1 Teoría de capas y modelado del almacén de datos
1.1 Propósito del almacén de datos
- Integre todos los datos comerciales de la empresa y establezca un centro de datos unificado
- Generar informes comerciales para la toma de decisiones.
- Proporcionar soporte de datos operativos para las operaciones del sitio web.
- Se puede utilizar como fuente de datos para cada negocio, formando un círculo virtuoso de retroalimentación mutua de los datos comerciales.
- Analice los datos de comportamiento del usuario, reduzca los costos de entrada y mejore los efectos de entrada a través de la minería de datos
- Desarrollar productos de datos que directa o indirectamente beneficien a la empresa
1.2 Diagrama de arquitectura de operación de almacén de datos
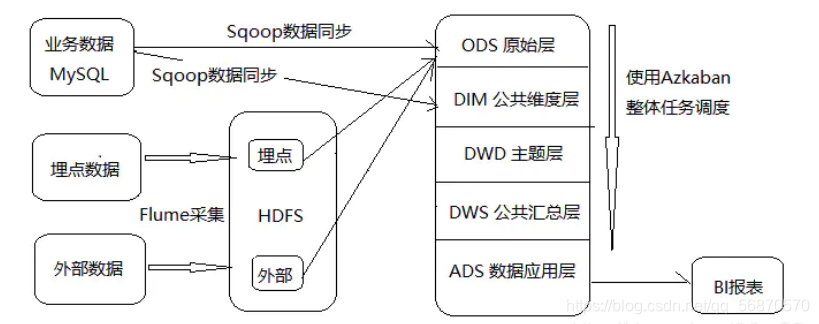
1.3 La diferencia entre data mart y data warehouse
Data Mart (mercado de datos): es un almacén de datos en miniatura, que generalmente tiene menos datos, menos áreas temáticas y menos datos históricos, por lo que es a nivel de departamento y generalmente solo para una cierta gama parcial de servicios de administración.
Almacén de datos (Data Warehouse): El almacén de datos es de nivel empresarial y puede proporcionar medios de apoyo a la toma de decisiones para el funcionamiento de varios departamentos de toda la empresa.
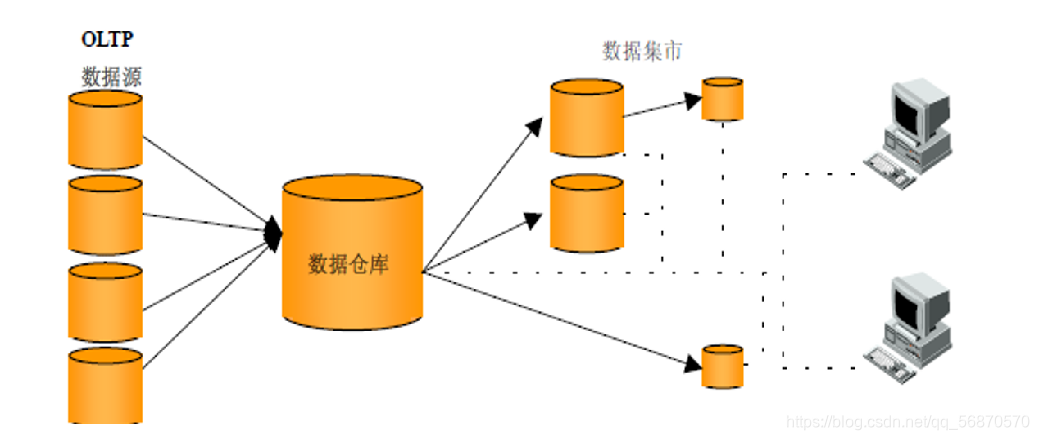
1.4 Jerarquía del almacén de datos
1.4.1 Razones para la estratificación
- Simplifique los problemas complejos: descomponga las tareas complejas en múltiples capas para completar, y cada capa solo maneja tareas simples, lo cual es conveniente para localizar problemas.
- Reduzca el desarrollo repetitivo: estandarice las capas de datos y use los datos de la capa intermedia para reducir una gran cantidad de cálculos repetidos y aumentar la reutilización de los resultados de los cálculos.
- Aísle los datos sin procesar: ya se trate de anomalías de datos o de sensibilidad de los datos, separe los datos reales de los datos estadísticos.
1.4.2 Modelo Jerárquico Básico
ODS (capa de fuente de datos, datos sin procesar) – ETL --> DWD (capa de detalle de datos) – hive sql --> DWS (resumen de datos) – sqoop --> ADS (aplicación de datos: informes, retratos de usuarios)
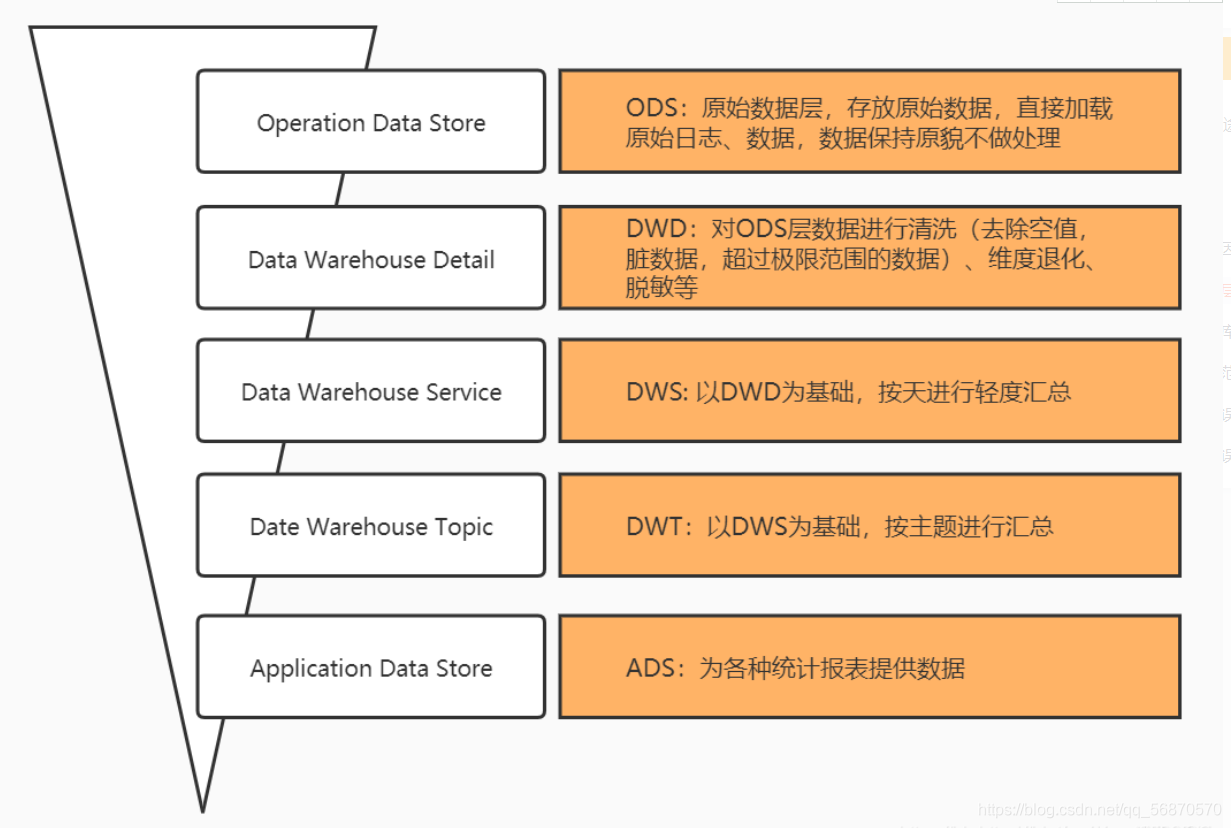
1.5 Jerarquía del almacén de datos
1.5.1 Descripción general de la jerarquía del almacén de datos
En el sistema de datos de Alibaba, se recomienda dividir el almacén de datos en tres capas, de abajo hacia arriba:
Capa de introducción de datos ODS (almacén de datos de operación): almacene datos sin procesar en el sistema de almacenamiento de datos, que es consistente con la estructura del sistema de origen, y es el área de preparación de datos del almacenamiento de datos. Completar principalmente las tareas de importar datos básicos a MaxCompute y registrar los cambios históricos de datos básicos.
Capa pública de datos CDM (Modelo de datos común, también conocido como capa de modelo de datos común): incluida la tabla de dimensiones DIM, DWD y DWS, procesada a partir de datos de capa ODS. Principalmente, complete el procesamiento y la integración de datos, establezca dimensiones consistentes, cree tablas de hechos detalladas reutilizables para análisis y estadísticas, y resuma los indicadores de granularidad públicos. De acuerdo con las características comerciales actuales, solo se establece temporalmente la capa DWD
-
Capa de hechos detallados (DWD): con el proceso de negocio como controlador de modelado, en función de las características de cada proceso de negocio específico, cree la tabla de hechos de nivel de detalle más detallado. Algunos campos de atributos de dimensión importantes de la tabla de hechos detallados pueden ser apropiadamente redundantes en combinación con las características de uso de datos de la empresa, es decir, el procesamiento de tablas amplias.
-
Capa intermedia de datos: DWM (Data Ware House Middle) Esta capa realizará operaciones ligeras de agregación en los datos basados en los datos de la capa DWD, generará una serie de tablas intermedias, mejorará la reutilización de los indicadores públicos y reducirá el procesamiento repetido. Intuitivamente hablando, es agregar dimensiones básicas comunes y calcular los indicadores estadísticos correspondientes.
-
Capa de hechos de granularidad de resumen público (DWS): con el sujeto objeto de análisis como el controlador de modelado, en función de los requisitos de indicador de producto y aplicación de nivel superior, cree una tabla de hechos de indicador de resumen granular público y fisicalice el modelo por medio de una amplia mesa. Construya indicadores estadísticos con convenciones de nomenclatura y calibre consistente, proporcione indicadores públicos para la capa superior y establezca tablas amplias de resumen y tablas de hechos detalladas.
-
Capa de dimensión común (DIM): según el concepto de modelado dimensional, establezca una dimensión uniforme para toda la empresa. Reduzca el riesgo de algoritmos y calibres de cálculo de datos inconsistentes. Las tablas de la capa de dimensiones comunes también suelen denominarse tablas de dimensiones lógicas, y las dimensiones y las tablas lógicas de dimensiones suelen tener una correspondencia biunívoca.
-
Capa de aplicación de datos ADS (Application Data Service): almacena datos de índices estadísticos personalizados de productos de datos. Generado de acuerdo con el procesamiento de capas CDM y ODS.
Chino e inglés y abreviaturas:
Capa de introducción de datos (ODS, Operation Data Store)
Capa pública de datos (CDM, Common Data Model)
Capa de dimensión común (DIM, Dimensión)
Detalle del almacén de datos (DWD, detalle del almacén de datos)
Capa de resumen de datos (DWS, servicio de almacenamiento de datos)
Capa de aplicación de datos (ADS, Application Data Service)
1.5.2 Usos de cada nivel
**1) Capa de introducción de datos (ODS, Operation Data Store): **Los datos originales se almacenan en el sistema de almacenamiento de datos casi sin procesamiento. La estructura es básicamente consistente con el sistema de origen, y es el área de preparación de datos de el almacén de datos. Datos sin procesar, principalmente datos de puntos enterrados (datos de registro) y datos de operaciones comerciales (binlong), la fuente de datos es principalmente Mysql, HDFS, Kafka, etc.
2) Capa pública de datos (CDM, Common Data Model, también conocida como capa de modelo de datos común) , incluida la tabla de dimensiones DIM, DWD y DWS, procesada a partir de datos de la capa ODS. Principalmente completa el procesamiento y la integración de datos, establece dimensiones coherentes, crea tablas de hechos detalladas reutilizables para análisis y estadísticas, y resume indicadores de granularidad pública . Esta capa incluye tres capas:
- Capa de dimensión común (DIM):
- Basado en el concepto de modelado dimensional, establezca una dimensión consistente para toda la empresa. Reduzca el riesgo de algoritmos y calibres de cálculo de datos inconsistentes. Las tablas de la capa de dimensiones comunes también suelen denominarse tablas de dimensiones lógicas, y las dimensiones y las tablas lógicas de dimensiones suelen tener una correspondencia biunívoca.
- Utilice principalmente tres motores de almacenamiento: MySQL, Hbase y Redis. MySQL se puede utilizar cuando los datos de la tabla de dimensiones son relativamente pequeños. En el caso de que el tamaño de los datos individuales sea relativamente pequeño y el QPS de la consulta sea relativamente alto, se puede utilizar el almacenamiento de Redis. para reducir la ocupación de recursos de memoria de la máquina Para escenarios donde la cantidad de datos es relativamente grande y no es particularmente sensible a los cambios en los datos de la tabla de dimensiones, se puede usar el almacenamiento HBase.
- Capa de detalles del almacén de datos (DWD) :
- La capa de ODS se limpia y se coloca sobre esta capa, que generalmente es la granularidad más fina.
- Con el proceso comercial como controlador de modelado, **construya la tabla de hechos a nivel de detalle más detallada en función de las características de cada proceso comercial específico. **En combinación con las características de uso de datos de la empresa, algunos campos de atributos de dimensión importantes de la tabla de hechos detallada pueden ser apropiadamente redundantes, es decir, procesamiento de tabla amplia.
- Capa de resumen de datos (DWS):
- Ligera agregación de la capa DWD y agregación de algunos indicadores acumulativos para aumentar la reutilización.
- Tomando el tema objeto de análisis como el controlador de modelado, en función de los requisitos de índice de producto y aplicación de nivel superior, cree una tabla de hechos de índice de resumen con granularidad pública y fisicalice el modelo por medio de una tabla ancha. Construya indicadores estadísticos con convenciones de nomenclatura y calibre consistente, proporcione indicadores públicos para la capa superior y establezca tablas amplias de resumen y tablas de hechos detalladas. Las tablas de la capa de hechos de granularidad de resumen público generalmente también se denominan tablas lógicas de resumen, que se utilizan para almacenar datos de indicadores derivados.
3) Capa de aplicación de datos (ADS, Application Data Service) : almacena datos de índice estadístico personalizados de productos de datos. Generado de acuerdo con el procesamiento de capas CDM y ODS.
1.6 Especificaciones de desarrollo
1.6.1 Reglas de nomenclatura
1) capa de ods
增量数据: {
project_name}.ods_{
数据来源}_{
源系统表名}_delta
全量数据: {
project_name}.ods_{
数据来源}_{
源系统表名}
数据来源说明:
01 -> hdfs 数据
02 -> mysql 数据
03 -> redis 数据
04 -> mongodb 数据
05 -> tidb 数据
举例如下:
行为日志表: ods_01_action_log
用户表: ods_02_user
2) capa tenue
公共区域维表: {
project_name}.dim_pub_{
自定义命名标签}
具体业务维表: {
project_name}.dim_{
业务缩写}_{
自定义命名标签}
举例如下:
公共区域维表: dim_pub_area
公共时间维表: dim_pub_date
A公司电商板块的商品全量表: dim_asale_itm
3) capa dwd
多个业务公共表: {
project_name}.dwd_pub_{
自定义命名标签}
具体业务数据增量表: {
project_name}.dwd_{
业务缩写}_{
自定义命名标签}_di
具体业务数据全量表: {
project_name}.dwd_{
业务缩写}_{
自定义命名标签}_df
举例如下:
交易会员信息事实表:ods_asale_trd_mbr_di
交易商品信息事实表:dwd_asale_trd_itm_di
交易订单信息事实表:dwd_asale_trd_ord_di
4) capa dws
多个业务公共表: {
project_name}.dws_pub_{
自定义命名标签}
具体业务最近一天汇总事实表: {
project_name}.dws_{
业务缩写}_{
自定义命名标签}_1d
具体业务最近N天汇总事实表: {
project_name}.dws_{
业务缩写}_{
自定义命名标签}_nd
具体业务历史截至当天汇总表: {
project_name}.dws_{
业务缩写}_{
自定义命名标签}_td
具体业务小时汇总表: {
project_name}.dws_{
业务缩写}_{
自定义命名标签}_hh
举例如下:
dws_asale_trd_byr_subpay_1d(A电商公司买家粒度交易分阶段付款一日汇总事实表)
dws_asale_trd_byr_subpay_td(A电商公司买家粒度分阶段付款截至当日汇总表)
dws_asale_trd_byr_cod_nd(A电商公司买家粒度货到付款交易汇总事实表)
dws_asale_itm_slr_td(A电商公司卖家粒度商品截至当日存量汇总表)
dws_asale_itm_slr_hh(A电商公司卖家粒度商品小时汇总表)---维度为小时
dws_asale_itm_slr_mm(A电商公司卖家粒度商品分钟汇总表)---维度为分钟
5) capa de anuncios
{
project_name}.ads_{
业务缩写}_{
自定义命名标签}
举例如下:
订单统计表: ads_nshop_order_form
订单支付统计: ads_nshop_orderpay_form
1.7 Malentendidos de las capas
La división interna de la capa del almacén de datos no es para capas, sino para resolver varios problemas, como la organización de tareas y flujos de trabajo de ETL, el flujo de datos, el control de permisos de lectura y escritura y la satisfacción de diferentes necesidades.
Una práctica más común en la industria es dividir toda la capa de almacenamiento de datos (DW) en dwd, dwb, dws, dim, mid y muchas otras capas. Sin embargo, todavía no podemos decir cuáles son los límites claros entre estas capas, o podemos explicar claramente los límites entre ellos, pero los escenarios comerciales complejos nos impiden implementarlos.
Por lo tanto, las tres capas de estratificación de datos, ODS, DWD y DWS, son generalmente las más básicas:
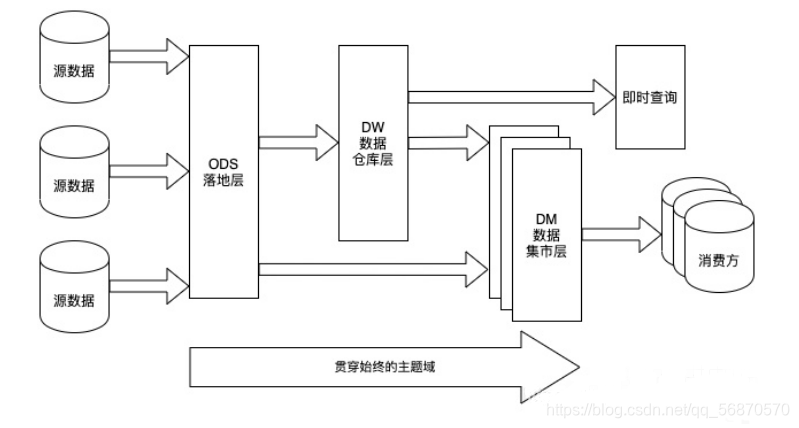
En cuanto a cómo dividir la capa DW, se define de acuerdo con las necesidades comerciales específicas y los escenarios de la empresa. En términos generales, necesita:
- La estratificación es el propósito de resolver el flujo de datos y respaldar rápidamente el negocio;
- Debe ser penetrado de acuerdo con el dominio de la materia y el dominio del negocio;
- No hay dependencia inversa entre capas.
- Si el soporte de datos se puede completar confiando en los datos de la capa ODS, entonces el lado comercial usa directamente la capa de aterrizaje, que también conduce a la exploración y experimentación rápida y de bajo costo de algunos datos.
- Después de determinar la especificación en capas, es mejor seguir esta estructura en el futuro, y se puede acordar;
- Primero se admiten la consanguinidad, la dependencia de datos, el diccionario de datos, las convenciones de nomenclatura de datos, etc.;
La estratificación en DW no es la más correcta, solo la más adecuada para ti.
1.8 Malentendidos de tablas anchas
Las tablas anchas se introducen en la capa del almacén de datos. La llamada mesa ancha, hasta el momento no existe una definición clara. Una práctica común es asociar muchas dimensiones, resúmenes de hechos o desgloses con una determinada tabla de hechos para formar una tabla que contenga un gran número de dimensiones y hechos relacionados.
El uso de mesas anchas tiene su cierta comodidad. El usuario no necesita considerar la asociación con la tabla de dimensiones, ni necesita comprender qué son la tabla de dimensiones y la tabla de hechos.
Sin embargo, a medida que crece el negocio, todavía no podemos diseñar y definir de manera predecible cuántas dimensiones deben ser redundantes en las tablas anchas, ni podemos definir claramente dónde se encuentra el resultado final de las dimensiones redundantes en las tablas anchas.
Una situación posible es que para cumplir con los requisitos de uso, las columnas existentes en la tabla de dimensiones deben agregarse continuamente a la tabla ancha. Esto conduce directamente a cambios frecuentes en la estructura de la mesa de la mesa ancha.
Lo que hacemos actualmente es:
- De acuerdo con el dominio del tema y el dominio comercial, ordene todos los nodos de un determinado negocio;
- Use los datos de los nodos clave como base de la tabla de hechos y luego expanda horizontalmente los datos acumulados de otras tablas de hechos (incluidos algunos indicadores estadísticos) y, al mismo tiempo, agregue las dimensiones correspondientes a algunas claves principales en el nodo. verticalmente;
- La participación de tablas anchas no depende de los requisitos comerciales específicos, sino que coincide con la línea comercial general;
- Trate de usar modelos dimensionales en lugar de tablas anchas;
¿Por qué utilizar el modelado dimensional en lugar de tablas anchas tanto como sea posible? Incluso si los campos y los datos son redundantes, la forma de modelado dimensional también representará la cantidad total de datos. El modo de tabla ancha es mejor. Razones:
- El modelado dimensional se basa en un cierto hecho establecido. Dado que es una tabla de hechos, la granularidad de la tabla de hechos básicamente no cambiará si el negocio de esta pieza no cambia;
- La tabla de hechos y la tabla de dimensiones están desacopladas, y el cambio de la tabla de dimensiones básicamente no afectará a la tabla de hechos, y la tabla de resultados solo necesita actualizar el flujo de datos;
- Se pueden agregar dinámicamente nuevas dimensiones de acuerdo con el esquema de estrella o el esquema de copo de nieve;
- El modelo dimensional se puede utilizar como base de la tabla ancha. Una vez que se determina todo el flujo de datos, la tabla ancha correspondiente se puede regenerar a través del modelo dimensional para un soporte comercial rápido;
tabla de 2 dimensiones y tabla de hechos
2.1 Tabla de dimensiones
Tabla de dimensiones : generalmente describe los hechos. Cada tabla de dimensiones corresponde a un objeto o concepto en el mundo real. Por ejemplo: usuario, producto, fecha, región, etc.
Características de la tabla de dimensiones:
- Las tablas de dimensiones tienen un alcance amplio (con múltiples atributos, comparaciones de columnas)
- En comparación con la tabla de hechos, el número de filas es relativamente pequeño: generalmente < 100 000
- El contenido es relativamente fijo: tabla de códigos
Tabla de dimensiones de tiempo:
| identificación de fecha | día de la semana | día del año | el cuarto | vacaciones |
|---|---|---|---|---|
| 2020-01-01 | 2 | 1 | 1 | Año Nuevo |
| 2020-01-02 | 3 | 2 | 1 | ninguno |
| 2020-01-03 | 4 | 3 | 1 | ninguno |
| 2020-01-04 | 5 | 4 | 1 | ninguno |
| 2020-01-05 | 6 | 5 | 1 | ninguno |
2.2 Tabla de hechos
Tablas de hechos: cada almacén de datos contiene una o más tablas de hechos. Las tablas de hechos pueden contener datos de ventas comerciales, como los producidos por transacciones de cajas registradoras, y las tablas de hechos suelen contener una gran cantidad de filas. La característica principal de una tabla de hechos es que contiene datos numéricos (hechos), y esta información numérica se puede agregar para proporcionar datos sobre la unidad como un historial Cada tabla de hechos contiene un índice de varias partes que contiene Relevancia clave La tabla de dimensiones es la clave principal, mientras que la tabla de dimensiones contiene los atributos del registro de hechos. Las tablas de hechos no deben contener información descriptiva, ni deben contener datos que no sean campos de medidas numéricas y campos de índices relacionados que hagan que los hechos correspondan a los elementos de la tabla de dimensiones.
Hay dos tipos de "medidas" incluidas en una tabla de hechos: una es una medida que se puede acumular y la otra es una medida que no se acumula. Las medidas más útiles son las que se pueden enrollar, los números que se suman son muy significativos. Los usuarios pueden obtener información agregada acumulando métricas, p. Puede resumir las ventas de un artículo específico para un grupo de tiendas durante un período de tiempo específico. Las medidas no acumulativas también se pueden usar en las tablas de hechos. Los resultados agregados generalmente no tienen sentido. Por ejemplo, cuando se mide la temperatura en diferentes lugares de un edificio, no tiene sentido sumar las temperaturas en todos los lugares diferentes del edificio, pero Promediar hace sentido.
En términos generales, una tabla de datos de hechos está asociada con una o más tablas de latitud, y los usuarios pueden usar una o más tablas de dimensiones al crear cubos con tablas de datos de hechos .
Cada fila de datos en la tabla de hechos representa un evento comercial (pedido, pago, reembolso, revisión, etc.). El término "hecho" se refiere al valor de medición de un evento comercial (tiempos contables, número, cantidad, etc.), por ejemplo, el 21 de mayo de 2020, el Sr. Song Song compró una botella de ginseng de lobo de mar por 250 yuanes en Píldora de JD.com. Tablas de dimensiones: tiempo, usuario, producto, comerciante. Hoja informativa: 250 yuanes, una botella
Las filas de cada tabla de hechos incluyen: valores de medidas numéricas aditivas, claves externas conectadas con tablas de dimensiones, generalmente con dos o más claves externas.
Características de una tabla de hechos:
- muy grande
- El contenido es relativamente estrecho: el número de columnas es pequeño (principalmente ID de clave externa y valor de medida)
- Cambia con frecuencia, con muchas nuevas incorporaciones todos los días.
1) Tabla de hechos transaccionales
Tome cada transacción o evento como una unidad, como un registro de orden de venta, un registro de pago, etc., como una fila de datos en la tabla de hechos. Una vez que se confirma la transacción y se insertan los datos de la tabla de hechos, los datos ya no se cambiarán y el método de actualización es una actualización incremental.
2) Tabla de hechos de instantáneas periódicas
Las tablas de hechos de instantáneas periódicas no conservan todos los datos, sino solo los datos en intervalos de tiempo fijos, como las ventas diarias o mensuales, o los saldos de cuentas mensuales.
Por ejemplo, los carritos de compras, con sumas y restas de productos, pueden cambiar en cualquier momento, pero nos preocupa más cuántos productos hay al final de cada día, lo cual es conveniente para nuestro análisis estadístico posterior.
3) Tabla de hechos de instantáneas acumulativas
Se utiliza una tabla de hechos de instantáneas acumulativas para realizar un seguimiento de los cambios en los hechos comerciales. Por ejemplo, el almacén de datos puede necesitar acumular o almacenar los datos puntuales de cada etapa comercial del pedido desde el momento en que se realiza el pedido hasta el momento en que se empaqueta, envía y firma el pedido para rastrear el progreso del ciclo de estado de la orden. Cuando este proceso empresarial está en curso, los registros de la tabla de hechos también se actualizan constantemente.
| Solicitar ID | identificación de usuario | tiempo de la orden | Tiempo de empacar | el tiempo de entrega | Tiempo de presentación | Total de la orden |
|---|---|---|---|---|---|---|
| 3-8 | 3-8 | 3-9 | 3-10 |
3 Planificación del modelado del almacén de datos
3.1 Capa SAO
¿Cómo planificamos y procesamos los datos de comportamiento de los usuarios y los datos comerciales en HDFS?
(1) Mantenga la apariencia original de los datos sin ninguna modificación y desempeñe el papel de hacer una copia de seguridad de los datos.
(2) Los datos se comprimen para reducir el espacio de almacenamiento en disco (por ejemplo: los datos originales son 100 G, que se pueden comprimir hasta aproximadamente 10 G)
(3) Cree una tabla de particiones para evitar posteriores escaneos completos de la tabla
3.2 Capa DIM y capa DWD
La capa DIM y la capa DWD necesitan construir un modelo dimensional, que generalmente adopta un modelo de estrella, y el estado presentado es generalmente un modelo de constelación.
El modelado dimensional generalmente sigue los siguientes cuatro pasos:
Seleccione Proceso empresarial → Granularidad de declaración → Confirmar dimensión → Confirmar hecho
(1) Seleccionar proceso de negocio
En el sistema de negocios, seleccione la línea de negocios que nos interesa, como el negocio de pedidos, el negocio de pagos, el negocio de reembolsos, el negocio de logística y una línea de negocios corresponde a una tabla de hechos.
(2) Granularidad de la declaración
La granularidad de los datos se refiere al nivel de refinamiento o exhaustividad de los datos almacenados en el almacén de datos.
Declarar granularidad significa definir con precisión qué representa una fila de datos en la tabla de hechos. Se debe seleccionar la granularidad más pequeña posible para satisfacer diversas necesidades.
Una declaración de granularidad típica se ve así:
Una fila de datos en la tabla de hechos del pedido representa un artículo de mercancía en un pedido.
Una fila de datos en la tabla de hechos de pago representa un registro de pago.
(3) Determinar la dimensión
La función principal de las dimensiones es describir hechos comerciales, principalmente expresando información como "quién, dónde y cuándo".
El principio para determinar las dimensiones es: si analizar indicadores de dimensiones relacionadas en requisitos posteriores. Por ejemplo, es necesario hacer estadísticas sobre cuándo se realizaron la mayoría de los pedidos, qué región realizó la mayoría de los pedidos y qué usuario realizó la mayoría de los pedidos. Las dimensiones que deben determinarse incluyen: dimensión de tiempo, dimensión de región y dimensión de usuario.
(4) Determinar los hechos
La palabra "hecho" aquí se refiere al valor de medición en el negocio (tiempos, número, número de piezas, cantidad que se puede acumular), como cantidad de pedido, número de pedido, etc.
En la capa DWD, el proceso comercial se utiliza como unidad de modelado y, en función de las características de cada proceso comercial específico, se construye la tabla de hechos más detallada de la capa de detalles. Las tablas de hechos se pueden ampliar adecuadamente.
La asociación entre la tabla de hechos y la tabla de dimensiones es relativamente flexible, pero para cumplir con los requisitos comerciales más complejos, puede asociar las tablas que se pueden asociar tanto como sea posible.
| tiempo | usuario | área | mercancías | cupón | Actividad | métrico | |
|---|---|---|---|---|---|---|---|
| Orden | √ | √ | √ | Tarifa de envío/cantidad de la oferta/cantidad original/cantidad final | |||
| detalles del pedido | √ | √ | √ | √ | √ | √ | Número de piezas/Importe de la prima/Importe original/Importe final |
| pagar | √ | √ | √ | monto del pago | |||
| agregar compra | √ | √ | √ | Número de piezas/cantidad | |||
| recolectar | √ | √ | √ | frecuencia | |||
| evaluar | √ | √ | √ | frecuencia | |||
| contracargo | √ | √ | √ | √ | Número de piezas/cantidad | ||
| Reembolso | √ | √ | √ | √ | Número de piezas/cantidad | ||
| colección de cupones | √ | √ | √ | frecuencia |
Hasta ahora, se ha completado el modelado dimensional del almacén de datos y la capa DWD está impulsada por procesos comerciales.
La capa DWS, la capa DWT y la capa ADS dependen de la demanda y no tienen nada que ver con el modelado dimensional.
Tanto DWS como DWT construyen tablas amplias y tablas según temas. El tema es equivalente al ángulo de observación del problema. Corresponde a la tabla de medidas.
3.3 Capa DWS y capa DWT
La capa DWS y la capa DWT se conocen colectivamente como la capa de superficie ancha.Las ideas de diseño de las dos capas son aproximadamente las mismas y se ilustran a través de los siguientes casos.
1) Se dibuja la pregunta: dos requisitos, contar la cantidad de pedidos en cada provincia y contar la cantidad total de pedidos en cada provincia
2) método de procesamiento: unir la tabla de provincias y la tabla de pedidos, agrupar por provincia y luego calcular. Los mismos datos se calculan dos veces y, de hecho, habrá más escenarios similares.
Entonces, ¿cómo puede el diseño evitar la doble contabilidad?
Para el escenario anterior, se puede diseñar una tabla para toda la región, cuya clave principal es el ID de la región, y los campos incluyen: tiempos de pedido, monto del pedido, tiempos de pago, monto del pago, etc. Todos los indicadores anteriores se calculan de manera uniforme y los resultados se guardan en la tabla ancha, lo que puede evitar efectivamente el doble cálculo de datos.
3) Resumen:
(1) Qué mesas anchas deben construirse: en función de las dimensiones.
(2) Campos en la tabla ancha: mire la tabla de hechos desde la perspectiva de diferentes dimensiones, enfocándose en los valores de medición agregados de la tabla de hechos.
(3) La diferencia entre las capas DWS y DWT: la capa DWS almacena el comportamiento resumido de todos los objetos sujetos en el día, como la cantidad de pedidos realizados en cada región en el día, el monto del pedido, etc., y el La capa DWT almacena el comportamiento acumulativo de todos los objetos sujetos, como la cantidad de pedidos realizados y la cantidad de pedidos realizados en cada región en los últimos 7 días (15 días, 30 días, 60 días).
3.4 Capa de anuncios
Analizar los principales indicadores temáticos del sistema de comercio electrónico por separado.
4 Combate del almacén de datos de Hive

1 Construcción de la capa ODS
1.1 Funciones y responsabilidades de la capa ODS
1) Mantenga la apariencia original de los datos sin ninguna modificación y desempeñe el papel de hacer una copia de seguridad de los datos.
2) LZO comprime los datos para reducir el espacio de almacenamiento en disco. Los datos de 100G se pueden comprimir hasta 10G.
3) Cree una tabla de particiones para evitar posteriores escaneos completos de la tabla y use tablas de particiones ampliamente en el desarrollo empresarial.
4) Crear una tabla externa. En el desarrollo empresarial, además de crear tablas temporales para su propio uso y crear tablas internas, la mayoría de los escenarios son para crear tablas externas.

1.2 Construcción de la capa ODS - importación de datos - cobertura total
No hay necesidad de particiones, y cada sincronización es para borrar primero y luego escribir, sobrescribiendo directamente.
Aplicable a situaciones en las que no habrá nuevas adiciones o cambios en los datos.
Por ejemplo, los datos de dimensión, como las tablas de diccionarios regionales, la hora y el género, no cambiarán o lo harán rara vez, y solo se pueden conservar los valores más recientes.
Aquí tomamos la tabla del diccionario del área t_district como un ejemplo para explicar.
DROP TABLE if exists yp_ods.t_district;
CREATE TABLE yp_ods.t_district
(
`id` string COMMENT '主键ID',
`code` string COMMENT '区域编码',
`name` string COMMENT '区域名称',
`pid` int COMMENT '父级ID',
`alias` string COMMENT '别名'
)
comment '区域字典表'
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress'='ZLIB');
sincronización de datos sqoop
Debido a que las tablas se almacenan en formato ORC, se requiere la API de HCatalog cuando se usa sqoop para importar datos.
-- Sqoop导入之前可以先原表的数据进行清空
truncate table yp_ods.t_district;
方式1-使用1个maptask进行导入
sqoop import \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select * from t_district where \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_district \
--m 1
1.3 Construcción de capas ODS – Importación de datos – Sincronización incremental
Cada día se agrega una nueva partición de fecha y los nuevos datos del día se sincronizan y almacenan.
Por ejemplo, tabla de registro de inicio de sesión, tabla de registro de acceso, tabla de registro de transacciones, tabla de evaluación de productos básicos, tabla de evaluación de pedidos, etc.
Aquí tomamos la tabla de registro de inicio de sesión t_user_login como ejemplo para explicar.
DROP TABLE if exists yp_ods.t_user_login;
CREATE TABLE if not exists yp_ods.t_user_login(
id string,
login_user string,
login_type string COMMENT '登录类型(登陆时使用)',
client_id string COMMENT '推送标示id(登录、第三方登录、注册、支付回调、给用户推送消息时使用)',
login_time string,
login_ip string,
logout_time string
)
COMMENT '用户登录记录表'
partitioned by (dt string)
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress' = 'ZLIB');
sincronización de datos sqoop
- Primera vez (importe total)
1. Independientemente del modo, la primera vez es la sincronización completa, cuando el ciclo se sincroniza de nuevo, usted mismo puede controlar el alcance de los datos de sincronización a través de la condición donde;
2. ${TD_DATE} representa la fecha de partición, que normalmente debería ser el día anterior a hoy, porque en circunstancias normales, son las 12 de la noche y el trabajo del día anterior está hecho, por lo que el campo de partición de los datos deben pertenecer al día anterior.
3. Para propósitos de demostración, ${TD_DATE} está codificado primero.
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *,'2022-11-18' as dt from t_user_login where \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_user_login \
--m 1
- Bucle (sincronización incremental)
#!/bin/bash
date -s '2022-11-20' #模拟导入增量19号的数据
#你认为现在是2022-11-20,昨天是2022-11-19
TD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`
/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *, '${TD_DATE}' as dt from t_user_login where 1=1 and (login_time between '${TD_DATE} 00:00:00' and
'${TD_DATE} 23:59:59') and \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_user_login \
-m 1
1.4 Construcción de capas ODS - importación de datos - sincronización nueva y actualizada
Cada día se agrega una nueva partición de fecha, y los datos nuevos y actualizados del día se sincronizan y almacenan.
Aplicable tanto a datos nuevos como actualizados, como tablas de usuarios, tablas de pedidos, tablas de productos, etc.
Aquí tomamos la tabla de la tienda t_store como ejemplo para explicar.
drop table if exists yp_ods.t_store;
CREATE TABLE yp_ods.t_store
(
`id` string COMMENT '主键',
`user_id` string,
`store_avatar` string COMMENT '店铺头像',
`address_info` string COMMENT '店铺详细地址',
`name` string COMMENT '店铺名称',
`store_phone` string COMMENT '联系电话',
`province_id` INT COMMENT '店铺所在省份ID',
`city_id` INT COMMENT '店铺所在城市ID',
`area_id` INT COMMENT '店铺所在县ID',
`mb_title_img` string COMMENT '手机店铺 页头背景图',
`store_description` string COMMENT '店铺描述',
`notice` string COMMENT '店铺公告',
`is_pay_bond` TINYINT COMMENT '是否有交过保证金 1:是0:否',
`trade_area_id` string COMMENT '归属商圈ID',
`delivery_method` TINYINT COMMENT '配送方式 1 :自提 ;3 :自提加配送均可; 2 : 商家配送',
`origin_price` DECIMAL,
`free_price` DECIMAL,
`store_type` INT COMMENT '店铺类型 22天街网店 23实体店 24直营店铺 33会员专区店',
`store_label` string COMMENT '店铺logo',
`search_key` string COMMENT '店铺搜索关键字',
`end_time` string COMMENT '营业结束时间',
`start_time` string COMMENT '营业开始时间',
`operating_status` TINYINT COMMENT '营业状态 0 :未营业 ;1 :正在营业',
`create_user` string,
`create_time` string,
`update_user` string,
`update_time` string,
`is_valid` TINYINT COMMENT '0关闭,1开启,3店铺申请中',
`state` string COMMENT '可使用的支付类型:MONEY金钱支付;CASHCOUPON现金券支付',
`idCard` string COMMENT '身份证',
`deposit_amount` DECIMAL(11,2) COMMENT '商圈认购费用总额',
`delivery_config_id` string COMMENT '配送配置表关联ID',
`aip_user_id` string COMMENT '通联支付标识ID',
`search_name` string COMMENT '模糊搜索名称字段:名称_+真实名称',
`automatic_order` TINYINT COMMENT '是否开启自动接单功能 1:是 0 :否',
`is_primary` TINYINT COMMENT '是否是总店 1: 是 2: 不是',
`parent_store_id` string COMMENT '父级店铺的id,只有当is_primary类型为2时有效'
)
comment '店铺表'
partitioned by (dt string)
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress'='ZLIB');
sincronización de datos sqoop
La clave para realizar una sincronización nueva y actualizada es que hay dos campos relacionados con el tiempo en la tabla:
create_time La hora de creación no se modificará una vez generada
update_time tiempo de actualización cambio de datos modificación de tiempo
Controle usted mismo el alcance de los datos sincronizados a través de la condición where.
- primero
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *,'2022-11-18' as dt from t_store where 1=1 and \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_store \
-m 1
- ciclo
#!/bin/bash
date -s '2022-11-20'
TD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`
/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *, '${TD_DATE}' as dt from t_store where 1=1 and ((create_time between '${TD_DATE} 00:00:00' and '${TD_DATE} 23:59:59') or (update_time between '${TD_DATE} 00:00:00' and '${TD_DATE} 23:59:59')) and \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_store \
-m 1
Finalmente, todas las tablas de capas ODS importadas de MySql
1.5 Resumen
Aquí hay una introducción a la construcción de la capa ODS del nuevo proyecto minorista del almacén de datos HIve, principalmente de tres maneras.
- cobertura completa
- Sincronización incremental
- Sincronización de nuevas incorporaciones y actualizaciones
2 Construcción de la capa DWD
2.1 Funciones y responsabilidades de la capa DWD
Limpie los datos en la tabla de capas de ods, consulte las reglas de limpieza de datos y limpie los datos de acuerdo con la situación real.
注意:如果清洗规则使用SQL可以实现,那么就使用SQL实现数据清洗,如果清洗的规则使用SQL实现起来非常麻烦,或者使用SQL压根无法实现,此时就可以考虑需要使用MapReduce代码或者Spark代码对数据进行清洗了。
-
La capa dwd se denomina capa de datos detallados en chino.
-
La función principal:
- Limpieza y transformación de datos, proporcionando garantía de calidad;
- Distinguir entre hechos y dimensiones.
-
Especificación de nombre de tabla
dwd.fact_xxxxxx
Tabla principal de pedidos, liquidación de pedidos, grupo de pedidos, reembolso de pedidos, instantánea de productos de pedidos, carrito de compras, colección de tiendas, etc.
dwd.dim_yyyyyy
Usuario, zona, hora, tienda, distrito comercial, información de dirección, producto, categoría de producto, marca, etc.
2.2 Construcción de la capa DWD - tabla de dimensiones regionales - importación de cobertura completa
DROP TABLE if EXISTS yp_dwd.dim_district;
CREATE TABLE yp_dwd.dim_district(
id string COMMENT '主键ID',
code string COMMENT '区域编码',
name string COMMENT '区域名称',
pid string COMMENT '父级ID',
alias string COMMENT '别名')
COMMENT '区域字典表'
row format delimited fields terminated by '\t'
stored as orc
tblproperties ('orc.compress' = 'SNAPPY');
Operación de cobertura total
INSERT overwrite TABLE yp_dwd.dim_district
select * from yp_ods.t_district
WHERE code IS NOT NULL AND name IS NOT NULL;
2.3 Construcción de capas DWD - formulario de evaluación de pedidos - importación incremental
#解释:每一次增量的数据都创建一个分区进行报错
DROP TABLE if EXISTS yp_dwd.fact_goods_evaluation;
CREATE TABLE yp_dwd.fact_goods_evaluation(
id string,
user_id string COMMENT '评论人id',
store_id string COMMENT '店铺id',
order_id string COMMENT '订单id',
geval_scores int COMMENT '综合评分',
geval_scores_speed int COMMENT '送货速度评分0-5分(配送评分)',
geval_scores_service int COMMENT '服务评分0-5分',
geval_isanony tinyint COMMENT '0-匿名评价,1-非匿名',
create_user string,
create_time string,
update_user string,
update_time string,
is_valid tinyint COMMENT '0 :失效,1 :开启')
COMMENT '订单评价表'
partitioned by (dt string)
row format delimited fields terminated by '\t'
stored as orc
tblproperties ('orc.compress' = 'SNAPPY');
- Importación por primera vez (importe total)
-- 从ods层进行加载
INSERT overwrite TABLE yp_dwd.fact_goods_evaluation PARTITION(dt)
select
id,
user_id,
store_id,
order_id,
geval_scores,
geval_scores_speed,
geval_scores_service,
geval_isanony,
create_user,
create_time,
update_user,
update_time,
is_valid,
substr(create_time, 1, 10) as dt
from yp_ods.t_goods_evaluation;
- Operaciones de importación incremental
INSERT into TABLE yp_dwd.fact_goods_evaluation PARTITION(dt)
select
id,
user_id,
store_id,
order_id,
geval_scores,
geval_scores_speed,
geval_scores_service,
geval_isanony,
create_user,
create_time,
update_user,
update_time,
is_valid,
substr(create_time, 1, 10) as dt
from yp_ods.t_goods_evaluation
where dt='2022-11-19';
2.4 Construcción de capas DWD - tabla de datos de pedidos - importación de bucles y cremalleras
La mesa cremallera es el punto clave de la entrevista, si te enfrentas a un puesto relacionado con el almacén, al entrevistador le gusta especialmente preguntar.
DROP TABLE if EXISTS yp_dwd.fact_shop_order;
CREATE TABLE if not exists yp_dwd.fact_shop_order( -- 拉链表
id string COMMENT '根据一定规则生成的订单编号',
order_num string COMMENT '订单序号',
buyer_id string COMMENT '买家的userId',
store_id string COMMENT '店铺的id',
order_from string COMMENT '此字段可以转换 1.安卓\; 2.ios\; 3.小程序H5 \; 4.PC',
order_state int COMMENT '订单状态:1.已下单\; 2.已付款, 3. 已确认 \;4.配送\; 5.已完成\; 6.退款\;7.已取消',
create_date string COMMENT '下单时间',
finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价',
is_settlement tinyint COMMENT '是否结算\;0.待结算订单\; 1.已结算订单\;',
is_delete tinyint COMMENT '订单评价的状态:0.未删除\; 1.已删除\;(默认0)',
evaluation_state tinyint COMMENT '订单评价的状态:0.未评价\; 1.已评价\;(默认0)',
way string COMMENT '取货方式:SELF自提\;SHOP店铺负责配送',
is_stock_up int COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ',
create_user string,
create_time string,
update_user string,
update_time string,
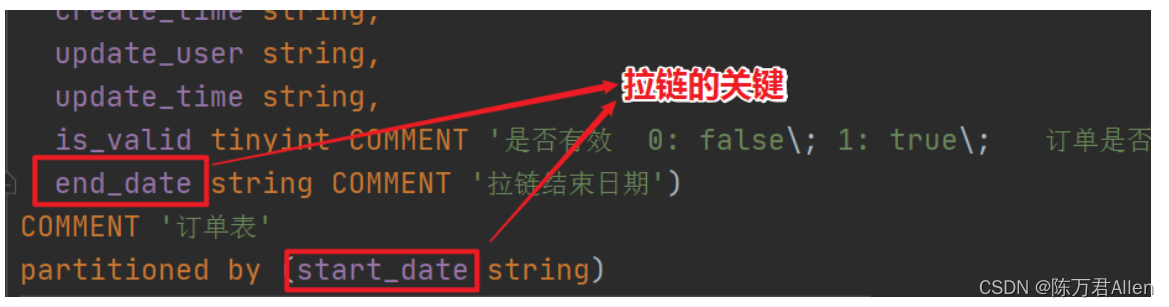
is_valid tinyint COMMENT '是否有效 0: false\; 1: true\; 订单是否有效的标志',
end_date string COMMENT '拉链结束日期'
) COMMENT '订单表'
partitioned by (start_date string)
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress' = 'SNAPPY');
- primera importación
- Si se trata de una inserción de partición dinámica, no olvide los parámetros relevantes
- Si el campo de la tabla en la capa ods tiene un tipo de enumeración, puede usar la instrucción case when para convertirlo en el proceso de ETL a dwd.
INSERT overwrite TABLE yp_dwd.fact_shop_order PARTITION (start_date)
SELECT
id,
order_num,
buyer_id,
store_id,
case order_from
when 1
then 'android'
when 2
then 'ios'
when 3
then 'miniapp'
when 4
then 'pcweb'
else 'other'
end
as order_from,
order_state,
create_date,
finnshed_time,
is_settlement,
is_delete,
evaluation_state,
way,
is_stock_up,
create_user,
create_time,
update_user,
update_time,
is_valid,
'9999-99-99' end_date,
dt as start_date
FROM yp_ods.t_shop_order;
- operación zip
insert overwrite table yp_dwd.fact_shop_order partition (start_date)
select *
from (
--1、ods表的新分区数据(有新增和更新的数据)
select id,
order_num,
buyer_id,
store_id,
case order_from
when 1
then 'android'
when 2
then 'ios'
when 3
then 'miniapp'
when 4
then 'pcweb'
else 'other'
end
as order_from,
order_state,
create_date,
finnshed_time,
is_settlement,
is_delete,
evaluation_state,
way,
is_stock_up,
create_user,
create_time,
update_user,
update_time,
is_valid,
'9999-99-99' end_date,
'2022-11-19' as start_date
from yp_ods.t_shop_order
where dt='2022-11-19'
union all
-- 2、历史拉链表数据,并根据up_id判断更新end_time有效期
select
fso.id,
fso.order_num,
fso.buyer_id,
fso.store_id,
fso.order_from,
fso.order_state,
fso.create_date,
fso.finnshed_time,
fso.is_settlement,
fso.is_delete,
fso.evaluation_state,
fso.way,
fso.is_stock_up,
fso.create_user,
fso.create_time,
fso.update_user,
fso.update_time,
fso.is_valid,
--3、更新end_time:如果没有匹配到变更数据,或者当前已经是无效的历史数据,则保留原始end_time过期时间;否则变更end_time时间为前天(昨天之前有效)
if (tso.id is not null and fso.end_date='9999-99-99',date_add(tso.dt, -1), fso.end_date) end_time,
fso.start_date
from yp_dwd.fact_shop_order fso left join (select * from yp_ods.t_shop_order where dt='2022-11-19') tso
on fso.id=tso.id
) his
order by his.id, start_date;
2.5 Resumen
Aquí hay una introducción a la construcción de la capa DWD del nuevo proyecto comercial de HIve, principalmente de tres maneras:
- importación de cobertura total
- importación incremental
- Importaciones de loops y zip
3 Construcción de la capa DWS
- El modelo de construcción (conjuntos de agrupación) de la capa DWS del almacén digital HIve New Retail Project_Chen Wanjun Allen's Blog-CSDN Blog
- El modelo de construcción (unión completa) de la capa DWS del almacén de datos de HIve New Retail Project_Chen Wanjun Allen's Blog-CSDN Blog
3.1 Funciones y responsabilidades de la capa DWS
Capa DWS: basada en el análisis estadístico de temas, esta capa se usa generalmente para las operaciones estadísticas más detalladas.
3.1.1 Combinación de dimensiones:
-
fecha
-
fecha+ciudad
-
fecha + ciudad + distrito comercial
-
fecha + ciudad + distrito comercial + tienda
-
fecha + marca
-
fecha + categoría
-
fecha+categoría principal+categoría media
-
fecha + categoría principal + columna central + categoría pequeña
3.1.2 Indicadores:
Ingresos por ventas, ingresos por plataforma, facturación por entrega, facturación por miniprograma, facturación por aplicación de Android, facturación por aplicación de Apple, facturación por centro comercial de PC, volumen de pedidos, volumen de participación, volumen de revisión negativa, volumen de entrega y volumen de reembolso, pedidos de miniprogramas, pedidos de aplicaciones de Android , Pedidos de Apple APP y Pedidos de PC Mall.
3.2 Tabla amplia de estadísticas de temas de ventas
Finalmente, se requiere usar group_type para determinar la agregación de qué dimensión proviene el indicador.
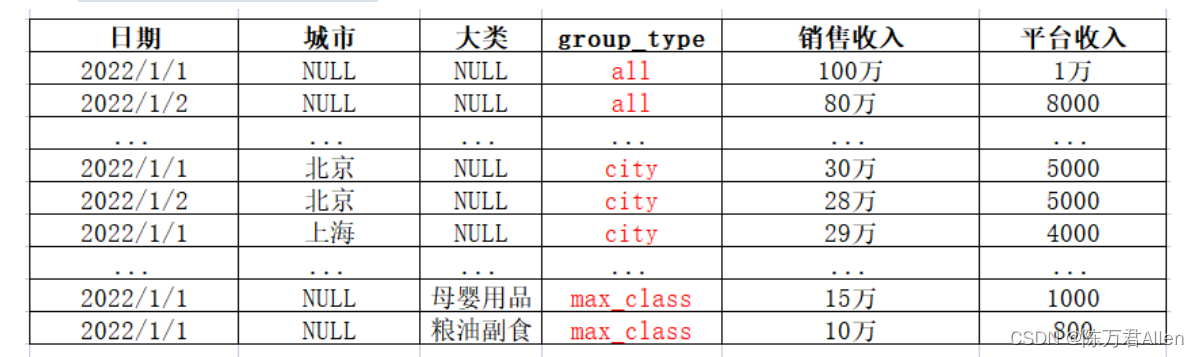
3.3 Resumen
(Conjuntos de agrupación), el modelo de Conjuntos de agrupación es adecuado para la construcción de tablas anchas dispersas multidimensionales y multiindicadoras, y se pueden colocar diferentes dimensiones en la misma tabla ancha para facilitar futuras consultas. Al mismo tiempo, al crear un campo de agregación, puede personalizar la operación de agregación según cada dimensión. Mas flexible.
(Full join), principalmente para situaciones de múltiples índices de baja dimensión. La idea principal del modelo de unión completa es
- Use la instrucción with para extraer los campos clave de la tabla dwb_order_detail
- Primero cuente los datos de 6 pequeñas tablas de resultados
- Unión completa de los datos de las 6 pequeñas tablas de resultados
- Extraer datos de la tabla de resultados de la unión completa
- Deduplicación, elimine los datos duplicados de date y goods_id