CeresDB es una base de datos de serie temporal nativa de la nube distribuida de alto rendimiento escrita en Rust. Su equipo de desarrollo anunció recientemente que después de casi un año de investigación y desarrollo de código abierto, se lanza oficialmente la base de datos de series temporales CeresDB 1.0, alcanzando los estándares de disponibilidad de producción .
Documentación china oficial de CeresDB 1.0: https://docs.ceresdb.io/cn/
Introducción a las funciones principales de CeresDB 1.0
motor de almacenamiento
-
Admite almacenamiento híbrido en columnas
-
Filtro XOR eficiente
Nube Nativa Distribuida
-
Darse cuenta de la separación de la informática y el almacenamiento (compatible con OSS como almacenamiento de datos, la implementación de WAL es compatible con OBKV, Kafka)
-
Soporta tabla de particiones HASH
Despliegue y O&M
-
Soporte de implementación independiente
-
Admite la implementación de clústeres distribuidos
-
Apoye a Prometheus + Grafana para construir el autocontrol
protocolo de lectura y escritura
-
Admite consultas y escritura SQL
-
Se implementó el protocolo de lectura y escritura de alto rendimiento incorporado de CeresDB y se proporcionó SDK multilingüe.
-
Admite Prometheus, se puede utilizar como almacenamiento remoto de Prometheus
SDK multilingüe de lectura y escritura
- SDK de cliente implementado en cuatro idiomas: Java, Python, Go, Rust
Introducción a la arquitectura CeresDB
CeresDB es una base de datos de series de tiempo. En comparación con las bases de datos de series de tiempo clásicas, el objetivo de CeresDB es poder procesar datos tanto en modo de serie de tiempo como analítico al mismo tiempo, y proporcionar lectura y escritura eficientes.
En una base de datos de series de tiempo clásica, Tagla columna ( InfluxDBllamada Tag, Prometheusllamada Label) generalmente genera un índice invertido para ella, pero en el uso real, Tagla cardinalidad de la columna es diferente en diferentes escenarios——— en algunos En el escenario, Tagla cardinalidad es muy alto (los datos en este escenario se llaman datos analíticos), y la lectura y escritura basada en el índice invertido pagará un alto precio por esto. Por otro lado, el método de escaneo + poda comúnmente utilizado en bases de datos analíticas puede procesar dichos datos analíticos de manera más eficiente.
Por lo tanto, el concepto de diseño básico de CeresDB es adoptar un formato de almacenamiento híbrido y los métodos de consulta correspondientes, para procesar eficientemente datos de series temporales y datos analíticos al mismo tiempo.
La siguiente figura muestra la arquitectura de la versión independiente de CeresDB
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
Optimización del rendimiento y resultados experimentales
CeresDB utiliza una combinación de almacenamiento híbrido en columnas, partición de datos, poda y escaneo eficiente para resolver el problema del rendimiento deficiente de las consultas de escritura en plazos masivos (alta cardinalidad).
optimización de escritura
CeresDB adopta el modelo de escritura similar a LSM (árbol de combinación con estructura de registro), que no necesita procesar índices invertidos complejos al escribir, por lo que el rendimiento de escritura es mejor.
optimización de consultas
Los siguientes medios técnicos se utilizan principalmente para mejorar el rendimiento de las consultas:
Poda:
-
Poda mínima/máxima: el costo de construcción es relativamente bajo y el rendimiento es mejor en escenarios específicos
-
Filtro XOR: mejore la precisión de filtrado del grupo de filas en el archivo de parquet
Escaneo eficiente:
-
Simultaneidad entre múltiples SST: escanee múltiples archivos SST al mismo tiempo
-
Simultaneidad interna de un solo SST: admite la capa de parquet para extraer varios grupos de filas en paralelo
-
Combine pequeñas E/S: para archivos en OSS, combine pequeñas solicitudes de E/S para mejorar la eficiencia de extracción
-
Caché local: archivos de caché extraídos por OSS, memoria de soporte y caché de disco
resultados de la prueba de rendimiento
Las pruebas de rendimiento se realizaron utilizando TSBS. Los parámetros de medición de presión son los siguientes:
-
10 etiquetas
-
10 campos
-
Línea de tiempo (Número de combinación de etiquetas) Nivel 100w
Configuración de la máquina de prueba de presión: 24c90g
Versión de InfluxDB: 1.8.5
Versión de CeresDB: 1.0.0
Comparación de rendimiento de escritura
El rendimiento de escritura de InfluxDB se degrada más con el tiempo. Después de que la escritura de CeresDB es estable, la tasa de escritura tiende a ser estable y el rendimiento de escritura general es más de 1,5 veces mayor que el de InfluxDB (la brecha puede ser más de 2 veces después de un período de tiempo)
En la figura a continuación, una sola fila contiene 10 campos.
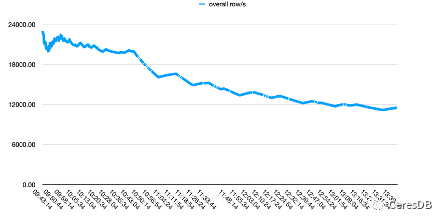
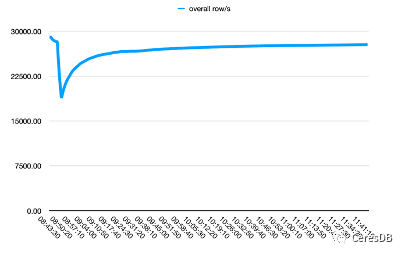
La imagen de arriba es Influxdb, y la imagen de abajo es CeresDB
Comparación de rendimiento de consultas
Condición de detección baja (condición: os=Ubuntu15.10), CeresDB es 26 veces más rápido que InfluxDB, los datos específicos son los siguientes:
-
Tiempo de consulta de CeresDB: 15 s
-
Tiempo de consulta de InfluxDB: 6m43s
Altas condiciones de cribado (menos aciertos de datos, condición: hostname=[8], en este momento el índice invertido tradicional será más efectivo en teoría), este es un escenario donde InfluxDB tiene más ventajas, y en este momento bajo la condición de que el se completa el calentamiento, CeresDB es 5 veces más lento que InfluxDB.
-
CeresDB:85ms
-
DB de entrada: 15 ms
hoja de ruta 2023
El equipo de desarrollo dijo que en 2023, después del lanzamiento de CeresDB 1.0, la mayor parte de su trabajo se centrará en el rendimiento, la distribución y la ecología circundante. En particular, el soporte de acoplamiento de la ecología circundante espera facilitar el uso de CeresDB a varios usuarios:
Ecología circundante
-
Compatibilidad ecológica, incluida la compatibilidad con protocolos de bases de datos de series temporales comunes, como PromQL, InfluxdbQL y OpenTSDB
-
Soporte de herramientas de operación y mantenimiento, incluido soporte k8s, sistema de operación y mantenimiento CeresDB, autocontrol, etc.
-
Herramientas de desarrollo, incluidas la importación y exportación de datos, etc.
actuación
-
Explora nuevos formatos de almacenamiento
-
Mejore diferentes tipos de índices para mejorar el rendimiento de CeresDB bajo diferentes cargas de trabajo
repartido
-
equilibrio de carga automático
-
Mejore la disponibilidad, la confiabilidad