2-1 Descripción del modelo
Queremos usar un conjunto de datos que contenga los precios de la vivienda en Portland, Oregon. Aquí, quiero dibujar mi conjunto de datos en función de los precios vendidos para diferentes tamaños de casas. Por ejemplo, si la casa de su amigo es de 1,250 pies cuadrados, debe decirles cuánto puede vender la casa.
Una cosa que puede hacer es construir un modelo, tal vez una línea recta. A partir de este modelo de datos, tal vez pueda decirle a su amigo que puede vender la casa por unos 220,000 (USD). Este es un ejemplo de un algoritmo de aprendizaje supervisado.

Usaré m minúscula para la cantidad de muestras de entrenamiento a lo largo del curso .
Tomando el problema de la transacción de vivienda anterior como ejemplo, si volvemos al conjunto de capacitación (Conjunto de capacitación) del problema como se muestra en la tabla a continuación

Las etiquetas que usaremos para describir este problema de regresión son las siguientes:
m representa el número de instancias en el conjunto de entrenamiento
x significa característica / variable de entrada
y representa la variable objetivo / variable de salida
(x, y) representa una instancia en el conjunto de entrenamiento
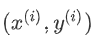 Representa la primera instancia de observación.
Representa la primera instancia de observación.
h representa la solución o función del algoritmo de aprendizaje, también se puede llamar hipótesis
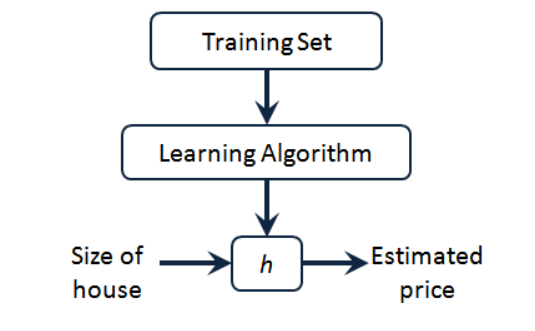
Podemos ver que existe el precio de la vivienda en nuestro conjunto de entrenamiento, se lo damos a nuestro algoritmo de aprendizaje, el trabajo del algoritmo de aprendizaje y luego emitimos una función, generalmente expresada en minúscula h.
Representa la hipótesis (hipótesis) y representa una función. La entrada es el tamaño de la casa, al igual que la casa que su amigo quiere vender, por lo que h deriva el valor de y basado en el valor de entrada x , y el valor de y corresponde al precio de la casa. Por lo tanto, h es de x a y correlación de funciones.
Entonces, ¿cómo expresamos h para nuestro problema de predicción del precio de la vivienda ?
Una posible forma de expresión es: 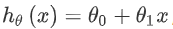 Debido a que contiene una sola característica / variable de entrada (el área de la casa), este problema se llama un problema de regresión lineal univariante.
Debido a que contiene una sola característica / variable de entrada (el área de la casa), este problema se llama un problema de regresión lineal univariante.
2-2 Función de costo
Definiremos el concepto de la función de costo, que nos ayuda a descubrir cómo ajustar la línea recta más probable a nuestros datos .

En regresión lineal tenemos un conjunto de entrenamiento como este, m representa el número de muestras de entrenamiento, por ejemplo m = 47 . Y nuestra función hipotética es la forma de la función utilizada para hacer predicciones: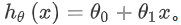
Introduciremos alguna terminología. Lo que tenemos que hacer ahora es elegir los parámetros apropiados para nuestro modelo  . En el caso del problema del precio de la vivienda, es la pendiente de la línea recta y la intersección en el eje y .
. En el caso del problema del precio de la vivienda, es la pendiente de la línea recta y la intersección en el eje y .
Error de modelado El parámetro que elegimos determina la precisión de la línea recta que obtenemos en relación con nuestro conjunto de entrenamiento, y la brecha entre el valor predicho por el modelo y el valor real en el conjunto de entrenamiento (la línea azul en la figura a continuación)

Nuestro objetivo es seleccionar los parámetros del modelo que pueden minimizar la suma de los errores de modelado al cuadrado.
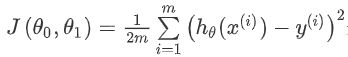
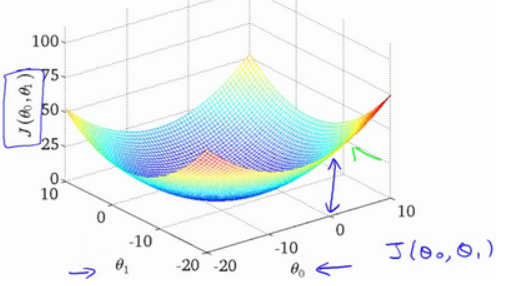
Dibujamos un mapa de contorno, las tres coordenadas son θ 0 y θ 1 y J (θ 0, θ1) :
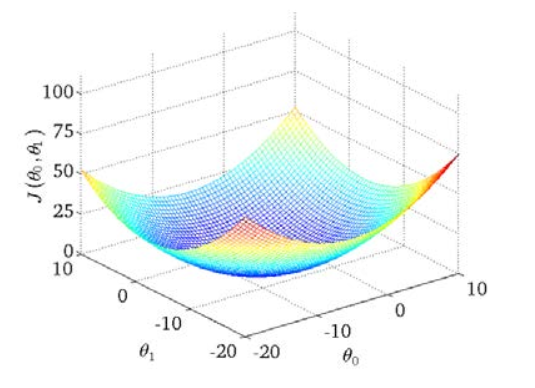
Se puede ver que hay un punto mínimo en el espacio tridimensional .
La función de costo también se conoce como la función de error al cuadrado, y a veces se conoce como la función de costo al error al cuadrado. La razón por la cual requerimos la suma de los errores al cuadrado es porque la función de costo al cuadrado del error es una opción razonable para la mayoría de los problemas, especialmente los problemas de regresión.
2-3 Comprensión de la función de costo (1)
Veamos algunos sentimientos intuitivos a través de algunos ejemplos y veamos qué está haciendo la función de costo.

A continuación, nuestro ejemplo es el análisis cuando θ 0 es 0
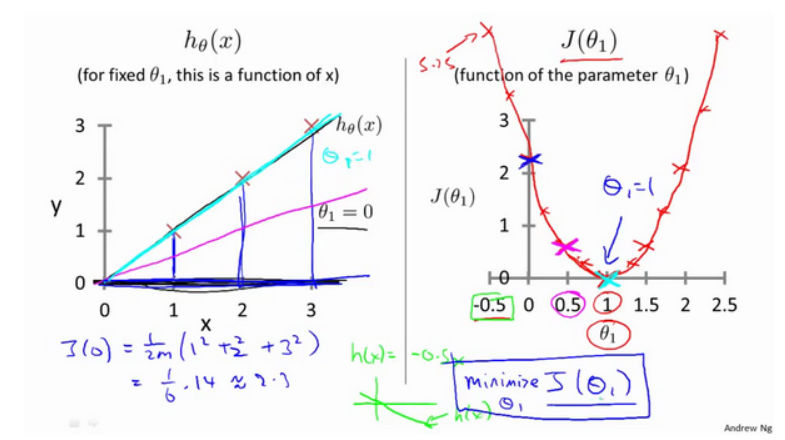
2-4 Comprensión de la función de costo (2)
La apariencia de la función de costo, el diagrama de contorno, muestra que hay un punto en el espacio tridimensional que minimiza J (θ 0, θ1) .
Suponga que la línea recta que ajustamos es como se muestra en la figura, ahora tenemos dos parámetros θ 0, θ1, y su función de costo es la siguiente
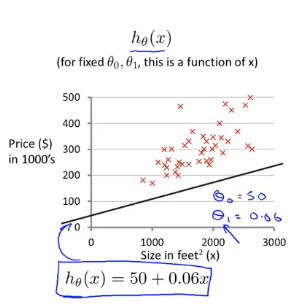
La siguiente figura muestra un mapa de contornos. Cada punto en el mapa de contornos tiene una pendiente e intersección correspondientes. Cuanto más cerca del centro, mejor se ajusta la línea recta.
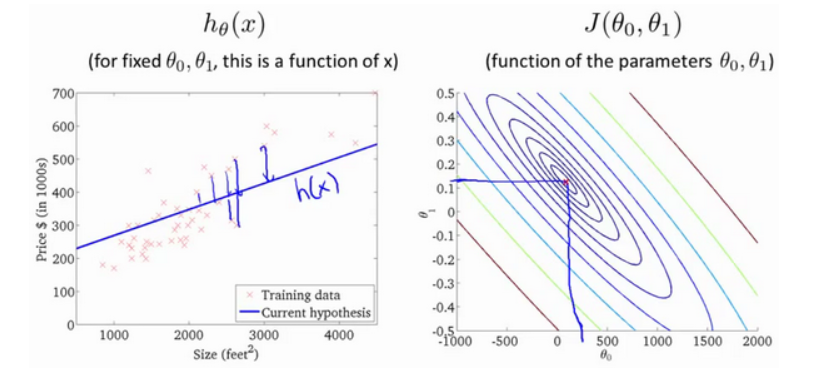
A través de estos gráficos, espero que puedan entender mejor las funciones J costo valores expresados lo que corresponden suposición es qué, y qué supuestos puntos correspondientes, más cerca de la función de coste J 's El valor mínimo.
2-5 descenso de gradiente
El descenso de gradiente es un algoritmo utilizado para encontrar el valor mínimo de la función. Usaremos el algoritmo de descenso de gradiente para encontrar el valor mínimo de la función de costo J (θ 0, θ 1 ) .
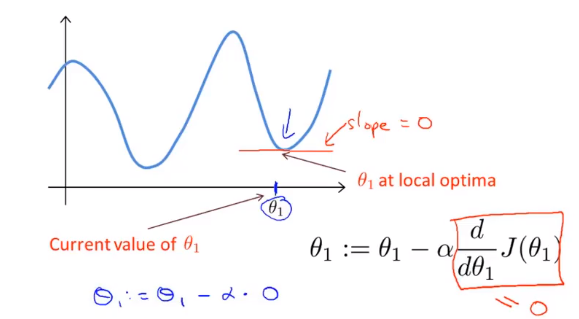
La idea detrás del descenso de gradiente es: al principio, elegimos al azar una combinación de parámetros , calculamos la función de costo y luego buscamos la siguiente combinación de parámetros que hará que el valor de la función de costo caiga más. Continuamos haciendo esto hasta que alcancemos un mínimo local, porque no hemos probado todas las combinaciones de parámetros, por lo que no estamos seguros de si el mínimo local que obtenemos es el mínimo global. Elegir diferentes combinaciones de parámetros iniciales puede encontrar diferentes Mínimo local de.
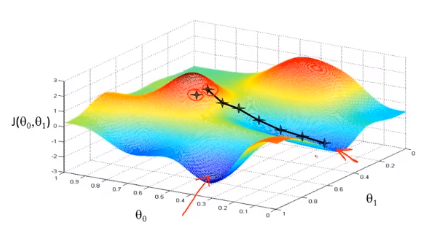
Imagina que estás parado en este punto de la montaña, parado en la montaña roja del parque que imaginas. En el algoritmo de descenso de gradiente, todo lo que tenemos que hacer es rotar 360 grados, mirar a nuestro alrededor y pedirnos que estemos en un lugar determinado. En esta dirección, baja la montaña con pequeños escalones. Piensa en cada paso que das hasta que estés cerca del punto más bajo local
La fórmula del algoritmo de descenso de gradiente por lotes es

Donde α es la tasa de aprendizaje, que determina cuántos pasos tomamos en la dirección en que la función de costo puede disminuir más. En el descenso de gradiente por lotes, cada vez que restamos todos los parámetros de aprendizaje al mismo tiempo por la tasa de aprendizaje multiplicada por la derivada de la función de costo.

En el algoritmo de descenso de gradiente, esta es la forma correcta de lograr actualizaciones simultáneas.
2-6 Resumen de puntos de conocimiento de descenso de gradiente

Asignar θ hace que J (θ) proceda en la dirección más rápida de descenso de gradiente, e itera todo el camino para finalmente obtener el mínimo local. Entre ellos se encuentra la tasa de aprendizaje α ( tasa de aprendizaje ), que determina cuántos pasos tomamos en la dirección que puede hacer que la función de costo disminuya más.
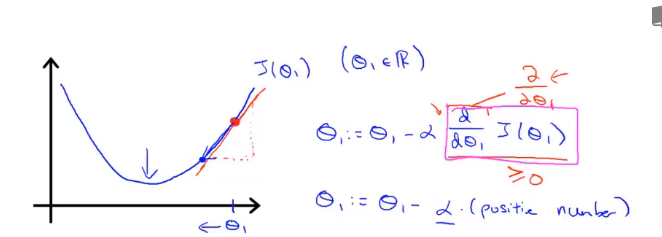
Ahora, esta línea tiene una pendiente positiva, que significa que tiene una derivada positiva, por lo que obtener la nueva [theta] 1 , después de la actualización es igual al menos un número positivo multiplicado por [theta] 1 .
Veamos qué sucede si α es demasiado pequeño o demasiado grande:
Si α es demasiado pequeño, es decir, mi tasa de aprendizaje es demasiado pequeña, el resultado es que solo puedo moverme un poco como un bebé, tratando de acercarme al punto más bajo, por lo que se necesitan muchos pasos para llegar al punto más bajo.
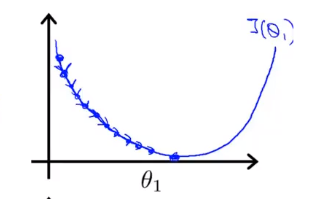
Si α es demasiado grande, entonces el método de descenso de gradiente puede cruzar el punto más bajo e incluso puede fallar en la convergencia. La siguiente iteración ha movido un gran paso, una vez, una y otra vez, sobre el punto más bajo una y otra vez, hasta que encuentre que realmente está lejos El punto se está alejando cada vez más, por lo que si es demasiado grande, guiará
Como resultado, no puede converger o incluso divergir.

Si su parámetro ya está en el punto más bajo local y la pendiente es 0, entonces la actualización del método de descenso de gradiente no hace nada, no cambiará el valor del parámetro. Esto también explica por qué el descenso del gradiente puede converger al punto más bajo local incluso cuando la tasa de aprendizaje α permanece sin cambios.
En el método de descenso de gradiente, cuando estamos cerca del mínimo local, el método de descenso de gradiente tomará automáticamente una amplitud menor, porque cuando estamos cerca del mínimo local, está claro que la derivada es igual a cero en el mínimo local, por lo tanto, cuando estamos cerca del local En el punto más bajo, el valor derivado se hará cada vez más pequeño, por lo que el descenso del gradiente tomará automáticamente una amplitud menor, este es el método de descenso del gradiente.
2-7 Descenso de gradiente de regresión lineal
La comparación entre el algoritmo de descenso de gradiente y el algoritmo de regresión lineal es la siguiente:

La clave para aplicar el método de descenso de gradiente a nuestro problema de regresión lineal anterior es encontrar la derivada de la función de costo, a saber:
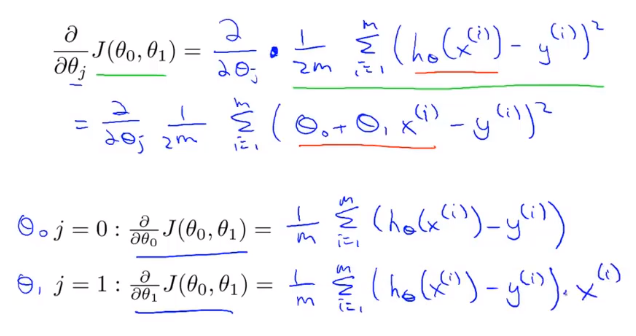
El algoritmo que acabamos de usar a veces se denomina descenso de gradiente por lotes. Significa que en cada paso del descenso del gradiente, utilizamos todas las muestras de entrenamiento m. En el descenso del gradiente, al calcular el término derivado diferencial, necesitamos realizar una operación de suma, por lo tanto, en cada descenso del gradiente individual Al final, tenemos que calcular tal cosa, este elemento necesita sumar todas las m muestras de entrenamiento.
Ahora que hemos dominado el descenso de gradiente, podemos usar el método de descenso de gradiente en diferentes entornos, y también lo usaremos ampliamente en diferentes problemas de aprendizaje automático.