I. Descripción general
El alto rendimiento es lo que persigue todo programador: ya sea que estén construyendo un sistema o escribiendo un conjunto de códigos, todos esperan lograr un alto rendimiento. Y el alto rendimiento es la parte más complicada. El disco, el sistema operativo, la CPU, la memoria, el caché, la red, el lenguaje de programación, la base de datos, la arquitectura, etc., pueden afectar el alto rendimiento del sistema. Una línea de registro de depuración inapropiada, una Un índice inadecuado puede reducir el rendimiento del servidor de 30.000 TPS a 8.000 TPS. Un parámetro tcp_nodelay puede extender el tiempo de respuesta de 2 ms a 40 ms. Por lo tanto, lograr una computación de alto rendimiento es un asunto muy complejo y desafiante. Las diferentes etapas en el proceso de desarrollo del sistema de software están relacionadas con si en última instancia se puede lograr un alto rendimiento.
¿Dónde están los puntos de diseño para el diseño de arquitectura de alto rendimiento?
(1) Intente mejorar el rendimiento de un solo servidor y maximizar el rendimiento de un solo servidor.
(2) Si un solo servidor no puede soportar el rendimiento, diseñe una solución de clúster de servidores.
(3) Implementación y codificación específicas, el diseño arquitectónico determina el límite superior del rendimiento del sistema y los detalles de implementación determinan el límite inferior del rendimiento del sistema.
Mapa de diseño de arquitectura de alto rendimiento:
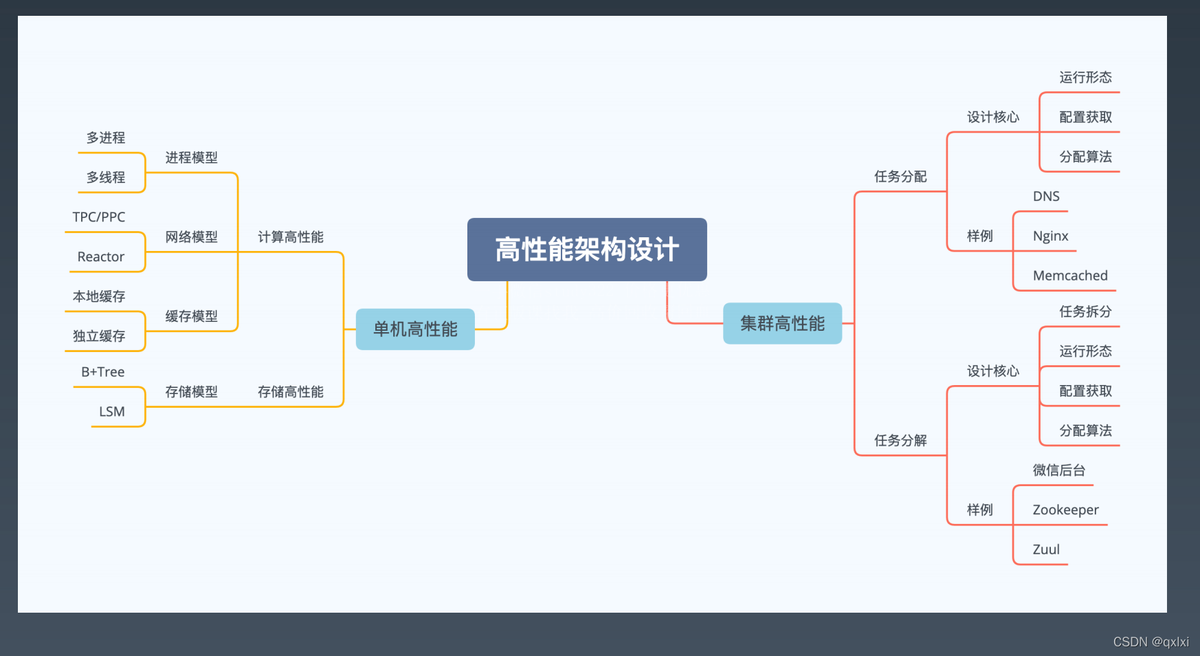
2. Alto rendimiento de servidor único
¿Cuáles son los puntos clave para un alto rendimiento en un solo servidor?
(1) Cómo gestiona el servidor las conexiones (modelo de E/S: bloqueante, sin bloqueo, síncrono, asíncrono).
(2) Cómo maneja el servidor las solicitudes (proceso, multiproceso, multiproceso).
¿Cuáles son los modos de alto rendimiento para un solo servidor?
| modelo |
Una breve descripción |
| PPC |
Cada vez que hay una nueva conexión, se crea un nuevo proceso para manejar específicamente la solicitud de esta conexión. La versión mejorada es prefork, que crea procesos por adelantado. |
| TPC |
Cada vez que hay una nueva conexión, se crea un nuevo hilo para manejar específicamente la solicitud de esta conexión. La versión mejorada es prethread, que crea hilos por adelantado. |
| Reactor |
Es decir, el modo Dispatcher, un modelo de red síncrono sin bloqueo, multiplexación de E / S y monitoreo unificado de eventos, y después de recibir el evento, asignar (Dispatch) a un determinado proceso o subproceso. |
| Proactor |
Es un modelo de red asincrónico que admite la reutilización y distribución de múltiples controladores de eventos cuando se completan eventos asincrónicos. |
2.1 PCP
PPC es la abreviatura de Proceso por conexión, cada vez que hay una nueva conexión, se crea un nuevo proceso para manejar específicamente la solicitud de conexión, este es el modelo utilizado por los servidores de red UNIX tradicionales. El diagrama de flujo básico es:
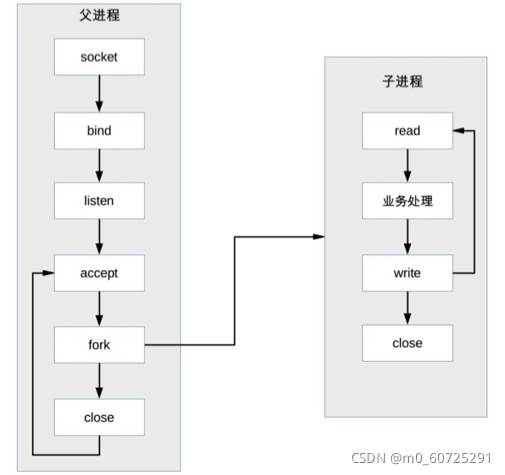
Descripción: El proceso principal acepta la conexión (aceptar en la figura), el proceso principal "bifurca" el proceso secundario (bifurcación en la figura), el proceso secundario procesa las solicitudes de lectura y escritura de la conexión (lectura del proceso secundario, procesamiento comercial , escriba en la figura), y el proceso hijo cierra la conexión (cierre en el subproceso de la figura).
Nota: Después de que el proceso padre "bifurca" el proceso hijo, llama directamente a cerrar. Parece que la conexión está cerrada. De hecho, simplemente disminuye el recuento de referencias del descriptor de archivo de la conexión en uno. La conexión real se cierra después del proceso hijo También llama a cerrar, y el sistema operativo no cerrará realmente la conexión hasta que el recuento de referencias del descriptor de archivo correspondiente a la conexión sea 0.
El modo PPC es simple de implementar y es más adecuado para situaciones donde la cantidad de conexiones al servidor no es tanta, como un servidor de base de datos. Para los servidores comerciales comunes, antes del surgimiento de Internet, este modelo realmente funcionaba bien porque las visitas al servidor y la concurrencia no eran tan grandes. CERN httpd, el primer servidor web del mundo, adoptó este modelo (para obtener más detalles, puede consultar https: //en.wikipedia.org/wiki/CERN_httpd). Tras el auge de Internet, el número de concurrencias y visitas a servidores ha aumentado de decenas a decenas de miles, se han destacado las desventajas de este modelo, principalmente en los siguientes aspectos:
La bifurcación es costosa: desde la perspectiva del sistema operativo, el costo de crear un proceso es muy alto: requiere asignar muchos recursos del kernel y copiar la imagen de memoria del proceso principal al proceso secundario. Incluso si los sistemas operativos actuales utilizan la tecnología Copiar sobre Escritura al copiar imágenes de memoria, el costo total de crear un proceso sigue siendo muy alto.
La comunicación entre los procesos padre e hijo es complicada: cuando el proceso padre "bifurca" el proceso hijo, el descriptor de archivo se puede transferir del proceso padre al proceso hijo mediante la copia de la imagen de la memoria. Sin embargo, una vez completada la "bifurcación", el La comunicación entre los procesos padre e hijo se vuelve más problemática y requiere el uso de IPC (Interprocess Communication) y otras soluciones de comunicación de procesos. Por ejemplo, si el proceso hijo necesita decirle al proceso padre cuántas solicitudes ha procesado antes de cerrar para respaldar el proceso padre en las estadísticas globales, entonces el proceso hijo y el proceso padre deben utilizar el esquema IPC para transferir información.
La cantidad de conexiones simultáneas admitidas es limitada: si cada conexión sobrevive durante mucho tiempo y continúan llegando nuevas conexiones, la cantidad de procesos aumentará y la frecuencia de programación y conmutación de procesos del sistema operativo será cada vez mayor. La presión también aumentará. Por lo tanto, en circunstancias normales, el número máximo de conexiones simultáneas que la solución PPC puede manejar es sólo unos pocos cientos.
Basado en el alto costo de la bifurcación, ha surgido una versión mejorada de prefork. El sistema crea previamente el proceso cuando se inicia y luego comienza a aceptar solicitudes de los usuarios. Cuando llega una nueva conexión, la operación de bifurcar el proceso puede ser omitido Permita que los usuarios accedan más rápido y tengan una mejor experiencia. El diagrama básico de prefork es:
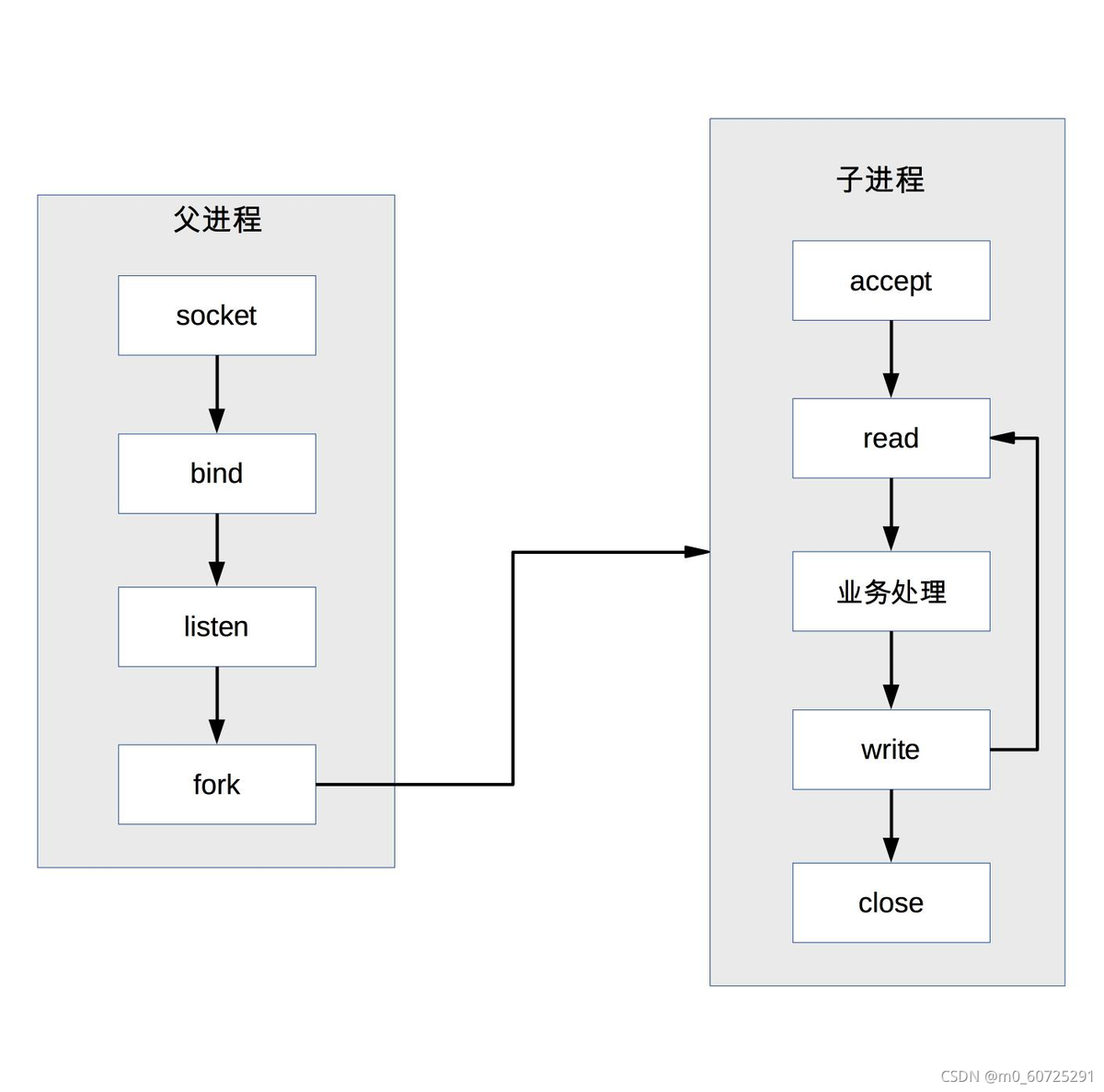
La clave para la implementación de prefork es que varios procesos secundarios aceptan el mismo socket. Cuando ingresa una nueva conexión, el sistema operativo garantiza que solo un proceso finalmente pueda aceptar con éxito. Pero hay un fenómeno de "shock".
Grupo impactante: aunque solo un proceso secundario puede aceptar con éxito, todos los procesos secundarios bloqueados al aceptar se despertarán, lo que resultará en una programación de procesos y cambios de contexto innecesarios (el kernel resolvió el problema de aceptación después de la versión 2.6 de Linux) pregunta)
El modo prefork, como PPC, todavía tiene los problemas de comunicación compleja de procesos padre-hijo y un número limitado de conexiones simultáneas admitidas, por lo que no hay muchas aplicaciones prácticas en la actualidad.
El servidor Apache proporciona el modo MPM prefork, que se recomienda para sitios que requieren confiabilidad o compatibilidad con software antiguo. De forma predeterminada, admite un máximo de 256 conexiones simultáneas.
2.2 TPC
TPC es la abreviatura de Thread Per Connection, lo que significa que cada vez que hay una nueva conexión, se crea un nuevo hilo para procesar específicamente la solicitud de conexión.
En comparación con los procesos, los subprocesos son más livianos y el costo de crear subprocesos es mucho menor que el de los procesos; al mismo tiempo, los subprocesos múltiples comparten el espacio de memoria del proceso y la comunicación de subprocesos es más simple que la comunicación de procesos.
TPC en realidad resuelve o debilita el problema del alto costo de bifurcación de PPC y la complicada comunicación entre los procesos padre e hijo.
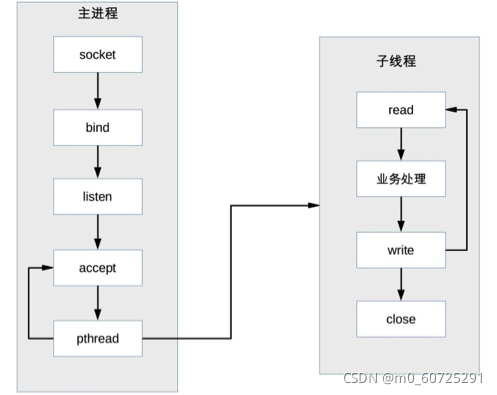
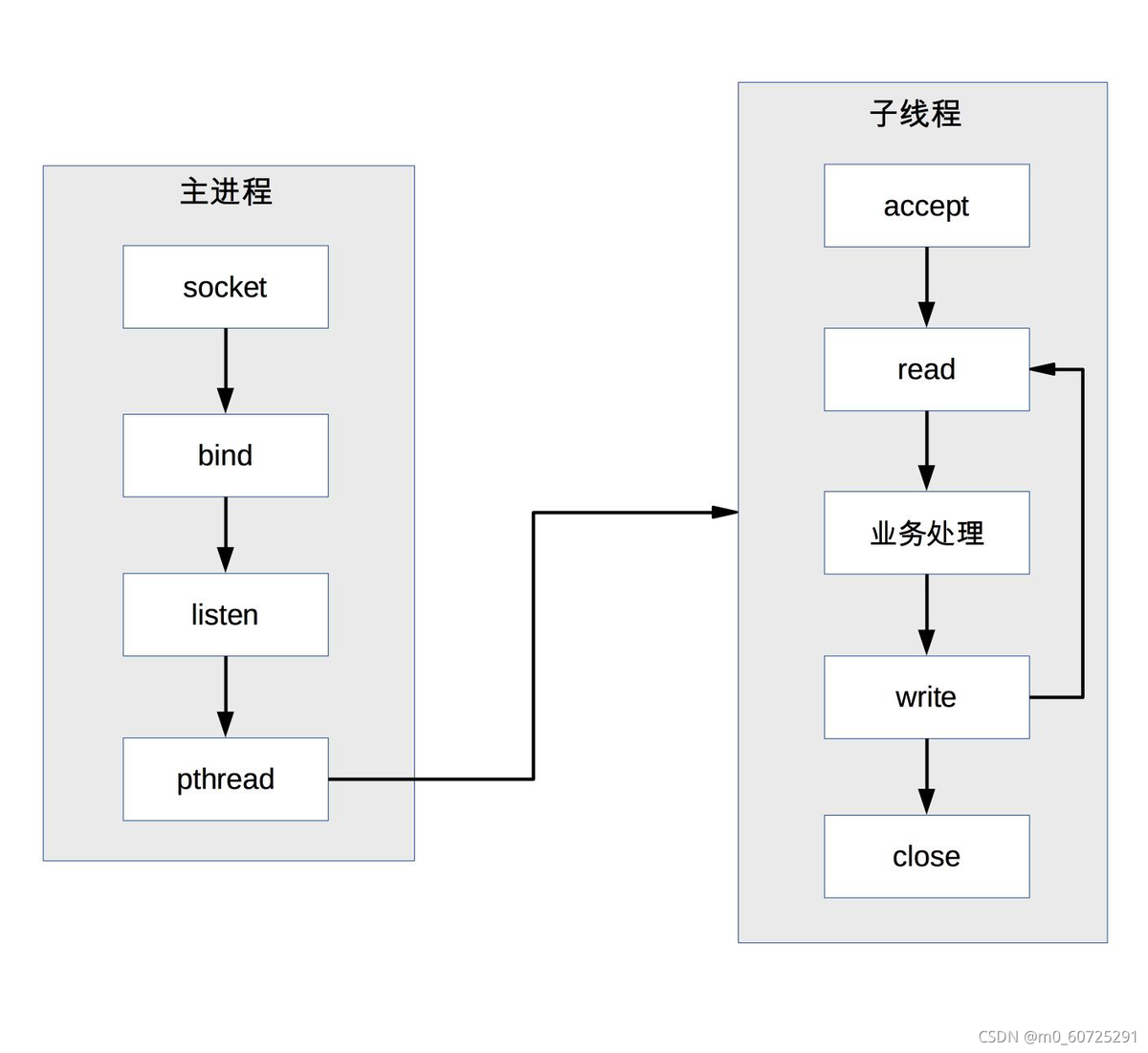
Descripción: el proceso principal acepta la conexión (aceptar en la figura), el proceso principal crea un subproceso secundario (pthread en la figura), el subproceso secundario procesa las solicitudes de lectura y escritura de la conexión (lectura del subproceso secundario, procesamiento comercial, escritura en la figura), y el hilo secundario cierra la conexión (figura cerrada en el hilo de neutrones).
Nota: En comparación con PPC, el proceso principal no necesita cerrar la conexión. La razón es que el subproceso secundario comparte el espacio de proceso del proceso principal y el descriptor del archivo conectado no se copia, por lo que solo es necesario cerrarlo una vez.
Aunque TPC resuelve los problemas de alto costo de bifurcación y comunicación de procesos complejos, también introduce nuevos problemas, específicamente los siguientes:
(1) Aunque crear un hilo es más barato que crear un proceso, no está exento de costos. Todavía existen problemas de rendimiento cuando la concurrencia es alta;
(2) No hay necesidad de comunicación entre procesos, pero la exclusión mutua y el intercambio entre subprocesos introducen una nueva complejidad, que accidentalmente puede provocar problemas de punto muerto;
(3) Los subprocesos múltiples tendrán problemas que se afectarán entre sí. Cuando ocurre una excepción en un subproceso, puede provocar que todo el proceso se cierre;
Además de introducir nuevos problemas, TPC también tiene problemas con la programación de subprocesos de la CPU y los costos de conmutación.
La solución TPC es básicamente similar a la solución PPC en naturaleza. En escenarios con cientos de conexiones simultáneas, la solución PPC se usa con más frecuencia porque la solución PPC no tiene el riesgo de interbloqueo, ni múltiples procesos se afectan entre sí, y es estable más alto.
En vista de las desventajas del costo de creación de subprocesos de TPC, el método prethread se deriva del método prefork. El modo prethread creará subprocesos por adelantado y luego comenzará a aceptar solicitudes de los usuarios. Cuando llegue una nueva conexión, puede ahorrar la necesidad de crear un hilo La operación hace que los usuarios se sientan más rápidos y experimenten mejor. El método prethread adoptado por MySql.
Dado que el intercambio de datos y la comunicación entre subprocesos múltiples son más convenientes, la implementación de prethread es en realidad más flexible que prefork. Los métodos de implementación comunes incluyen los siguientes:
(1) El proceso principal acepta y luego entrega la conexión a un hilo para su procesamiento.
(2) Todos los subprocesos intentan aceptar, pero al final solo un subproceso acepta con éxito. El diagrama básico de la solución es el siguiente:
El modo de trabajo MPM del servidor Apache es esencialmente una solución previa al subproceso, pero con ligeras mejoras. El servidor Apache primero creará múltiples procesos y luego creará múltiples subprocesos en cada proceso, lo que se hace principalmente para considerar la estabilidad, es decir: incluso si un subproceso en un proceso secundario es anormal y hace que todo el proceso secundario salga, habrá be other El proceso secundario continúa brindando servicios sin causar que todo el servidor cuelgue.
La alta concurrencia debe dividirse según dos condiciones: la cantidad de conexiones y la cantidad de solicitudes.
-
Conexiones masivas (decenas de miles) y solicitudes masivas: como ventas urgentes, Double Eleven, 12306, etc.
-
Solicitudes masivas de conexión constante (de decenas a cientos): como middleware
-
Solicitudes constantes de conexión masiva (QPS supera mil): como sitios web de portales
-
Solicitud constante de conexión constante (QPS docenas o cientos): como sistema operativo interno, sistema de gestión
PPC y TPC deberían ser más adecuados para sistemas con un rendimiento relativamente grande, conexiones largas y una pequeña cantidad de conexiones.
bio: bloqueo de io, PPC y TPC pertenecen a este tipo nio: multiplexación de io, el reactor se basa en esta tecnología aio: asíncrono io, Proactor se basa en esta tecnología
La multiplexación de E/S es un mecanismo a través del cual un proceso/hilo puede monitorear múltiples conexiones. Una vez que una conexión está lista (generalmente lista para lectura o escritura), puede notificar al programa que realice las operaciones de lectura y escritura correspondientes.
La multiplexación de IO consiste en esperar a que varios descriptores de archivos estén listos al mismo tiempo, lo que se proporciona en forma de llamadas al sistema. Si todos los descriptores de archivos no están listos, la llamada al sistema se bloquea; de lo contrario, la llamada regresa, lo que permite al usuario realizar operaciones posteriores.
Cuando varias conexiones comparten un objeto de bloqueo, el proceso solo necesita esperar a un objeto de bloqueo sin sondear todas las conexiones. Los métodos de implementación comunes incluyen select, epoll, kqueue, etc.
epoll es una tecnología de multiplexación de IO en Linux, que puede manejar millones de identificadores de sockets de manera muy eficiente. epoll registra un descriptor de archivo a través de epoll_ctl() por adelantado. Una vez que un descriptor de archivo está listo, el kernel utilizará un mecanismo de devolución de llamada similar a la devolución de llamada para activar rápidamente el descriptor de archivo. Cuando el proceso llame a epoll_wait(), será notificado (Comparado con select, se elimina el recorrido de los descriptores de archivos, pero a través del mecanismo de escuchar devoluciones de llamada)
Seleccionar / sondear sondea la lista de sockets después de recibir la notificación para ver qué socket se puede leer. El sondeo de sockets ordinario se refiere a llamar repetidamente a la operación de lectura.
La diferencia entre epoll y select:
(1) El número de identificadores de selección es limitado. Existe una declaración en el archivo de encabezado linux/posix_types.h: #define __FD_SETSIZE 1024, lo que significa que select puede monitorear hasta 1024 fds al mismo tiempo, pero epoll no Su límite es el número máximo de identificadores de archivos abiertos.
(2) El mayor beneficio de epoll es que la eficiencia no disminuirá a medida que aumenta el número de FD. El procesamiento de sondeo se utiliza en selec. La estructura de datos es similar a la de una matriz y epoll mantiene una cola. Mire directamente cola Está bien si no está vacío. epoll solo funcionará en sockets "activos" (en la implementación del kernel, epoll se implementa en función de la función de devolución de llamada en cada fd). Solo los sockets "activos" llamarán activamente a la función de devolución de llamada (agregue este identificador a la cola), otros inactivos los identificadores de estado no lo harán.
Si no hay una gran cantidad de conexiones inactivas o inactivas, epoll no será mucho más eficiente que select/poll.
(3) Utilice mmap para acelerar el paso de mensajes entre el kernel y el espacio del usuario. Ya sea select/poll o epoll, el kernel necesita notificar el mensaje FD al espacio de usuario. Cómo evitar copias de memoria innecesarias es muy importante. En este punto, epoll se implementa mediante mmap la misma memoria entre el kernel y el espacio de usuario. .
2.3 reactores
La multiplexación de E/S combinada con el grupo de subprocesos resuelve perfectamente los problemas de PPC y TPC y le da un muy buen nombre: Reactor. El modo Reactor también se llama modo Dispatcher (verá clases con este nombre en muchos sistemas de código abierto, que en realidad implementan el modo Reactor). Está más cerca del significado del modo en sí, es decir, multiplexación de E/S y Monitoreo unificado de eventos Despacho a un proceso posterior al evento.
Los componentes principales del modo Reactor incluyen Reactor y el grupo de recursos de procesamiento (grupo de procesos o grupo de subprocesos), donde Reactor es responsable de monitorear y enviar eventos, y el grupo de recursos de procesamiento es responsable de procesar eventos.
Combinado con diferentes escenarios comerciales, el esquema de implementación específico del modo puede ser flexible y modificable, como por ejemplo:
-
Proceso único de reactor único (hilo);
-
Multihilo de reactor único;
-
Multiproceso Multi-Reactor (hilo);
-
Proceso/hilo único de reactor múltiple (sin sentido);
La elección específica de proceso o hilo en el esquema anterior está más relacionada con el lenguaje y la plataforma de programación. Por ejemplo, el lenguaje Java generalmente usa subprocesos (por ejemplo, Netty), y el lenguaje C puede usar tanto procesos como subprocesos. Por ejemplo, Nginx usa procesos y Memcache usa subprocesos.
2.3.1 Proceso único de reactor único (hilo)
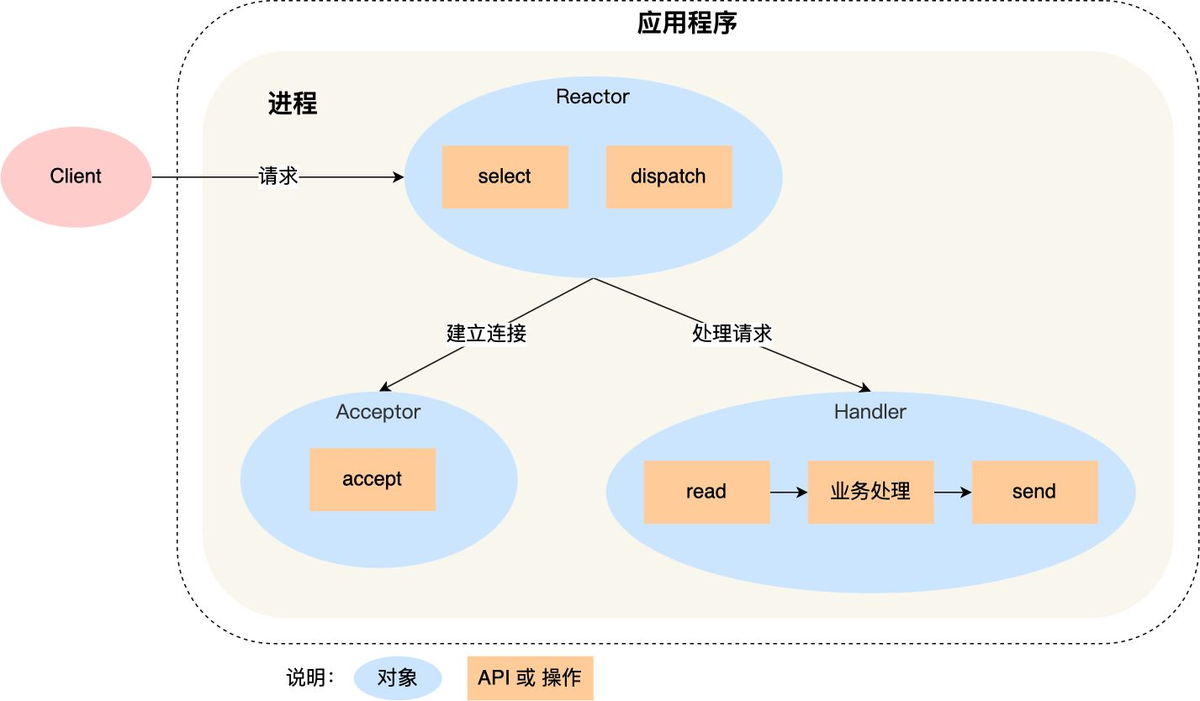
Puede ver que hay tres objetos en el proceso: Reactor, Aceptador y Controlador:
-
La función del objeto Reactor es monitorear y distribuir eventos;
-
La función del objeto Aceptador es obtener la conexión;
-
La función del objeto Handler es gestionar el negocio;
seleccionar, aceptar, leer y enviar son API de programación de red estándar, y el envío y el procesamiento comercial son operaciones que deben completarse.
Descripción del proceso:
El objeto Reactor monitorea los eventos de conexión mediante selección y los distribuye mediante envío después de recibir los eventos;
Si es un evento de establecimiento de conexión, es manejado por el Aceptador, quien acepta la conexión a través de aceptar y crea un Controlador para manejar varios eventos posteriores de la conexión;
Si no es un evento de establecimiento de conexión, Reactor llamará al controlador correspondiente a la conexión (el controlador creado en el paso 2) para responder, y el controlador completará el proceso comercial completo de lectura-> procesamiento comercial-> envío;
Ventajas: el modo es muy simple, no hay comunicación entre procesos ni competencia de procesos;
Desventajas: solo hay un proceso y no se puede ejercer el rendimiento de la CPU de múltiples núcleos; cuando el controlador procesa el negocio en una determinada conexión, todo el proceso no puede manejar los eventos de otras conexiones, lo que puede provocar fácilmente cuellos de botella en el rendimiento.
Escenarios aplicables: solo es aplicable a escenarios con procesamiento empresarial muy rápido. Redis es actualmente un conocido software de código abierto que utiliza un único Reactor y un único proceso.
Redis 6.0 también utiliza subprocesos múltiples, pero la idea de diseño básica sigue siendo un proceso único y un subproceso único, pero la lectura, el análisis y la escritura son subprocesos múltiples y la ejecución de comandos sigue siendo de un solo subproceso.
2.3.2 Subprocesos múltiples de un solo reactor
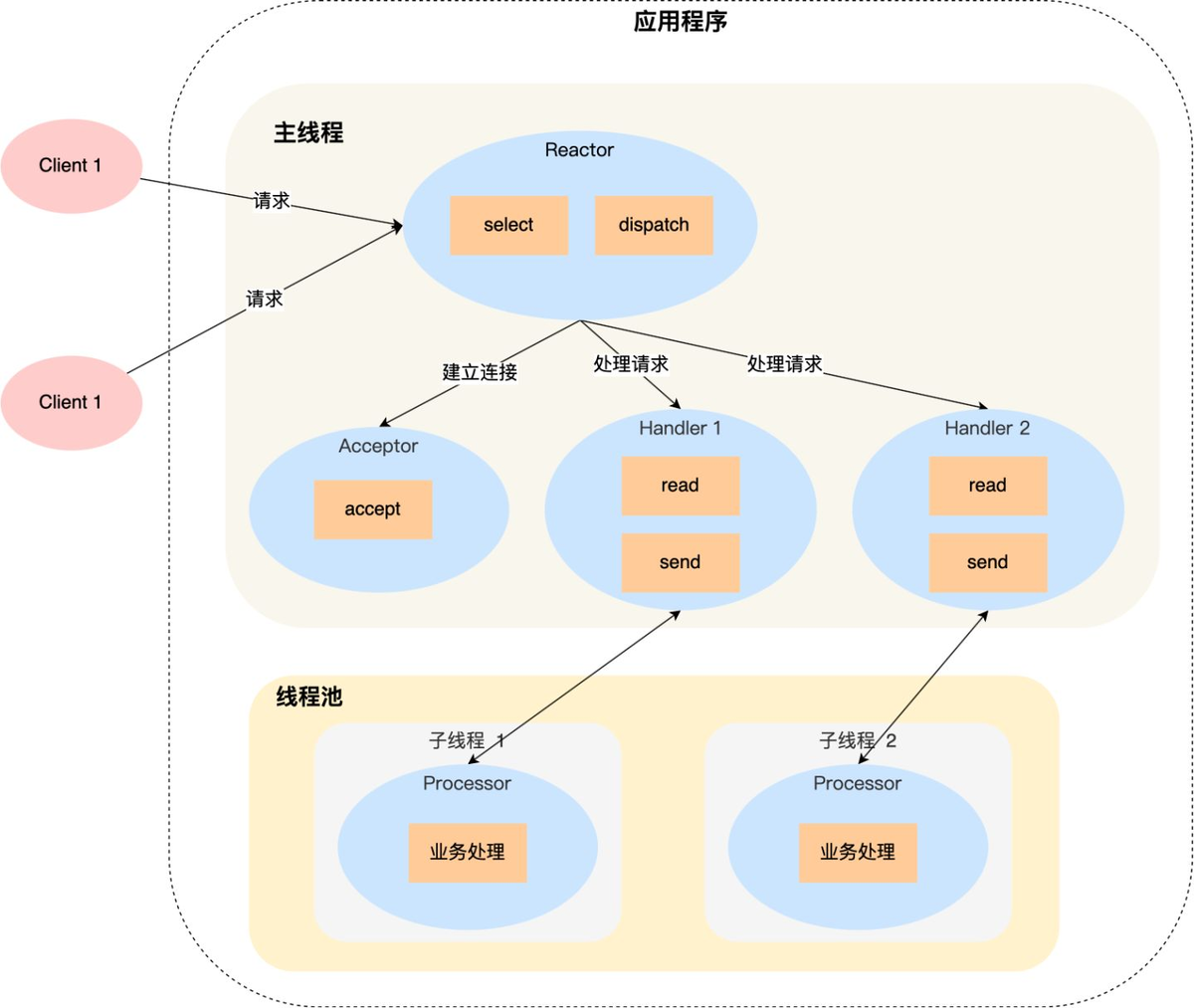
Descripción del proceso:
El objeto Reactor en el hilo principal monitorea los eventos de conexión mediante selección y los distribuye mediante envío después de recibir los eventos;
Si es un evento de establecimiento de conexión, es manejado por el Aceptador, quien acepta la conexión a través de aceptar y crea un Controlador para manejar varios eventos posteriores de la conexión;
Si no es un evento de establecimiento de conexión, Reactor llamará al controlador correspondiente a la conexión (el controlador creado en el paso 2) para responder;
El Controlador solo es responsable de responder a los eventos y no realiza procesamiento comercial; después de que el Controlador lee los datos mediante lectura, se enviará al Procesador para su procesamiento comercial;
El Procesador completará el procesamiento comercial real en un subproceso independiente y luego enviará el resultado de la respuesta al Controlador del proceso principal para su procesamiento; el Controlador devolverá el resultado de la respuesta al cliente a través del envío después de recibir la respuesta;
Aunque ha superado las deficiencias de la solución de proceso/hilo único de Reactor y puede aprovechar al máximo la potencia de procesamiento de las CPU de múltiples núcleos, también tiene los siguientes problemas:
(1) El intercambio y el acceso a datos multiproceso son relativamente complejos e implican mecanismos de protección y exclusión mutua para los datos compartidos;
(2) Reactor es responsable de monitorear y responder a todos los eventos, y solo se ejecuta en el hilo principal. Cuando la concurrencia sea alta en un instante, se convertirá en un cuello de botella en el rendimiento;
Por qué no existe una única solución multiproceso de Reactor:
Si se utilizan varios procesos, una vez que el proceso secundario completa el procesamiento comercial, devolverá los resultados al proceso principal y notificará al proceso principal a qué cliente se envía, lo cual es muy problemático. Debido a que el proceso padre solo escucha los eventos en cada conexión a través de Reactor y luego los asigna, el proceso hijo no se comunica con el proceso padre a través de una conexión. Si desea simular la comunicación entre el proceso padre y el proceso hijo como una conexión y agregar un Reactor para escuchar, es más complicado. Cuando se utilizan subprocesos múltiples, debido a que los subprocesos múltiples comparten datos, la comunicación entre subprocesos es muy conveniente. Aunque se debe prestar especial atención a los problemas de sincronización al compartir datos entre subprocesos, esta complejidad es mucho menor que la complejidad de la comunicación entre procesos.
2.3.3 Multiproceso/hilo Multi-Reactor
Para resolver el problema del Reactor único y los subprocesos múltiples, la forma más intuitiva es cambiar el Reactor único a varios Reactores:
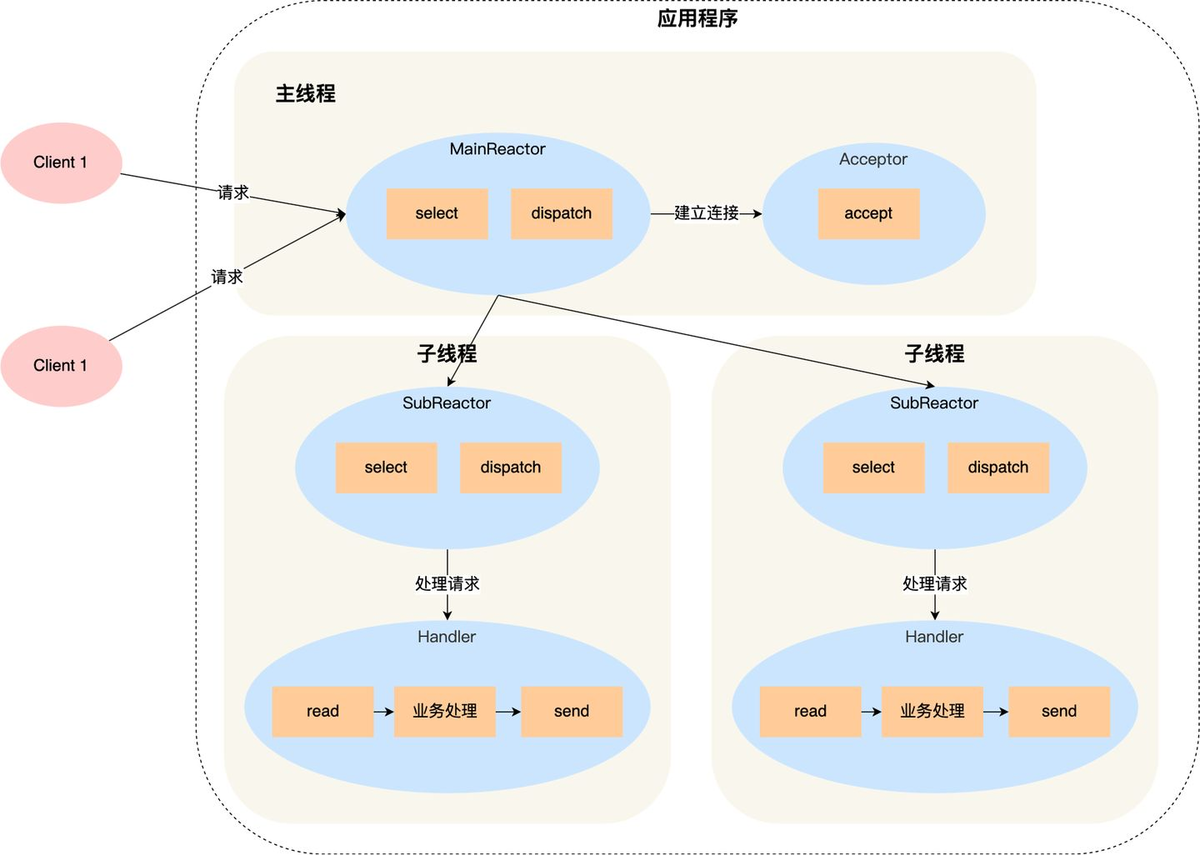
Descripción del proceso:
(1) El objeto mainReactor en el proceso padre monitorea el evento de establecimiento de conexión a través de selección, después de recibir el evento, lo recibe a través del Aceptador y asigna la nueva conexión a un proceso hijo;
(2) El subReactor del subproceso agrega la conexión asignada por el mainReactor a la cola de conexiones para su monitoreo y crea un controlador para manejar varios eventos de la conexión;
(3) Cuando ocurre un nuevo evento, subReactor llamará al controlador correspondiente a la conexión (es decir, el controlador creado en el paso 2) para responder, y el controlador completa el proceso comercial completo de lectura → procesamiento comercial → envío;
La solución multiproceso/hilo de múltiples reactores parece más complicada que la solución de múltiples subprocesos de un solo reactor, pero en realidad es más sencilla de implementar. Las razones principales son:
(1) Las responsabilidades del proceso padre y del proceso hijo son muy claras: el proceso padre solo es responsable de recibir nuevas conexiones y el proceso hijo es responsable de completar el procesamiento comercial posterior.
(2) La interacción entre el proceso padre y el proceso hijo es muy simple: el proceso padre solo necesita pasar la nueva conexión al proceso hijo y el proceso hijo no necesita devolver datos.
(3) Los subprocesos son independientes entre sí y no necesitan sincronizarse ni compartirse (esto se limita a seleccionar, leer, enviar, etc. relacionados con el modelo de red, que no necesitan sincronizarse ni compartirse. "Negocios "Procesamiento" aún puede necesitar sincronizarse y compartirse)
El famoso sistema de código abierto actual Nginx utiliza multi-Reactor y multiproceso, y las implementaciones de multi-Reactor y multi-threading incluyen Memcache y Netty.
Nginx adopta un modo multirreactor y multiproceso, pero la solución es diferente del modo multirreactor y multiproceso estándar. La diferencia específica es que solo se crea el puerto de escucha en el proceso principal, y el Reactor principal no se crea para "aceptar" la conexión, sino que el Reactor del subproceso "acepta" la conexión y el bloqueo se utiliza para Controle que solo un subproceso pueda "aceptar" a la vez. Después de que el proceso "acepte" la nueva conexión, se colocará en su propio Reactor para su procesamiento y no se asignará a otros procesos secundarios.
2.4 Proactor
Reactor es un modelo de red síncrono sin bloqueo, porque las operaciones reales de lectura y envío requieren la sincronización del proceso del usuario. Si la operación de E / S se cambia a asíncrona, el rendimiento se puede mejorar aún más. Este es el modelo de red asíncrona Proactor.
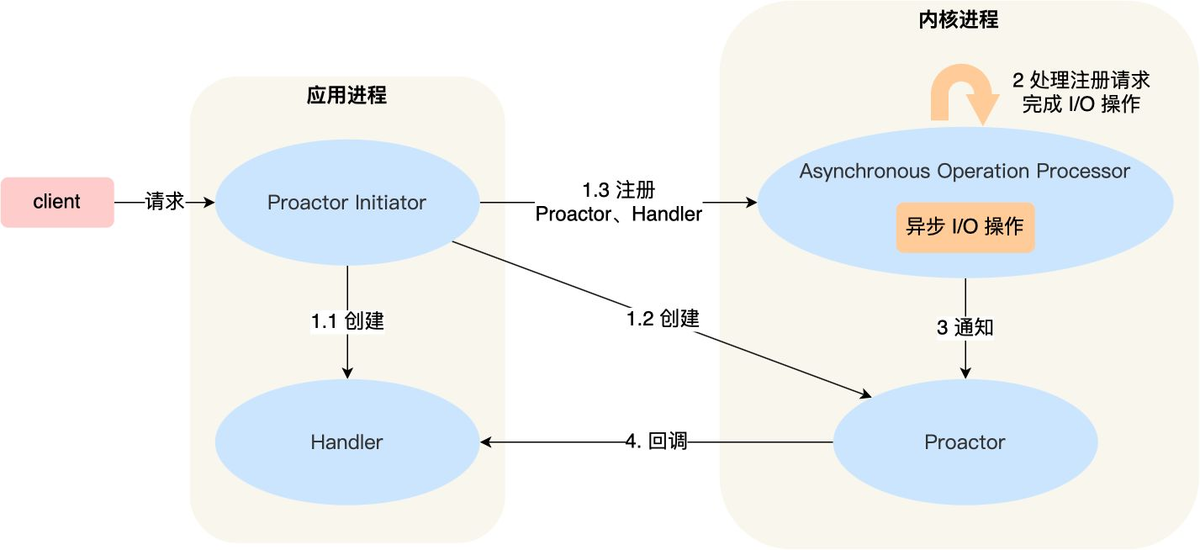
Descripción del proceso:
(1) Proactor Initiator es responsable de crear Proactor y Handler, y registrar Proactor y Handler en el kernel a través del Procesador de operaciones asincrónicas;
(2) El procesador de operaciones asincrónicas es responsable de procesar las solicitudes de registro y completar las operaciones de E / S. El procesador de operaciones asincrónicas notifica a Proactor después de completar las operaciones de E / S;
(3) Proactor vuelve a llamar a diferentes controladores para el procesamiento comercial según los diferentes tipos de eventos.
(4) El Controlador completa el procesamiento comercial y el Controlador también puede registrar un nuevo Controlador en el proceso del núcleo;
En teoría, Proactor es más eficiente que Reactor. La E/S asíncrona puede aprovechar al máximo las funciones DMA para superponer operaciones y cálculos de E/S. Sin embargo, para lograr una verdadera E/S asíncrona, el sistema operativo necesita mucho trabajo.
DMA: el acceso directo a la memoria (acceso directo a la memoria) es una característica importante de todas las computadoras modernas. Permite que los dispositivos de hardware de diferentes velocidades se comuniquen sin depender de una gran cantidad de carga de interrupción de la CPU; actualmente, el verdadero asincrónico I se implementa en Windows a través de IOCP /O, y AIO en el sistema Linux no es perfecto.
Desventajas: La lógica de implementación de Proactor es compleja, depende del soporte del sistema operativo para operaciones asincrónicas. Actualmente, existen pocos sistemas operativos que implementen operaciones asincrónicas puras. Windows implementa un conjunto completo de interfaces de programación asincrónicas que admiten sockets. Este conjunto de interfaces es IOCP, que es E / S asincrónica implementada en el nivel del sistema operativo. En el verdadero sentido, se implementa E / S asincrónica, por lo que la red de alto rendimiento Los programas se implementan en Windows, pero se puede utilizar una solución Proactor más eficiente. El sistema Linux no admite muy bien IO asíncrono y no es muy completo.
Escenarios aplicables: programas controlados por eventos que reciben y procesan de forma asincrónica múltiples solicitudes de servicio simultáneamente.
2.5 La diferencia entre Reactor y Proactor
-
Reactor es un modo de red síncrono sin bloqueo que percibe eventos legibles y escribibles. Cada vez que se detecta un evento (como un evento listo para leer), el proceso de la aplicación debe llamar activamente al método de lectura para completar la lectura de datos, es decir, el proceso de la aplicación debe leer activamente los datos en el caché de recepción del socket en la aplicación. memoria de proceso En, este proceso es sincrónico y el proceso de aplicación solo puede procesar los datos después de leerlos.
-
Proactor es un modo de red asíncrono que percibe eventos de lectura y escritura completados. Al iniciar una solicitud de lectura y escritura asincrónica, es necesario pasar información como la dirección del búfer de datos (utilizado para almacenar los datos del resultado), para que el núcleo del sistema pueda completar automáticamente el trabajo de lectura y escritura de datos por nosotros. Todo el trabajo de lectura y escritura aquí lo realiza el operador. El sistema no necesita que el proceso de la aplicación inicie activamente la lectura/escritura para leer y escribir datos como Reactor. Una vez que el sistema operativo complete el trabajo de lectura y escritura, notificará a la aplicación. proceso para procesar directamente los datos.
Por lo tanto, Reactor puede entenderse como "cuando llega un evento, el sistema operativo notifica al proceso de la aplicación y deja que el proceso de la aplicación lo maneje", mientras que Proactor puede entenderse como "cuando llega un evento, el sistema operativo lo procesa y luego notifica". el proceso de solicitud después de su tramitación". Los "eventos" aquí son eventos de E/S que tienen nuevas conexiones, datos para leer y datos para escribir. El "procesamiento" aquí incluye la lectura del controlador al kernel y la lectura del kernel al espacio del usuario.
Para dar un ejemplo en la vida real, el modelo Reactor significa que el mensajero está abajo y te llama para decirte que el mensajero ha llegado a tu comunidad, debes bajar a recogerlo tú mismo. En el modo Proactor, el mensajero lo entregará directamente a su puerta y luego le notificará.
Tanto Reactor como Proactor son modos de programación de red basados en la "distribución de eventos". La diferencia es que el modo Reactor se basa en eventos de E/S "por completar", mientras que el modo Proactor se basa en eventos de E/S "completados". .
3. Alto rendimiento del clúster
Aunque el rendimiento del hardware informático se ha desarrollado rápidamente, todavía palidece en comparación con la velocidad de desarrollo de las empresas, especialmente después de entrar en la era de Internet, la velocidad de desarrollo de las empresas supera con creces la velocidad de desarrollo del hardware. En el desarrollo de estos negocios, de todos modos no se puede respaldar el rendimiento de una sola máquina y se deben utilizar grupos de máquinas para lograr un alto rendimiento.
Si una persona no puede hacerlo, busque algunas personas más para hacerlo.
Mejorar el rendimiento a través de una gran cantidad de máquinas no es tan simple como sumar máquinas, sino que es una tarea compleja cooperar con varias máquinas para lograr un alto rendimiento.
El diseño de la arquitectura de alto rendimiento del clúster implica principalmente dos aspectos: asignación de tareas y descomposición de tareas.
3.1 Asignación de tareas
La asignación de tareas significa que cada máquina puede manejar tareas comerciales completas y se asignan diferentes tareas a diferentes máquinas para su ejecución. De la siguiente manera, un servidor se convierte en dos servidores:
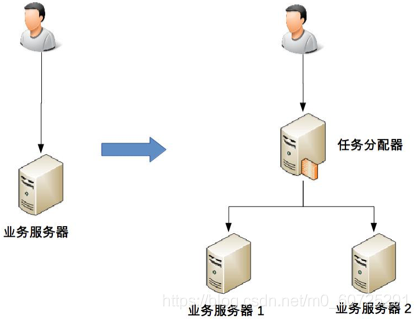
(1) Es necesario agregar un asignador de tareas, que puede ser un dispositivo de red de hardware (por ejemplo, F5, conmutador, etc.), un dispositivo de red de software (por ejemplo, LVS) o un software de equilibrio de carga (por ejemplo, Nginx, HAProxy), o puede ser un sistema de desarrollo propio (puerta de enlace). Elegir un asignador de tareas adecuado también es una cuestión compleja y requiere una consideración exhaustiva de varios factores como el rendimiento, el costo, la mantenibilidad y la disponibilidad.
(2) Existe conexión e interacción entre el asignador de tareas y el servidor empresarial real, es necesario seleccionar un método de conexión adecuado y administrar la conexión. Por ejemplo, establecimiento de conexión, detección de conexión, cómo lidiar con la interrupción de la conexión, etc.
(3) El asignador de tareas necesita agregar un algoritmo de asignación. Por ejemplo, si se debe utilizar un algoritmo de operación por turnos, distribuir según el peso o distribuir según la carga. Si se distribuye según la carga del servidor, el servidor empresarial también debe poder informar su propio estado al asignador de tareas.
La distribución de tareas es en realidad lo que a menudo se denomina equilibrio de carga. Las tareas de trabajo se equilibran y distribuyen a múltiples unidades operativas a través de tecnología de carga. El equilibrio de carga se basa en la estructura de la red y es un medio importante para proporcionar alta disponibilidad del sistema, capacidades de procesamiento y aliviar la presión de la red.
Los diferentes algoritmos de asignación de tareas tienen diferentes objetivos: algunos se basan en consideraciones de carga, otros en consideraciones de rendimiento (rendimiento, tiempo de respuesta) y otros en consideraciones comerciales.
3.1.1 Clasificación de equilibrio de carga
Según las diferentes ubicaciones de implementación, se pueden dividir en dos categorías:
(1) Carga del servidor: equilibrio de carga de hardware y equilibrio de carga de software;
(2) Carga de clientes. (Cinta, Dubbo, Ahorro en la nube de primavera)
Según los diferentes métodos de implementación, se puede dividir en tres categorías:
(1) equilibrio de carga de DNS;
(2) Equilibrio de carga de hardware;
(3) Equilibrio de carga de software.
3.1.2 La diferencia entre el equilibrio de carga del servidor y el equilibrio de carga del cliente
Según la implementación del equilibrio responsable en el lado del servidor (independientemente del software y el hardware), la lista de servidores se colgará debajo del dispositivo de equilibrio de carga (software y hardware) y los nodos defectuosos se eliminarán mediante la detección de latidos para garantizar que todos los nodos del servidor en Se puede acceder a la lista normalmente. Tanto las cargas útiles de software como las cargas útiles de hardware se pueden construir basándose en un enfoque arquitectónico similar al siguiente.
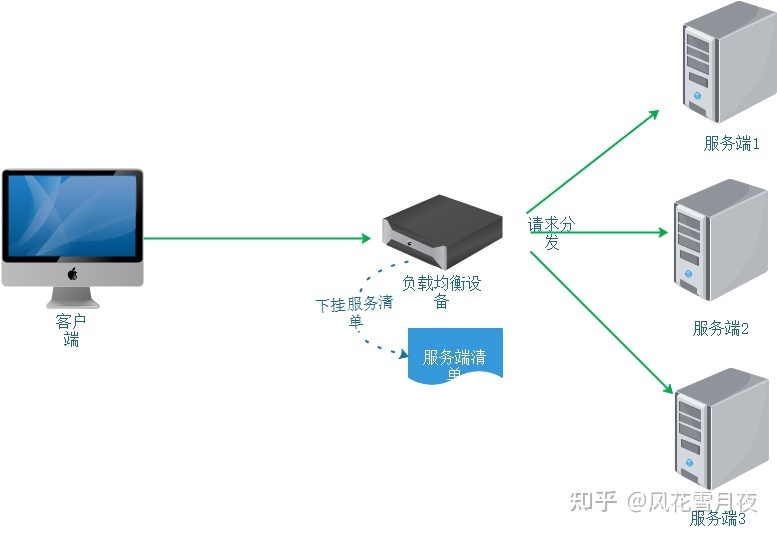
En el equilibrio de carga del cliente, los nodos del cliente mantienen una lista de servicios a los que necesitan acceder, y estas listas provienen del centro de registro de servicios. En comparación con el equilibrio de carga del servidor, el equilibrio de carga del cliente es un concepto muy especializado. El equilibrio de carga del cliente se define en el componente Ribbon del marco distribuido de Spring-Cloud. Cuando se utiliza el marco distribuido Spring-Cloud, es probable que el mismo servicio se inicie varias veces al mismo tiempo. Cuando llega una solicitud, para estos múltiples servicios, la forma en que Ribbon determina qué servicio usar para esta solicitud a través de políticas es la carga del cliente. equilibrio. . En el marco distribuido Spring-Cloud, el equilibrio de carga del cliente es transparente para los desarrolladores, simplemente agregue la anotación @LoadBalanced. La diferencia principal entre el equilibrio de carga del cliente y el equilibrio de carga del servidor radica en la lista de servicios en sí: la lista de servicios de equilibrio de carga del cliente la mantiene el cliente y el servicio intermedio mantiene por separado la lista de servicios de equilibrio de carga del servidor.
3.1.3 Equilibrio de carga DNS
DNS es el método de equilibrio de carga más simple y común y generalmente se utiliza para lograr el equilibrio a nivel geográfico.
ventaja:
1. Simple y de bajo costo: el trabajo de equilibrio de carga lo maneja el servidor DNS y no es necesario desarrollar ni mantener el equipo de equilibrio de carga usted mismo.
2. Acceso cercano, mejora la velocidad de acceso: cuando se analiza DNS, se puede resolver en la dirección del servidor más cercana al usuario en función de la IP de origen de la solicitud, lo que puede acelerar el acceso y mejorar el rendimiento.
defecto:
1. Actualizaciones inoportunas: el tiempo de caché de DNS es relativamente largo. Después de modificar la configuración de DNS, debido a razones de almacenamiento en caché, muchos usuarios continuarán accediendo a la dirección IP antes de la modificación. Dicho acceso fallará y no se logrará el propósito de equilibrio de carga. y También afecta a la normal utilización de los servicios por parte de los usuarios.
2. Escalabilidad deficiente: el control del equilibrio de carga de DNS recae en el proveedor de nombres de dominio y no puede proporcionar funciones más personalizadas y características de expansión basadas en las características comerciales.
3. La estrategia de distribución es relativamente simple: el equilibrio de carga de DNS admite pocos algoritmos, no puede distinguir las diferencias entre servidores (la carga no se puede juzgar en función del estado del sistema y los servicios) y no puede detectar el estado de la copia de seguridad. servidor final.
3.1.4 Equilibrio de carga de hardware
El equilibrio de carga de hardware implementa la función de equilibrio de carga a través de dispositivos de hardware separados. Este tipo de dispositivo es similar a los enrutadores y conmutadores y puede entenderse como un dispositivo de red básico utilizado para el equilibrio de carga. Incluye principalmente F5 y A10, etc.
ventaja:
1. Funciones potentes: admite totalmente el equilibrio de carga en todos los niveles, admite algoritmos integrales de equilibrio de carga y admite el equilibrio de carga global.
2. Rendimiento potente: en comparación, el equilibrio de carga de software puede admitir 100.000 niveles de concurrencia, lo que ya es excelente, mientras que el equilibrio de carga de hardware puede admitir más de 1 millón de concurrencias.
3. Alta estabilidad: el equilibrio de carga de hardware comercial se ha sometido a pruebas rigurosas y a un uso a gran escala, y tiene una alta estabilidad.
4. Admite protección de seguridad: además de la función de equilibrio de carga, el dispositivo de equilibrio de hardware también tiene funciones de seguridad como firewall y ataques anti-DDoS.
defecto:
1. Caro.
2. Pobre capacidad de expansión.
3.1.5 Equilibrio de carga de software
El equilibrio de carga de software implementa la función de equilibrio de carga a través del software de equilibrio de carga. Los más utilizados son Nginx y LVS. Nginx es el equilibrio de carga de software de 7 capas y LVS es el equilibrio de carga de 4 capas del kernel de Linux. La diferencia entre la Capa 4 y la Capa 7 es el protocolo y la flexibilidad.
ventaja:
1. Simple: Tanto la implementación como el mantenimiento son relativamente simples.
2. Barato: simplemente compre un servidor Linux e instale el software.
3. Flexible: el equilibrio de carga de Capa 4 y Capa 7 se puede seleccionar según el negocio, y también se puede expandir más convenientemente según el negocio. Por ejemplo, las funciones personalizadas del negocio se pueden implementar a través de complementos de Nginx.
Desventajas:
1. Rendimiento general: un Nginx puede admitir aproximadamente 50 000 concurrencias
2. La función no es tan poderosa como el equilibrio de carga de hardware.
3. Generalmente, no tiene funciones de seguridad como firewall y ataques anti-DDoS.
3.1.6 Principios de uso
-
El equilibrio de carga de DNS se utiliza para lograr el equilibrio de carga a nivel geográfico;
-
El equilibrio de carga de hardware se utiliza para lograr el equilibrio de carga a nivel de clúster;
-
El equilibrio de carga de software se utiliza para lograr el equilibrio de carga a nivel de máquina.
3.1.7 Algoritmos comunes de equilibrio de carga
-
Estático: asigne tareas con una probabilidad fija, independientemente de la información del estado del servidor, como sondeos, algoritmos de sondeo ponderados, etc.
-
Dinámico: utilice la información del estado de carga en tiempo real del servidor para determinar la asignación de tareas, como el método de conexión mínimo y el método de conexión mínimo ponderado.
-
Aleatorio, al seleccionar aleatoriamente los servicios para su ejecución, generalmente este método se usa menos;
-
Entrenamiento de rotación, implementación predeterminada del equilibrio de carga, procesamiento de colas después de que llega la solicitud;
-
El entrenamiento de rotación ponderada, al clasificar el rendimiento del servidor, asigna pesos más altos a los servidores con alta configuración y baja carga para equilibrar la presión de cada servidor;
-
Address Hash, la programación del servidor se realiza mediante el mapeo de módulo del valor HASH de la dirección solicitada por el cliente.
-
Número mínimo de conexiones; incluso si las solicitudes están equilibradas, la presión puede no estar equilibrada. El método de número mínimo de conexiones consiste en asignar solicitudes al servidor con la menor presión actual en función de las condiciones del servidor, como el número de solicitudes pendientes. y otros parámetros.
3.1.8 Tecnología de equilibrio de carga
-
Tecnología de equilibrio responsable basada en DNS
-
Proxy inverso:
-
Basado en NAT (transacción de dirección de red)
-
El equilibrio de carga del cliente Ribbion implementa SpringCloud El equilibrio de carga del cliente Ribbion es el proyecto central del subproyecto Spring Cloud Netflix. Es una herramienta de carga de cliente basada en Http y TCP, que proporciona principalmente funciones de equilibrio de carga para llamadas al servidor y reenvío de puerta de enlace API. Spring Cloud Ribbon es un marco de barra de herramientas que no necesita implementarse ni ejecutarse de forma independiente, sino que está integrado con otros proyectos para su uso. A través de la encapsulación de Spring Cloud Ribbon, es muy sencillo implementar el equilibrio de carga del cliente en la arquitectura de microservicios Spring Cloud.
Spring Cloud Alibaba integra Ribbon de forma predeterminada. Cuando una aplicación Spring Cloud se integra con Spring Cloud Alibaba Nacos Discovery, activará automáticamente la configuración automática de Ribbon implementada en Nacos (el interruptor Ribbon.nacos.enabled controla si se activa automáticamente y el el valor predeterminado es verdadero). El mecanismo de mantenimiento de ServerList estará cubierto por NacosServerList, y la lista de instancias de servicio será mantenida por el mecanismo de gobernanza de servicios de Nacos. Nacos todavía usa la implementación de equilibrio de carga predeterminada de Spring Cloud Ribbon de manera predeterminada, pero solo extiende el mecanismo de mantenimiento de la lista de instancias de servicio.
3.1.9 Cargar la clase de prioridad más baja
El sistema de equilibrio de carga asigna de acuerdo con la carga del servidor. La carga aquí no es necesariamente la "carga de la CPU" en el sentido habitual, sino la presión actual del sistema, que puede medirse por la carga de la CPU o el número de Conexiones, utilización de E/S O, rendimiento de la tarjeta de red, etc. para medir la presión del sistema. Carga más baja primero:
-
LVS, un dispositivo de equilibrio de carga de red de 4 capas, puede juzgar el estado del servidor en función del "número de conexiones": cuanto mayor sea el número de conexiones del servidor, mayor será la presión sobre el servidor.
-
Nginx, un sistema de carga de red de 7 capas, puede juzgar el estado del servidor en función del "número de solicitudes HTTP"
-
Si desarrolla su propio sistema de equilibrio de carga, puede elegir indicadores para medir la presión del sistema en función de las características comerciales. Si hace un uso intensivo de la CPU, la presión del sistema se puede medir mediante la "carga de la CPU"; si hace un uso intensivo de E/S, la presión del sistema se puede medir mediante la "carga de E/S".
ventaja:
-
El algoritmo con la prioridad de carga más baja resuelve el problema de no poder detectar el estado del servidor en el algoritmo de sondeo.
defecto:
-
El algoritmo con el menor número de conexiones primero requiere que el sistema de equilibrio de carga cuente las conexiones actualmente establecidas por cada servidor. Su escenario de aplicación se limita a que cualquier solicitud de conexión recibida por el equilibrio de carga se reenviará al servidor para su procesamiento. De lo contrario, si la relación entre el sistema de equilibrio de carga y el servidor es fija. El método del grupo de conexiones no es adecuado para este algoritmo.
-
El algoritmo de prioridad más baja de carga de CPU requiere que el sistema de equilibrio de carga recopile la carga de CPU de cada servidor de alguna manera y determine si se utiliza una carga de 1 minuto como estándar o una carga de 15 minutos como estándar. Definitivamente es mejor que 15 minutos. Los minutos son mejores o peores. Los intervalos de tiempo óptimos para diferentes servicios son diferentes. Si el intervalo de tiempo es demasiado corto, fácilmente causará fluctuaciones frecuentes. Si el intervalo de tiempo es demasiado largo, puede causar una respuesta lenta cuando llegue el valor máximo.
3.1.10 Clase de mejor rendimiento
El algoritmo de prioridad de carga más baja se asigna desde la perspectiva del servidor, mientras que el algoritmo de prioridad de mejor rendimiento se asigna desde la perspectiva del cliente, dando prioridad a la asignación de tareas al servidor con la velocidad de procesamiento más rápida, a través de este método se logra la respuesta más rápida a el cliente.
defecto:
-
El sistema de equilibrio de carga necesita recopilar y analizar el tiempo de respuesta de cada tarea de cada servidor. En un escenario donde se procesa una gran cantidad de tareas, esta recopilación y estadísticas en sí también consumirán mucho rendimiento.
-
Para reducir este consumo estadístico, se puede utilizar el muestreo para recopilar estadísticas y se requiere una frecuencia de muestreo adecuada.
-
Ya sean todas estadísticas o estadísticas de muestreo, es necesario seleccionar el período apropiado
3.1.11 Clase hash
En algunos escenarios, se espera que una solicitud específica siempre se ejecute en un servidor. En este caso, es necesario utilizar un algoritmo hash coherente para lograrlo.
Ejemplo: los datos del usuario se almacenan en caché en el servicio, por lo que es mejor mantener el mismo servidor cada vez que el usuario lo visita.
Los algoritmos de equilibrio de carga de Cache Redis, Memcache, Nginx y Dubbo utilizan Hash consistente.
Hay dos formas de Hash:
-
Hash de dirección de origen
-
Hash de identificación
Introducción al algoritmo específico: https://blog.csdn.net/u011436427/article/details/123344374
3.1.12 Clúster distribuidor de tareas
A medida que la escala del sistema continúa expandiéndose, el asignador de tareas también enfrentará presión de carga, por lo que el asignador de tareas también necesita usar clústeres para expandir la capacidad y mejorar la disponibilidad.

Esta arquitectura es más compleja que la arquitectura de dos servidores empresariales, reflejándose principalmente en:
-
El asignador de tareas ha cambiado de uno a varios (correspondiente al asignador de tareas 1 al asignador de tareas M en la figura). La complejidad que trae este cambio es que es necesario asignar diferentes usuarios a diferentes asignadores de tareas (es decir, la línea de puntos "Asignación de usuarios "parte en la figura), los métodos comunes incluyen sondeo DNS, DNS inteligente, CDN (red de entrega de contenido, red de distribución de contenido), dispositivo GSLB (equilibrio de carga global del servidor, equilibrio de carga global), etc.
-
La conexión entre los asignadores de tareas y los servidores empresariales ha cambiado de una simple red "1 a muchos" (un asignador de tareas se conecta a varios servidores empresariales) a una red "muchos a muchos" (varios asignadores de tareas se conectan a varios servidores empresariales). estructura de forma.
-
La cantidad de máquinas se expande de 3 a 30 (generalmente la cantidad de asignadores de tareas es menor que la de los servidores comerciales. Aquí suponemos que hay 25 servidores comerciales y 5 asignadores de tareas), y la complejidad de la gestión del estado y el manejo de fallas también aumenta. muy.
Los dos ejemplos anteriores toman como ejemplo el procesamiento comercial. De hecho, "tarea" cubre una amplia gama y puede referirse a un procesamiento comercial completo o una tarea específica. Por ejemplo, "almacenamiento", "informática", "almacenamiento en caché", etc. pueden considerarse como una tarea, por lo que el sistema de almacenamiento, el sistema informático y el sistema de caché pueden construirse de acuerdo con el método de asignación de tareas. Además, un "asignador de tareas" no tiene por qué ser una máquina físicamente existente o un programa que se ejecute de forma independiente. También puede ser un algoritmo integrado en otros programas, como la arquitectura de clúster de Memcache.
3.2 Descomposición de tareas
A través de la asignación de tareas, se puede superar el cuello de botella del rendimiento de procesamiento de una sola máquina y se pueden agregar más máquinas para satisfacer las necesidades de rendimiento del negocio. Sin embargo, si el negocio en sí se vuelve cada vez más complejo, el rendimiento solo se puede expandir a través de asignación de tareas Los ingresos serán cada vez menores.
Por ejemplo, cuando el negocio es simple, si una máquina se expande a 10 máquinas, el rendimiento se puede aumentar 8 veces (es necesario deducir parte de la pérdida de rendimiento causada por el grupo de máquinas, por lo que no puede alcanzar las 10 veces teóricas). ), pero si el negocio se vuelve cada vez más complejo, si una máquina se expande a 10, el rendimiento solo puede mejorar 5 veces. La razón principal de este fenómeno es que el negocio se vuelve cada vez más complejo y el rendimiento de procesamiento de una sola máquina será cada vez menor. Para seguir mejorando el rendimiento, es necesario adoptar el segundo método: la descomposición de tareas.
Continuando con la arquitectura en "Asignación de tareas" anterior como ejemplo, si el "servidor empresarial" se vuelve cada vez más complejo, se puede dividir en más componentes, tomando como ejemplo la arquitectura backend de WeChat.
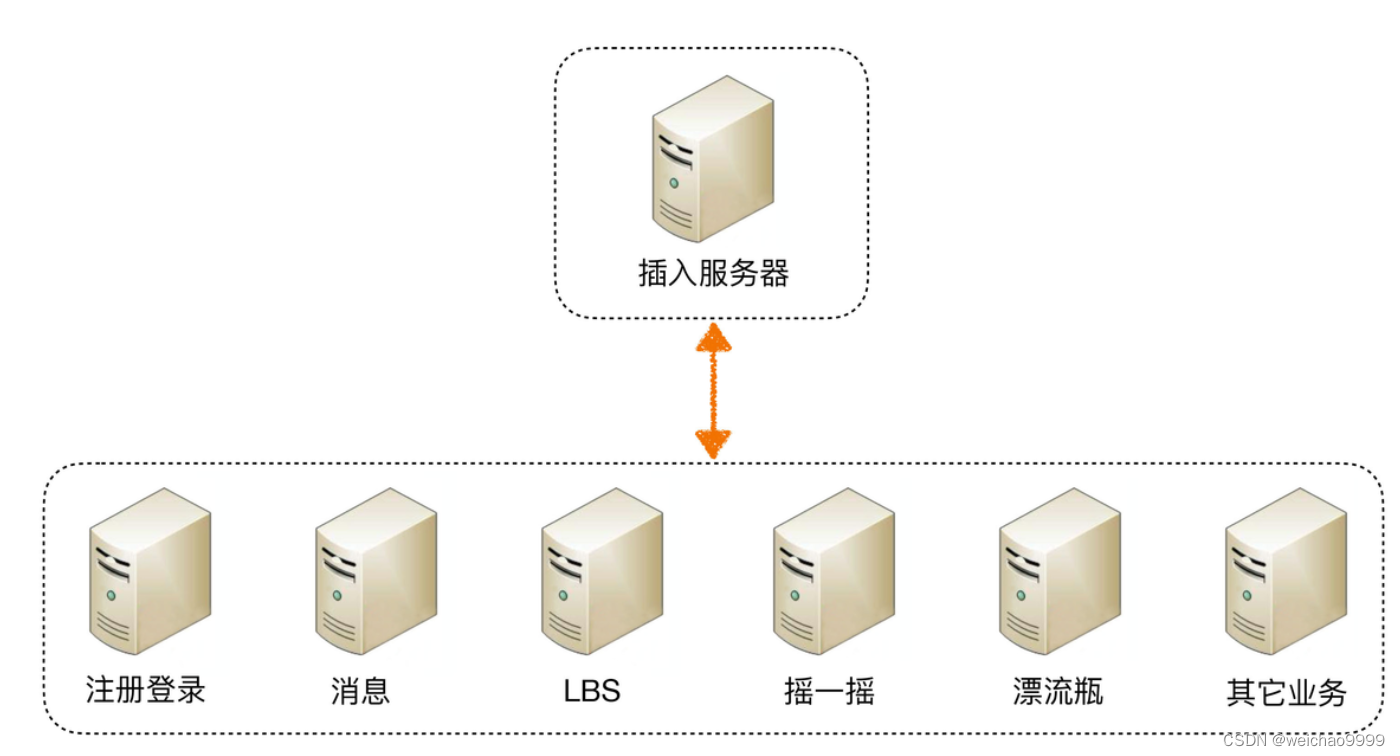
Como se puede ver en el diagrama de arquitectura anterior, la arquitectura backend de WeChat divide lógicamente cada subnegocio, que incluye: acceso, registro e inicio de sesión, mensajería, LBS, batido, botella de deriva y otros negocios (chat, video, Momentos, etc.). ).
Mediante este método de descomposición de tareas, el sistema empresarial unificado pero complejo original se puede dividir en sistemas empresariales pequeños y simples que requieren la cooperación de múltiples sistemas. Desde un punto de vista empresarial, la descomposición de tareas no reducirá la funcionalidad ni reducirá la cantidad de código (de hecho, la cantidad de código puede aumentar porque las llamadas se cambian desde dentro del código a llamadas a través de la interfaz entre servidores), entonces, ¿por qué pasar? ¿La descomposición de tareas mejora el rendimiento?
Hay varios factores principales:
(1) Los sistemas simples son más fáciles de lograr un alto rendimiento
Cuanto más simple sea el funcionamiento del sistema, menos puntos afectarán al rendimiento, lo que facilitará la realización de una optimización específica. Cuando el sistema es muy complejo, en primer lugar, es más difícil encontrar el punto clave de rendimiento porque hay demasiados puntos que deben ser considerados y verificados; en segundo lugar, incluso si requiere mucho esfuerzo encontrarlo, no es Es fácil modificarlo, porque se puede cambiar el punto clave de rendimiento A. Se ha mejorado, pero sin darse cuenta ha reducido el rendimiento del punto B. No solo no ha mejorado el rendimiento de todo el sistema, sino que también puede disminuir.
(2) Se puede ampliar para una sola tarea
Cuando cada tarea lógica se descompone en subsistemas independientes, los cuellos de botella en el rendimiento de todo el sistema son más fáciles de descubrir y, después del descubrimiento, solo es necesario optimizar o mejorar el rendimiento del subsistema con el cuello de botella, sin cambiar todo el sistema, y el el riesgo será mucho menor. Tome la arquitectura backend de WeChat como ejemplo: si el número de usuarios crece demasiado rápido y el rendimiento del subsistema de registro e inicio de sesión se ve obstaculizado, solo necesita optimizar el rendimiento del subsistema de inicio de sesión y registro (que puede ser optimización de código o simplemente agregue máquinas) El mensaje Otros subsistemas como la lógica y la lógica LBS no necesitan cambiarse en absoluto.
Dado que descomponer un sistema unificado en múltiples subsistemas puede mejorar el rendimiento, ¿no es mejor dividirlo lo más finamente posible? Por ejemplo, el backend de WeChat anterior tiene actualmente 7 subsistemas lógicos. Si estos 7 subsistemas lógicos se subdividen en 100 subsistemas lógicos, ¿será mayor el rendimiento?
De hecho, de lo contrario, no solo no mejorará el rendimiento, sino que también se reducirá. La razón principal es que si el sistema se divide demasiado finamente, para completar un determinado negocio, el número de llamadas entre sistemas aumentará. exponencialmente, y el número de llamadas entre sistemas aumentará exponencialmente.El canal de llamada se transmite actualmente a través de la red y su rendimiento es mucho menor que el de la llamada a función en el sistema. Explícalo con un diagrama sencillo.
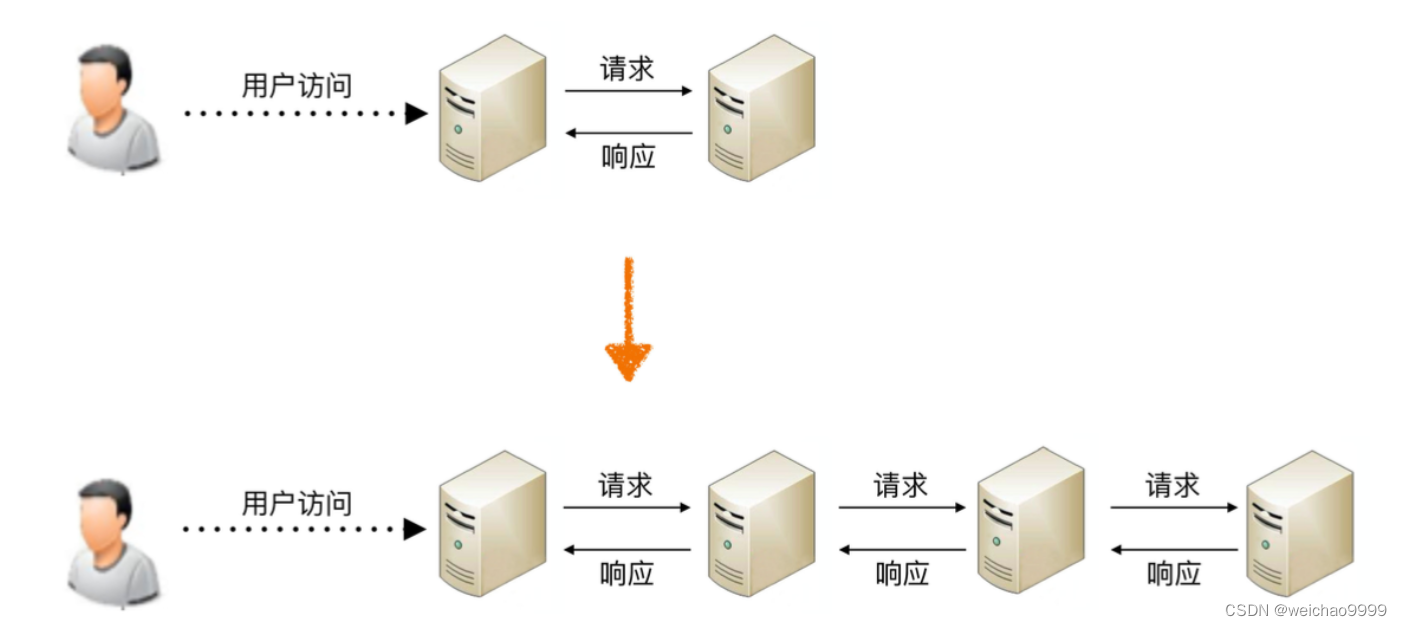
Como se puede ver en la figura, cuando el sistema se divide en dos subsistemas, el acceso del usuario requiere una solicitud entre sistemas y una respuesta; cuando el sistema se divide en cuatro subsistemas, el número de solicitudes entre sistemas cambia de uno a Incrementado a 3 veces; si continúa dividiéndose en 100 subsistemas, para completar el acceso de un determinado usuario, el número de solicitudes entre sistemas se convierte en 99 veces.
Para simplificar la descripción, se abstrae el modelo más simple: suponiendo que estos sistemas utilizan conexiones de red IP, idealmente una solicitud y una respuesta tardan 1 ms en la red, y el procesamiento empresarial en sí tarda 50 ms. También se supone que la división del sistema no tiene ningún impacto en el rendimiento de una sola solicitud comercial. Cuando el sistema se divide en 2 subsistemas, se necesitan 51 ms para procesar el acceso de un usuario, y cuando el sistema se divide en 100 subsistemas, se necesitan 51 ms. para procesar el acceso de un usuario. En realidad alcanzó los 149ms.
Aunque la división del sistema puede mejorar el rendimiento del procesamiento empresarial hasta cierto punto, la mejora del rendimiento también es limitada. Es imposible que el procesamiento empresarial demore 50 ms cuando el sistema no está dividido, pero solo 1 ms después de la división del sistema, porque Lo que en última instancia determina el rendimiento del procesamiento empresarial es la lógica de negocios en sí. Siempre que la lógica de negocios en sí no sufra cambios importantes, el rendimiento teórico tiene un límite superior. La división del sistema puede acercar el rendimiento a este límite, pero no puede superar este límite. Por lo tanto, los beneficios de rendimiento que aporta la descomposición de tareas tienen un cierto grado. No es que cuanto más detallada sea la descomposición de tareas, mejor. Para el diseño de arquitectura, cómo captar esta granularidad es muy crítico.