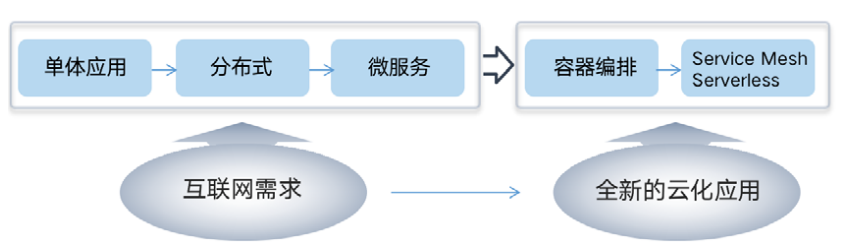
El sistema de tecnología nativa de la nube puede parecer desordenado y complicado, pero en diferentes perspectivas, encarna la línea principal de "conseguir un toque y mover todo el cuerpo". Desde la perspectiva de la línea de tiempo, el desarrollo de la tecnología de contenedores dio origen a una tendencia de pensamiento nativa de la nube, que resolvió el problema del suministro de recursos en la parte inferior. Luego, Kubernetes de código abierto se convirtió en la especificación estándar para la orquestación de contenedores. Cuando la aplicación abierta La plataforma basada en la escalabilidad de Kubernetes se volvió más abundante. Se ha convertido en la piedra angular más importante de la ecología nativa de la nube. Posteriormente, las ideas centrales de las tecnologías Service Mesh y Serverless se centran más en obtener valor en el lado empresarial, hundiendo más capacidades en la infraestructura, brindando la posibilidad de aplicaciones ligeras y migración a la nube.
Desde la perspectiva de los requisitos técnicos, la arquitectura de microservicios es la forma preferida de resolver el problema de complejidad única, pero ha provocado un aumento sustancial en la complejidad general de todo el sistema. La tecnología de contenedores y Kubernetes han resuelto respectivamente la implementación y la implementación de un Además de la administración y programación de contenedores, Kubernetes también brinda un mejor soporte subyacente para Service Mesh, y también brinda la natividad en la nube sin servidor de la infraestructura subyacente y el hundimiento adicional de las capacidades del middleware.
1. Contenedor
Un contenedor es una tecnología que divide efectivamente un proceso en un espacio independiente, a fin de equilibrar los conflictos de uso de recursos entre espacios independientes. Básicamente, un contenedor es un proceso especial. Su función principal es crear un "límite" restringiendo y modificando el rendimiento dinámico del proceso. Además, su capacidad de limitación de recursos y la "fuerte coherencia" que muestra la función de duplicación, Todos hacer de la tecnología de contenedores una de las tecnologías subyacentes más críticas para la nube nativa.
Los contenedores Docker a menudo se denominan tecnología de virtualización "ligera" debido a sus efectos de aislamiento similares a los de las máquinas virtuales, pero tal afirmación no es rigurosa. En la máquina virtual, el hipervisor es la parte más importante. Simula varios tipos de hardware, como CPU, memoria, dispositivos de E / S a través de funciones de virtualización de hardware, y luego instala un nuevo sistema operativo en este hardware virtual, a saber, en el sistema operativo invitado. , los procesos de aplicación que se ejecutan en un sistema operativo virtual están aislados entre sí.
La diferencia entre Docker y las máquinas virtuales se refleja en los diferentes métodos de aislamiento de procesos. Docker implementa el aislamiento de procesos adjuntando parámetros de espacio de nombres adicionales a la aplicación. No hay un "contenedor de Docker" real ejecutándose en el host. Esta operación "oscura" hace que el El proceso parece estar funcionando en un "contenedor" aislado, por lo que el contenedor reduce el consumo y la ocupación de recursos adicionales, y tiene grandes ventajas en términos de agilidad y alto rendimiento.
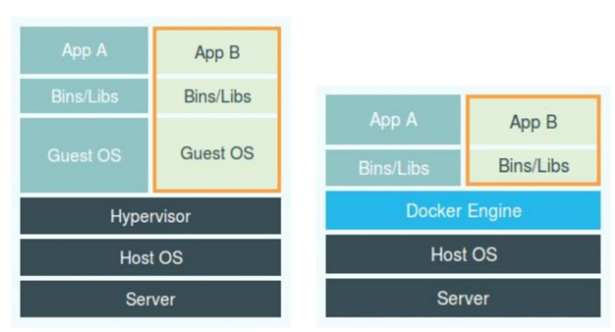
Además, las funciones principales del contenedor también incluyen capacidades de restricción de recursos basadas en Cgroups y funciones de duplicación. La función de Cgroups es limitar el límite superior de recursos que puede usar un grupo de procesos, incluidos recursos como CPU, memoria, disco y ancho de banda de la red. La función de espejo hace que la tecnología del contenedor muestre una "fuerte consistencia", es decir, el contenido de la imagen descargada en cualquier ubicación es completamente consistente, reproduciendo completamente el entorno original completo del creador de imágenes, lo que abre todos los aspectos del "desarrollo- "prueba-implementación", haciendo de la tecnología de contenedores el método principal de lanzamiento de software.
2. Gobernadores
Cuando la duplicación de contenedores se convierte en un estándar de la industria para la distribución de aplicaciones, la tecnología de "orquestación de contenedores" que puede definir la organización de contenedores y las especificaciones de administración se ha convertido en un nodo de valor clave en toda la pila de tecnología de contenedores. Las principales herramientas de orquestación de contenedores incluyen la combinación Compose + Swarm de Docker, la combinación Mesos + Marathon de Mesosphere, el proyecto Kubernetes codirigido por Google y RedHat, y los proyectos OpenShift y Rancher basados en Kubernetes. Al final, el proyecto Kubernetes, con su excelente apertura, escalabilidad y comunidad de desarrolladores activa, se destacó en la batalla de la orquestación de contenedores y se convirtió en el estándar de facto para la programación de recursos distribuidos y la operación y el mantenimiento automatizados.
La idea de diseño principal del proyecto Kubernetes es definir varias relaciones entre tareas de una manera unificada desde una perspectiva más macro, y dejar espacio para admitir más tipos de relaciones en el futuro. Desde un punto de vista funcional, Kubernetes maneja mejor automáticamente las diversas relaciones entre contenedores de acuerdo con los deseos de los usuarios y las reglas de todo el sistema, es decir, la orquestación de contenedores, incluida la implementación, la programación y la expansión entre los nodos. racimos. Proyectos como Mesos y Swarm son buenos para colocar un contenedor en el mejor nodo para ejecutarlo de acuerdo con ciertas reglas, es decir, la programación del contenedor. Esta es también una razón importante por la que finalmente se destacó el proyecto Kubernetes.
Capacidades centrales de Kubernetes:
- Descubrimiento de servicios y equilibrio de carga: muestra varios servicios de aplicaciones a través de los recursos del servicio, combinados con DNS y múltiples mecanismos de equilibrio de carga para respaldar la comunicación mutua entre aplicaciones en contenedores.
- Orquestación de almacenamiento: admite múltiples almacenamientos en forma de plungin, como local, nfs, ceph, almacenamiento de bloques en la nube pública, etc.
- Programación de recursos: establezca los recursos necesarios y los límites de recursos para la programación del pod, admita la liberación automática de aplicaciones y la reversión de aplicaciones, y administre la configuración relacionada con la aplicación.
- Reparación automática: supervise todos los hosts en el clúster, detecte y maneje automáticamente las excepciones en el clúster, reemplace los nodos de pod que deben reiniciarse y haga que el clúster de contenedores se ejecute en el estado deseado del usuario.
- Gestión de claves y configuración: almacene información confidencial a través de secretos y almacene los archivos de configuración de la aplicación a través de configmap para evitar corregir archivos de configuración en la imagen y aumentar la flexibilidad del diseño del contenedor.
- Función de expansión horizontal: realiza un escalado elástico según la utilización de la CPU o el nivel de plataforma, como agregar y eliminar nodos automáticamente.
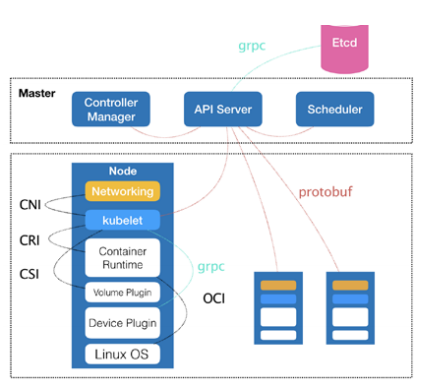
El proyecto de Kubernetes consta de un nodo de control Master y un nodo de computación Node. Master, como nodo de control y gestión, se compone de tres componentes independientes estrechamente coordinados: kube-apiserver es responsable de los servicios API, kube-planificador es responsable de la programación de recursos y kube-controller-manager es responsable de la orquestación de contenedores. , los datos persistentes del clúster son administrados por kube- Después de que se procesa un servidor, se almacena en Etcd, como Pod, Servicio y otra información de objeto. El nodo de cálculo Node es la carga de trabajo del proyecto, y el componente kubelet es la parte central del mismo. Es responsable de la creación, inicio y cierre del contenedor correspondiente al Pod. Al mismo tiempo, trabaja en estrecha colaboración con el Nodo maestro para realizar las funciones básicas de la gestión de clústeres.
Hoy en día, el proyecto Kubernetes no solo es el estándar de facto para la tecnología de contenedores, sino también la piedra angular del desarrollo de todo el sistema nativo de la nube, redefiniendo varias posibilidades de orquestación y gestión de aplicaciones en el campo de la infraestructura. En todo el ecosistema nativo de la nube, el proyecto Kubernetes ha jugado un papel en la vinculación del pasado y el próximo. A lo anterior, Kubernetes expone la abstracción de datos formateados de las capacidades de la infraestructura, como Servicio, Ingreso, Pod y Implementación, que son todas capacidades expuestas a los usuarios por la API nativa de Kubernetes. Por otro lado, Kubernetes proporciona interfaces estándar para el acceso a la capacidad de la infraestructura, como CNI, CSI, DevicePlugin y CRD, de modo que la nube se puede utilizar como proveedor de capacidad para acceder a las capacidades del sistema Kubernetes de forma estandarizada. Con el desarrollo de conceptos técnicos como microservicios y DevOps, las plataformas de aplicaciones abiertas basadas en la escalabilidad de Kubernetes reemplazarán a PaaS como la corriente principal, y el valor de la nube volverá a la aplicación en sí, y cada vez se verán más proyectos de código abierto. desarrollado con el concepto de implementación, operación y mantenimiento nativo en la nube, y finalmente evolucionó directamente a un servicio en la nube.
3. Microservicios
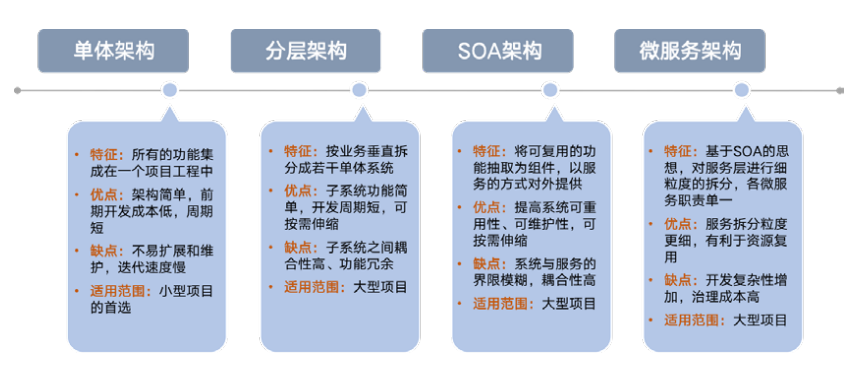
Los microservicios son el producto de la evolución de la arquitectura de servicios. Después de experimentar la arquitectura monolítica, la arquitectura vertical y la arquitectura orientada a servicios (SOA), la arquitectura de microservicios (MSA) puede considerarse como una implementación distribuida de la arquitectura SOA. A medida que el desarrollo empresarial y la demanda continúan aumentando, las funciones de una sola aplicación se han vuelto cada vez más complejas y la eficiencia de la iteración de la aplicación ha disminuido significativamente debido a los modos centralizados de I + D, pruebas, lanzamiento y comunicación.
La arquitectura de microservicio es esencialmente para soportar una mayor complejidad de operación y mantenimiento a cambio de una mayor agilidad. Su ventaja radica en ser pequeño, gobernado y descentralizado, pero también conduce a un aumento en la demanda, el costo y la complejidad de la infraestructura.
Hasta ahora, no existe una definición estándar unificada para microservicios, combinada con la descripción de Martin Fowler: la arquitectura de microservicio es un patrón / estilo arquitectónico que desarrolla una sola aplicación en un conjunto de pequeños servicios y se ejecuta de forma independiente en su propio proceso. Utilice mecanismos ligeros como como API HTTP para comunicarse entre sí. Estos servicios se basan en empresas específicas, se implementan de forma independiente a través de un mecanismo de implementación totalmente automatizado y se pueden escribir en diferentes lenguajes de programación, así como en diferentes tecnologías de almacenamiento de datos, y mantienen un mínimo de administración centralizada.
Dubbo y Spring Cloud se están moviendo hacia la integración, y más funciones se hundirán en la infraestructura
- Nube de primavera
Spring Cloud es el líder de la primera generación de arquitectura de microservicios. Proporciona una solución integral para la realización de la arquitectura de microservicios. Como una pila de tecnología de estilo familiar, proporciona a los desarrolladores herramientas para construir rápidamente un modelo común de sistemas distribuidos. Incluyendo administración de configuración, descubrimiento de servicios, fusibles, enrutamiento inteligente, micro-agentes, buses de control, tokens únicos, bloqueos globales, elección de líder, sesiones distribuidas, estado del clúster, etc.
- Dubbo
Como marco de servicio distribuido de código abierto de Alibaba, Dubbo se compromete a proporcionar soluciones de invocación de servicios remotos RPC transparentes y de alto rendimiento y soluciones de gobernanza de servicios SOA. La parte central incluye: comunicación remota, tolerancia a fallas de clúster, descubrimiento automático, etc.
En los últimos años, el ecosistema Dubbo ha seguido mejorando. En mayo de 2019, Dubbo-go se unió oficialmente al ecosistema oficial Dubbo, y posteriormente implementó el protocolo REST y el soporte gRPC, abriendo los ecosistemas Spring Cloud y gRPC. La interoperabilidad entre Go proyecto y se ha resuelto el proyecto Java & Dubbo Solución eficaz. Hoy, debido a la aparición de Spring Cloud Alibaba, Dubbo integrará a la perfección varios productos periféricos del ecosistema Spring Cloud.
Ya sea Dubbo o Spring Cloud, están más o menos limitados a escenarios de aplicaciones y entornos de desarrollo específicos, carecen de soporte para la versatilidad y el multilingüismo, y solo resuelven los problemas a nivel de desarrollo de microservicios, y carecen de la solución general de DevOps. han creado las condiciones para el surgimiento de Service Mesh.
Como solución completa para la gestión y comunicación de microservicios, Dubbo y Spring Cloud coexistirán y se fusionarán durante mucho tiempo, pero algunas de las funciones que brindan serán reemplazadas gradualmente por infraestructura.
- Por ejemplo, los microservicios implementados en el clúster de kubernetes, el uso de las funciones de registro y descubrimiento de servicios de kubernetes será más fácil;
- Otro ejemplo es el uso de la arquitectura Istio, funciones como la gestión del tráfico y el disyuntor se transferirán al proxy del enviado, y cada vez más funciones se eliminarán de la aplicación y se hundirán en la infraestructura.
4. Malla de servicio
Service Mesh generalmente se traduce como service mesh En la compleja topología de servicios de las aplicaciones nativas de la nube, Service Mesh es la capa de infraestructura responsable de la entrega confiable de solicitudes en estas topologías. Service Mesh agrega un Sidecar a la ruta de la llamada de solicitud, hunde las funciones complejas originalmente completadas por el cliente en el Sidecar, realiza la simplificación del cliente y la transferencia del control de la comunicación entre los servicios. sistema, el servicio La relación de invocación entre ellos se expresa como una malla, que es también el origen del nombre de la red de servicios.
Podemos resumir y resumir la definición de Service Mesh a partir de las siguientes características:
- Abstracción: Service Mesh quita la función de comunicación de la aplicación, forma una capa de comunicación separada y la hunde en la capa de infraestructura.
- Función: Service Mesh es responsable de realizar la entrega confiable de solicitudes, que no es diferente del método de biblioteca tradicional en términos de función.
- Implementación: Service Mesh se materializa como un agente de red liviano en implementación. Se implementa en modo Sidecar y aplicaciones uno a uno, y la comunicación entre los dos se llama de forma remota a través de Localhost.
- Transparencia: la implementación de funciones de Service Mesh es completamente independiente de la aplicación. Puede implementar actualizaciones, expandir funciones y reparar defectos de forma independiente. La aplicación no necesita prestar atención a los detalles específicos de implementación de Service Mesh, es decir, es transparente a la aplicación.
El valor central de Service Mesh no solo se refleja en sus funciones y características, sino también en la separación de la lógica empresarial y la lógica no empresarial. La lógica no empresarial se eliminará del SDK del cliente y se ejecutará como un proceso independiente de Proxy, con lo que se hundirán las diversas capacidades que existían originalmente en el SDK en el contenedor, Kubernetes o la infraestructura basada en VM, realizando alojamiento en la nube y aplicación ligera. Cuantifique para ayudar a la aplicación nativa de la nube.
El principal software de código abierto de Service Mesh incluye Linkerd, Envoy e Istio. Tanto Linkerd como Envoy encarnan directamente el concepto central de Service Mesh. Son similares en función, es decir, realizan el descubrimiento de servicios, solicitan enrutamiento, balanceo de carga y otras funciones, resuelven problemas de comunicación entre servicios y hacen que las aplicaciones no sean conscientes de la comunicación de servicios. Istio toma una perspectiva más alta y divide Service Mesh en plano de datos y plano de control. El plano de datos es responsable de todas las comunicaciones de red entre microservicios, mientras que el plano de control es responsable de administrar el proxy del plano de datos, e Istio, naturalmente, es compatible con Kubernetes. marco de programación de aplicaciones y Service Mesh.
El aterrizaje de microservicios requiere un conjunto completo de infraestructura. Cuando los contenedores se convierten en la unidad de trabajo más pequeña para los microservicios, Kubernetes, como plataforma general de administración de contenedores, puede aprovechar las mayores ventajas de la arquitectura de microservicios y convertirla en una nueva generación de computación en la nube. Sistema operativo. Kubernetes no solo admite la ejecución de aplicaciones en contenedores tradicionales y nativas de la nube, sino que también cubre las etapas de desarrollo y operaciones. La combinación con Service Mesh puede proporcionar a los usuarios una experiencia completa de microservicio de un extremo a otro.
5. Sin servidor
Serverless generaliza los escenarios de aplicación de Service Mesh, no solo se limita a la comunicación síncrona entre servicios, sino que también se extiende a más escenarios con acceso a la red y se realiza a través del SDK del cliente, incluido el servicio de computación, almacenamiento, base de datos, middleware, etc. Por ejemplo, en la práctica sin servidor de Ant Financial, el modo Mesh también se extiende a escenarios como Database Mesh (acceso a la base de datos), Message Mesh (mecanismo de mensajes) y Cache Mesh (almacenamiento en caché).
En la actualidad, Serverless generalmente se considera como una colección de FaaS (función como servicio) y BaaS (back-end como servicio), pero Serverless solo define una experiencia de usuario, no una determinada tecnología. FaaS y BaaS son solo un tipo de Método sin servidor para realizar. A medida que la tecnología sin servidor continúa madurando, más y más aplicaciones que utilizan los servicios de Kubernetes se transformarán en aplicaciones sin servidor.
6. Middleware nativo en la nube
El middleware tradicional es similar a una tubería de agua en una ciudad. Promueve y administra el flujo de datos de una aplicación a otra. Tiene un alto grado de acoplamiento comercial y no puede aportar valor directo a los usuarios. En la era de la nube, la heterogeneidad del software y la demanda de interconexión se han incrementado significativamente. Se le han dado nuevas definiciones funcionales al middleware, es decir, funciones independientes, bajo acoplamiento y componentes modulares. Un componente clave de una arquitectura de desarrollo de aplicaciones distribuidas con alta disponibilidad, alta escalabilidad y consistencia eventual.
Desde la perspectiva de la definición de funciones, el middleware es un tipo de software de computadora que conecta componentes de software y aplicaciones. Incluye un conjunto de servicios para que varios software que se ejecutan en una o más máquinas puedan interactuar a través de la red. Es reutilizable. Categoría de software. El middleware nativo de la nube incluye API, servidor de aplicaciones, TP, RPC, MOM y también puede asumir la función de integración de datos e integración de aplicaciones. Cualquier software entre el kernel y las aplicaciones de usuario puede entenderse como middleware.
Con el rápido desarrollo de IoT y tecnologías de computación en la nube, EDA (Event Driven Architecture) está siendo adoptada por más y más empresas. A través de la abstracción y asincronización de eventos, puede proporcionar desacoplamiento comercial y acelerar la iteración comercial. También está comenzando a respaldar Industrias verticales Cambio a la arquitectura general de aplicaciones críticas para el negocio, aplicadas en los campos de aplicaciones empaquetadas, herramientas de desarrollo, gestión y supervisión de procesos empresariales.
La EDA a menudo se implementa a través del middleware de mensajes. El middleware de mensajes tiene como objetivo utilizar un mecanismo de entrega de mensajes eficiente y confiable para el intercambio de datos independiente de la plataforma. Al proporcionar modelos de entrega y cola de mensajes, puede expandir la comunicación entre procesos en un entorno distribuido y sobre comunicación de datos integra sistemas distribuidos. El middleware de mensajes común incluye ActiveMQ, RabbitMQ, RocketMQ, Kafka, etc., que se pueden aplicar a escenarios como la transferencia de datos entre sistemas, el recorte de picos de tráfico de alta concurrencia y el procesamiento de datos asíncronos.
En la era de la computación en la nube, los proveedores de la nube brindan paquetes más cercanos a los negocios y, en su mayoría, utilizan sus propios servicios sin servidor para ejecutar cargas de eventos. Las capacidades de middleware se implementan fácilmente a través de servicios en la nube, incluidos Alibaba Cloud Function Compute, Azure Function y AWS Lambda Manejo de eventos.
En el futuro, el middleware de aplicaciones ya no será un proveedor de capacidades, sino una interfaz estándar para el acceso a las capacidades. Esta interfaz estándar se creará a través de los protocolos HTTP y gRPC, y la capa de acceso de toda la lógica empresarial de servicios y aplicaciones se desacoplará. a través de Sidecar, que es coherente con la idea de Service Mesh. Además, el modelo Sidecar se puede aplicar a todos los escenarios de middleware, "hundiendo" las capacidades de middleware en una parte de las capacidades de Kubernetes.
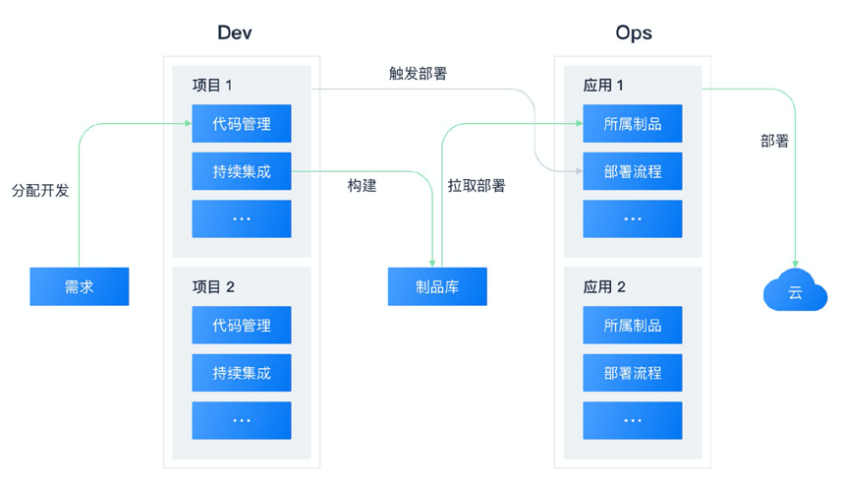
7. DevOps
Con la mejora continua del ecosistema de código abierto nativo de la nube y el hundimiento continuo de funciones complejas en la nube, el modelo básico de implementación, operación y mantenimiento de software se ha unificado básicamente. Antes de DevOps, los profesionales usaban el modelo en cascada o el modelo de desarrollo ágil para el desarrollo de proyectos de software. DevOps, como una combinación de Desarrollo y Operaciones, se define como un conjunto de prácticas para realizar la automatización de procesos entre el desarrollo de software y los equipos de TI. Estas prácticas se construyen sobre la base de una cultura colaborativa entre equipos y llenan el vacío entre el lado del desarrollo y el El lado de operación y mantenimiento La brecha de información para construir, probar y lanzar software de manera más rápida y confiable se ha convertido ahora en el modelo principal de desarrollo y entrega de software.

En general, DevOps incluye tres partes: desarrollo, pruebas y operación y mantenimiento. Específicamente, consta de múltiples etapas: desarrollo continuo, integración continua, pruebas continuas, retroalimentación continua, monitoreo continuo, implementación continua, operación y mantenimiento continuos, colectivamente referidos como el ciclo de vida de DevOps.
La separación e integración de las funciones de DevOps se refleja plenamente en el nivel de flujo de información. En las etapas de desarrollo, entrega, prueba, retroalimentación de prueba, entrega y publicación, varios proveedores y receptores de información utilizan herramientas y sistemas de alta calidad para lograr transmisión precisa de información y ejecución eficiente de operaciones mecanizadas.
A partir del concepto de desarrollo anterior, la idea de DevOps se deriva del hecho de que la capa de infraestructura no es lo suficientemente sólida ni lo suficientemente estandarizada, por lo que el lado comercial necesita un conjunto de herramientas para vincular al personal de I + D, operación y mantenimiento y la infraestructura correspondiente. Pero a medida que Kubernetes y la infraestructura se vuelven cada vez más complejos, el ecosistema nativo de la nube creará las correspondientes abstracciones y capas. La función de cada capa solo interactúa con su propia abstracción de datos, es decir, el enfoque del lado del desarrollo y del lado de la operación y el mantenimiento. Separado. El Serverless, cada vez más generalizado, también se convertirá en una orientación ideológica y en parte de DevOps. Por el lado de la capacidad, "operación y mantenimiento livianos", "NoOps" y "capacidades de operación y mantenimiento de autoservicio" se convertirán en los métodos principales de operación y mantenimiento de aplicaciones. En el lado de la aplicación, la descripción de la aplicación se resumirá ampliamente en el lado del usuario, los conceptos impulsados por eventos y sin servidor se dividen y generalizan, y se pueden aplicar a escenarios diversificados distintos de FaaS.
Artículos relacionados