1. Introducción a XPath
XPath es un lenguaje para encontrar información en documentos XML. Diseñado originalmente para buscar documentos XML, pero también se puede utilizar para buscar documentos HTML.
2. Instalar lxml
lxml es una biblioteca de análisis de terceros para Python, admite el análisis de HTML y XML, y es extremadamente eficiente, lo que compensa las deficiencias de la propia biblioteca estándar xml de Python en el análisis de XML.
Cómo instalar bibliotecas de terceros:
pip install lxml
3. Principio de análisis XPath
- Cree una instancia de un objeto etree y los datos del código fuente de la página analizada deben cargarse en el objeto.
- Llame al método xpath en el objeto etree combinado con expresiones xpath para realizar el posicionamiento de la etiqueta y la captura de contenido.
4. Crea una instancia del objeto etree
- Cargue los datos del código fuente en el documento html local en el objeto etree:
etree.parse(filePath) - Cargue los datos del código fuente obtenidos de Internet en el objeto:
etree.HTML(response.text) - xpath('expresión xpath')
5. Expresión de ruta XPath
| expresión | ilustrar |
|---|---|
| / | Seleccionar desde el nodo raíz |
| // | Representa múltiples niveles, comenzando desde cualquier posición |
| . | Seleccione el nodo actual |
| … | Seleccione el nodo principal del nodo actual |
| @ | seleccionar atributo |
| //div[@class='title'] etiqueta[@attrName=“attrValue”] | posicionamiento de atributos |
| //div[@clase=“zhang”]/p[3] | Posicionamiento del índice, el índice comienza desde 1 |
| /texto() | Lo que se obtiene es el contenido de texto directo en la etiqueta |
| //texto() | Contenido de texto no inmediato en etiquetas (todo el contenido de texto) |
| /@attrName ==>img/src | Tomar atributos |
6. Combinado con explicación de combate real
Tome el sitio web de CSDN como ejemplo para explicar
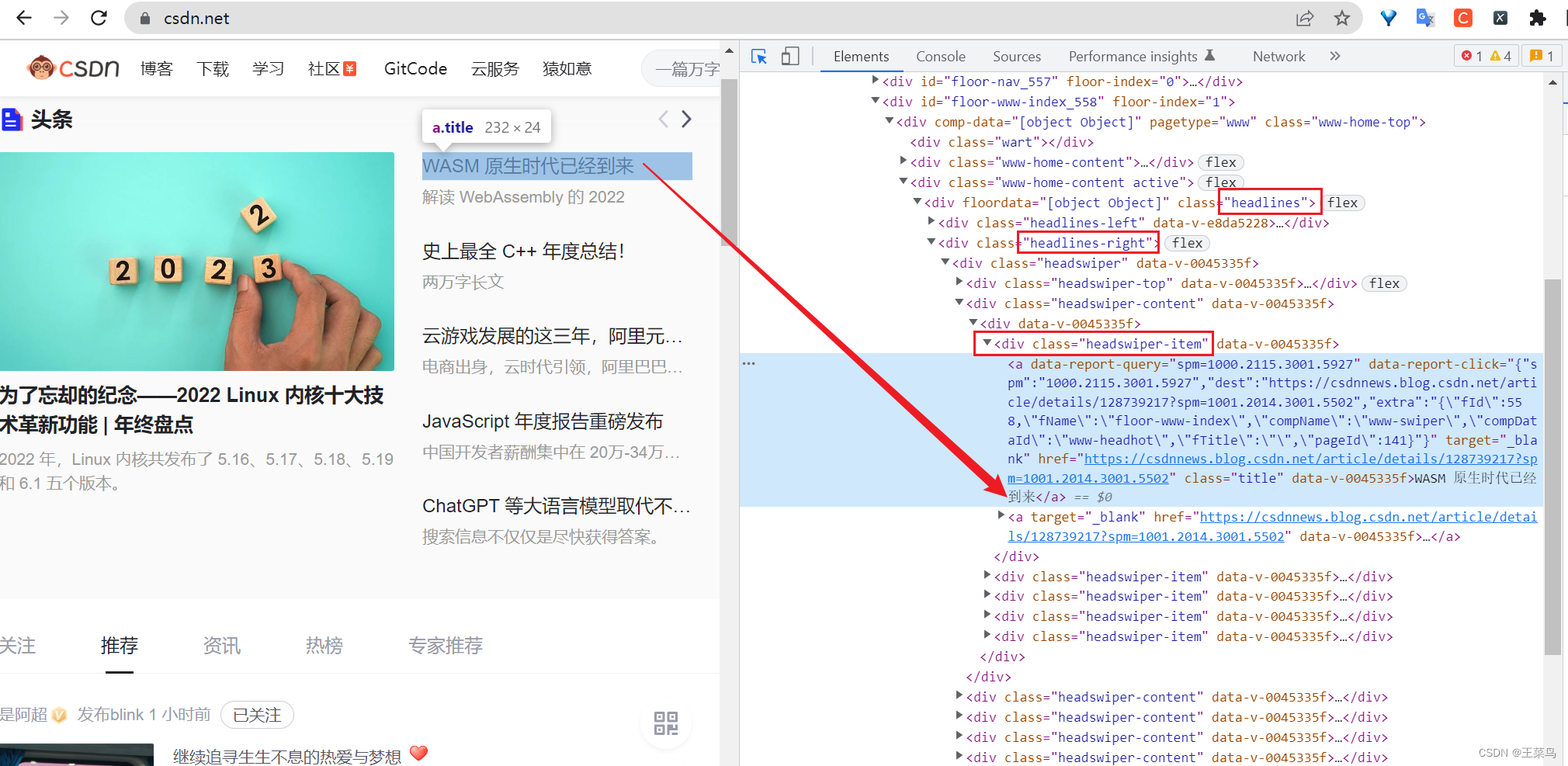
ejemplo: Aquí quiero obtener el título del titular del blog en la página de inicio del sitio web oficial, abrir la consola (haga clic en la flecha pequeña en la consola o presione Ctrl+Shift+C al mismo tiempo), señale el título y ubíquelo de acuerdo con el valor de clase de la etiqueta div (esto es Usualmente usamos más sintaxis xpath.
from lxml import etree
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
url = "https://www.csdn.net/"
response = requests.get(url=url, headers=headers)
# 使用etree解析
data = etree.HTML(response.text)
# //div表示任意路径下的div标签
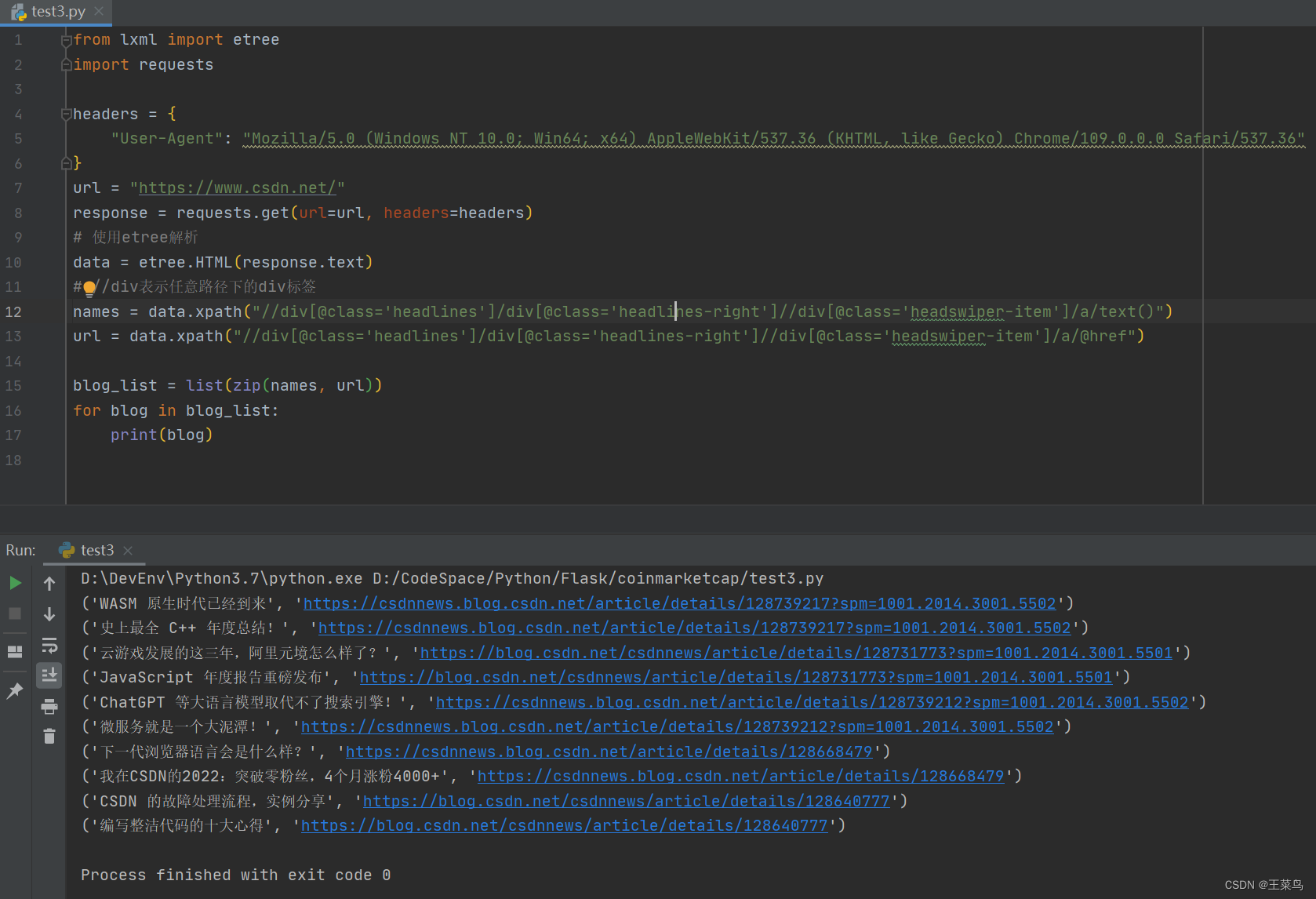
names = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/text()")
url = data.xpath("//div[@class='headlines']/div[@class='headlines-right']//div[@class='headswiper-item']/a/@href")
blog_list = list(zip(names, url))
for blog in blog_list:
print(blog)
Darse cuenta del efecto: