Creo que para muchos profesionales del análisis de datos, estas dos herramientas se usan más. PandasNo solo SQLpueden Pandaslimpiar y analizar el conjunto de datos, sino también dibujar todo tipo de gráficos geniales, pero cuando el conjunto de datos es muy grande, Pandasobviamente no es suficiente . usarlo para procesarlo.
Hoy, presentaré otra herramienta de procesamiento y análisis de datos, llamada Polars, es más rápida en el procesamiento de datos, por supuesto, también incluye dos API, una es Eager API, la otra es Lazy API, el uso de Eager APIy Pandases similar, la sintaxis Similar no es demasiado mucho, la ejecución inmediata puede producir resultados. Si te gusta este artículo, recuerda marcar, seguir y dar me gusta.
[Nota] La versión completa del código, los datos y el intercambio técnico se puede obtener al final del artículo.
Y de manera muy similar, habrá paralelismo Lazy APIy Sparkoperaciones optimizadas para la lógica de consulta.
Instalación e importación de módulos.
Instalemos primero el módulo, usando el pipcomando
pip install polars
Después de que la instalación sea exitosa, usamos Pandasy Polarspara leer los datos respectivamente, observamos la diferencia en su rendimiento, importamos los módulos que se usarán
import pandas as pd
import polars as pl
import matplotlib.pyplot as plt
%matplotlib inline
Pandasleer archivo con
El conjunto de datos utilizado esta vez es el nombre de usuario de un usuario registrado de un sitio web, con un tamaño total de 360 MB. Primero usamos el Pandasmódulo para leer el csvarchivo.
%%time
df = pd.read_csv("users.csv")
df.head()
producción
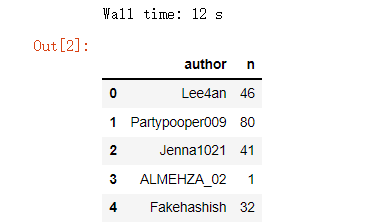
Se puede ver que tomó un total de 12 segundos para Pandasleer CSVel archivo. El conjunto de datos tiene un total de dos columnas, una columna es el nombre de usuario y la cantidad de veces que se repite el nombre de usuario "n", ordenemos el conjunto de datos y llame al sort_values()método, el código se muestra a continuación
%%time
df.sort_values("n", ascending=False).head()
producción
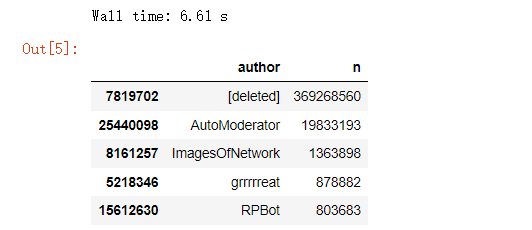
Se utiliza paraPolars leer archivos de operaciones.
A continuación, usamos el Polarsmódulo para leer y operar el archivo para ver cuánto tiempo lleva.El código es el siguiente
%%time
data = pl.read_csv("users.csv")
data.head()
producción

Se puede ver que polarssolo se necesitan 730 milisegundos para leer los datos con el módulo, lo que se puede decir que es mucho más rápido. Ordenamos el conjunto de datos de acuerdo con la columna "n". El código es el siguiente
%%time
data.sort(by="n", reverse=True).head()
producción
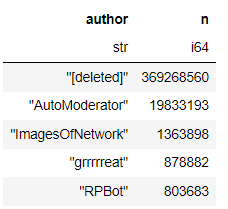
Se tarda 1,39 segundos en ordenar el conjunto de datos. A continuación, usamos el módulo polares para realizar un análisis exploratorio preliminar del conjunto de datos. ¿Cuáles son las columnas y los nombres de las columnas en el conjunto de datos? Todavía estamos familiarizados con "Titan" Nick" conjunto de datos como ejemplo
df_titanic = pd.read_csv("titanic.csv")
df_titanic.columns
producción
['PassengerId',
'Survived',
'Pclass',
'Name',
'Sex',
'Age',
......]
Se Pandasllama al mismo método para generar el nombre de la columna columns, y luego veamos cuántas filas y columnas tiene el conjunto de datos en total,
df_titanic.shape
producción
(891, 12)
Eche un vistazo al tipo de datos de cada columna en el conjunto de datos
df_titanic.dtypes
producción
[polars.datatypes.Int64,
polars.datatypes.Int64,
polars.datatypes.Int64,
polars.datatypes.Utf8,
polars.datatypes.Utf8,
polars.datatypes.Float64,
......]
Análisis estadístico de relleno de nulos y datos
Echemos un vistazo a la distribución de valores nulos en el conjunto de datos y llamemos al null_count()método
df_titanic.null_count()
producción

Podemos ver que hay valores vacíos en las columnas "Edad" y "Cabaña", podemos intentar llenarlos con el valor promedio, el código es el siguiente
df_titanic["Age"] = df_titanic["Age"].fill_nan(df_titanic["Age"].mean())
Para calcular el valor promedio de una columna, solo necesita llamar al mean()método, luego el cálculo de la mediana y el valor máximo/mínimo es el mismo, el código es el siguiente
print(f'Median Age: {
df_titanic["Age"].median()}')
print(f'Average Age: {
df_titanic["Age"].mean()}')
print(f'Maximum Age: {
df_titanic["Age"].max()}')
print(f'Minimum Age: {
df_titanic["Age"].min()}')
producción
Median Age: 29.69911764705882
Average Age: 29.699117647058817
Maximum Age: 80.0
Minimum Age: 0.42
Filtrado y visualización de datos
Filtramos a los pasajeros que tienen más de 40 años, los códigos son los siguientes
df_titanic[df_titanic["Age"] > 40]
producción
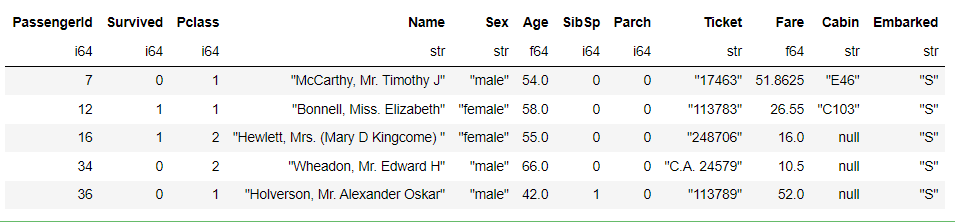
Finalmente, simplemente dibujamos un gráfico, el código es el siguiente
fig, ax = plt.subplots(figsize=(10, 5))
ax.boxplot(df_titanic["Age"])
plt.xticks(rotation=90)
plt.xlabel('Age Column')
plt.ylabel('Age')
plt.show()
producción
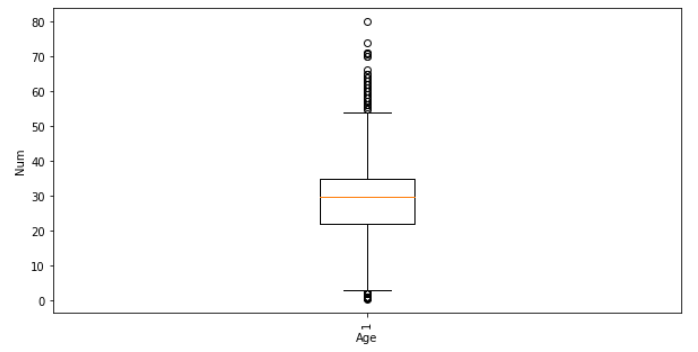
En general, hay muchas similitudes con los módulos polarsen el análisis y procesamiento de datos, y Pandasalgunas API son diferentes. Los zapatos para niños interesados pueden consultar su sitio web oficial: https://www.pola.rs/
artículo recomendado
-
El curso de mandarín "Aprendizaje automático" de Li Hongyi (2022) ya está aquí
-
Alguien hizo una versión china del aprendizaje automático y el aprendizaje profundo del Sr. Wu Enda
-
Soy adicto, y recientemente le di a la compañía una gran pantalla visual (con código fuente)
-
Tan elegantes, los artefactos de análisis de datos automáticos de 4 Python son realmente fragantes
Intercambio de Tecnología
¡Bienvenido a reimprimir, coleccionar, dar me gusta y apoyar!

En la actualidad, se ha abierto un grupo de intercambio técnico, con más de 2000 miembros . La mejor manera de comentar al agregar es: fuente + dirección de interés, que es conveniente para encontrar amigos de ideas afines.
- Método 1. Envíe la siguiente imagen a WeChat, mantenga presionada para identificarla y responda en segundo plano: agregar grupo;
- Método ②, agregar microseñal: dkl88191 , nota: de CSDN
- Método ③, cuenta pública de búsqueda de WeChat: aprendizaje de Python y extracción de datos , respuesta en segundo plano: agregar grupo
