Este artículo presenta la compilación del código fuente de Spark2.1.0
1. Entorno de compilación:
Jdk1.8 o superior
Hadoop2.7.3
Scala2.10.4
Requerimientos:
Maven 3.3.9 o superior (importante)
Haga click aquí para descargar
http://mirror.bit.edu.cn/apache/maven/maven-3/3.5.2/binaries/apache-maven-3.5.2-bin.tar.gz
Modificar /conf/setting.xml
<espejo>
<id> alimaven </id>
<nombre> aliyun maven </nombre>
<url> http://maven.aliyun.com/nexus/content/groups/public/ </url>
<mirrorOf> central </mirrorOf>
</mirror>
2. Descarga http://spark.apache.org
2.1 Descargar
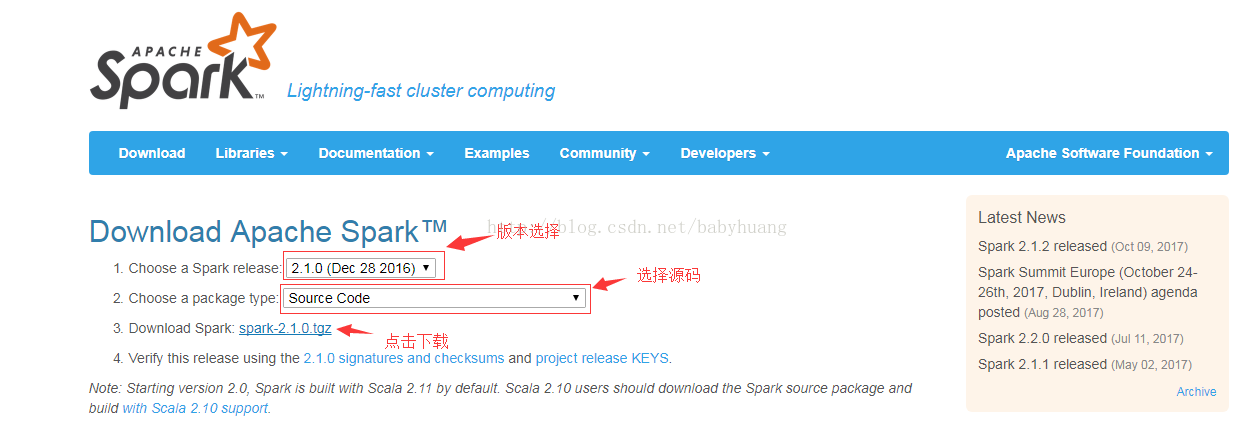
2.2. Descomprimir
tar -zxvf spark-2.1.0.tgz
3. Ingrese al directorio principal, modifique el archivo compilado y compile
Modifique make-distribution.sh en el directorio spark-2.1.0 / dev y comente la versión original especificada, lo que puede ahorrar tiempo
vi make-distribution.sh
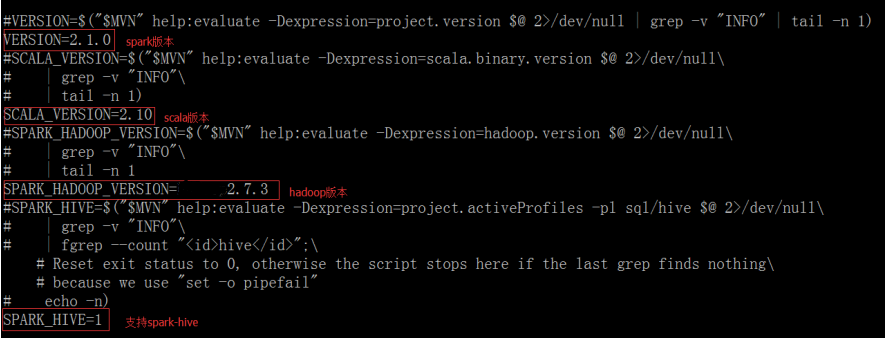
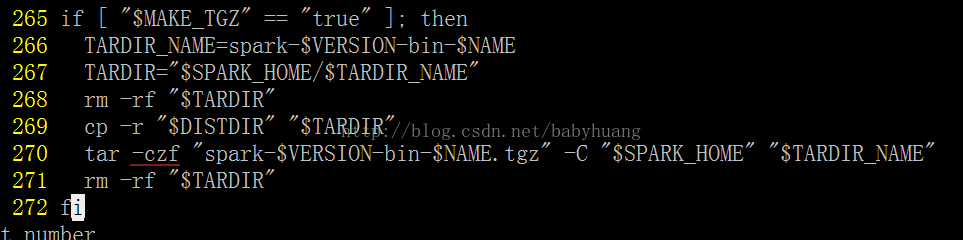
Consejos:
Como se muestra en la figura del archivo, hay menos " - " antes de czf , por lo que debe modificarlo usted mismo.
Nota:
Si la versión de hadoop que usa es cdh, debe modificar el archivo pom.xml en el directorio raíz de Spark y agregar la dependencia de cdh
<repository>
<id> cloudera </id>
<name> cloudera Repository </name>
<url> https://repository.cloudera.com/artifactory/cloudera-repos/ </url>
</repository>
添加 在 < repositorys> </repositorys> 里
3.1 Configurar memoria
export MAVEN_OPTS = "- Xmx2g -XX: ReservedCodeCacheSize = 512m"
3.2 Compilar
./dev/make-distribution.sh \
--nombre 2.7.3 \
--tgz \
-Pyarn \
-Phadoop-2.7 \ -Dhadoop.version = 2.7.3 \
-Phive -Phive-thriftserver \
-DskipTests paquete limpio
Entonces solo espera en silencio, el tiempo de primera compilación puede ser muy largo, varias horas o diez horas, dependiendo de la velocidad de la red, porque hay muchos paquetes para descargar
Explicación del comando:
--name 2.7.3 *** Especifique el nombre de chispa compilado , nombre =
--tgz *** comprimir a formato tgz
-Pyarn \ *** plataforma de hilo de soporte
-Phadoop-2.7 \ -Dhadoop.version = 2.7.3 \ *** Especifique la versión 2.7.3 de hadoop
-Phive -Phive-thriftserver \ ***支持colmena
-DskipTests clean package *** Omitir paquete de prueba
Bueno, la recopilación de Spark está aquí.
Permítanme compartir algunos de los problemas encontrados en la compilación.
Error 1 :
No se pudo ejecutar el objetivo en el proyecto spark-launcher_2.11:
No se pudieron resolver las dependencias para el proyecto org.apache.spark: spark-launcher_2.11: jar: 2.1.0:
No se pudo encontrar org.apache.hadoop: hadoop-client: jar: hadoop2.7.3 en https://repo1.maven.org/maven2 se almacenó en caché en el depósito local
resolution will not be reattempted until the update interval of central has elapsed or updates are forced -> [Help 1]
解决:遇该错误,原因可能是编译命令中有参数写错。。。。(希望你没遇到 )
)
错误2:
+ tar czf 'spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3.tgz' -C /zhenglh/new-spark-build/spark-2.1.0 'spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3'
tar (child): Cannot connect to spark-[info] Compile success at Nov 28, 2017 11: resolve failed
编译的结果没打包:
spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3
这个错误可能第一次编译的人都会遇到
解决:见温馨提示