formato de almacenamiento de archivos
Desde el sitio web oficial de Hive, Apache Hive admite varios formatos de archivo familiares que se usan en Apache Hadoop, como TextFile(文本格式), RCFile(行列式文件), SequenceFile(二进制序列化文件), y AVRO, de los cuales actualmente usamos , y .ORC(优化的行列式文件)ParquetTextFileSequenceFileORCParquet
Echemos un vistazo más de cerca a estos dos almacenamientos determinantes.
1, ORCO
1.1 Estructura de almacenamiento ORC
Primero obtenemos el diagrama del modelo de almacenamiento ORC del sitio web oficial
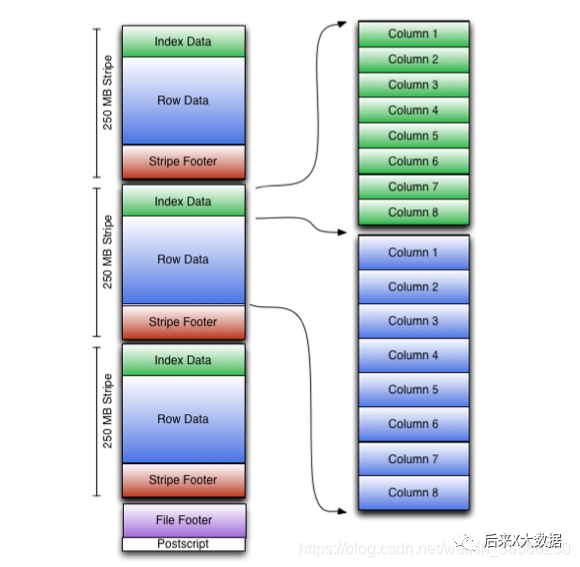
Parece un poco complicado, así que simplifiquemos un poco, dibujé un diagrama simple para ilustrar
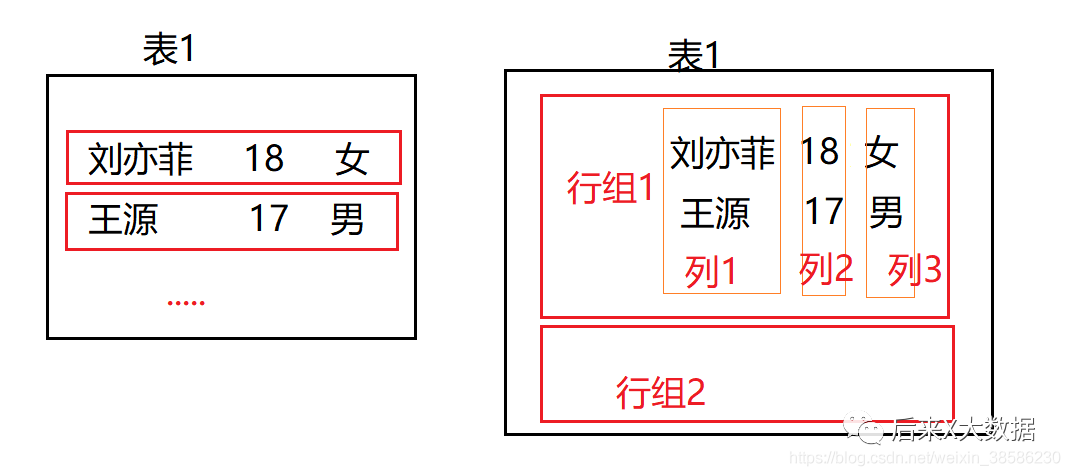
La figura de la izquierda muestra el método tradicional de almacenamiento de base de datos basado en filas, que se almacena por fila. Si no hay un índice de almacenamiento, si necesita consultar un campo, debe encontrar los datos de toda la fila y luego filtrar it, que consume más recursos de IO., por lo que al principio se utilizó el método index para resolver este problema en Hive.
Sin embargo, debido al alto costo de los índices, "en el Hive 3.X actual, los índices se han abolido" y, por supuesto, se introdujo el almacenamiento en columnas durante mucho tiempo.
El método de almacenamiento de almacenamiento en columnas se almacena una columna a la vez, como se muestra en la figura de la derecha en la figura anterior.En este caso, si consulta los datos de un campo, es equivalente a una consulta de índice, que es altamente eficiente . Sin embargo, si necesita buscar toda la tabla, requerirá más recursos porque necesita tomar todas las columnas y resumirlas por separado. Entonces apareció el almacenamiento de determinantes ORC.
-
Cuando se requiere un escaneo completo de la tabla, se puede leer por grupo de filas
-
Si necesita obtener datos de columna, lea la columna especificada sobre la base del grupo de filas, en lugar de los datos de todas las filas en todos los grupos de filas y los datos de todos los campos en una fila.
Después de comprender la lógica básica del almacenamiento ORC, echemos un vistazo a su diagrama de modelo de almacenamiento.
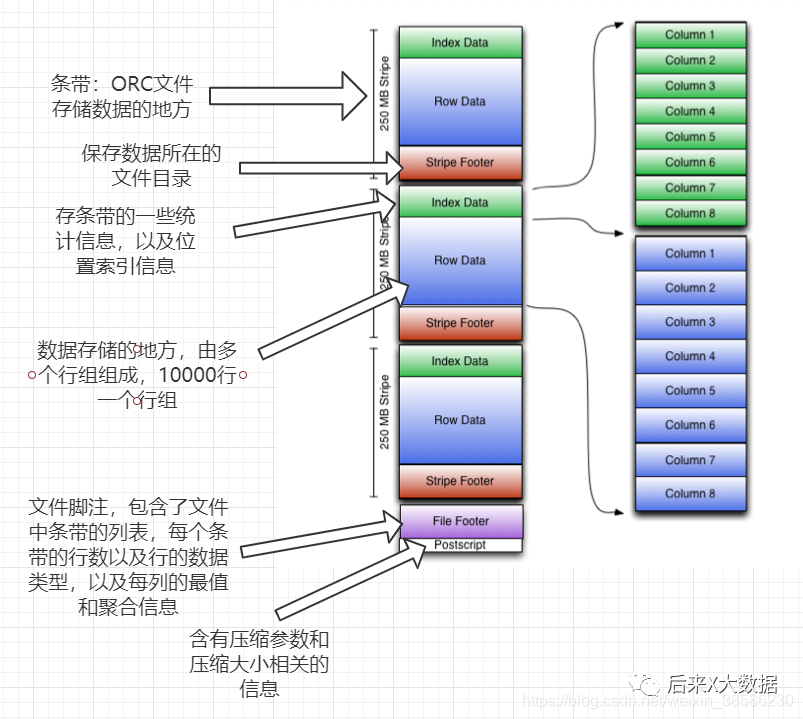
Al mismo tiempo, también adjunto el texto detallado a continuación, para que pueda consultarlo:
-
Franja: donde el archivo ORC almacena datos, cada franja generalmente tiene el tamaño de bloque de HDFS. (Contiene las siguientes 3 partes)
index data:保存了所在条带的一些统计信息,以及数据在 stripe中的位置索引信息。
rows data:数据存储的地方,由多个行组构成,每10000行构成一个行组,数据以流( stream)的形式进行存储。
stripe footer:保存数据所在的文件目录
-
Pie de página del archivo: contiene una lista de ranuras en el archivo, el número de líneas en cada franja y el tipo de datos de cada columna. También contiene información agregada como mínimo, máximo, recuento de filas, suma, etc. para cada columna.
-
posdata: contiene información sobre los parámetros de compresión y el tamaño de compresión
Entonces, de hecho, se encontró que ORC proporciona tres niveles de índices, nivel de archivo, nivel de franja y nivel de grupo de filas. Por lo tanto, al consultar, estos índices se pueden usar para evitar la mayoría de los archivos y bloques de datos que no cumplen con las condiciones de consulta. .
Sin embargo, tenga en cuenta que la información de descripción de todos los datos en ORC se junta con los datos almacenados y no utiliza una base de datos externa.
"Nota especial: las tablas en formato ORC también admiten transacciones ACID, pero las tablas que admiten transacciones deben ser tablas en cubos, por lo que es adecuado para actualizar grandes lotes de datos. No se recomienda actualizar con frecuencia pequeños lotes de datos con transacciones".
#开启并发支持,支持插入、删除和更新的事务
set hive. support concurrency=truei
#支持ACID事务的表必须为分桶表
set hive. enforce bucketing=truei
#开启事物需要开启动态分区非严格模式
set hive.exec,dynamicpartition.mode-nonstrict
#设置事务所管理类型为 org. apache.hive.q1. lockage. DbTxnManager
#原有的org. apache. hadoop.hive.q1.1 eckmar. DummyTxnManager不支持事务
set hive. txn. manager=org. apache. hadoop. hive. q1. lockmgr DbTxnManageri
#开启在相同的一个 meatore实例运行初始化和清理的线程
set hive. compactor initiator on=true:
#设置每个 metastore实例运行的线程数 hadoop
set hive. compactor. worker threads=l
#(2)创建表
create table student_txn
(id int,
name string
)
#必须支持分桶
clustered by (id) into 2 buckets
#在表属性中添加支持事务
stored as orc
TBLPROPERTIES('transactional'='true‘);
#(3)插入数据
#插入id为1001,名字为student 1001
insert into table student_txn values('1001','student 1001');
#(4)更新数据
#更新数据
update student_txn set name= 'student 1zh' where id='1001';
# (5)查看表的数据,最终会发现id为1001被改为 sutdent_1zh
1.2 Configuración de Hive sobre ORC
Propiedades de configuración de la tabla (configuradas al crear una tabla, por ejemplo tblproperties ('orc.compress'='snappy');)
-
orc.compress: Indica el tipo de compresión del archivo ORC "Los tipos opcionales son NONE, ZLB y SNAPPY. El valor predeterminado es ZLIB (Snappy no admite cortes)" --- Esta configuración es la más crítica.
-
orc.compress.Slze: Indica el tamaño del bloque comprimido (chunk), el valor por defecto es 262144 (256KB).
-
orc.stripe.size: banda de escritura, el tamaño del grupo de búfer de memoria que se puede usar, el valor predeterminado es 67108864 (64 MB)
-
orc.row.index.stride: el tamaño de datos del índice de nivel de grupo de filas, el valor predeterminado es 10000, debe establecerse en un número mayor o igual a 10000
-
orc.create index: Ya sea para crear un índice de nivel de grupo de filas, el valor predeterminado es verdadero
-
orc.bloom filter.columns: Los grupos que necesitan crear filtros de floración.
-
orc.bloom filter fpp: La probabilidad de falso positivo (Falso Positivo) usando el filtro bloom, el valor predeterminado es 0.
Extensión: el uso del filtro bloom en Hive puede determinar rápidamente si los datos se almacenan en la tabla con menos espacio de archivo, pero también hay una situación en la que se determina que los datos que no pertenecen a esta tabla pertenecen a esta tabla, que es llamada Probabilidad de falso positivo, los desarrolladores pueden ajustar la probabilidad, pero cuanto menor sea la probabilidad, el filtro Bloom necesita
2, parqué
Después de hablar sobre ORC arriba, también tenemos una comprensión básica del almacenamiento de filas y columnas, y Parquet es otra estructura de almacenamiento de filas y columnas de alto rendimiento.
2.1 Estructura de almacenaje de Parquet
Dado que ORC es tan eficiente, ¿por qué debería haber otro Parquet? Eso es porque "Parquet es para hacer que una representación de datos en columnas comprimida y eficiente esté disponible para cualquier proyecto en el ecosistema de Hadoop".
❝Parquet es independiente del lenguaje y no está vinculado a ningún marco de procesamiento de datos. Es adecuado para una variedad de lenguajes y componentes. Los componentes que pueden funcionar con Parquet son:
Motores de consulta: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
Marco informático: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
Modelos de datos: Avro, Thrift, Protocol Buffers, POJO
❞
Echemos un vistazo a la estructura de almacenamiento de Parquet, primer vistazo al sitio web oficial

Bueno, es un poco grande, dibujaré una versión simplificada.
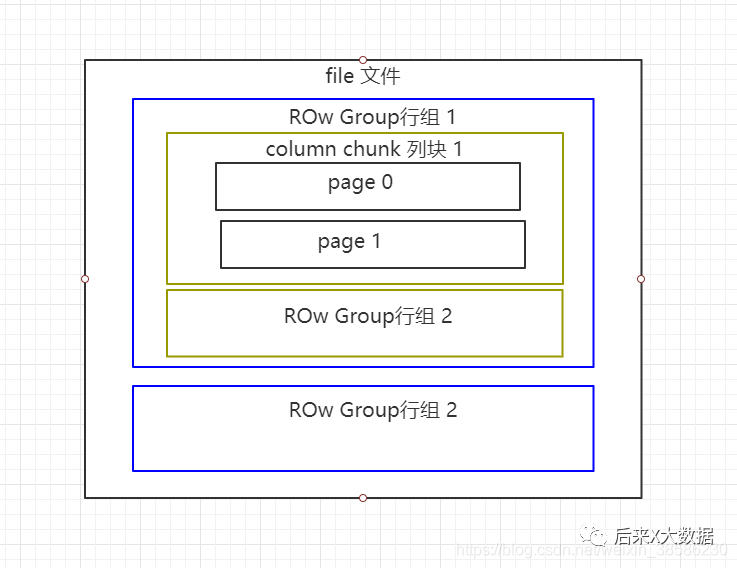
Los archivos de Parquet se almacenan en formato binario, por lo que no se pueden leer directamente. Al igual que ORC, los metadatos del archivo se almacenan con los datos, por lo que los archivos en formato de Parquet se autoanalizan.
-
Grupo de filas: cada grupo de filas contiene una cierta cantidad de filas, y al menos un grupo de filas se almacena en un archivo HDFS, similar al concepto de franja de orco.
-
Fragmento de columna: cada columna en un grupo de filas se almacena en un bloque de columnas, y todas las columnas en el grupo de filas se almacenan consecutivamente en este archivo de grupo de filas. Los valores en un bloque de columnas son todos del mismo tipo, y diferentes bloques de columnas pueden comprimirse usando diferentes algoritmos.
-
Página: cada bloque de columnas se divide en varias páginas. Una página es la unidad de codificación más pequeña. Diferentes páginas en el mismo bloque de columnas pueden usar diferentes métodos de codificación.
2.2Propiedades de configuración de la mesa de parquet
-
parquet.block size: el valor predeterminado es 134217728 bytes, que son 128 MB, lo que indica el tamaño de bloque del grupo de filas en la memoria. Si este valor se establece en un valor grande, se puede mejorar la eficiencia de lectura de los archivos de Parquet, pero, en consecuencia, se consume más memoria al escribir.
-
parquet.page:size: El valor predeterminado es 1048576byt, que es 1MB, lo que indica el tamaño de cada página (página). Esto se refiere específicamente al tamaño de la página comprimida, y los datos de la página se descomprimirán primero al leer. Una página es la unidad más pequeña de datos operativos de Parquet, y se debe leer una página completa de datos cada vez para acceder a los datos. Si este valor se establece demasiado pequeño, causará problemas de rendimiento al comprimir
-
parquet.compression: El valor por defecto es SIN COMPRIMIR, que indica el método de compresión de la página. "Los métodos de compresión disponibles son UNCOMPRESSED, SNAPPY, GZP y LZO" .
-
Parquet enable.dictionary: el valor predeterminado es tue, lo que indica si la codificación del diccionario está habilitada.
-
parquet.dictionary page.size: el valor predeterminado es 1048576 bytes, que es 1 MB. Cuando se utiliza la codificación de diccionario, se crea una página de diccionario en cada fila y columna de Parquet. Usando la codificación de diccionario, si hay muchos datos repetidos en las páginas de datos almacenadas, puede tener un buen efecto de compresión y también puede reducir la ocupación de memoria de cada página.
3. Comparación de ORC y Parquet
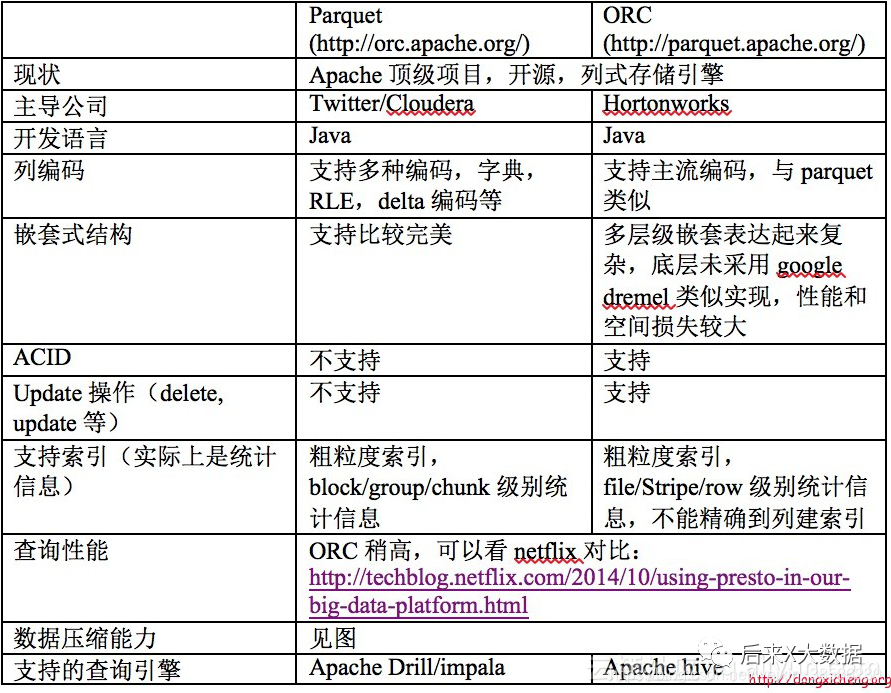
Al mismo tiempo, del caso del autor de "Hive Performance Tuning in Practice", 2 tablas que usan los formatos de almacenamiento ORC y Parquet respectivamente, importan los mismos datos y realizan una consulta sql, "se encuentra que las filas se leen usando ORC son mucho más pequeños que Parquet" , por lo que al usar ORC como almacenamiento, puede filtrar más datos innecesarios con la ayuda de metadatos, y la consulta requiere menos recursos de clúster que Parquet. (Para obtener un análisis de rendimiento más detallado, diríjase a https://blog.csdn.net/yu616568/article/details/51188479)
"Entonces, ORC aún se ve mejor en términos de almacenamiento"
Método de compresión
| Formato | Divisible | Velocidad media de compresión | Eficiencia de compresión de archivos de texto | Códec de compresión Hadoop | Implementación de Java puro | Nativo | Observación |
|---|---|---|---|---|---|---|---|
| gzip | no | rápido | alto | org.apache.hadoop.io.compress.GzipCodec | Sí | Sí | |
| lzo | sí (dependiendo de la biblioteca utilizada) | muy rapido | medio | com.hadoop.compression.lzo.LzoCodec | Sí | Sí | Requiere que LZO esté instalado en cada nodo |
| bzip2 | Sí | lento | muy alto | org.apache.hadoop.io.compress.Bzip2Codec | Sí | Sí | Use Java puro para la versión divisible |
| zlib | no | lento | medio | org.apache.hadoop.io.compress.DefaultCodec | Sí | Sí | Códec de compresión predeterminado de Hadoop |
| Rápido | no | muy rapido | Bajo | org.apache.hadoop.io.compress.SnappyCodec | no | Sí | Snappy tiene un puerto Java puro, pero no funciona con Spark/Hadoop |
¿Cómo elegir la combinación de almacenamiento y compresión?
De acuerdo con los requisitos de ORC y parquet, generalmente hay
1. Almacenamiento en formato ORC, compresión Snappy
create table stu_orc(id int,name string)
stored as orc
tblproperties ('orc.compress'='snappy');
2, almacenamiento en formato Parquet, compresión Lzo
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='lzo');
3, almacenamiento en formato Parquet, compresión Snappy
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='snappy');
Debido a que el SQL de Hive se convertirá en tareas de MR, si el archivo se almacena en ORC, Snappy lo comprime. Debido a que Snappy no admite la división de archivos, el archivo comprimido "solo será leído por una tarea" . Si el archivo comprimido es grande, entonces el tiempo requerido para procesar el mapa del archivo será mucho más largo que el tiempo de lectura del mapa del archivo ordinario, que a menudo se denomina "el sesgo de datos del mapa que lee el archivo" .
Para evitar esta situación, es necesario utilizar algoritmos de compresión que admitan la segmentación de archivos, como bzip2 y Zip, al comprimir datos. Sin embargo, ORC no es compatible con estos métodos de compresión que se acaban de mencionar, por lo que esta es la razón por la cual las personas no eligen ORC cuando pueden encontrar archivos grandes para evitar la desviación de datos.
En el enfoque Hve on Spark, ocurre lo mismo. Spark, como arquitectura distribuida, generalmente intenta leer datos de varias máquinas diferentes juntas. Para lograr esto, cada nodo de trabajo debe poder encontrar el comienzo de un nuevo registro, lo que requiere que el archivo se divida, pero algunos archivos en formatos comprimidos que no se pueden dividir requieren un solo nodo para leer todos los datos. Esto puede fácilmente crear cuellos de botella en el rendimiento.