Este artículo tiene como valor predeterminado descargar todos los archivos a / home / YourUserName / downloads
1. Introducción a Hive
Hive es una herramienta de almacenamiento de datos basada en Hadoop para la extracción, transformación y carga de datos. Este es un mecanismo que puede almacenar, consultar y analizar datos a gran escala almacenados en Hadoop. La herramienta de almacenamiento de datos de Hive puede asignar archivos de datos estructurados a una tabla de base de datos y proporcionar funciones de consulta SQL , que pueden convertir declaraciones SQL en tareas MapReduce para su ejecución. La ventaja de Hive es que el costo de aprendizaje es bajo, y las estadísticas de MapReduce rápidas se pueden realizar a través de declaraciones SQL similares, lo que facilita MapReduce, sin la necesidad de desarrollar aplicaciones MapReduce especializadas.
2. Instalación y configuración de Hive
- Descarga Hive
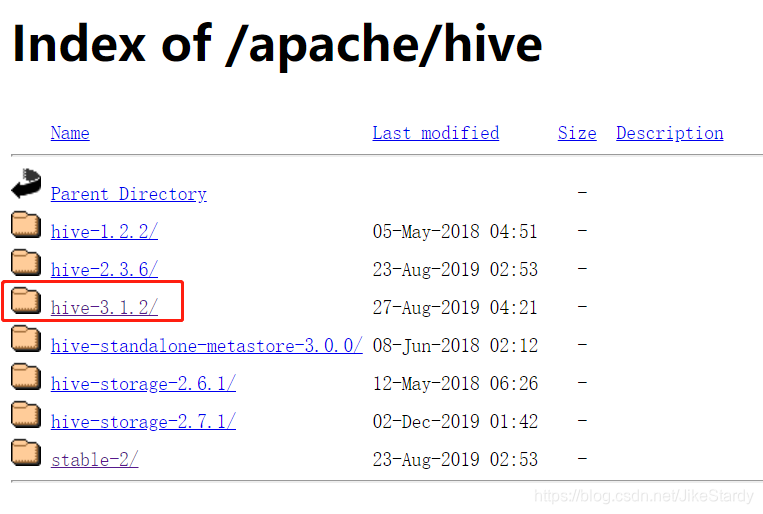
Ingrese a la página de origen de descarga de Apache Hive
Nota: la versión 3.xx funciona con la versión 3.yy de Hadoop y la versión 2.xx funciona con la versión 2.yy de Hadoop.
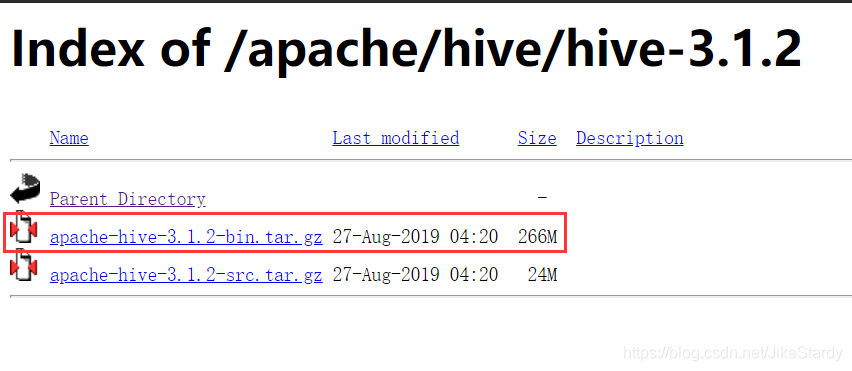
Mi Hadoop es la versión 3.1.3, así que descargo 3.1.2 Hive ** (recuerda descargar el paquete compilado) **
wget http://mirror.bit.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gzAdemás, la base de datos que configuré para Hive es MySQL, por lo que necesito descargar el paquete jar del controlador MySQL
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jarLa velocidad de descarga anterior es demasiado lenta, puede intentar lo siguiente
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.47.tar.gz # 从这里下载的文件要解压哦 tar -zxf mysql-connector-java-5.1.47.tar.gz
- iniciar la instalación
Abrir la cremallera
tar -zxf apache-hive mv apache hive cp hive /usr/local/hiveConfigurar variables de entorno
vi /etc/sourceUnirse
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/binEn el directorio hdfs y conceda permisos
hdfs dfs -mkdir -p /usr/local/hive/warehouse hdfs dfs -mkdir -p /usr/local/hive/tmp hdfs dfs -mkdir -p /usr/local/hive/log hdfs dfs -chmod g+w /usr/local/hive/warehouse hdfs dfs -chmod g+w /usr/local/hive/tmp hdfs dfs -chmod g+w /usr/local/hive/logConfiguración
hive-env.shcd /usr/local/hive/conf cp hive-env.sh.template hive-env.sh vim hive-env.shAgregue el siguiente contenido en él (hay una línea correspondiente después de que se copia la plantilla)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0_241 export HADOOP_HOME=/usr/local/hadoop export HIVE_HOME=/usr/local/hive export HIVE_CONF_DIR=$HIVE_HOME/conf export HIVE_AUX_JARS_PATH=$HIVE_HOME/lib/*Configuración
hive-site.xmlcp -r hive-default.xml.template hive-site.xml vim hive-site.xmlEn
<configuration>adición de la siguiente etiqueta<property> <name>system:java.io.tmpdir</name> <value>/tmp/hive/java</value> <property> <property> <name>system:user.name</name> <value>${user.name}</value> <property>Y modifica lo siguiente
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://Master:3306/hive?createDatabaseIfNotExist=true&characterEncoding=utf8&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>toor</value> </property>Nota: ¿Por qué usar & amp; en el valor de ConnectionURL aquí? Porque & es una referencia de entidad predefinida en XML
Referencia de entidad Personajes representados Nombre del personaje & lt; < Menos que & gt; > mas que el &erio; Y con & apos; ' apóstrofe & quot; " Doble comillas Coloque el archivo del controlador descargado
/usr/local/hive/libdebajocp /home/yourusername/downloads/mysql-connector-java-5.1.47.jar /usr/local/hive/lib # 如果是用第二个命令下载的则 # cp /home/yourusername/downloads/mysql-connector-java-5.1.47/mysql-connector-java-5.1.47.jar /usr/local/hive/libÚselo para
schemaToolinicializar la base de datos mysqlschematool -dbType mysql -initSchema
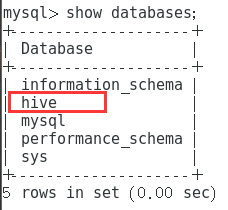
Luego iniciamos sesión en MySQL para verificar
mysql -u root -p yourpasswordVer si hay una base de datos llamada colmena
show databases;Debería ser como sigue

- Inicie Hive (primero debe iniciar Hadoop)
hiveLa salida es la siguiente

3. Problemas encontrados en el proceso
- Causas relacionadas con el enlace rápido log4j , no se puede inicializar
Elimine el paquete relevante en la ruta de clase, dejando solo uno
Por ejemplo, aquí eliminamos el paquete log4j en $ HIVE_HOME / lib
rm -rf /usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jarNota: El nombre del paquete aquí puede ser diferente, ingrese el comando de acuerdo con la salida del registro en la terminal

- 提示Excepción en el hilo "principal" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument
Este es un problema de que la versión de guayaba utilizada por hive es demasiado baja. Puede copiar guayaba en Hadoop directamente, y recuerde eliminar la guayaba que viene con hive.
cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib cd /usr/local/hive/lib rm -rf guava-19.0.jar
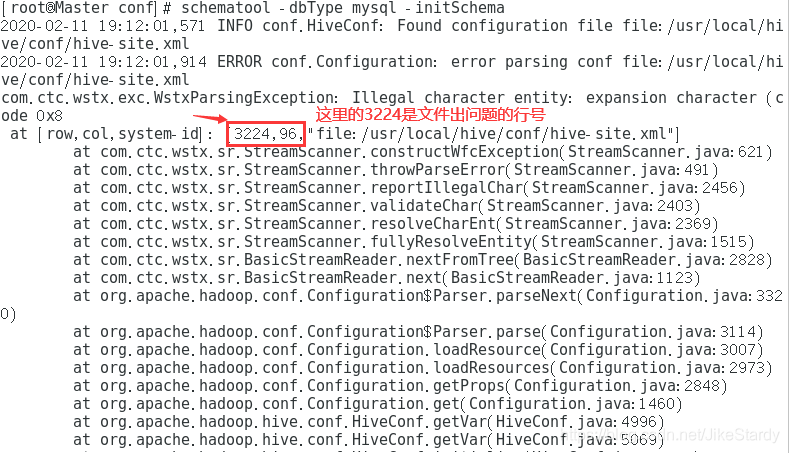
- problema de hive-site.xml
cd /usr/local/hive/conf vim hive-site.xmlUsar comandos vim
:3224Presione enter para ver dónde ocurrió el error
Entonces hay un problema de cerrar la etiqueta <configuration>

- hive 启动 失败 :No se puede crear el directorio / tmp / hive. El nodo de nombre está en modo seguro.
Comando para salir del modo seguro
hdfs dfsadmin -safemode leavePosibles Causas:
El modo de seguridad de hdfs se ve afectado por las siguientes propiedades del archivo de configuración hdfs-site.xml:
<property> <name>dfs.namenode.safemode.threshold-pct</name> <value>0.99</value> </property>Esto es un porcentaje, lo que significa que cuando NameNode obtiene el 99% de todo el bloque de datos del sistema de archivos, saldrá automáticamente del modo seguro. Este porcentaje puede ser configurado por usted mismo, si este valor es menor o igual a 0, no entrará en modo seguro, pero si el valor es mayor que 1, estará en modo seguro indefinidamente.
Infinite está en modo seguro, existen las siguientes posibilidades:
1) El valor de dfs.namenode.safemode.threshold-pct es mayor que 1
2) ¿Hay una pequeña cantidad de nodos y el requisito de copia no es 1, por ejemplo, solo hay un nodo, pero la copia mínima (dfs.replication.min) es 2, entonces, en este caso, definitivamente habrá un modo de seguridad infinito, porque 2 Copias, pero solo un nodo, la segunda copia no se puede copiar.
Explicación del modo seguro:
El NameNode entra primero en modo seguro cuando se inicia. Si el nodo de datos pierde un cierto porcentaje de bloques (dfs.safemode.threshold.pct) , el sistema siempre estará en modo seguro, es decir, de solo lectura .
dfs.safemode.threshold.pct (valor predeterminado 0.999f) significa que cuando se inicia HDFS, si el número de bloques reportados por el DataNode llega a 0.999 veces el número de bloques registrados en los metadatos, se puede dejar el modo seguro, de lo contrario siempre será así Modo de solo lectura. Si se establece en 1, HDFS siempre está en SafeMode.
Hay dos formas de salir de este modo seguro
(1) Modificacióndfs.safemode.threshold.pctEs un valor relativamente pequeño y el predeterminado es 0,999. (Nota: configúrelo en 0 en hdfs-site.xml, desactive el modo seguro)
(2)hadoop dfsadmin -safemode dejarOrden de irseNota: El usuario puede utilizar
dfsadmin -safemodepara operar el modo seguro, la descripción del valor del parámetro es la siguiente:
- entrar-entrar en modo seguro
- dejar-Force NameNode para salir del modo seguro
- get: devuelve si el modo seguro está habilitado
- espera-espera hasta el final del modo seguro.