x(k+1).
La pregunta es ¿qué es x(k)?
Respuesta: x(k) es la mejor estimación de x en el tiempo k obtenida por filtrado de Kalman en el paso anterior, después del llamado promedio ponderado. Así que hay iteraciones. Este es el filtro de Kalman.
En cuanto a cómo se calcula este peso (ganancia de Kalman), si comprende esto, descubrirá los detalles.
Ampliemos y expliquemos aún más el texto anterior:
El filtro de Kalman es un algoritmo de procesamiento de datos recursivo óptimo . El comienzo indica su significado real. Kalman es el nombre del inventor, y el filtrado es un método. Para los principiantes, la combinación de los dos no sabe qué tipo de algoritmo es, e incluso la palabra "filtrado" causará interferencia y malentendidos, lo que hará que la gente piense erróneamente que esto es algo similar a un filtro de paso bajo que filtra un determinado tipo de señal.
En el estudio anterior se ha explicado muy claramente el significado de “filtrado”, es decir, lo que se filtra no es un determinado tipo de señal, sino la incertidumbre .
Cuando describimos un sistema, la incertidumbre se refleja principalmente en tres aspectos:
- No existe un modelo matemático perfecto. El mundo es complejo y cambiante, las personas pueden encontrar modelos matemáticos para describir un sistema, pero siempre se requieren varias condiciones ideales, por lo tanto, ningún sistema puede ser perfectamente descrito por modelos matemáticos, solo la diferencia entre alta y baja aproximación;
- La perturbación del sistema es incontrolable y difícil de modelar. Por ejemplo, cuando un vehículo de repente se encuentra con una fuerte lluvia mientras conduce por la carretera, ¿cómo se debe modelar y representar esta perturbación? difícil;
- Hay un error en el sensor de medición. Esto también es fácil de entender. El sensor es como una regla para medir la longitud de un objeto. Siempre habrá resultados diferentes al usar reglas diferentes.
A continuación, echemos un vistazo a la implementación del algoritmo recursivo a través del ejemplo de la regla mencionada anteriormente. Creo que este ejemplo es muy ingenioso. A través de una simple derivación matemática, la gente puede entender la esencia del pensamiento filtrado de Kalman.

en realidad significa当前的估计值 等于 上一次的估计值 + 系数 x(当前的测量值-上一次的估计值)
Por tanto, el filtrado de Kalman solo se relaciona con la información de último momento , y no necesita registrar los datos previos en todo el proceso, lo que hace que sea muy utilizado en dispositivos embebidos con memoria y potencia de cálculo limitadas.
2. Explicación intuitiva del principio
Supongamos que un automóvil que circula por la carretera comienza en el punto A, el automóvil conduce al punto B en el bulevar en el siguiente segundo y el automóvil sale del bulevar al punto C en el siguiente segundo. Hay dos sensores de posiciónIMU(惯性测量单元) y están instalados en este vehículo .GNSS(全球导航卫星系统)
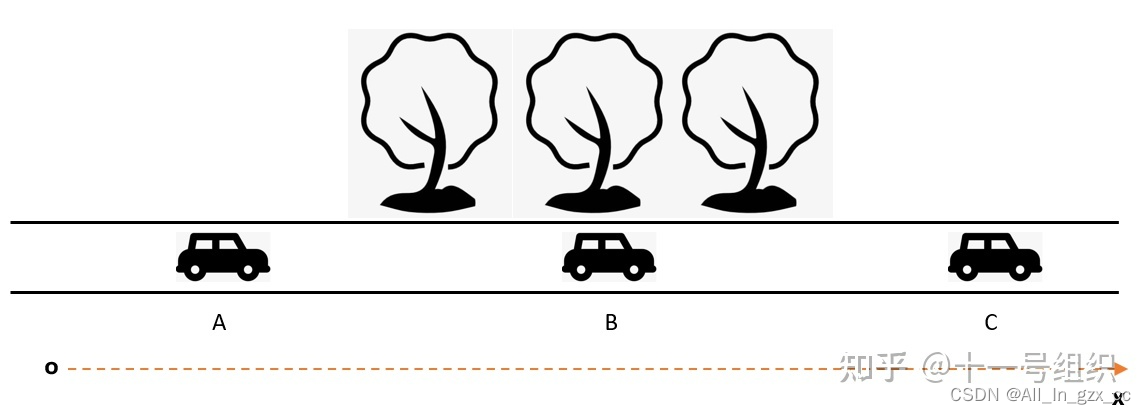
- Se supone que se conocen la posición y la velocidad del punto inicial A , la distancia desde el origen del eje X del sistema de coordenadas inerciales es de 2 m y la velocidad es Vt-1.
- Cuando el vehículo entra en el punto B, por un lado, podemos medir la aceleración en los tres ejes y la velocidad angular en los tres ejes de la carrocería según la IMU, combinada con la velocidad inicial Vt-1, podemos calcular ese punto B viaja en la dirección del eje X en relación con el punto A. Valor estimado de la distancia , aquí suponemos
估计值10 m. - Por otro lado, podemos medir directamente la latitud y longitud del punto B a través de GNSS. Después de la conversión de coordenadas, podemos obtener directamente el valor de observación del punto B viajando en la dirección del eje X. Aquí asumimos que el valor de observación es 13m .
Aquí viene el problema, la distancia desde el punto en el sistema de coordenadas inercial ahora tiene dos valores 估计值(12m=10m+2m) y 观测值(13m), y los dos valores son inconsistentes, ¿cómo determinamos el punto B准确估计值 ?
Como todos sabemos, hay errores y ruidos en el proceso de IMU que mide la aceleración y la velocidad angular de la carrocería del automóvil, y también hay errores y ruidos en el proceso de posicionamiento GNSS de la latitud y longitud del vehículo a través de señales satelitales. Los valores dados por los dos sensores son la probabilidad más alta , lo que significa que la probabilidad es la más alta en esta posición , y otras posiciones no son imposibles pero tienen una probabilidad más baja. En la teoría del algoritmo de filtro de Kalman, se considera que obedecen los datos de medición de la IMU o el valor de observación directa del GNSS, ya sea la posición del automóvil durante un segundo 正态分布.
正态分布es una distribución de probabilidad, generalmente expresada como N(均值、方差).
- Una variable aleatoria sujeta a una distribución normal tiene una mayor probabilidad de tomar un valor cercano a la media y una menor probabilidad de tomar un valor más alejado de la media.
- Al mismo tiempo, cuanto menor es la varianza, más concentrada está la distribución cerca de la media, y cuanto mayor es la varianza, más dispersa es la distribución.
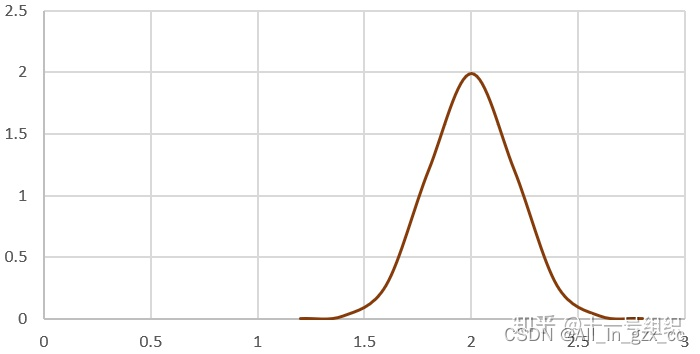
Aquí asumimos que la posición Xt-1 del punto A obedece a N(2, 0.2 2 ), como se muestra en la siguiente figura. En la figura se puede ver que la ordenada a 2 m es la más grande y la probabilidad es la más grande, y las probabilidades de otros valores son todas más pequeñas que aquí. La varianza de 0.2 2 representa el nivel de error de la posición del punto A.
Para dos tipos de sensores , IMU y GNSS , su variación de ruido se puede medir y conocer en el momento de su uso. Aquí omitimos el proceso de modelado del modelo móvil y asumimos directamente
- Según la IMU, la distancia entre el punto B y el punto A
估计值XIobedece a N(10, 0,1 2 ), y la varianza de 0,1 2 representa el nivel de error del ruido de la IMU. Este nivel de error está relacionado con la precisión de la IMU y el tiempo acumulado de medida 测量值XGGNSS obtiene la obediencia N(13, 0,4 2 ) del punto B con respecto al origen a través de señales de satélite , y la varianza 0,4 2 representa el nivel de error del ruido GNSS. Este nivel de error, por un lado, se ve afectado por el nivel de precisión de la placa satelital en GNSS, y por otro lado, está relacionado principalmente con el entorno en el que se encuentra, si hay oclusión, si hay un multi -ambiente metálico, etc. Debido a que el punto B está debajo de la carretera arbolada, la señal del satélite a veces desaparece, por lo que el nivel de error de 0,4 2 es relativamente alto en este momento.
Ahora tenemos dos conjuntos de datos,
- Un grupo es el punto B relativo al origen 0
估计值XBOI= XI + XA = N(10, 0.1 2 ) + N(2, 0.2 2 ) = N(12, 0.1 2 +0.2 2 ), 观测值XGUn conjunto es = N(13, 0.4 2 ) del punto B relativo al origen 0 .
El clímax del texto completo está aquí. ¿Cómo puedo encontrar el valor estimado más preciso de las dos distribuciones de probabilidad? Es concebible que este valor estimado preciso también siga una distribución normal. El valor a buscar . La respuesta dada por Kalman es, directamente 将两个概率分布相乘, es decir, N(12, 0.1 2 +0.2 2 ) * N(13,0.4 2 ).
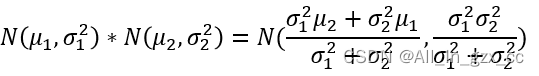
La fórmula de multiplicación de la distribución normal es como la anterior, y el valor en N(12, 0.1 2 +0.2 2 ) * N(13,0.4 2 ) se lleva a la siguiente fórmula, y se puede obtener la siguiente distribución normal.
El valor estimado exacto del punto B es el valor medio de esta distribución normal de 12,23 m, y el nivel de error de este valor estimado exacto es 0,19 2 . 0.22 2 /(0.22 2 +0.4 2 ) Este parámetro se llama en la teoría del algoritmo de filtro de Kalman 卡尔曼增益. (12.23, 0.19 2
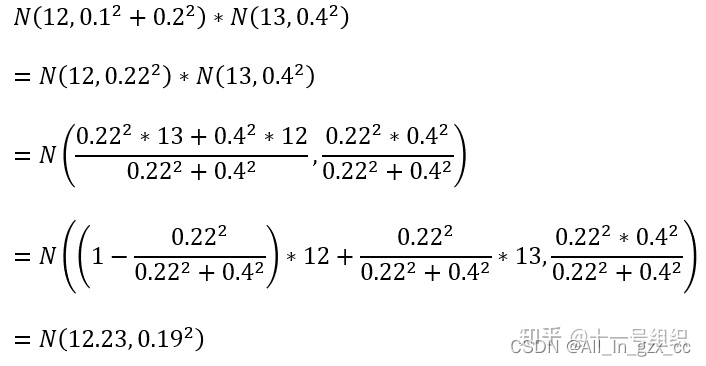
) en el punto B se utilizará como valor inicial para calcular la posición del punto C, y se repetirá el proceso anterior.
3. Análisis teórico del algoritmo
El algoritmo de filtro de Kalman es el tipo de algoritmo que es difícil de entender pero muy simple de usar. Solo hay cinco fórmulas en todo el algoritmo, y la derivación detallada de las fórmulas no es necesaria ni interesante para la mayoría de las personas. Por lo tanto, este párrafo presenta directamente la ecuación de predicción derivada y la ecuación de actualización, y simplemente explica el significado de las variables y ecuaciones.
1. Ecuación de predicción
xk-1Para 系统上一时刻状态向量, este vector de estado puede 包含任何需要跟踪的信号, y cada variable en el vector de estado obedece a una distribución normal. En el ejemplo anterior de comprensión intuitiva del movimiento del vehículo, esta variable de estado contiene la velocidad y la posición .
Usamos 预测矩阵F, para describir 上一时刻状态到当前时刻状态的关系. Al mismo tiempo, considerando que los factores externos traerán algunos cambios que no están relacionados con el estado del sistema en sí, introducimos 外部控制量ut-1y 系统参数B. Hasta aquí nace una ecuación de predicción de estado considerando a sí misma y factores externos , como se muestra en la siguiente fórmula.

En el ejemplo del movimiento del vehículo, existe cierta relación entre las variables de velocidad y posición en las variables de estado en el momento anterior, si la velocidad es alta, el vehículo viajará más lejos cuando corra al momento actual. Pero en otros sistemas, es posible que no podamos ver intuitivamente las dependencias entre las variables a simple vista, que también es el objetivo central del algoritmo de filtro de Kalman .从不确定的系统中,尽可能的挖掘确定的信息
El algoritmo de filtro de Kalman utilizado aquí 协方差矩阵Pk-1es 衡量上一时刻状态变量中 每个变量的 相关程度. Al mismo tiempo, la interferencia de ruido que no se rastrea协方差为Q se ve afectada como el ruido, por lo que podemos obtener la matriz de covarianza considerando factores externos en el momento actual , como se muestra en la siguiente fórmula.
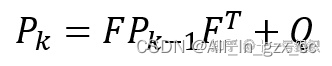
En cuanto a la matriz de covarianza, puedes leer el siguiente blog:
En breve:
- La varianza se usa para medir el grado de dispersión de una sola variable aleatoria,
- La covarianza se usa generalmente para describir la similitud entre dos variables aleatorias. Mientras que la varianza es un caso especial de covarianza, la situación en la que dos variables son iguales.
- La matriz de covarianza simplemente expresa la relación de covarianza de todas las variables en forma de matriz. Las operaciones matemáticas se pueden realizar de manera más conveniente a través de la herramienta de matriz.
2. Actualiza la ecuación
A través del proceso de predicción anterior, tenemos una estimación aproximada del estado actual del sistema. Al mismo tiempo, también
mediremos el estado del sistema en el momento actual a través de sensores . Para las medidas, necesitamos uno más , vamos . Luego, después de una ardua derivación, se pueden obtener las siguientes ecuaciones de actualización de estado.观测值zk其测量的不确定性R变换矩阵H将 系统真实状态空间 映射成 观测空间
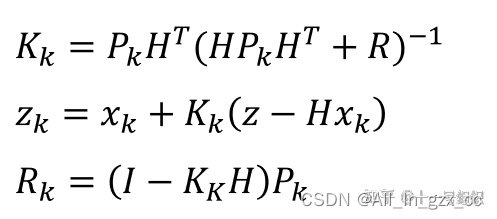
3. Aplicación
Una de las aplicaciones clásicas del algoritmo de filtro de Kalman en conducción autónoma es el posicionamiento por fusión . Los sistemas de conducción autónoma L4/L5 están básicamente equipados con GNSS e IMU de serie. La frecuencia de actualización de los datos de posicionamiento GNSS es baja (típicamente 10 Hz) y los datos de posicionamiento de salida no son confiables bajo la influencia de la oclusión o la ruta múltiple. La frecuencia de actualización de los datos de posicionamiento de la IMU es alta (típicamente 150 Hz), pero la operación integral interna producirá un gran error acumulativo con el tiempo.
Para obtener datos de posicionamiento globales y precisos, cada empresa utiliza los datos de posicionamiento confiables de GNSS para calibrar la IMU y eliminar el error acumulativo de la IMU. Al mismo tiempo, cuando el posicionamiento GNSS no es confiable, los propios resultados de cálculo de la IMU se utilizan para optimizar los datos de posicionamiento GNSS no confiables. La forma de obtener información más determinista a partir de la información incierta de GNSS/IMU es utilizar el algoritmo de filtro de Kalman.
En términos de seguimiento y predicción de obstáculos , el algoritmo de filtro de Kalman se usa ampliamente para estimar la posición y la velocidad de los obstáculos mediante la fusión de datos de lidar y radar de ondas milimétricas.
En términos de seguimiento y predicción de la línea del carril , el algoritmo de filtro de Kalman puede estimar la posición de la línea del carril en el momento siguiente mediante la predicción de la imagen actual, y puede identificar y juzgar la dirección de la línea del carril (girar a la izquierda o a la derecha), y extraer información efectiva de la carretera se utiliza para realizar un seguimiento de las líneas de los carriles.