Descripción del Proyecto
Basado en datos de comercio electrónico, el proceso de procesamiento de datos se presenta en detalle, combinado con el almacén de datos de colmena y el desarrollo de chispas, para realizar análisis de big data de múltiples formas.
Las fuentes de datos se pueden obtener a través de la recopilación de registros, rastreadores y bases de datos, e importar al almacén de datos después de la limpieza y conversión de datos, y el resumen de datos se obtiene a través del análisis de datos en el almacén de datos y se utiliza para la toma de decisiones corporativas. Este proyecto se basa en la siguiente tabla de categorías para analizar el data warehouse de comercio electrónico, que se divide en pedidos (tabla de comportamiento del usuario), trenes (tabla de pedidos), productos (tabla de productos), departamentos (tabla de categorías), order_products__prior (user tabla de comportamiento histórico), para lograr un análisis multidimensional del almacén de grado.
Concepto de almacén de datos:
Data WareHouse (Data WareHouse), abreviado como DW, proporciona una colección estratégica de todo el soporte de datos del sistema para el proceso de toma de decisiones de la empresa . A través del análisis de datos en el almacén de datos, ayuda a la empresa a mejorar los procesos comerciales, controlar los costos, y mejorar la calidad del producto.
El almacén de datos no es el destino final de los datos, sino para prepararse para el destino final de los datos, estos preparativos son para los datos: limpieza, escape, clasificación, reorganización, fusión, división y estadísticas.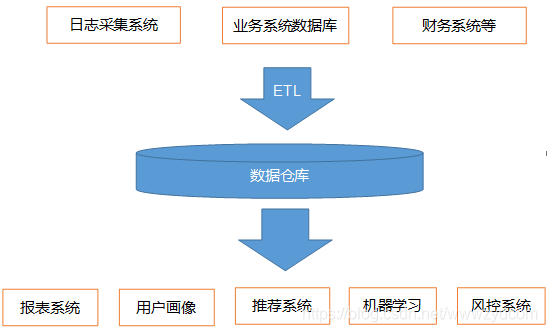
[infobox title = "一. Hoja de datos"]
1.orders.csv (posicionamiento en el almacén de datos: tabla de comportamiento del usuario)
order_id: número de pedido
user_id: ID de usuario
eval_set: el comportamiento del pedido (generado en el historial o requerido para el entrenamiento)
order_number: el orden de la orden de compra del usuario
order_dow: día de la semana del pedido, el pedido se compró el día de la semana (0-6)
order_hour_of_day: En qué período de horas se generó el pedido (0-23)
days_since_prior_order: indica el número de días entre el siguiente pedido y el anterior.
order_id, user_id, eval_set, order_number, order_dow, order_hour_of_day, days_since_prior_order
2539329,1, anterior, 1,2,08,
2398795,1, anterior, 2,3,07,15.0
473747,1, anterior, 3,3,12,21.0
2254736,1, anterior, 4,4,07,29.0
431534,1, anterior, 5,4,15,28.0
2.trains.csv
order_id: número de pedido
product_id: ID de producto
add_to_cart_order: agrega la posición del carrito de compras
reordenado: si este pedido es recomprado (1 significa sí 0 significa no)
order_id, product_id, add_to_cart_order, reordenado
1,49302,1,1
1,11109,2,1
1,10246,3,0
1,49683,4,0
3.products.csv (posicionamiento del almacén de datos: tabla de dimensiones del producto)
product_id: ID de producto
product_name: nombre del producto
aisle_id: ID del estante
Department_id: a qué categoría pertenecen los datos del producto, necesidades diarias o necesidades diarias, etc.
product_id, product_name, aisle_id, department_id
1, galletas sándwich de chocolate, 61,19
2, sal para todas las estaciones, 104,13
3, té Oolong dorado robusto sin azúcar, 94,7
4, Smart Ones Classic Favorites Mini Rigatoni con salsa de crema de vodka, 38,1
5, Salsa Green Chile Anytime, 5,13
4.departments.csv (tabla de dimensiones de categoría)
Department_id: ID de departamento, ID de categoría
departamento: nombre de categoría
departamento_id, departamento
1, congelado
2, otro
3, panadería
5.order_products__prior.csv (datos históricos de comportamiento del usuario)
order_id, product_id, add_to_cart_order, reordenado
2,33120,1,1
2,28985,2,1
2,9327,3,0
[/Caja de información]
[infobox title = "II. Análisis de datos"]
1. ¿Crear tablas para pedidos y trenes e importar datos a Hive?
Construye la tabla de pedidos
crear tablas badou.orders (
order_id cadena
, cadena de user_id
, eval_set cadena
, order_number cadena
, order_dow cadena
, order_hour_of_day string
, days_since_prior_order string)
campos delimitados por formato de fila terminados por ','
líneas terminadas por '\ n'
1. Cargue la sobrescritura de datos locales sobreescritura en adjuntar
cargar datos en la ruta de acceso local '/badou20/03hive/data/orders.csv'
sobrescribir en pedidos de mesa
seleccionar * del límite de pedidos 10;
colmena> seleccionar * del límite de pedidos 10;
Okay
order_id user_id eval_set order_number order_dow order_hour_of_day days_since_prior_order
2539329 1 anterior 1 2 08
2398795 1 anterior 2 3 07 15.0
473747 1 anterior 3 3 12 21,0
2254736 1 anterior 4 4 07 29,0
431534 1 anterior 5 4 15 28,0
2. Cargar datos de hdfs (no locales)
cargar datos en la ruta '/orders.csv'
sobrescribir en pedidos de mesa
Construye la mesa de trenes
create table badou.trains(
order_id string,
product_id string,
add_to_cart_order string,
reordered string)
row format delimited fields terminated by ','
lines terminated by '\n'
load data local inpath '/badou20/03hive/data/order_products__train.csv'
overwrite into table trains
2. ¿Cómo eliminar los datos sucios en la primera fila de la tabla? (La primera línea de los datos originales es el nombre de la columna, que debe eliminarse al importar)
Método 1: comando de shell
Idea: antes de cargar datos, trate con datos anormales sed '1d' orders.csv
head -10 orders.csv> tmp.csv
cat tmp.csv
sed '1d' tmp.csv> tmp_res.csv
cat tmp_res.csv
Comando sed de Linux | Tutorial para novatos
Método 2: HQL (hive sql)
insert overwrite table badou.orders
select * from orders where order_id !='order_id'
insert overwrite table badou.trains
select * from trains where order_id !='order_id'
3. ¿Cuántos pedidos (recuento (distinta)) tiene cada uno (Grupo B y grupo ) el usuario tiene ?
user_id order_id => user_id order_cnt
Agrupación: categorizar diferentes categorías, grupo de uso común por
Resultado: recuento de pedidos => order_cnt
seleccione user_id, ordert_cnt dos columnas
La segunda columna se puede escribir a continuación
, contar (id_orden distinto) order_cnt
-, contar (*) order_cnt
-, contar (1) order_cnt
-, count (order_id) order_cnt
Declaración completa:
select
user_id
, count(distinct order_id) order_cnt
from orders
group by user_id
order by order_cnt desc
limit 10
Resultado: dos trabajos, tiempo total de CPU MapReduce invertido: 1 minuto 4 segundos 370 mseg
133983 100
181936 100
14923 100
55827 100
4. ¿Cuál es el número medio de artículos por usuario por pedido?
Compré 2 pedidos hoy, uno es de 10 productos, el otro es de 4 productos
(10 + 4) Cuántos productos corresponden a un pedido / 2
Resultado: un usuario compró varios productos = 7
a. Primero, use la tabla de prioridades para calcular cuántos elementos hay en un pedido. Correspondiente a 10,4
Nota: cuando utilice funciones agregadas (recuento, suma, promedio, máximo, mínimo), utilice agrupar por juntos
Seleccione
order_id, count (product_id distinto) pro_cnt
de anteriores
agrupar por order_id
límite 10;
b. Asocie la tabla a priors con la tabla de pedidos a través de order_id y lleve al usuario la cantidad de productos en el paso a
Resultado: la cantidad de productos correspondiente al usuario
Seleccione
od.user_id, t.pro_cnt
de pedidos od
unir internamente (
Seleccione
order_id, cuenta (1) como pro_cnt
de anteriores
agrupar por order_id
límite 10000
) t
en od.order_id = t.order_id
límite 10;
c. Para el paso b, se suma la suma de la cantidad de bienes correspondientes al usuario
Seleccione
od.user_id, sum (t.pro_cnt) como sum_prods
de pedidos od
unir internamente (
Seleccione
order_id, cuenta (1) como pro_cnt
de anteriores
agrupar por order_id
límite 10000
) t
en od.order_id = t.order_id
agrupar por od.user_id
límite 10;
d. Calcular el promedio
Resultado: cantidad de producto del usuario / cantidad de pedido del usuario
Seleccione
od.user_id
, sum (t.pro_cnt) / count (1) como sc_prod
, avg (pro_cnt) como avg_prod
de pedidos od
unir internamente (
Seleccione
order_id, cuenta (1) como pro_cnt
de anteriores
agrupar por order_id
límite 10000
) t
en od.order_id = t.order_id
agrupar por od.user_id
límite 10;
unión interna: varias tablas para unión interna
donde: extraer los datos que nos interesan
5. ¿Cuál es la distribución de las órdenes de compra para cada usuario en una semana (de columna a fila )? dow => día de la semana 0-6 significa de lunes a domingo
order_dow
orderday, pro_cnt
2020-12-19 1000000
18/12/2020 1000010
id_usuario, dow0, dow1, dow2, dow3, dow4, dow5, dow6
1 0 3 2 2 4 0 0
2 0 5 5 2 1 1 0
Nota: En el desarrollo real, debe ser el primero en usar datos de lotes pequeños para verificar, verificar la exactitud de la lógica del código y luego ejecutar todo. !
user_id order_dow
1 0 suma = 0 + 1 = 1
1 0 suma = 1 + 1 = 2
1 1
2 1
método uno:
Seleccione
user_id
, suma (caso cuando order_dow = '0' luego 1 else 0 end) dow0
, suma (caso cuando order_dow = '1' luego 1 else 0 end) dow1
, suma (caso cuando order_dow = '2' luego 1 else 0 end) dow2
, suma (caso cuando order_dow = '3' luego 1 else 0 end) dow3
, suma (caso cuando order_dow = '4' luego 1 else 0 end) dow4
, suma (caso cuando order_dow = '5' luego 1 else 0 end) dow5
, suma (caso cuando order_dow = '6' luego 1 else 0 end) dow6
de pedidos
- donde user_id en ('1', '2', '3')
agrupar por user_id
método uno:
Seleccione
user_id
, sum (if (order_dow = '0', 1,0)) dow0
, suma (if (order_dow = '1', 1,0)) dow1
, suma (if (order_dow = '2', 1,0)) dow2
, suma (if (order_dow = '3', 1,0)) dow3
, suma (if (order_dow = '4', 1,0)) dow4
, suma (if (order_dow = '5', 1,0)) dow5
, suma (if (order_dow = '6', 1,0)) dow6
de pedidos
donde user_id en ('1', '2', '3')
agrupar por user_id
Precisión de los resultados de la verificación del muestreo:
user_id dow0 dow1 dow2 dow3 dow4 dow5 dow6
1 0 3 2 2 4 0 0
2 0 6 5 2 1 1 0
Requisitos del aula: compruebe qué productos ha comprado cada usuario en un período de tiempo determinado.
Análisis: user_id, product_id
pedidos: order_id, user_id
trenes: order_id, product_id
Seleccione
ord.user_id, tr.product_id
de pedidos ord
trenes de unión interna tr
en ord.order_id = tr.order_id
donde order_hour_of_day = '10'
límite 10
CREAR TABLA `udata` (
cadena `user_id`,
cadena `item_id`,
cadena `rating`,
cadena `timestamp`)
FORMATO DE FILA DELIMITADO
Nota: palabra clave de marca de tiempo, use ''
881250949 -> 04/12/1997 23:55:49
La tabla udata está marcada con una marca de tiempo:
Requisitos: Al recomendar, quiero saber cuándo es el momento más cercano o más lejano a partir de ahora.
Seleccione
max (`timestamp`) max_timestamp, min (` timestamp`) min_timestamp
de udata
max_timestamp min_timestamp
893286638 874724710
Requisito: Obtener los días de comentarios específicos de un determinado usuario. Como resultado, en qué días el usuario está activo, puede ser ① El usuario está realmente activo ② El usuario puede estar deslizando órdenes, revise las reseñas
user_id ['2020-12-19', '2020-12-18', ....]
24 * 60 * 60
collect_list: no elimine duplicados, recopile todos los user_ids
seleccione Collect_list ('1,2,3')
Seleccione
user_id, collect_list (emitir (días como int)) como day_list
desde
(Seleccione
user_id
, (cast (893286638 as bigint) - cast (`timestamp` as bigint)) / (24 * 60 * 60) * calificación como días
de udata
) t
agrupar por user_id
límite 10;
Requisitos: ¿Cuáles son las cantidades de bienes adquiridos por los usuarios superiores a 100?
Unir todos: los datos se fusionan, pero los datos no se eliminan de los duplicados. Tenga en cuenta que el tipo de campo y el número de campos antes y después de la unión deben ser coherentes
unión: fusión y deduplicación de datos
método uno:
Seleccione
user_id, count (product_id distinto) pro_cnt
desde
(
- Ordene la integración de la escena de datos de entrenamiento de dos datos del sistema nuevos y antiguos
Seleccione
a.user_id, b.product_id
de pedidos como
izquierda unirse a trenes b
en a.order_id = b.order_id
unión de todos
- Datos del historial de pedidos
Seleccione
a.user_id, b.product_id
de pedidos como
izquierda unirse a priors b
en a.order_id = b.order_id
) t
agrupar por user_id
teniendo pro_cnt> = 100
límite 10;
Método 2: Introducir la palabra clave with, función: la lógica involucrada es muy complicada y la relación de anidamiento se usa particularmente, lo que mejora la legibilidad del código y facilita la resolución de problemas
Modificado por con puede entenderse como una tabla temporal o un conjunto de datos temporales
con user_pro_cnt_tmp como (
Seleccionar de
(--- Solicitar datos de entrenamiento
Seleccione
a.user_id, b.product_id
de pedidos como
izquierda unirse a trenes b
en a.order_id = b.order_id
unión de todos
- Datos del historial de pedidos
Seleccione
a.user_id, b.product_id
de pedidos como
izquierda unirse a priors b
en a.order_id = b.order_id
) t
)
-, order_pro_tmp como (
-), ....
Seleccione
user_id
, cuenta (product_id distinto) pro_cnt
de user_pro_cnt_tmp
agrupar por user_id
teniendo pro_cnt> = 100
límite 10;
[/Caja de información]