
Equipo fuente | Plataforma de operación en vivo BytedanceEn la construcción continua de servicios de agregación de datos entre dominios basados en ES, descubrimos que muchas características de ES son bastante diferentes de las bases de datos de uso común como MySQL. Este artículo compartirá los principios de implementación de ES y sugerencias de selección de negocios en plataformas de transmisión en vivo. y problemas encontrados en la práctica y el pensamiento.
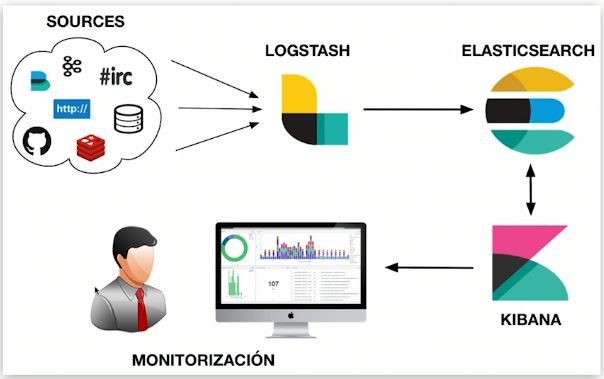
Introducción a ES y escenarios de aplicación
Elasticsearch es un motor de análisis, recuperación y almacenamiento masivo de datos distribuido y casi en tiempo real. Lo que a menudo llamamos "ELK" se refiere a un sistema de datos compuesto por Elasticsearch, Logstash/Beats y Kibana que es capaz de recopilar, almacenar, recuperar y visualizar. ES desempeña un papel en el almacenamiento e indexación de datos, la recuperación de datos y el análisis de datos en sistemas de datos similares.
Características ES
Cada selección de tecnología tiene sus propias características y las características generales de ES también se ven afectadas por la implementación subyacente. La segunda parte de este artículo detallará las causas fundamentales de las siguientes características.
Ventajas:
-
Distribuido: a través de la fragmentación, puede admitir datos de hasta nivel PB y proteger los detalles de la fragmentación desde el exterior. Los usuarios no necesitan estar al tanto del enrutamiento de lectura y escritura;
-
Escalable: fácil de expandir horizontalmente, no es necesario dividir manualmente bases de datos y tablas como MySQL ni utilizar componentes de terceros;
-
Velocidad rápida: cálculo paralelo de cada fragmento, velocidad de recuperación rápida;
-
Recuperación de texto completo: múltiples optimizaciones específicas, como admitir la recuperación de texto completo en varios idiomas a través de varios complementos de segmentación de palabras y mejorar la precisión mediante el procesamiento semántico;
-
Funciones ricas de análisis de datos.
Contras:
-
No se admiten transacciones: el proceso de cálculo de cada fragmento es paralelo e independiente;
-
Casi en tiempo real: hay un retraso de varios segundos desde que se escriben los datos hasta que se pueden consultar;
-
El idioma nativo DSL es relativamente complejo y tiene un cierto coste de aprendizaje.
Usos comunes
Las características afectarán los escenarios de aplicación de los componentes en la parte de análisis y recuperación de documentos, la plataforma de operación de transmisión en vivo usa ES para agregar información diversa de cientos de millones de anclajes y la usa para mostrar varias listas en la parte de recuperación de registros; se utiliza para detectar errores de búsqueda de registros.
Implementación y arquitectura de ES
A continuación, comprenda cómo se logran las ventajas de ES mencionadas anteriormente y cómo se originan las deficiencias. Cuando hablamos de ES, debemos hablar de Lucene, que es una biblioteca Java de búsqueda de texto completo que utiliza Lucene como componente subyacente para implementar todo. Funciones A continuación se presentan principalmente las características de Lucene. ¿Qué funciones y qué nuevas capacidades tiene ES en comparación con Lucene?
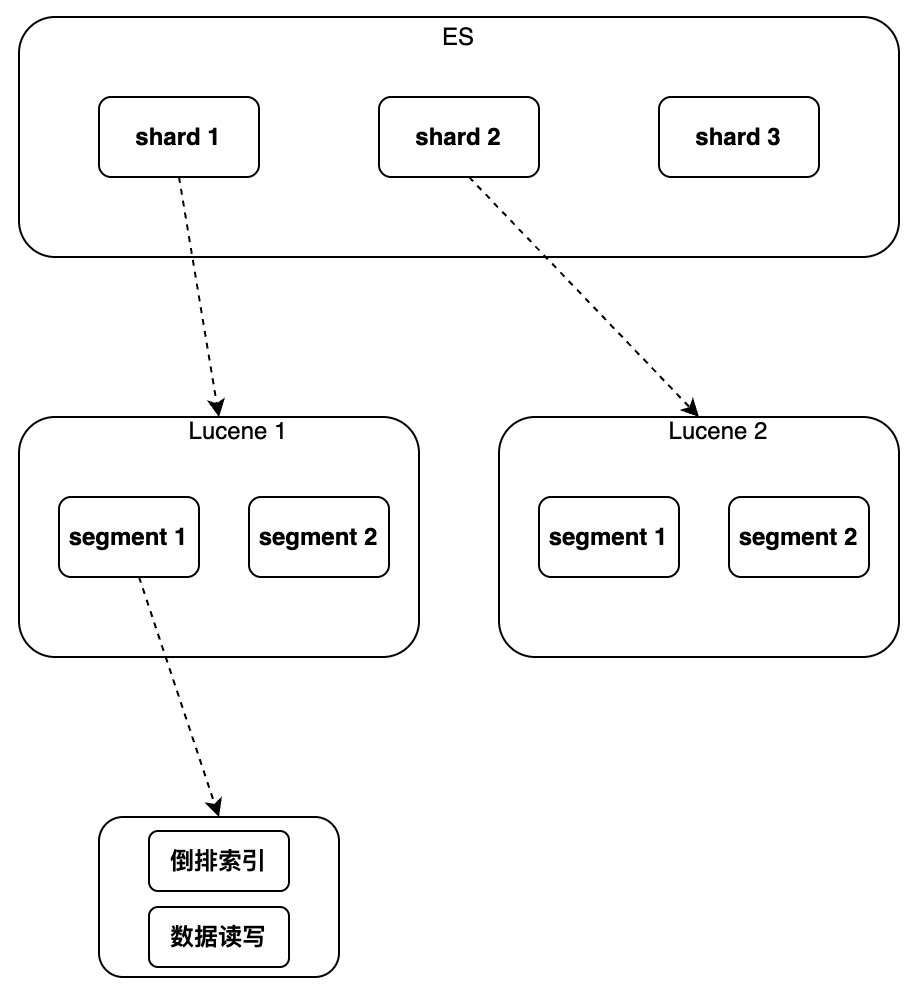
Lucene implementa la indexación y recuperación de datos en una sola instancia. Puede admitir el índice invertido y la escritura secuencial de datos, pero no admite la modificación y eliminación. No existe el concepto de clave primaria global. No puede utilizar una forma unificada para identificar documentos y. no puede soportar la distribución.
Por lo tanto, ES ha agregado algunas características nuevas en comparación con Lucene
,
principalmente incluido el nuevo campo de clave primaria global "_id", que hace posible la modificación/eliminación de datos y el enrutamiento de fragmentos y el uso de un archivo separado para marcar el documento eliminado para "escribir nuevo; La operación de actualización se implementa mediante "Documento, marcando el Documento antiguo como eliminado" agregando un nuevo número de versión al Documento, la concurrencia se admite en forma de bloqueo optimista, el proceso de realización de la distribución se realiza mediante la ejecución de múltiples instancias de Lucene para enrutar la lectura y También se ha agregado análisis de agregación de solicitudes de escritura y fusión de acuerdo con el ID de clave principal, que puede implementar análisis de clasificación, estadísticas, etc. de los resultados de la consulta. Los detalles de implementación específicos se presentarán a continuación en el orden desde la instancia única hasta el clúster.
única instancia
índice
El propósito de la indexación es acelerar el proceso de recuperación. La selección del índice es un problema inevitable para todas las bases de datos. El escenario objetivo inicial del diseño de ES es la recuperación de texto completo, por lo que admite el "índice invertido" y se han realizado muchas optimizaciones para ello. Además, también admite otros índices, como Block Kd Tree. ES coincidirá automáticamente con el tipo de índice correspondiente según el tipo de campo y creará índices para los campos que deben indexarse.
El índice invertido y el árbol Block Kd también son tipos de índices comúnmente utilizados para el análisis. Para las cadenas, hay dos situaciones comunes: el texto usa segmentación de palabras + índice invertido, mientras que la palabra clave usa segmentación sin palabras + índice invertido. Para tipos numéricos, como Long/Float, se suele utilizar Block Kd Tree.
índice invertido
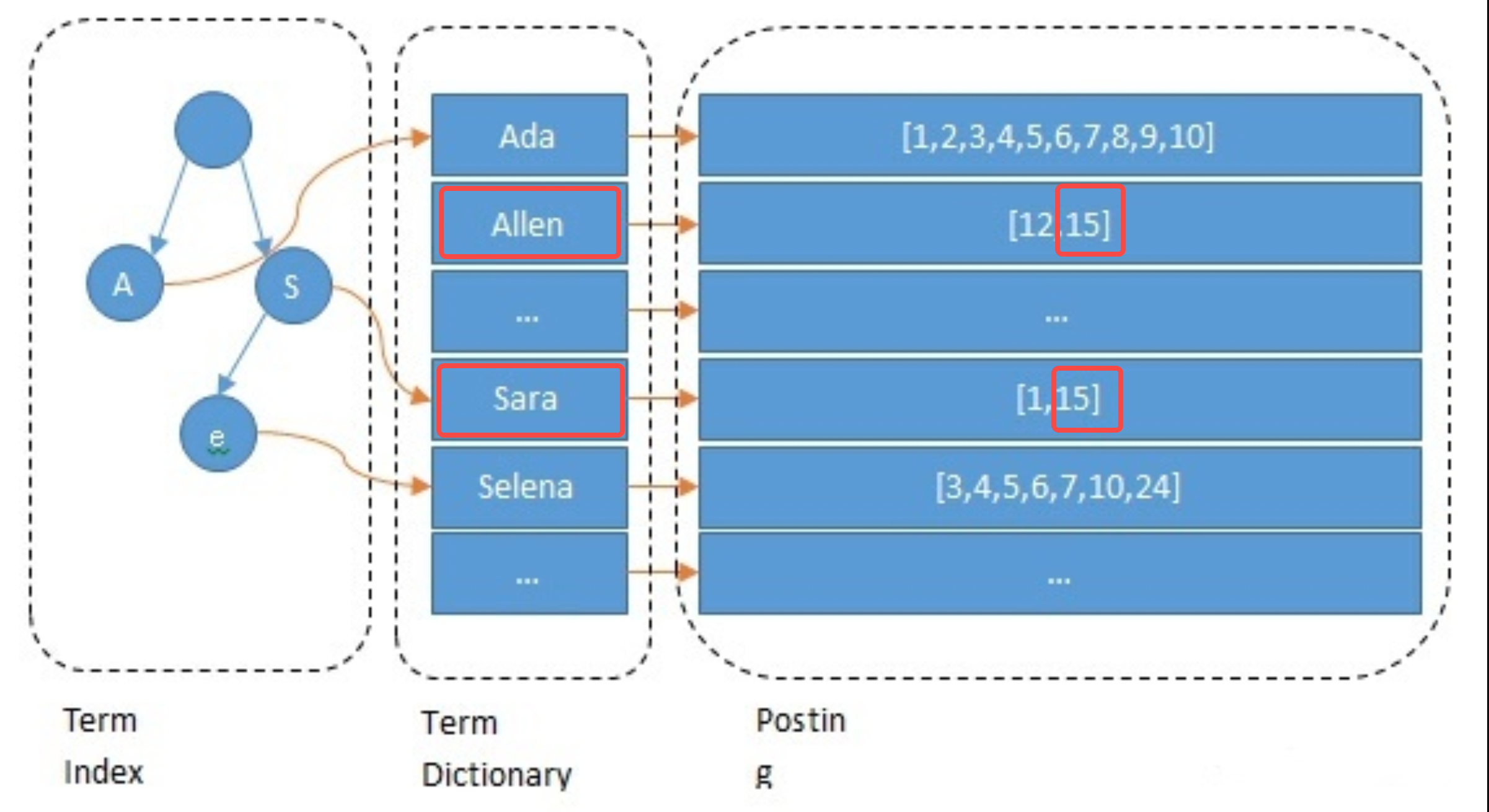
Al crear el índice, ES indexará cada campo de forma predeterminada. Este proceso incluye segmentación de palabras, procesamiento semántico y construcción de tablas de mapeo. Primero, el texto se segmentará en palabras. El método de segmentación de palabras está relacionado con el idioma, como cortar por espacios en inglés. Luego, se eliminan las palabras sin significado y se realiza la normalización semántica. Finalmente construya la tabla de mapeo. El siguiente ejemplo muestra brevemente el proceso de procesamiento del campo Nombre del ancla 15: se segmenta en allen y sara; se convierte a minúsculas y otras operaciones y se construyen las asignaciones de allen->15 y sara->15.
// 主播1 { "id": 1 "name":"ada sara" ... // 其他字段 } // 主播15 { "id": 15 "name":"allen sara" }
Proceso de consulta
Tome la consulta del ancla llamada "allen sara" como ejemplo. Según los resultados de la segmentación de palabras, se encuentran dos listas [12, 15] y [1, 15] respectivamente (en aplicaciones reales, la consulta también se basará en sinónimos); para fusionar las listas y puntuaciones, presione La prioridad es obtener los resultados [15, 12, 1] (este es el paso de recuperación en la búsqueda y también se refinará según el algoritmo).
Elementos de optimización
Para acelerar la recuperación y reducir la presión de la memoria/del disco duro, ES realiza las siguientes optimizaciones en el índice invertido, que también es la ventaja de ES sobre otros componentes. Lo que hay que tener en cuenta aquí es que la utilización final del espacio de almacenamiento puede ser una característica común de todas las bases de datos. Redis también ahorra espacio en la memoria de la misma manera: los datos se almacenan en la menor cantidad de bits posible, y se almacenan tanto conjuntos pequeños como grandes. almacenados de diferentes maneras.
-
Índice de términos: utilice árboles de prefijos para acelerar el posicionamiento de las palabras de "Término" y resolver el problema de la velocidad de recuperación lenta causada por demasiadas palabras;
-
Diccionario de términos: coloque palabras con el mismo prefijo en un bloque de datos y conserve solo el sufijo, como [hola, cabeza] -> [lo, anuncio];
-
Publicación: ordenado + codificación incremental + almacenamiento en bloque, como [9, 10, 15, 32, 37] -> [9, 1, 5, 17, 5], cada elemento puede usar almacenamiento de 5 bits;
-
Optimización de la combinación de publicaciones: utilice Roaring Bitmap para ahorrar espacio. Cuando utilice consultas de múltiples condiciones, debe fusionar varias publicaciones;
-
Procesamiento semántico: se pueden consultar contenidos con semántica similar.
Características del índice invertido:
-
Admite búsqueda de texto completo: admite múltiples idiomas con diferentes complementos de segmentación de palabras, como el complemento de segmentación de palabras IK para implementar la búsqueda de texto completo en chino;
-
Tamaño de índice pequeño: el árbol de prefijos comprime en gran medida el espacio y el índice se puede colocar en la memoria para acelerar la recuperación;
-
Soporte deficiente para la búsqueda de rango: limitado por la selección del árbol de prefijos;
-
Escenarios aplicables: búsqueda por palabra, búsqueda sin rango. Los campos no numéricos de ES utilizan este tipo de índice.
Bloqueo
K
d Índice de árbol
El índice Block Kd Tree es muy amigable para las búsquedas de rango. Los tipos de campos como valores ES, geo y rango utilizan este tipo de índice. En la selección de negocios, los campos numéricos que requieren búsqueda de rango deben usar tipos numéricos como Largo. Para índices invertidos, los campos que no requieren búsqueda de texto completo deben usar el tipo Palabra clave.
Debido al espacio limitado, este artículo no presentará demasiado aquí. Los amigos que estén interesados en BKd Tree pueden consultar el siguiente contenido:
-
https://www.shenyanchao.cn/blog/2018/12/04/lucene-bkd/
-
https://www.elastic.co/cn/blog/lucene-points-6-0
almacenamiento de datos
Esta parte explica principalmente cómo se almacenan los datos en una sola instancia en la memoria y el disco duro.
Segmento de almacenamiento segmentado
Los datos de una sola instancia ocupan hasta cientos de GB y almacenarlos en un archivo es obviamente inapropiado. Al igual que Kafka, Pulsar y otros componentes que necesitan almacenar datos Append Only, ES elige dividir los datos en segmentos para su almacenamiento.
-
Segmento: cada segmento tiene su propio archivo de índice y los resultados se combinan después de consultas paralelas;
-
Tiempo de generación de segmentos: generación programada o según el tamaño del archivo, la duración es configurable, generalmente unos segundos;
-
Fusión de segmentos: debido a que los segmentos se generan con regularidad y generalmente son relativamente pequeños, es necesario fusionarlos en segmentos grandes.
Riesgo de latencia y pérdida de datos
-
Retraso de recuperación: la recuperación condicional depende del índice, y el índice solo está disponible cuando se genera el segmento, por lo que generalmente hay un retraso de varios segundos desde la escritura hasta la recuperación;
-
Riesgo de pérdida de datos: los segmentos recién generados tardarán decenas de minutos en eliminarse de forma predeterminada y existe el riesgo de pérdida de datos;
-
Reduzca el riesgo de pérdida de datos: Translog se utiliza adicionalmente para registrar eventos de escritura. De forma predeterminada, el disco se vacía cada 5 segundos, pero aún existe el riesgo de perder varios segundos de datos.
Cómo implementar Eliminar/Actualizar
-
Eliminar: cada segmento corresponde a un archivo del, que registra la ID eliminada y los resultados de la búsqueda deben filtrarse;
-
Actualización: escriba nuevos documentos y elimine documentos antiguos.
grupo
Las bases de datos de una sola máquina tienen problemas como capacidad y rendimiento limitados y capacidades débiles de recuperación ante desastres. Estos problemas generalmente se resuelven mediante fragmentación y redundancia de datos. Sin embargo, estas dos operaciones generalmente presentan los siguientes problemas. Primero veamos cómo ES fragmenta y realiza copias de seguridad de los datos, y luego cómo resolver las siguientes tres preguntas: ¿Cómo se enrutan las solicitudes de lectura y escritura a cada fragmento? ¿Cómo fusionar los resultados de búsqueda de cada fragmento? ¿Cómo elegir el maestro entre instancias activas y en espera?
Fragmento distribuido
El número de fragmentos para cada índice se puede configurar de forma independiente. La siguiente figura toma como ejemplo un índice con tres fragmentos. La capacidad de almacenamiento general aumenta mediante la expansión horizontal y la velocidad de recuperación se mejora mediante el cálculo paralelo de cada fragmento.
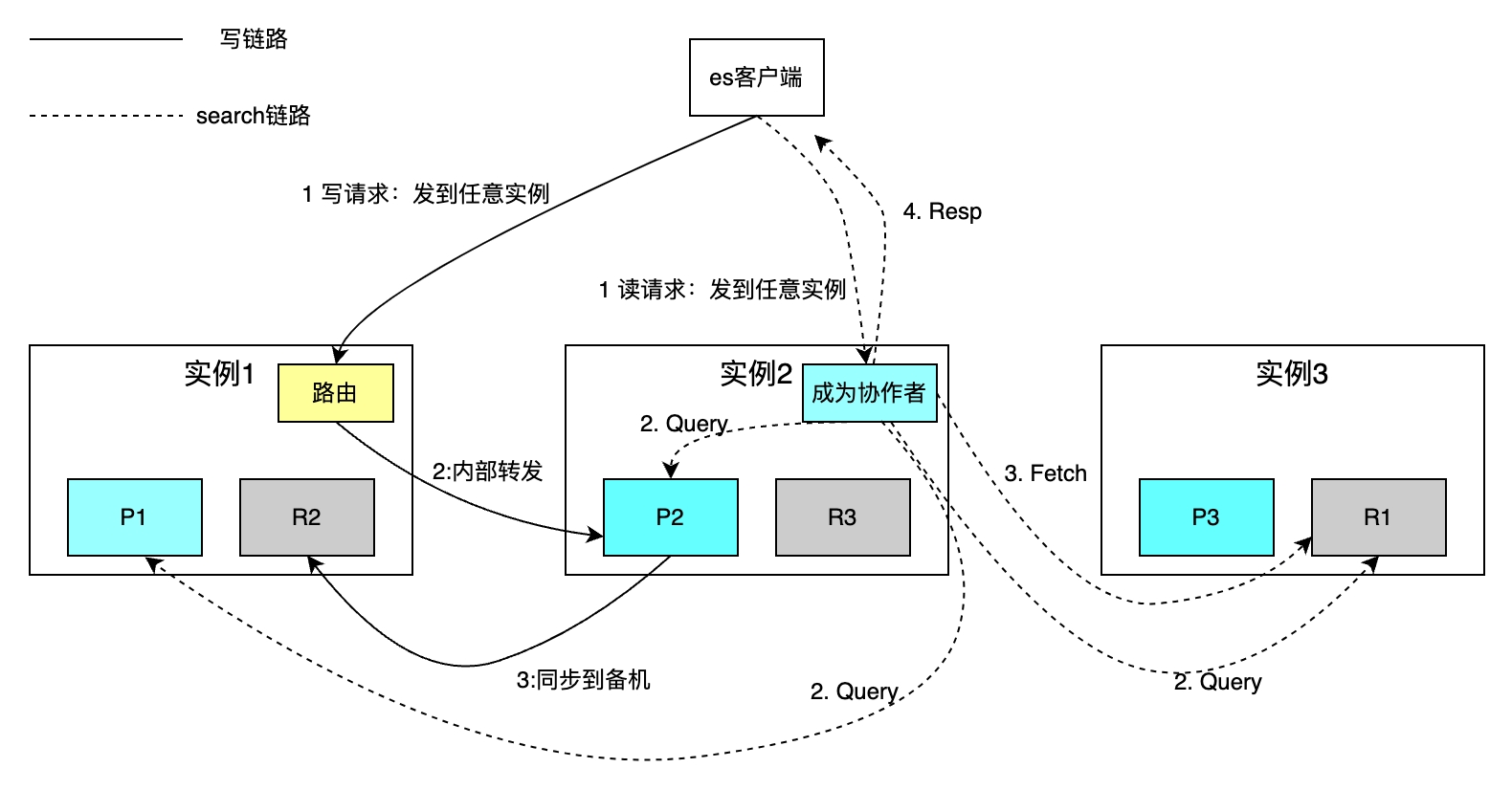
La política de enrutamiento lee y escribe un único documento basado en la clave principal. El enrutamiento hash utiliza la ID como clave principal de forma predeterminada para las operaciones de escritura, si la parte comercial no especifica la ID de la clave principal, ES usa el algoritmo Guid para generarla automáticamente. Debido a las restricciones de la política de enrutamiento, el aumento o disminución en la cantidad de fragmentos requiere la migración de todos los datos. Las solicitudes de búsqueda basadas en la recuperación condicional se implementan a través de dos pasos: las fases de consulta de la fase de coordinación y consulta del colaborador, y la fase de adquisición de la fase de recuperación. El colaborador envía una solicitud de lectura a cualquier instancia, y la instancia envía la solicitud a cada fragmento en paralelo. Cada fragmento ejecuta SQL local y devuelve 2000+100 datos al colaborador, cada dato incluye id y uid. El colaborador clasifica todos los datos fragmentados, obtiene las identificaciones de 100 documentos y luego obtiene los datos por identificación y los devuelve al cliente.
La desventaja es que el método de recuperación anterior protege el concepto de fragmentación del cliente, lo que facilita enormemente las operaciones de lectura y escritura. Sin embargo, cada instancia también necesita abrirse. un espacio de tamaño límite desde + Cuando se produce un cambio de página profundo, se requiere una gran cantidad de espacio para ordenar documentos fragmentados * (desde + límite).
En respuesta a los problemas anteriores, en la práctica, agregamos parámetros como uid>2200 que cambian con cada solicitud a los elementos condicionales de Buscar después, lo que puede reducir el número de clasificaciones de desde+límite a Límite para otra forma de desplazamiento; Buscar después, mantener los elementos de condición de cada solicitud internamente en ES y admitir la concurrencia.
Ingresos por sincronización maestro-esclavo
Los beneficios incluyen principalmente una alta disponibilidad a través de la redundancia de datos y un mayor rendimiento del sistema. El método de sincronización de datos incluye la sincronización maestro-esclavo dentro del clúster, que generalmente se implementa en diferentes salas de computadoras en la misma región para acelerar las operaciones de escritura. Se puede seleccionar la coherencia entre uno, todo o quórum. Además, existe la sincronización entre clústeres (CCR), que se utiliza para la recuperación ante desastres de múltiples clústeres y el acceso cercano en diferentes regiones. Adopta un método asincrónico y el nivel de índice puede ser una replicación de datos unidireccional o bidireccional. .
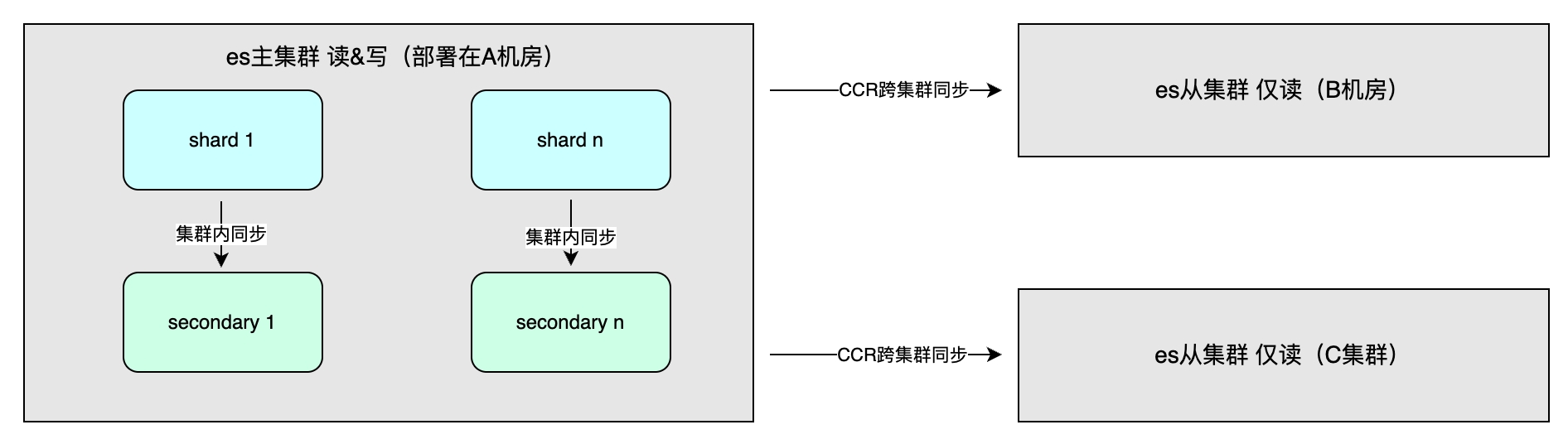
Escena aplicable
Los detalles de implementación de ES determinan sus características generales, lo que a su vez afecta los escenarios aplicables. Los escenarios aplicables incluyen: gran volumen de datos, por debajo del nivel PB; recuperación de texto completo, se requiere indexación y clasificación flexible de múltiples campos (Kibana); Sin embargo, no se recomienda utilizar ES como único almacenamiento para datos importantes, porque existe un retraso de varios segundos y el riesgo de pérdida de datos y, a diferencia de MySQL, la alta disponibilidad se optimiza cuidadosamente en cada detalle.
Práctica del sistema de agregación de datos entre dominios para la plataforma de operación de transmisión en vivo
Escenarios de aplicación
En la plataforma de operación de gremios y presentadores de transmisión en vivo, existen muchos escenarios para la visualización y análisis de datos, como listas de presentadores, presentadores y tareas de gremio, etc. Este tipo de datos generalmente tiene las siguientes características: gran volumen de datos, muchos campos y de muchas fuentes, por ejemplo, el número de campos de índice para anclajes es cercano a 200, las fuentes de datos son hasta más de 10 (como plataformas de datos, plataformas de seguridad, billeteras, etc.) y operaciones como recuperación y clasificación. por múltiples campos son compatibles.
Cuando los usuarios ven los datos, se necesita mucho tiempo para obtener datos de cada parte comercial en tiempo real y es difícil realizar consultas condicionales y ordenar en función de múltiples campos, por lo que los datos deben agregarse en una sola base de datos con anticipación. . Es difícil para bases de datos como MySQL y Redis cumplir con las características anteriores, y ES puede admitirlas mejor. Por lo tanto, creamos un sistema de servicio de agregación de datos entre dominios basado en ES: consume cambios en las fuentes de datos ascendentes y los escribe en el. ES índice grande para satisfacer las necesidades de consulta. Tome el "Índice de anclaje" como ejemplo para ilustrar el modo de agregación de datos:
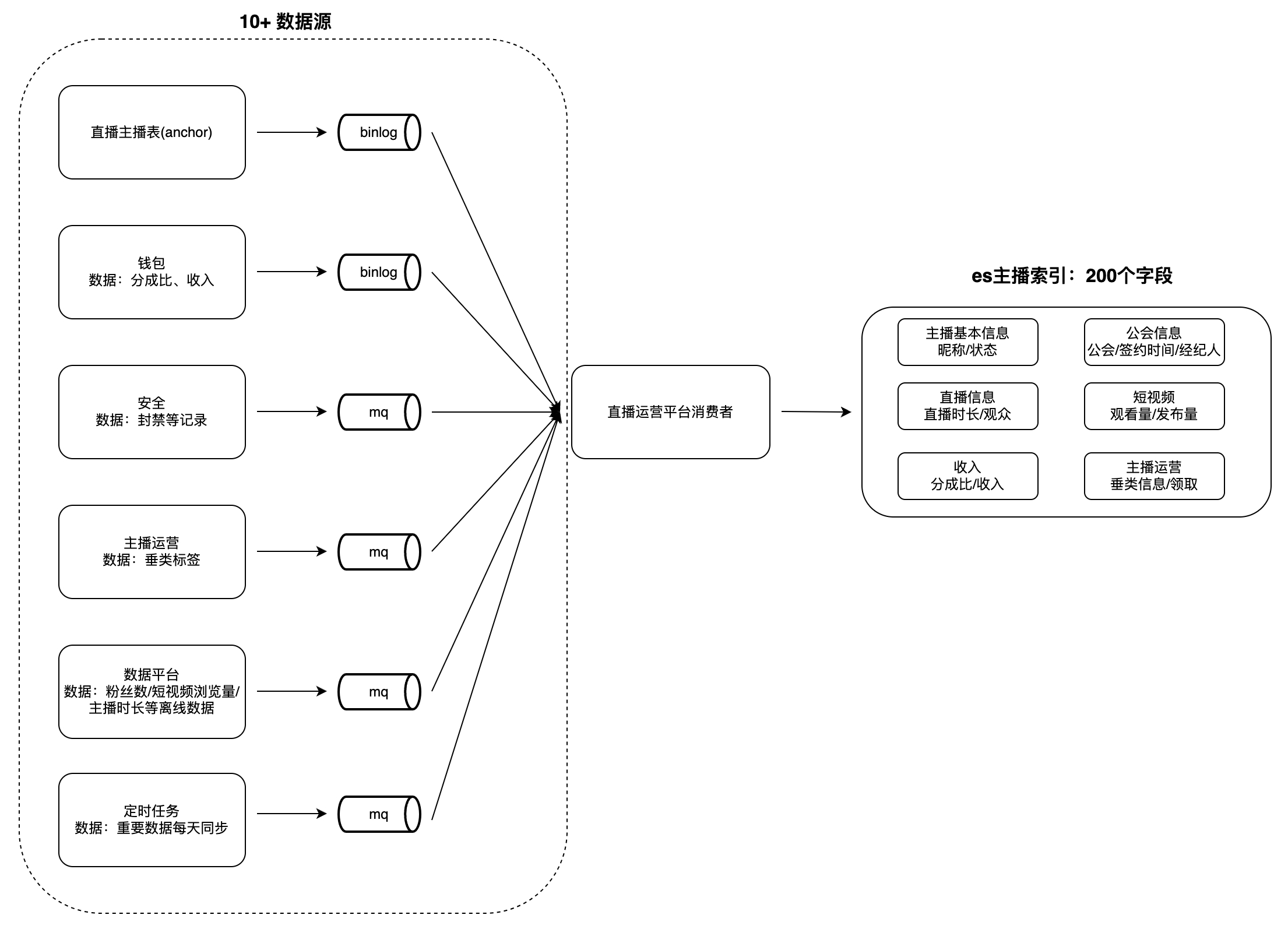
desafío
La primera versión de la implementación utilizó un único PSM como consumidor para leer datos ascendentes y escribirlos en ES. Dado que las escrituras no estaban aisladas, hubo muchos problemas. En primer lugar, todas las partes que acceden escriben la lógica de consumo de datos en el mismo PSM, lo que genera un alto acoplamiento de la lógica de procesamiento de datos y dificultades de mantenimiento. En segundo lugar, existe el riesgo de que varias partes comerciales escriban en el mismo campo, lo que puede provocar excepciones comerciales. Además, el modo de escritura de datos ES de cobertura total da como resultado una velocidad de procesamiento de datos lenta y una velocidad de consumo de MQ baja. Al mismo tiempo, todavía existen problemas como la competencia de recursos y consultas lentas que no pueden asociarse con aguas arriba específicas. Con aproximadamente 5 campos nuevos agregados cada dos meses y los datos continúan creciendo, si estos problemas no se abordan, habrá mayores desafíos en el futuro.
El análisis de los problemas anteriores se puede dividir en tres categorías: la lógica de procesamiento de cada fuente de datos está altamente acoplada y el conjunto se ve fácilmente afectado por una sola parte comercial; la velocidad de procesamiento de datos es lenta, lo que intensifica la falta de lectura; y capacidades de gobernanza de escritura: aislamiento de escritura, estadísticas de consultas lentas.
solución
La siguiente figura presenta la estructura general después de la gobernanza. En base a esto, analizaremos los problemas y consideraciones encontrados en el proceso de gobernanza uno por uno.
Este contenido no se puede mostrar fuera de los documentos de Feishu por el momento.
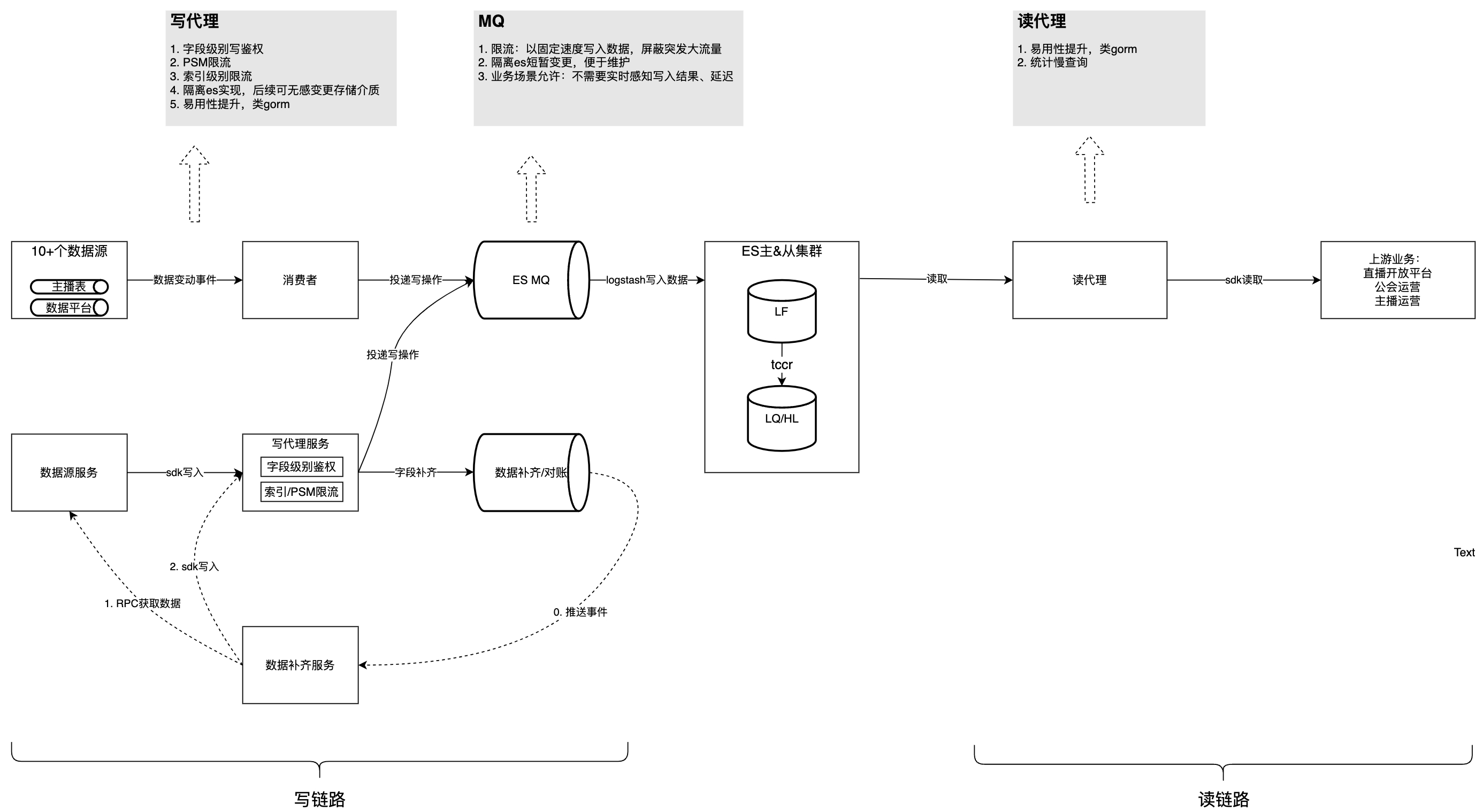
Problema 1: la lógica de consumo de cada fuente de datos está fuertemente acoplada, es difícil de mantener, se afecta entre sí y se apodera de los recursos.
La manifestación específica de este problema es que se implementan más de 10 lógicas de consumo de datos MQ en el mismo PSM. La lógica de procesamiento de datos compartidos y los cambios menores pueden afectar otros procesamientos de MQ, lo que hace que el servicio monitoree múltiples eventos de MQ. La competencia de recursos y la distribución desigual de las particiones de un único evento MQ conducen a una utilización desigual de los recursos en una sola máquina, lo que no se puede resolver mediante la expansión horizontal de la máquina. Por lo tanto, la inestabilidad del código de un solo MQ afectará el consumo de todos los temas de MQ. La distribución desigual de las particiones de los temas de MQ individuales hará que la CPU de las instancias de consumidores individuales se dispare, afectando así el consumo de otros temas.
Estrategia de optimización:
-
Mejorar la velocidad de consumo de un solo evento: actualización parcial de ES revisar la configuración limitante actual de todos los temas;
-
Cree más métodos de escritura de datos y distribuya la escritura de campos no básicos a varias partes comerciales. Por ejemplo, proporciona SDK de escritura e introduce Dsyncer.
Problema 2: el consumo de datos
de MQ
es lento y las actualizaciones de datos comerciales se retrasan
El procesamiento de un solo mensaje MQ requiere mucho tiempo. Tomando como ejemplo el modo de escritura de datos ES de cobertura completa, actualizar un campo requiere escribir los campos restantes que no necesitan actualizarse juntos, porque es necesario obtener casi 200 datos de campo. en tiempo real a través de RPC. En general, lleva mucho tiempo y la velocidad de consumo de MQ es lenta; algunos temas de MQ consumen 1 trabajador en una sola instancia. El principal impacto es que el retraso en la actualización de datos es alto y la información del usuario tarda un tiempo en mostrarse en las plataformas posteriores después de los cambios. Y cada actualización requiere que se obtengan casi 200 campos de múltiples partes comerciales. Las anomalías en una única fuente de datos harán que todo el consumo de eventos MQ falle y se vuelva a intentar.
Estrategia de optimización:
-
Cambie el modo de escritura de datos del clúster ES de cobertura total a actualización parcial: un solo campo se puede actualizar a pedido y el consumidor ya no necesita obtener casi 200 campos de múltiples partes comerciales, lo que no solo reduce el tiempo de procesamiento de datos, sino que también reduce el código. Dificultad de mantenimiento;
-
Configure todos los temas de MQ para que tengan varios trabajadores, y aquellos que requieren consumo secuencial se configuran para enrutarse al mismo trabajador según la ID de clave principal.
Problema 3: la escritura no está aislada/autenticada/limitada
La escritura de campos carece de aislamiento y autenticación, y existe el riesgo de que varias partes comerciales escriban en el mismo campo, lo que puede causar anomalías comerciales. La razón principal es que las partes que escriben comparten recursos. Si una de las partes escribe demasiado rápido, ocupará los recursos de otras partes, lo que aumentará el retraso en la escritura. Por lo tanto, es necesario controlar estrictamente las actualizaciones del campo principal del almacenamiento ES para evitar generar una gran cantidad de comentarios de los usuarios.
Estrategia de optimización:
-
Se agregó autenticación de escritura a nivel de campo, lo que permite que solo los PSM autorizados escriban ciertos datos de campo;
-
Para llevar a cabo estrategias de limitación de tráfico en las dos dimensiones de PSM e índice, se utilizan componentes configurables dinámicamente en la plataforma de gestión de tráfico general.
Problema 4: falta de estadísticas de consultas lentas y métodos de optimización
Al igual que MySQL y otras bases de datos, SQL no estándar provocará análisis innecesarios y grandes retrasos en las consultas. ES proporciona la capacidad de consultar SQL que requiere mucho tiempo, pero no puede correlacionar PSM, Logid y otra información ascendente, lo que dificulta la resolución de problemas.
Estrategia de optimización: el agente de lectura registra SQL, PSM ascendente, Logid y otros mensajes que superan el umbral en forma de una capa intermedia para ES e informa condiciones de consulta lentas todos los días.
Pregunta 5: Facilidad de uso
Estrategia de optimización:
-
Habilite el complemento ES SQL en el clúster ES Debido a que la sintaxis de ES SQL es ligeramente diferente de MySQL SQL, se proporciona soporte adicional a través del servicio del agente de lectura: el lado del usuario usa la sintaxis de MySQL y el agente de lectura usa expresiones regulares para reescribir. Estándares SQL a ES SQL; inyecte ScrollID en ES SQL, el lado del usuario no necesita preocuparse por cómo expresar la consulta de desplazamiento en SQL;
-
Ayude a los usuarios a deserializar datos de consultas en estructuras.
// es dsl查询样例 GET twitter/_search { "size": 10, "query": { "match" : { "title" : "Elasticsearch" } }, "sort": [ {"date": "asc"} ] } // 使用读sdk的等价sql select * from twitter where title="Elasticsearch" order by date asc limit 10
Resultados de gobernanza
A través de la gobernanza anterior, se eliminó por completo la acumulación de enlaces de escritura y la capacidad de consumo aumentó en un 150%, lo que se refleja específicamente en aumentar el QPS del negocio de 4k a 10k, sin alcanzar el límite superior de rendimiento del sistema. La lectura máxima QPS es 1500 y el SLA se mantiene estable en 99,99% a largo plazo. Actualmente, varias partes comerciales están utilizando el SDK y las partes comerciales informaron que el tiempo de acceso se ha reducido de los 2 días originales a 0,5 días.
Planificación de seguimiento
La planificación de seguimiento incluye principalmente expandir las capacidades de conciliación de MVP de escenarios individuales a todos los escenarios; promover la optimización empresarial ascendente de SQL basada en estadísticas de consultas lentas y proporcionar más métodos de escritura de datos, como FaaS;
Basado en la experiencia interna de mejores prácticas a gran escala de ByteDance, Volcano Engine proporciona
productos
ES
consistentes externamente : servicios de búsqueda en la nube y productos en la nube de nivel empresarial. El servicio de búsqueda en la nube es compatible con Elasticsearch, Kibana y otros software y complementos de código abierto de uso común. Proporciona recuperación de múltiples condiciones, estadísticas e informes de texto estructurado y no estructurado. Puede lograr implementación con un solo clic, escalamiento elástico. operación y mantenimiento simplificados, y creación rápida de análisis de registros, recuperación y análisis de información y otras capacidades comerciales.
{{o.nombre}}
{{m.nombre}}